分享第二篇论文阅读笔记,欢迎指正,LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model
论文:https://arxiv.org/abs/2304.15010
代码:https://github.com/ZrrSkywalker/LLaMA-Adapter
介绍
本文提出了 LLaMA-Adapter V2,一种参数高效的视觉指令模型。
主要通过以下方法来增强LLaMA-Adapter
-
解锁更多可学习参数:解锁更多的可学习参数(例如,norm, bias 和 scale),将指令跟随能力分布到整个LLaMA模型中,而不仅仅是Adapter部分。
-
早期融合策略:将视觉token只输入到LLM的早期层,尽早融入视觉知识。
-
联合训练方法:引入了一种图像-文本对和指令跟随数据的联合训练方法,通过优化不同组的可学习参数来减轻这两个任务(图像-文本对齐和指令跟随)之间的干扰。
-
在推理时结合其他模型,例如图像字幕生成/OCR系统等;
LLaMA-Adapter V2与LLaMA-Adapter相比,仅增加了1400万个参数就能执行多模态指令。
虽然一开始的LLaMA-Adapter可以通过冻结指令跟随模型,然后训练投影层来实现图像-文本对齐从而达到不需要多模态数据也能得到多模态模型,但是视觉特征往往主导模型的回应,从而降低了模型指令跟随的能力。
因此在LLaMA-Adapter V2 中,作者仅将动态视觉提示分发到前 K 层,而不会过分影响最后几层模型的自适应输出,所以使得图像文本对齐不再破坏模型的指令跟随能力。
最终所有可训练参数仅占整个模型的约 0.04%,因此 LLaMA-Adapter V2 仍然是一种参数高效的方法。
回顾LLaMA-Adapter
- 零初始化注意力。LLaMA-Adapter冻结了整个LLaMA模型,引入拥有1.2M参数的额外轻量级适配器模块。适配器层用于 LLaMA 的较高的 Transformer 层,并将一组可学习的软提示连接起来作为词标记的前缀(软提示向量在训练过程中逐步调整,以使模型能够实现指令跟随)。为了将新适应的知识融入到冻结的 LLaMA 中,LLaMAAdapter 提出了一种零初始化注意机制,在训练过程中,门控幅度逐渐增加,从而逐渐将指令跟踪能力注入冷冻的 LLaMA 中。
- 简单的多模态变体。除了使用纯语言指令进行微调之外,LLaMA-Adapter 还可以合并图像和视频输入以进行多模态推理。例如,在处理图像时,LLaMA-Adapter 采用预先训练的视觉编码器(例如 CLIP )来提取视觉特征。然后,这些特征被聚合成全局特征,并通过可学习的投影层,以使视觉语义与语言嵌入空间保持一致。之后,全局视觉特征会按元素添加到 Transformer 较高层的每个适应提示中。这使得 LLaMA-Adapter 能够根据文本和视觉输入生成响应。
- 开放式多模式推理。虽然 LLaMA-Adapter 能够处理相对简单的任务,例如 ScienceQA,但仍不清楚它是否可以生成开放式响应,例如通用视觉问答所需的响应。为了研究这一点,作者首先从 LLaMA-Adapter 开始,用语言指令数据进行预训练,以利用其现有的指令跟随功能。然后通过在 COCO Caption 数据集上微调其适配器模块和视觉投影层来进行实验。最后作者发现新学习的视觉提示往往会主导适应提示,从而超越固有的指令跟随特征。因此提出了LLaMAAdapter V2,一种参数高效的视觉指令模型,以充分释放LLaMA的多模态潜力。
LLaMA-Adapter V2
线性层的偏置调整
LLaMA-Adapter 在冻结的 LLaMA 模型上采用可学习的适应提示和零初始化注意机制。但参数更新仅限于适应提示和门控因子,没有修改LLM的内部参数,这限制了其进行深度微调的能力。所以为了自适应地处理指令跟踪数据的任务,作者解冻了 LLaMA 中的所有归一化层,对于 Transformer 中的每个线性层,添加一个偏差和一个比例因子作为两个可学习参数。
具有不相交参数的联合训练
由于 500K 图文对和 50K 指令数据之间的数据量差异,简单的将它们组合起来进行优化可能会严重损害 LLaMA-Adapter 的指令跟随能力。
这里作者提出了一种 联合训练策略,通过优化 LLaMA-Adapter V2 中不同的参数组来分别处理 图像-文本对齐 和 指令跟随 两个任务。
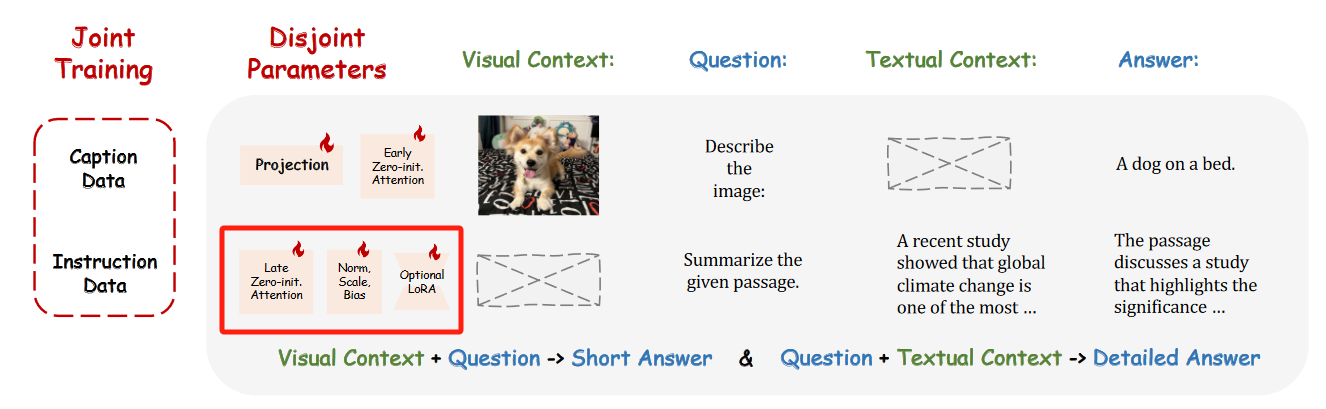
- 图像-文本对齐训练:对于图像-文本配对数据,仅优化与 图像理解 相关的参数,包括 视觉投影层(visual projection layers) 和 早期零初始化注意力层(early zero-initialized attention with gating)。
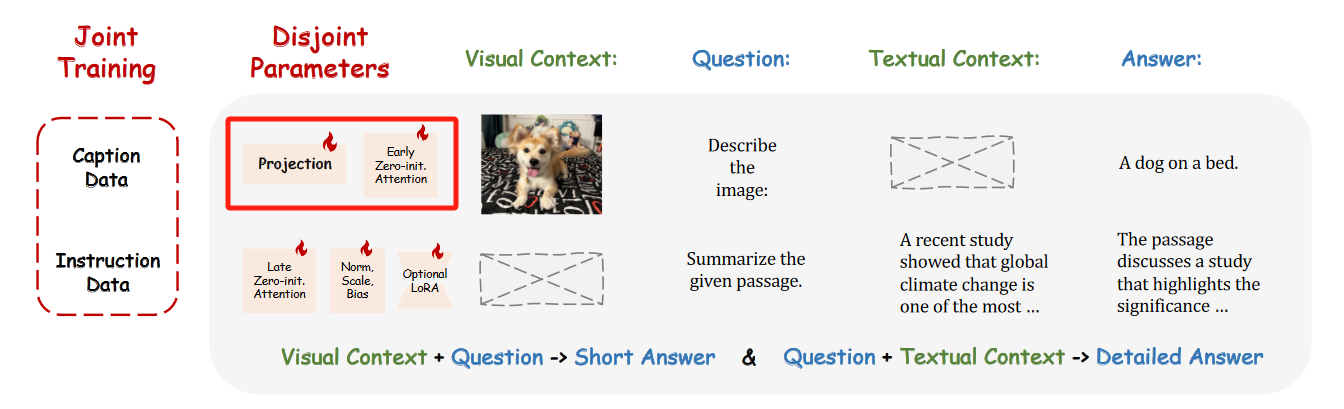
- 指令跟随训练:对于语言指令数据,优化与 语言生成 相关的参数,包括 后期适配器提示(late adaptation prompts)、零初始化注意力机制的门控(zero gating)、未冻结的归一化层(unfrozen norm)、以及 新增的偏置和缩放因子(或者可选的低秩适配(low-rank adaptation))。
视觉知识的早期融合
LLaMA-Adapter V2 将 编码后的视觉标记(visual tokens) 和 适配提示 分别注入到不同的 Transformer 层,而不是将它们直接融合在一起。
- 对于共享的数据集适配提示仍然在最后的 L 层插入(例如 L=30)。
- 对于输入的视觉提示,它们在 第一层 Transformer 中与词标记直接拼接,并使用 零初始化注意力 机制,而不是与适配提示融合。
集成其他模型
LLaMA-Adapter V2 通过引入专家系统(如图像描述、OCR 和搜索引擎)来增强其视觉指令跟随能力。相比于大规模图像-文本训练数据,LLaMA-Adapter V2 在小规模数据集上进行微调,更高效,但是会面临视觉指令跟随能力不足的问题。专家系统为模型提供额外的视觉推理能力。
实验
实验设置
训练数据。52K 单轮指令数据(来自 GPT4-LLM)、567K 图像描述数据(来自 COCO Caption),以及 80K 对话数据(来自 ShareGPT)。与 我们上一篇读的论文 LLaVA 不同,该模型没有使用视觉指令数据。
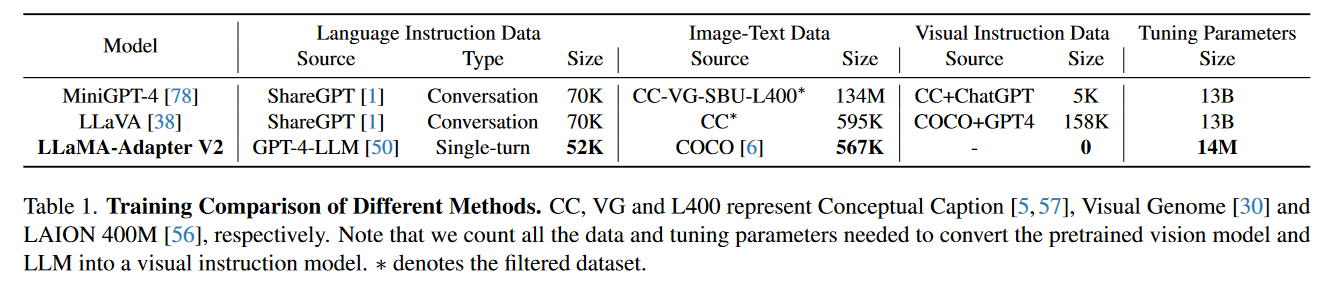
实现细节。在 LLaMA-7B 模型的实现中,静态适配提示被插入到最后 31 层,动态视觉提示则附加到第一层,提示长度为 20。所有归一化层的参数、线性层的偏置和缩放因子在训练过程中都会更新,其他 LLaMA 的参数保持冻结。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【多模态读论文系列】LLaMA-Adapter V2论文笔记

发表评论 取消回复