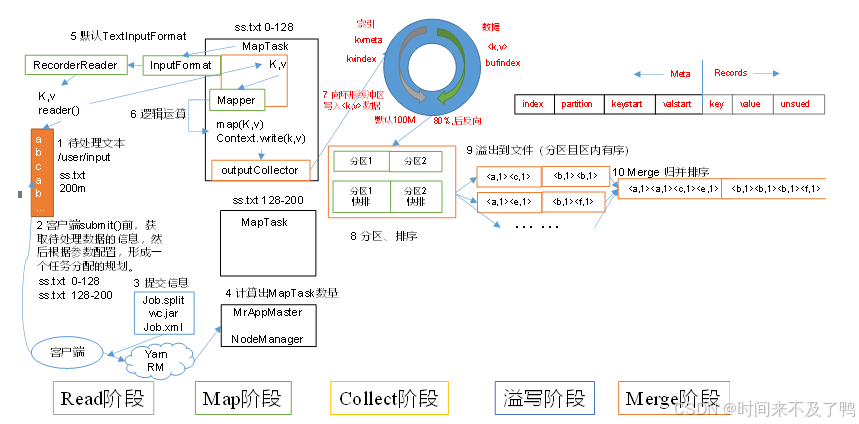
MapTask工作机制
(1)Read阶段:MapTask通过InputFormat获得的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:利用快速排序算法
(5)Merge阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
Reduce-join案例
将左边两个表合并为右边的表

数据清洗(ETL)
在运行核心业务MapReduce程序之前,往往要先对数据进行清洗,清理掉不符合用户要求的数据。清理的过程往往只需要运行Mapper程序,不需要运行Reduce程序。
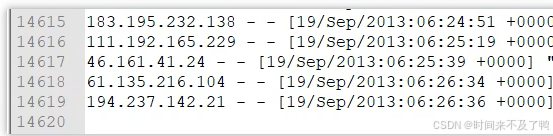
原始数据:
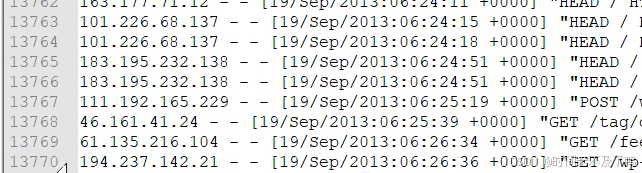
清洗后的数据
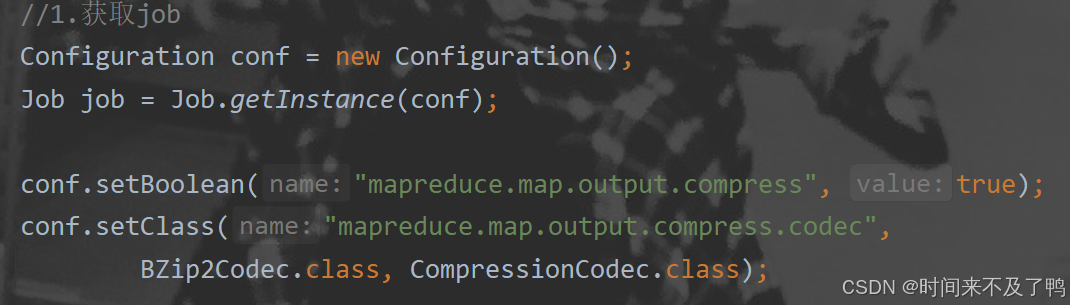
Hadoop数据压缩
Map端输出压缩
运行后不会产生.bzip

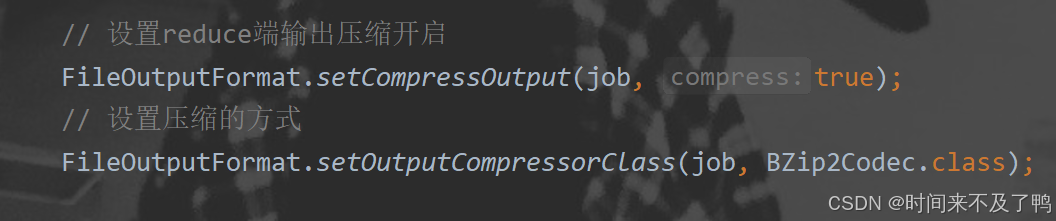
reduce端输出压缩
代码更改
输出结果

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Hadoop---MapReduce(3)

发表评论 取消回复