在现代应用架构中,缓存是提升性能的关键组件。
Redis,作为一个高性能的键值存储系统,因其快速的数据访问能力而被广泛使用。然而,由于物理内存的限制,Redis必须在存储空间和性能之间找到平衡,这就引出了缓存淘汰策略的重要性。
为什么要淘汰
比如说线上偶尔会遇到本地缓存了太多数据,导致应用内存不足的问题。
像Java这样具有自动垃圾回收功能的编程语言时,如果内存不足,就可能频繁触发垃圾回收过程,甚至触发完整的垃圾回收(full GC),影响应用程序的性能。所以使用缓存肯定要控制住缓存的内存使用量。
当达到了内存使用上限,但是又需要加入新的键值对时,怎么办?
最保守的做法就是直接报错,那么就没有办法缓存新的数据了。后续如果缓存中已有的数据过期了,才能缓存新的数据。
但是对于大多数的业务来说,已经在缓存中的数据可能用不上了,虽然还没有过期,但是可以考虑淘汰掉,腾出空间来存放新的数据,这些新的数据比老的数据有更大的可能性被使用。
淘汰策略
缓存淘汰策略是指当缓存达到其最大容量时,决定哪些数据应该被移除以腾出空间给新数据的机制。Redis提供了多种缓存淘汰策略,每种策略都有其特定的使用场景和性能影响。
noeviction(默认策略)
noeviction策略简单地拒绝所有写入操作,当内存达到限制时,新的写入请求会被返回错误。这种策略适用于那些不能容忍数据丢失,且写入请求较少的场景。
allkeys-lru
allkeys-lru策略会从所有键中选择最近最少使用的键进行淘汰。这种策略适用于那些对所有数据的访问频率大致相同的场景,例如,缓存静态数据。
volatile-lru
volatile-lru策略仅从设置了过期时间的键中选择最近最少使用的键进行淘汰。这种策略适用于那些对过期数据敏感,且希望在内存不足时优先移除即将过期数据的场景。
allkeys-random
allkeys-random策略从所有键中随机选择键进行淘汰。这种策略适用于那些对数据的访问模式没有特定偏好,且希望以随机方式淘汰数据的场景。
volatile-random
volatile-random策略从设置了过期时间的键中随机选择键进行淘汰。这种策略适用于那些希望在内存不足时随机移除即将过期数据的场景。
volatile-ttl
volatile-ttl策略从设置了过期时间的键中选择即将过期的键进行淘汰。这种策略适用于那些希望在内存不足时优先移除即将过期数据的场景,但与volatile-lru相比,它更倾向于移除那些剩余时间最短的数据。
LRU
LRU(Least Recently Used)是指最近最少使用算法。当缓存容量不足的时候,就从所有的 key 里面挑出一个最近一段时间最长时间未使用的 key淘汰掉。
在实践中,一般是优先考虑 LRU,因为 LRU 对时间局部性突出的应用非常友好,而大多数的应用场景都满足时间局部性的要求。
时间局部性是指最近被访问过的数据在未来也很可能被再次访问的特性。大多数应用场景都具有这种特性,因此LRU算法能够有效地保留最近被访问的数据,淘汰那些长时间未被访问的数据。
弊端
但是 LRU 在一些特殊的场景下,表现的也不好。
(1)访问历史记录
因为越是历史悠久的,越有可能已经被淘汰了。
(2)遍历
在遍历过程中,LRU算法可能会保留当前遍历到的对象,因为这些对象最近被访问过。但实际上,已经被遍历过的对象可能应该被淘汰,以便为尚未遍历到的对象腾出空间。这可能导致缓存命中率降低,因为缓存中保留了很多已经不需要的数据,而需要的数据却没有被缓存。
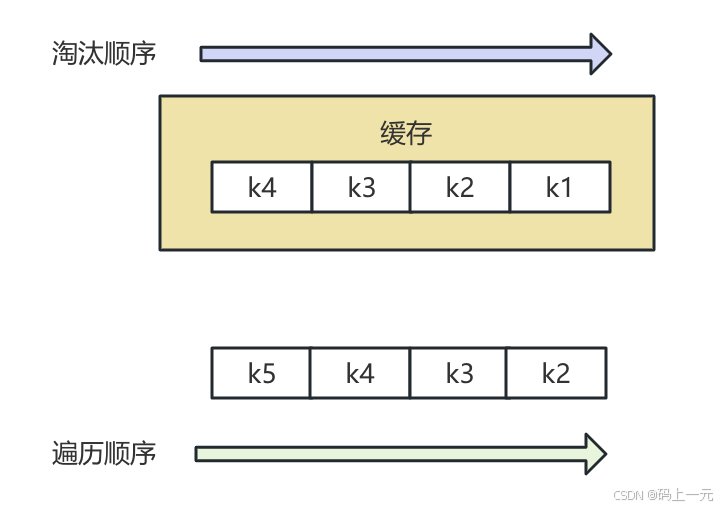
例如,图中遍历到 k5 的时候会触发淘汰,把 k4 淘汰了。紧接着遍历 k4,会把 k3 淘汰了。以此类推,最终结果就是缓存完全没命中。
实现
利用链表把 key 连起来,然后每次被访问到的 key 都挪到队尾,那么队首就是最近最长时间未访问过的 key,当缓存容量不足时,就从队首开始淘汰 key。
比如借助 Java 的 LinkedHashMap 去实现 LRU 算法。
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int capacity;
// 调用LinkedHashMap的构造函数
public LRUCache(int capacity) {
// 设置一个适当的负载因子以减少rehash操作
// 第三个参数true表明LinkedHashMap按照访问顺序来排序,最近访问的在尾部,最老访问的在头部
super(capacity, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当Map中数据量大于指定缓存个数的时候,返回true,自动删除最老的数据
return size() > capacity;
}
// 提供get和put方法
public V get(Object key) {
return super.get(key);
}
public V put(K key, V value) {
return super.put(key, value);
}
// 打印所有缓存中的项
public void printCache() {
super.entrySet().forEach(entry -> System.out.println(entry.getKey() + " : " + entry.getValue()));
}
}
自定义淘汰策略
比如说某个服务同时服务于 VIP 用户和普通用户,那么完全可以在缓存触发淘汰的时候,先把普通用户的数据淘汰了。所以可以考虑为每一个键值对绑定一个优先级,每次缓存要执行淘汰的时候,就从先淘汰优先级最低的数据。
利用有序集合控制键值对数量,并且按照优先级来淘汰键值对。这个有序集合是使用数据的优先级来排序的,也就是用优先级作为 score。
增加一个键值对就要执行一个 lua 脚本。在这个脚本里面,它会先检测有序集合里面的元素个数有没有超过允许的键值对数量上限,如果没有超过,就写入键值对,再把 key 加入有序集合。如果超过了上限,那么就从有序集合里面拿出第一个 key,删除这个 key 对应的键值对。
同时监听 Redis 上的删除事件,每次收到删除事件,就把有序集合中对应的 key 删除。
-- Lua 脚本用于自定义淘汰策略
-- KEYS[1] 是缓存中的key
-- KEYS[2] 是缓存中的有序集合的key
-- ARGV[1] 是新的值
-- ARGV[2] 优先级
--1. 先判断有序集合中的 key 数量
local nums = redis.call('ZCARD', KEYS[2])
if tonumber(nums) >= 3 then
-- 代表有序集合容量已到上限,开始删除优先级最低的那个元素
local members = redis.call('ZRANGE', KEYS[2], 0, 0, 'WITHSCORES')
-- 检查有序集合是否为空
if members and tonumber(members) > 1 then
-- 获取分数最低的成员(第一个成员的分数)
local lowest_member_score = members[2]
local lowest_member = members[1]
-- 执行ZREM命令删除分数最低的成员
redis.call('ZREM', KEYS[2], lowest_member)
redis.call('DEL', lowest_member)
else
-- 如果有序集合为空或不存在成员,则返回空
return nil
end
end
--2. 开始设置 key,和有序集合的元素
local result = redis.call('SET', KEYS[1], ARGV[1])
result = redis.call('ZADD', KEYS[2], ARGV[2], KEYS[1])
return result
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 缓存淘汰策略:Redis中的内存管理艺术

发表评论 取消回复