配置管理
一:什么是配置管理
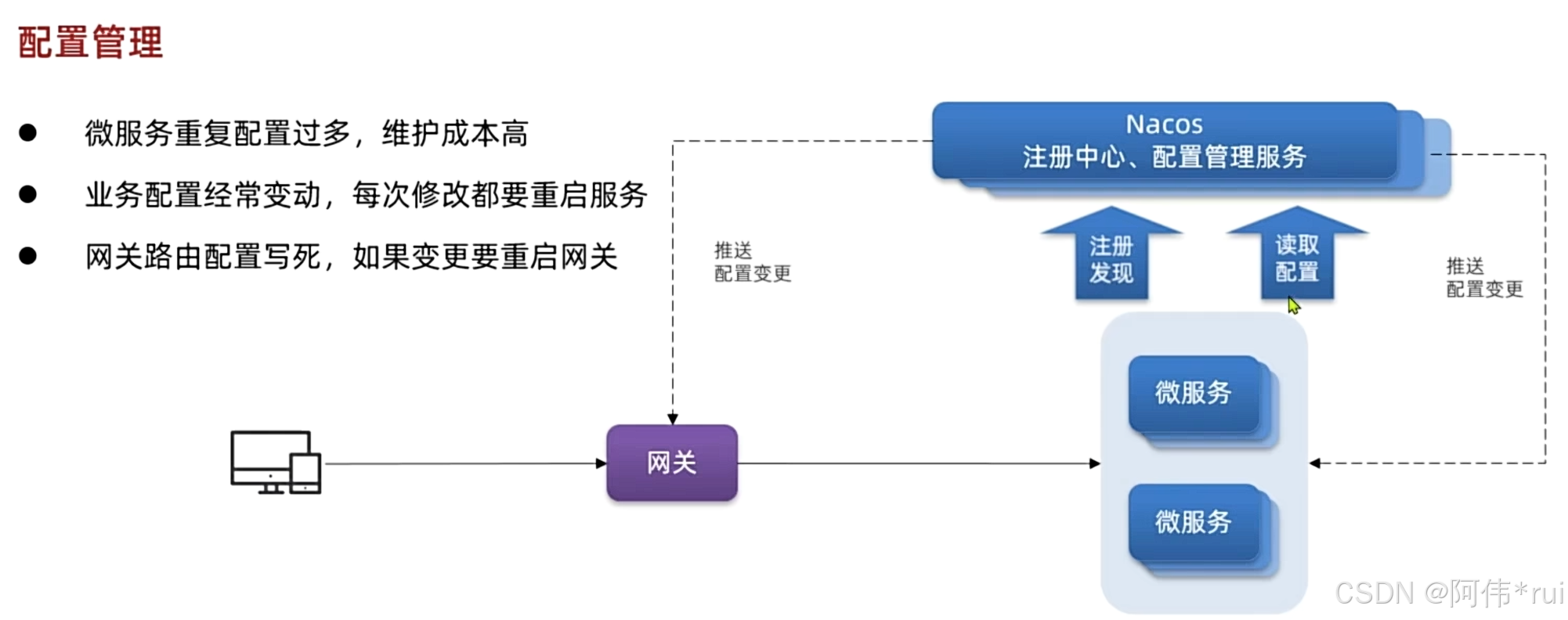
为什么需要配置管理:
1:微服务数量太多,每一个微服务都需要进行配置,而且重复的配置也有很多,万一要变动所有微服务的配置都需要变动
2:我们的业务配置变更后,必须重启服务才能生效;
3:网关配置也是需要重启,重启的这段时间所有的服务都用不了;
所以引入了配置管理服务,配置管理可以统一管理配置,配置变更也会即时的推送配置;
二:配置共享
我们之间可以使用nacos进行配置的管理:
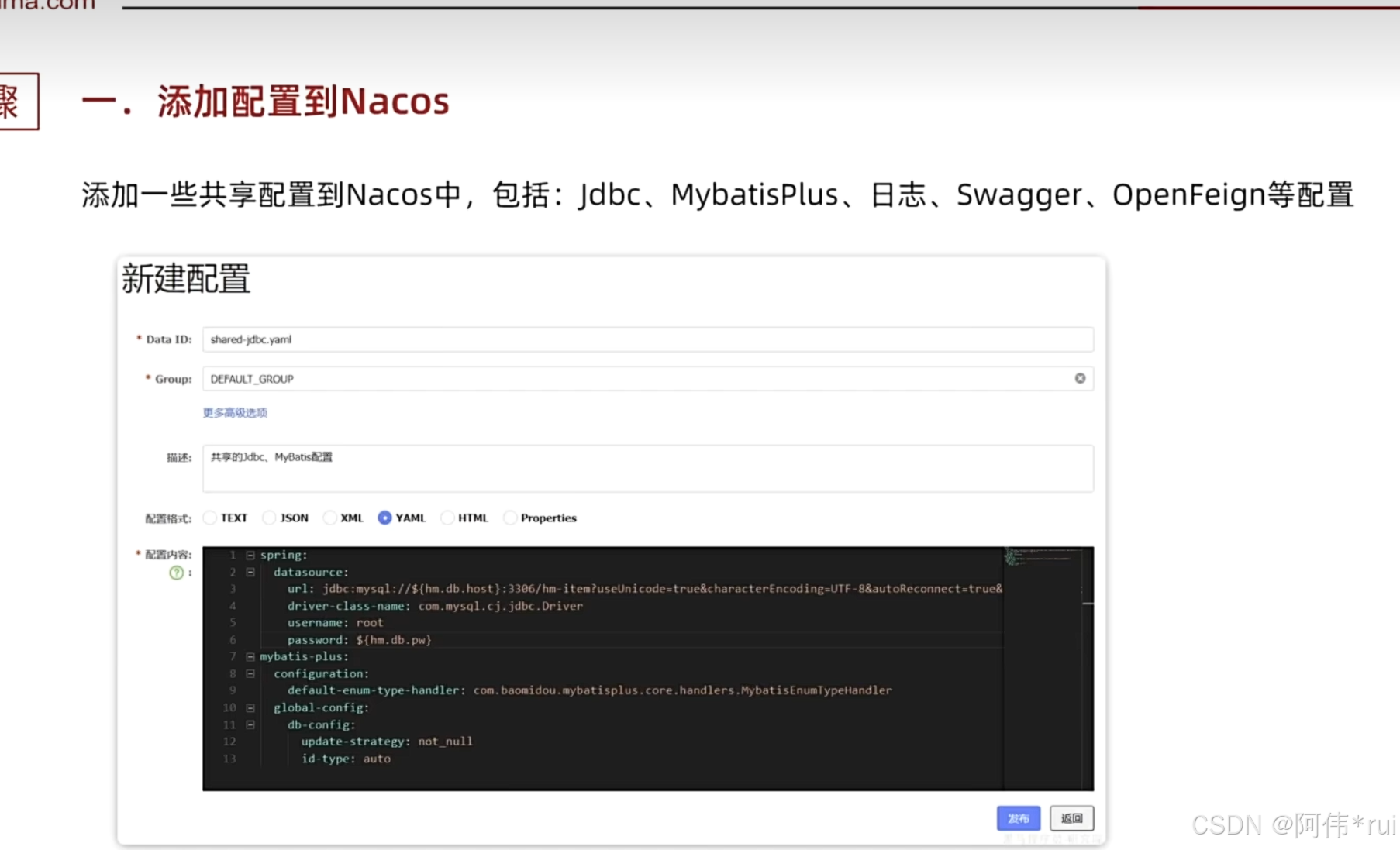
配置共享解决配置重复的问题
添加共享配置
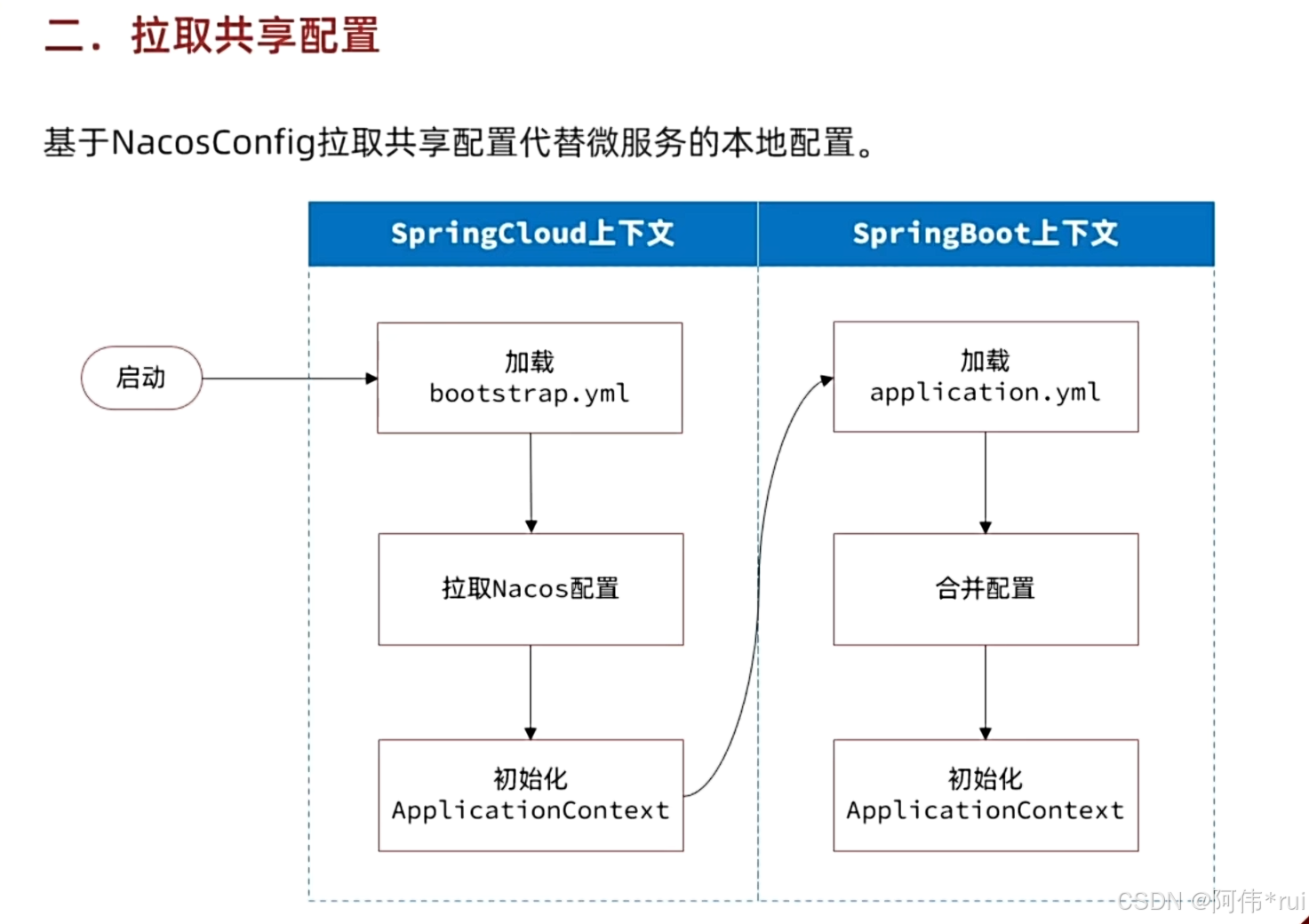
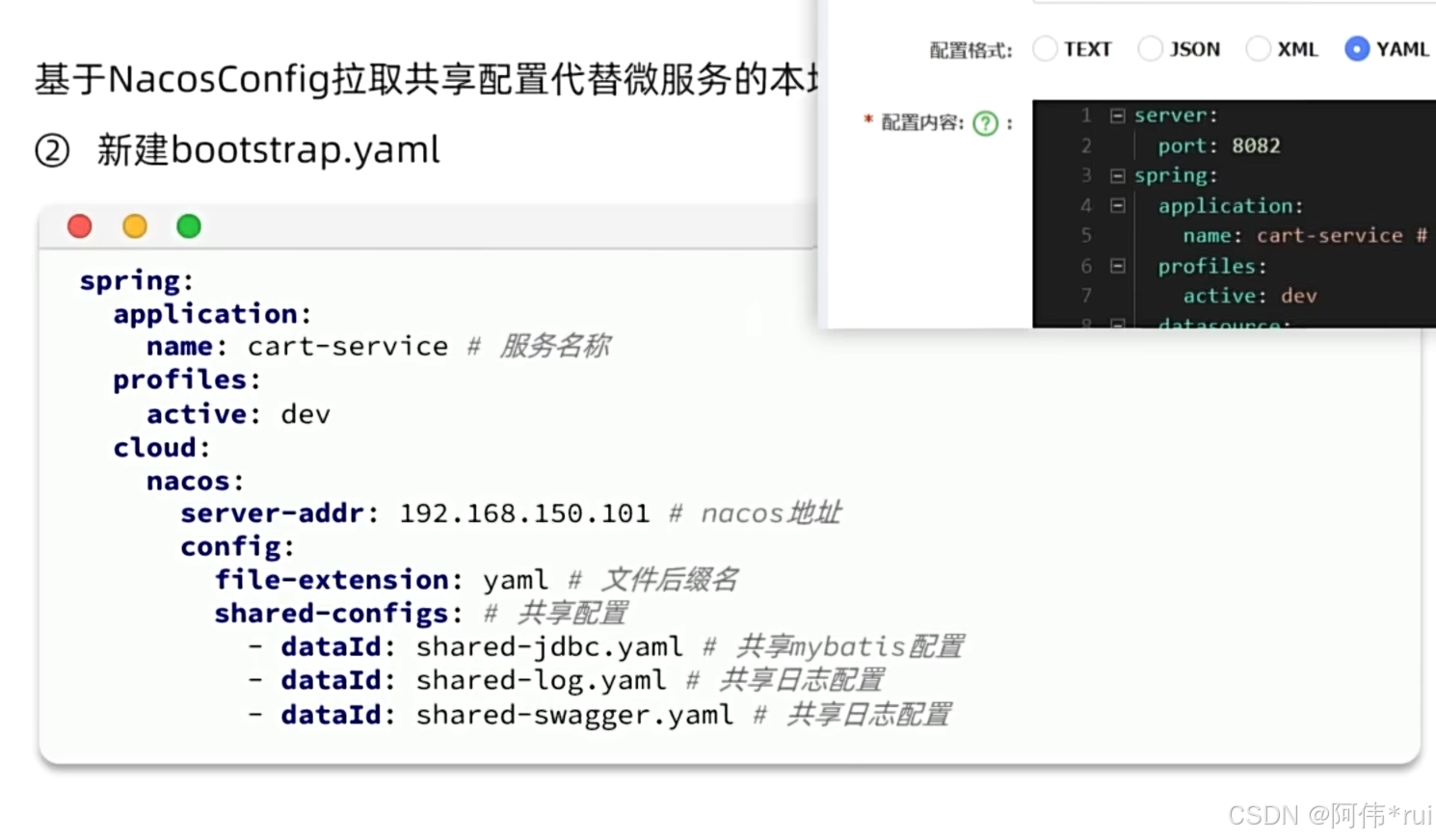
原本springboot启动会现加载yml文件然后初始化上下文,现在在springcloud中进行了配置管理我们就要从nacos中拉取共享配置,
但是我们的nacos地址是配置在springboot的yml文件中的,不知道naco是地址怎么取拉取配置文件,所以springcloud启动的时候会先加载bootstrap文件,这里面就有nacos的地址,然后根据地址再去拉取共享配置,将共享配置初始化在上下文中,然后再去加载springboot的yml文件,因为共享文件中有许多占位符,所以要先合并配置再去初始化springboot的上下文

读取bootstrap和拉取共享配置都需要引入相关依赖;
三:配置热更新

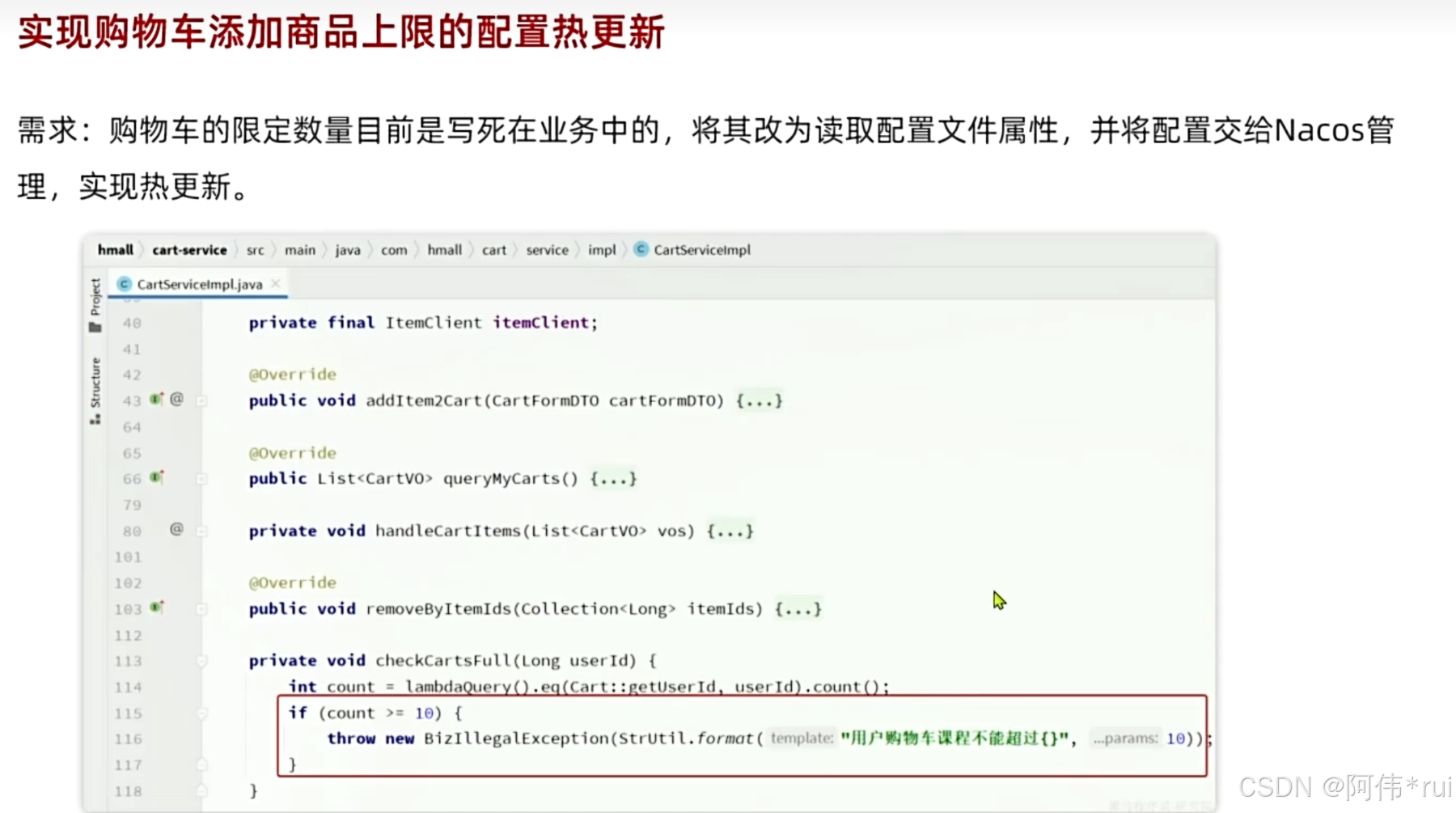
实现配置的热更新要进行两部操作,第一步,在nacos中在添加一个配置文件,用来填写需要进行热更新的配置,第二步,读取热更新的配置需要一个配置类专门来读取;
@ConfigurationProperties(prefix = "hm.cart")
@Data
@Component
public class CartProperties {
private Integer MaxItems;
}
雪崩问题
一:原因分析
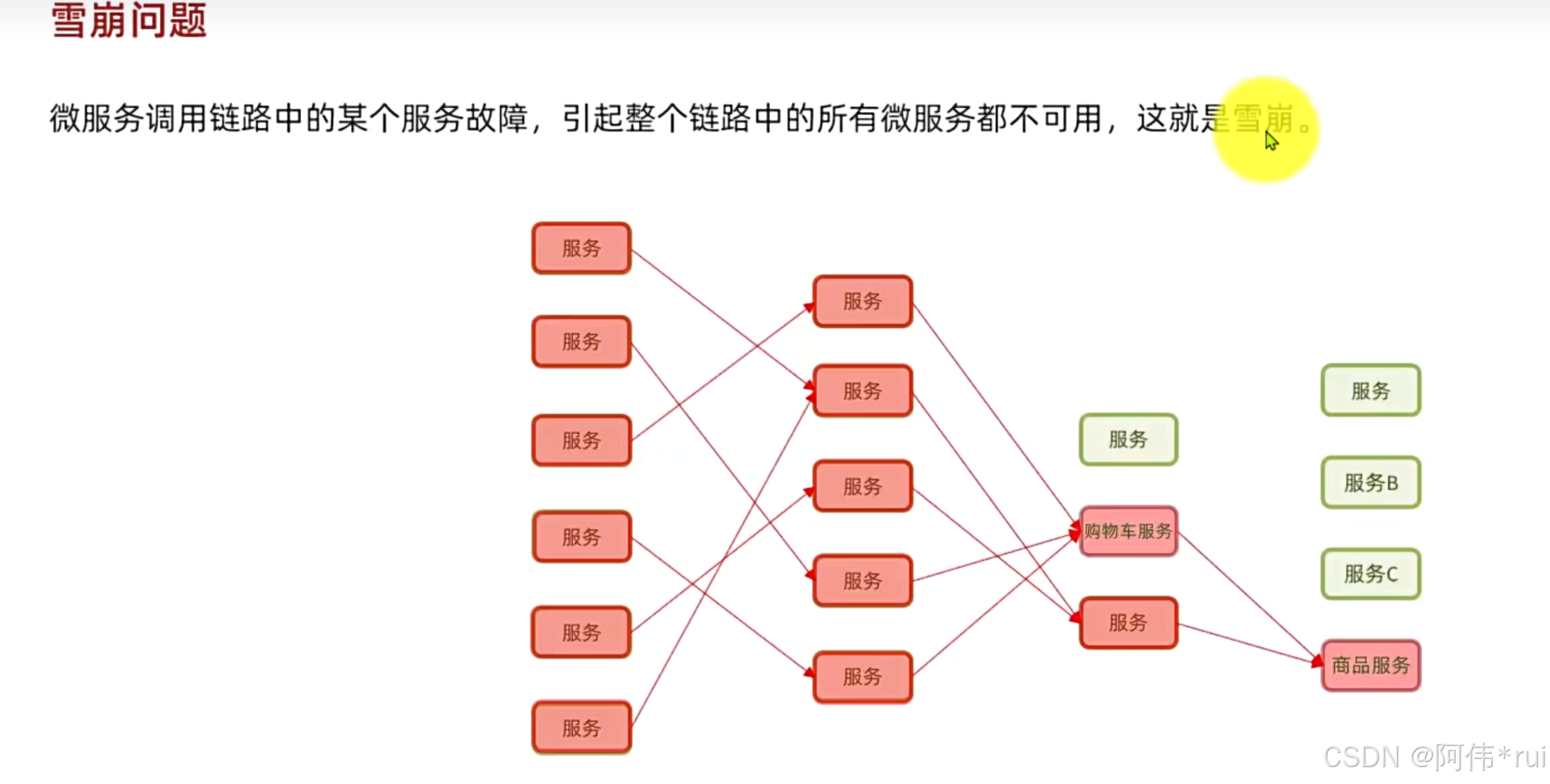
雪崩问题:微服务调用链路中一个服务出现故障导致,整个链路的所有微服务都不可用这就是雪崩;
举个例子,有一个服务出现了故障,其他服务去调用这个服务就得不到返回,如果是高并发的请求,无数的请求会将tomcat的资源耗尽,导致当前服务也处于一个不可用的状态,然后又因为这些服务的调用是错综复杂的就会发生连锁反应,多个微服务都会发生故障;

总结来说:出现雪崩问题的原因1:服务自身故障;2:服务调用者没有做好异常处理,导致自身故障;
解决思路:1避免故障,通过代码的健壮性;
2:做好调用异常的后备方案;
二:解决方案
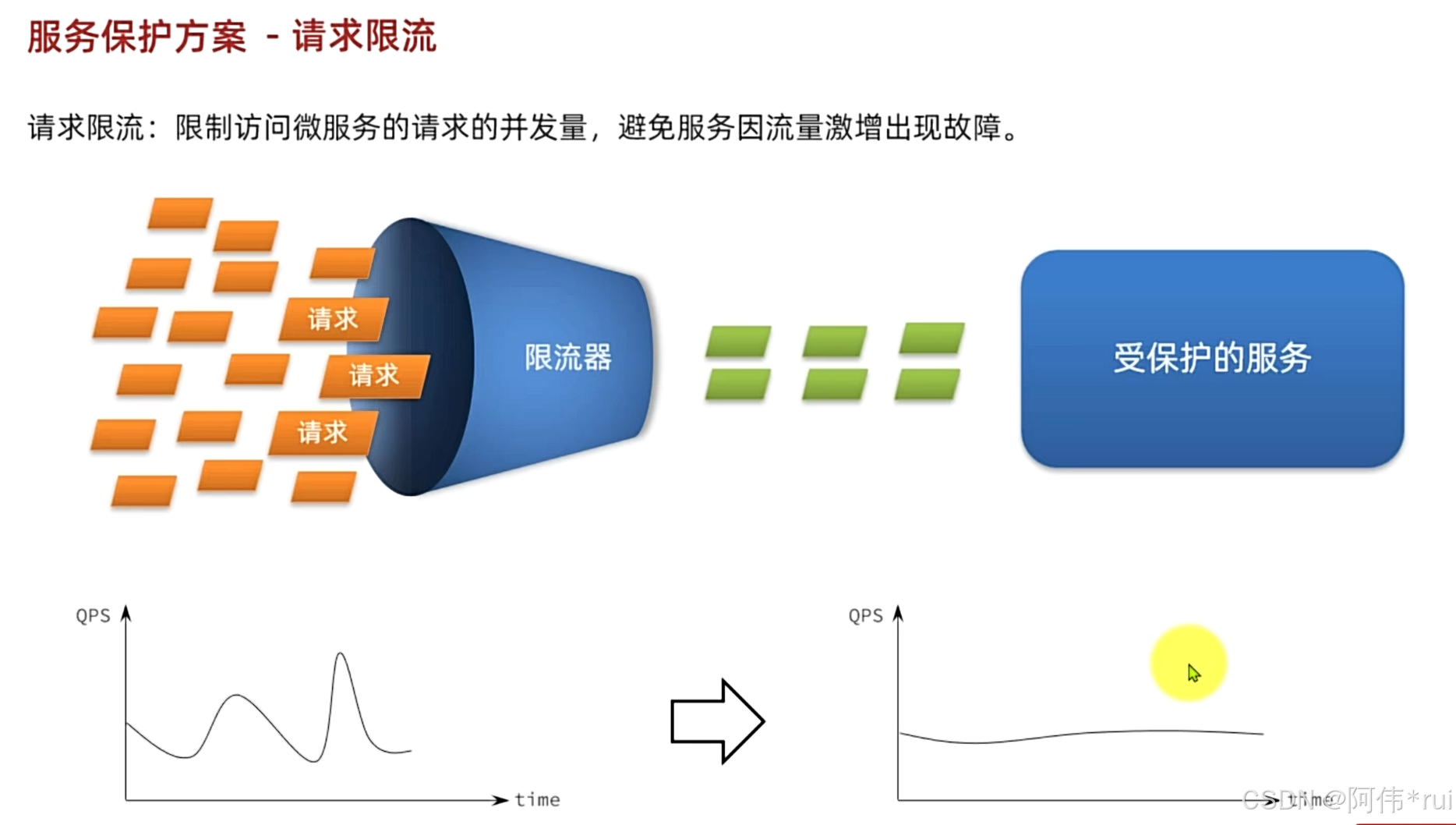
通过限流器将请求限流,避免因流量激增而出现故障
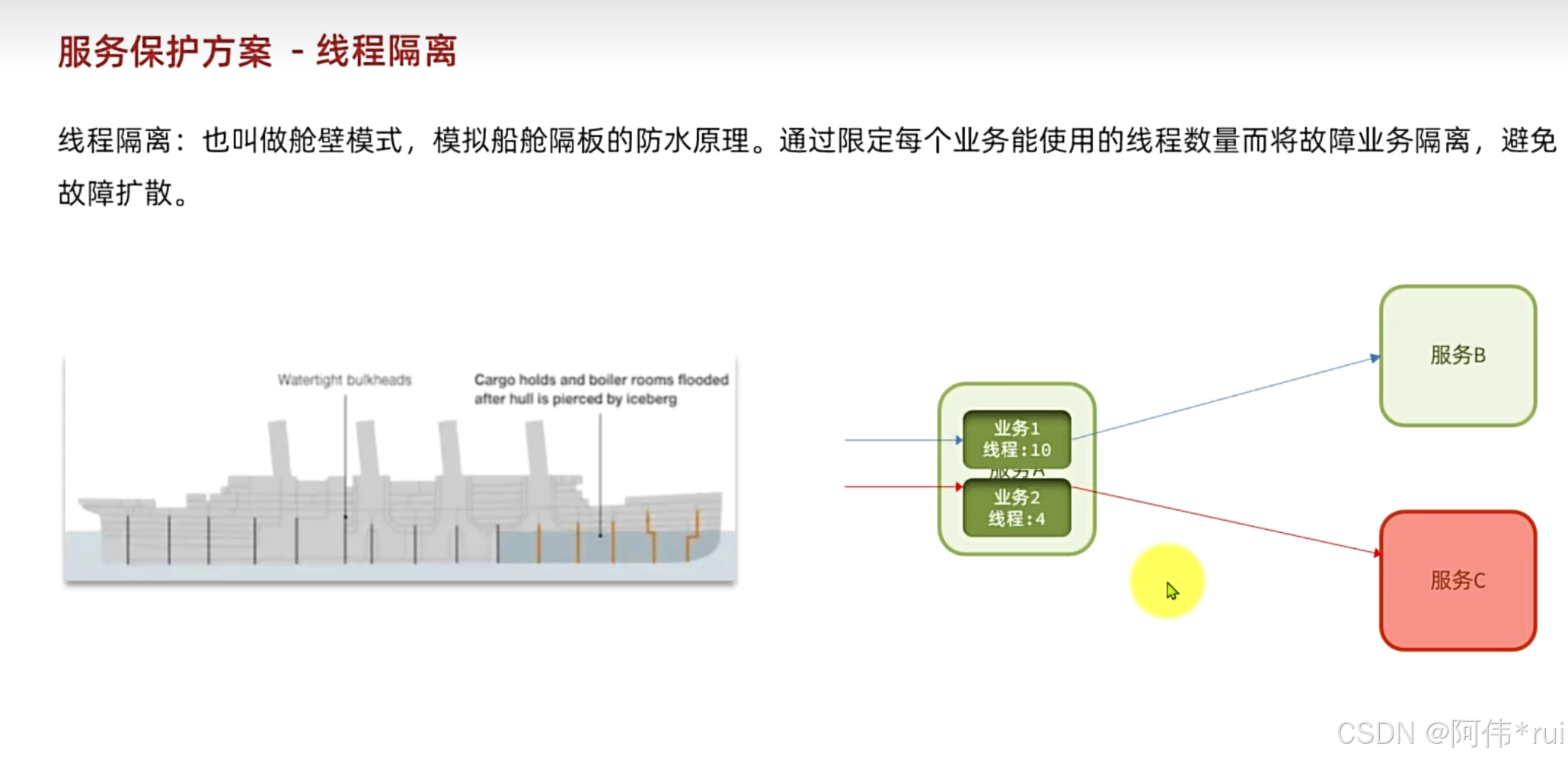
通过线程的隔离:这是解决了因为调用的服务故障导致自身的资源耗尽进而导致自身的服务也故障的问题,我们只要给调用故障的服务的资源又一定的限制,达到限制就不能在访问了,从而避免了将整个服务的资源全部占用的情况;
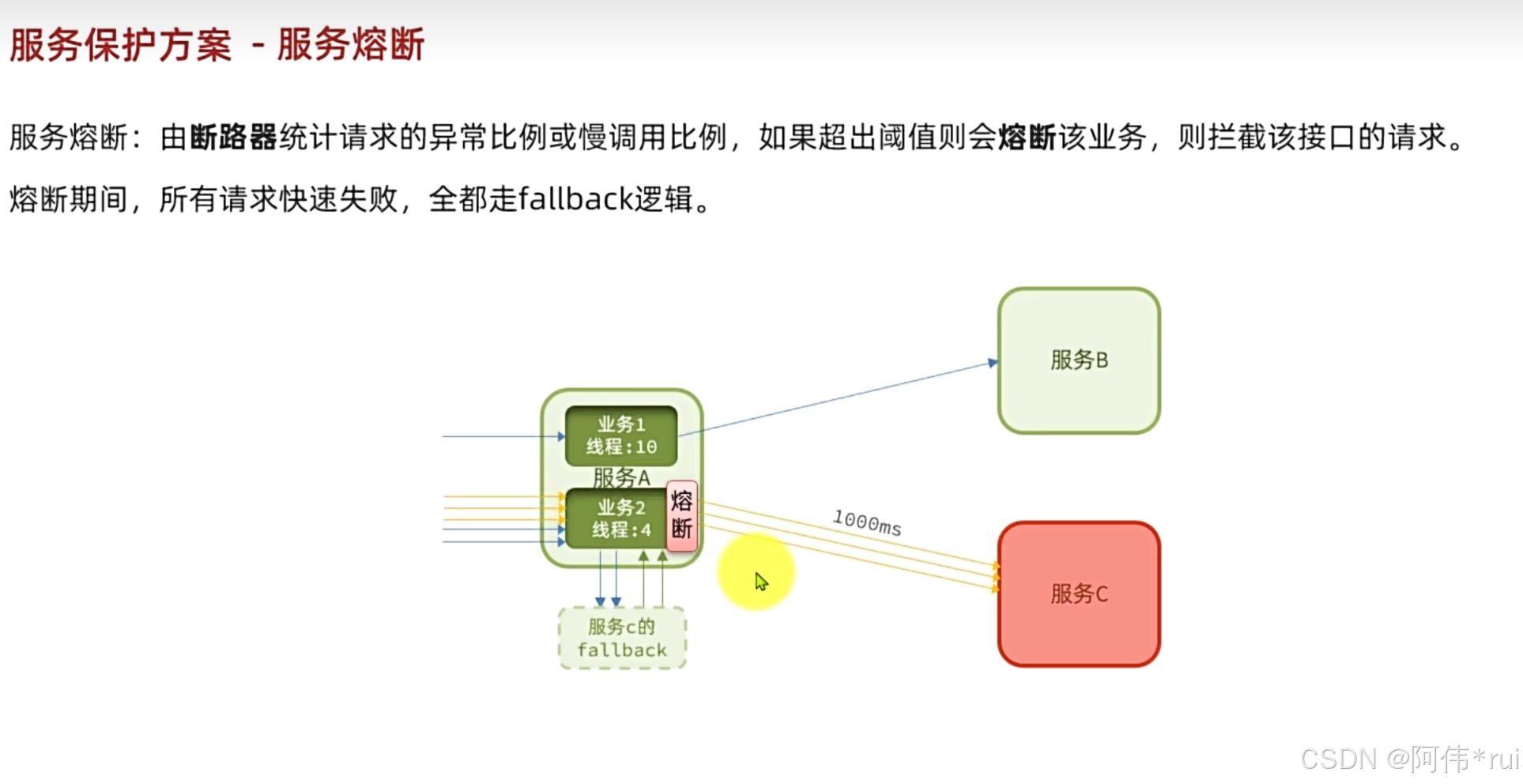
在线程隔离的基础上,我们耗尽了限制的资源就不会再请求了,但是我们还是发送很多无用的请求,知道服务异常还是会访问直到资源占用完;我们就可以使用服务熔断:
服务熔断:由断路器统计请求的异常比例或慢调用比例。一旦超出阈值就会熔断业务,拦截请求;然后还要走fallback逻辑
总结一下雪崩的解决方案:1:限流器;2:线程隔离;3:服务熔断;
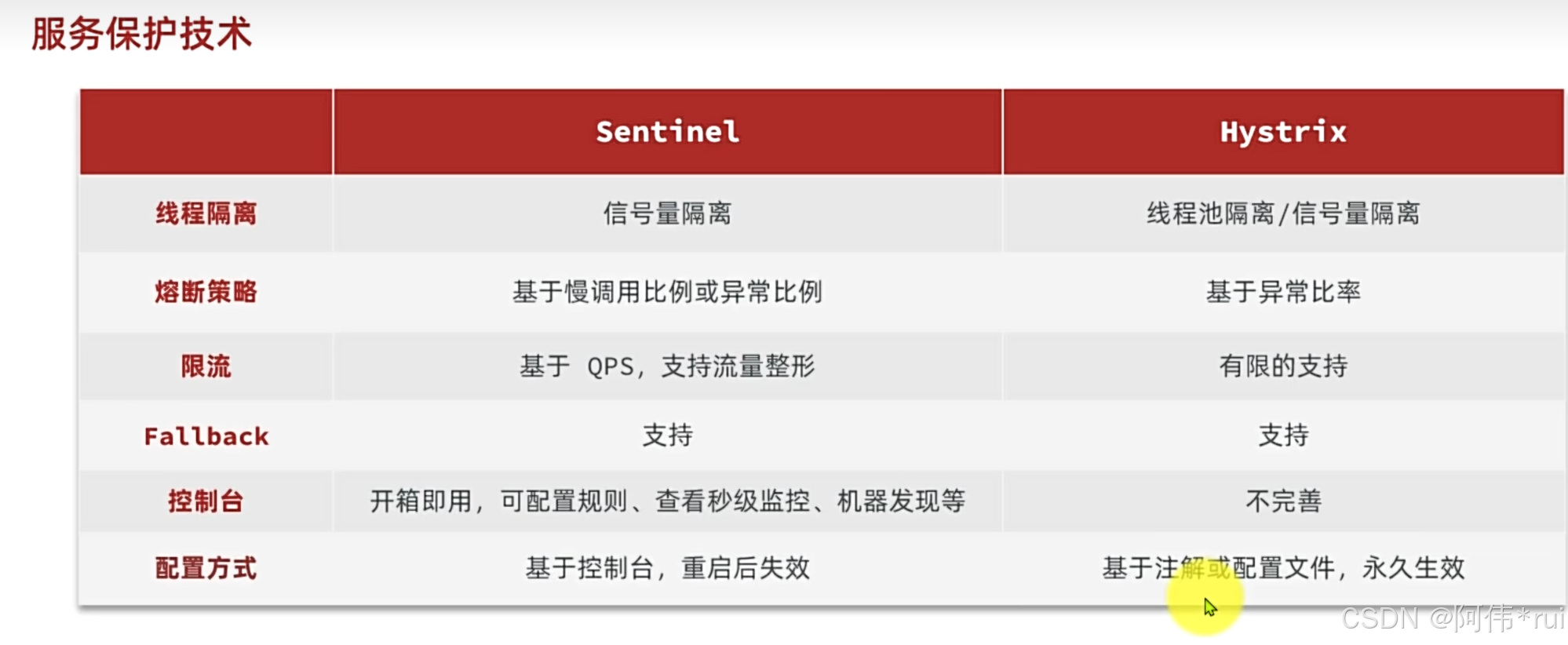
实现服务保护我们可以借助这些组件:比如springcloud alibaba的sentinel;
Sentinel
一:快速入门
1:首先去下载sentinel控制台的jar包:

2:然后在cmd中输入命令:(运行jar包)
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
3:然后就能访问8090:
4:在项目中引入依赖:
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
5:在yaml文件中配置sentinel地址,与sentinel建立连接
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
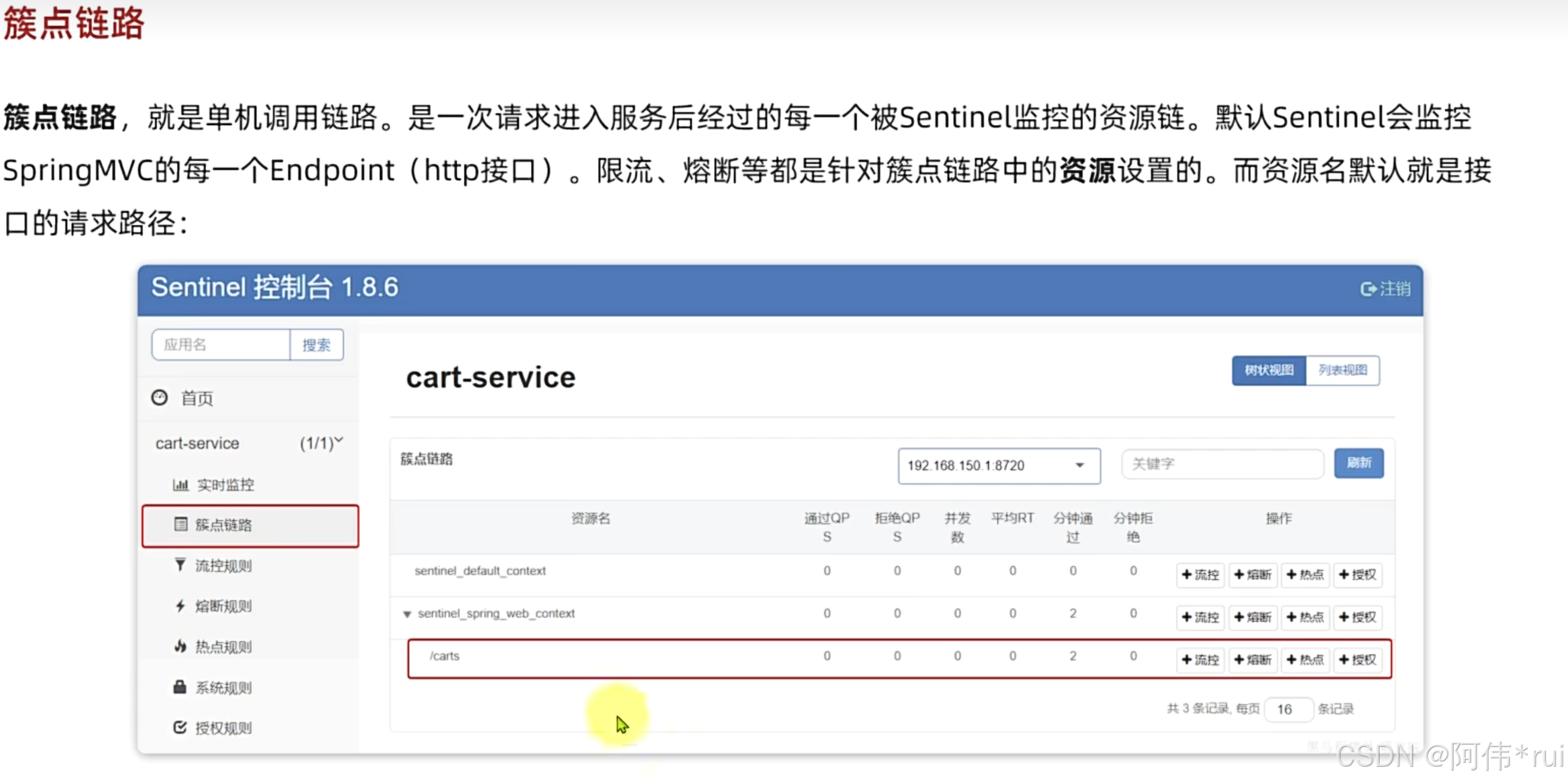
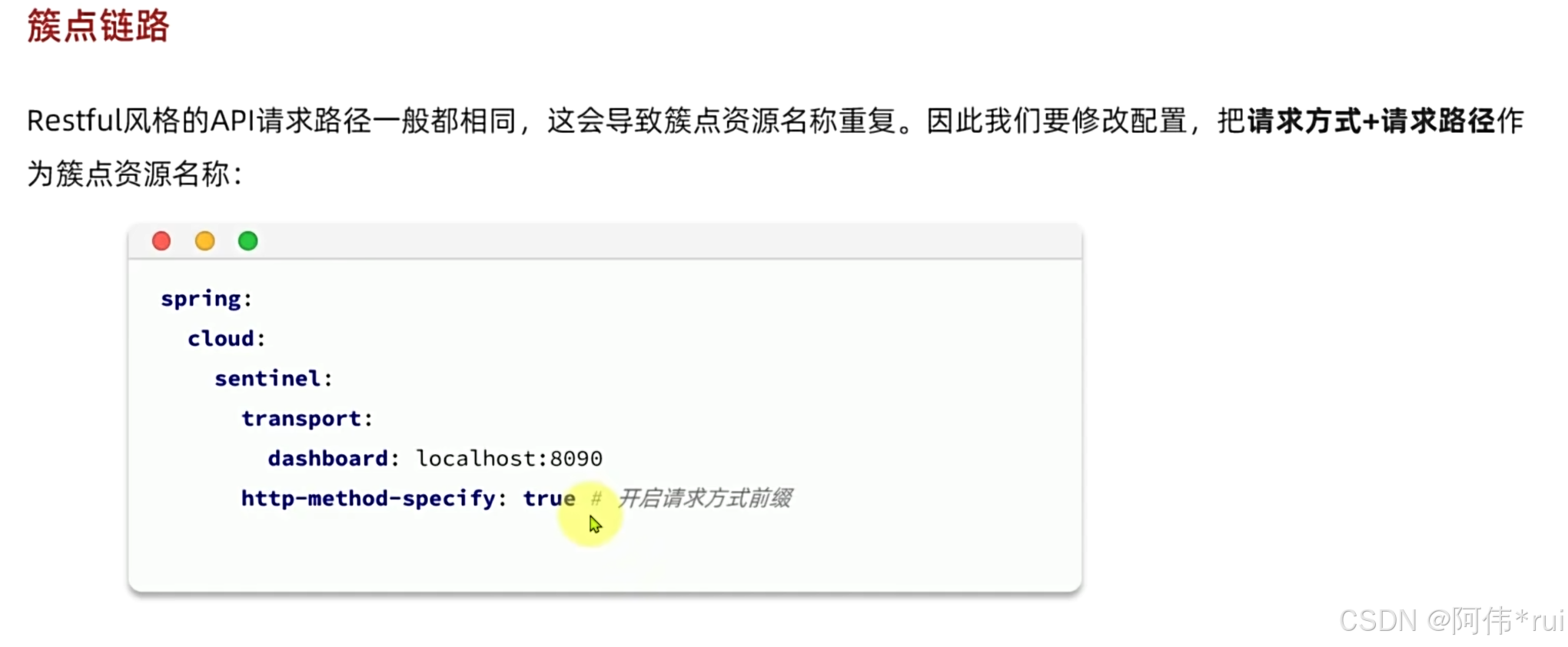
防止簇点的资源名称重复我们要加上配置项http-method-specify
二:请求限流
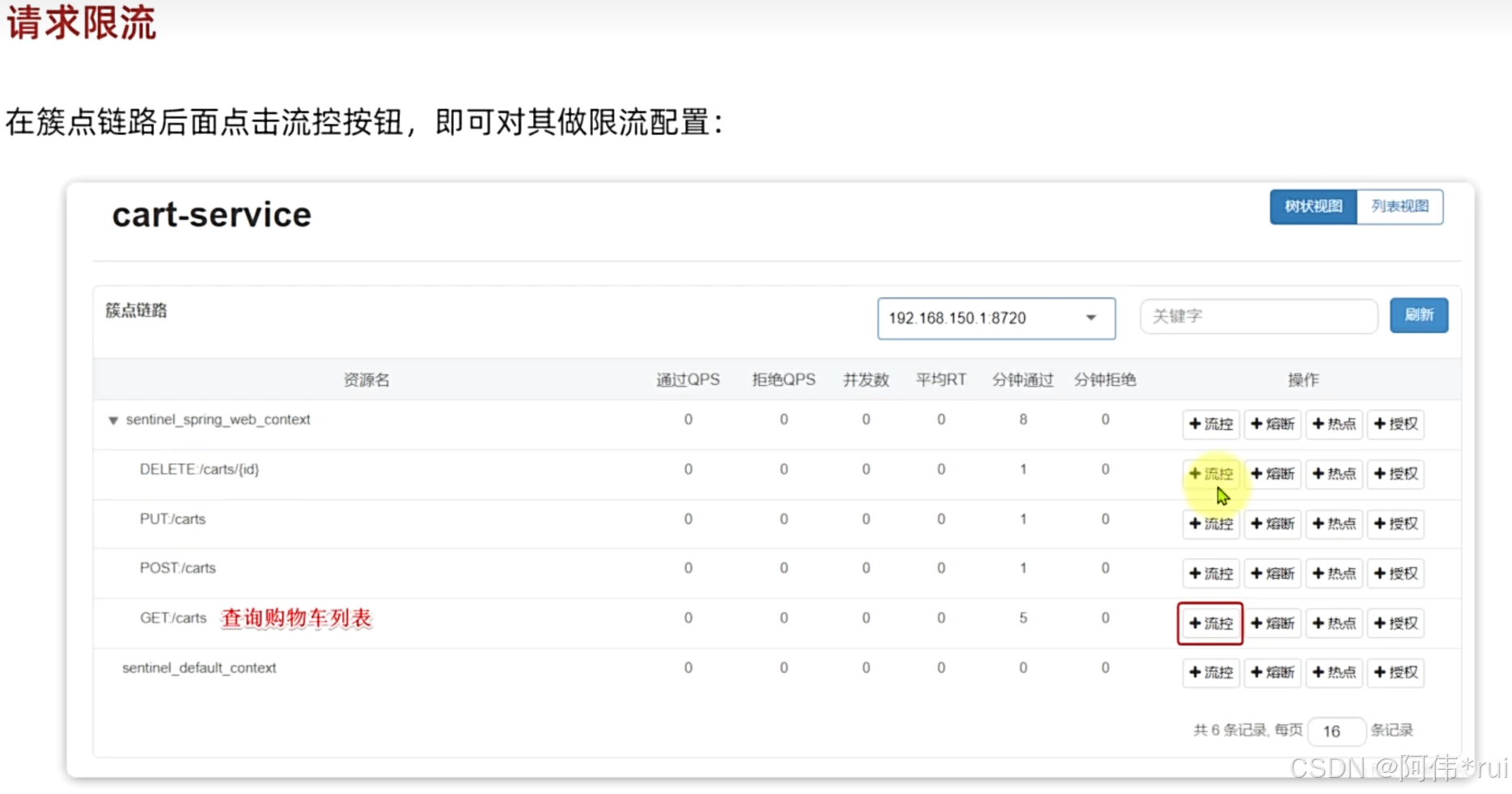
直接在控制台中设置就行了
三:线程隔离
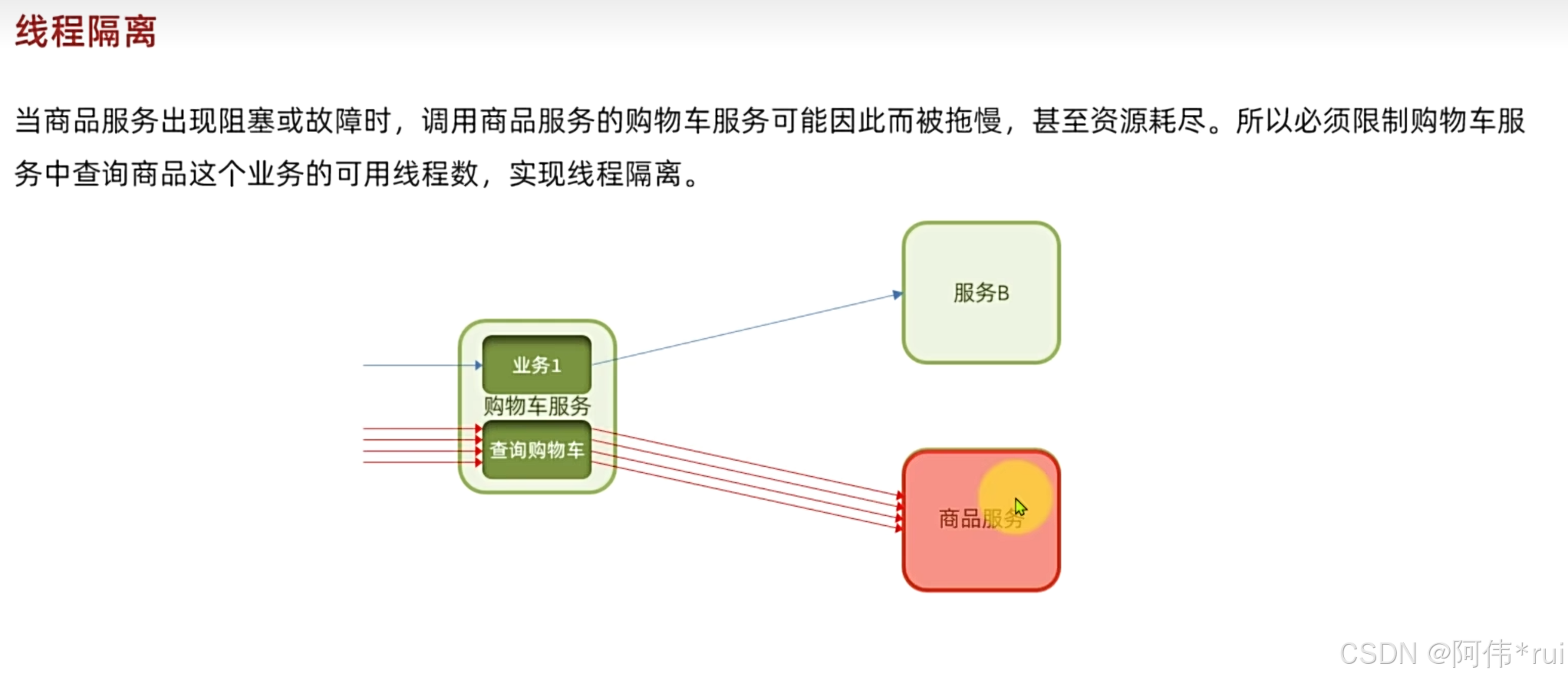
为了防止远程调用的服务挂了导致请求堵塞,以至于用完所有的资源造成自身的服务瘫痪
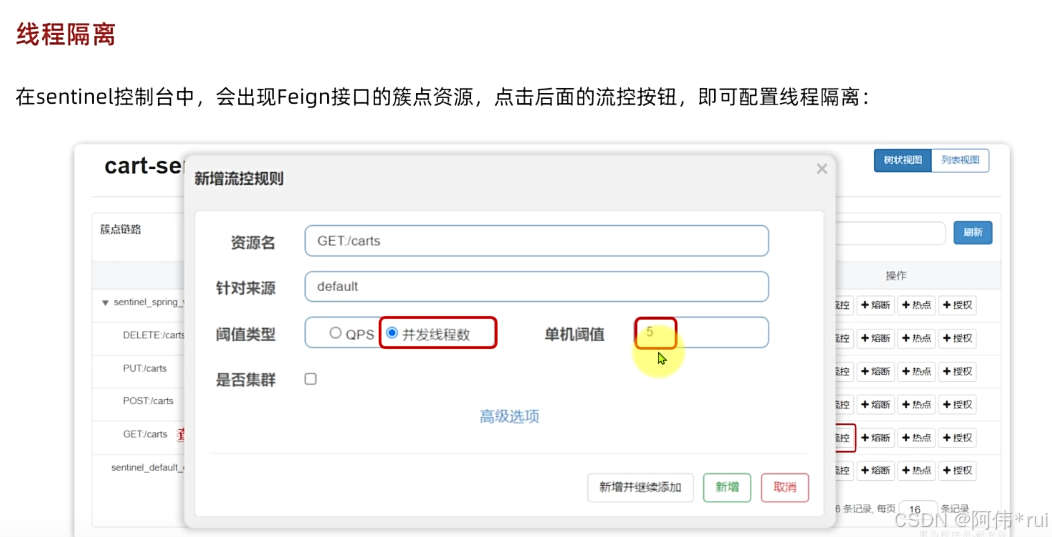
配置方法:流控规则中的并发线程数就是线程隔离,表示当前服务一共拥有这么多线程;
这样即使一个服务中的一个接口堵塞,其他接口的访问也不会受影响;
四:fallback
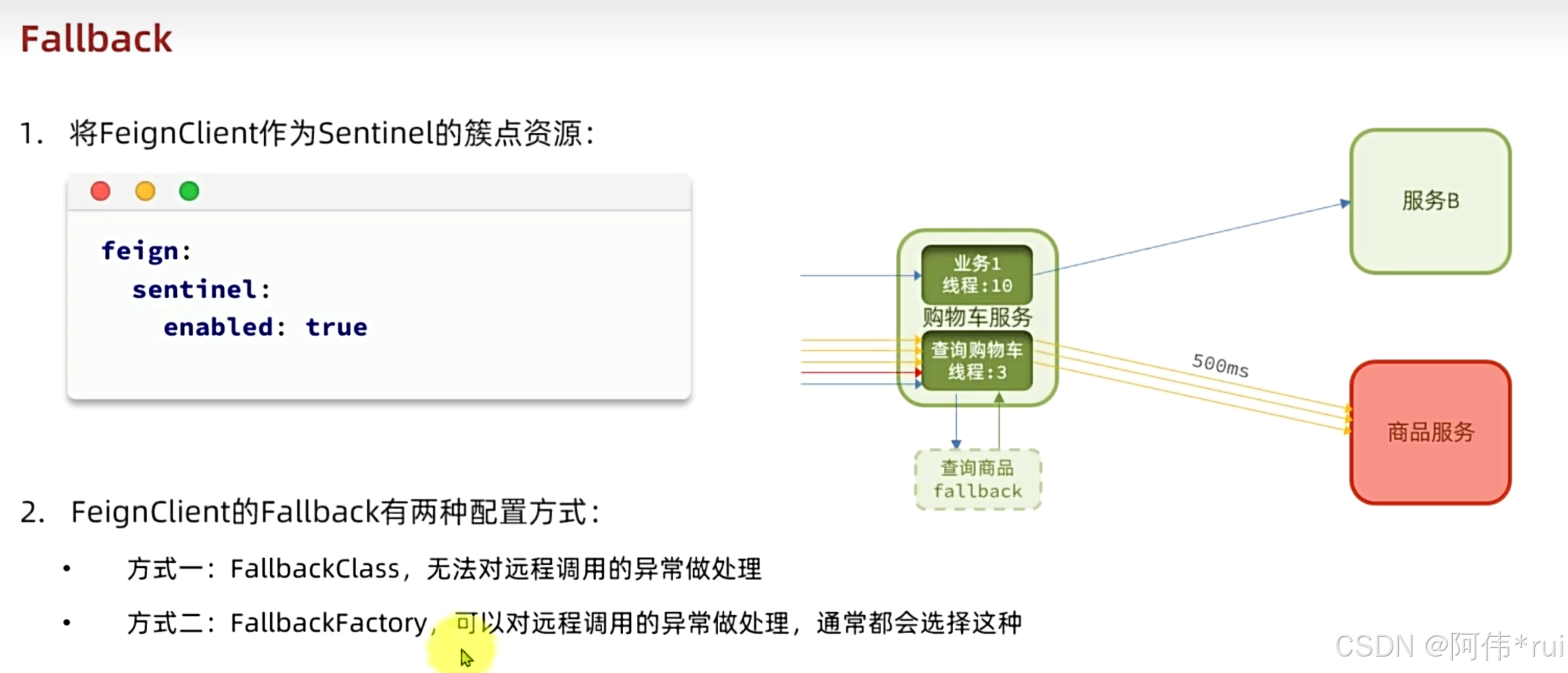
将远程调用也作为一个簇点,对远程调用进行fallback处理
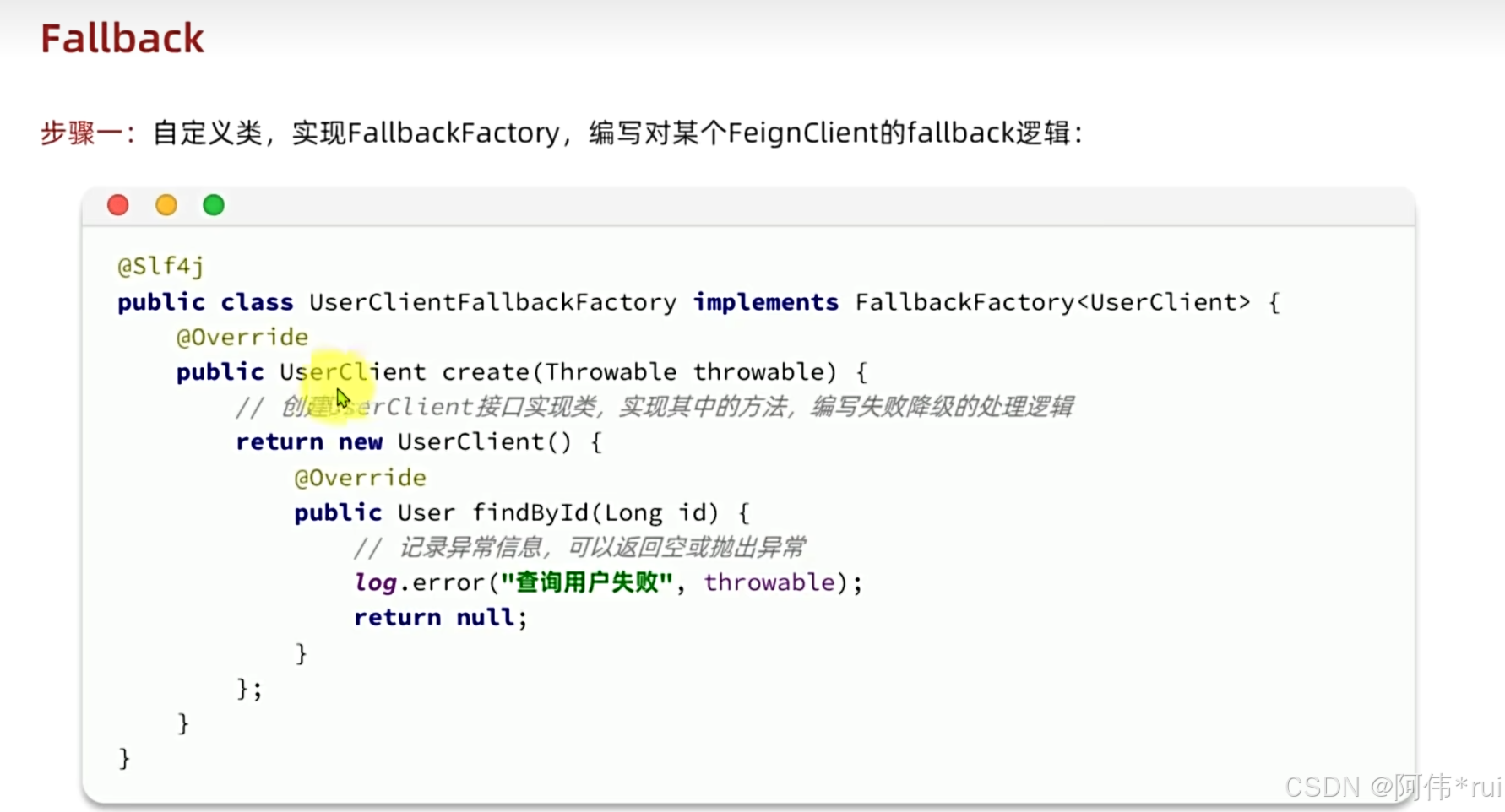
第一步:定义一个fallback工厂类,工厂类里返回一个client对象,里面实现cilent的方法,是在远程调用异常的时候才会去调用这个方法;
第二步:将fallback注册成一个bean
第三步:在client的feignclient注解中添加属性:
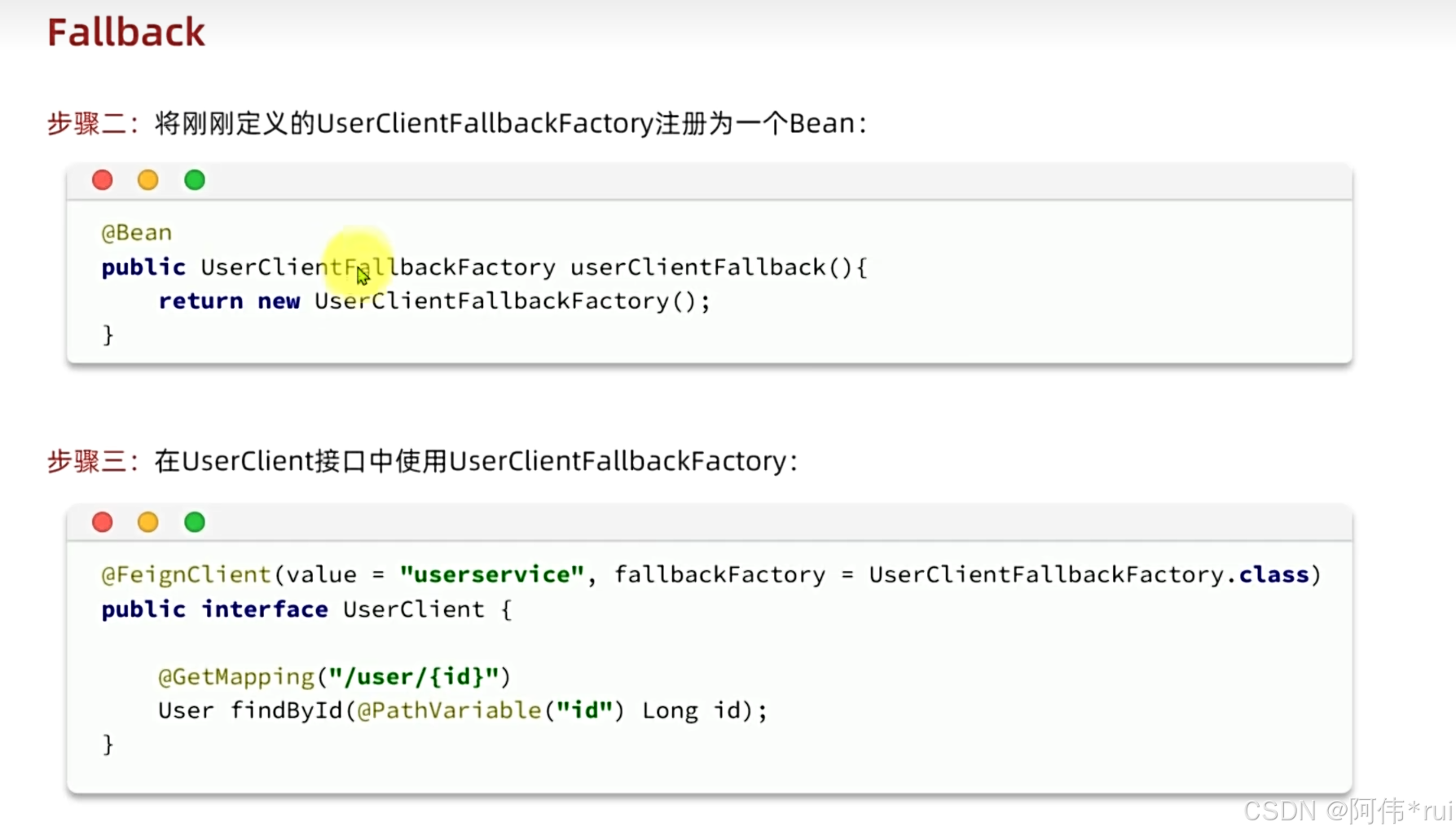
@Slf4j
public class ItemClientFallbackFactory implements FallbackFactory<ItemClient> {
@Override
public ItemClient create(Throwable cause) {
return new ItemClient() {
@Override
public List<ItemDTO> queryItemByIds(Collection<Long> ids) {
log.error("查询商品失败",cause);
return null;
}
@Override
public void deductStock(Collection<OrderDetailDTO> items) {
log.error("扣减库存失败",cause);
throw new RuntimeException(cause);
}
};
}
}
自定义工厂类,实现抛出异常之后的逻辑
@Bean
public ItemClientFallbackFactory itemClientFallbackFactory(){
return new ItemClientFallbackFactory();
}
在配置类中将其注册为一个bean
@FeignClient(value = "item-service",fallbackFactory = ItemClientFallbackFactory.class)
在FeignClient注解上添加注解声明这个工厂类
这样在远程调用失败的时候就不会返回异常了
总结下fallback的使用方法:自定义工厂类,工厂类中返回client对象,client对象中重写自身的方法,是异常之后执行的逻辑,然后在配置类中将fallback工厂类注册成一个bean,然后在client类的注解上加上属性;
五:服务熔断
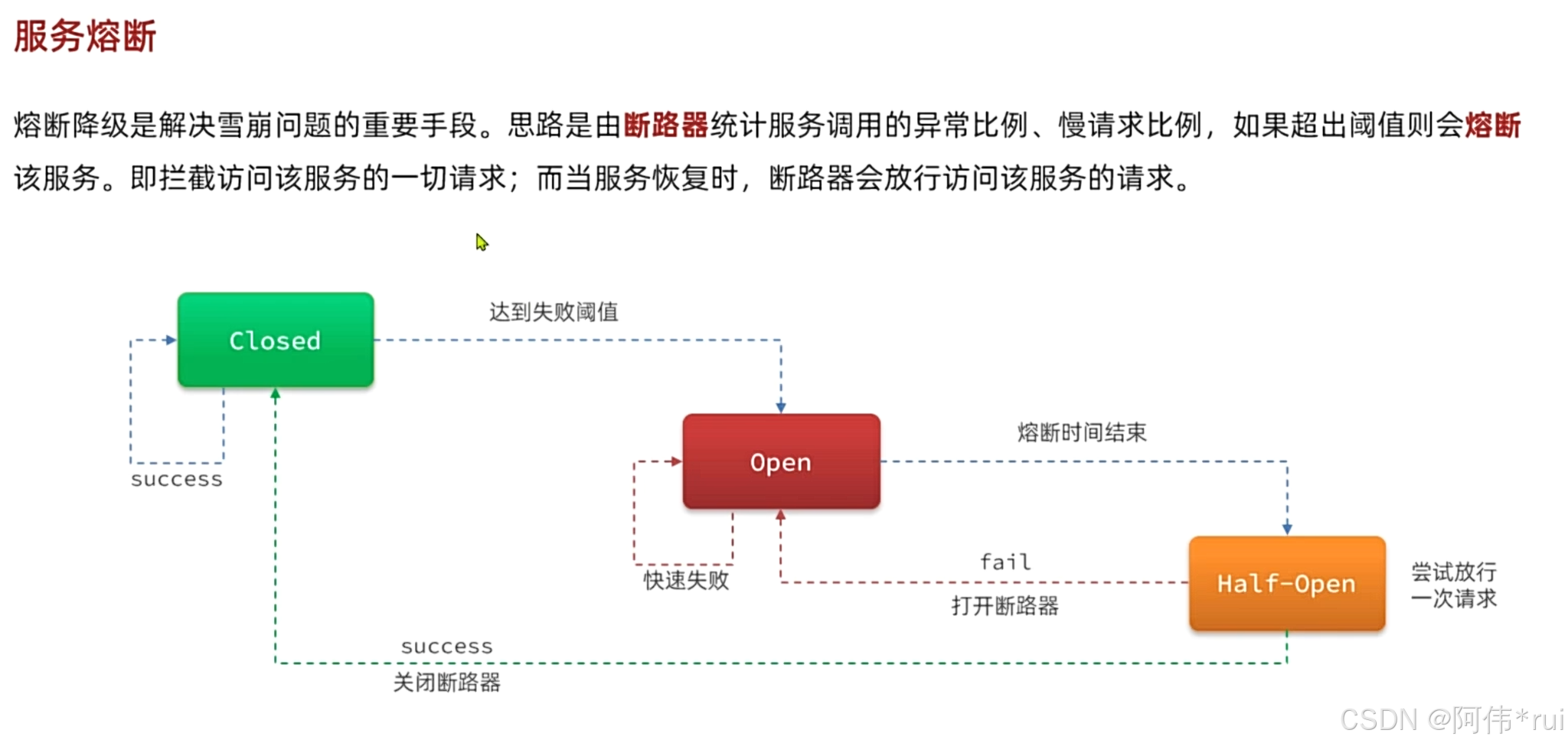
服务熔断:断路器统计服务调用的异常比例和慢调用比例,达到阈值就会熔断该服务拦截一切请求,当服务恢复时会放行请求;
断路器的逻辑:断路器中有三个状态,closed,open,half-open;一般情况下断路器处于closed状态,断路器放行请求,并且统计异常的比例和满请求的比例,当到达一定阈值后会进入open阶段,这个阶段断路器会拦截请求,请求会快速失败,open是临时状态,每隔一段时间都会转入到half-open状态,尝试放行请求,如果还是异常就再次回到open,如果成功就closed;
就会熔断该服务拦截一切请求,当服务恢复时会放行请求;
断路器的逻辑:断路器中有三个状态,closed,open,half-open;一般情况下断路器处于closed状态,断路器放行请求,并且统计异常的比例和满请求的比例,当到达一定阈值后会进入open阶段,这个阶段断路器会拦截请求,请求会快速失败,open是临时状态,每隔一段时间都会转入到half-open状态,尝试放行请求,如果还是异常就再次回到open,如果成功就closed;
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 配置管理,雪崩问题分析,sentinel的使用

发表评论 取消回复