嗨,大家好,我是小华同学,关注我们获得“最新、最全、最优质”开源项目和高效工作学习方法

GOT-OCR2.0是开源端到端模型,实现OCR技术的重大突破。它不仅能够识别标准字体,还能应对各种复杂场景下的文本识别任务,包括但不限于手写体、艺术字体和模糊文本。项目的核心是一个深度学习模型,能够自动学习并适应不同的文本特征。
核心功能
GOT-OCR2.0项目的核心在于其提出的OCR 2.0理论,该理论通过以下特点,实现了OCR技术的提升:
-
统一端到端模型:与传统的OCR系统不同,GOT-OCR2.0采用了一个统一的模型来处理各种OCR任务,包括文本检测、文本识别等。
-
自底向上的设计:该模型从像素到字符的识别过程中,无需依赖人工设计的特征,大大减少了人工干预。
-
多任务学习:模型能够同时学习多个相关任务,提高了识别的准确率和鲁棒性。
应用场景
GOT-OCR2.0的应用场景非常广泛,以下是一些典型的使用案例:
-
文档数字化:将大量的纸质文档快速转换为电子文档,便于存储和检索。
-
车牌识别:在智能交通系统中,用于自动识别车牌号码。
-
信息提取:从图片中提取文本信息,用于数据分析或自然语言处理。
使用方法
要使用GOT-OCR2.0,首先需要从GitHub上克隆项目到本地环境。以下是一些基本步骤:
-
环境准备:确保Python环境以及必要的依赖库已安装。
-
模型训练:使用提供的训练脚本来训练模型,可以使用自己的数据集或者项目提供的预训练数据。
-
模型测试:通过测试脚本来评估模型的性能。
-
模型部署:将训练好的模型部署到实际应用中。
以下是项目的部分代码示例,展示了模型训练的基本流程:
# 示例代码
from got_ocr import GOTOCR
# 初始化模型
model = GOTOCR()
# 训练模型
model.train(dataset='your_dataset_path')
# 测试模型
model.test(dataset='your_test_dataset_path')
项目展示
以下是GOT-OCR2.0项目的一些成果展示,可以看到模型在多种场景下都有很好的表现。

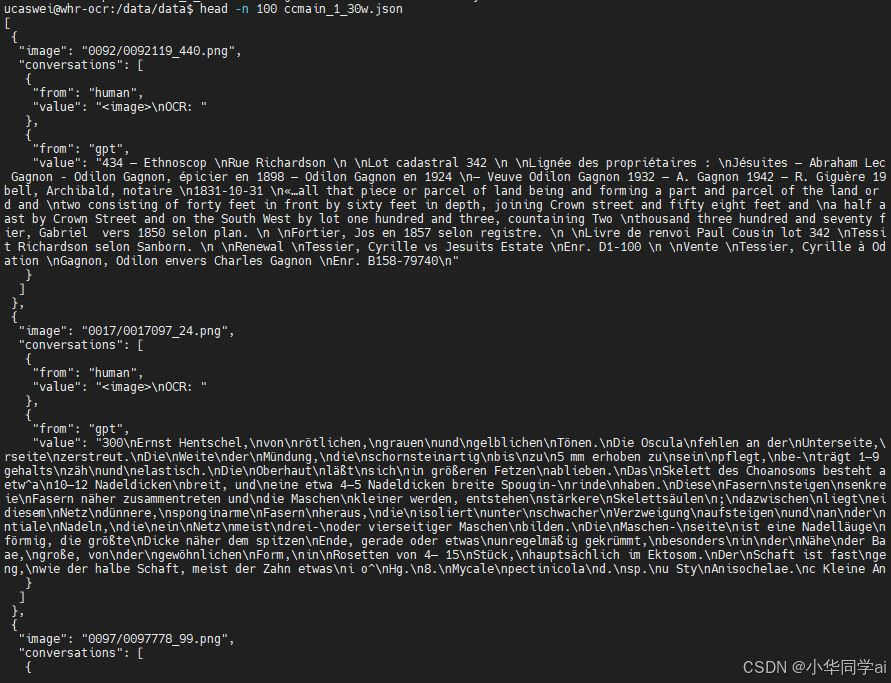
同类项目比较
在OCR领域,还有其他一些知名的项目,以下是GOT-OCR2.0与它们的比较:
-
Tesseract:一个开源的OCR引擎,支持多种语言,但需要更多的手动调优和特征工程。
-
OCRopus:一个开源的OCR系统,提供了多种算法和工具,但不是一个统一的端到端模型。
-
MMOCR:基于PyTorch的开源OCR工具箱,提供了丰富的模型和工具,但与GOT-OCR2.0相比,可能需要更多的配置和优化。
结语
GOT-OCR2.0项目通过其创新的统一端到端模型,为OCR技术的发展提供了新的方向。它的易用性、高准确率和广泛的应用场景,使其成为OCR领域的一个值得关注的项目。随着技术的不断进步,我们期待看到更多像GOT-OCR2.0这样的项目,为我们的日常生活带来更多便利。
项目地址
https://github.com/Ucas-HaoranWei/GOT-OCR2.0
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » GOT-OCR:开源免费的OCR项目,多语言多模态识别,端到端识别新体验!不仅能识别文字,连数学公式、图表都不在话下!

发表评论 取消回复