个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
️热门专栏:
Java基本语法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12615970.html?spm=1001.2014.3001.5482
Collection与数据结构 (92平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
线程与网络(96平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
MySql数据库(93平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
Spring(97平均质量分)https://blog.csdn.net/2301_80050796/category_12724152.html?spm=1001.2014.3001.5482
Redis(97平均质量分)https://blog.csdn.net/2301_80050796/category_12777129.html?spm=1001.2014.3001.5482
RabbitMQ(97平均质量分) https://blog.csdn.net/2301_80050796/category_12792900.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

目录
1. 主从复制模式中存在的问题
我们前面提到的主从复制模式有一个致命的问题,如果主节点挂了的话,就没有办法进行写操作.这就需要程序员人工干预,重新配置启动主节点.大致过程如下:
1)运维人员通过监控系统,发现Redis主节点故障宕机。
2)运维人员从所有节点中,选择⼀个(此处选择了slave1)执行slaveof no one,使其作为新的主节点。
3)运维人员让剩余从节点(此处为slave2)执行slaveof {newMasterIp} {newMasterPort}从新主节点开始数据同步。
4)更新应用方连接的主节点信息到 {newMasterIp}{newMasterPort}。
5)如果原来的主节点恢复,执行slaveof{newMasterIp}{newMasterPort}让其成为一个从节点。
为了保证服务器的高可用,我们就希望系统可以自动完成修复与配置,于是我们就引入了哨兵.
2. 哨兵(sentinel)
当主节点出现故障时,哨兵能够自动完成故障的发现和故障的转移,并通知应用方,从而实现真正的高可用.
哨兵最主要的核心功能就是监控,自动故障转移,通知新的主节点到客户端.
2.1 哨兵是如何工作的
哨兵是单独的redis sentinel进程,这样的哨兵在系统中提供了多个,他们共同监控数据存储节点(主节点+从结点).这里之所以要搞多个哨兵节点,主要是用来防止哨兵节点自身也出现问题.
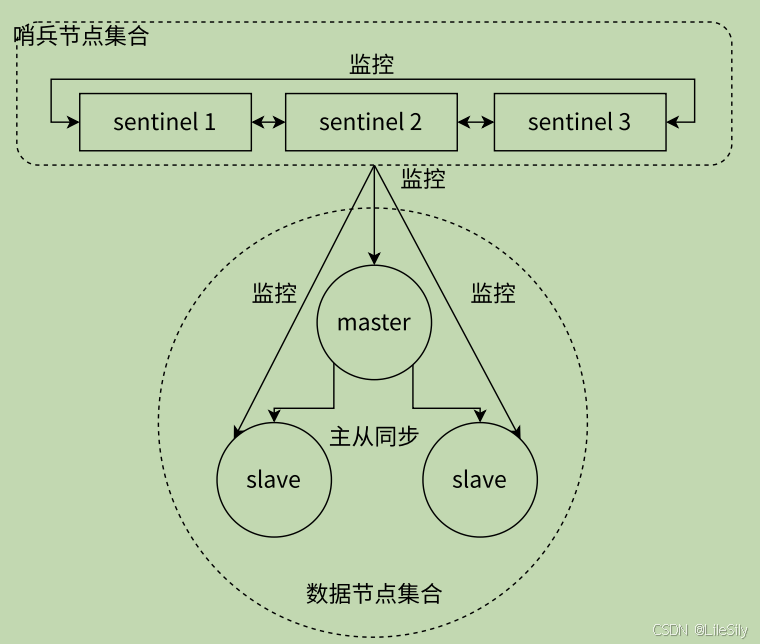
- 首先是防止哨兵节点自身宕机.如果说哨兵节点只有一个,如果这个哨兵节点挂掉了,就无法监控数据节点的运行状态了,无法监控就以为着如果数据节点挂了之后,就无法再自动进行恢复了.
- 其次是防止哨兵出现误判.如果只有一个哨兵,但是哨兵和数据节点之间的网络连接出现了抖动,延迟,或者是丢包,哨兵可能会误判这个数据节点出现故障.
哨兵通过与数据存储结点建立tcp长连接,并定期向数据节点发送心跳包,来保证数据节点还在运行状态.如果从结点挂掉了,其实没有关系,让主节点在进行一下同步就好了.如果是主节点挂了,这时候哨兵就要发挥作用了.大体的恢复流程如下.- 多个哨兵节点发送心跳包,主节点无响应,达成主节点挂掉的共识.
- 在这些哨兵中,会选举出一个Leader,这个Leader负责从现有的从结点中,挑选一个结点作为新的主节点.
- 挑选出新的主节点之后,哨兵节点就会自动控制被选中的这个节点,执行
slaveof no one,并控制其他从节点,修改slaveof到这个新的主节点上. - 哨兵节点会自动的通知客户端程序,告知新的主节点是谁,而且后续客户端在进行写操作的时候,就会针对新的主节点进行操作了.
2.2 docker安装部署
我们就按照上图的方式来部署,按理来说,这六个节点应该在六台不同的服务器上来搭建的.但是我们现在没有那么多的服务器,如果我们使用我们主从复制模式中的那种方式来处理,修改每台服务器的端口号/配置文件/数据文件,这样的配置模式较为复杂,而且在一台机器上部署需要避免端口之间的冲突.这会和在不同的主机上部署有着较大的差异.
所以我们就需要引入一个非常有用的中间件,Docker来解决上述问题.
2.2.1 Docker简单介绍
何为Docker,我们一定都听说过一个词,叫做虚拟机.所谓虚拟机就是通过软件,在一个电脑上模拟出另外的一些硬件.但是虚拟机有一个非常大的问题,比较吃配置,这个事情对我们仅有的一台服务器来说,压力山大.
Docker可以认为是一个"轻量级"的虚拟机,起到了虚拟机这样的环境隔离的效果,但是有没有吃很多的硬件配置资源.
在Docker中,有两个非常重要的概念需要我们做出区分,一个就是"镜像",另一个就是"容器".“镜像"可以看做一个模版或者是一个蓝图,包含了一个应用程序锁需要的所有文件,环境配置和依赖.而"容器”,就是一个运行的实例,容器是基于镜像而创建的,并且在运行的时候,可以看做一个单独的,隔离的进程空间.他们两个的关系类似与"可执行程序"和"进程"之间的关系.
2.2.2 docker安装
安装于配置的步骤如下
- 安装docker和docker-compose
docker的安装和镜像源配置有些复杂,具体可以参考以下文章:
https://blog.csdn.net/Tester_muller/article/details/131440306?ops_request_misc=%257B%2522request%255Fid%2522%253A%25220B86149A-10DD-4BD8-AD68-B868717D86F9%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=0B86149A-10DD-4BD8-AD68-B868717D86F9&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-131440306-null-null.142v100pc_search_result_base7&utm_term=Ubuntu%E5%AE%89%E8%A3%85docker&spm=1018.2226.3001.4187 - 停止之前的redis主节点和从节点的服务
root@iZ2ze9pwr3i8b65w9dr55dZ:~# ps -aux|grep redis
redis 9622 0.1 0.3 80016 6776 ? Ssl Oct26 31:13 /usr/bin/redis-server 0.0.0.0:6379
root 638323 0.1 0.2 90260 5116 ? Ssl Nov04 9:41 redis-server 0.0.0.0:6381
root 638335 0.1 0.3 90260 5360 ? Ssl Nov04 9:40 redis-server 0.0.0.0:6380
root 892387 0.0 0.1 6480 2328 pts/0 S+ 19:21 0:00 grep --color=auto redis
root@iZ2ze9pwr3i8b65w9dr55dZ:~# redis-cli -p 6380
127.0.0.1:6380> SHUTDOWN
not connected>
root@iZ2ze9pwr3i8b65w9dr55dZ:~#
root@iZ2ze9pwr3i8b65w9dr55dZ:~# redis-cli -p 6381
127.0.0.1:6381> SHUTDOWN
not connected>
root@iZ2ze9pwr3i8b65w9dr55dZ:~# service redis-server stop
- 使用docker获取到redis镜像
docker pull redis:5.0.9
2.3 基于docker搭建redis哨兵环境
此处,我们首先要使用docker-compose.yml来进行容器编排.我们可以通过这个配置文件(这里的配置文件是yml的格式)来把具体需要创建哪些容器,每个容器运行的各种参数都描述清楚.后续只需要通过一个简单的命令来批量启动/停止这些容器.
接下来我们就可以编写docker-compose.yml文件了.
2.3.1 编排redis主从节点
- 首先我们需要在目录
/root/redis/目录之下创建docker-compose.yml文件.我们需要注意的是,这个配置文件的名字是不可以乱取的,只能是这个名字,这和我们之前学习Spring的时候,配置文件application.yml的名字不能乱取是一样的. - 之后我们在这个文件中写下一下的内容
version: '3.7'
services:
master:
image: 'redis:5.0.9'
container_name: redis-master
restart: always
command: redis-server --appendonly yes
ports:
- 6379:6379
slave1:
image: 'redis:5.0.9'
container_name: redis-slave1
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6380:6379
slave2:
image: 'redis:5.0.9'
container_name: redis-slave2
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6381:6379
这其中,我们可以看到,我们创建了三个容器,一个是redis的主节点,两个是redis的从结点.我们对配置文件中的一些字段进行解释.
- services下的三个名字,代表的是redis服务自己的名字,这个名字我们可以自己设定.
- port,代表的是端口映射,我们知道docker可以理解为一个轻量级的虚拟机,在这个容器中,每个进程也都有属于自己的端口号,而docker本身又存在自己的宿主机,比如6380:6379,6380代表的是在宿主机上的进程端口号,6379代表的是在docker容器中的端口号,这样我们就可以在宿主机上通过6380端口号访问到docker容器中的6379端口号进程,这里的端口映射,有些像我们之前在本地配置访问redis的隧道.
- command启动redis的命令行,其中从结点的--slaveof后面可以直接写主节点的redis服务的名字.后续docker在启动的时候,会根据docker自动进行域名解析,会把redis服务的名字自动解析为ip地址.如果实在是向在后面直接写ip地址的话,也不一定写得上去,这是以为在容器启动之后,会动态分配ip地址,被分配的ip地址是什么,我们自己也不清楚,当然,我们可以通过某些手段来配置静态的ip.
2.3.2 编排redis哨兵节点
我们可以选择把redis的哨兵和主从节点的配置文件分开创建.这样做一方面是为了方便观察日志,另一方面是为了确保redis主从节点启动之后再启动哨兵节点,,如果我们把六个容器都配置在一个yml文件中的话,有可能先启动哨兵,日志的执行可能会产生变数,我们分成两组来启动的话,就可以保证上述顺序的正确.
- 在目录
/root/redis-sentinel/目录之下创建docker-compose.yml文件 - 在此文件中写下以下内容
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379
networks:
default:
external:
name: redis-data_default
我们来解释上面的一些字段的意思:
- volumes代表的是配置文件的映射,代表的是宿主的./sentinel2.conf配置文件会被映射到容器中的/etc/redis/sentinel.conf路径中.
- networks如果没有这个字段,我们在启动redis哨兵的时候,哨兵和数据节点就处于两个局域网中.默认情况下,两个局域网是不互通的.这里我们加入了这个字段,来把redis的数据节点和哨兵节点放入同一个局域网中.其中我们先需要使用docker network ls查询到redis数据节点的局域网,之后我们把哨兵节点的局域网和数据节点修改成一样的即可.上面我们都修改成了redis-data_default,该节点就是redis数据节点的局域网.
- 创建哨兵的配置文件
创建sentinel1.confsentinel2.confsentinel3.conf.三份文件的内容是完全相同的.都放到/root/redis-sentinel/目录中.配置文件的内容如下:
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000
我们来理解一下sentinel monitor redis-master redis-master 6379 2是什么意思,其中redis-master告诉哨兵节点,你监控的是哪个节点,这里监控的是数据节点中的主节点.redis-master 6379是主节点的主机名和ip地址,这里使用的是docker中的主机名和端口号,docker会主机名进行域名解析.2代表的是法定票数,这样可以更加稳健的确认当前的redis-server是否挂掉了,哨兵们会通过投票的方式来确认redis-server是否挂掉,只要票数超过两票,就会认为当前redis-server挂掉了.
- 之后我们就可以把数据节点和哨兵节点都启动起来了.
docker-compose up -d
如果启动之后发现有配置错误的话,我们可以使用docker-compose down停止并删除刚才创建好的容器.需要注意的是,上述的操作必须要在yml文件中的同级目录中才可以执行成功. - 之后我们打开哨兵节点的配置文件,我们发现哨兵节点启动之后,配置文件已经docker自动被修改.
bind 0.0.0.0
port 26379
sentinel myid 4d2d562860b4cdd478e56494a01e5c787246b6aa
sentinel deny-scripts-reconfig yes
# Generated by CONFIG REWRITE
dir "/data"
sentinel monitor redis-master 172.22.0.4 6379 2
sentinel down-after-milliseconds redis-master 1000
sentinel config-epoch redis-master 1
sentinel leader-epoch redis-master 1
sentinel known-replica redis-master 172.22.0.2 6379
sentinel known-replica redis-master 172.22.0.3 6379
sentinel known-sentinel redis-master 172.22.0.7 26379
f718caed536d178f5ea6d1316d09407cfae43dd2
sentinel known-sentinel redis-master 172.22.0.5 26379
2ab6de82279bb77f8397c309d36238f51273e80a
sentinel current-epoch 1
我们看到,配置文件中之前的redis-master已经被自动解析成了ip地址.
2.4 哨兵的重新选举机制-----解决监控主机宕机问题(常考面试题)
我们知道,哨兵存在的意义就是能够在redis主从结构出现问题的时候,比如主节点挂了这种情况,哨兵就会帮我们自动选举一个主节点来代替之前挂掉的主节点,保证整个redis仍然是可用的状态.
那么主节点是如何选举出一个新的主节点的呢?
- 判断主观下线
哨兵节点通过给redis-server发送心跳包,判定redis服务器是否正常工作,心跳包如果没有得到响应,这个哨兵就会认为当前服务器挂了.但也只是当前服务器认为挂了而已. - 判断客观下线
如果多个哨兵通过投票,都认为服务器挂了,而且超过了我们之前在yml配置文件中写入的法定票数.哨兵们就会一直认为服务器挂掉了. - 选取哨兵节点中的Leader
多个节点中的哨兵需要通过Raft算法来选举出一个哨兵节点中的Leader,来负责数据节点中的slave到master的提拔过程,这个算法总结下来就是,手快有手慢无.
哨兵们会通过投票的方式来完成Leader的选举,谁的票数最多,谁就会获胜,raft算法就是有一个哨兵由于网络比较快,首先投了主机一票,其他的哨兵一看,这个哨兵自愿成为愿意管事的Leader,其他的哨兵也就会顺从这个哨兵,把票都投给他.
- Leader哨兵提拔合适的slave为master,提拔的原则就是:
- 首先看优先级,每个redis的数据节点,都会在配置文件中,有一个优先级设置----
slave-priority,谁的优先级越高,谁就越会胜出. - 之后看从结点的数据复制的偏移量,即offset,offset越大说明从主节点中复制的数据越多,和主节点的数据越接近,就会优先选取offset大的来当master.
- 其次看的就是runid,runid在每个Redis节点启动的时候,都会自动随机生成一串数字.也就是随便挑一个了.
- 首先看优先级,每个redis的数据节点,都会在配置文件中,有一个优先级设置----
- 新的主节点设置好了,Leader会控制这个主节点执行
slave no one的命令,称为master,之后再控制其他的从结点,slaveof这个新的主节点.
注意事项:
- 哨兵节点最好是奇数个,避免在投票选举Leader的时候出现平票情况.
- 哨兵不负责存储数据
- 哨兵模式不可以解决极端情况下写数据丢失的情况,比如数据还没有同步到从结点,主节点先挂掉了,这时候丢失的数据是没有办法找回的.
- 哨兵模式不能提高数据的存储容量.
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » [Redis] Redis哨兵机制

发表评论 取消回复