一、原理篇
Word2Vec最初由Google公司于2013年开创性地提出,之后成为NLP领域中的基础算法。Word2Vec能够将单词映射为一个向量,这个向量能够有效刻画单词之间的语义相似度。
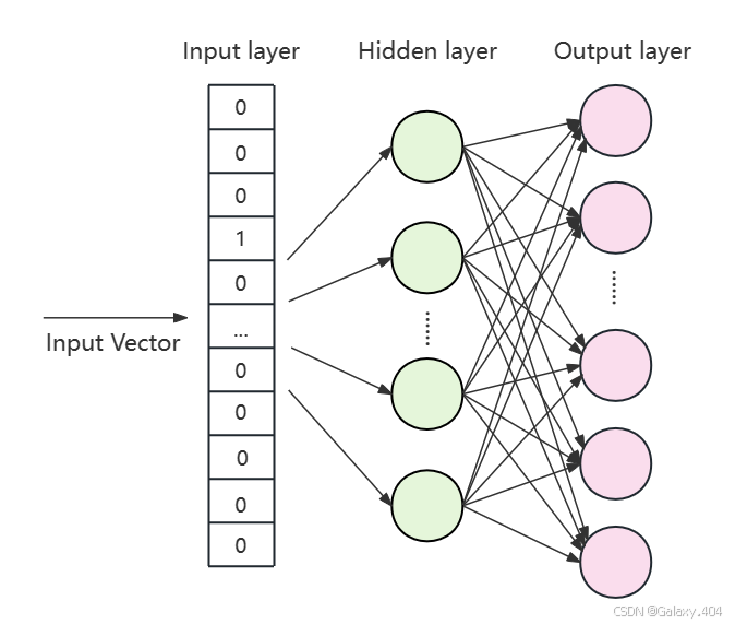
Word2Vec模型由三层神经网络构成,包括输入层、输出层和一个线性隐藏层。线性隐藏层允许模型直接将输入单词映射到向量表示,可以更有效地识别和表达单词间的语义关系。
Word2Vec包括CBOW和Skip-gram两种模型。CBOW模型通过分析一个词的周围上下文来预测这个词,Skip-gram模型则从一个中心词出发,预测其周围可能的上下文。
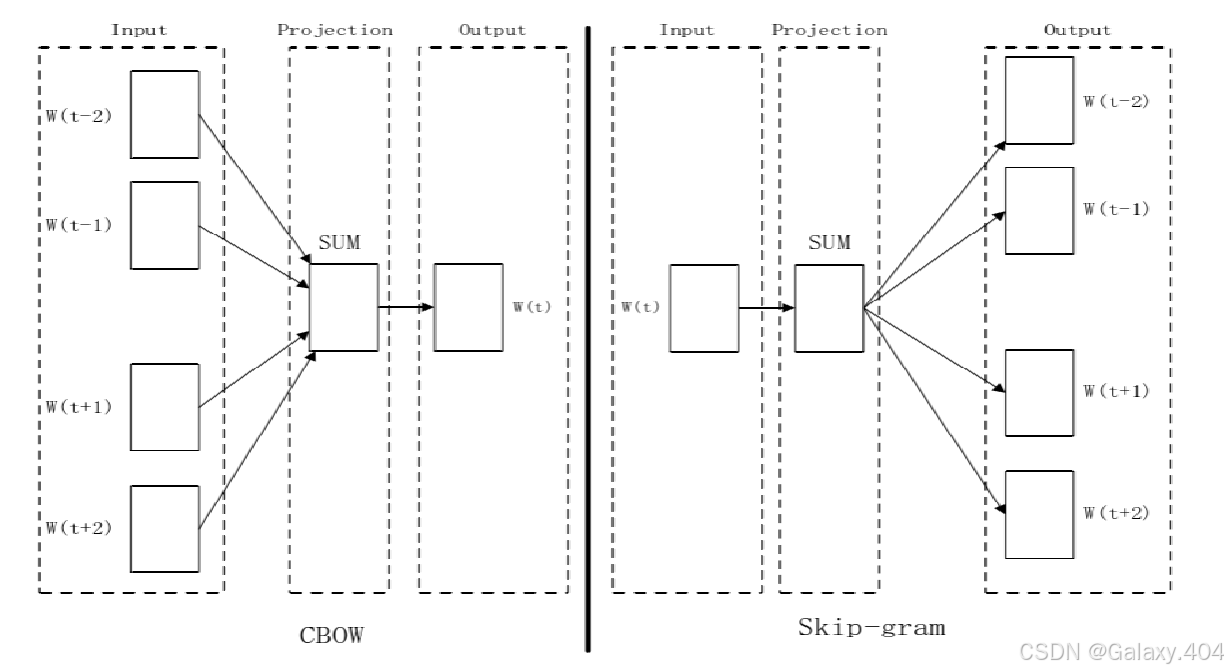
这里使用到的是Skip_gram,通过中心词来预测上下文。其模型架构如下所示:
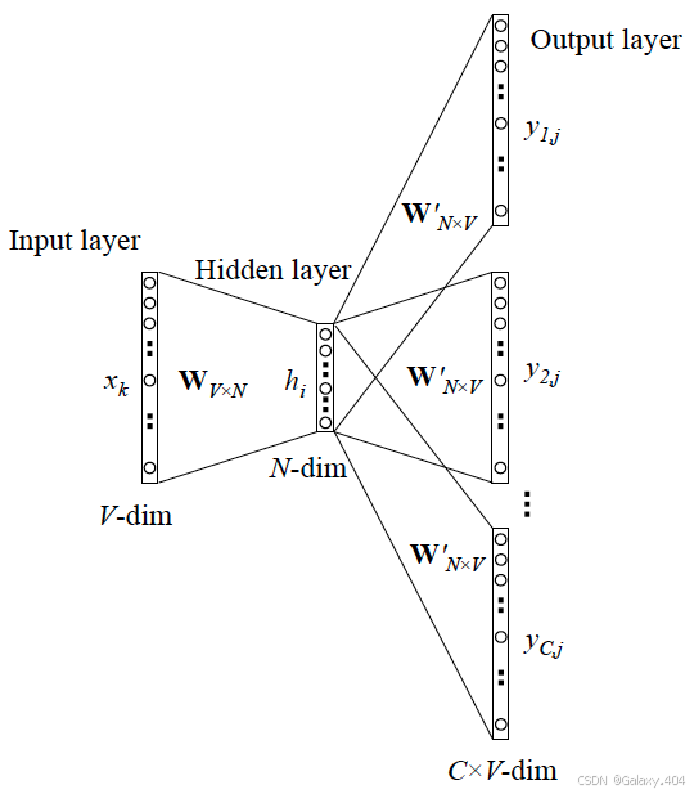
Skip-gram首先将每个单词转换为固定维度的向量,然后预测它周围上下文单词的词向量。
假设选定的窗口大小为m,则考虑的周边单词总数为2m,即中心词左侧与右侧各m个。虽然每个窗口中有2m个周围词,但每个训练实例仅包括一个中心词与一个周围词的组合。因此,对于每一个中心词,模型将生成2m个训练样本。
以句子“One of the greatest romantic comedies of the past decade.”为例。如果选取“greatest”作为中心词,窗口大小m为2,则周围词为“of”、 “the”、“romantic”、“comedies”。
在训练过程中,将产生4个样本:“greatest”预测“of”、“greatest”预测“the”、“greatest”预测“romantic”以及“greatest”预测“comedies”。
步骤如下:
(1)输入层:接收目标单词的One-hot编码向量,向量的长度等于词汇表的大小V。
(2)隐藏层:将输入层的One-hot编码向量通过与权重矩阵 

(3)输出层:使用另一个权重矩阵 
(4)概率分布:V维向量经softmax函数处理转化为概率分布形式,各元素代表相应单词在目标单词上下文中的出现几率。Softmax机制保证所有概率值之和为1,每个值都在0和1之间,反映了目标单词的所有可能上下文词的相对可能性。
(5)模型优化:模型通常通过计算交叉熵损失来评估预测概率分布与实际数据之间的差异。根据这个损失,通常使用反向传播算法来计算
二、代码篇
1、完整代码
# 1.导入必要的库
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import matplotlib.pyplot as plt
# 2.数据准备
sentences = ["jack like dog", "jack like cat", "jack like animal",
"dog cat animal", "banana apple cat dog like", "dog fish milk like",
"dog cat animal like", "jack like apple", "apple like", "jack like banana",
"apple banana jack movie book music like", "cat dog hate", "cat dog like"]
word_list = " ".join(sentences).split()
vocab = list(set(word_list))
word_index = {w: i for i, w in enumerate(vocab)}
vocab_size = len(vocab)
# 3.构造中心词及其上下文
window_size = 2
skip_grams = []
for index in range(window_size, len(word_list) - window_size):
center = word_index[word_list[index]]
context_id = list(range(index - window_size, index)) + list(range(index + 1, index + window_size + 1))
context = [word_index[word_list[i]] for i in context_id] # 这里得到的是每个单词在无重复列表中的位置索引
for w in context:
skip_grams.append([center, w]) # 这里也就是我们要的skip_grams了,二维,每一行为【中心词,1个上下文词】
# 4.构造输入输出数据
def make_data():
input_data = []
output_data = []
for i in range(len(skip_grams)):
input_temp = np.eye(vocab_size)[skip_grams[i][0]]
output_temp = skip_grams[i][1]
input_data.append(input_temp)
output_data.append(output_temp)
return input_data, output_data
input_data, output_data = make_data()
input_data, output_data = torch.LongTensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
batch_size = 7
loader = Data.DataLoader(dataset, batch_size, True)
# 5.模型搭建
embedding_dim = 2
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
self.W = nn.Parameter(torch.randn(vocab_size, embedding_dim))
self.V = nn.Parameter(torch.randn(embedding_dim, vocab_size))
def forward(self, X):
# X:[batch_size, vocab_size] one-hot
hidden_layer = torch.mm(X.float(), self.W) # hidden:[batch_size, embedding_dim]
output_layer = torch.mm(hidden_layer, self.V) # output_layer:[batch_size, vocab_size]
return output_layer
# 6.定义训练过程
model = Word2Vec()
optimzer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss()
# 7.模型训练
for epoch in range(2000):
for i, (batch_x, batch_y) in enumerate(loader):
pred = model(batch_x)
loss = criterion(pred, batch_y)
if (epoch + 1) % 500 ==0:
print(epoch+1, loss.item())
optimzer.zero_grad()
loss.backward()
optimzer.step()
# 8.可视化
for i, label in enumerate(vocab):
W, WT = model.parameters()
x, y = float(W[i][0]), float(W[i][1])
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()2、代码简单解释
1.最开始导入一些必要的库
2.首先需要准备一些数据,用于模型训练并测试
这里需要对数据文本进行切分,且得到一个没有重复元素的列表,然后构造单词-位置索引字典word_index。
3.对于Word2Vec,需要根据窗口大小构造出Skip_grams
也就是包含 [中心词,一个上下文词] 的二维矩阵,这里设置了只在上下文都能截取到跟窗口大小规模一样的单词范围内,这里设置了窗口大小window_size=2,所以从第3个单词开始到倒数第3个单词结束。
Skip_grams 输出结果:
[ [4, 5], [4, 11], [4, 5], [4, 11], [5, 11], [5, 4], [5, 11], [5, 1], [11, 4], [11, 5], [11, 1], [11, 5], [1, 5], [1, 11], [1, 5], [1, 11], [5, 11], [5, 1], [5, 11], [5, 9], [11, 1], [11, 5], [11, 9], [11, 4], [9, 5], [9, 11], [9, 4], [9, 1], [4, 11], [4, 9], [4, 1], [4, 9], [1, 9], [1, 4], [1, 9], [1, 10], [9, 4], [9, 1], [9, 10], [9, 8], [10, 1], [10, 9], [10, 8], [10, 1], [8, 9], [8, 10], [8, 1], [8, 4], [1, 10], [1, 8], [1, 4], [1, 11], [4, 8], [4, 1], [4, 11], [4, 4], [11, 1], [11, 4], [11, 4], [11, 2], [4, 4], [4, 11], [4, 2], [4, 0], [2, 11], [2, 4], [2, 0], [2, 11], [0, 4], [0, 2], [0, 11], [0, 4], [11, 2], [11, 0], [11, 4], [11, 1], [4, 0], [4, 11], [4, 1], [4, 9], [1, 11], [1, 4], [1, 9], [1, 11], [9, 4], [9, 1], [9, 11], [9, 5], [11, 1], [11, 9], [11, 5], [11, 11], [5, 9], [5, 11], [5, 11], [5, 8], [11, 11], [11, 5], [11, 8], [11, 8], [8, 5], [8, 11], [8, 8], [8, 11], [8, 11], [8, 8], [8, 11], [8, 5], [11, 8], [11, 8], [11, 5], [11, 11], [5, 8], [5, 11], [5, 11], [5, 10], [11, 11], [11, 5], [11, 10], [11, 8], [10, 5], [10, 11], [10, 8], [10, 10], [8, 11], [8, 10], [8, 10], [8, 5], [10, 10], [10, 8], [10, 5], [10, 3], [5, 8], [5, 10], [5, 3], [5, 6], [3, 10], [3, 5], [3, 6], [3, 7], [6, 5], [6, 3], [6, 7], [6, 11], [7, 3], [7, 6], [7, 11], [7, 1], [11, 6], [11, 7], [11, 1], [11, 4], [1, 7], [1, 11], [1, 4], [1, 12], [4, 11], [4, 1], [4, 12], [4, 1], [12, 1], [12, 4], [12, 1], [12, 4], [1, 4], [1, 12], [1, 4], [1, 11] ]
4.构造输入输出数据
这里的输入我们回答原理篇可以知道,输入层接收目标单词的 one-hot 编码向量,向量的长度等于词汇表的大小V。
所以这里设置了 [skip_grams[i][0]] ,也就是便利获得 skip_grams 中的第一列所有数值,也就是中心词,将中心词作为输入,但是要使用 np.eye() 将其转化为 one-hot 编码,得到的就是一个 vocab_size * vocab_size 大小的 one-hot 编码矩阵。
5.模型搭建
隐藏层 hidden_layer 由输入层的 one-hot 编码
这是因为在 Word2Vec 中,我们希望将词从高维的 one-hot 编码(即词汇表大小)映射到一个低维的嵌入空间(embedding_dim)。因此,self.W 的作用是将词的 one-hot 向量转换成低维的词嵌入向量,这个向量的维度就是 embedding_dim。
然后再使用另一个权重矩阵
6.定义训练过程
这里初始化model,并且设置优化器为Adam,并且使用了交叉熵损失。
7.模型训练
这里从数据加载器中加载数据,将当前批次的输入数据batch_x传入模型中得到预测结果,同时计算预测值与真实值的损失loss,每500个epoch打印损失。然后梯度清零、反向传播计算梯度、更新模型参数。
8.可视化
将 Word2Vec 模型训练得到的词嵌入向量在二维平面上进行可视化。之所以在二维平面上进行可视化,是因为在 Word2Vec 模型中设置的嵌入维度 (embedding_dim) 为 2。
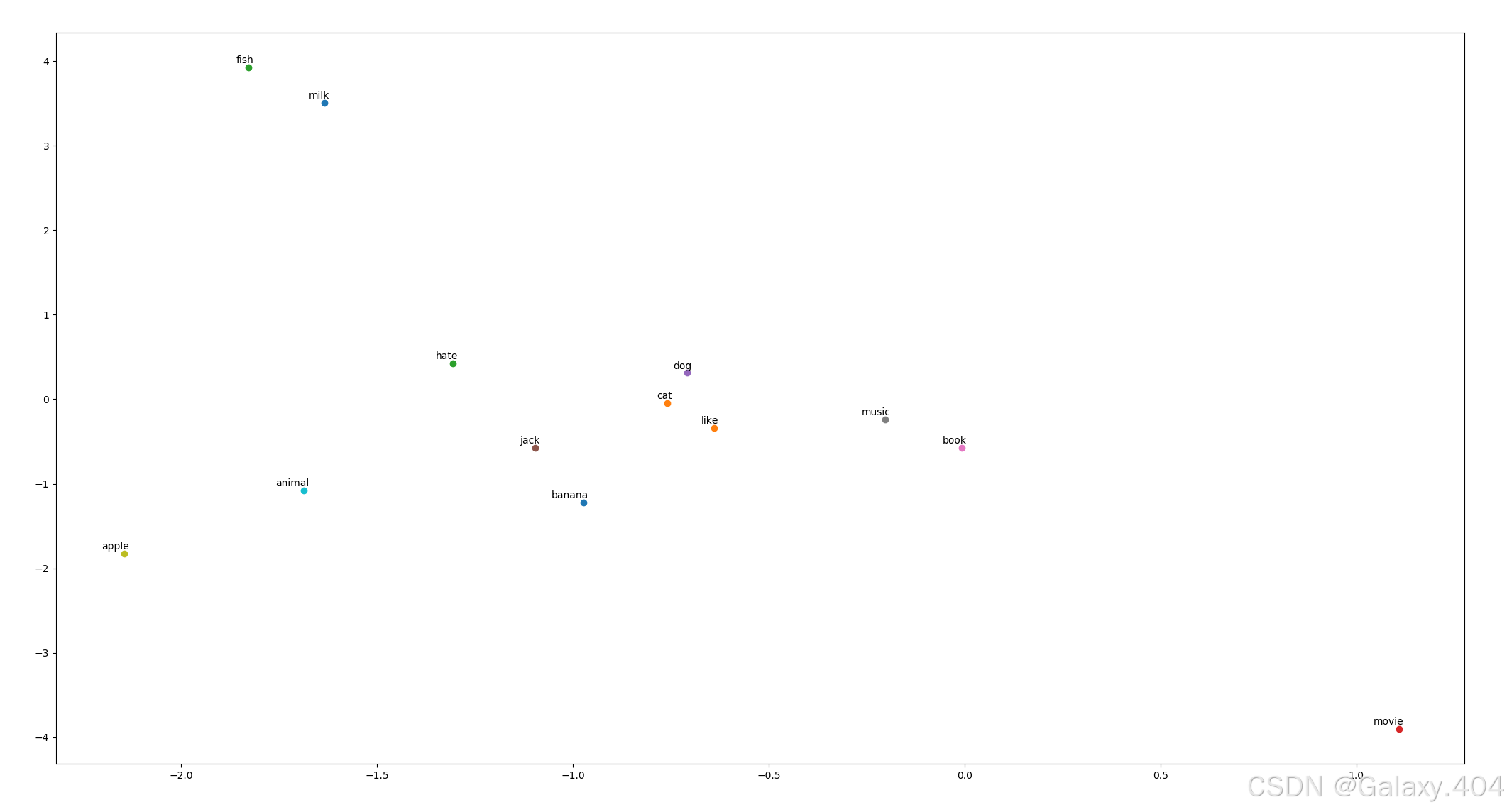
由于这里的 W 和 W' 是随机的,所以每一次运行之后得到的最红可视化结果可能会有区别。
参考
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Word2Vec——嵌入单词并显示图形

发表评论 取消回复