使用 Ollama 平台上的 Llama 3.2-vision 模型进行视频目标检测
在本期推荐的文章中,视频将展示如何通过 Ollama 平台上的 Llama 3.2-vision 多模态模型,结合 Python 和 FastAPI 框架,轻松实现视频目标检测功能。只需要简单的代码,我们就能识别视频中的目标人物,甚至有可能帮助我们找回失踪的宠物。
主要内容
- 全新多模态模型 Llama3.2-vision: 在 Ollama 平台上,Llama3.2-vision 带来了强大的图像和视频处理能力。
- 简单的 Python 和 FastAPI 代码: 不需要复杂的配置,直接通过 Python 代码调用模型来实现视频中的目标检测。
- 精准识别和置信度: 系统逐帧分析视频,识别目标人物并提供相应的置信度和描述。
- 实际应用: 除了识别人物,Llama 3.2-vision 还能帮助我们寻找丢失的宠物。
视频亮点
- Ollama 支持 Llama 3.2 Vision: 介绍 Ollama 平台上支持的 Llama 3.2-vision 模型的功能。
- 基础功能测试: 通过简单的图像识别测试,了解 Llama3.2-vision 的基本能力。
- 提取博客文章内容: 展示如何通过 Llama 3.2 提取博客文章中的关键信息。
- 视频抽帧分析: 演示了视频逐帧分析如何精准地检测骑车人物等目标。
- Web 界面版本: 还展示了一个基于 Web 的前端界面版本,便于实际测试和展示结果。
代码实现及演示
代码实现讲解
视频详细讲解了如何通过简单的 Python 代码,结合 FastAPI 框架,快速集成 Llama3.2-vision 模型来进行目标识别。代码的核心思想是逐帧分析视频,并通过模型来识别视频中的目标人物。
测试案例
- 识别金毛犬图片: 通过输入金毛犬的图像,系统能够精准识别出图像中的狗狗。
- 提取博客文章内容: 模型还能够提取和处理文本数据,帮助我们快速整理文章内容。
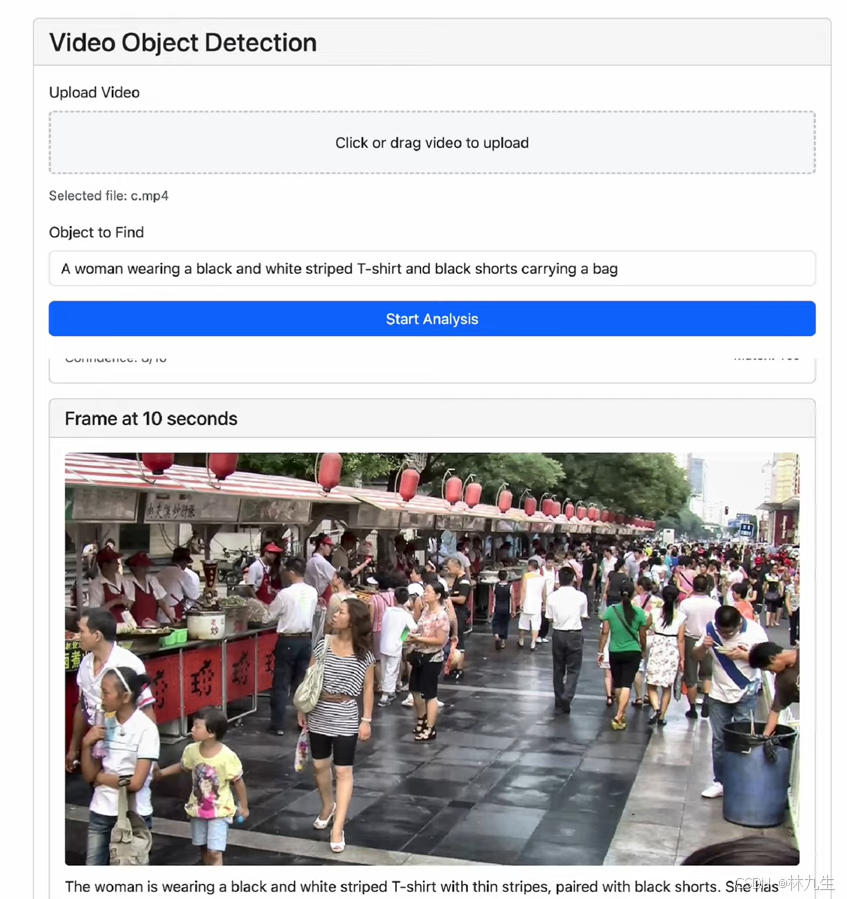
视频目标检测
系统逐帧分析视频并通过模型来识别骑车人物或其他目标。每一帧都会返回识别结果和置信度,确保检测结果的准确性。
视频链接
视频时间戳
- 00:00 介绍:Ollama 支持 Llama 3.2 Vision
- 01:47 基础功能测试:识别图像
- 02:30 测试案例:识别金毛犬图片
- 03:00 测试案例:提取博客文章内容
- 03:55 代码实现详细讲解
- 05:50 视频抽帧分析功能说明
- 06:20 运行示例:检测骑车人物
- 07:38 成功检测结果展示
- 08:29 Web界面版本演示
- 09:29 实际测试:检测特定目标人物
- 10:07 完整分析过程演示
- 11:21 总结和代码获取说明
总结
通过这篇文章和视频演示,您将学会如何使用 Llama 3.2-vision 多模态模型进行视频目标检测,同时掌握如何利用 Python 和 FastAPI 框架快速实现此功能。这项技术不仅能应用于视频分析,还能为实际生活中的目标识别提供帮助,特别是在寻找丢失宠物等场景中具有很大潜力。
标签:#AI技术 #多模态模型 #视频目标检测 #Llama3 #Ollama #Python #提示词工程 #FastAPI #VLM #Llama3.2 #Prompt #PromptEngineering
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【每日推荐】使用 Ollama 平台上的 Llama 3.2-vision 模型进行视频目标检测

发表评论 取消回复