纯个人python的一个小回忆笔记,当时假期花两天学的python,确实时隔几个月快忘光了,为了应付作业才回忆起来,不涉及太多基础,适用于有一定编程基础的参考回忆。

一、pandas是什么?
Pandas 是一个开源的 Python 数据分析库,它提供了快速、灵活以及表达力强的数据结构,旨在使“关系”或“标签”数据的操作既简单又直观。它主要用于【数据清洗】和【数据分析】工作。
以下是 Pandas 一些关键特性的简要概述:
DataFrame:Pandas 的核心数据结构,类似于 Excel 中的表格,可以包含不同类型的列,非常适合存储和操作结构化数据。
Series:一种一维数组结构,可以包含任何数据类型,通常用作 DataFrame 的单个列。
数据处理能力:Pandas 提供了大量用于数据清洗和处理的功能,包括缺失数据处理、数据过滤、数据对齐和数据聚合等。
时间序列分析:Pandas 内置了对时间序列数据的支持,可以轻松地处理和分析时间序列数据。
数据合并与重塑:Pandas 提供了强大的数据合并、连接和重塑功能,使得数据的整合和转换变得简单。
数据导入与导出:Pandas 可以轻松地从多种数据源(如 CSV、Excel、SQL 数据库等)导入数据,并且可以将处理后的数据导出到不同的格式。
高级时间序列功能:Pandas 拥有处理时间序列数据的强大工具,包括频率转换、移动窗口统计等。
集成和扩展:Pandas 可以很容易地与其他 Python 数据分析库(如 NumPy、SciPy、Matplotlib 和 Scikit-learn)集成,也可以通过接口与其他编程语言和数据存储系统交互。
二、读取文件
首先一般我们爬虫爬取下来的数据,或者从别人那获取到的数据,都应该是在文件里的。那么要获取数据,就要分析、提取出这些文件里的内容
那么pandas就能够分析读取文件数据,但是它支持的文件格式必须的【表格形式】!
例如下面这几种:

1、安装与使用pandas
首先我们要引入这个库
用下面命令安装
pip install pandas
用anaconda管理python的可以执行这个命令安装,也是一样的conda install pandas
然后在代码首行导入:
import pandas as pd # as pd的意思是给pandas起别名,用pd代替pandas
2、尝试导入文件
(文件内容在这,这是我本人爬虫一个简单网站获取的数据,这里把内容放这,请各位对照着文件格式,分别创建对应的文件、并复制粘贴到自己的文件里)
【excel文件】,自行创建一个叫【books.xlsx】的文件,直接复制粘贴进去
Title Price A Light in the Attic 51.77 Tipping the Velvet 53.74 Soumission 50.10 Sharp Objects 47.82 Sapiens: A Brief History of Humankind 54.23 The Requiem Red 22.65 The Dirty Little Secrets of Getting Your Dream Job 33.34 The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull 17.93 The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics 22.60 The Black Maria 52.15 Starving Hearts (Triangular Trade Trilogy, #1) 13.99 Shakespeare's Sonnets 20.66 Set Me Free 17.46 Scott Pilgrim's Precious Little Life (Scott Pilgrim #1) 52.29 Rip it Up and Start Again 35.02 Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991 57.25 Olio 23.88 Mesaerion: The Best Science Fiction Stories 1800-1849 37.59 Libertarianism for Beginners 51.33 It's Only the Himalayas 45.17【csv文件】,自行创建一个叫【books.csv】的文件,直接复制粘贴进去
Title,Price A Light in the Attic,51.77 Tipping the Velvet,53.74 Soumission,50.10 Sharp Objects,47.82 Sapiens: A Brief History of Humankind,54.23 The Requiem Red,22.65 The Dirty Little Secrets of Getting Your Dream Job,33.34 "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull",17.93 The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics,22.60 The Black Maria,52.15 "Starving Hearts (Triangular Trade Trilogy, #1)",13.99 Shakespeare's Sonnets,20.66 Set Me Free,17.46 Scott Pilgrim's Precious Little Life (Scott Pilgrim #1),52.29 Rip it Up and Start Again,35.02 "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991",57.25 Olio,23.88 Mesaerion: The Best Science Fiction Stories 1800-1849,37.59 Libertarianism for Beginners,51.33 It's Only the Himalayas,45.17【txt文件】, 自行创建一个叫【books.txt】的文件,直接复制粘贴进去
Title: A Light in the Attic, Price: 51.77 Title: Tipping the Velvet, Price: 53.74 Title: Soumission, Price: 50.10 Title: Sharp Objects, Price: 47.82 Title: Sapiens: A Brief History of Humankind, Price: 54.23 Title: The Requiem Red, Price: 22.65 Title: The Dirty Little Secrets of Getting Your Dream Job, Price: 33.34 Title: The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Price: 17.93 Title: The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics, Price: 22.60 Title: The Black Maria, Price: 52.15 Title: Starving Hearts (Triangular Trade Trilogy), Price: 13.99 Title: Shakespeare's Sonnets, Price: 20.66 Title: Set Me Free, Price: 17.46 Title: Scott Pilgrim's Precious Little Life (Scott Pilgrim #1), Price: 52.29 Title: Rip it Up and Start Again, Price: 35.02 Title: Our Band Could Be Your Life: Scenes from the American Indie Underground 1981-1991, Price: 57.25 Title: Olio, Price: 23.88 Title: Mesaerion: The Best Science Fiction Stories 1800-1849, Price: 37.59 Title: Libertarianism for Beginners, Price: 51.33 Title: It's Only the Himalayas, Price: 45.17
1)读取csv文件
首先复制你的csv文件的路径
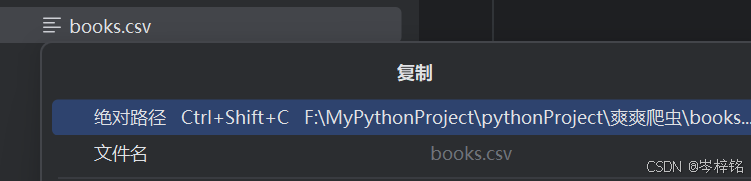
但是主注意文件路径这里,一般直接复制引用过来时,字符串里的“\”通常会被误认为是【转义字符】,会导致路径错误
只需要在路径前加一个“r”或“R”,就能成为一个没有【转义字符】的普通字符串


然后很简单,第一步拿到文件路径
第二步用pandas的read_csv方法可以读取出csv文件的内容,然后直接输出就能看到内容
import pandas as pd
# 这是文件的路径变量
csv_path = r'F:\MyPythonProject\pythonProject\爽爽爬虫\books.csv'
# 用pandas的read_csv方法读取csv文件
csv_data = pd.read_csv(csv_path)
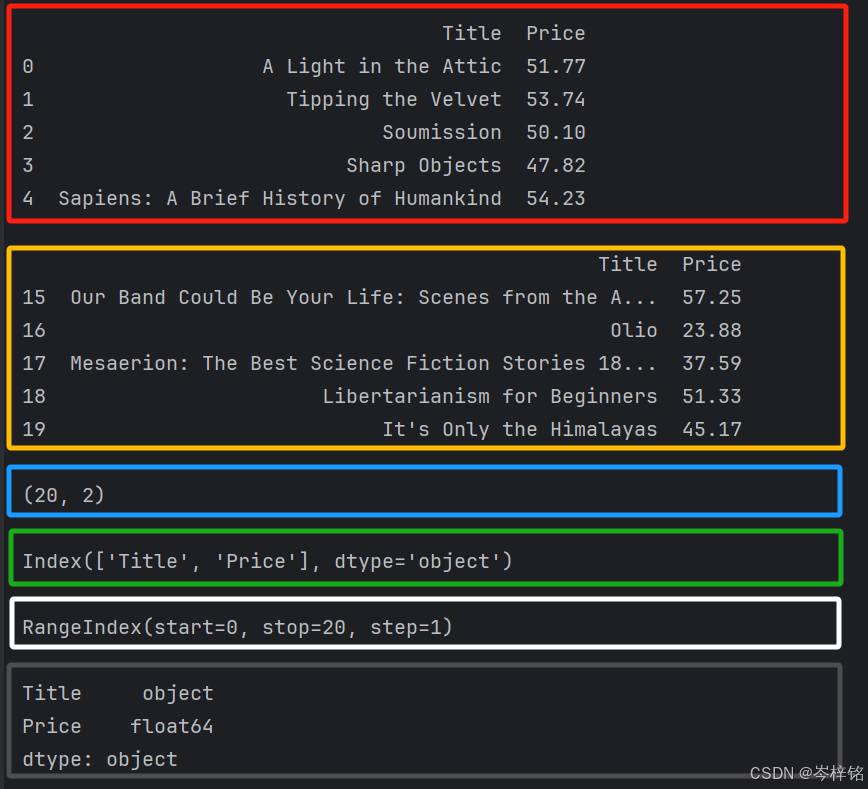
print(csv_data, end="\n\n")另外,pandas提供了很多查看文件内容细节的方法,比如:读取前几行、读取最后几行、查看数据几行几列、查看列名、查看各列的数据的数据类型......
;
# 读取前几行数据 print(csv_data.head(), end="\n\n") # 读取后几行数据 print(csv_data.tail(), end="\n\n") # 查看数据形状 print(csv_data.shape, end="\n\n") # 查看【列名】(也就是表格开头一行的“标签”) print(csv_data.columns, end="\n\n") # 查看有几行数据 print(csv_data.index, end="\n\n") # 查看数据类型(包括每一列的数据分别是什么类型的数据值) print(csv_data.dtypes, end="\n\n")
2)读取excel文件
跟读取csv文件一样,只不过用来读取的函数是【pd.read_excel( )】
# 读取Excel文件
excel_path = r'F:\MyPythonProject\pythonProject\爽爽爬虫\books.xlsx'
excel_data = pd.read_excel(excel_path)
print(excel_data, end="\n\n")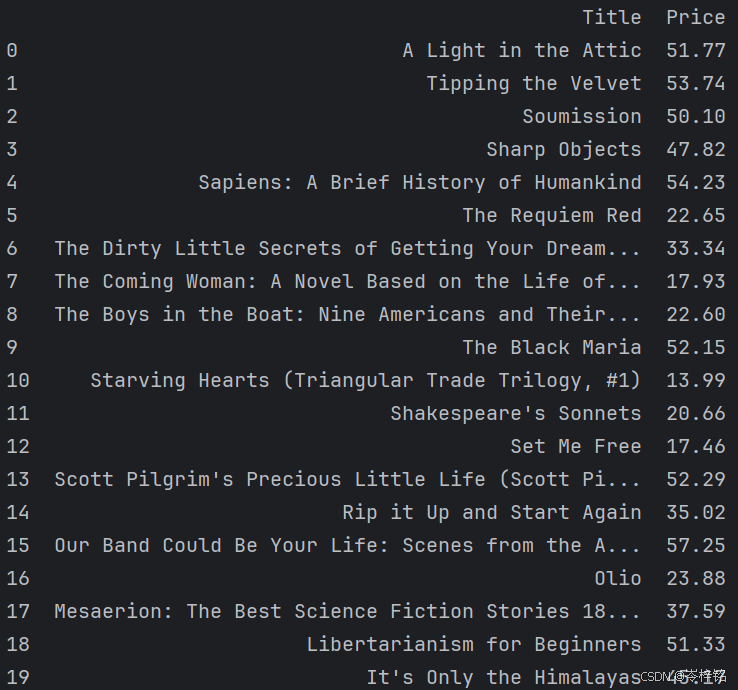
3)读取txt文件
这个txt文件注意了,初学者先拿我上面的文件一字不漏的复制进去别改,txt文件不像mysql、excel这些文件一样规划好了分割字符串的分隔符,分隔符是我们自定义的,你可以设置分隔符、列名在任意位置、以什么为标准
例如:
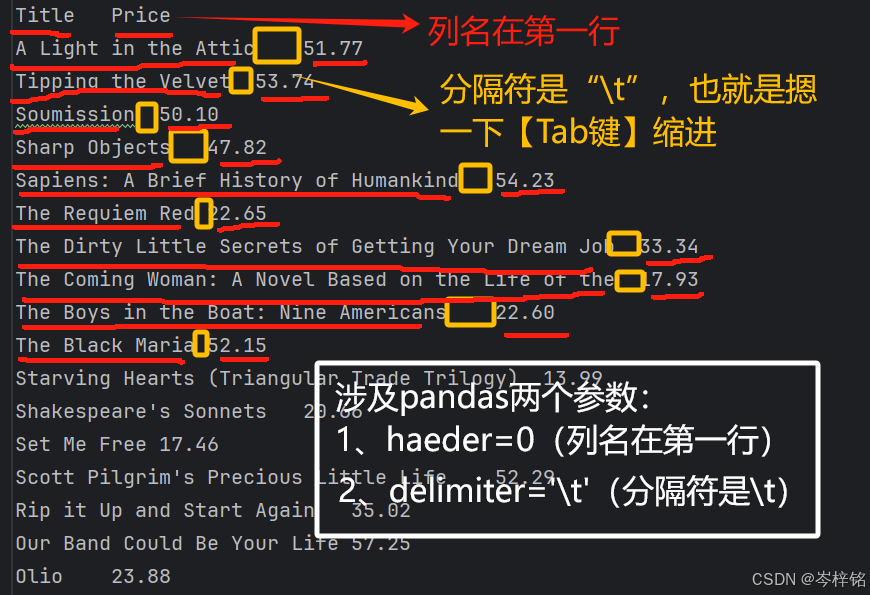
列名在第一行:
;
列名不在第一行,而且分隔符是“, ”:
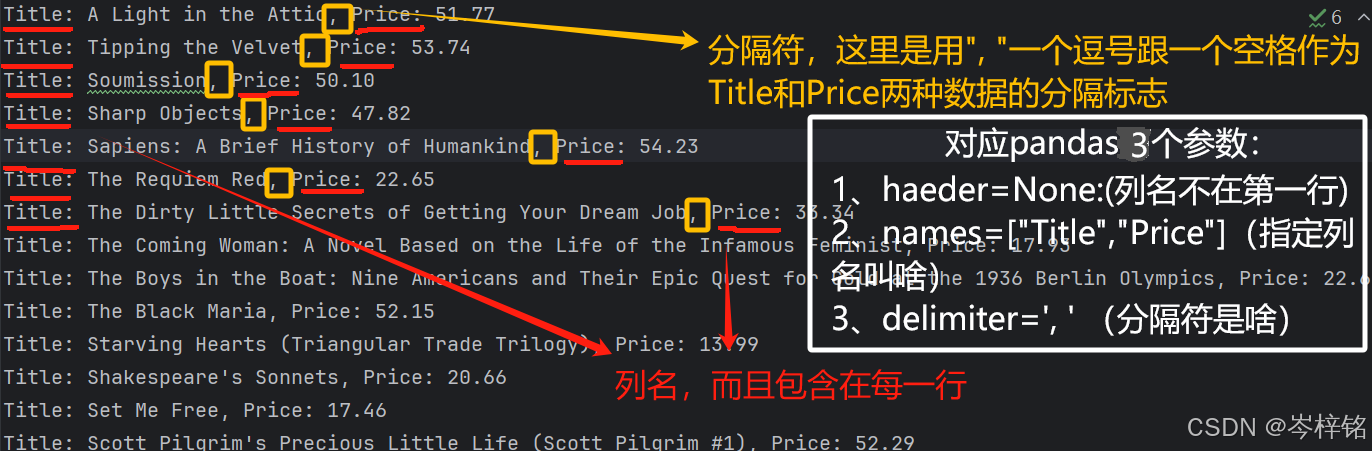
那么我们用的还是【pd.readcsv( )】这个函数,但是我们要对应我们自定义的txt文件进行针对的参数配置
(注意最后一个参数,不加会报错,因为会默认读取引擎是c语言的,但是在这里我们要用的是python的,没什么技术含量,只是不加会报错)

对应上面我给的txt的示例读取代码:
# 读取TXT文件
txt_path = r'F:\MyPythonProject\pythonProject\爽爽爬虫\books.txt'
txt_data = pd.read_csv(
txt_path, # 文件路径
delimiter=', ', # 分隔符,这里我指定以“,”和“ ”作为分隔符来切割数据
header=None, # 是否将第一行作为列名(默认为True)
names=["Title", "Price"], # 指定列名
engine='python' # 指定解析引擎,编译器会默认为'c','python'可以处理更复杂的分隔符
)
print(txt_data, end="\n\n")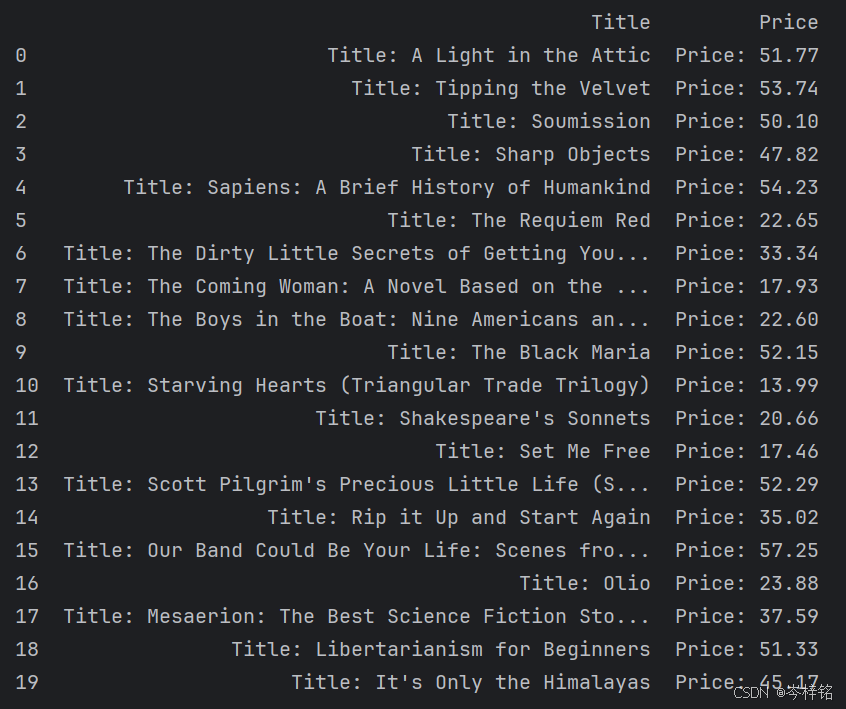
4)读取数据库的表文件
这里数据库的数据就自己创建吧,我就不再给文件了,太麻烦了,这里只给pandas教程
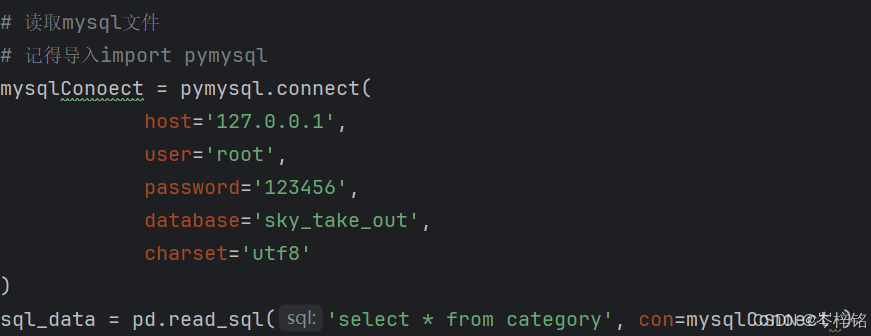
【老方法】
网上的老方法是用【pymysql】库的connect( )方法来连接数据库,但是我查了发现会报错,查了很多地方都说不用这个方法了,有懂的同志可以说一下问什么这样会错

【新方法】
首先还是上面的安装步骤我就不详细说了,【pip install sqlalchemy】下载 sqlalchemy 包
然后导入
;
然后创建连接数据库的引擎【create_engine( 'URL' )】
;
这里注意【create_engine( 'URL' )】这里的URL,前面有一段字符串是根据不同数据库的不同固定拼接
;
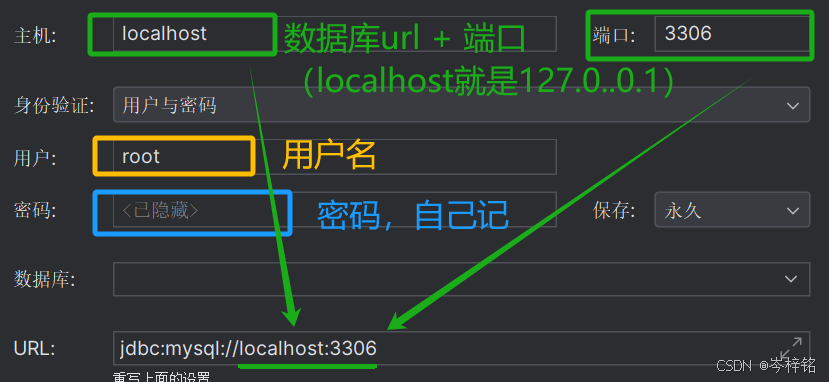
然后你后面的具体数据库信息可以去自己查看,会数据库的大概都懂,这里以mysql做简单演示:
;
然后就是使用pandas的【pd.read_sql_query( )】函数查询数据库
;
源代码【简洁写法】
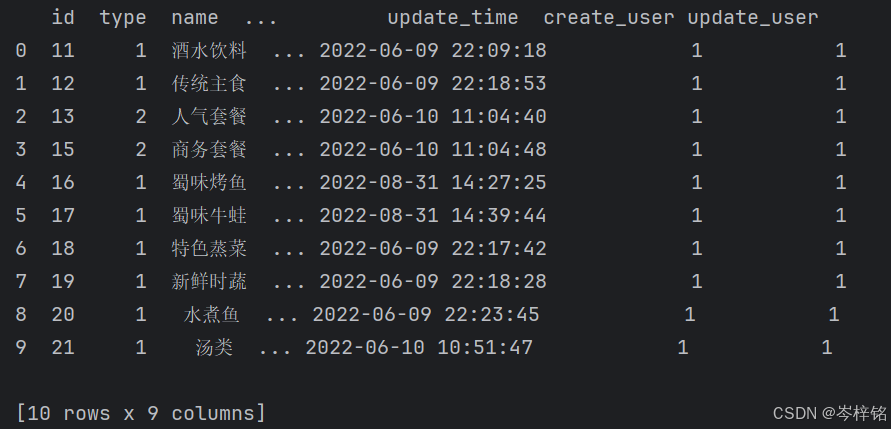
# 简洁写法 # 创建数据库连接引擎 engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/sky_take_out') # 使用pandas的read_sql_query函数查询数据库 sql_data = pd.read_sql('select * from category', engine) print(sql_data, end="\n\n")当然【规范写法】你也可以把要拼接的url的那些配置参数用变量写好先,再拼接,sql语句也是
# 清晰结构的写法 # 基础配置 MYSQL_HOST = 'localhost' MYSQL_PORT = '3306' MYSQL_USER = 'root' MYSQL_PASSWORD = '123456' MYSQL_DB = 'sky_take_out' # 创建数据库连接引擎 engine = create_engine('mysql+pymysql://%s:%s@%s:%s/%s?charset=utf8' % (MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, MYSQL_DB)) # 使用pandas的read_sql_query函数查询数据库 sql = 'select * from category' df = pd.read_sql(sql, engine) print(df, end="\n\n")





三、pandas的数据结构(DataFrame和Series)
Pandas 的主要数据结构是 Series(一维数组)和 DataFrame(二维表格型数据结构),它们都是建立在 NumPy 数组之上的。
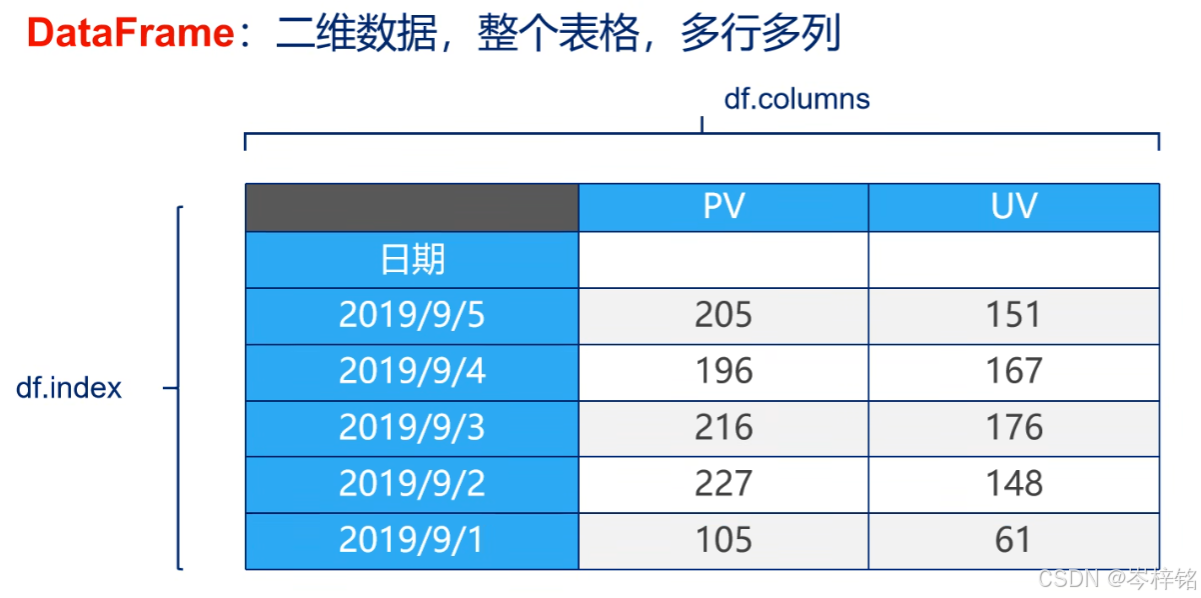
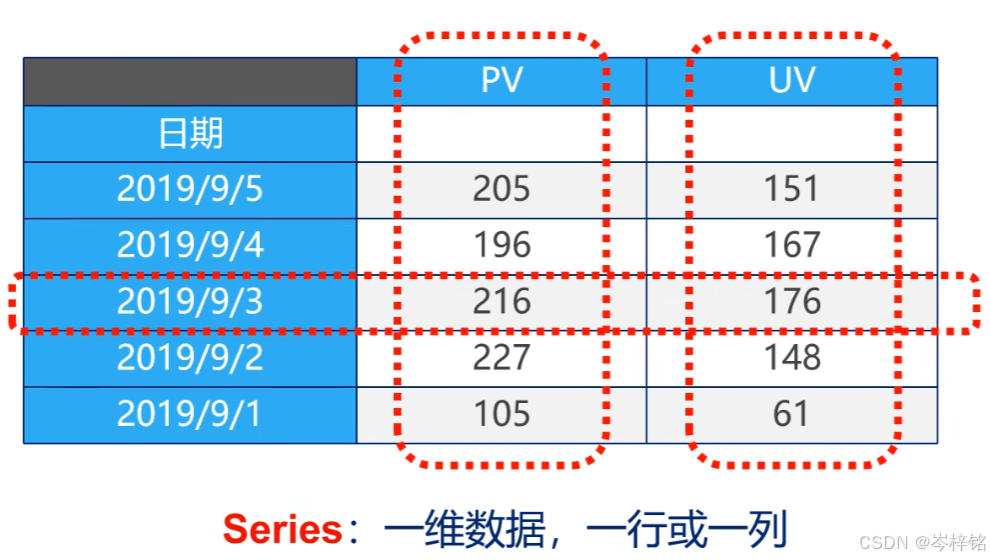
1、Series一维数组
Series是一种类似一维数组的数据列表,有两种元素组成:【数据】和【索引】,一个数据对应一个索引,索引默认是0、1、2这种数字索引,也可以是自定义的字符串
说白了,就是【键值对】,最能证明的就是可以用python的【字典】来创建一个Series数组,字典不就是键值对嘛
【默认的每个数据的索引就是0、1、2...数字索引】
import numpy as np
import pandas as pd
# 默认的每个数据的索引就是0、1、2...数字索引
s = pd.Series([1, 2, 'a', 4, False])
print(s)
# 索引 数据值
# ——> 0 1
# 1 2
# 2 a
# 3 4
# 4 False
# dtype: object
# 获取Series数组的索引
print(s.index) # ——> RangeIndex(start=0, stop=5, step=1)
# 获取Series数组的数据值
print(s.values) # ——> [1 2 'a' 4 False]【创建一个 [ 指定索引 ] 的Series数组】
import numpy as np
import pandas as pd
# 创建一个【指定索引】的Series数组
s = pd.Series([1, 2, 'a', 4, False], index=['a', 'b', 'c', 'd', 'e'])
print(s)
# 索引 数据值
# ——> a 1
# b 2
# c a
# d 4
# e False
# dtype: object
print(s.index) # ——> Index(['a', 'b', 'c', 'd', 'e'], dtype='object')【使用python字典创建Series数组】
import numpy as np
import pandas as pd
# 使用python字典创建Series数组
manba = {
'name': 'KOBE',
'age': 24,
'gender': 'man',
'isAlive': False
}
s = pd.Series(manba)
print(s)
# 索引 数据值
# ——> name KOBE
# age 24
# gender man
# isAlive False
# dtype: object
print(s.index) # ——> Index(['name', 'age', 'gender', 'isAlive'], dtype='object')【获取数据值】
# 使用python字典创建Series数组
manba = {
'name': 'KOBE',
'age': 24,
'gender': 'man',
'isAlive': False
}
s = pd.Series(manba)
# 跟字典一模一样
print(s['name']) # ——> KOBE
# 注意:要一次获取多个索引的数据值,就要用列表形式[a,b...],不能直接在索引那写多个索引
print(s[['age', 'isAlive']])
# 索引 数据值
# ——> age 24
# isAlive False
# dtype: object
# 这里注意,获取多个索引值的时候,返回的还是一个Series数组
# 返回的是数据值的数据类型
print(type(s['name'])) # ——> <class 'str'>
# 返回的是Series数组数据类型
print(type(s[['age', 'isAlive']])) # ——> <class 'pandas.core.series.Series'>2、Dataframe二维数组
说白了也是字典,只不过是每个成员元素都是【列表】
Dataframe既然是二维的,那么里面字典的【键】对应每一列的【列名】,【值】对应每一列数据值

【创建Dataframe数组】
# Dataframe
NBAStar = {
'name': ['KOBE', 'Jrodan', 'Curry', 'Lin', 'Yaoming'],
'age': [24, 23, 30, 7, 11],
'gender': ['man', '男人', '男人', '男人', '男人'],
'isAlive': [False, True, True, True, True]
}
df = pd.DataFrame(NBAStar)
print(df)
# 索引 name age gender isAlive
# ——> 0 KOBE 24 man False
# 1 Jrodan 23 男人 True
# 2 Curry 30 男人 True
# 3 Lin 7 男人 True
# 4 Yaoming 11 男人 True
# 输出每一列的【列名】,也就是这个Dataframe每个元素的【键】
print(df.columns) # ——> Index(['name', 'age', 'gender', 'isAlive'], dtype='object')
# 输出每一行的【行索引】,默认是0、1、2...数字索引
print(df.index) # ——> RangeIndex(start=0, stop=5, step=1)【查看数据类型】
直接【df.dtypes】查看所有每一列的“列名(标签)”以及对应的每一列值的“数据类型”
print(df.dtypes) # 输出每一列的【标签】和对应的值的【数据类型】 # name object # age int64 # gender object # isAlive bool # dtype: object【查看每一列的“列名(标签)”】
# 输出每一列的【列名】,也就是这个Dataframe每个元素的【键】 print(df.columns) # ——> Index(['name', 'age', 'gender', 'isAlive'], dtype='object')【查看每一行的【行索引】,默认是0、1、2...数字索引】
# 输出每一行的【行索引】,默认是0、1、2...数字索引 print(df.index) # ——> RangeIndex(start=0, stop=5, step=1)
【自定义行索引】
一般行索引都是自动生成的0、1、2....,如果你看不爽自动生成的【数字行索引】
你也可以用:【df.index = [ "自定义索引1","自定义索引2","自定义索引3"...... ]】
NBAStar = { 'name': ['KOBE', 'Jrodan', 'Curry', 'Lin', 'Yaoming'], 'age': [24, 23, 30, 7, 11], 'gender': ['man', '男人', '男人', '男人', '男人'], 'isAlive': [False, True, True, True, True] } df = pd.DataFrame(NBAStar) # 将行索引换成自定义的 df.index = ['球星01', '球星02', '球星03', '球星04', '球星05'] print(df)或者直接在创建DataFrame的时候就指定好行索引
NBAStar = { 'name': ['KOBE', 'Jrodan', 'Curry', 'Lin', 'Yaoming'], 'age': [24, 23, 30, 7, 11], 'gender': ['man', '男人', '男人', '男人', '男人'], 'isAlive': [False, True, True, True, True] } df = pd.DataFrame(NBAStar, index=['球星01', '球星02', '球星03', '球星04', '球星05']) print(df)
;
除此之外,你还可以用【 df.set_index('指定的列名', inplace=True) 】
直接将已有的【某一列】指定为行索引
比如还是用上面例子,将上面表以已经存在的【name】为行索引
NBAStar = { 'name': ['KOBE', 'Jrodan', 'Curry', 'Lin', 'Yaoming'], 'age': [24, 23, 30, 7, 11], 'gender': ['man', '男人', '男人', '男人', '男人'], 'isAlive': [False, True, True, True, True] } df = pd.DataFrame(NBAStar) df.set_index('name', inplace=True) print(df)
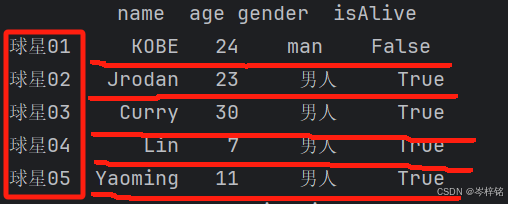
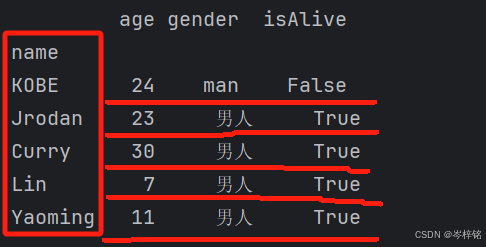
【自定义列名】
跟自定义行索引差不多,直接【df.columns = [ "自定义列名1","自定义列名2","自定义列名3"...... ]】
NBAStar = { 'name': ['KOBE', 'Jrodan', 'Curry', 'Lin', 'Yaoming'], 'age': [24, 23, 30, 7, 11], 'gender': ['man', '男人', '男人', '男人', '男人'], 'isAlive': [False, True, True, True, True] } df = pd.DataFrame(NBAStar) # 将列索引换成自定义的 df.columns = ['姓名', '年龄', '性别', '是否存活'] print(df)
;
或者用【df.rename(columns={'原列名': '新列名', '原列名':'新列名'...})】
NBAStar = { 'name': ['KOBE', 'Jrodan', 'Curry', 'Lin', 'Yaoming'], 'age': [24, 23, 30, 7, 11], 'gender': ['man', '男人', '男人', '男人', '男人'], 'isAlive': [False, True, True, True, True] } df = pd.DataFrame(NBAStar) # 用rename将列索引换成自定义的 df.rename(columns={'name': '姓名', 'age': '年龄', 'gender': '性别', 'isAlive': '是否存活'}, inplace=True) print(df)但是【df.rename(columns={'原列名': '新列名', '原列名':'新列名'...})】通常用于只修改某一个或某几个列名
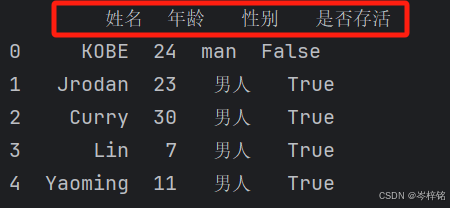
【dataframe数据转回字典】
NBAStar = { 'name': ['KOBE', 'Jrodan', 'Curry', 'Lin', 'Yaoming'], 'age': [24, 23, 30, 7, 11], 'gender': ['man', '男人', '男人', '男人', '男人'], 'isAlive': [False, True, True, True, True] } df = pd.DataFrame(NBAStar) # 用.to_dict()将【DataFrame】转回成【字典】 print(df.to_dict())

【获取数据值】
【获取1行或1列】:返回的数据值的数据类型就是【Series一维数组类型】
【获取1列】
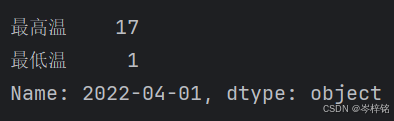
# 如果是获取1列数据 ——> 直接【df['键']】 print(df['name']) # 行索引 各列名 # ——> 0 KOBE # 1 Jrodan # 2 Curry # 3 Lin # 4 Yaoming # Name: name, dtype: object # 数据类型是Series数组 print(type(df['name'])) # ——> <class 'pandas.core.series.Series'>【获取1行】
# 获取行要多加个【loc】 # 如果是获取1行数据 ——> 【df.loc[数字索引]】 print(df.loc[0]) # 列名 这行各列的值 # ——> name KOBE # age 24 # gender man # isAlive False # Name: 0, dtype: object # 数据类型是Series数组 print(type(df.loc[0])) # ——> <class 'pandas.core.series.Series'>
【获取多行或多列】:返回的数据值的数据类型就是【Dataframe二维数组类型】
【获取多列】
# 如果是获取多列数据 ——> 直接【df[['键1','键2'...]]】 print(df[['name', 'age']]) # 行索引 name age # ——> 0 KOBE 24 # 1 Jrodan 23 # 2 Curry 30 # 3 Lin 7 # 4 Yaoming 11 # dtype: object # 数据类型是Dataframe二维数组(因为多行了嘛,就不能是一维了) print(type(df[['name', 'age']])) # ——> <class 'pandas.core.frame.DataFrame'>【获取多行】
# 如果是获取多行数据 ——> 【df.loc[数字索引1:数字索引2]】 # 利用切片索引的方式获取多行 print(df.loc[0:2]) # 行索引 name age gender isAlive # ——> 0 KOBE 24 man False # 1 Jrodan 23 男人 True # 2 Curry 30 男人 True # dtype: object # 注意:这里的数字索引2是取不到的,也就是取到数字索引1,取不到数字索引2 # 数据类型是Dataframe二维数组(因为多行了嘛,就不能是一维了) print(type(df.loc[0:2])) # ——> <class 'pandas.core.frame.DataFrame'>
总结:查找列直接[“列名”],查找行直接loc[“行索引”]
四、pandas查询数据5种方法
主要的三个方法:
- loc:按行、列的名称或标签来访问,且切片是按闭区间切片,也就是区间两边都能取到;
- iloc:按行、列的索引位置(从0开始)来访问,按传统的左闭右开的方式切片;
- ix:既可以按照名称或标签,也可以按照索引位置来访问dataframe。
【注】现在dataframe也可以不用加.loc或.iloc,直接用df[...]就可以访问数据,且和ix功能一致。但是,如果需要在原表上修改数据,则需要加上.loc方法,因为.loc既可以查询,还可以覆盖写入。
这里我提供一个用于我后面例子讲解的一个【2022年4月份天气数据】csv文件:
链接: 百度网盘 请输入提取码 提取码: wwdm 复制这段内容后打开百度网盘手机App,操作更方便哦
;
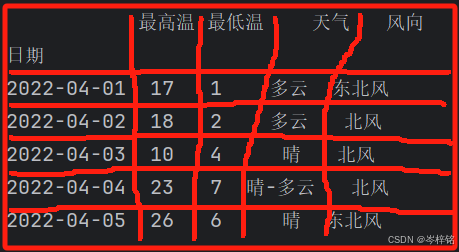
拿到文件之后保存在本地一个位置,然后先写好下面这段代码,简单初始一下数据的格式:
import pandas as pd df = pd.read_csv("[你自己放这个csv文件的绝对路径]",header=0) # 注意路径里的【\】换成【\\】 df.set_index('日期',inplace=True) print(df.head(), end="\n\n") df.loc[:, "最高温"] = df["最高温"].str.replace("°C", "").astype('int32') #将最高气温列中的℃去掉 df.loc[:, "最低温"] = df["最低温"].str.replace("°C", "").astype('int32') #将最低气温列中的℃去掉 print(df.head(), end="\n\n")最终变成这样的一个表格数据(以日期为每一行行索引,气温的数值去掉 “°C” )
1、【loc[ ]】查询(常用)
总结就是:【df[ 行区间, 列区间 ]】
【查多行数据(按行区间查)】
df.loc["2022-04-01":"2022-4-5", "最高温"]
;
【查多列数据(按列区间查)】
df.loc["2022-04-01", "最高温":"最低温"]
;
【查多行多列(行列都按区间查)】
df.loc["2022-04-01":"2022-04-05", "最高温":"天气"]
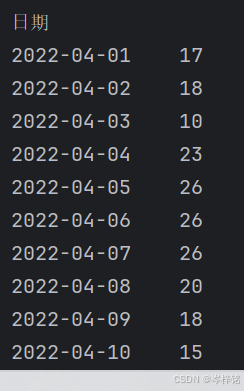
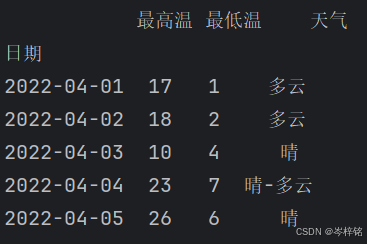
【条件查询】
【简单查询】,就是df.loc[ ]里面的左边 “行区间” 用【df["列名"]的条件】,右边就是列区间
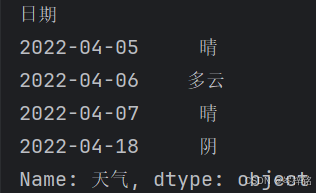
df.loc[df["最高温"] > 25, "天气"]
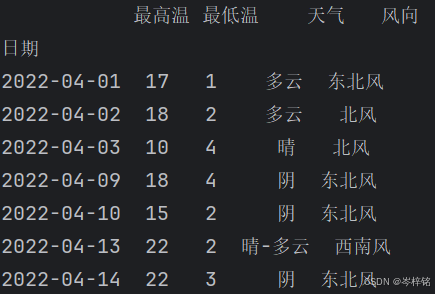
df.loc[df["最低温"] < 6, : ]
【复杂查询】
多个条件查询
df.loc[(df["最高温"] < 25) & (df["最低温"] > 11) & (df["天气"]=="晴"), :]
还可以写个函数来作为【行索引区间】
注意,这里【行索引区间】那里都不用传参,因为并不是调用函数,因为本身这里函数本身可以当成变量,被传来传去
def goodWeather(df): return (df["最高温"] < 25) & (df["最低温"] > 11) print( df.loc[goodWeather, :])
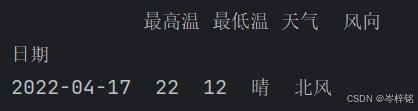
def goodWeather2(df): # df.index.str.startswith("2022-04")这是检查DataFrame的索引是否以"2022-04"开头 # str属性用于访问Series中的字符串数据 # startswith方法用于检查字符串是否以指定的前缀开头 return df.index.str.startswith("2022-04") & (df["天气"] == "晴") print( df.loc[goodWeather2, :] )

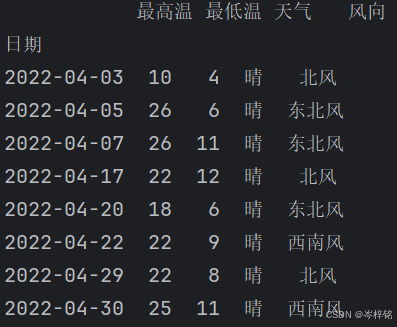
五、pandas新增列
4种新增列方式
1、直接两列加减乘除生成一个新列
df['温差'] = df['最高温'] - df['最低温']
print(df.head())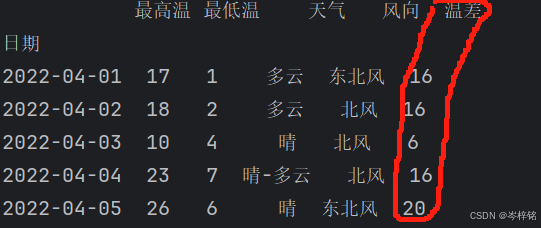
# 或者用df.loc[]查询的时候直接添加新列
df.loc[:, "平均温"] = (df['最高温'] + df['最低温']) / 2
print(df.head())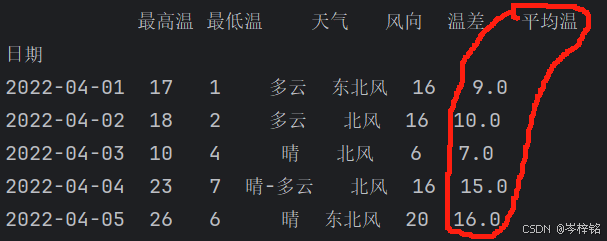
2、.apply方法
它需要传入一个函数,这个函数可以处理逻辑操作
def getWenduType(x):
if x["最高温"] > 30:
return "高温"
if x["最低温"] < 3:
return "低温"
return "适宜"
# 注意要设置axis=1,指定这个方法执行的是【列】
df.loc[:, "温度类型"] = df.apply(getWenduType, axis=1)
print(df.head())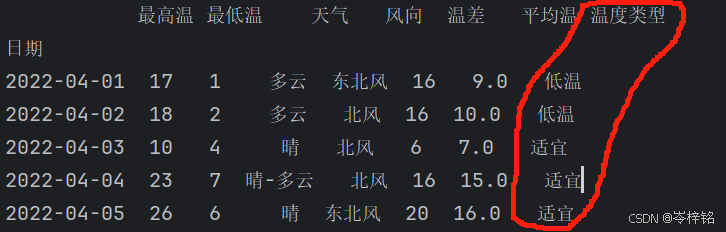
3、.assign方法
它支持同时添加多个新列
它不会改变原数组,而是会返回一个新数组
newDf = df.assign(
最高温华氏温度 = lambda x : x["最高温"] * 1.8 + 32,
最低温华氏温度 = lambda x : x["最高温"] * 1.8 + 32
)
print(newDf.head())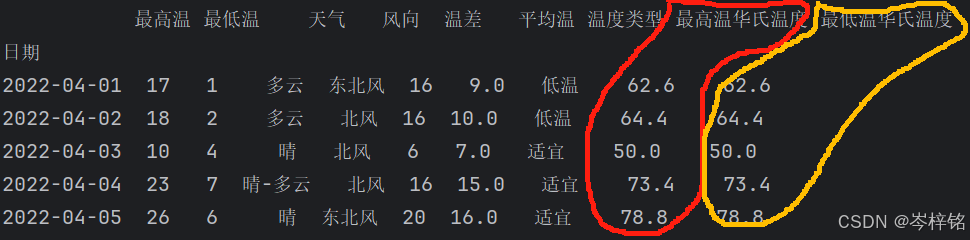
4、按条件选择分组
df.loc[条件, 列名]
先按条件选择数据,然后对这部分数据赋值新列
# 先创建一个空列
df["温差类型"] = ''
df.loc[df["温差"] > 10, "温差类型"] = "温差大"
df.loc[df["温差"] <= 10, "温差类型"] = "温差小"
print(df.head())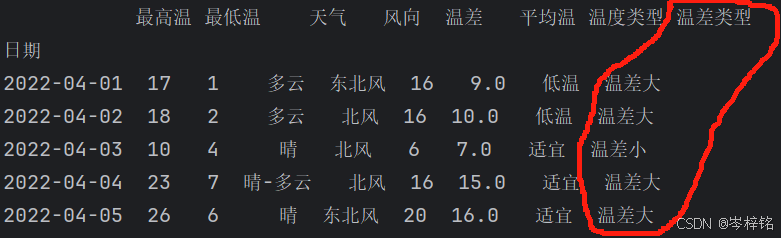
六、pandas统计方法
1、汇总类统计
直接统计各列的最大值、最小值、平均值、唯一值.......
df.describe()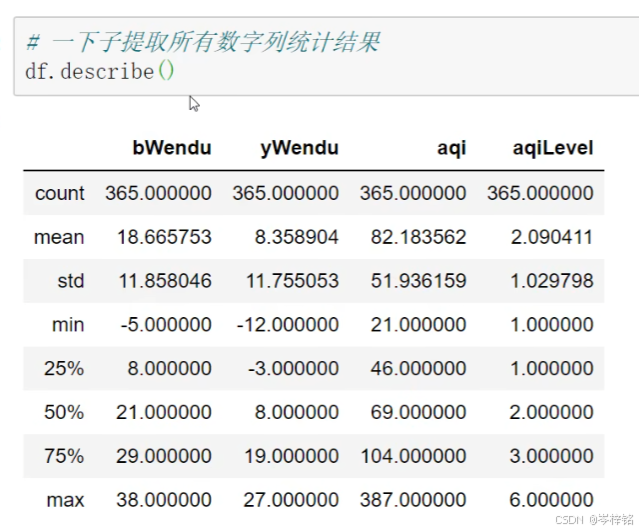
可以单独对某一列来统计
print(df['最高温'].max()) # 最高温的最大值
print(df['最高温'].min()) # 最高温的最小值
print(df['最高温'].mean()) # 最高温的平均值
print(df['最高温'].median()) # 最高温的中位数
print(df['最高温'].mode()) # 最高温的众数
print(df['最高温'].std()) # 最高温的标准差
print(df['最高温'].var()) # 最高温的方差2、唯一去重和按值计数
唯一去重,跟numpy的【unique】一样的
df["天气"].unique()
按值计数【value_counts】
df["最高温"].value_counts()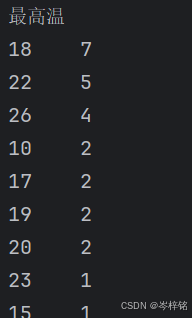
3、协方差和相关系数(有用,会用到)
这个虽然是数学相关的东西,我们可能会以为跟我们没有太大直接关系,但是很有用,比如:
1、看两只股票,是不是同涨同跌?程度涨跌幅多大?是否正负相关?
2、产品销量的波动跟哪些因素正相关、负相关,程度多大?
这是跟数学有关的内容,这里我们不需要深究具体的原理,如果有兴趣的可以去下面链接自行查看,讲的还挺好的:
相关系数: 相关系数_百度百科
在做这些前,因为协方差、相关系数要求表格中都是数值才方便统计,那要做些处理把我们的“晴”、“东南风” 这些字符串数据处理成数字先,复制我的下面这段代码
import pandas as pd
df = pd.read_csv("F:\\MyPythonProject\\pythonProject\\爽爽爬虫\\天气\\2022-4.csv",header=0)
df.set_index('日期',inplace=True)
df.loc[:, "最高温"] = df["最高温"].str.replace("°C", "").astype('int32') #将最高气温列中的℃去掉
df.loc[:, "最低温"] = df["最低温"].str.replace("°C", "").astype('int32') #将最低气温列中的℃去掉
# 因为数据框 df 中包含字符串类型的列(例如 "多云"),而 cov 方法期望所有数据都是数值类型。
# 处理天气列,将其转换为数值类型
# 这里假设 "多云" 可以用 0 表示,其他天气可以用 1 表示,可以根据实际情况调整
weather_mapping = {'多云': 0, '晴': 1, '阴': 2, '小雨': 3, '中雨': 4, '大雨': 5, '暴雨': 6}
df["天气"] = df["天气"].map(weather_mapping)
# 处理风向列,将其转换为数值类型
# 这里假设 "东北风" 可以用 0 表示,其他风向可以用 1 表示,可以根据实际情况调整
wind_mapping = {'东北风': 0, '东风': 1, '东南风': 2, '南风': 3, '西南风': 4, '西风': 5, '西北风': 6, '北风': 7}
df["风向"] = df["风向"].map(wind_mapping)【协方差】
协方差:简单一句人话就是【看xy这两个变量变化的同向、反向的程度】,xy代表两种数学期望
协方差为正,说明xy变量同向变化,越大说明通向程度越高;协方差为负,说明xy变量反向变化,越大说明反向程度越大。
df.cov()
也可以单独对比两个变量(两列)的协方差:
df["最高温"].cov(df["最低温"])
【相关系数】
;
相关系数:简单一句人话就是【看两个变量变化的相似程度】,相关系数是用以反映变量之间相关关系密切程度的统计指
相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;当他们相关系数为1时,说明正向相似度最大;为-1时,说明反向相似度最大
df.corr()
df["最高温"].corr(df["最低温"])# 看一下【温差】跟【天气】相关程度
df["天气"].corr(df["最高温"] - df["最低温"])(不是很接近1是因为数据是我乱写的,不是真的天气数据......不要怀疑这个pandas)
七、数据表清洗
这里需要用到一个新的文件作为我下面的例子,可以自行到这提取:
链接: 百度网盘 请输入提取码 提取码: i8us 复制这段内容后打开百度网盘手机App,操作更方便哦
前面我们学了读取csv、excel文件,但是要知道那是我们精心写好格式的文件,直接读取就会得到我们要的完整数据表格,但是如果用我上面提供这种文件就不行了。
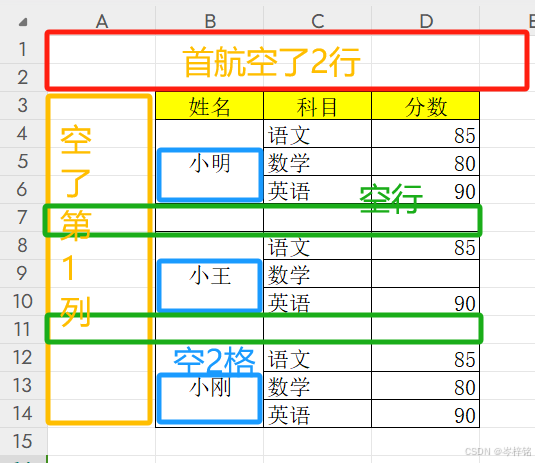
像这个文件,人为写入的,有大量的空行、空列、合并单元格,这样的格式在读取的时候是不能自动对应读出一个完整表格的
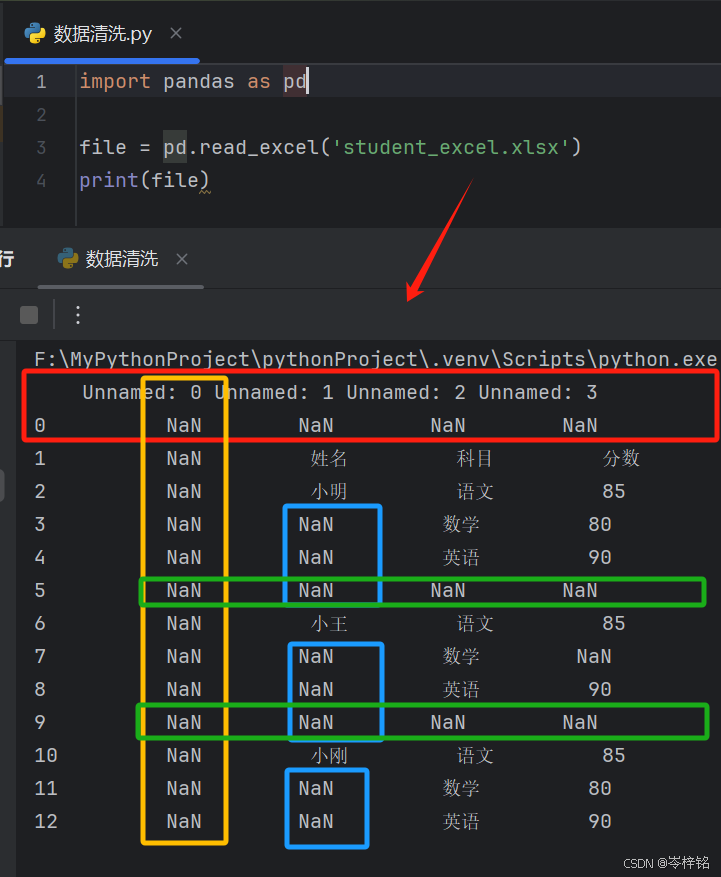
1)读取表格处理空首行
前面空行的,在读取时直接用【skiprows】参数可以设置跳过空的首行
import pandas as pd
# skiprows=? 空几行就写几
file = pd.read_excel('student_excel.xlsx', skiprows=2)
print(file)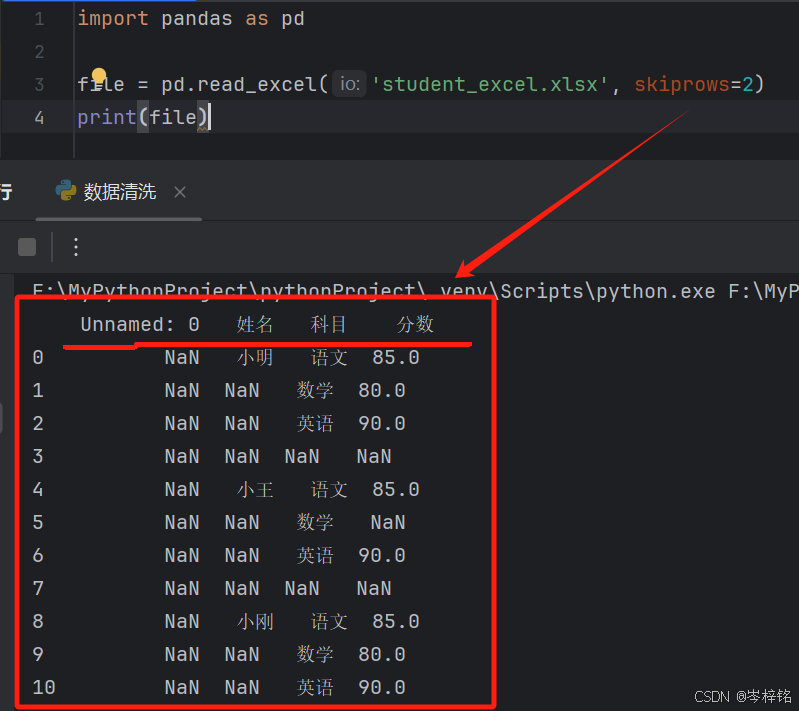
2)处理前的查看
在处理前我们可以用一些方法看一下是哪些地方空着、或者哪里没空着
【.isnull( )】:看整个表哪里是空值
print(file.isnull()) # 查看每列缺失值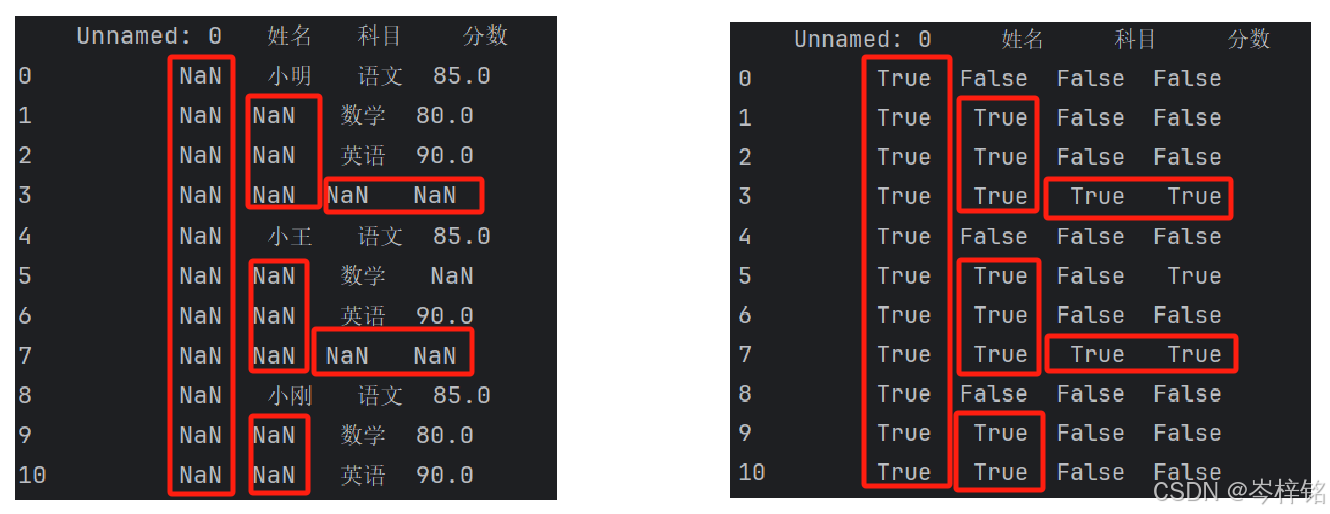
【.notnull( )】:看整个表哪里是非空值
print(file.notnull()) # 查看每列非缺失值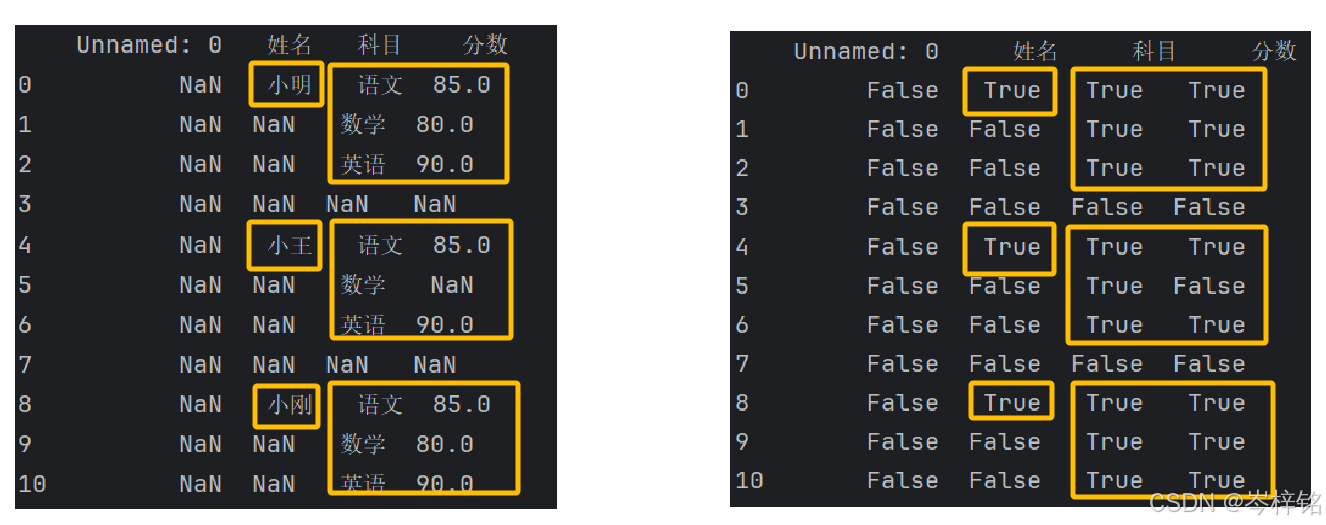
【数组[“某一列”].notnull( )】:看某一列的非空值
print(file["分数"].notnull()) # 查看某列非缺失值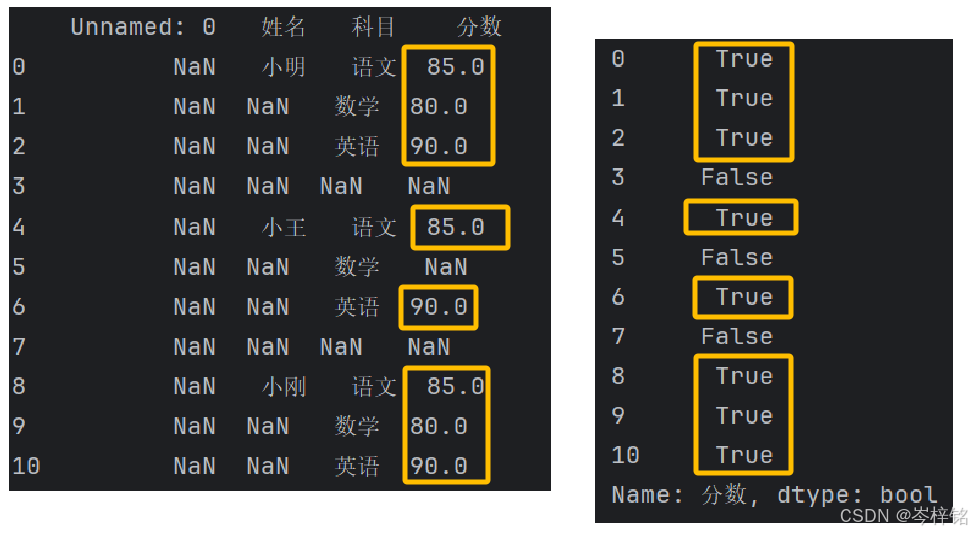
3)【drpna】删无用行跟列
【删空列】
# 这三个参数,第一个是指定删的的是【列】,第二个参数是怎么删(all就是代表【全部空值】),第三个参数是是否修改原来数据表
file.dropna(axis="columns", how="all", inplace=True) # 删除所有缺失值的列
print(file)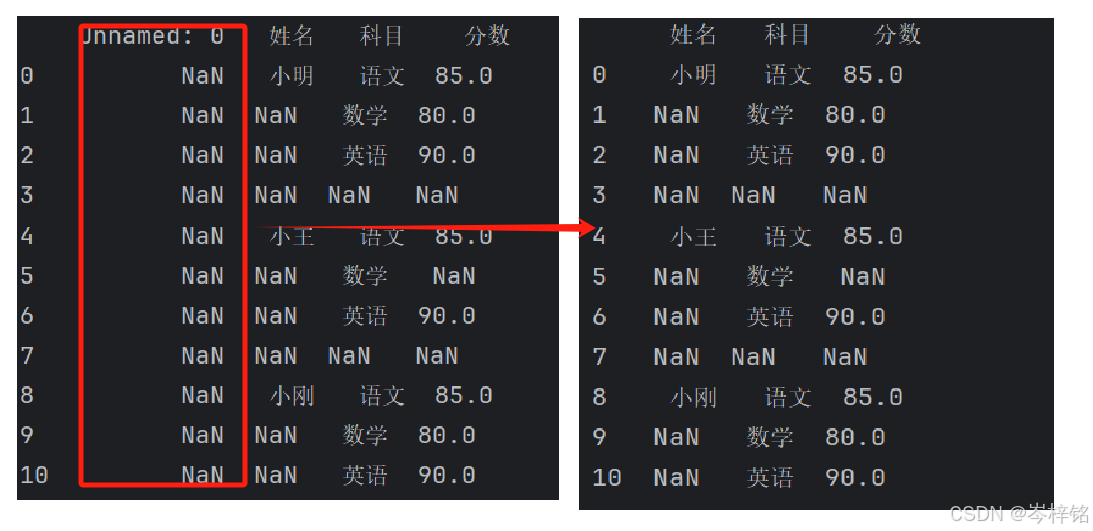
【删空行】
file.dropna(axis="index", how="all", inplace=True) # 删除所有缺失值的行
print(file)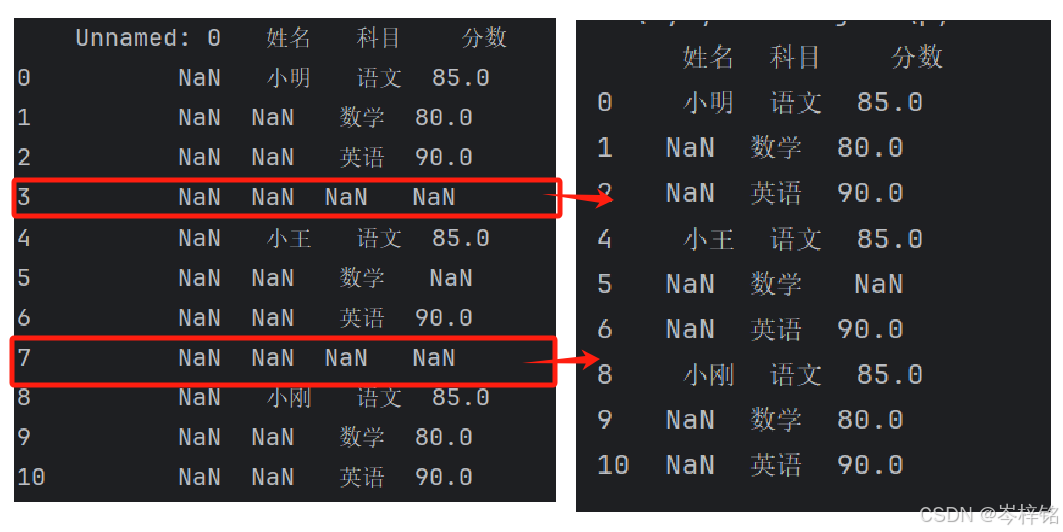
4)覆盖空值写入
覆盖写入【指定列】的【指定值】,2种方法一样的
# 第一种方法:直接以字典的形式传入【数据表.fillna( { "列名": 指定的值 } )】 file.fillna({"分数": 0}, inplace=True) print(file) # 第二种方法:以【数据表.loc[:, "列名"] = 数据表["列名"].fillna(指定值)】的形式传入 file.loc[:, "分数"] = file["分数"].fillna(0) print(file)
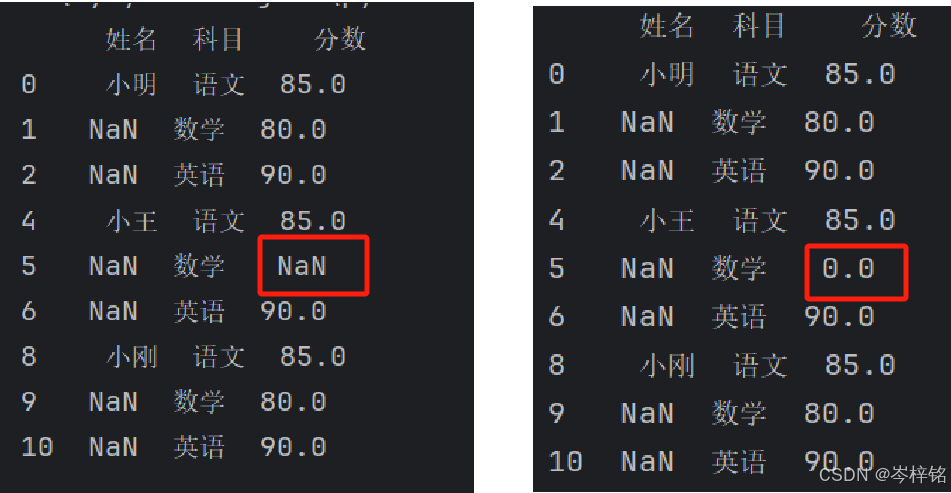
直接用数据表的列前的有效值覆盖写入
【老方法】
之前pandas的老方法是:
用列前面的值覆盖新值是【数据表.loc[:, "列名"] = 数据表["列名"].fillna(method="ffill")】
用列后面覆盖新值是【数据表.loc[:, "列名"] = 数据表["列名"].fillna(method="bfill")】
# 直接用数据表的列前或者后面的有效值覆盖写入 # 前面值覆盖后面 file.loc[:, "姓名"] = file["姓名"].fillna(method="ffill") print(file) # 后面值覆盖前面 # file.loc[:, "姓名"] = file["姓名"].fillna(method="bfill") # print(file)
但是未来这种方式可能即将被取消,取而代之的【新写法】
用列前面的值覆盖新值是【数据表.loc[:, "列名"] = 数据表["列名"].fillna(method="ffill")】
用列后面覆盖新值是【数据表.loc[:, "列名"] = 数据表["列名"].fillna(method="bfill")】
# 前面值覆盖后面
file.loc[:, "姓名"] = file["姓名"].ffill()
print(file)
# 后面值覆盖前面
file.loc[:, "姓名"] = file["姓名"].bfill()
print(file)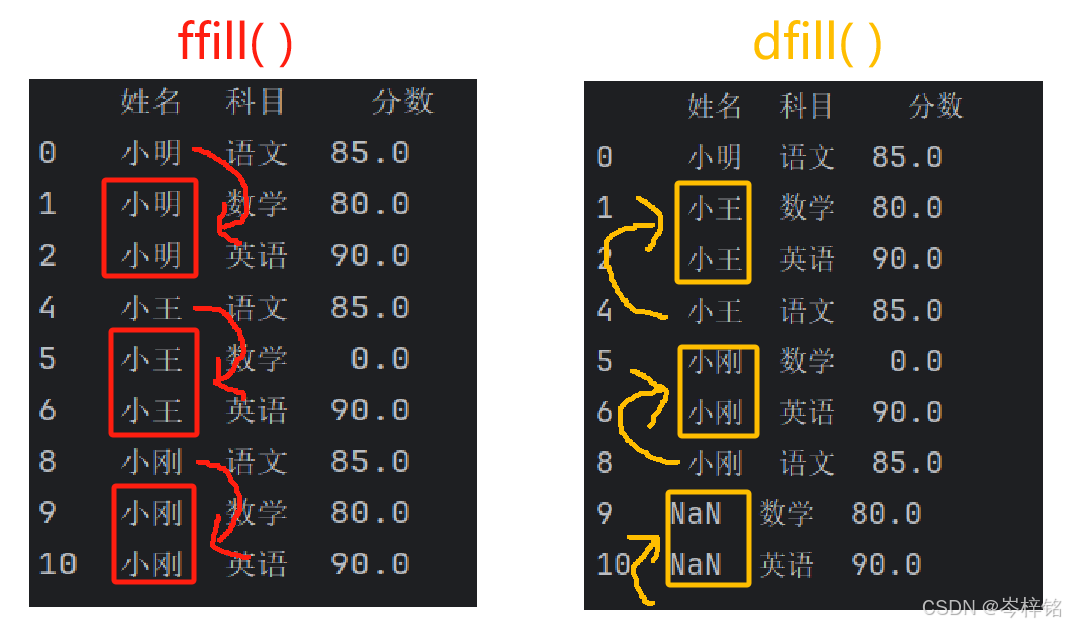
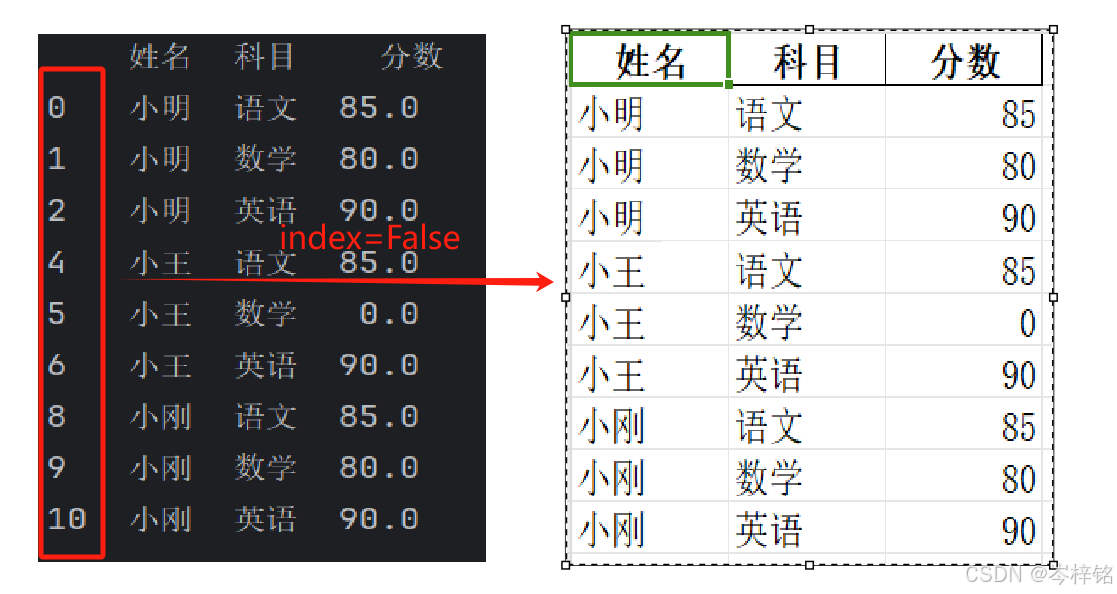
最后将清洗的数据重新写入新excel表,index=False这个参数可以不写入行索引到文件中
# index= False,可以不写入行索引 file.to_excel("student_excel_clean.xlsx", index=False)
八、数据表排序
1、serices列排序
【升序】:【 数据表["列名"].sort_values( ) 】
# 升序排序
df["最高温"].sort_values()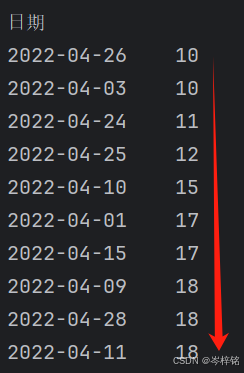
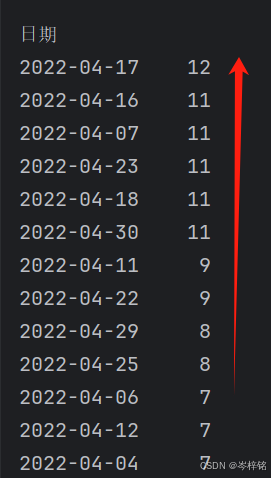
【降序】:【 数据表["列名"].sort_values( ascending=False ) 】
# 降序排序
df["最低温"].sort_values(ascending=False)
2、dataframe表排序
【整个表按某一单列升序】
# 整个表按某一列升序排序
df.sort_values(by="最高温")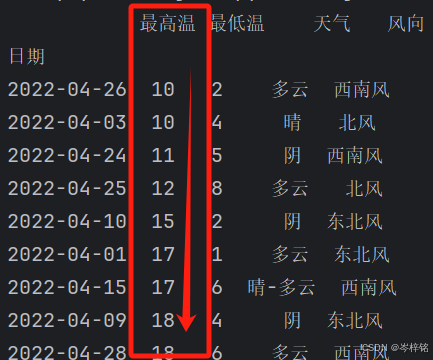
【整个表按某一单列降序】
# 整个表按某一列降序排序
df.sort_values(by="最高温",ascending=False)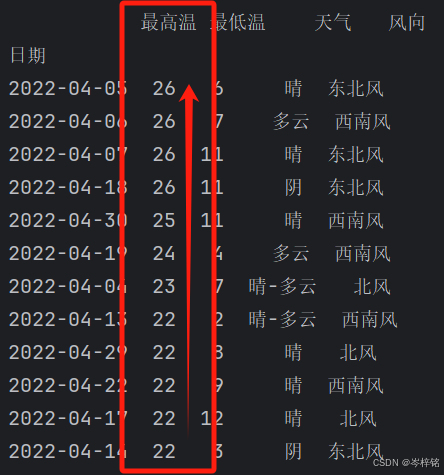
【整个表按某多单列升序】
# 整个表按两列排序
df.sort_values(by=["最高温","最低温"])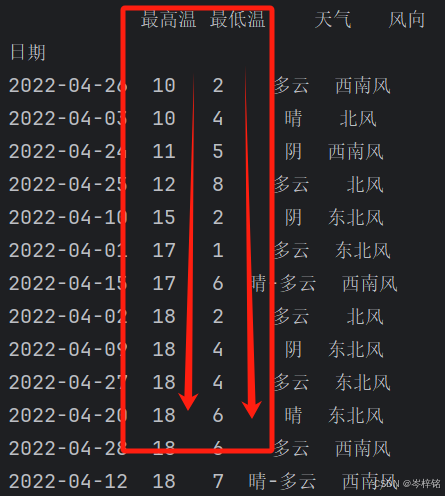
【整个表按某多单列,并指定是升序还是降序】
# 整个表按两列排序,第一列降序,第二列升序
df.sort_values(by=["最高温","最低温"],ascending=[False,True])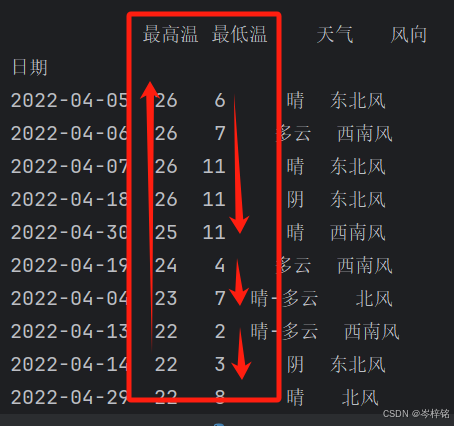
九、实现数据合并
这里我直接把文件放到这里,别去别的地方查,别的地方要收费,别让csdn赚这钱:
链接: 百度网盘 请输入提取码 提取码: w7ja 复制这段内容后打开百度网盘手机App,操作更方便哦
1、merge合并
1、读取多个文件
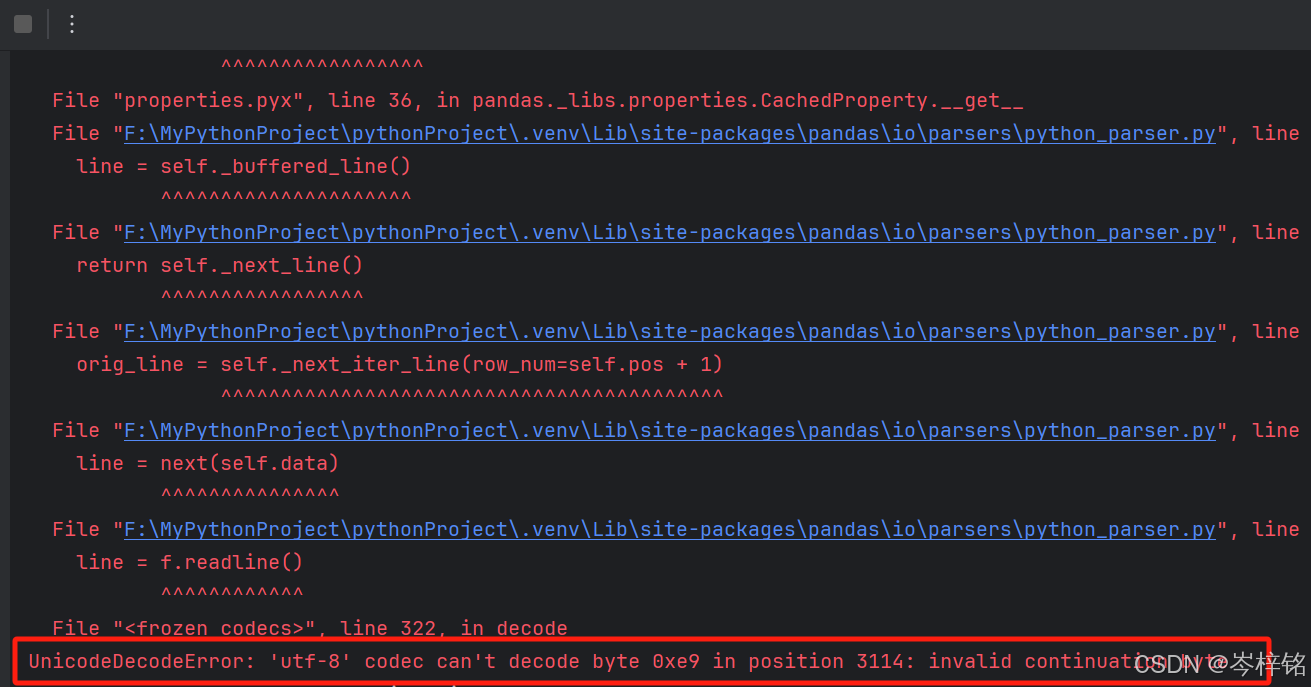
另外这里有一个问题,文件下载好之后,里面的movies.dat这个文件其实并没有按照正常的【UTF-8】格式保存,所以编译读取的时候会报错:
;
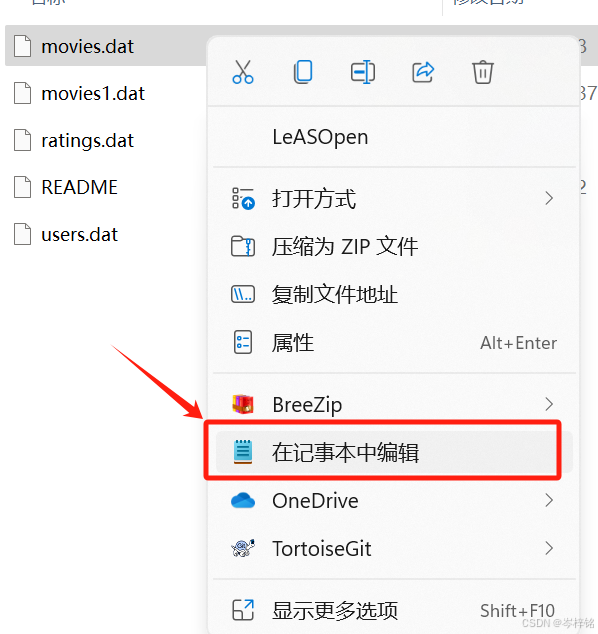
那么遇到【UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 3114: invalid continuation byte】问题我们只能修改源文件,右键用记事本编辑;然后另存为新的一个文件
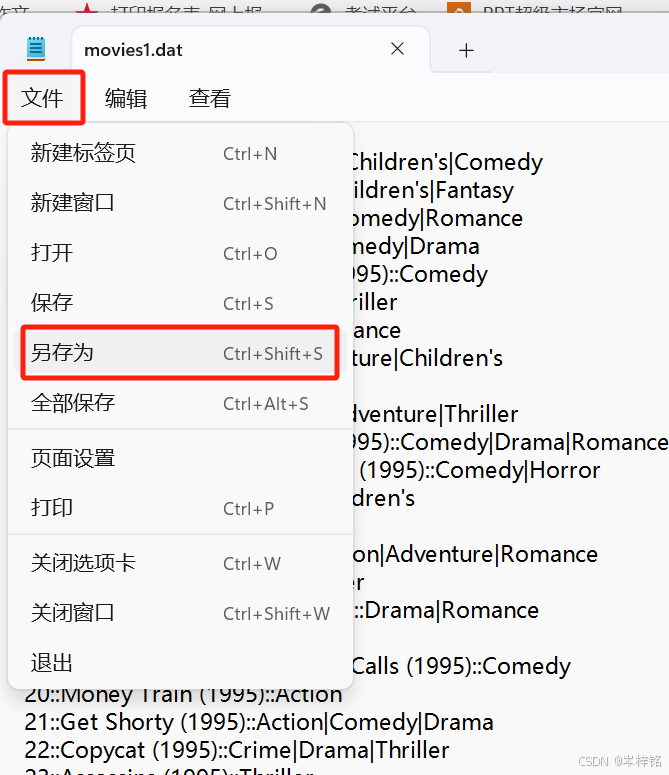
;
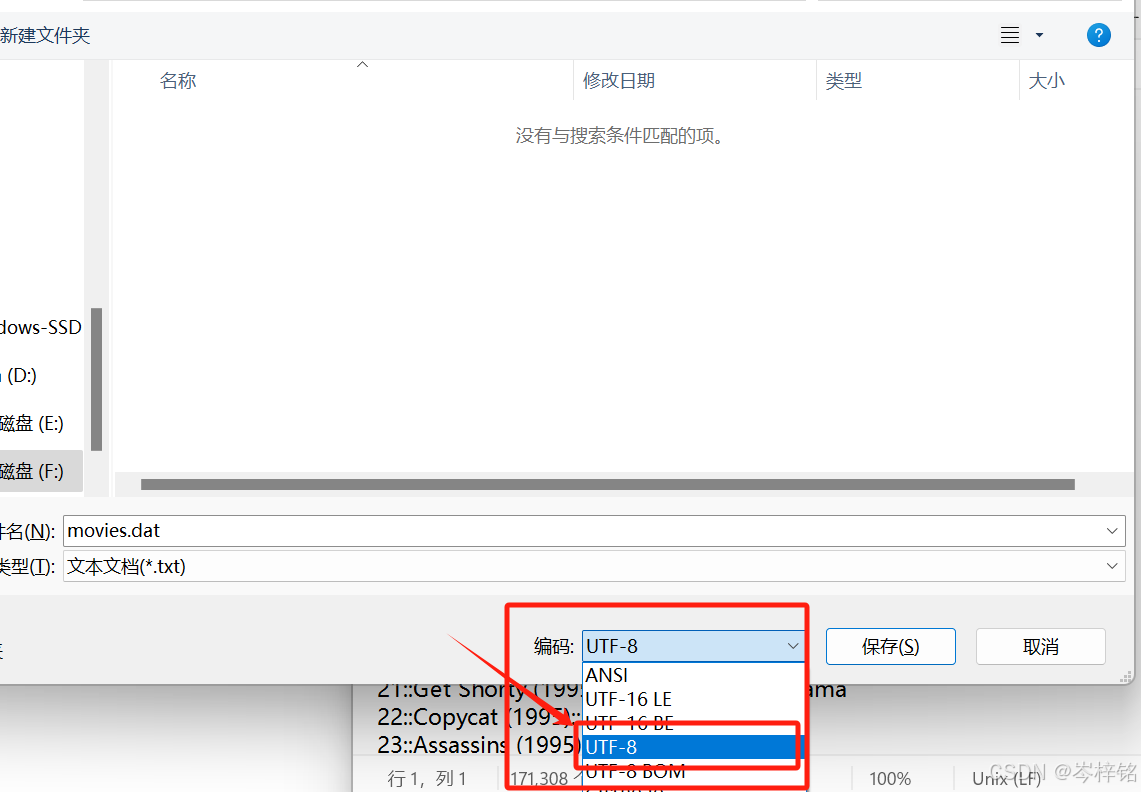
然后保存的时候找到底下的【编码】,选择【UTF-8】,其他不管默认保存就行,然后就可以正常读取了
然后我们开始读取部分的代码,回顾第二大点知识,这些dat文件依然正常用【read_csv( )】读取,但是要别忘了配置参数:
观察文本内容可以发现,不同内容之间是用 “ :: ” 分隔开的,而且没有写明列名是什么,那么我们只需要
1、以 “ :: ” 为分隔符划分每一行的数据:【sep: "::"】
2、设置每一种数据对应的列名:
第一种【names = ["列名1", "列名2", "列名3"......]】
第二种【names = "列名1::列名2::列名3......".split('::')】
(这是根据文中分隔符来对应配对列名)
3、别忘了【engine='python'】
import pandas as pd
df_ratings = pd.read_csv(
# 自己改一下路径
'F:\\编程学习资料\\大数据\\电影数据集\\ml-1m\\ratings.dat',
sep='::',
engine='python',
names="UserID::MovieID::Rating::Timestamp".split('::')
)
print(df_ratings.head())
df_users = pd.read_csv(
# 自己改一下路径
'F:\\编程学习资料\\大数据\\电影数据集\\ml-1m\\users.dat',
sep='::',
engine='python',
names="UserID::Gender::Age::Occupation::Zip-code".split('::')
)
print(df_users.head())
df_movies = pd.read_csv(
# 自己改一下路径
'F:\\编程学习资料\\大数据\\电影数据集\\ml-1m\\movies1.dat',
sep='::',
engine='python',
names="MovieID::Title::Genres".split('::'),
encoding='utf-8'
)
print(df_movies.head())2、merge合并结构类似的表
这里合并数据表要涉及到数据库的知识了,学没学过数据库的都可以复习了解一下
1)同字段列名结构下的两表合并
merge简单就4种合并:【inner】、【left】、【right】、【outer】
写法就是:【新合并表】=【pd.merge( 表1(默认就是左表), 表2, how="4种合并的其中一种" )】
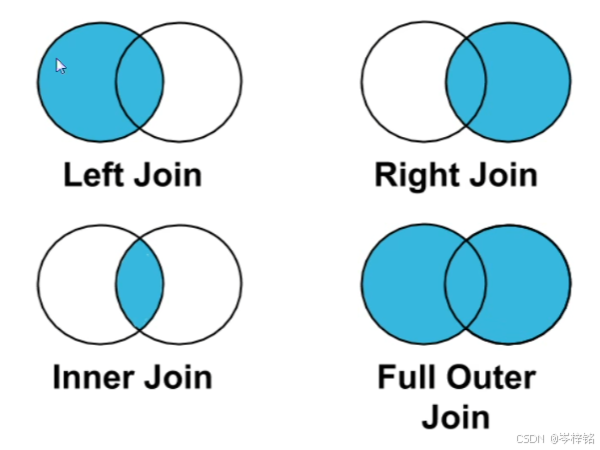
【inner】:就是交集,两表都有的部分显示
(merge合并如果不设置是什么合并方式,就默认就是inner)
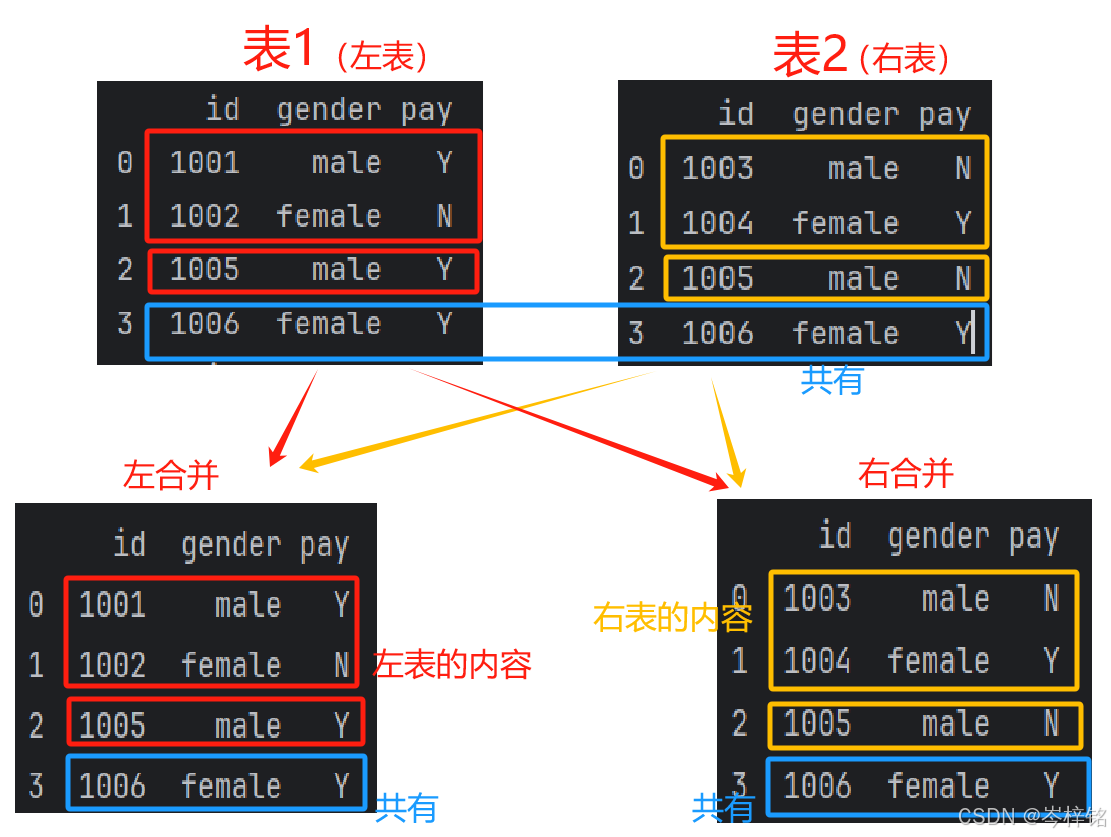
【left】:显示左表的所有内容,左表里没有右表的共同内容部分不显示
【right】:显示右表的所有内容,右表里没有左表的共同内容部分不显示
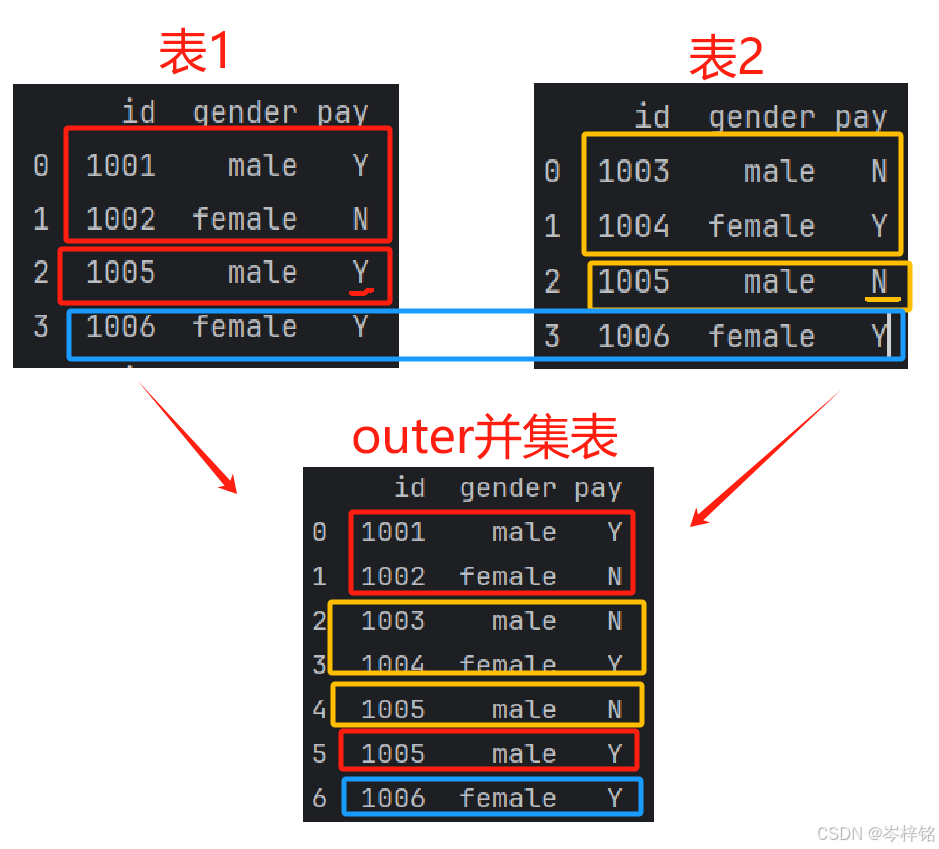
【outer】:就是并集,两表的所有内容显示
比如创建两个结构一样、内容不一样的表
import pandas as pd df1 = pd.DataFrame({ "id":[1001,1002,1005,1006], "gender":['male','female','male','female'], "pay":['Y','N','Y','Y'], }) df2 = pd.DataFrame({ "id":[1003,1004,1005,1006], "gender":['male','female','male','female'], "pay":['N','Y','N','Y',], })
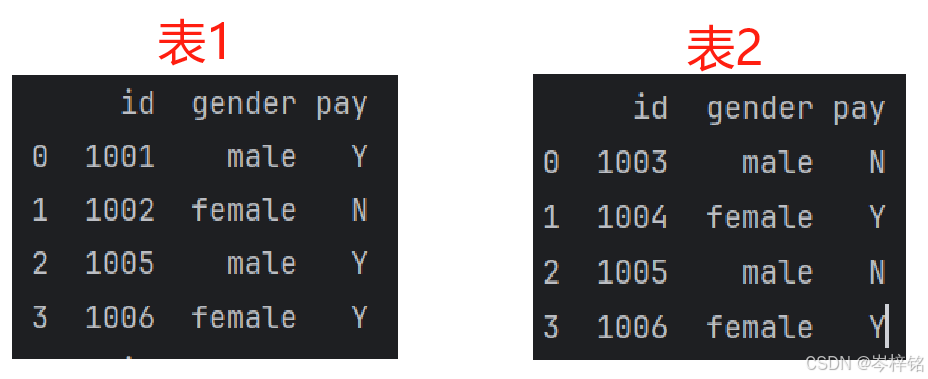
然后我们试一下
【inner】:
# 其实默认就是inner df1_df2 = pd.merge(df1,df2) # inner是两表交集,不管写参数时两个表谁在前谁在后,都是一样结果 df1_df2_inner = pd.merge(df1,df2,how='inner') df2_df1_inner = pd.merge(df2,df1,how='inner')

【outer】:
# inner是两表并集,不管写参数时两个表谁在前谁在后,都是一样结果 df1_df2_outer = pd.merge(df1,df2,how='outer') df2_df1_outer = pd.merge(df2,df1,how='outer')
【left】和【right】:
# 左右合并要注意两个表参数的前后顺序了 # 左合并 df1_df2_left = pd.merge(df1,df2,how='left') # 等于pd.merge(df2,df1,how='right') df2_df1_left = pd.merge(df2,df1,how='left') # 等于pd.merge(df1,df2,how='right') # 右合并 df1_df2_right = pd.merge(df1,df2,how='right') # 等于pd.merge(df2,df1,how='left') df2_df1_right = pd.merge(df2,df1,how='right') # 等于pd.merge(df1,df2,how='left')
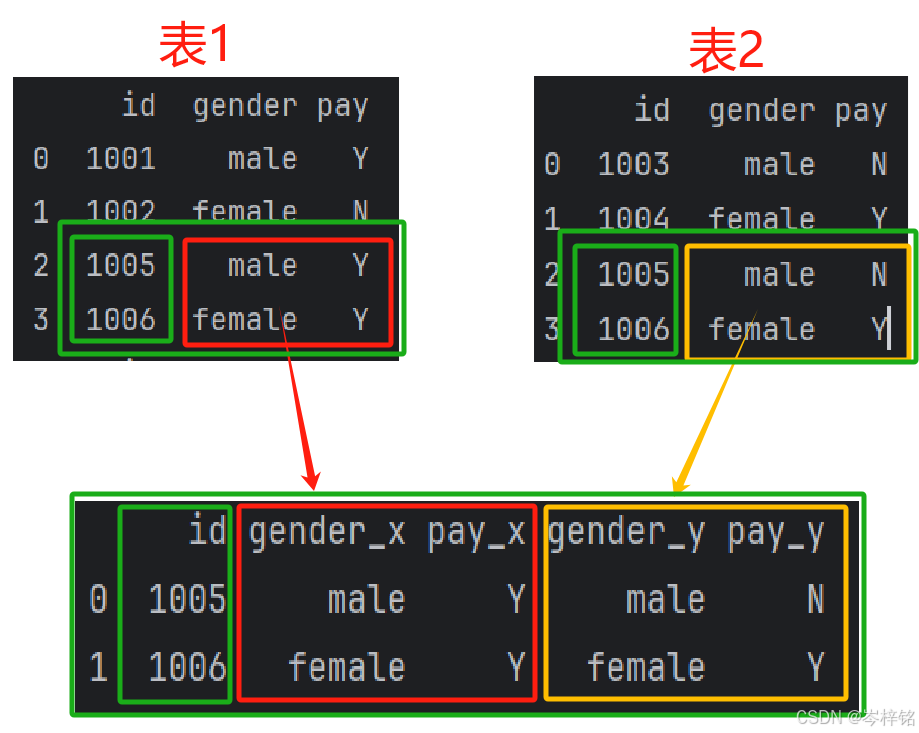
如果加上【on="列名"】可以根据两个表共同的这个“列名”来合并表,这样就是将这个“列名”作为一个【键】(其实相当于inner表)
但是因为两个表的这个【键】对应的两个表,可能会有相同重名的“列名”。
那么merge就会标明“哪个列名” 是属于 “哪个表的”
df1_df2 = pd.merge(df1,df2, on='id') print(df1_df2)
那如果看那个【_x】【_y】不爽的话,也可也改成自己想要的
df1_df2 = pd.merge(df1,df2,on='id', suffixes=['_左','_右']) print(df1_df2)
;
那么指定【on="列名"】并且【inner合并】的这种方式通常要用于【一对多】关系
这里【一对多】、【一对一】、【多对多】我就不再过多阐述

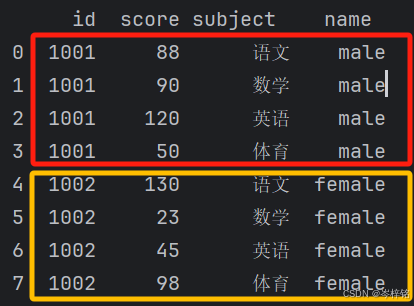
2)同字段列名结构下的两表合并
前面举的例子是同结构的,那一开始我让各位下载的那三个大数据表就是不同结构的,只有部分列名相同
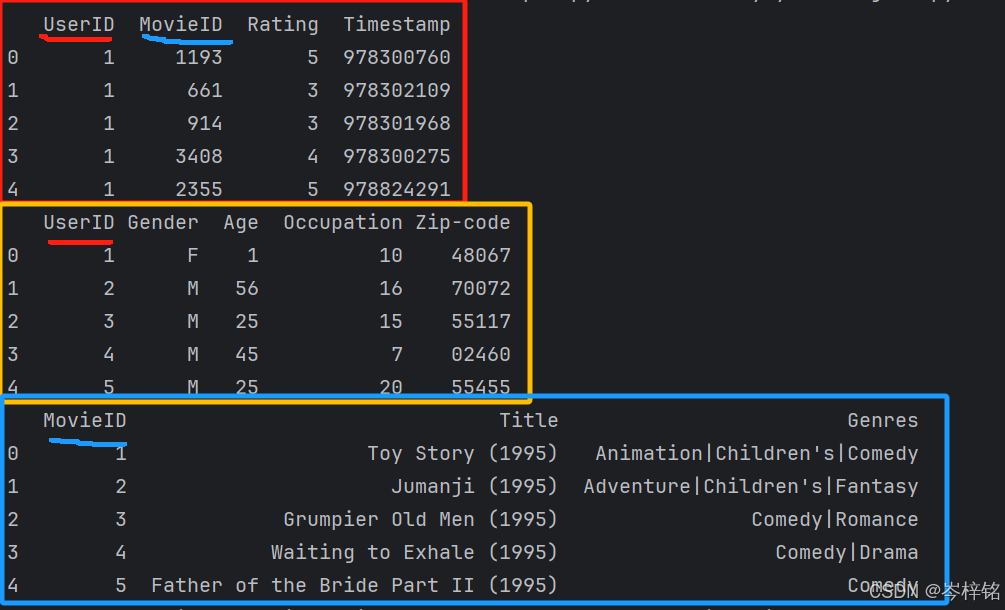
那么两个表之间要根据【共有的“列名”】进行合并,而且要分别指定是哪个【“列名”】
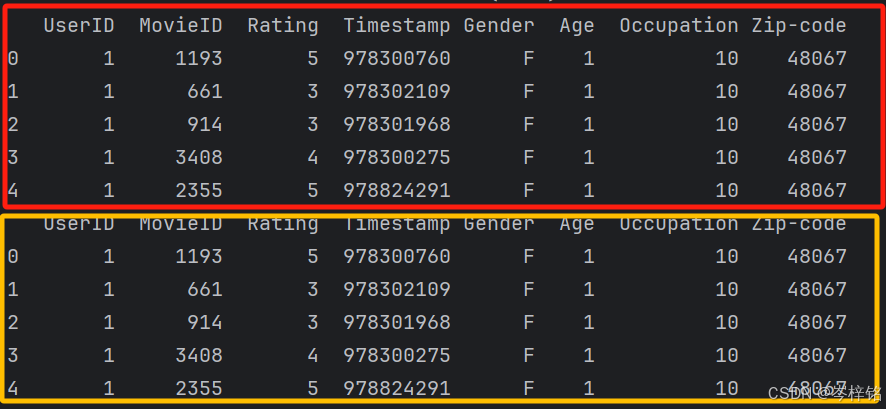
df_ratings_users = pd.merge(
df_ratings,
df_users,
left_on='UserID',
right_on='UserID',
how='inner'
)
df_ratings_users_movies = pd.merge(
df_ratings_users,
df_movies,
left_on='MovieID',
right_on='MovieID',
how='inner'
)
2、concat合并
这个方法可以用来合并一行或多行、一列或多列·
首先我们创建两个不同列的dataframe
import pandas as pd # df1和df2的第3列是不一样的 df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'], 'C': ['C0', 'C1', 'C2', 'C3'] }) df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'], 'B': ['B4', 'B5', 'B6', 'B7'], 'D': ['C4', 'C5', 'C6', 'C7'] })
然后先使用默认的concat合并:默认参数【axis=0、join=outer、ignore_index=False】
# 先使用默认concat:axis=0、join=outer、ignore_index=False df1_df2 = pd.concat([df1, df2]) print(df1_df2)

然后试一下:【ignore_index=True, join='inner'】
df1_df2 = pd.concat([df1, df2], ignore_index=True, join='inner') print(df1_df2)

【添加列】
那么当设置【axis=1】时,就可以添加列了
# 添加一列
s1 = pd.Series(['foo', 'bar', 'baz', 'qux'], name='X')
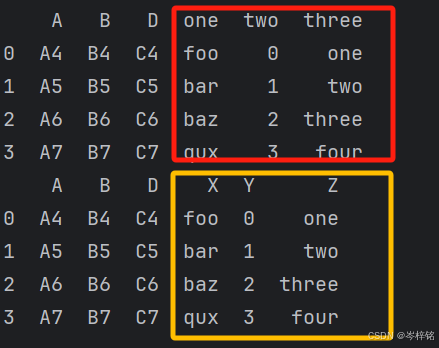
print(pd.concat([df1, s1], axis=1))
# 添加多列
s2 = pd.Series(list(range(4)), name='Y')
s3 = pd.Series(['one', 'two', 'three', 'four'], name='Z')
# 加上key可以指定这三列在合并表中的新列名
S = pd.concat([s1, s2, s3], axis=1, keys=['one', 'two', 'three'])
print(pd.concat([df2, S], axis=1))
# 或者直接混合
print(pd.concat([df2, s1, s2, s3], axis=1))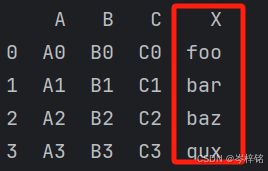
暂时先这么多,后面再补充......
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python数据分析——pandas

发表评论 取消回复