linux之文件(上)
一.文件的预备知识
在我们刚刚开始学习linux时反复提及到一件事:万物皆文件,而文件=属性+内容。
那么我们对文件进行操作的本质就是对内容或者属性进行操作,而属性和内容的本质其实都是数据,所以我们存储文件时既要存储属性又要存储内容,当我们创建一个文件时默认是存储在磁盘中的。
那么我们想要访问一个在磁盘中的文件时是不是需要先将文件打开,在我们之前学习冯诺依曼体系的时候我们了解过用户是无法直接访问硬件的那么我们是否就无法访问在磁盘中的文件,所以打开一个文件的操作就是将磁盘中的文件加载到内存中来让我们用户进行访问。
所以文件就可以区分为打开前的文件和打开后的文件
打开前的文件:普通的磁盘文件
打开后的文件:加载到内存中的文件
同时我们在关注文件的时候还有注意一个东西就是我们想要访问一个磁盘中的文件中的我们是什么??
这个我们难道指的是我们用户吗?是我们用户打开了这个文件吗?不!这个我们指的是进程,我们只是调用了接口来让进程打开文件而已!
在了解了是进程打开文件后我们会产生两个问题:
- 一个进程可以打开多个文件吗?
- 多个进程可以打开多个文件吗?
问题的答案其实很好确定但是答案延申出来的知识就需要我们琢磨一下了
答案其实很简单无论是问题1还是问题2,答案都是可以的,因为进程打开文件的操作肯定是通过操作系统的。
为什么呢?我们思考一下:没有打开的文件是存储在磁盘中的而磁盘是硬件设备,我们用户又是无法访问硬件设备的那么想要将磁盘中的文件加载到内存中是不是就需要操作系统来做了。
那么操作系统是如何让进程打开文件的呢,答案就是提供系统接口。
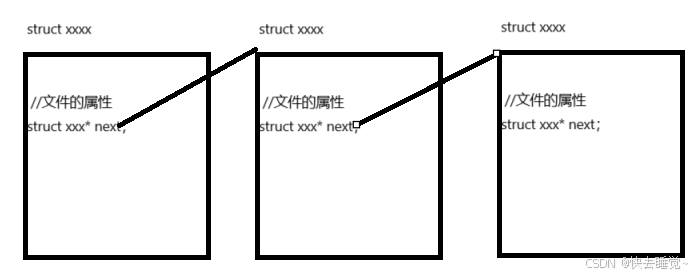
同时在了解了内存中被打开的文件是可以存在多个的,那么操作系统是否需要管理这些文件。那么该怎么管理这些文件:先描述,再组织。我们知道文件是由内容和属性组成的那么我们是否可以在一个文件被打开之前在内核中创建一个属于文件的结构体来存储文件的属性同时在这个结构体中我们还需要存储一个指针来指向下一个文件从而使得这些被打开的文件组成一张链表来方便管理就如同进程的pcb。
那么这次我们关于文件的预备知识就说完了,同时我要告诉大家的是这次我们研究的主要就是进程和被打开文件的关系
二.C语言的文件接口和linux的系统接口
在学习linux中关于文件接口函数前我们先复习一下C语言中我们学习的文件接口
2.1fopen
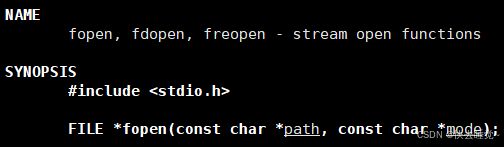
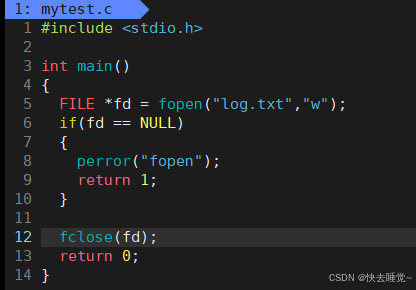
我们直接上代码来跟大家说明fopen的各个参数的意义
对于这个函数我们其实是不陌生的所以我只让大家关注两个东西
- 这个fopen的返回值是FILE,而且我们接收返回值的时候也是用FILE*,那么这个FILE到底是什么?
- 各种模式的使用方面的不同。
对于这两个问题呢第一个问题现在我只能告诉大家这个FILE是一个结构体,具体内容在我们后面学习就可以一窥究竟了
第二个问题就很好回答了,我们可以打开fopen的使用手册来跟大家一个一个讲解

2.2fclose
fclose就非常的简单粗暴了,只需要将参数设为打开文件所返回的值即可。
2.3open
在回顾了C语言的文件接口后我们现在来学习一下Linux中的系统接口,同时在学习的途中我们可以思考一下C语言的文件接口和这些系统接口有什么关系?
我们来一个一个的介绍open的参数以及返回值
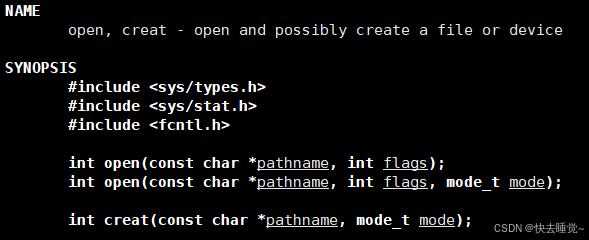
- 返回值
在了解参数的问题前我们需要了解open函数的返回值,从手册中我们发现其返回值是一个整型变量,我们现在只需要知道这个整型的名字叫做文件描述符,它的作用简单来说就是定位这次调用函数所被打开的文件。
所以如果我们成功打开了一个文件将会返回这个文件的文件描述符,失败了就会返回-1 - pathname
这个参数的意义很简单和之前的fopen相同都是指文件的名字。 - flags
这个参数的意义就和fopen的mode是相同的,就是来判断是以哪种模式访问文件但是它的使用方法和mode不同。
从手册中我们可以发现这个参数的可选项非常多,但是其实在我们日常使用中我们只需要了解其中的部分项即可,这次介绍我也就介绍常用的几个
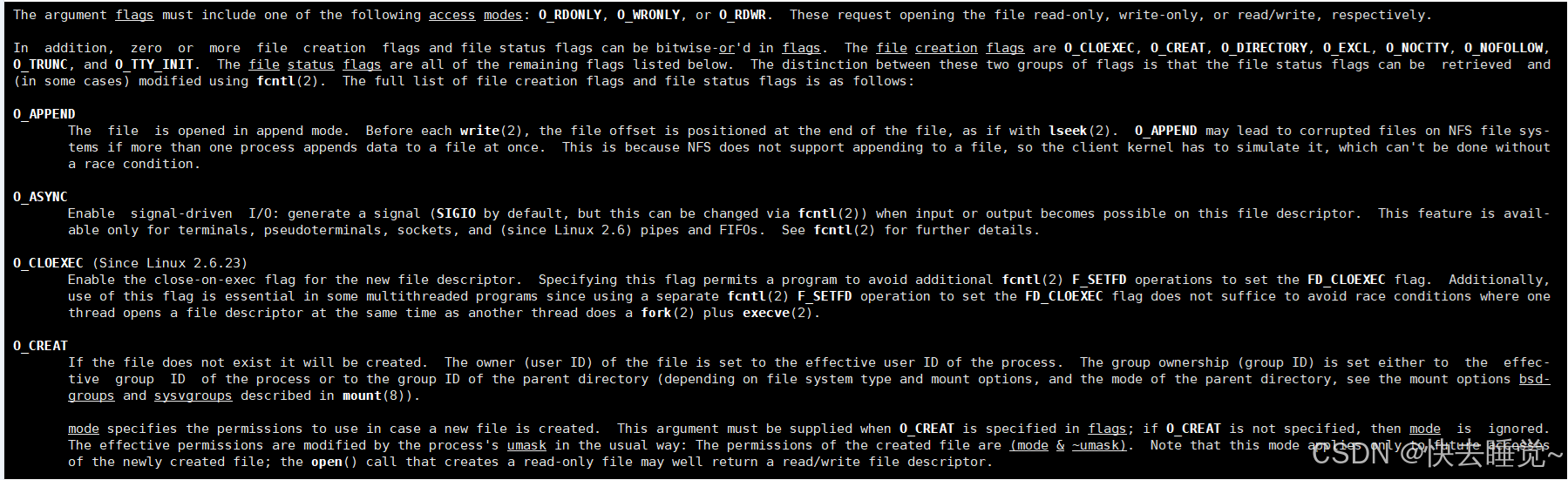
- O_RDONLY, O_WRONLY, O_RDWR
这三个分别是以读取,写入,读取和写入的权限访问文件。这三项只能进行三选一而且三项中必须存在一项。 - O_CREAT
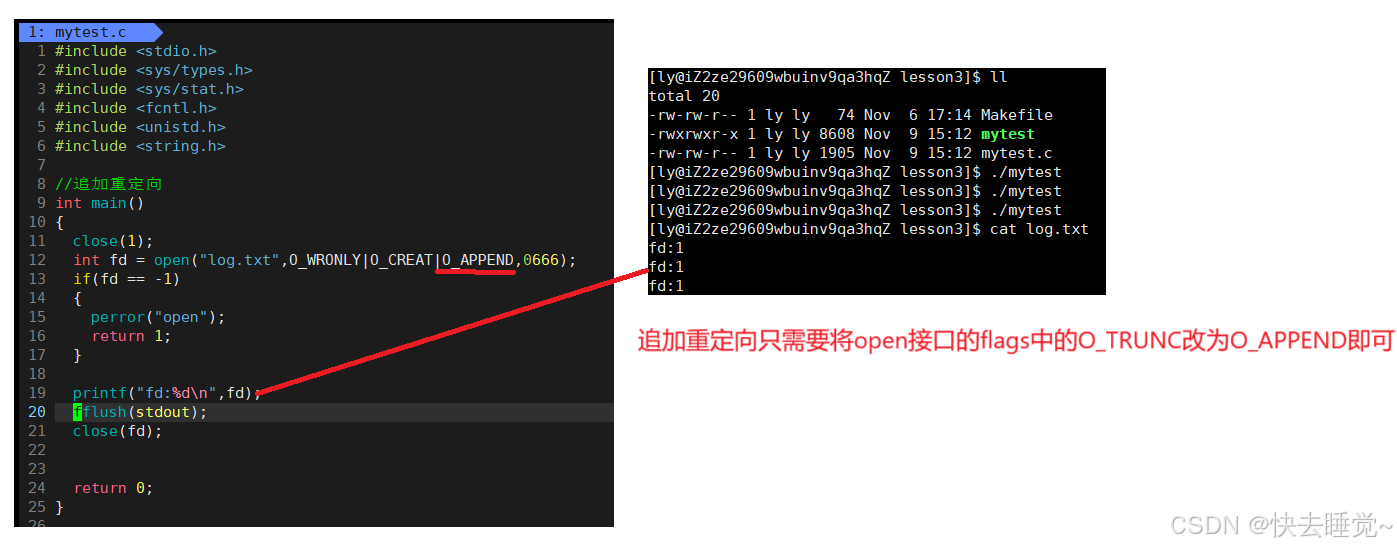
从creat的意思我们就可以大概知道这个参数的作用是什么:如果文件不存在就先创建文件 - O_APPEND,O_TRUNC
第一个的意思是每次写操作都写入文件的末尾即追加方式,而第二个就与其相反即在每次的写操作之前会将文件内容清空。
那么在大概了解了这些变量的意思后我们要如何使用这个参数呢?还是先来看手册中是怎么说的
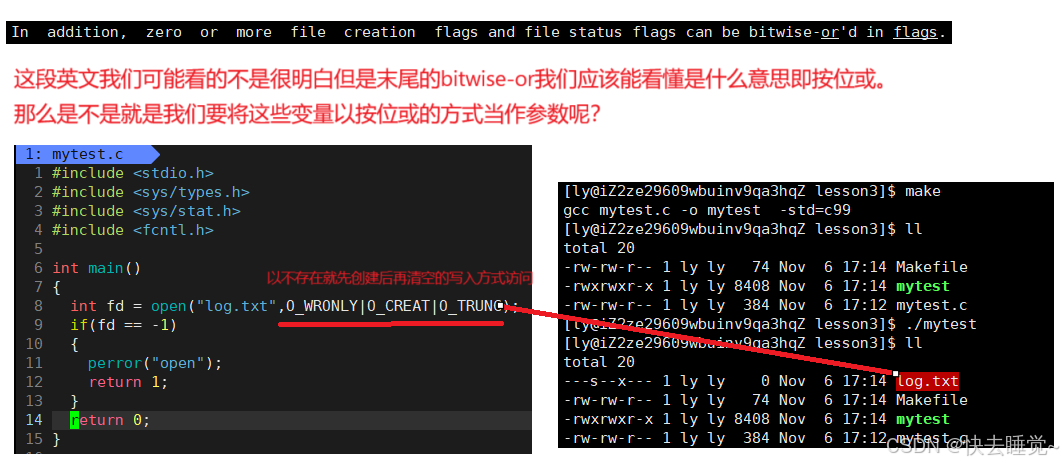
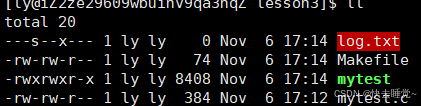
- mode
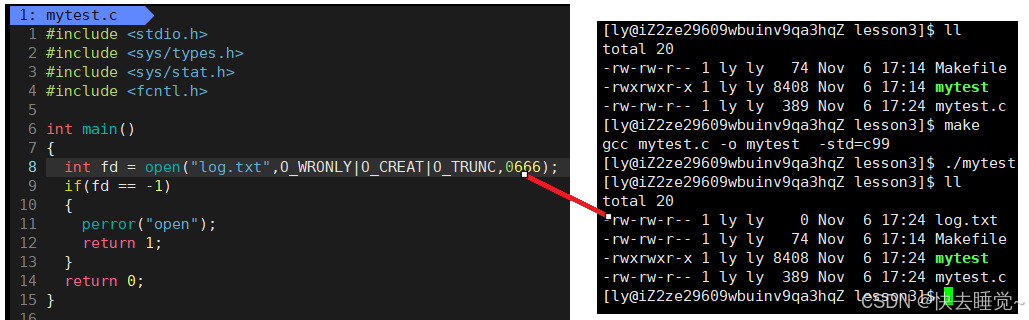
这里的mode就和上文中fopen的mode不同了,这个参数仅仅在flags中使用了O_CREAT时使用。在讲述这个参数的意义时我们先仔细观察上面那张图片所创建的新文件有什么问题
从这个文件底色发红我们就可以看出来了这个新创建的文件出现了问题,问题就在于这个文件的权限!它和我们其他的文件不同甚至出现了乱码,这就是我们使用了O_CREAT但是没有给第三个参数具体的值导致的。
所以这个mode的意义就是用于指定被创建文件的访问权限位,那么要如何使用这个参数呢?这就需要我们之前学习的关于权限的知识,我就不再重复了大家可以去翻开我之前的文章。在使用的同时要注意权限掩码哦。
2.4close
close没有什么好说的,和fclose仅仅只有返回值的和参数的类型不同。
2.5write
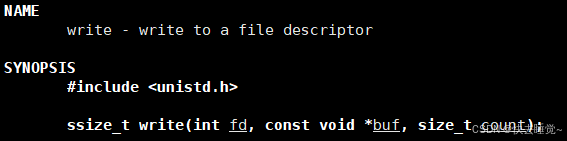

write的三个参数分别代表了你想写入的文件的文件描述符,想要写入内容的数组,想要写入的长度。
同时当使用write成功后会返回写入的字节数,失败则返回-1
我们用代码来用作参考
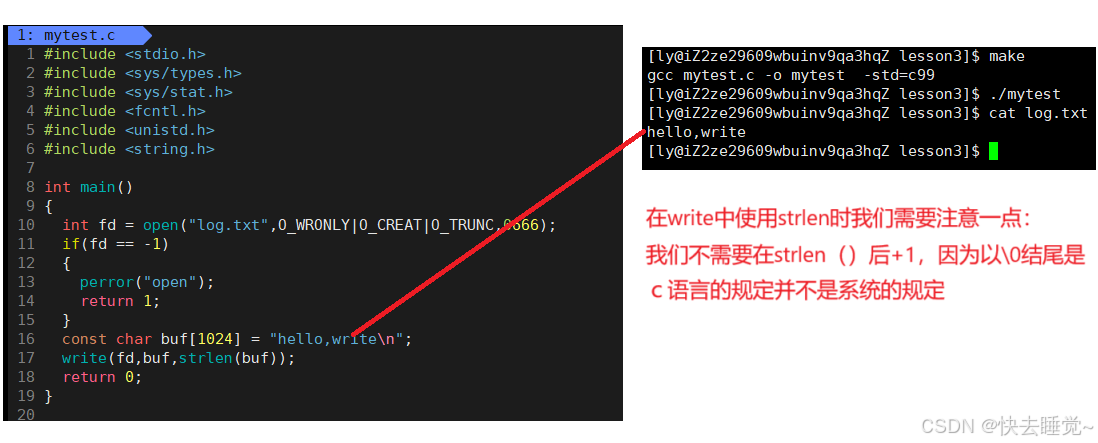
2.6read
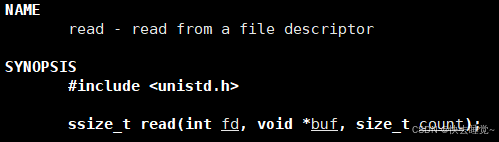

read的使用方法和write相同,都是以文件描述符,数组,长度为参数。
同时成功则返回读出的字节数失败就返回-1但是如果在使用read之前就已经到达了文件的末尾则会返回0。
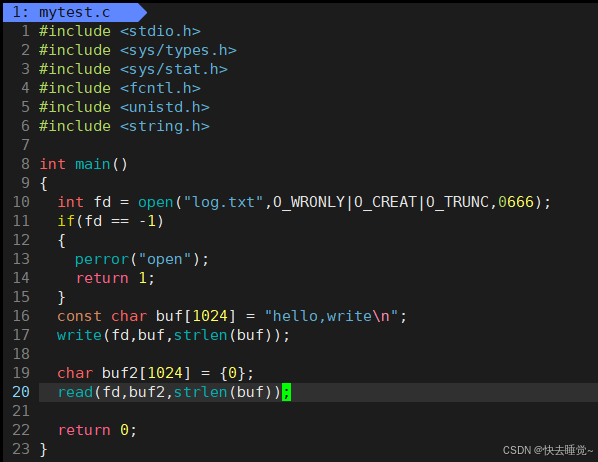
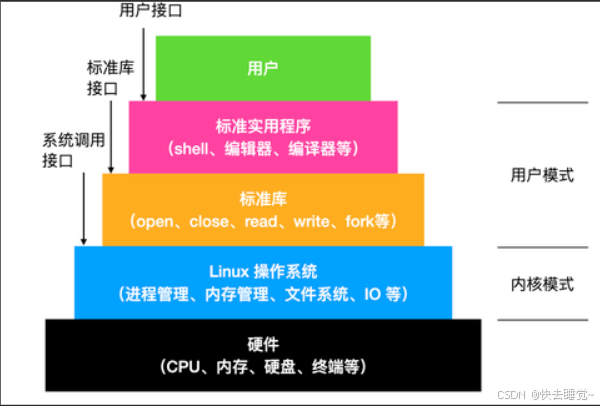
在了解了C语言的库函数和Linux的系统调用接口后我们可以发现这两类函数其实有相似之处,那么他们到底有什么区别呢?我们可以从我们之前学习操作系统时的一张图中可以看出来
从这张图可以看出来标准库函数其实就是封装了系统调用接口,所以那些fopen和fclose都是封装了open和close的。
三.文件与系统
3.1文件描述符
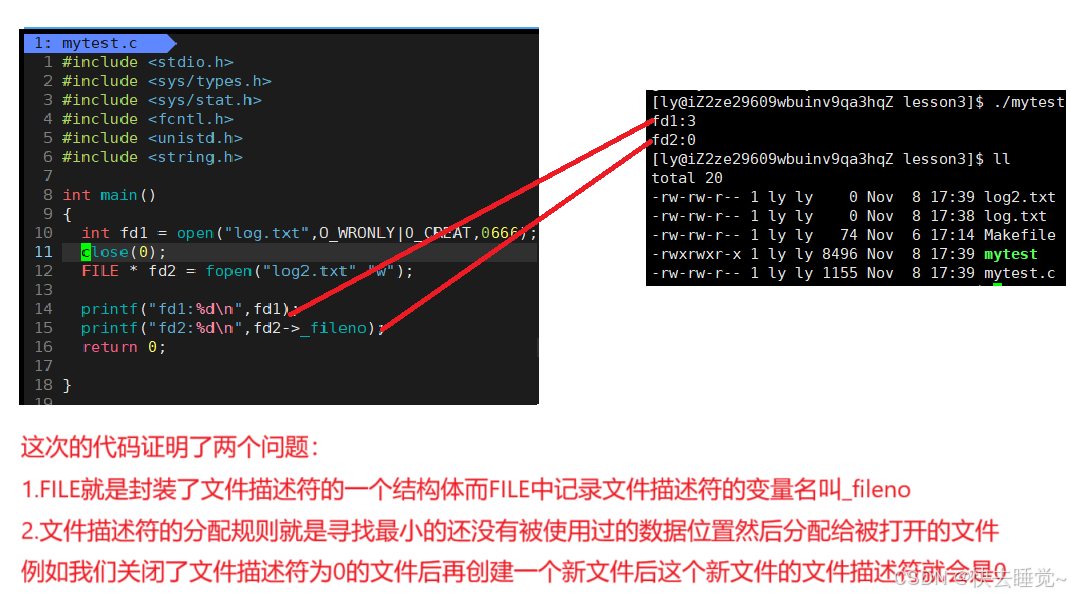
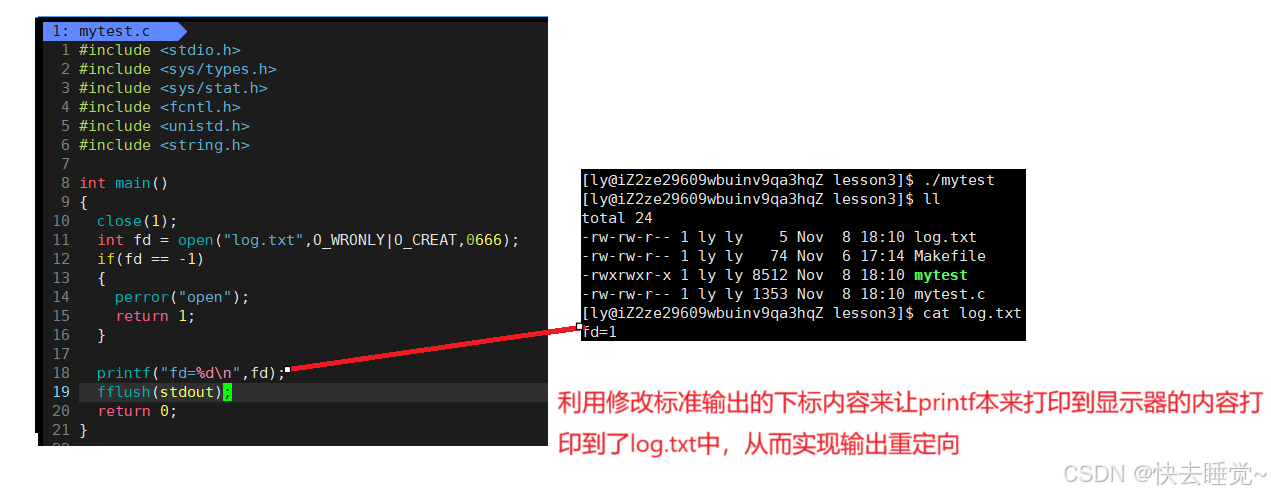
我们知道了fopen是封装了open的C标准库函数后我们会发现一个问题?为什么这两个函数的返回值是不同的呢?一个是FILE一个是int,而且在我们分别介绍这两个函数的时候说过FILE是一个结构体而int变量是文件描述符同时我们也知道文件描述符的作用是定位到某个文件那么我们就可以推论出FILE肯定就是封装了文件描述符的一个结构体。那么我们要如何证明呢?
在我们证明FILE肯定是封装了文件描述符之前我们需要更加深入的了解文件描述符的意义是什么???
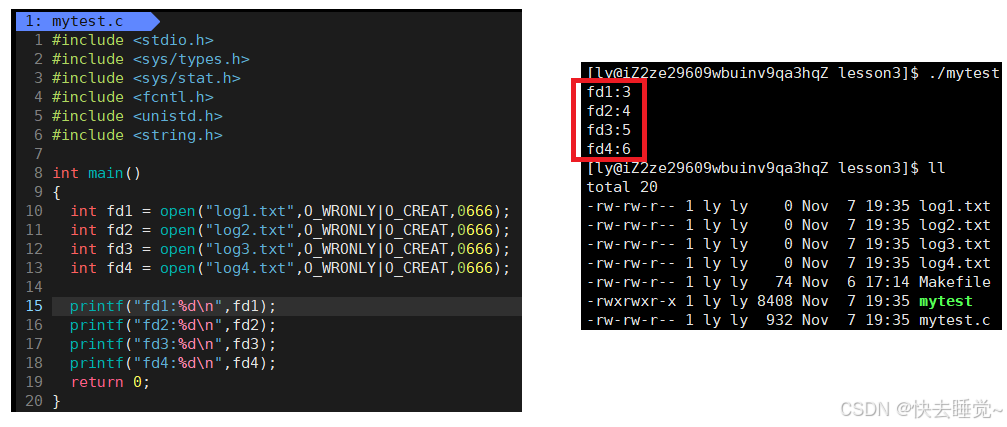
我们现在只知道文件描述符是整型变量,所以我们可以试着多打开几个文件来观察文件描述符这个整型变量有什么规律可言。
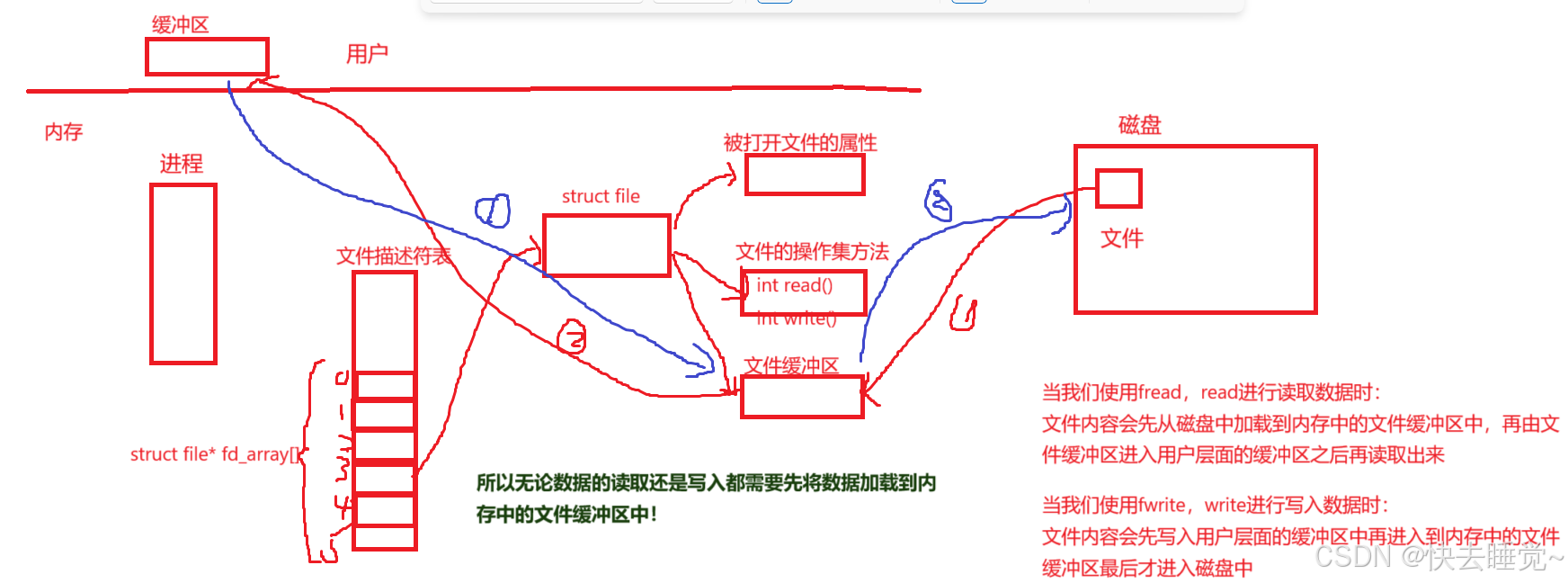
我们可以发现文件描述符是一个以3的开始的连续的整数但是现在的我们也只能知道这样的规律了,而想要深入了解文件描述符是何意义我们需要关注进程和被打开文件的对应关系是如何维护?
我们如今只知道被打开的文件是会被内核创建一个对应的结构体变量并形成一个链表但是这仅仅是文件方面的,我们并不知道进程和文件是如何形成对应关系的。
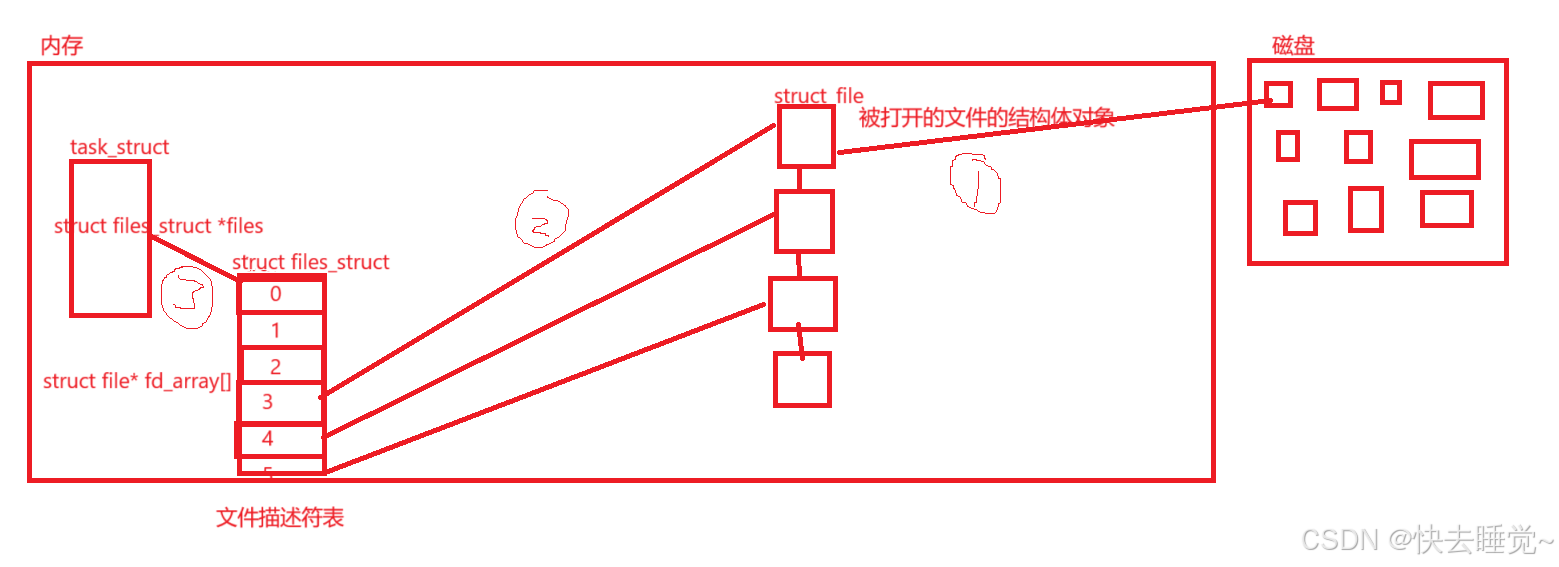
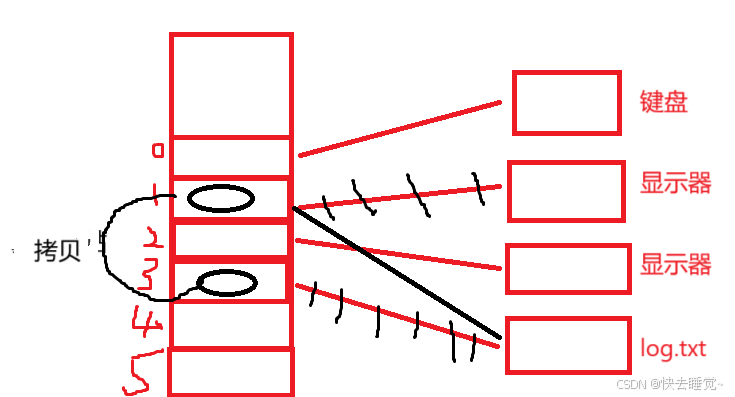
我们将这一张图分为三部分来讲述
- 文件从磁盘加载到内存
当我们使用函数打开文件时内核会生成一个结构体来存储被打开文件的属性并且形成一张链表,同时要注意的时被打开文件是有顺序的! - 进程pcb中的文件描述符表
在每个进程的pcb中会有一个指针指向一个结构体,而这个结构体中会形成一个文件结构体的指针数组即文件描述符表但是这个结构体中存储的不只有文件描述符表还有其他的数据,而文件描述符的本质就是这个数组的下标! - 文件描述符表和文件结构体的对应关系
当进程调用函数每打开文件时内核每创建一个文件结构体后文件描述表中的指针数组就会从下标3所对应的指针指向这个文件结构体,前提是我们没有把0,1,2所指向的文件关闭。
从这张图我们也可以发现其实现了进程管理和文件管理实现了解耦,进程只需要关注文件描述表并不需要关注文件在内存中是如何存储的,而文件管理也只需要关注文件在磁盘和内存中的存储方式即可。
同时我们可以知道操作系统访问文件时是只认文件描述符的,那么文件描述符是如何从磁盘中的文件传输到用户的呢,我在图里画了顺序我们来理解一下。
文件从磁盘中加载到内存后按照顺序和文件描述符表一一对应,进程再从文件描述符表指针中去读取出文件描述符。
3.2 标准输入,标准输出和标准错误
但是为什么我们创建的文件所对应的文件描述符是从下标3开始的呢?0,1,2都去哪了?
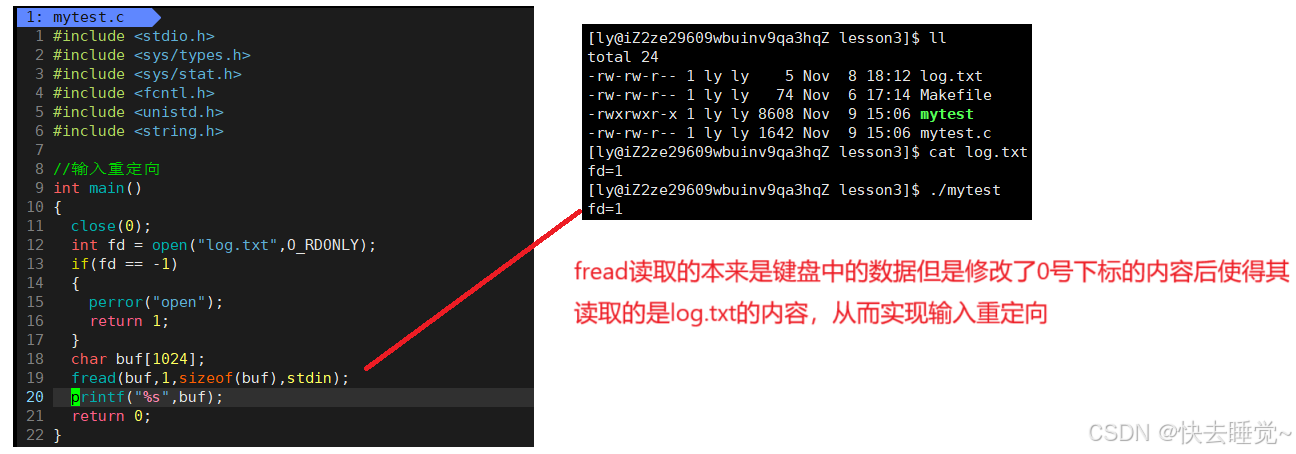
进程在运行的时候默认是会打开0,1,2所对应的文件的而这三个文件分别是标准输入stdin,标准输出stdout和标准错误stderr。而标准输入所对应的文件是键盘,stdout和stderr对应的文件都是显示器,而操作系统默认打开这三个文件的意义是什么呢?
输入输出的打开其实很好理解,如果操作系统不默认把键盘和显示器的文件打开那么我们怎么能读取键盘中的数据怎么能向显示屏中写入数据呢?所以默认打开0,1的目的就是为了让程序员能够进行输入输出的代码编写。
而标准错误stderr又是用来干什么的?我们用一个例子来进行说明,在我们使用各种各样的软件的时候肯定都遭遇过一些稀奇古怪的错误那么对于我们使用者来说我们不需要在意这些错误的发生时间和具体情况等等但是对于开发这个软件的程序员他就需要了解这些情况所以在每个软件中都会存在一个日志,这个日志中会存储软件每时每刻的运行情况比如打开了什么发生了什么错误之类的。但是只要是一个成熟一点的软件错误的发生量肯定是远远小于正常情况的运行量的所以如果程序员在开发日志的时候不将错误信息和正常信息分开就有可能会造成无法找到错误信息。
而标准错误就是用来专门存储错误信息的,它是来让程序员将错误信息和正常信息进行区分的一种方法。
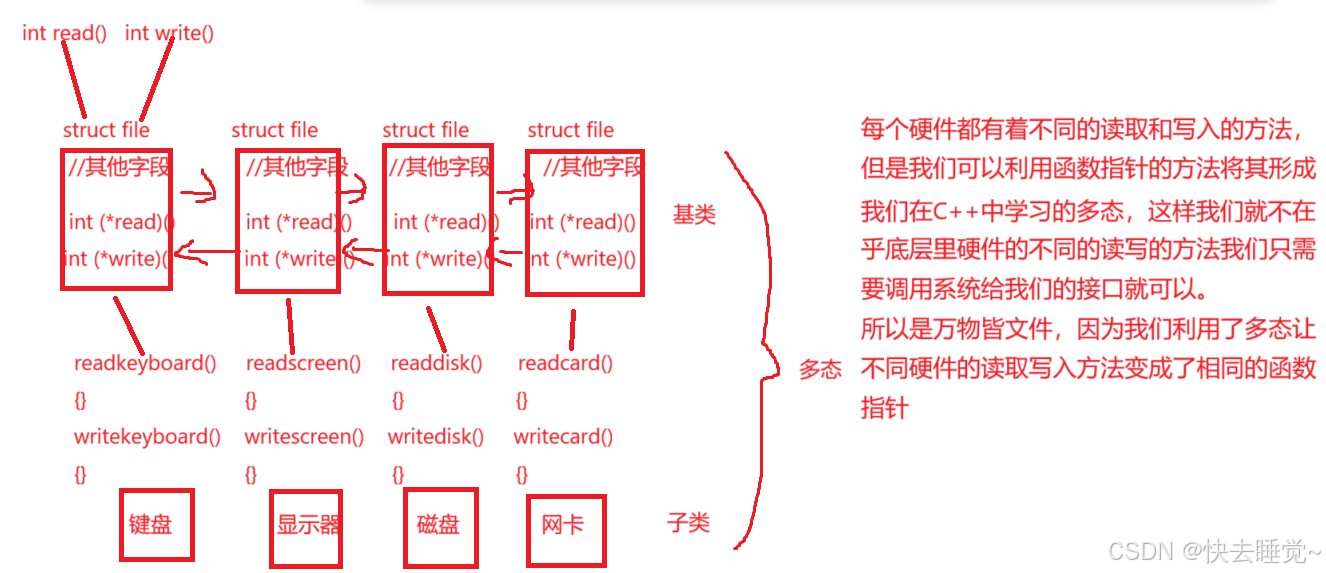
在了解了0,1,2所代表的意义后我们可以重新思考一个我们以前说过的问题:为什么万物皆文件?标准输入所代表的硬件是键盘,而标准输出和标准错误代表的硬件是显示器但是对于文件的操作我们可以分为读取和写入可是硬件都不同那么读取和写入的方法都不同,那么是为什么会说万物皆文件呢??
3.3fd的分配规则
在前面了解文件描述表的时候我们知道了如果我们没有将文件描述符0,1,2所指向的文件即标准输入标准输出和标准错误关闭那么文件描述符就会从3开始指向新创建的文件。那么如果将0,1,2在创建文件前进行了关闭呢?
ps:0,1,2是已经默认打开的文件所以我们可以直接使用其来进行数据访问
四.重定向
在讲述重定向时肯定会有人想到我们之前学习Linux的指令时好像提到过重定向这个东西那么当时我们是用什么来说明重定向的呢?
当时我们只了解如何使用这两个重定向但是不了解其中的原理
4.1重定向的概念
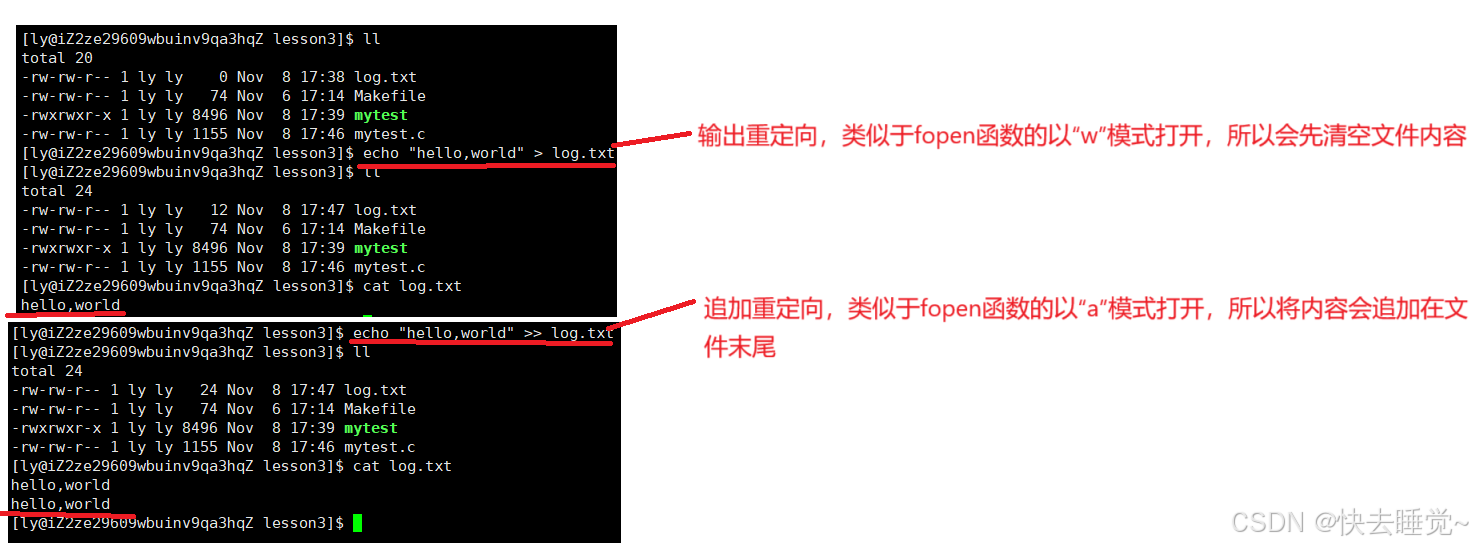
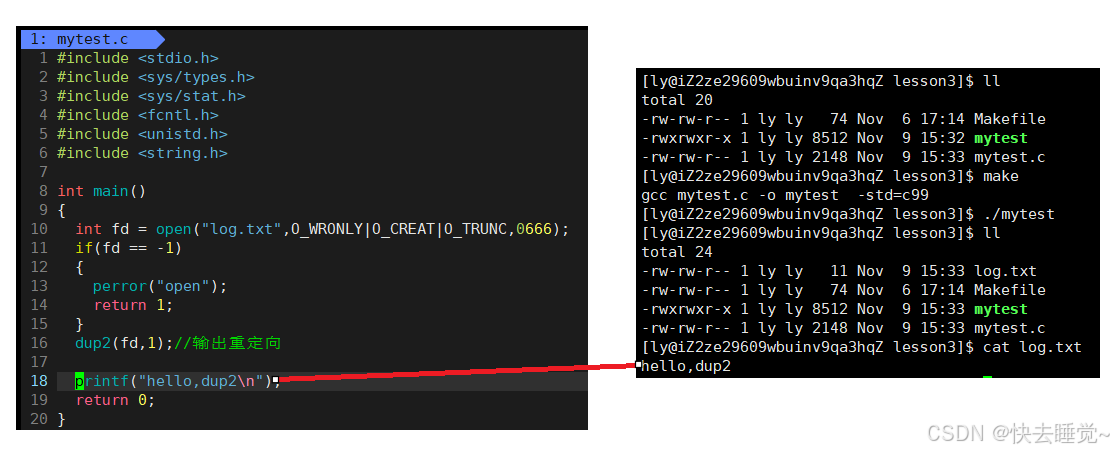
在我们学习文件和系统的关系时提到过操作系统只认文件描述符,所以无论是系统调用接口还是封装了系统调用接口的C标准库函数都是只认文件描述符的。例如我们最常使用的printf函数,我们平时使用它就是向显示屏中打印字符,那么在我们学习了文件后我们知道它是向文件描述符为1的文件中写入。所以如果我们可以将文件描述符为1的文件改为我们自己创建的文件的话是不是就可以让其向这个文件中写入,这就是重定向的概念。
所以重定向的本质就是修改特定文件的下标内容。
4.2重定向的使用
对于重定向的使用大致为三种方法:
-
指令使用
即最开始介绍的方法> >> < -
自己手动修改特定文件的下标内容来形成重定向
-
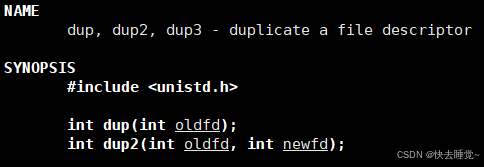
使用dup2函数
虽然有上面两种使用方法但是指令方法局限性较高,而自己编程又过于麻烦。但是通过上面的代码我们大概了解了重定向在C语言中要如何实现,那么是否有更好的思路或者方法来实现呢?
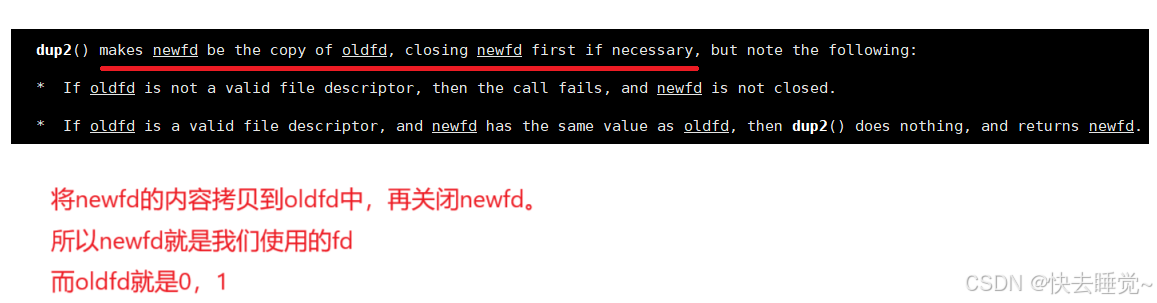
我们自己手搓重定向都是先关闭标准输入或标准输出文件后再创建新文件利用文件描述符的分配规则来实现,但是我们是否可以先创建一个新文件然后将新文件的内容复制粘贴到特定文件的下标内容中从而使得有两个文件描述符指向一个文件最后再将那个不是特定文件描述符的进行关闭,这样只有那个特定文件的下标内容是指向新文件。这样也就形成了重定向工作。
所以出现了dup2接口,它的原理就是进行文件描述符级别的数组内容的拷贝。
五.缓冲区
在了解缓冲区之前我先问大家一个问题:我们在应用层面进行数据的读写的本质是什么?
答案是:本质是将内核缓冲区的数据进行来回的拷贝。
这句话大家可能不太理解是何意思,我用一张图来进行大概的说明,这个说明只想让大家在心里有这个概念,更深层次的理解我们等会再进行介绍。
5.1缓冲区的概念
我们知道了对应数据的读取和写入都需要经过缓冲区那么缓冲区到底是什么???
缓冲区就是内存空间的一部分,是用来缓冲输入或输出的数据。
既然缓冲区可以暂存数据那么他就一定会有对应的刷新方法:
- 无缓冲(立刻刷新)
- 行缓冲(行刷新)
- 全缓冲(缓冲区满了再刷新)
这是一般情况如果有特殊情况则需要特殊处理
- 强制刷新
- 在进程退出的时候一般要刷新缓冲区
对于显示器文件,是采用的行缓冲
对于磁盘上的文件则是全缓冲
5.2缓冲区的意义
有了缓冲区的存在,我们就可以积攒一部分的数据后再统一发送,这样就提高了传输数据的效率。
所以缓冲区的意义就是:提高效率。
我们想要理解缓冲区光说肯定没有意义,我们可以通过一个样例。
我们可以结合以前fork的知识和刚刚学习的缓冲区的知识来进行理解
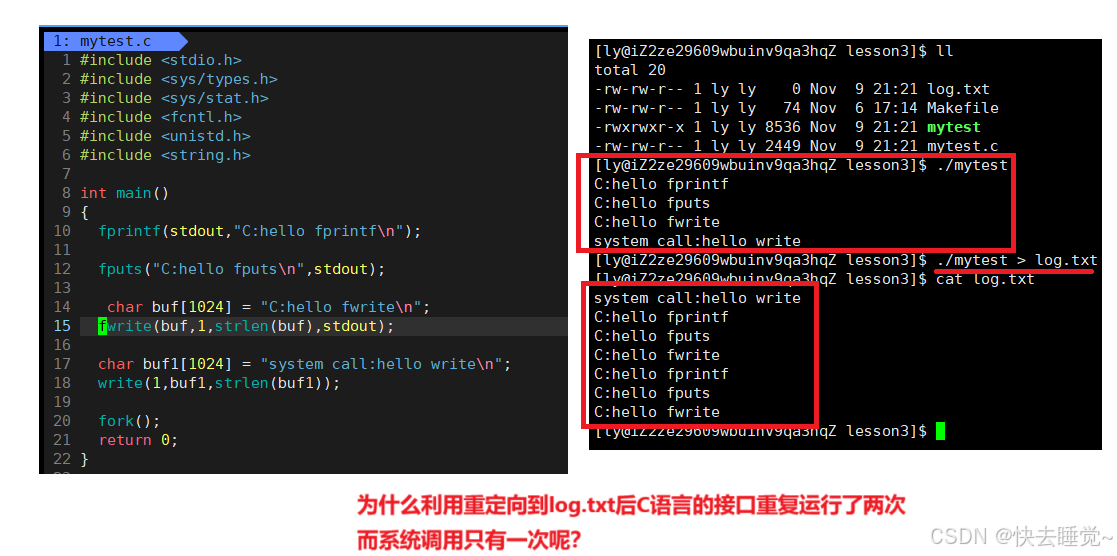
- 首先我们要先知道我们所谈的“缓冲区”是和操作系统没有关系的,它只是C语言的本身有关。
- 同时我们要知道对于C语言或者C++提供的缓冲区里存储的都是用户的数据,并且也属于进程在运行时自己的数据。但是如果我们将这个数据交给了操作系统后这份数据就不属于我们了。
- 当我们向显示器文件中进行打印时显示器文件使用的行刷新,而不管是系统调用接口还是C语言的函数我们最后都加上了\n,那么在fork之前数据都全部被刷新了。
- 而当我们重定向到log.txt,本质上是向磁盘文件中写入数据,但是向磁盘文件中写入时缓冲区就变成了全缓冲,只有将缓冲区全部写满才会进行刷新。仅仅写入一些简单数据并不能把缓冲区写满,所以fork执行的时候数据都在缓冲区中。
然后当进程退出时一般是要进行刷新缓冲区的即使对于全刷新的文件并且数据还没有写满。那么刷新缓冲区算不算清空或者“写入”操作呢??这是算的,那么无论是父进程还是子进程在有写入的操作时就会触发写时拷贝!从而会产生两个缓冲区! - 在触发了写时拷贝时父子进程都会刷新一次缓冲区所以分别都会打印到log.txt文件中,那么为什么系统调用接口只有一次呢?原因只有可能是系统调用接口没有使用C语言的缓冲区,它是直接写入操作系统的不属于进程,所以没有发生写时拷贝,从而只运行了一次。
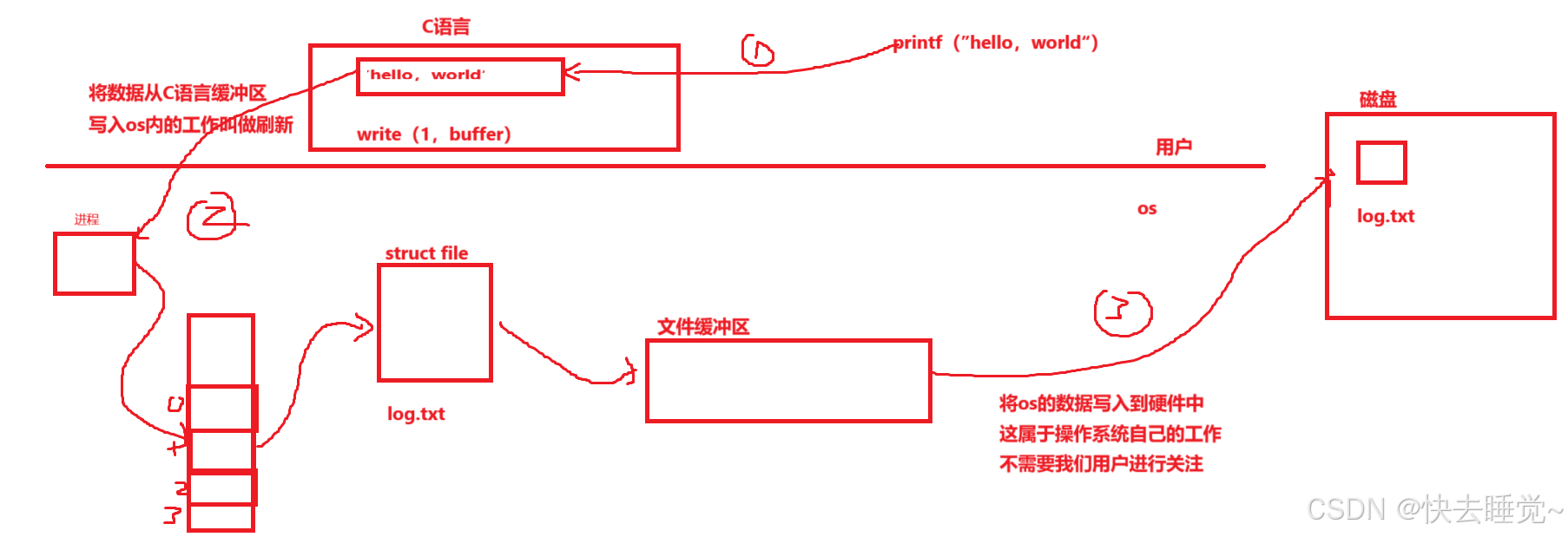
5.3用户缓冲区和内核缓冲区
我们日常中使用的最多的就是C语言和C++给我们提供的缓冲区,这是用户缓冲区。而在内存中存储的文件缓冲区则属于内核缓冲区。这两种缓冲区有什么区别或者有什么关系吗?
同时我们也要提出一个问题:刷新是什么?我们一直说行刷新,全刷新。那么刷新到底是什么??
刷新的概念就是:将语言缓冲区写入os内的操作。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » linux之文件(上)

发表评论 取消回复