点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(正在更新…)
章节内容
上节我们完成了如下的内容:
- scikit-learn 归一化
- scikit-learn 距离的惩罚
决策树模型
- 树模型是有监督学习类算法中应用广泛的一类模型,同时可应用与分类问题和回归问题,其中用于解决分类问题的树模型常被称为分类树,而用于解决回归类问题的树模型被称为回归树。
- 树模型通过递归式切割的方法来寻找最佳分类标准,进而最终形成规则。
- 其算法原理虽然简单,但模型本身使用面极广,且在分类问题和回归问题上均有良好的表现,外加使用简单,无需人为进行过多变量调整和数据预处理,同时生成规则清晰,模型本身可解释性非常强,因此在各个行业均有广泛应用。
- 决策树(Decision Tree)是一种实现分治策略的层次数据结构,它是一种有效的非参数学习方法,并可以用于分类和回归,我们主要讨论分类的决策树。
- 分类决策树模型表示一种基于特征对实例进行分类的属性结构(包括二叉树和多叉树)。
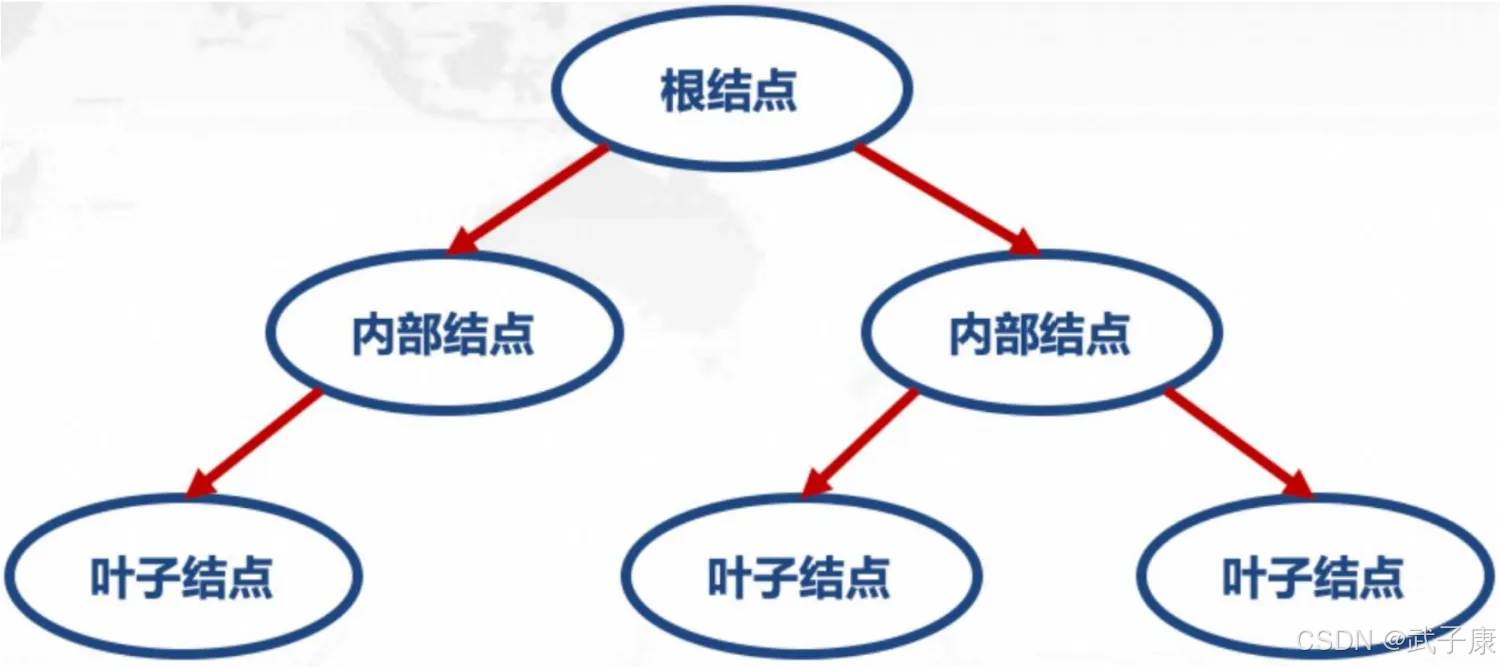
决策树由节点(Node)和有向边(Directed edge)组成,树中包含三种节点:
- 根节点(Root Node):包含样本全集,没有入边,但有零条或多条多边。
- 内部节点(Internal Node):对应于属性测试条件,恰有一条入边,和两条或多条出边。
- 叶节点(Leaf Node)或终节点(Terminal Node):对应于决策结果,恰有一条入边,但没有出边。
决策树基本流程
从根节点到每个叶子节点的路径对应了一个判定测试序列,其基本流程遵循了简单且直观的“分而治之”策略。
由此,局部区域通过少数几步递归分裂确定,每个决策节点实现一个具有离散输出的属性测试函数,标记分支。
假设给定训练集输入:
在每个节点应用一个测试,并根据测试的输出确定一个分支,这一过程从跟节点开始,并递归的重复,直至到达一个叶子节点,这是,该 leaf 的值形成输出。
决策与条件概率分布
决策树可以表示为给定决策节点下类的条件概率分布,这一条件概率分布定义在特征空间的一个划分上。每个将空间划分为较小区域,在从根节点沿一条路径向下时,这些较小的区域进一步划分,并在每个区域定义一个类的概率分布就构成了一个条件概率分布。
假设 X 是表示特征的随机变量,Y 是表示类的随机变量,则条件概率分布可表示P(Y | X),X 取值于给定划分条件下的区域集合,Y 取值于类的集合。各叶节点(区域)上的条件概率往往会偏向某一个类,即属于某一类的概率较大。
决策树在分类时会将该节点的实例强行分到条件概率大的那一类去。
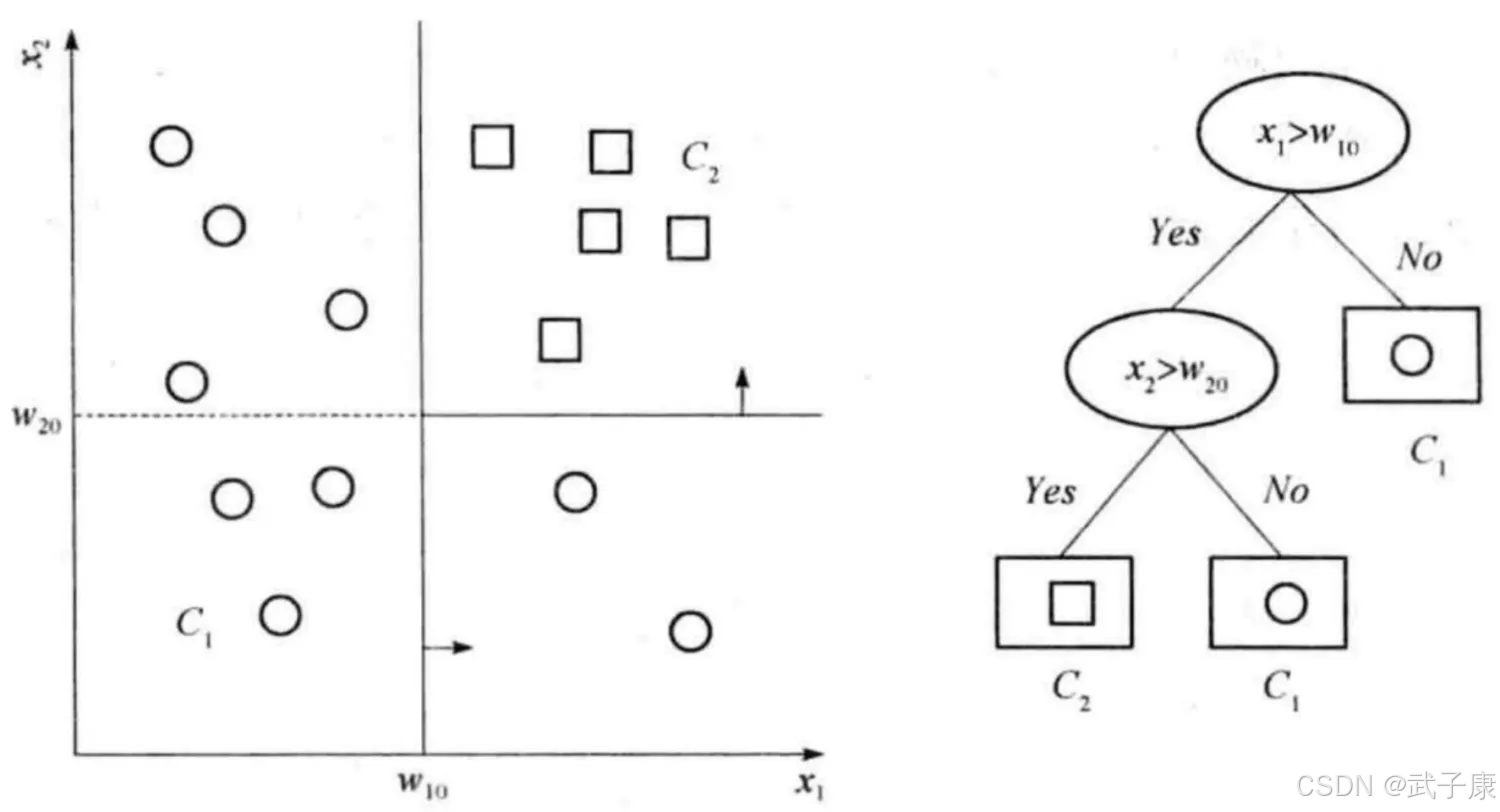
左图表示了特征空间的一个划分,假定现在只有 W10 和 W20 两个决策点,特征空间被决策点沿轴划分,并且相继划分相互正交,每个小矩形表示一个区域,特征空间上的区域构成了集合,X 取值为区域的集合。
我们在这里只假设两类,即 Y 的取值为 方块、圆圈。当某个区域 C 的条件概率分布满足 P(Y=圆圈|X=C)> 0.5 时,则认为这个区域属于圆圈类,即落在这个区域的实例都被视为该类。
右图为对应于概率分布的决策树,如果输入维是 Xn 是离散的,取 N 个可能的值之一,则该决策节点检查 Xn 的值,并取相应分支,实现一个 n 路划分。因此,如果决策节点具有离散分支,数值输入应当离散化。

学习算法
决策树学习本质上从训练数据集中归纳出一组分类规则,也称为“树归纳”。
- 对于给定的训练数据集,存在许多对它无错编码的树。而为了简单起见,我们感兴趣的是从中选出“最小”的树,这里的树的大小用树的节点数和决策节点的复杂性度量。
- 从另一个角度看,决策树学习是由训练数据集估计条件概率模型,基于特征空间划分的类的条件概率模型有无数个,我们选择的模型应该是不仅能对训练数据有很好的拟合,而且对未知数据也有很好的预测。
- 树的学习算法从包含全部训练数据开始,每一步都是最佳划分。依赖于所选择的属性是值属性还是离散属性,每次将数据划分为两个或者 N 个子集,然后使用对应的子集递归进行划分,直到所有训练数据子集被基本正确分类,或者没有合适的特征为止。
- 此时,创建一个树叶节点并标记它,这就生成了一颗决策树。
综上,决策树学习算法包括特征选择、决策树的生成与决策树的剪枝。
由于决策树表示一个条件概率的分布,所以深浅不同的决策树对应着不同的复杂度的概率模型,其中决策树的生成只考虑局部最优,相对的,决策树的剪枝则考虑全局最优。
香农熵的计算
决策树学习的关键在如何选择最优划分属性,一般而言,随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点纯度(purity)越来越高。在分类树中,划分的优劣用不纯度度量(impurity-measure)定量分析。
在信息论与概率统计中,熵是表示随机变量不确定性的度量。这里我们使用的熵,也叫做香农熵,这个名字来源信息论之父克劳德·香农。

为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值(数学期望),即上述公式。对于二分类问题,如果 p1=1 而 p2 = 0,则出油的实例都属于 Ci 类。
如果 p1 = p2 = 0.5,熵为 1。
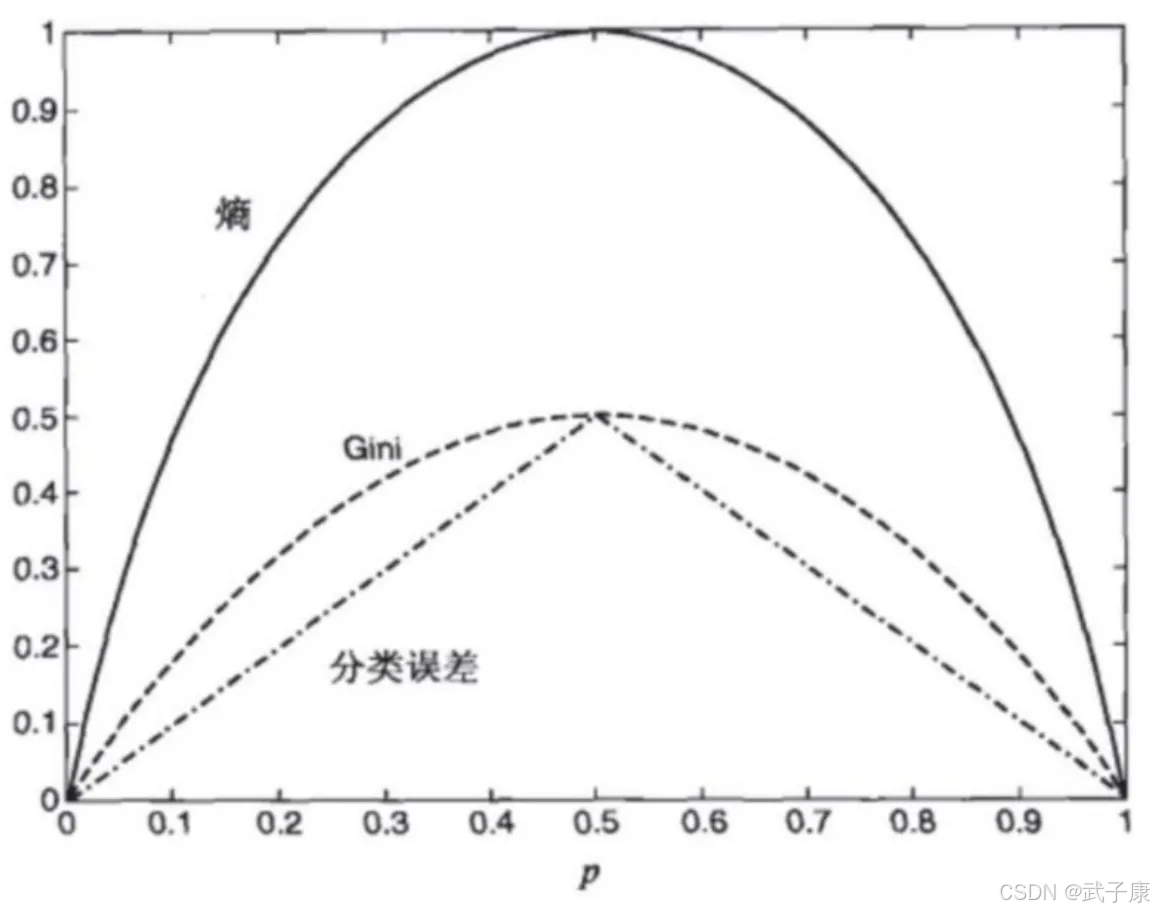
但是,熵并非是唯一可能的度量。
这些都可以推广到 K > 2 类,并且给定损失函数,误分类误差可以推广到最小风险。
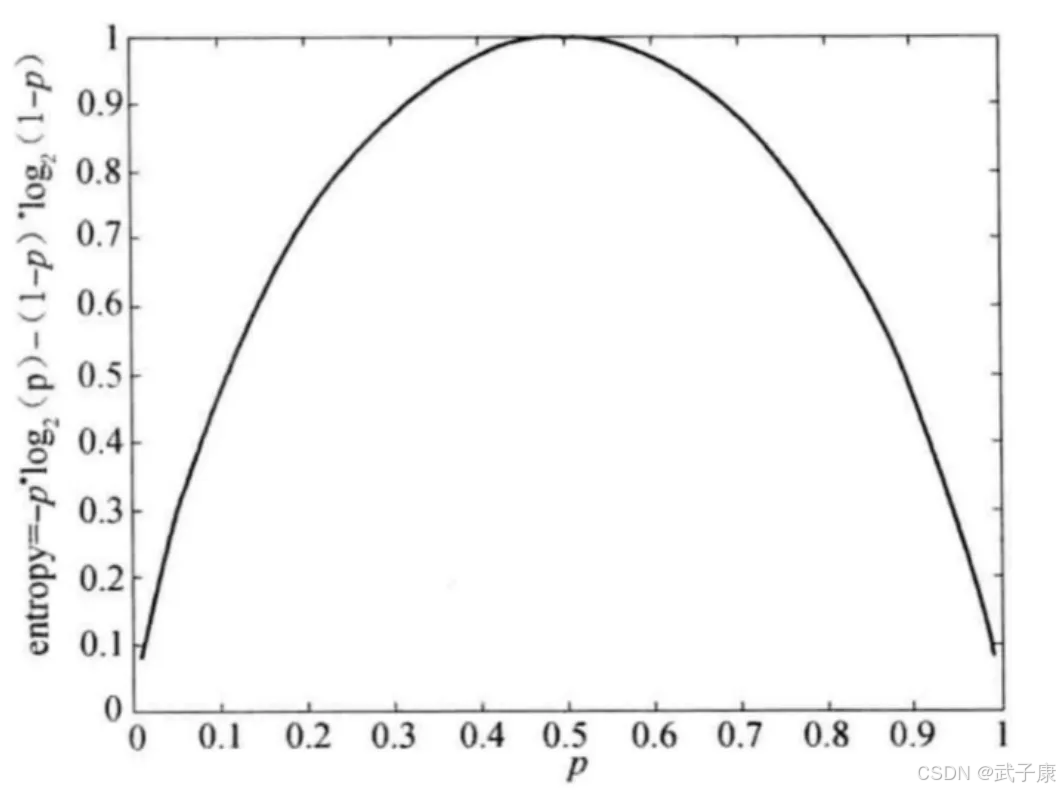
下图显示了二元分类问题不纯性度量值的比较,p 表示属于其中一个类的记录所占的比例。从图中可以看出,三种方法都在类分布均衡时(即当 p=0.5 时)达到最大值,而当所有记录都属于同一个类时(p=1 或 p=0)达到最小值。

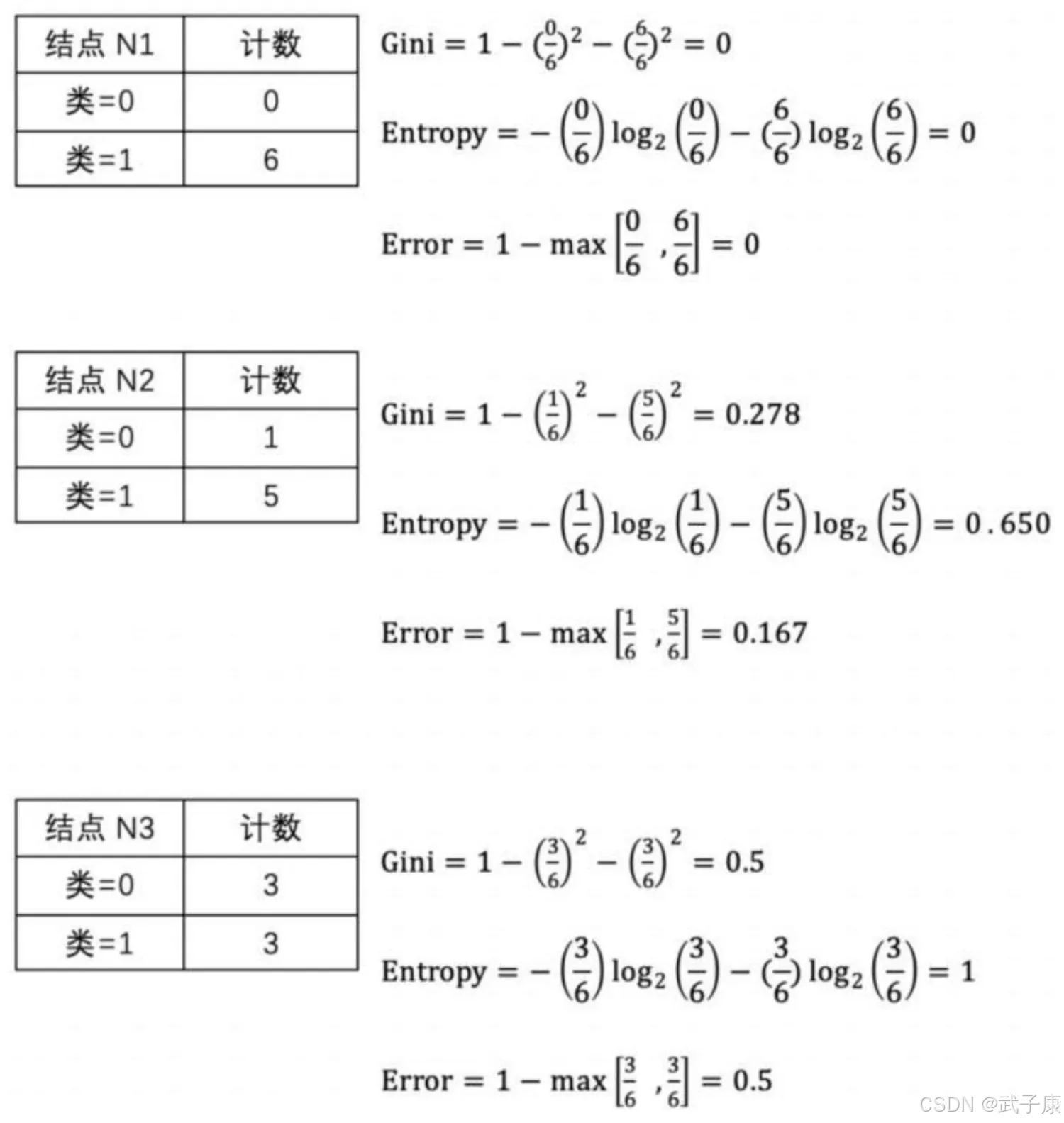
这里给出三种不纯性度量方法的计算实例:
从上面的例子及图中可以看出,不同的不纯性度量是一致的。根据计算,节点 N1 具有最低的不纯性度量值,然后依次是 N2、N3。虽然结果是一致的,但是作为测试条件的属性选择仍然因不纯性度量的选择而异。
香农熵的代码实现
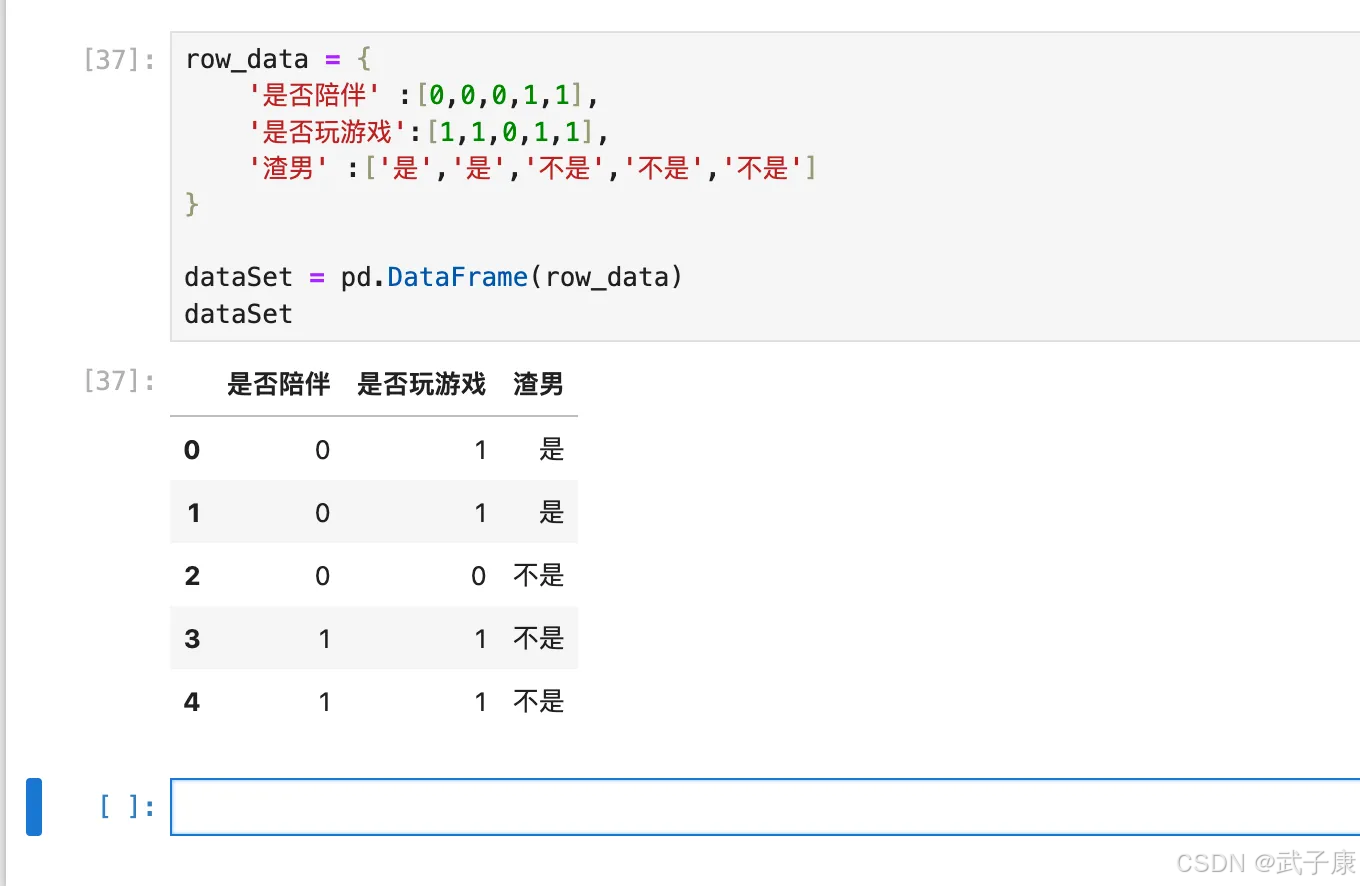
row_data = {
'是否陪伴' :[0,0,0,1,1],
'是否玩游戏':[1,1,0,1,1],
'渣男' :['是','是','不是','不是','不是']
}
dataSet = pd.DataFrame(row_data)
dataSet
执行结果如下图所示:
通过代码实现一下:
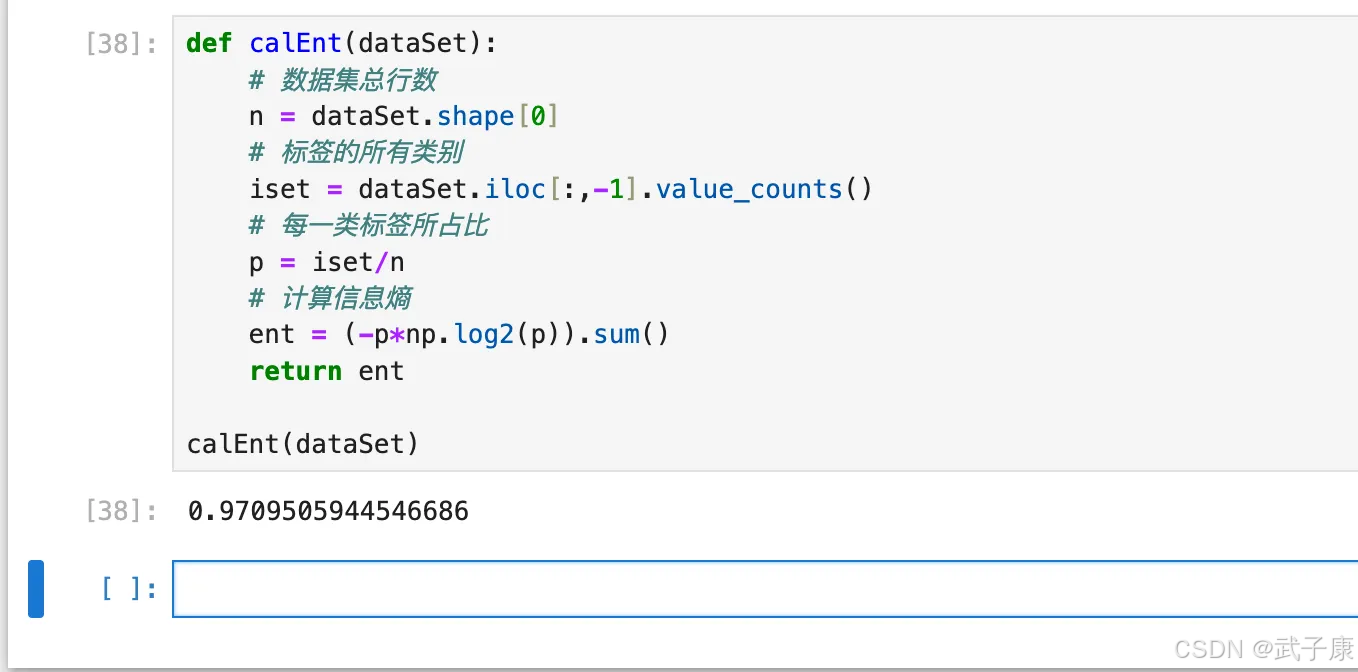
def calEnt(dataSet):
# 数据集总行数
n = dataSet.shape[0]
# 标签的所有类别
iset = dataSet.iloc[:,-1].value_counts()
# 每一类标签所占比
p = iset/n
# 计算信息熵
ent = (-p*np.log2(p)).sum()
return ent
calEnt(dataSet)
运行的结果如下图所示:
熵越高,信息的不纯度就越高,则混合的数据就越多。
也就是说,单从判断的结果来看,如果你从这 5 个人中瞎猜,要准确判断其中一个人是不是“bad boy”是不容易的。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据-199 数据挖掘 机器学习理论 - 决策树 模型 决策与条件 香农熵计算

发表评论 取消回复