PaddleYolo 是飞桨(PaddlePaddle)框架下的一个目标检测库,主要用于图像和视频中的物体检测。PaddleYOLO包含YOLO系列模型的相关代码,支持YOLOv3、PP-YOLO、PP-YOLOv2、PP-YOLOE、PP-YOLOE+、RT-DETR、YOLOX、YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOv5u、YOLOv7u、YOLOv6Lite、RTMDet等模型。
SwanLab 是一个开源的模型训练记录工具,面向AI研究者,提供了训练可视化、自动日志记录、超参数记录、实验对比、多人协同等功能。在SwanLab上,研究者能基于直观的可视化图表发现训练问题,对比多个实验找到研究灵感,并通过在线链接的分享与基于组织的多人协同训练,打破团队沟通的壁垒。
你可以使用PaddleYolo快速进行目标检测模型训练,同时使用SwanLab进行实验跟踪与可视化。
1. 引入SwanLabCallback
首先在你clone的PaddleYolo项目中,找到ppdet/engine/callbacks.py文件,在代码的底部添加如下代码:
class SwanLabCallback(Callback):
def __init__(self, model):
super(SwanLabCallback, self).__init__(model)
try:
import swanlab
self.swanlab = swanlab
except Exception as e:
logger.error('swanlab not found, please install swanlab. '
'Use: `pip install swanlab`.')
raise e
self.swanlab_params = {k[8:]: v for k, v in model.cfg.items() if k.startswith("swanlab_")}
self._run = None
if dist.get_world_size() < 2 or dist.get_rank() == 0:
_ = self.run
self.run.config.update(self.model.cfg)
self.best_ap = -1000.
self.fps = []
@property
def run(self):
if self._run is None:
self._run = self.swanlab.get_run() or self.swanlab.init(**self.swanlab_params)
return self._run
def on_step_end(self, status):
if dist.get_world_size() < 2 or dist.get_rank() == 0 and status['mode'] == 'train':
training_status = status['training_staus'].get()
batch_time = status['batch_time']
data_time = status['data_time']
batch_size = self.model.cfg['{}Reader'.format(status['mode'].capitalize())]['batch_size']
ips = float(batch_size) / float(batch_time.avg)
metrics = {
"train/" + k: float(v) for k, v in training_status.items()
}
metrics.update({
"train/ips": ips,
"train/data_cost": float(data_time.avg),
"train/batch_cost": float(batch_time.avg)
})
self.fps.append(ips)
self.run.log(metrics)
def on_epoch_end(self, status):
if dist.get_world_size() < 2 or dist.get_rank() == 0:
mode = status['mode']
epoch_id = status['epoch_id']
if mode == 'train':
fps = sum(self.fps) / len(self.fps)
self.fps = []
end_epoch = self.model.cfg.epoch
if (epoch_id + 1) % self.model.cfg.snapshot_epoch == 0 or epoch_id == end_epoch - 1:
save_name = str(epoch_id) if epoch_id != end_epoch - 1 else "model_final"
tags = ["latest", f"epoch_{epoch_id}"]
elif mode == 'eval':
fps = status['sample_num'] / status['cost_time']
merged_dict = {
f"eval/{key}-mAP": map_value[0]
for metric in self.model._metrics
for key, map_value in metric.get_results().items()
}
merged_dict.update({
"epoch": status["epoch_id"],
"eval/fps": fps
})
self.run.log(merged_dict)
if status.get('save_best_model'):
for metric in self.model._metrics:
map_res = metric.get_results()
key = next((k for k in ['bbox', 'keypoint', 'mask'] if k in map_res), None)
if not key:
logger.warning("Evaluation results empty, this may be due to "
"training iterations being too few or not "
"loading the correct weights.")
return
if map_res[key][0] >= self.best_ap:
self.best_ap = map_res[key][0]
save_name = 'best_model'
tags = ["best", f"epoch_{epoch_id}"]
def on_train_end(self, status):
self.run.finish()
2. 修改trainer代码
在ppdet/engine/trainer.py文件中,在from .callbacks import那一行添加SwanLabCallback:
from .callbacks import Callback, ComposeCallback, LogPrinter, Checkpointer, VisualDLWriter, WandbCallback, SwanLabCallback
接着,我们找到Trainer类的__init_callbacks方法,在if self.mode == 'train':下添加如下代码:
if self.cfg.get('use_swanlab', False) or 'swanlab' in self.cfg:
self._callbacks.append(SwanLabCallback(self))
至此,你已经完成了SwanLab与PaddleYolo的集成!接下来,只需要在训练的配置文件中添加use_swanlab: True,即可开始可视化跟踪训练。
3. 修改配置文件
我们以yolov3_mobilenet_v1_roadsign为例。
在configs/yolov3/yolov3_mobilenet_v1_roadsign.yml文件中,在下面添加如下代码:
use_swanlab: true
swanlab_project: PaddleYOLO # 可选
swanlab_experiment_name: yolov3_mobilenet_v1_roadsign # 可选
swanlab_description: 对PaddleYOLO的一次训练测试 # 可选
# swanlab_workspace: swanhub # 组织名,可选
4. 开始训练
python -u tools/train.py -c configs/yolov3/yolov3_mobilenet_v1_roadsign.yml --eval
在训练过程中,即可看到整个训练过程的日志,以及训练结束后自动生成的可视化图表。
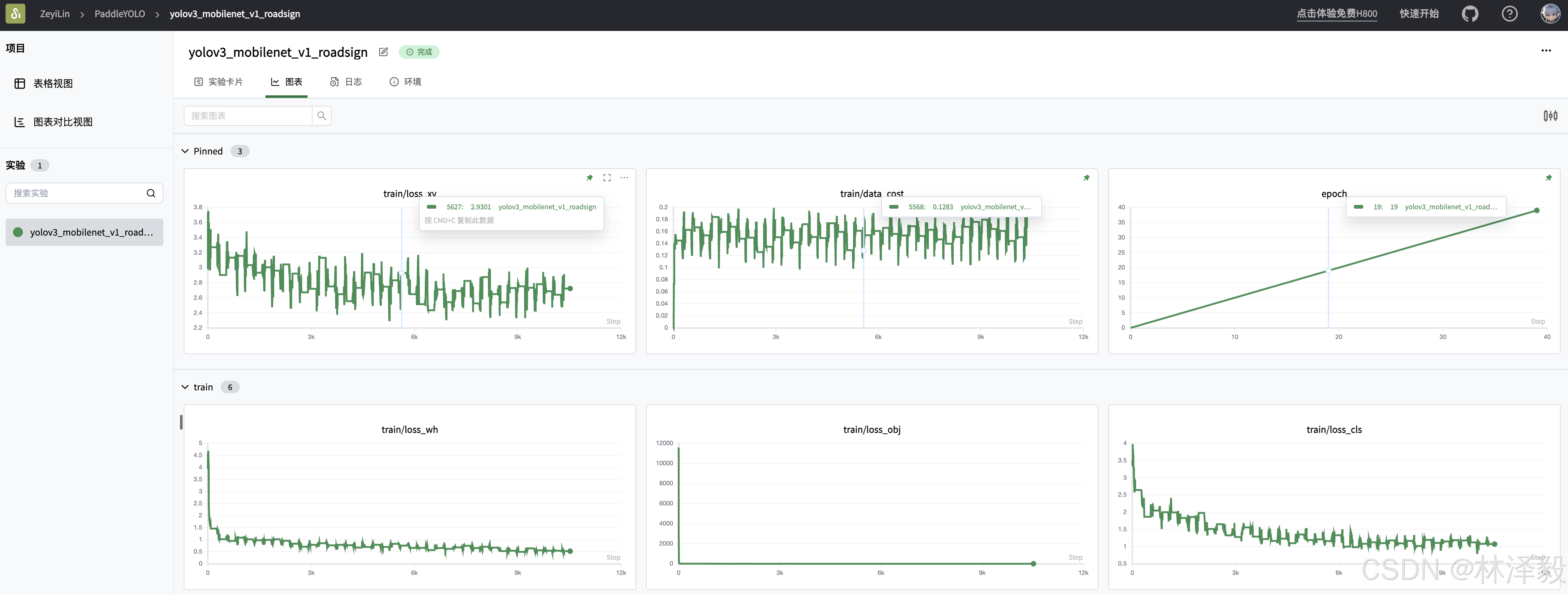
5. 相关链接
- PaddleYOLO: https://github.com/PaddlePaddle/PaddleYOLO
- SwanLab:https://swanlab.cn
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » PaddleYOLO目标检测训练(集成SwanLab可视化全过程)

发表评论 取消回复