一、简介
本篇幅主要介绍了:
- SQL中内连接(inner join)、外连接(left join、right join、full join)的机制;
- 连接关键字
on上涉及表分区筛选的物理执行及引擎优化; null在表关联时的情况与执行;
内容适用于常见大数据计算引擎,诸如hive、tez、sparksql、presto(trino)等。考虑到后续引擎版本迭代,具体执行以物理执行计划为准,查看执行计划只需再SQL最前方加上explain关键字即可,比如:explain select t1.id,t2.id as id2 from tablename1 t1 join tablename2 t2 on t1.id=t2.id
阅读者适用于SQL入门还没弃坑的同学。
二、有关sql中null的解读
1. 空这个概念
sql中,人们称之为空,一般有三种解释:
- 空字符串,
'' - 不合理,不存在,比如小孩的年龄,如果xx用户都没有小孩,那就不存在这个概念了
- 不确定,未知。sql中的null一般做该中解释,未知意味着null与null以及任何只与null的判断都是返回null;sql中的null只能用
is null才能返回true
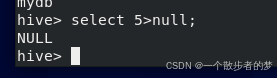
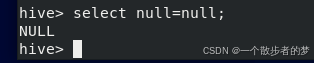
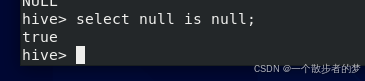
比如:select 5>null; select null=null也是返回nullselect null is null返回true
2. 当null出现在逻辑and和or条件里
and 两边都是true才返回true;select 1>null and true返回null

or 两边只要有一边是true就返回true;select 1>null or true 返回true

3. and和or的优先级
where field_name1 is not null and field_name2>100 or field_name3 is not null and field_name4>0 or field_name5 is not null
这段sql判断逻辑等于:where (field_name1 is not null and field_name2>100) or (field_name3 is not null and field_name4>0) or field_name5 is not null
先and前后判断,最后剩下几个or的或关系
为提升可读性,当涉及多个and,or条件判断时,尽量用括号括起来(如上);
如果条件放在join的on里边作用一样;
select t1.id,t2.id,t2.field_name2
from tablename1 t1
join tablename2 t2
on 1=null and t1.id=t2.id and t1.dt='20241109' and t2.dt='20241109' and t1.id>100 or t2.id<300
以上sql返回t2.id<300的笛卡尔交集
三、连接机制介绍
首先理解内连接和外连接的机制,然后再看on关键字的作用;on关键字的条件只是判断在什么情况下两个表的记录行会产生关联行为;
有表:tablename1,tablename2,两个表都是分区表,且两个表的分区字段名都是dt
1. 内连接:inner join
取交集
样例sql:
select t1.id,t2.id,t2.field_name2
from tablename1 t1
join tablename2 t2
on t1.id=t2.id and t1.dt='20241109' and t2.dt='20241109' and t1.id>100
等于(这个t1.id>100是在join之前得tablescan中filter筛选的):
sql1:
select t1.id,t2.id,t2.field_name2
from tablename1 t1
join tablename2 t2
on t1.id=t2.id
where t1.dt='20241109' and t2.dt='20241109' and t1.id>100 and t2.id is not null
等于sql2:
select t1.id,t2.id,t2.field_name2
from (select id from tablename1 where dt='20241109' and t1.id>100) t1
join (select id,field_name2 from tablename2 where dt='20241109' and is not null) t2
on t1.id=t2.id
需要注意的是,有一种sql写法,表里没有join,实际也是按inner join走的,比如下面这段sql:
select t1.appid,t1.target,t1.sq,t2.product_type
from ads_mg_core_target_value t1 ,dim_game_info t2
where t1.appid=t2.appid
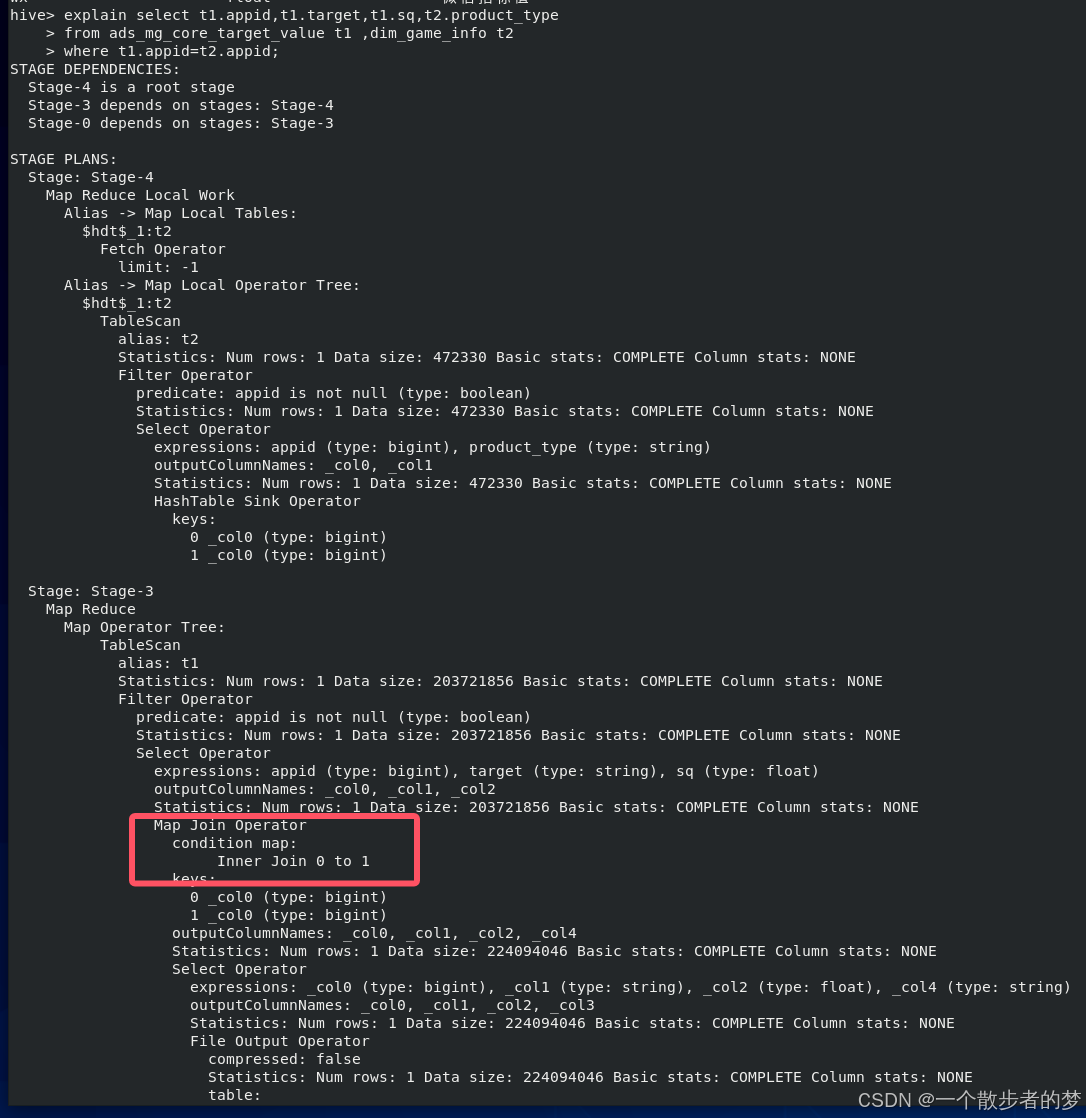
我们打印下执行计划:
explain select t1.appid,t1.target,t1.sq,t2.product_type
from ads_mg_core_target_value t1 ,dim_game_info t2
where t1.appid=t2.appid
我这里装的是单机hive,且表体量都很小,所以打印的执行计划最后走的是mapjoin
我们把自动mapjoin给关掉,再看下:set hive.auto.convert.join=false;
这时候显示的是reduce join了
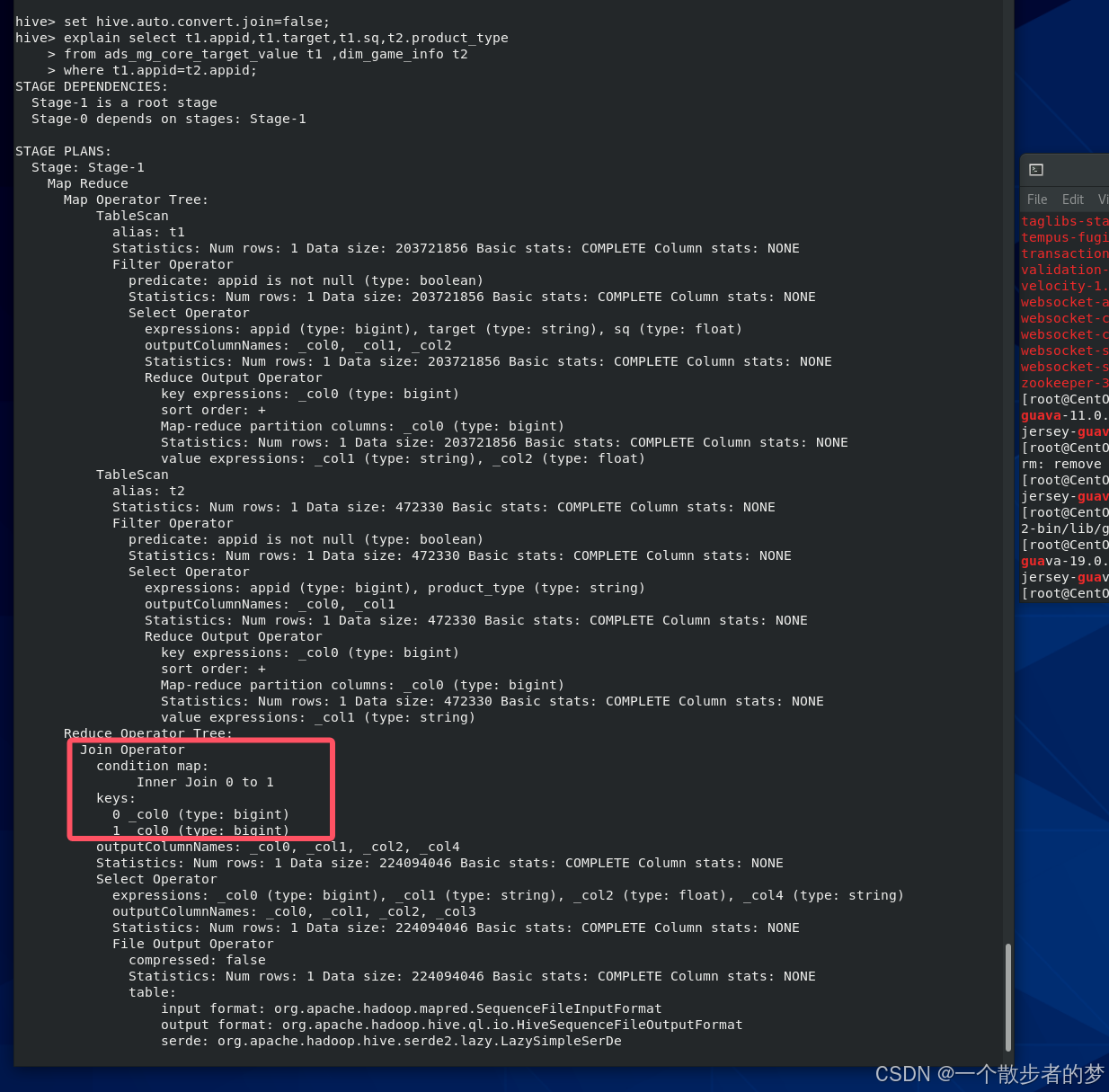
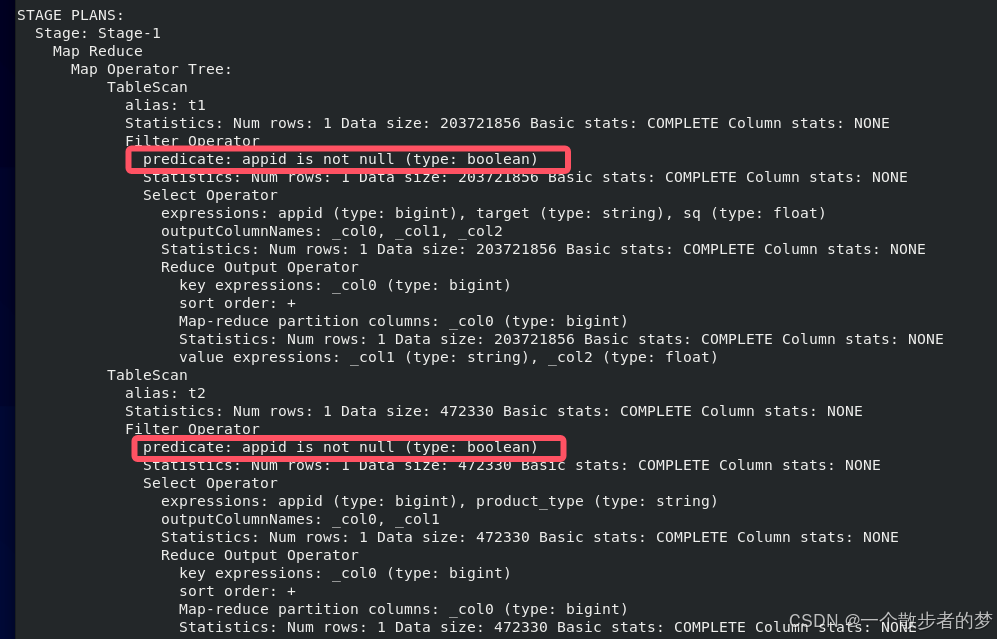
以上三个sql案例,两个表都只读了20241109一个分区的数据,且t1.id>100都是在读分区map时扫描过滤的(引擎优化)
因为null与任何的判断最终都是返回null(除了isnull判断),所以当sql不涉及isnull判断时,对于on量表关联的字段,引擎会做优化,在tablescan表扫描时将null值给剔掉,故inner join不存在null的倾斜(在map时全剔掉了)
2. 左右连接:left join | right join
left join 跟right join的机制大致等同,一个保留左表全部数据(left join),一个保留右表全部数据(right join)
我们还是以上面的sql为案例,改成left join
sql-1
select t1.id,t2.id,t2.field_name2
from tablename1 t1
left join tablename2 t2
on t1.id=t2.id and t1.dt='20241109' and t2.dt='20241109' and t1.id>100
这段sql如果t1表全量数据体量很大,那就是灾难了,tablename1全表扫描,因为left join保留左表全部数据。大概率是写sql的人sql写错了;tablename2表只读了一个分区;对于not (t1.dt='20241109' and t1.id>100)部门,on没有符合的条件,t2.field_name2全都是null;
不等于
sql-2
select t1.id,t2.id,t2.field_name2
from tablename1 t1
left join tablename2 t2
on t1.id=t2.id
where t1.dt='20241109' and t2.dt='20241109' and t1.id>100
不等于sql-3(因为最后还是筛选了t2.dt=20241109,所以这段等于两者取inner join,且t1只扫描了20241101一个分区):
select t1.id,t2.id,t2.field_name2
from tablename1 t1
left join tablename2 t2
on t1.id=t2.id and t1.dt='20241109' and t1.id>100
where t2.dt='20241109'
等于sql-4:
select t1.id,t2.id,t2.field_name2
from tablename1 t1
join (select * from tablename2 where dt='20241109' where id is not null) t2
on t1.id=t2.id and t1.dt='20241109' and t1.id>100
3. 全连接:full join
全量接,左右会保留左右两边表的所有记录行,对于on关联不上的,被关联表的字段返回null。
sql-1
select t1.id,t2.id,t2.field_name2
from tablename1 t1
full join tablename2 t2
on t1.id=t2.id and t1.dt='20241109' and t2.dt='20241109' and t1.id>100
这个表最后就是tablename1和tablename2两个表都全表扫描,只有当on条件成立是才会映射被关联表字段,其他关联不上的,被关联表该字段都是null;
如果要筛选分区及条件后再用id full join,只能先用子查询改写再join
select t1.id,t2.id,t2.field_name2
from (select t1.id from tablename1 where id>100 and dt='20241109') t1
full join (select id,field_name2 from tablename2 where dt='20241109') t2
on t1.id=t2.id
现在有两个表:
两个表用id字段full join,也就是t1 full join t2 on t1.id=t2.id
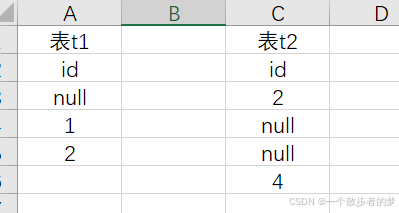
那么结果返回几条呢?
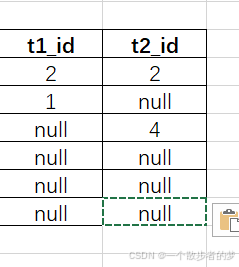
因为null与任何非isnull判断都是返回null,full join保留左右表全部数据,所以该段sql一共返回6行数据,测试sql:
select t1.id as t1_id,t2.id as t2_id
from
(
select null as id
union all
select 1 as id
union all
select 2 as id
) t1
full join
(
select 2 as id
union all
select null as id
union all
select null as id
union all
select 4 as id
) t2
on t1.id=t2.id
order by t1.id desc,t2.id desc
实际返回如下:
4. left semi join
这是一种特殊的join,sql中in/exists的实现。相比普通inner join,匹配到一条数据就无须再尝试匹配其他数据了。inner join遇到重复会发散;left semi join只会返回左表的部分(仅on的key参与计算);语法支持的情况,也可以用in去改写。具体看执行计划。
5. 多表关联
当存在多表关联时,一般的执行顺序是从左往右走,比如:
tablename1 t1
left join tablename2 t2
on t1.id=t2.id
join tablenamme3 t3
on t1.id2=t3.id2
先t1跟t2 left join,结果再跟t3 join;
有的引擎会基于成本优化,调整join顺序,以上sql可能物理执行时这样的(因为两者结果是等同的,如果t2表很小,t3表很大,可能会做出这种优化,具体看物理执行):
tablename1 t1
join tablenamme3 t3
on t1.id2=t3.id2
left join tablename2 t2
on t1.id=t2.id
也会有一种情况,如果多表关联on的关联条件是相同的,比如(都是id):
tablename1 t1
left join tablename2 t2
on t1.id=t2.id
join tablenamme3 t3
on t1.id=t3.id
看起来有两个join,实际在大数据中,只跑了一段mr,map时读取三个表的数据,reduce左两个join的关联再返回。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » SQL中的内连接(inner join)、外连接(left|right join、full join)以及on关键字中涉及分区筛选、null解释

发表评论 取消回复