延续上一篇文章,不懂的宝子们请看以下链接:

目录
(1) 、根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门编号:
一、Group by 语句
(1)、计算emp表每个部门的平均工资
select t.deptno,avg(t.sal) avg_ sal from emp t group by t.deptno;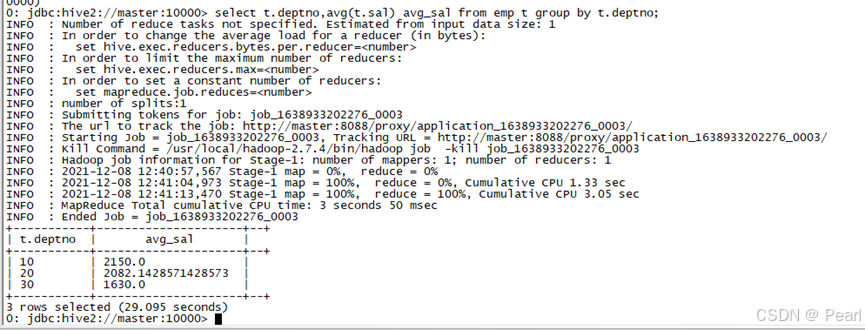
(2)、计算emp表每个部门中每个岗位的最高工资
select t.deptno, t.job,max(t.sal) max_sal from emp t group by t.deptno, t.job;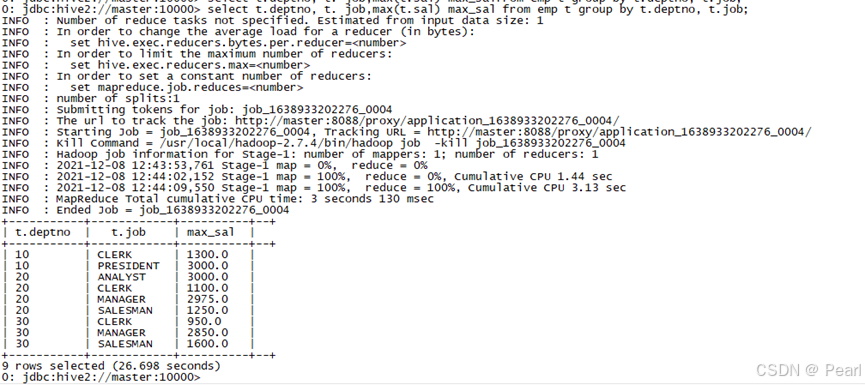
二、Having 语句
(1)、求每个部门的平均工资
select deptno,avg(sal) from emp group by deptno;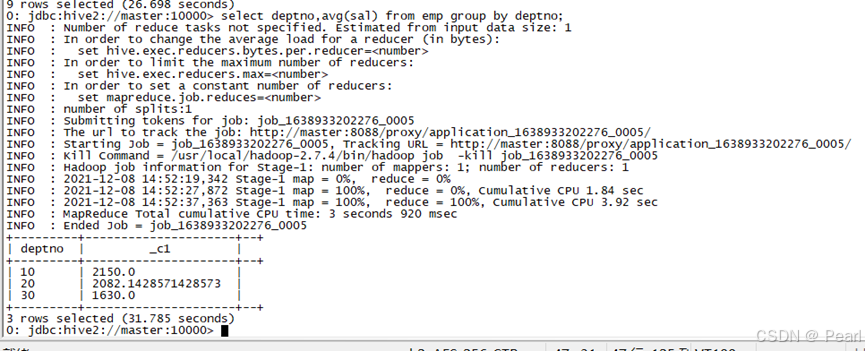
(2)、求每个部门的平均工资大于22000的部门
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal >2000;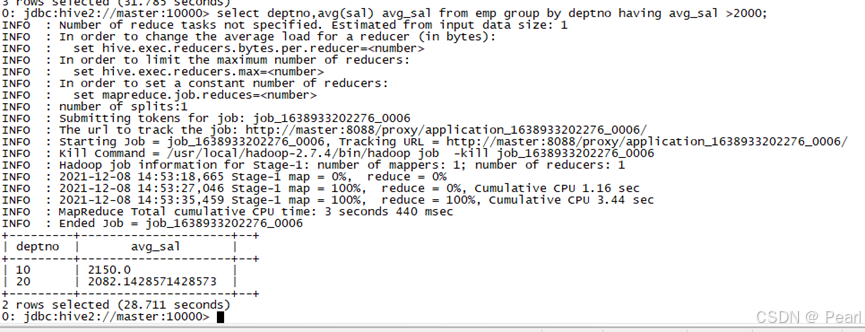
三、Order by 语句
(1)、查询员工信息,按工资降序排列
select * from emp order by sal desc;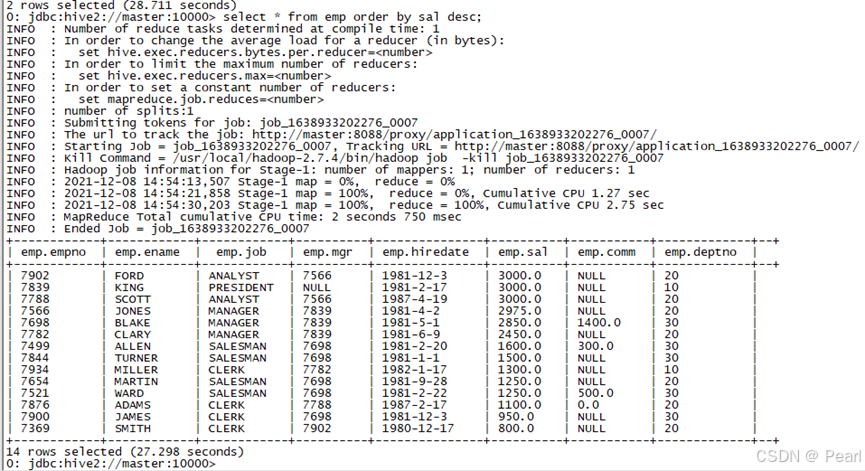
(2)、按照部门和工资升序排序
select ename, deptno, sal from emp order by deptno,sal;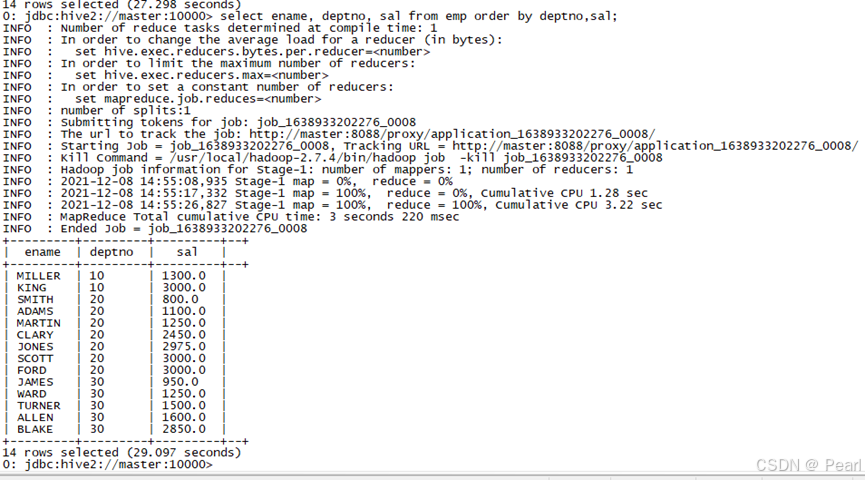
四、Sort by语句
(1)、设置reduce个数
set mapreduce.job.reduces=3;(2)、查看设置reduce个数
set mapreduce.job.reduces;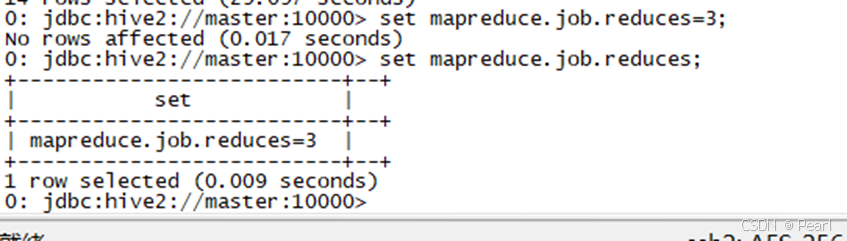
(3)、根据部门编号降序查看员工信息
select * from emp sort by empno desc;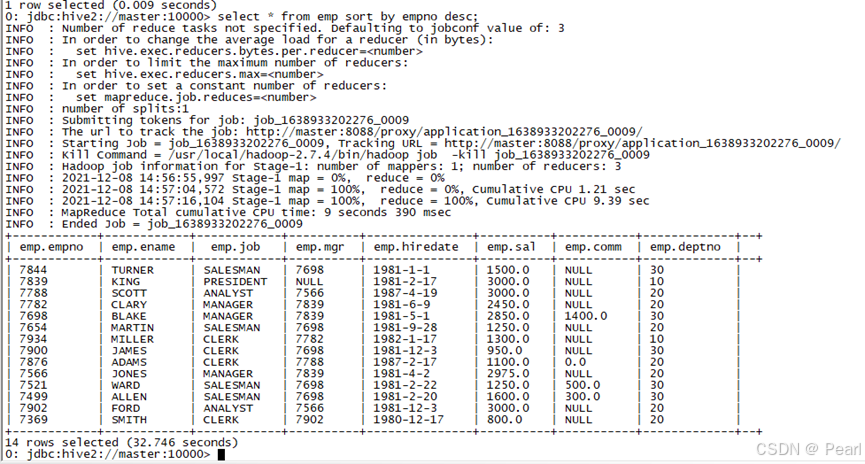
(4) 、将在询结果导入到文件中(按照部门编号降序排序)
insert overwrite local directory '/root/sortby-result' select * from emp sort by deptno desc;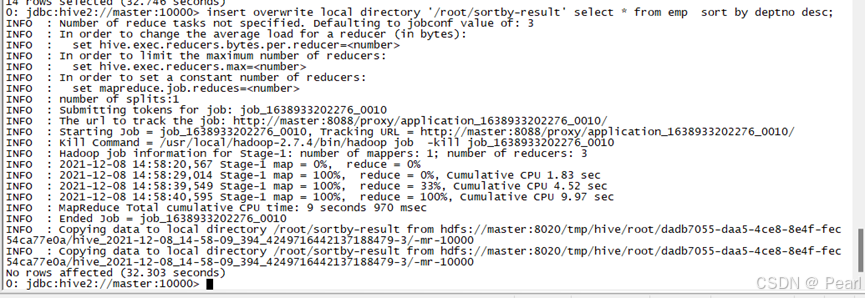
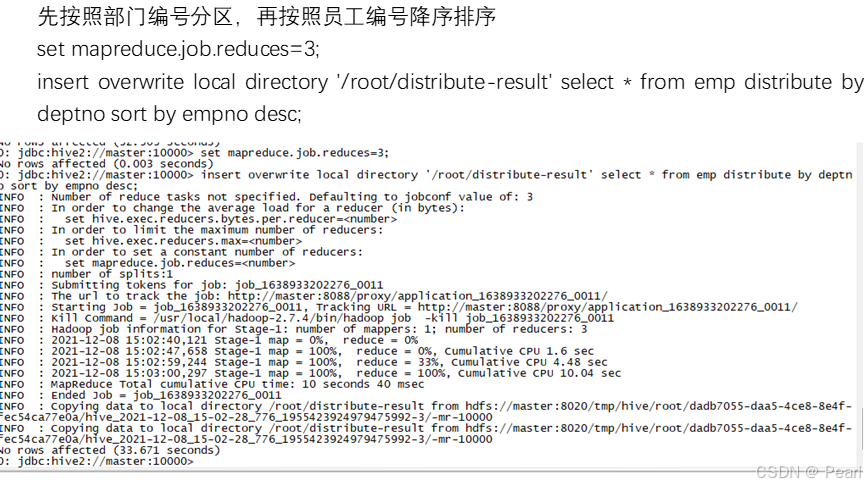
五、Distribute by
六、Cluster by
以下两种写法等价:
select * from emp cluster by deptno;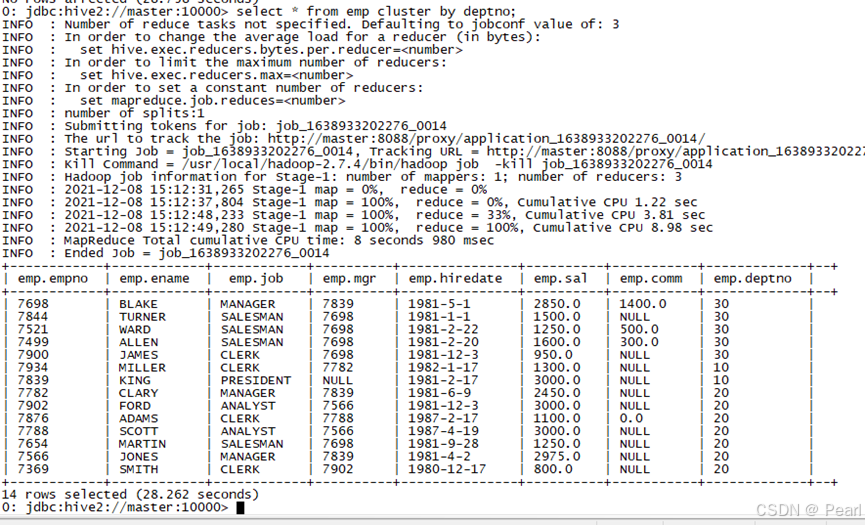
select * from emp distribute by deptno sort by deptno;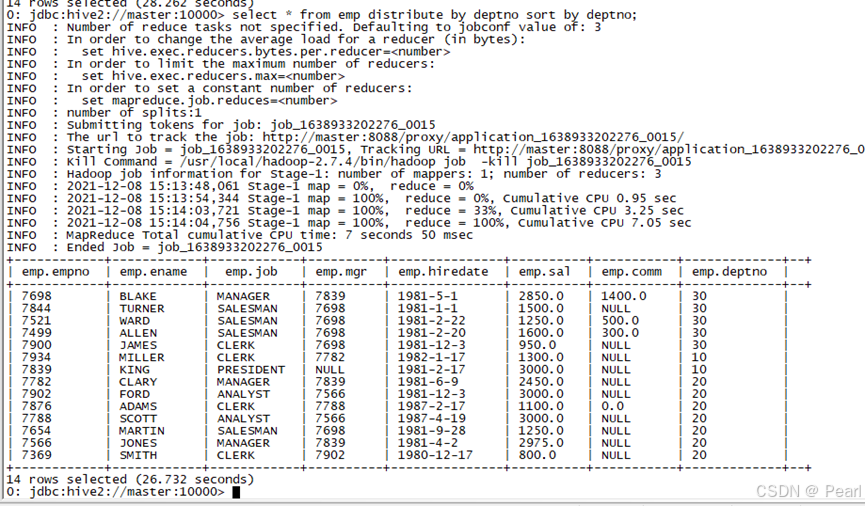
七、Join 操作
(1) 、根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门编号:
select e.empno, e.ename,d.deptno,d.dname from emp e join dept d on e.deptno=d.deptno;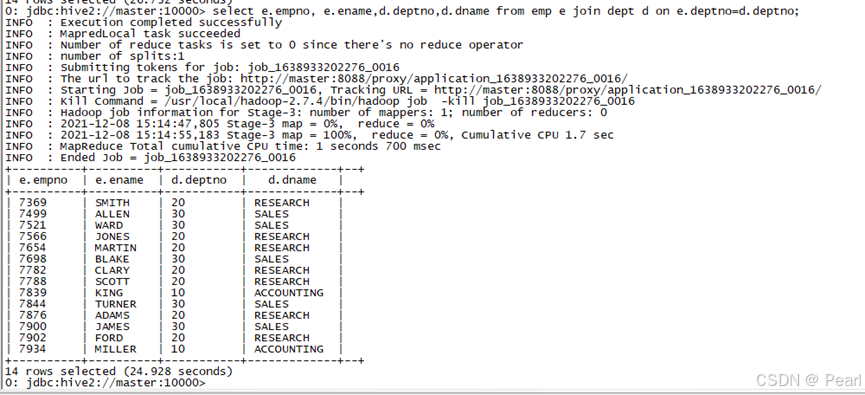
(2)、左外连接
Join操作符左边表中符合条件的所有记录将会被返回。
select e.empno, e.ename,d.deptno,d.dname from emp e left join dept d on e.deptno=d.deptno;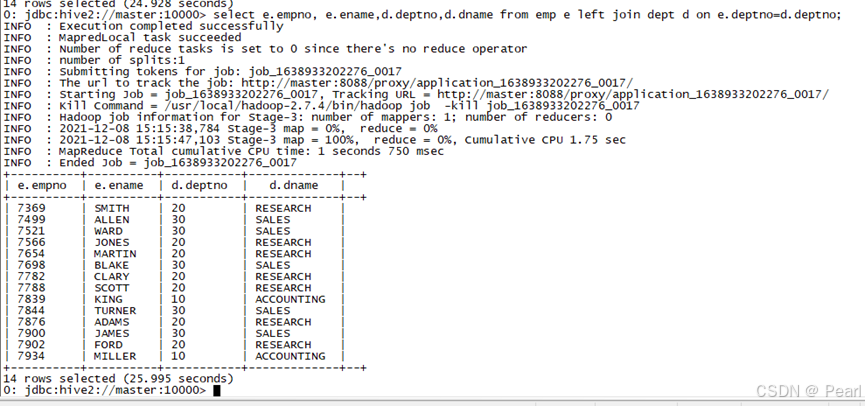
(3)、右外连接
Join操作符右边表中符合条件的所有记录将会被返回。
select e.empno, e.ename,d.deptno,d.dname from emp e right join dept d on e.deptno=d.deptno;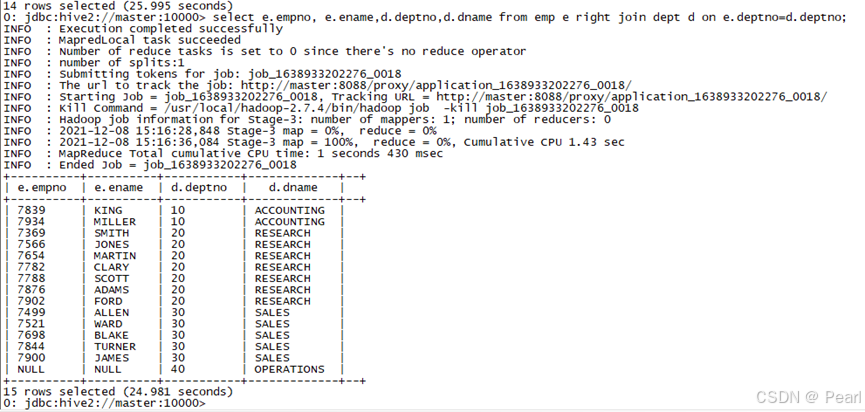
(4)、满外连接
返回所有表中符合条件的所有记录,如果任一-表的指定字段没有符合条件的值的话,那么就使用NULL值替代。
select e.empno, e.ename,d.deptno,d.dname from emp e full join dept d on e.deptno=d.deptno;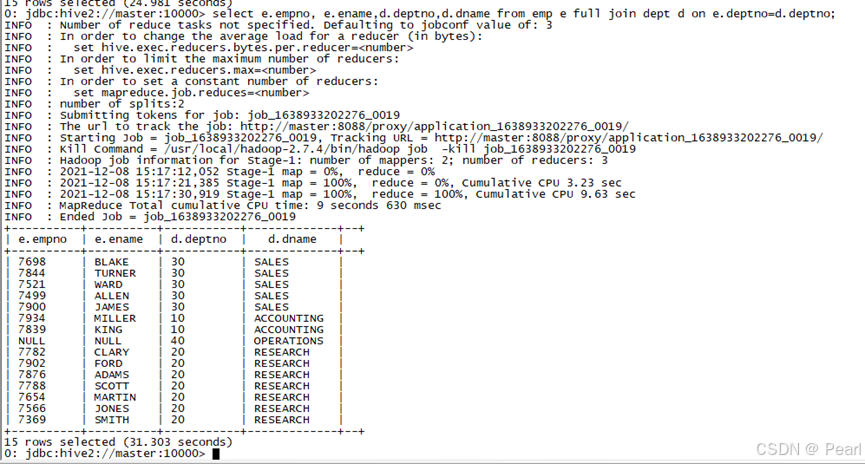
在使用Join语句时,如果想限制输出结果,可以在Join语句后面添加Where语句,进行过滤。
select e.empno, e.ename,d.deptno,d.dname from emp e full join dept d on e.deptno=d.deptno where d.deptno=20;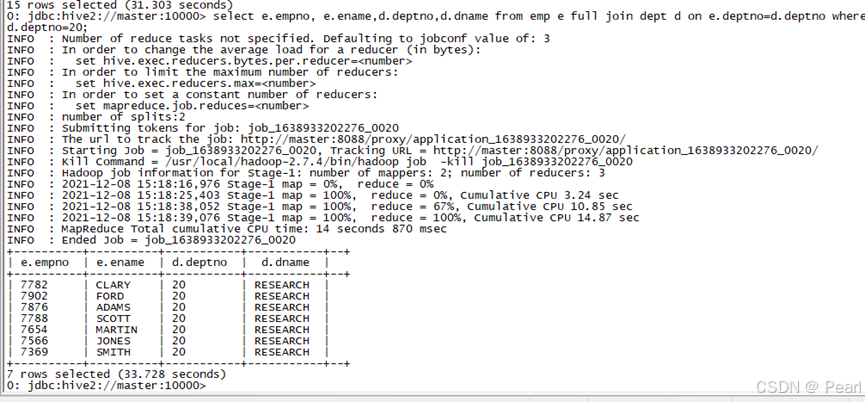
学习到这里就完结啦~不懂的宝子请私信哦!

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Hadoop实训】Hive 数据操作②

发表评论 取消回复