本节内容,给大家带来的是stable diffusion的基础模型课程。基础模型,我们有时候也称之为大模型。在之前的课程中,我们已经多次探讨过大模型,并且也见识过一些大模型绘制图片的独特风格,相信大家对stable diffusion大模型已经有了一定的了解。使用不同的大模型,绘制的图片风格,内容,精细程度都会有所区别,本节课我们会详细讲述stable diffusion的常见大模型以及他们的特征。
我们前面的课程中已经讲解过如何使用好的提示词来引导stable diffusion生成图片。
但是,如果使用早期的官方基础模型,比如sd1.5,实际上,我们即使设计了非常好的提示词以及参数,比如之前使用过的提示词:
masterpiece,(best quality:1.3),ultra high res, raw photo, chilly nature documentary film photography, style: realistic pictures, 1girl, detailed skin, a clear face, snow mountain environment, natural light
生成的图片可能是这样的。
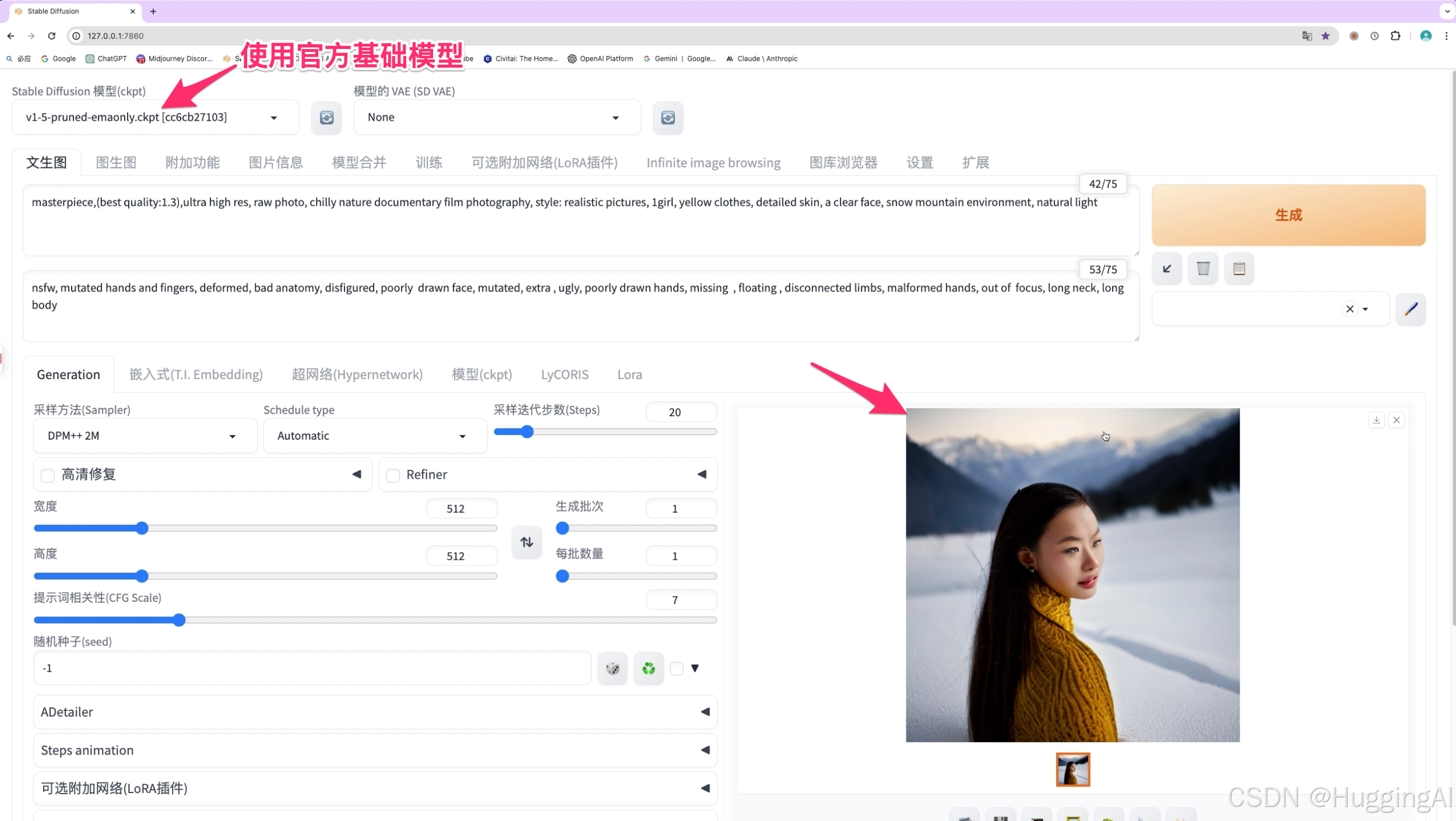
这是因为我们现在使用的是最原始的官方基础模型,这些原始官方基础模型是范性的,在图片绘制的过程中能适应广泛的场景,但没有特别的倾向和偏好,也没有针对人物等要素进行特别的调优,尤其对于早期官方基础大模型,AI的随机性很有可能使sd绘制出比较诡异的图像,或者出图质量不及我们的预期。而对于新一些的官方基础模型则在出图时稳定性更高,比如sdxl,SD3,SD3.5等。
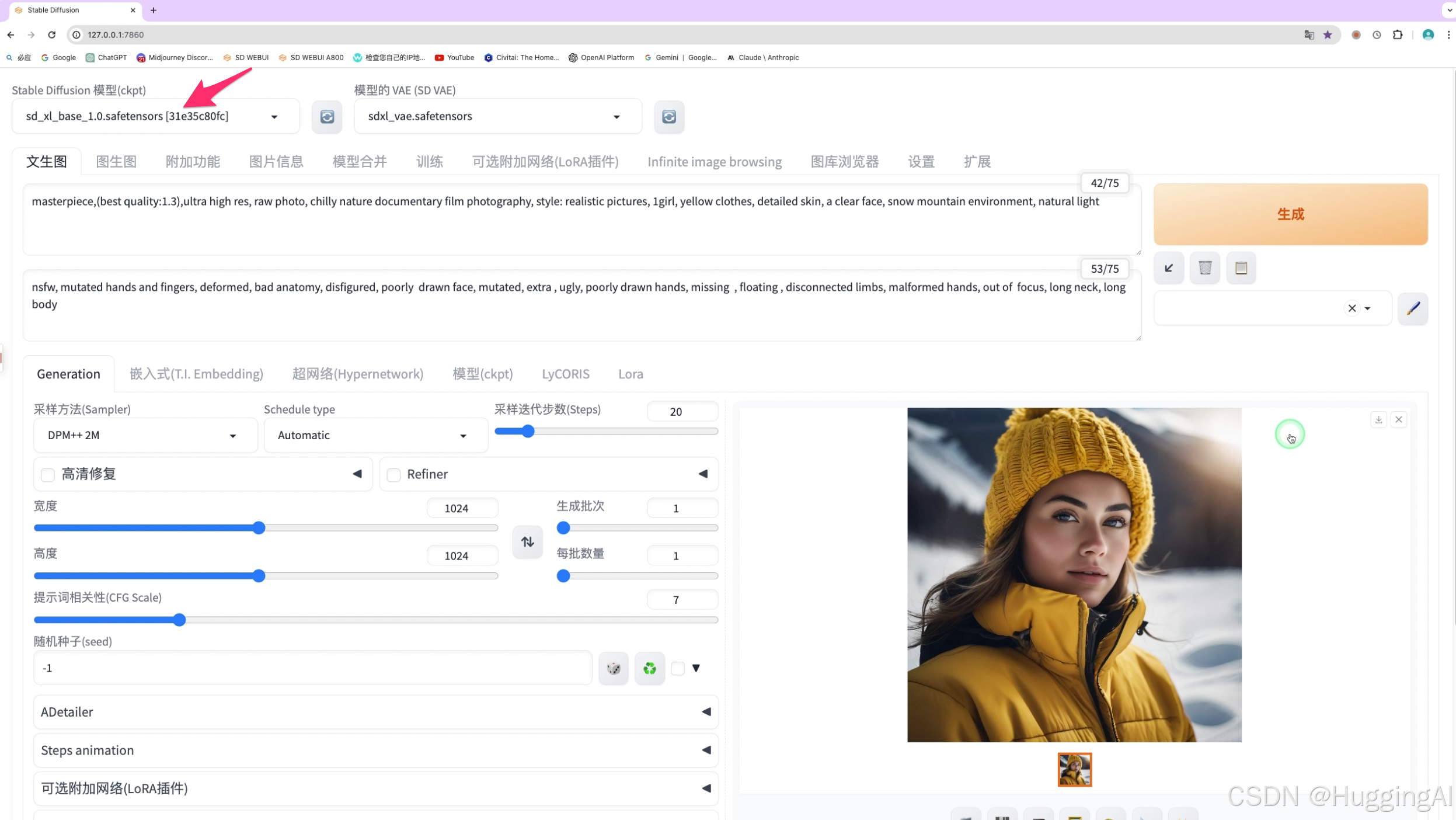
虽然新的模型稳定性更高,但同样有时也会绘制出奇怪的图像。
如果想要生成符合预期的高质量图片,我们需要借助一些其他的技术方案。比如我们可以使用基于官方模型微调训练后的大模型。
这些大模型通常是采用DreamBooth方案,利用定制的图像数据对预训练的Stable Diffusion基础模型进行微调,使模型在保持其原有生成能力的同时,能够生成与提供的样本图像相似的内容。采用该方案构建的是新的基础大模型。我们也可以使用Lora,LyCoris或者hypernetwork等来引导模型生成特定风格或特色的图像,这些知识,我们会在后续的课程中陆续讲解,本节课程,我们主要讲解各类大模型的使用。

一:官方基础模型
我们先来看一看stable diffusion有哪些官方基础模型。
目前为止stable diffusion陆续推出了多个版本的官方基础模型
包括SD1.4, SD1.5, SD2.0, SD2.1,SDXL,SD3,SD3.5等
Stable diffusion整个生态由公司实体 StabilityAI 和 RunwayML 等为代表共同领衔推进。
SD 1.4模型由StabilityAI推出,通过评测,1.4与1.5区别不大,但光源效果不如1.5平滑合理,色阶对比度和光源渲染也不如1.5
SD1.5模型则是由RUNWAY出品(GEN-2),该模型也是目前为止使用最多的基础模型,因为我们平常使用到的很多大模型都是基于该基础模型训练而来,我们去C站看一下,我们进入C站,点击上方菜单的models,然后点击Base Model只显示基础模型,
选择一个checkpoint基础模型,我们点击进入模型主页后,在右边部分可以看到模型的基础信息,
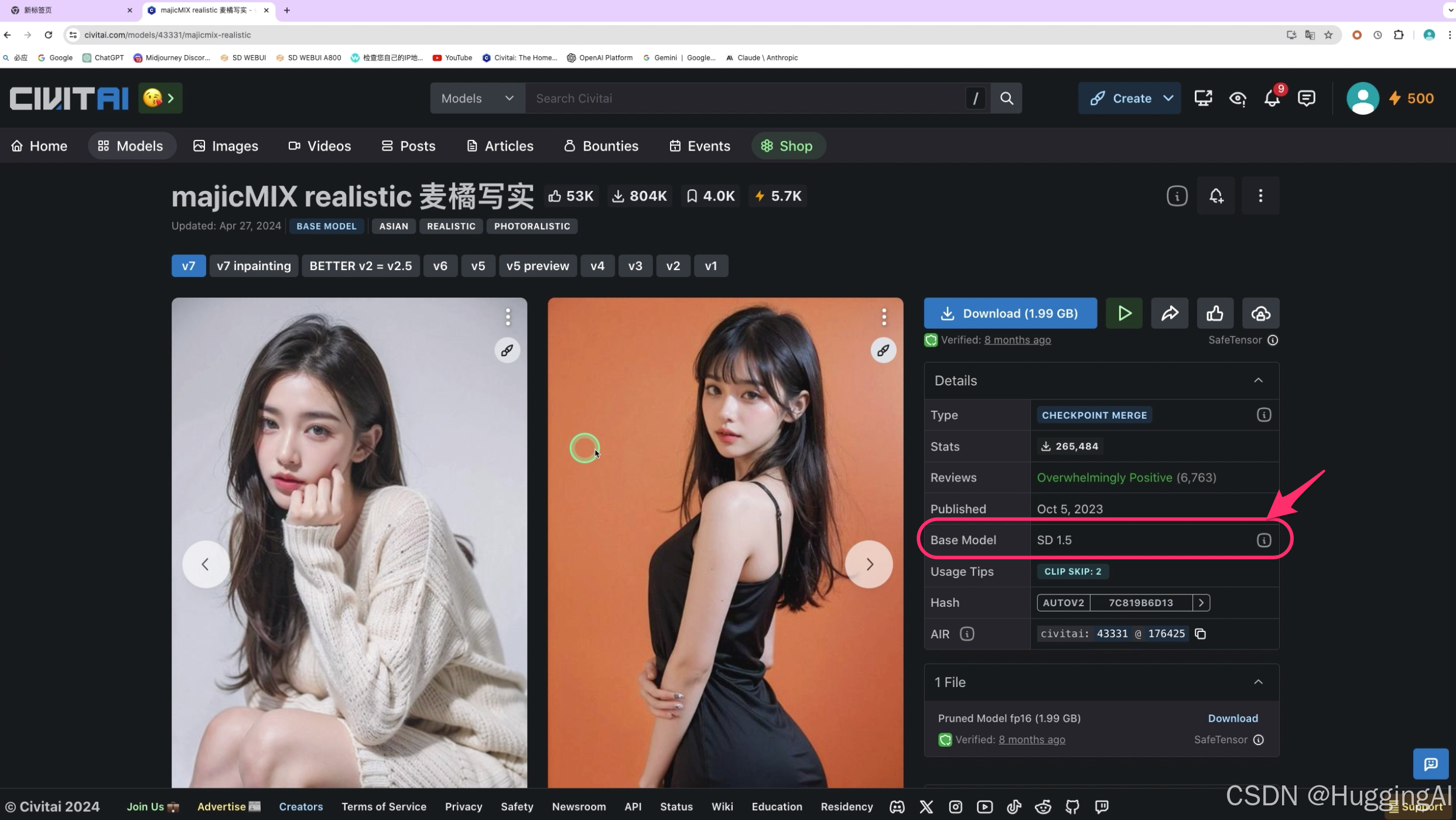
可以看到这些大模型的Base Model都是1.5,比如我们之前有用到的majicMIX,abyssorangemix 以及另外一些常用大模型,这些模型,其Base Model底模都是SD1.5。当然,目前,也有很多基于其他官方基础模型的大模型,比如我们点击过滤图片,过滤选择只展示sdxl1.0的大模型,可以看到采用sdxl1.0作为底模的大模型列表。
SD 2主要包含2.0和2.1版本,SD2系列模型由StabilityAI推出,相比早期的SD1系列模型,SD2加入了严格的内容过滤规则,某些不合适的图像元素在该模型下会被禁止;另外,SD2在非标准分辨率的图像,建筑、室内设计、野生动物和景观场景方面的图像质量上有较大提升。

SDXL模型是在SD2之后推出的模型,我们在之前的课程中也有使用过。SDXL陆续推出了多个子版本的模型,SDXL系列模型采用了更多的训练数据以及更大的模型结构,从而能够生成更高分辨率、更细腻和更逼真的图像,在处理复杂的图像文本提示时,SDXL也能够更加稳定地生成符合预期的结果,减少生成过程中的异常或不一致。SDXL通常对硬件资源的要求更高,比如一般推荐在16G以上显存GPU以及32G以上内存的主机或服务器来执行操作。

SD3.5模型则是官方最新推出的基础模型,SD3.5可以通过官方地址 https://github.com/Stability-AI/sd3.5 中的链接下载。
SD3.5模型性能以及提示词系统进一步优化,并且兼顾了图像质量,图片生成速度快,能够准确响应提示,且风格控制能力非常强。

在实际使用中,我们可能较少会直接使用这些官方提供的基础大模型。我们之前提到过,stable diffusion是开源模型,有着积极和活跃的社区资源。而其中,众多爱好者基于官方基础模型训练了各具特色的新的基础大模型,使用这些大模型所绘制的图片,无论是质量,还是风格特色上,都比基础模型有着更好的应用场景。
我们可以从C站和liblib上找到很多优秀的大模型,需要提醒的是,C站是国外站点,目前需要一定方法才能正常访问。而哩布哩布是国内站点,对国内普通用户更加友好。
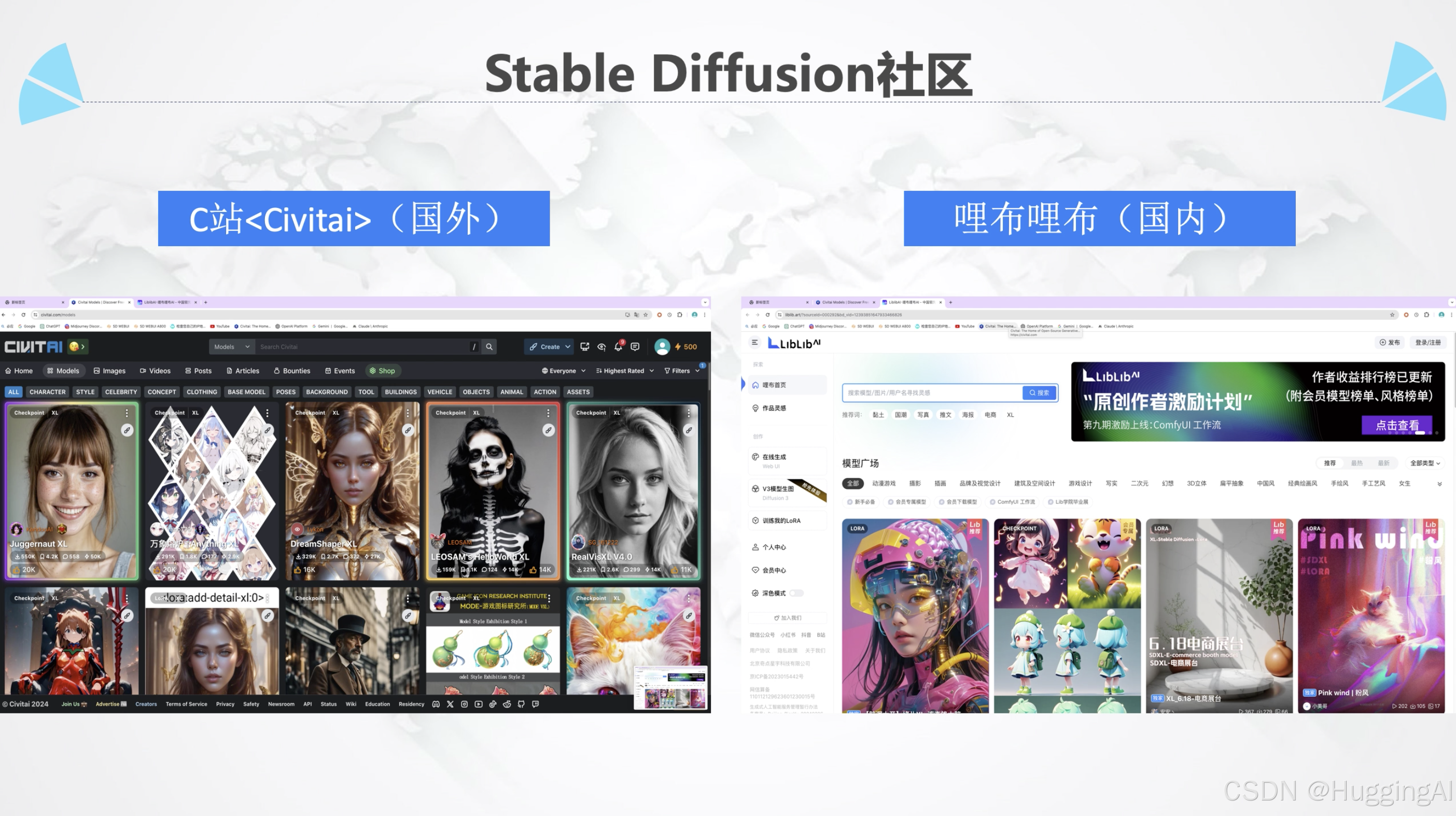
因为C站目前是stable diffusion最具影响力的社区,所以我们这里以C站为例来演示。
二:写实类模型
我们对这些大模型做了一些总结和分类:
比如写实类模型,写实类模型擅长绘制人物写实图片
在C站上,majicMIX realistic是非常流行的入物写实模型,比较适合亚洲人,我们可以演示一下使用该模型生成图片,我们在早前安装课程中已经演示过如何在C站查找模型,我们可以在C站首页搜索关键字majicMIX realistic
搜索结果的第一位就是我们要找的模型,注意这里卡片左上角的Checkpoint标签代表该卡片对应的是基础大模型,我们点击进入,
页面上方列出了该模型的多个版本。可以看到该模型最新的版本是V7,可以点击版本号切换不同的版本
版本列表下方,会展示一些使用该模型生成的典型示例图

在右侧则可以看到模型的详细信息,包括大小,发布时间,基础模型,可以看到,该模型的基础底模为SD1.5,也就是说,该模型是基于SD1.5,然后使用相关的资源训练而成。另外也提供了Download下载链接按钮。
在模型示例图下方,点击show more可以查看模型作者提供的说明,这里也是我们必须要强调的,在使用一个模型之前,我们务必要仔细阅读模型作者提供的说明和文档。
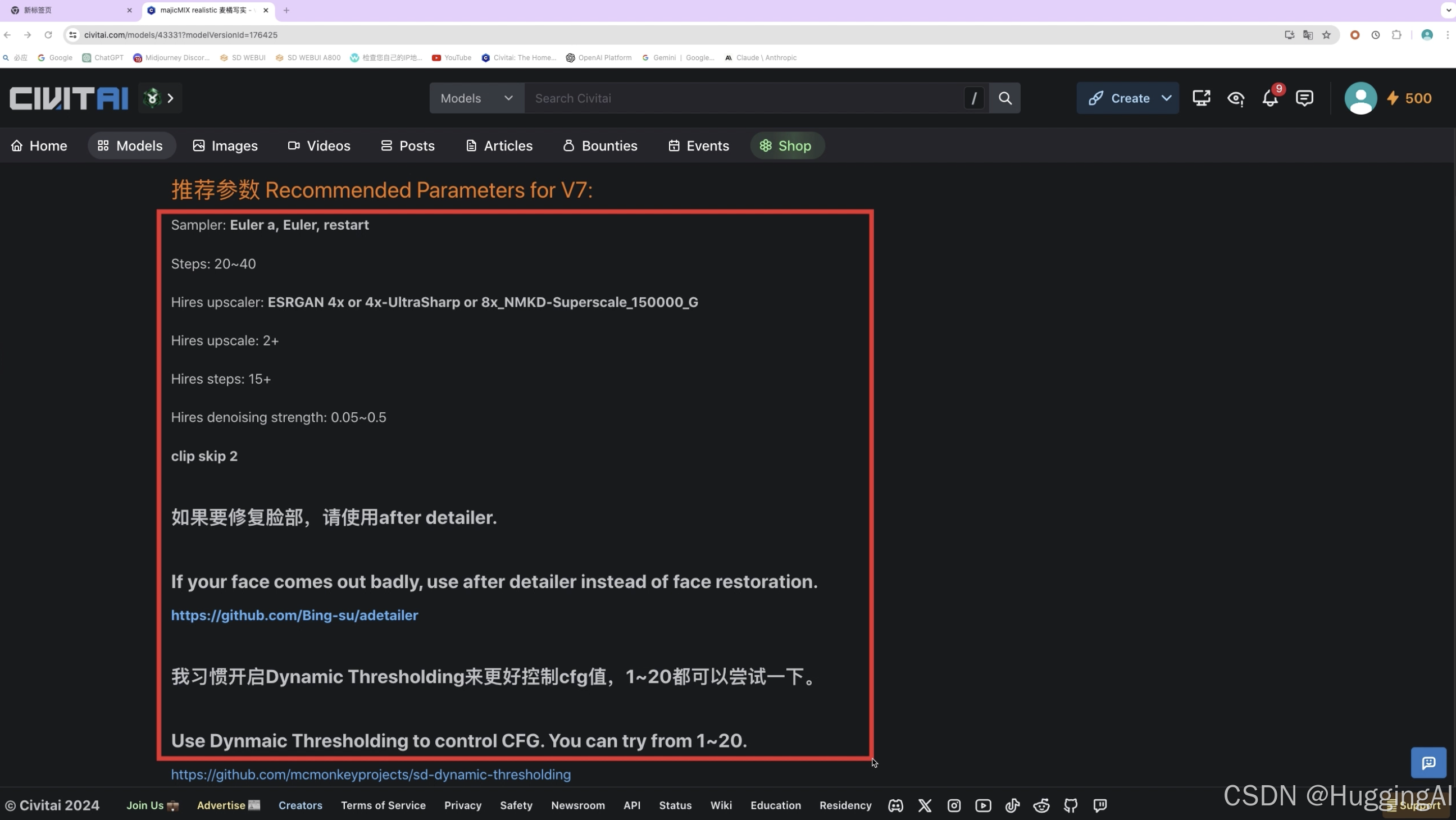
这些说明里面包含了非常多的信息,比如,推荐使用的算法,采样步数,等等,按照说明去使用该模型,才能更好地生成期望的图片,比如majicMIX realistic该模型,:
采样器推荐: Euler a, Euler, restart
迭代步数推荐设置为: 20~40
文档也提到与高清修复相关的参数
Hires upscaler: ESRGAN 4x or 4x-UltraSharp or 8x_NMKD-Superscale_150000_G
Hires upscale: 2+
Hires steps: 15+
Hires denoising strength: 0.05~0.5
clip skip 2
以及如果要修复脸部,建议使用after detailer.
这些信息对绘制图片的质量都会产生关键影响。
另外,需要注意的是,不同的版本的使用文档均在此处,使用时记得区分就好。
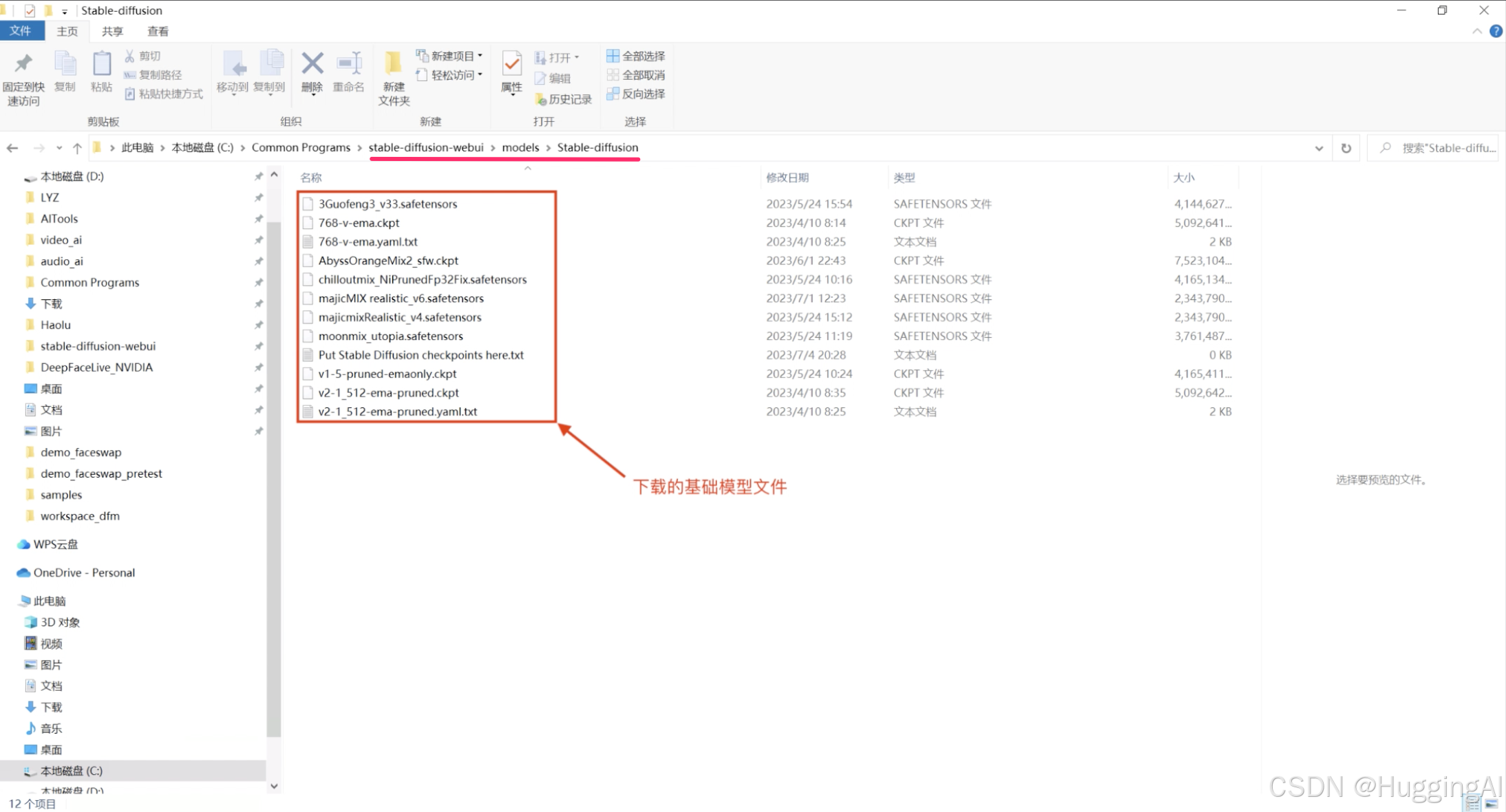
点击右侧Download按钮就可以将该模型下载到本地,checkpoint基础模型下载后应该放置到stable diffusion程序中目录下models文件夹下的Stable-diffusion子文件夹,
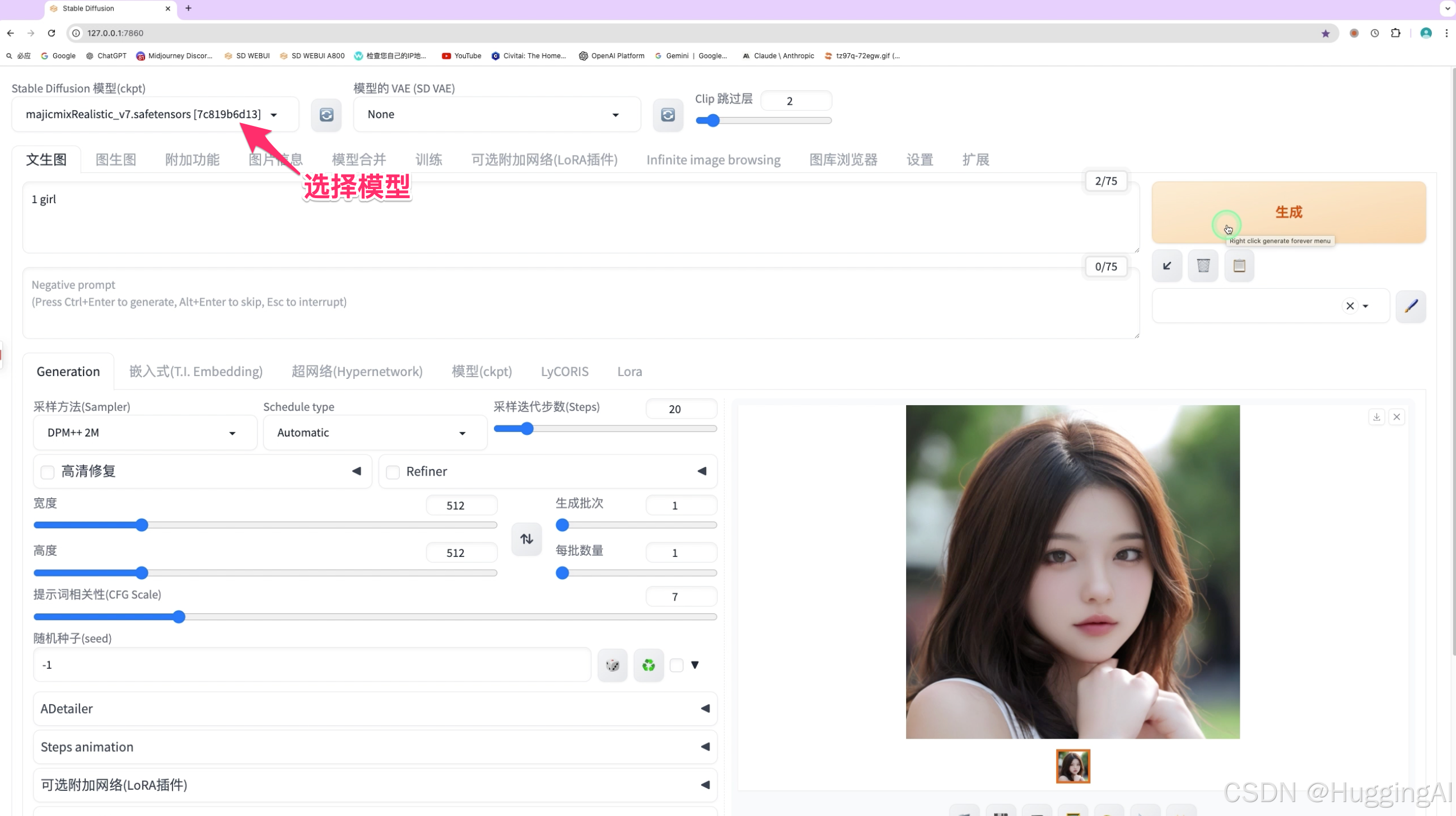
在stable diffusion webui主界面模型选择列表出点击刷新,选择下载的模型,然后按照文档书写提示词和调整参数,便可以使用该模型绘制出品质非常不错的图片。
在页面的下方,提供了关于该模型的讨论区以及Gallery图片画廊
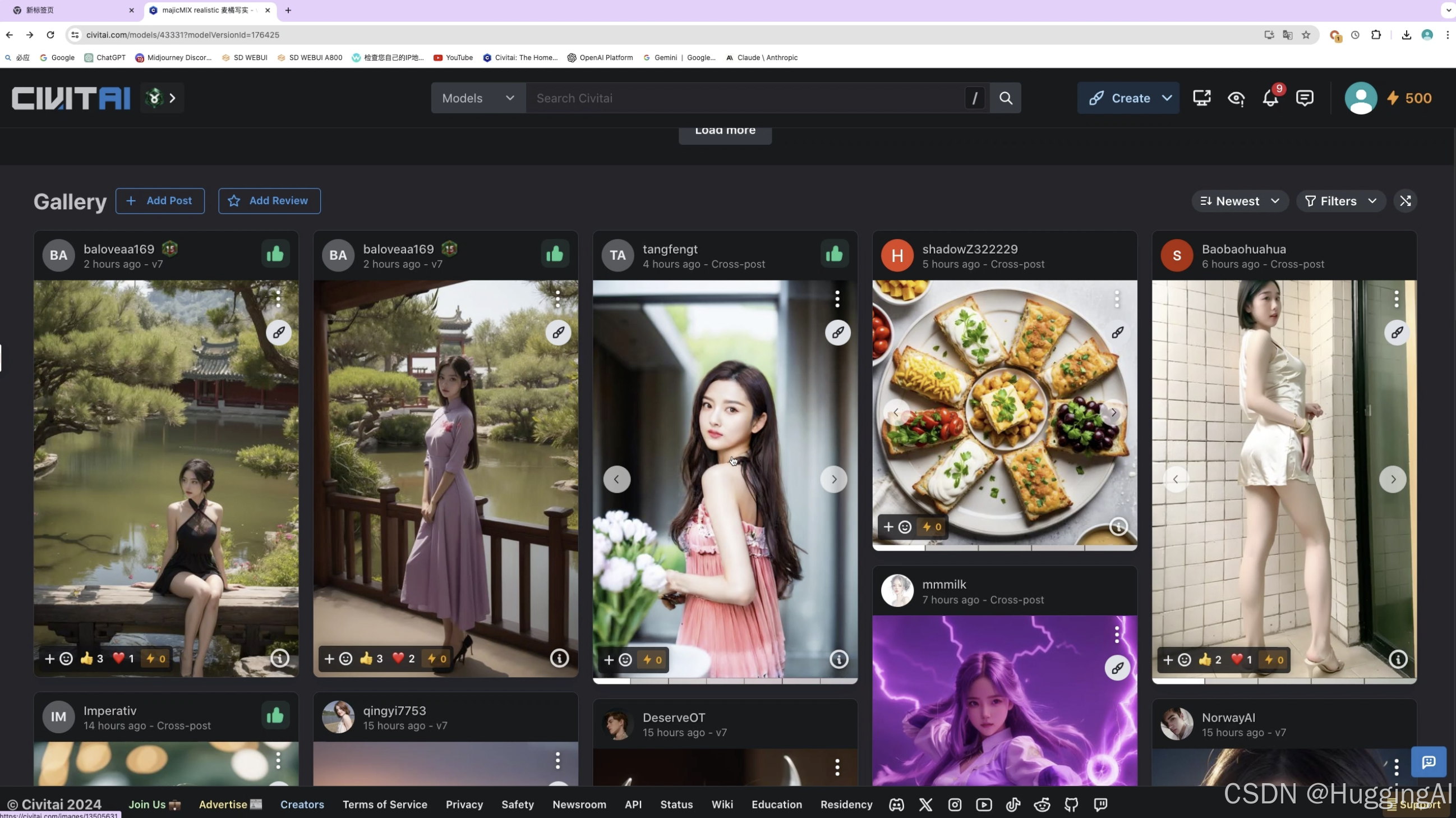
Gallery图片画廊可以浏览该模型生成的众多图片,这些图片都是爱好者们上传的,点击图片,可以查看生成对应图片所使用的提示词,参数,使用的模型,种子值等信息。
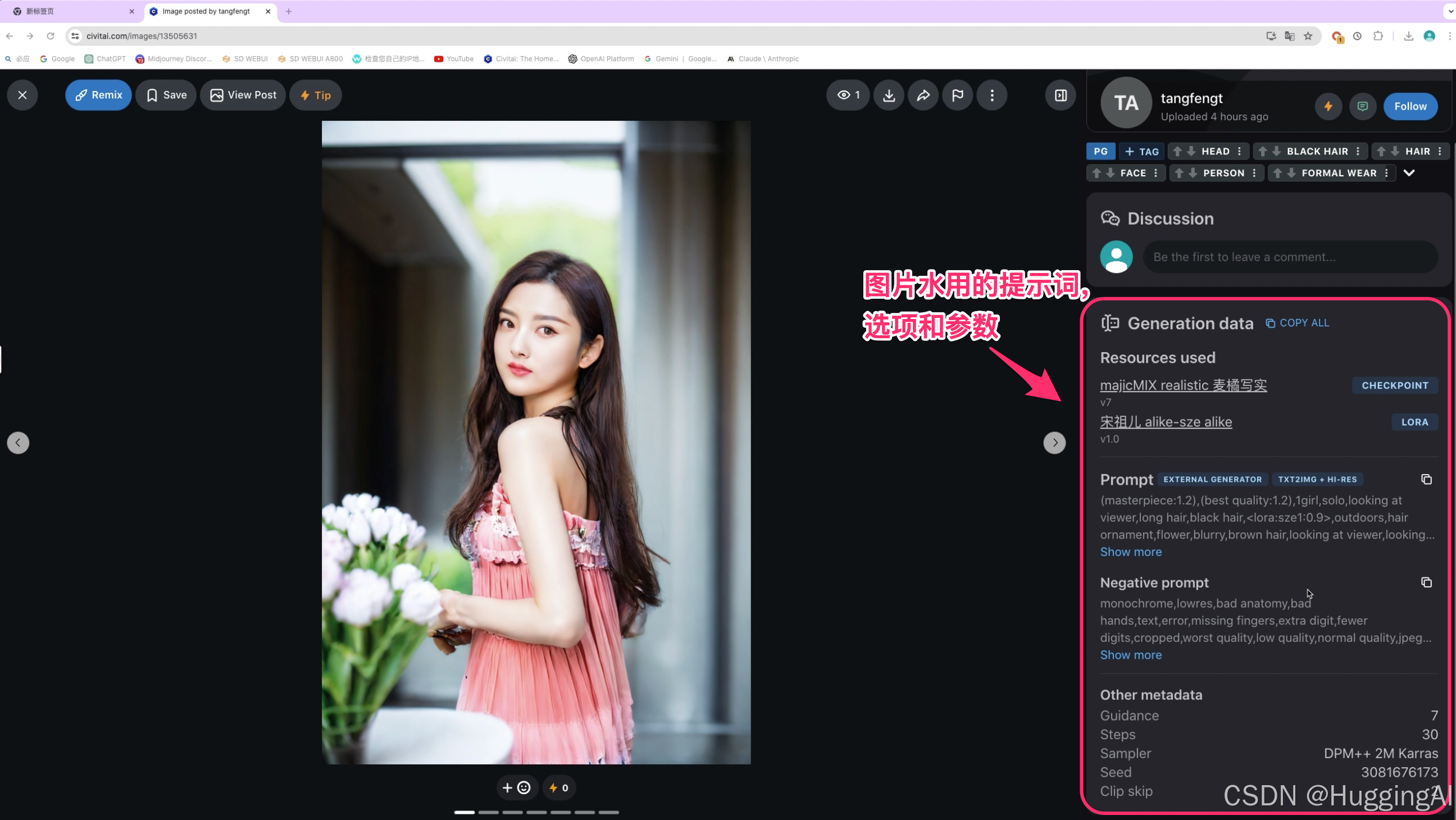
但是需要注意的是,根据我们的实践经验,有时候,完全复制提示词和参数,使用相同的基础模型,Lora模型,插件,使用相同的种子值,生成的图片也可能是有细微差别的,这是因为我们使用的某件组件版本和上传图片的用户可能不尽相同,比如扩展和插件的版本。另外,C站上图片提供的信息并不总是完整的,我们可以尝试使用上节课程中介绍的获取图片信息的方式获取完整的图像信息。
除了majicMIX realistic,还有一些写实类大模型使用度非常高,我们做了一些总结
比如Realistic Vision,该大模型表现非常全面。比较适合人物和动物,更适合西方人物形象。
CyberRealistic ,该模型也更适合西方人物图像,并且其泛化能力强,很少的提示词可以生成不错的效果。另外对lora和embedding的兼容性好。
RunDiffusion XL,该模型基于SDXL1.0官方基础模型制作,生成的图片电影质感很强,且生成汽车等实物图片的效果非常不错,同时,该模型也能生成很有艺术感的图像。

这些模型,其搜索下载和使用方式与majicMIX realistic是相同的,我们不再做具体的演示。
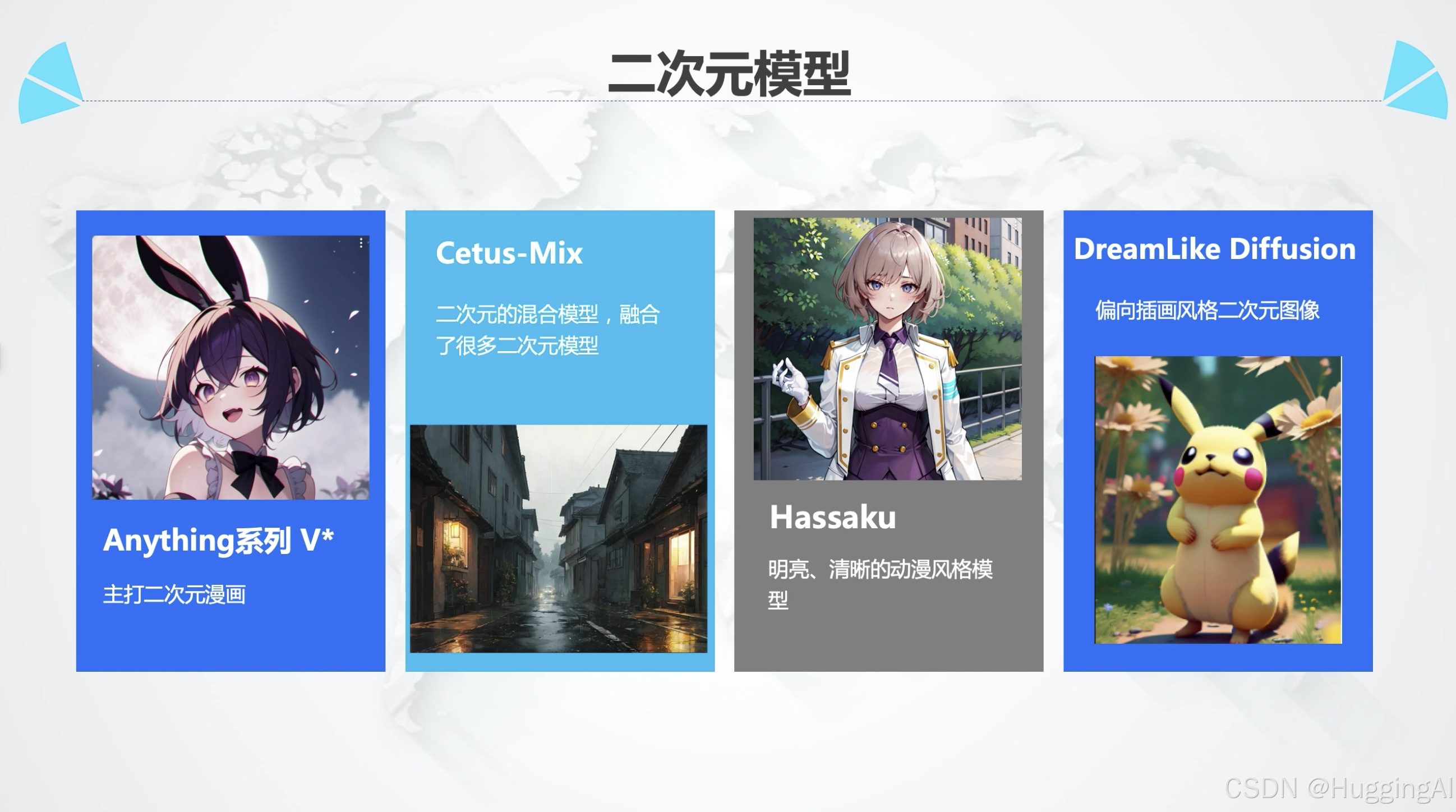
三:二次元模型
我们刚刚探讨了写实模型。接下来,我们介绍一类深受绘画爱好者喜爱的模型—二次元模型。
二次元模型更擅长生成二次元图片,包括二次元人物,场景等等。我们来看一看有哪些优秀的二次元模型
Anything系列 V*是必须要介绍的一个二次元模型,该模型的爱好和使用者非常广泛,我们在很多AI资源站点看到的那些非常精美的二次元图像都是由该模型生成。
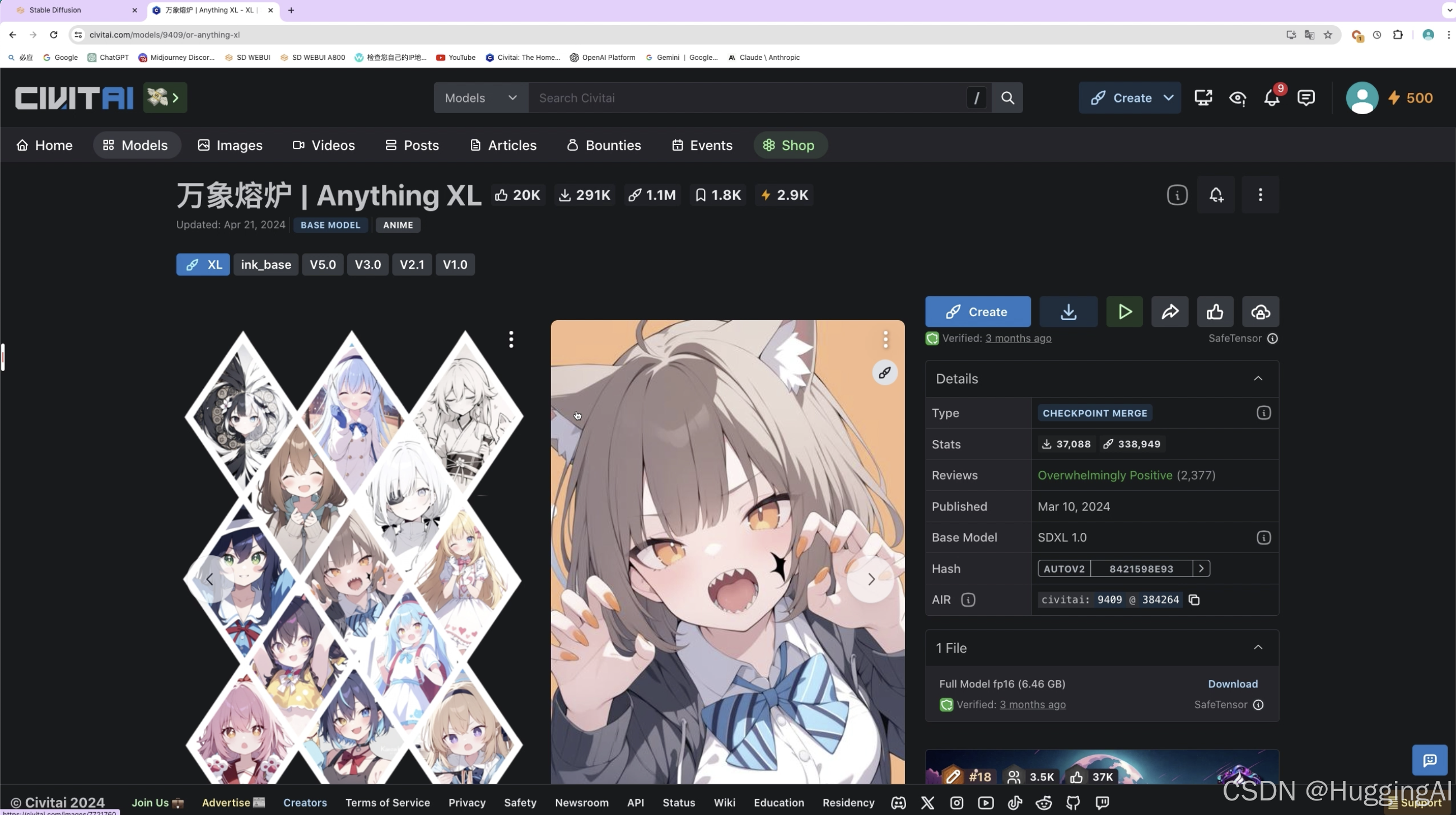
Anything系列主打二次元漫画,我们可以在C站上搜索到这个模型, 搜索关键字是Anything,搜索结果我们点击过滤图标,sort model by选择基于下载次数来排序
然后排在第一位的下载量做多,也就是万象熔炉这个模型即是我们的目标模型,点击进入
该模型有多个版本,使用该模型可以生成效果极佳的动漫图片。
XL版本基于SDXL构建,另外还有一些早期版本,
比如早前使用非常广泛的V3版本,V3版本使用比较简单,只需简易的提示词搭配便能生成高质量的动漫图:
我们演示一下,填入提示词
1girl, white hair, golden eyes, beautiful eyes, detail, flower meadow, cumulonimbus clouds, lighting, detailed sky, garden
点击生成,便能生成非常不错的动漫图
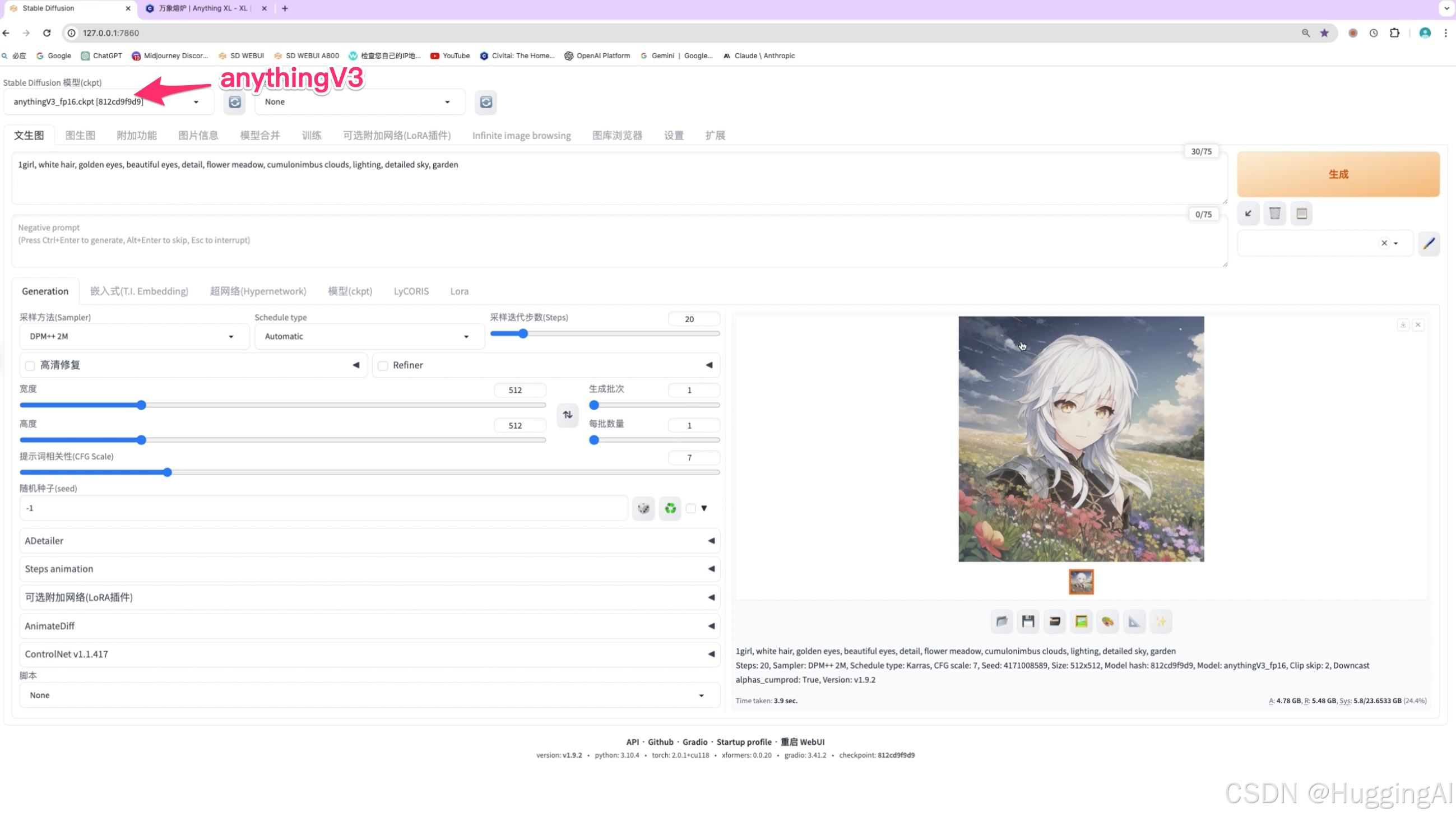
而V5版本对提示词的要求严格了很多,在使用V5版本时,需要设计精准的提示词,详细信息可以通过show more打开模型说明查看。
另外一个比较有名的二次元大模型是Cetus-Mix,该模型是一个二次元资源的混合模型,他融合了很多二次元的模型,所以对二次元人物,场景等多种需求都能很好的满足。
另外Hassaku也是被广泛下载和使用的二次元模型,且该模型在不断的更新中
DreamLike Diffusion是一个偏向插画的二次元模型,使用该模型可以绘制偏向插画风格的二次元图像。
四:2.5D模型
除了写实和二次元模型,还有一类2.5D模型也是众多sd爱好者所偏爱的模型,
比如大名鼎鼎的Guofeng3模型,我们可以使用该模型生成极具国风特色的人物图像,
GhostMix模型
GhostMix 也是C站上一款著名的模型,以其在生成 2.5D 图像方面的强大能力而闻名,该模型专注于人脸和逼真细节的创作,非常适合创作生动且详细的艺术作品。
DreamShaper模型
该模型生成的图像整体风格偏幻想,动漫和机甲风格,另外该模型在写实图像上也非常出色

随着越来越多的爱好者加入,C站上的各类模型越来越丰富,受课程长度限制,我们仅能简单介绍一些受欢迎程度较高的模型,C站上还有很多优秀的大模型, 大家可以前往探索和挖掘。
五:特定风格模型
除了上述介绍的写实,二次元,2.5D模型,还有一些具有特定风格的模型,可以帮助我们在特定应用场景生成特定风格的图像
比如
ArchitectureRealMix,该模型非常擅长建筑设计,景观设计,
InteriorDesignSuperMix 该模型则擅长室内设计

对于从事这些建筑,景观行业,室内设计的设计师而言,这两个模型能提供非常优秀的作品创意。
六:VAE
我们再补充一些有用的知识点。
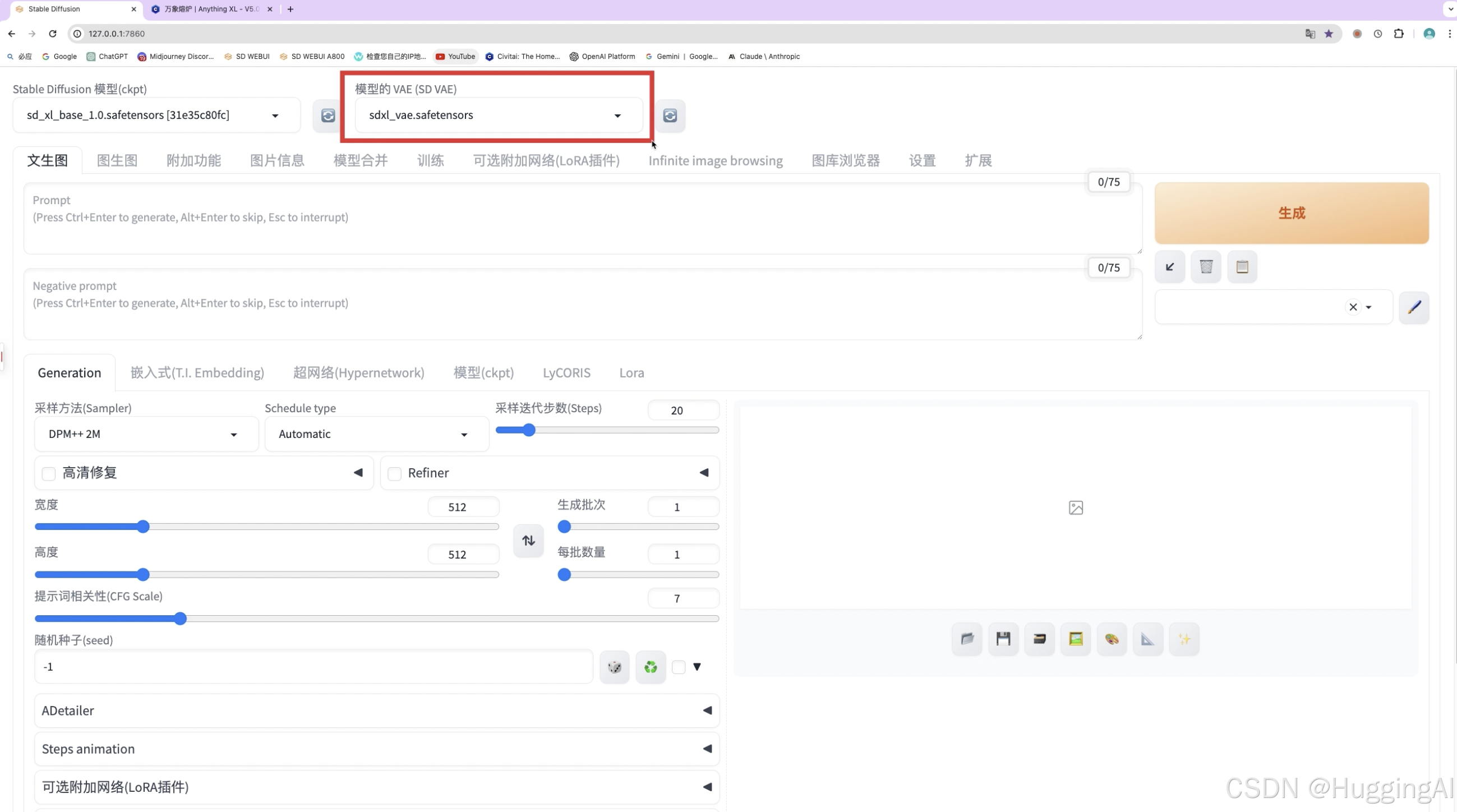
我们在使用SDXL模型的时候应该有发现,我们在选择大模型的右侧为止,也通过列表选择了模型的VAE。
什么是VAE,在Stable Diffusion中,VAE的全称为Variational Autoencoder,翻译成中文则是变分自编码器,VAE是一个核心组件,用于处理图像的编码和解码过程。VAE在模型中的作用主要是帮助模型学习如何将图像数据有效地压缩成一个紧凑的潜在空间表示,然后再从这个表示中重构图像。这种方法在生成图像任务中尤为重要,因为它允许模型捕捉和复现复杂的数据分布。
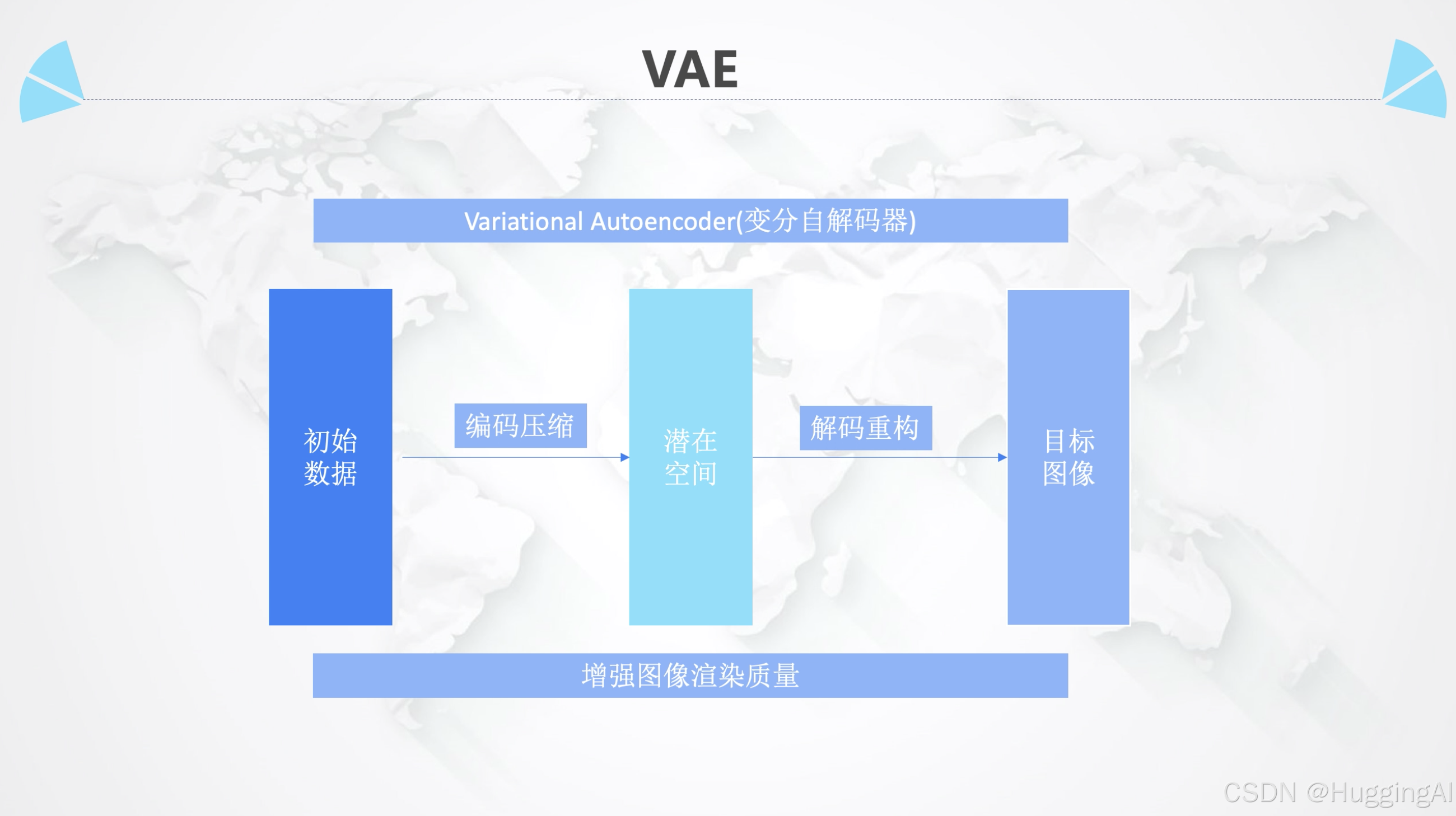
一般情况,我们无需安装和设置VAE文件就可以运行 Stable Diffusion,因为大部分模型,都已经内置了默认的 VAE。但有的时候一个改进的VAE可以从潜在空间中更好地解码图像,尤其是细微的细节可以得到更好的恢复,比如渲染眼睛和文本等所有细节比较重要的地方,使用改进的VAE,能有助于细节的绘制。
上面的讲述可能有些难以理解,我们只需记住,某些时候,使用额外改进的VAE,可以增加图像的渲染质量。我们可以根据模型的文档来决定是否使用VAE。
VAE选择列表在默认情况下是不回在webui的界面中最上方显示的,我们需要在设置中用户界面设置中,找到快捷设置列表输入sd_vae选择对应的项目,将sd_vae添加到快捷列表,
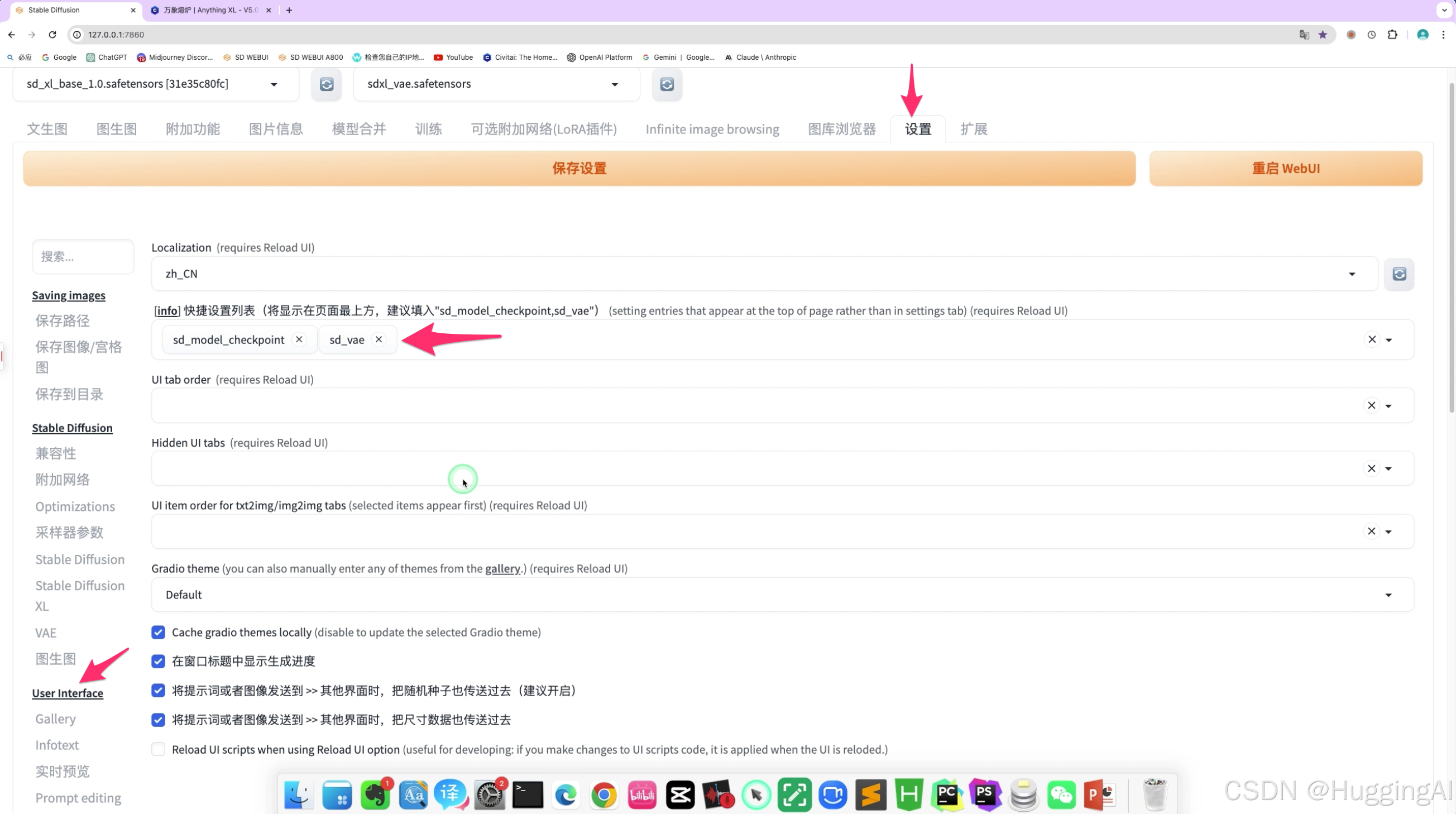
点击保存设置,重启webui,重启后,上方的快捷设置列表便会出现模型VAE的设置列表快捷项目。
七:inpainting模型
我们再补充一个知识点,我们在浏览C站的某些大模型,比如之前演示过的majicMIX realistic模型,可以看到,某些版本选择中提供了含有关键字inpainting的大模型,比如这里提供了V7 inpainting版本大模型,这些大模型是针对重绘场景所训练的大模型。
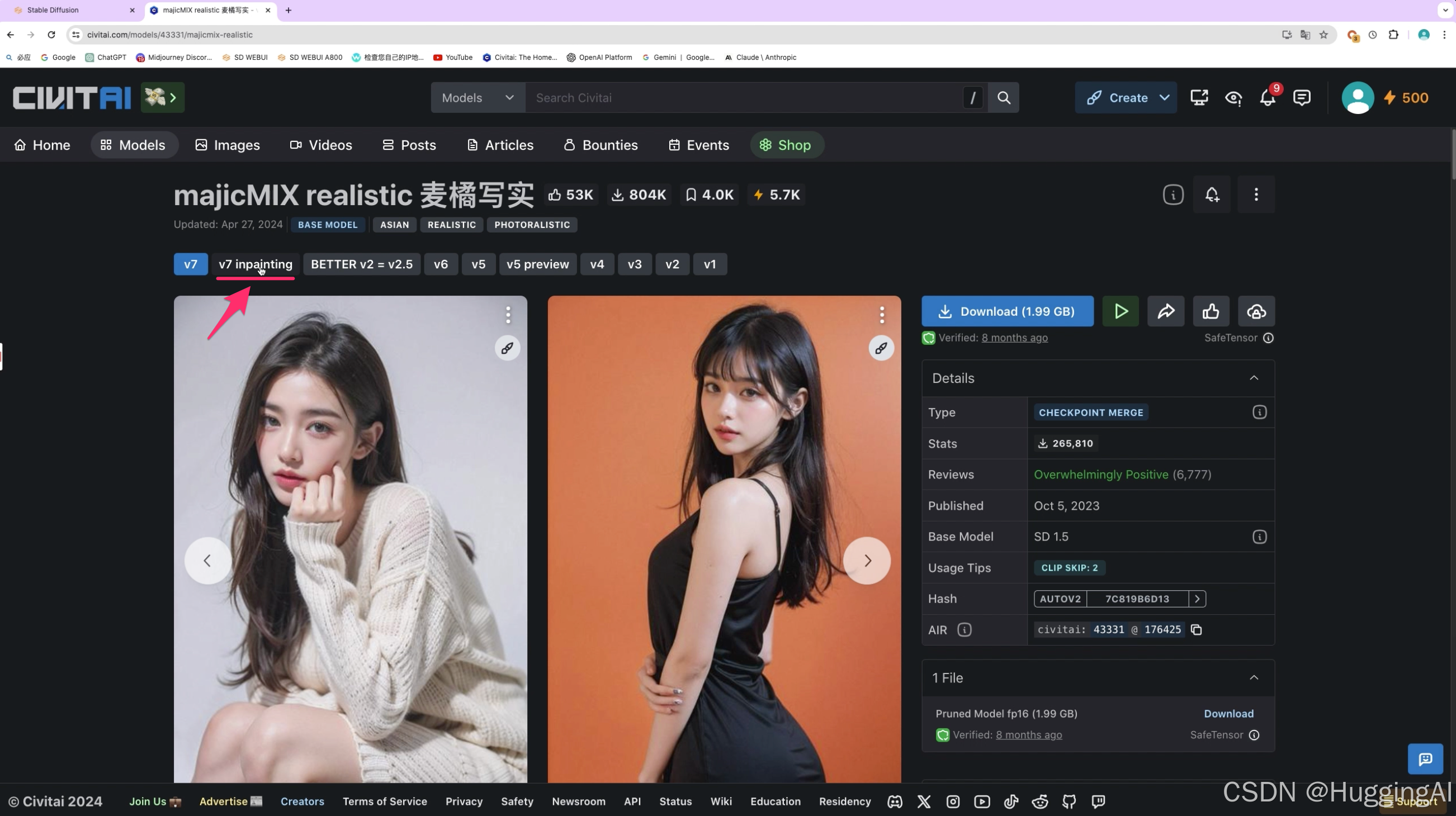
使用这些模型,可以显著减少图像边缘衔接时所出现的不自然接缝,从而在视觉上更加平滑和自然,在重绘场景,我们可以优先使用这些模型。
好了,本节课的课程到这里就结束了,我们做一下总结,本节课程我们详细讲述了stable diffusion中关于基础大模型的知识,我们首先分析了官方推出的多个版本的原始基础大模型,然后我们分类演示了一些不同风格的大模型,这些大模型通常是基于官方大模型微调训练而来,我们也讲述了下载和使用这些大模型需要注意的一些事项。最后,我们补充了VAE以及inpainting大模型的一些知识。在绘图时,选择合适的大模型,设计优秀的提示语句,设置好对应参数便能很好地引导AI依据我们的构思和想法会制出精美的图像。另外,除了DreamBooth训练微调原始基础模型获得新的大模型,我们还可以利用一些其他的技术来对模型进行微调,从而帮助AI绘制理想的图像,比如LoRA。LyCoris,embeddings,hypernetwork,我们会在接下来的课程陆续讲解。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » stable diffusion 大模型

发表评论 取消回复