目录
哈哈大家已经聊这么多了啊,上个月被剥削晕过去了现在才醒。最后一篇了,这三个模式感觉可以总结的地方不多,加上隔的时间有点长了,偷个懒过一遍。
职责链模式
概念
职责链模式的作用和模板模式、策略模式类似,都是复用和扩展,在实际的项目开发中比较常用,特别是框架开发中,我们可以利用它们来提供框架的扩展点,能够让框架的使用者在不修改框架源码的情况下,基于扩展点定制化框架的功能。
职责链模式的英文翻译是Chain Of Responsibility Design Pattern。在GoF的《设计模式》中,它是这么定义的:
Avoid coupling the sender of a request to its receiver by giving more than one object a chance to handle the request. Chain the receiving objects and pass the request along the chain until an object handles it.
翻译成中文就是:将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
解读:在职责链模式中,多个处理器(也就是刚刚定义中说的“接收对象”)依次处理同一个请求。一个请求先经过A处理器处理,然后再把请求传递给B处理器,B处理器处理完后再传递给C处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式。
代码实现
职责链模式的常见实现方式有两种,链表和数组。
第一种实现方式如下所示。其中,Handler是所有处理器类的抽象父类,handle()是抽象方法。每个具体的处理器类(HandlerA、HandlerB)的handle()函数的代码结构类似,如果它能处理该请求,就不继续往下传递;如果不能处理,则交由后面的处理器来处理(也就是调用successor.handle())。HandlerChain是处理器链,从数据结构的角度来看,它就是一个记录了链头、链尾的链表。其中,记录链尾是为了方便添加处理器。
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public abstract void handle();
}
public class HandlerA extends Handler {
@Override
public void handle() {
boolean handled = false;
//...
if (!handled && successor != null) {
successor.handle();
}
}
}
public class HandlerB extends Handler {
@Override
public void handle() {
boolean handled = false;
//...
if (!handled && successor != null) {
successor.handle();
}
}
}
public class HandlerChain {
private Handler head = null;
private Handler tail = null;
public void addHandler(Handler handler) {
handler.setSuccessor(null);
if (head == null) {
head = handler;
tail = handler;
return;
}
tail.setSuccessor(handler);
tail = handler;
}
public void handle() {
if (head != null) {
head.handle();
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}实际上,上面的代码实现不够优雅。处理器类的handle()函数,不仅包含自己的业务逻辑,还包含对下一个处理器的调用,也就是代码中的successor.handle()。一个不熟悉这种代码结构的程序员,在添加新的处理器类的时候,很有可能忘记在handle()函数中调用successor.handle(),这就会导致代码出现bug。
针对这个问题,我们对代码进行重构,利用模板模式,将调用successor.handle()的逻辑从具体的处理器类中剥离出来,放到抽象父类中。这样具体的处理器类只需要实现自己的业务逻辑就可以了。重构之后的代码如下所示:
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public final void handle() {
boolean handled = doHandle();
if (successor != null && !handled) {
successor.handle();
}
}
protected abstract boolean doHandle();
}
public class HandlerA extends Handler {
@Override
protected boolean doHandle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerB extends Handler {
@Override
protected boolean doHandle() {
boolean handled = false;
//...
return handled;
}
}
// HandlerChain和Application代码不变我们再来看第二种实现方式,代码如下所示。这种实现方式更加简单。HandlerChain类用数组而非链表来保存所有的处理器,并且需要在HandlerChain的handle()函数中,依次调用每个处理器的handle()函数。
public interface IHandler {
boolean handle();
}
public class HandlerA implements IHandler {
@Override
public boolean handle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerB implements IHandler {
@Override
public boolean handle() {
boolean handled = false;
//...
return handled;
}
}
public class HandlerChain {
private List handlers = new ArrayList<>();
public void addHandler(IHandler handler) {
this.handlers.add(handler);
}
public void handle() {
for (IHandler handler : handlers) {
boolean handled = handler.handle();
if (handled) {
break;
}
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}在GoF给出的定义中,如果处理器链上的某个处理器能够处理这个请求,那就不会继续往下传递请求。实际上,职责链模式还有一种变体,那就是请求会被所有的处理器都处理一遍,不存在中途终止的情况。这种变体也有两种实现方式:用链表存储处理器和用数组存储处理器,跟上面的两种实现方式类似,只需要稍微修改即可。
我这里只给出其中一种实现方式,如下所示。另外一种实现方式你对照着上面的实现自行修改。
public abstract class Handler {
protected Handler successor = null;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
public final void handle() {
doHandle();
if (successor != null) {
successor.handle();
}
}
protected abstract void doHandle();
}
public class HandlerA extends Handler {
@Override
protected void doHandle() {
//...
}
}
public class HandlerB extends Handler {
@Override
protected void doHandle() {
//...
}
}
public class HandlerChain {
private Handler head = null;
private Handler tail = null;
public void addHandler(Handler handler) {
handler.setSuccessor(null);
if (head == null) {
head = handler;
tail = handler;
return;
}
tail.setSuccessor(handler);
tail = handler;
}
public void handle() {
if (head != null) {
head.handle();
}
}
}
// 使用举例
public class Application {
public static void main(String[] args) {
HandlerChain chain = new HandlerChain();
chain.addHandler(new HandlerA());
chain.addHandler(new HandlerB());
chain.handle();
}
}使用场景
职责链模式的原理和实现讲完了,我们再通过一个实际的例子,来学习一下职责链模式的应用场景。
对于支持UGC(User Generated Content,用户生成内容)的应用(比如论坛)来说,用户生成的内容(比如,在论坛中发表的帖子)可能会包含一些敏感词(比如涉黄、广告、反动等词汇)。针对这个应用场景,我们就可以利用职责链模式来过滤这些敏感词。
对于包含敏感词的内容,我们有两种处理方式,一种是直接禁止发布,另一种是给敏感词打马赛克(比如,用***替换敏感词)之后再发布。第一种处理方式符合GoF给出的职责链模式的定义,第二种处理方式是职责链模式的变体。
我们这里只给出第一种实现方式的代码示例,如下所示,并且,我们只给出了代码实现的骨架,具体的敏感词过滤算法并没有给出,你可以参看我的另一个专栏《数据结构与算法之美》中多模式字符串匹配的相关章节自行实现。
扩展-Servlet Filter
Servlet Filter是Java Servlet规范中定义的组件,翻译成中文就是过滤器,它可以实现对HTTP请求的过滤功能,比如鉴权、限流、记录日志、验证参数等等。因为它是Servlet规范的一部分,所以,只要是支持Servlet的Web容器(比如,Tomcat、Jetty等),都支持过滤器功能。为了帮助你理解,我画了一张示意图阐述它的工作原理,如下所示。
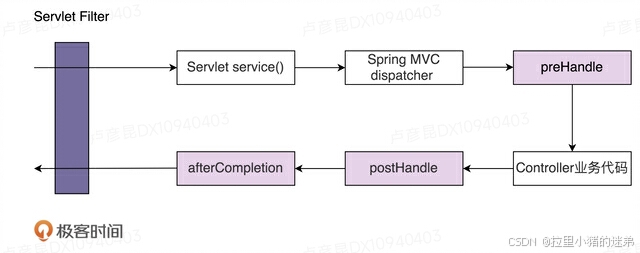
在实际项目中,我们该如何使用Servlet Filter呢?我写了一个简单的示例代码,如下所示。添加一个过滤器,我们只需要定义一个实现javax.servlet.Filter接口的过滤器类,并且将它配置在web.xml配置文件中。Web容器启动的时候,会读取web.xml中的配置,创建过滤器对象。当有请求到来的时候,会先经过过滤器,然后才由Servlet来处理。
public class LogFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// 在创建Filter时自动调用,
// 其中filterConfig包含这个Filter的配置参数,比如name之类的(从配置文件中读取的)
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
System.out.println("拦截客户端发送来的请求.");
chain.doFilter(request, response);
System.out.println("拦截发送给客户端的响应.");
}
@Override
public void destroy() {
// 在销毁Filter时自动调用
}
}
// 在web.xml配置文件中如下配置:
logFilter
com.xzg.cd.LogFilter
logFilter
/*从刚刚的示例代码中,我们发现,添加过滤器非常方便,不需要修改任何代码,定义一个实现javax.servlet.Filter的类,再改改配置就搞定了,完全符合开闭原则。那Servlet Filter是如何做到如此好的扩展性的呢?我想你应该已经猜到了,它利用的就是职责链模式。现在,我们通过剖析它的源码,详细地看看它底层是如何实现的。
在上一节课中,我们讲到,职责链模式的实现包含处理器接口(IHandler)或抽象类(Handler),以及处理器链(HandlerChain)。对应到Servlet Filter,javax.servlet.Filter就是处理器接口,FilterChain就是处理器链。接下来,我们重点来看FilterChain是如何实现的。
不过,我们前面也讲过,Servlet只是一个规范,并不包含具体的实现,所以,Servlet中的FilterChain只是一个接口定义。具体的实现类由遵从Servlet规范的Web容器来提供,比如,ApplicationFilterChain类就是Tomcat提供的FilterChain的实现类,源码如下所示。
为了让代码更易读懂,我对代码进行了简化,只保留了跟设计思路相关的代码片段。完整的代码你可以自行去Tomcat中查看。
public final class ApplicationFilterChain implements FilterChain {
private int pos = 0; //当前执行到了哪个filter
private int n; //filter的个数
private ApplicationFilterConfig[] filters;
private Servlet servlet;
@Override
public void doFilter(ServletRequest request, ServletResponse response) {
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
filter.doFilter(request, response, this);
} else {
// filter都处理完毕后,执行servlet
servlet.service(request, response);
}
}
public void addFilter(ApplicationFilterConfig filterConfig) {
for (ApplicationFilterConfig filter:filters)
if (filter==filterConfig)
return;
if (n == filters.length) {//扩容
ApplicationFilterConfig[] newFilters = new ApplicationFilterConfig[n + INCREMENT];
System.arraycopy(filters, 0, newFilters, 0, n);
filters = newFilters;
}
filters[n++] = filterConfig;
}
}ApplicationFilterChain中的doFilter()函数的代码实现比较有技巧,实际上是一个递归调用。你可以用每个Filter(比如LogFilter)的doFilter()的代码实现,直接替换ApplicationFilterChain的第12行代码,一眼就能看出是递归调用了。我替换了一下,如下所示。
@Override
public void doFilter(ServletRequest request, ServletResponse response) {
if (pos < n) {
ApplicationFilterConfig filterConfig = filters[pos++];
Filter filter = filterConfig.getFilter();
//filter.doFilter(request, response, this);
//把filter.doFilter的代码实现展开替换到这里
System.out.println("拦截客户端发送来的请求.");
chain.doFilter(request, response); // chain就是this
System.out.println("拦截发送给客户端的响应.")
} else {
// filter都处理完毕后,执行servlet
servlet.service(request, response);
}
}这样实现主要是为了在一个doFilter()方法中,支持双向拦截,既能拦截客户端发送来的请求,也能拦截发送给客户端的响应,你可以结合着LogFilter那个例子,以及对比待会要讲到的Spring Interceptor,来自己理解一下。而我们上一节课给出的两种实现方式,都没法做到在业务逻辑执行的前后,同时添加处理代码。
扩展-Spring Interceptor
刚刚讲了Servlet Filter,现在我们来讲一个功能上跟它非常类似的东西,Spring Interceptor,翻译成中文就是拦截器。尽管英文单词和中文翻译都不同,但这两者基本上可以看作一个概念,都用来实现对HTTP请求进行拦截处理。
它们不同之处在于,Servlet Filter是Servlet规范的一部分,实现依赖于Web容器。Spring Interceptor是Spring MVC框架的一部分,由Spring MVC框架来提供实现。客户端发送的请求,会先经过Servlet Filter,然后再经过Spring Interceptor,最后到达具体的业务代码中。我画了一张图来阐述一个请求的处理流程,具体如下所示。
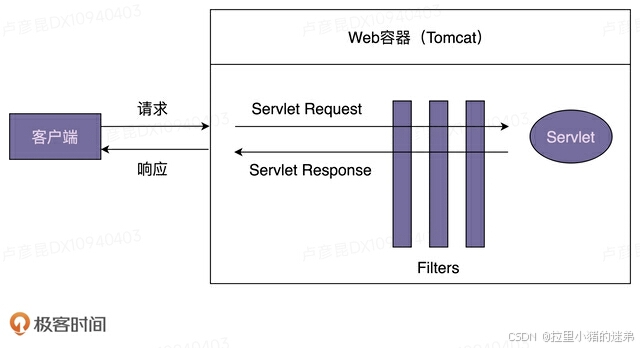
在项目中,我们该如何使用Spring Interceptor呢?我写了一个简单的示例代码,如下所示。LogInterceptor实现的功能跟刚才的LogFilter完全相同,只是实现方式上稍有区别。LogFilter对请求和响应的拦截是在doFilter()一个函数中实现的,而LogInterceptor对请求的拦截在preHandle()中实现,对响应的拦截在postHandle()中实现。
public class LogInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
System.out.println("拦截客户端发送来的请求.");
return true; // 继续后续的处理
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
System.out.println("拦截发送给客户端的响应.");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
System.out.println("这里总是被执行.");
}
}
//在Spring MVC配置文件中配置interceptors同样,我们还是来剖析一下,Spring Interceptor底层是如何实现的。
当然,它也是基于职责链模式实现的。其中,HandlerExecutionChain类是职责链模式中的处理器链。它的实现相较于Tomcat中的ApplicationFilterChain来说,逻辑更加清晰,不需要使用递归来实现,主要是因为它将请求和响应的拦截工作,拆分到了两个函数中实现。HandlerExecutionChain的源码如下所示,同样,我对代码也进行了一些简化,只保留了关键代码。
public class HandlerExecutionChain {
private final Object handler;
private HandlerInterceptor[] interceptors;
public void addInterceptor(HandlerInterceptor interceptor) {
initInterceptorList().add(interceptor);
}
boolean applyPreHandle(HttpServletRequest request, HttpServletResponse response) throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = 0; i < interceptors.length; i++) {
HandlerInterceptor interceptor = interceptors[i];
if (!interceptor.preHandle(request, response, this.handler)) {
triggerAfterCompletion(request, response, null);
return false;
}
}
}
return true;
}
void applyPostHandle(HttpServletRequest request, HttpServletResponse response, ModelAndView mv) throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = interceptors.length - 1; i >= 0; i--) {
HandlerInterceptor interceptor = interceptors[i];
interceptor.postHandle(request, response, this.handler, mv);
}
}
}
void triggerAfterCompletion(HttpServletRequest request, HttpServletResponse response, Exception ex)
throws Exception {
HandlerInterceptor[] interceptors = getInterceptors();
if (!ObjectUtils.isEmpty(interceptors)) {
for (int i = this.interceptorIndex; i >= 0; i--) {
HandlerInterceptor interceptor = interceptors[i];
try {
interceptor.afterCompletion(request, response, this.handler, ex);
} catch (Throwable ex2) {
logger.error("HandlerInterceptor.afterCompletion threw exception", ex2);
}
}
}
}
}在Spring框架中,DispatcherServlet的doDispatch()方法来分发请求,它在真正的业务逻辑执行前后,执行HandlerExecutionChain中的applyPreHandle()和applyPostHandle()函数,用来实现拦截的功能。具体的代码实现很简单,你自己应该能脑补出来,这里就不罗列了。感兴趣的话,你可以自行去查看。
状态模式
状态模式一般会用在需要状态机的场景,状态机的实现方式有多种,除了状态模式,比较常用的还有分支逻辑法和查表法。
什么是有限状态机?
有限状态机,英文翻译是Finite State Machine,缩写为FSM,简称为状态机。状态机有3个组成部分:状态(State)、事件(Event)、动作(Action)。其中,事件也称为转移条件(Transition Condition)。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。
对于刚刚给出的状态机的定义,我结合一个具体的例子,来进一步解释一下。
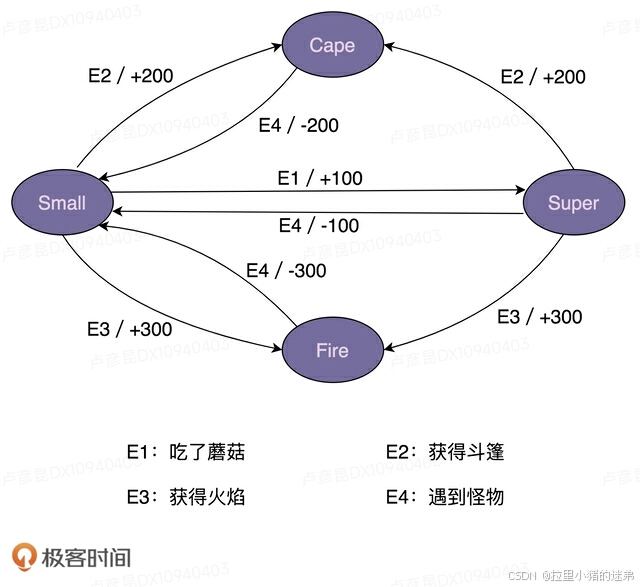
“超级马里奥”游戏不知道你玩过没有?在游戏中,马里奥可以变身为多种形态,比如小马里奥(Small Mario)、超级马里奥(Super Mario)、火焰马里奥(Fire Mario)、斗篷马里奥(Cape Mario)等等。在不同的游戏情节下,各个形态会互相转化,并相应的增减积分。比如,初始形态是小马里奥,吃了蘑菇之后就会变成超级马里奥,并且增加100积分。
实际上,马里奥形态的转变就是一个状态机。其中,马里奥的不同形态就是状态机中的“状态”,游戏情节(比如吃了蘑菇)就是状态机中的“事件”,加减积分就是状态机中的“动作”。比如,吃蘑菇这个事件,会触发状态的转移:从小马里奥转移到超级马里奥,以及触发动作的执行(增加100积分)。
为了方便接下来的讲解,我对游戏背景做了简化,只保留了部分状态和事件。简化之后的状态转移如下图所示:
状态机实现方式一:分支逻辑法
对于如何实现状态机,我总结了三种方式。其中,最简单直接的实现方式是,参照状态转移图,将每一个状态转移,原模原样地直译成代码。这样编写的代码会包含大量的if-else或switch-case分支判断逻辑,甚至是嵌套的分支判断逻辑,所以,我把这种方法暂且命名为分支逻辑法。
按照这个实现思路,我将上面的骨架代码补全一下。补全之后的代码如下所示:
public class MarioStateMachine {
private int score;
private State currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
if (currentState.equals(State.SMALL)) {
this.currentState = State.SUPER;
this.score += 100;
}
}
public void obtainCape() {
if (currentState.equals(State.SMALL) || currentState.equals(State.SUPER) ) {
this.currentState = State.CAPE;
this.score += 200;
}
}
public void obtainFireFlower() {
if (currentState.equals(State.SMALL) || currentState.equals(State.SUPER) ) {
this.currentState = State.FIRE;
this.score += 300;
}
}
public void meetMonster() {
if (currentState.equals(State.SUPER)) {
this.currentState = State.SMALL;
this.score -= 100;
return;
}
if (currentState.equals(State.CAPE)) {
this.currentState = State.SMALL;
this.score -= 200;
return;
}
if (currentState.equals(State.FIRE)) {
this.currentState = State.SMALL;
this.score -= 300;
return;
}
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}对于简单的状态机来说,分支逻辑这种实现方式是可以接受的。但是,对于复杂的状态机来说,这种实现方式极易漏写或者错写某个状态转移。除此之外,代码中充斥着大量的if-else或者switch-case分支判断逻辑,可读性和可维护性都很差。如果哪天修改了状态机中的某个状态转移,我们要在冗长的分支逻辑中找到对应的代码进行修改,很容易改错,引入bug。
状态机实现方式二:查表法
实际上,上面这种实现方法有点类似hard code,对于复杂的状态机来说不适用,而状态机的第二种实现方式查表法,就更加合适了。接下来,我们就一块儿来看下,如何利用查表法来补全骨架代码。
实际上,除了用状态转移图来表示之外,状态机还可以用二维表来表示,如下所示。在这个二维表中,第一维表示当前状态,第二维表示事件,值表示当前状态经过事件之后,转移到的新状态及其执行的动作。
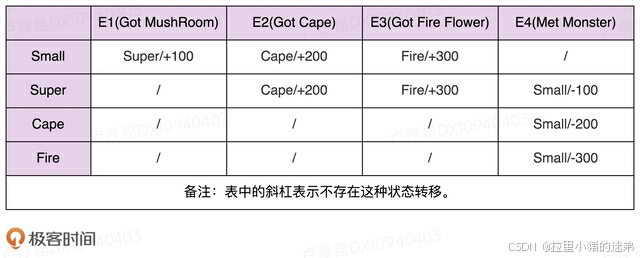
相对于分支逻辑的实现方式,查表法的代码实现更加清晰,可读性和可维护性更好。当修改状态机时,我们只需要修改transitionTable和actionTable两个二维数组即可。实际上,如果我们把这两个二维数组存储在配置文件中,当需要修改状态机时,我们甚至可以不修改任何代码,只需要修改配置文件就可以了。具体的代码如下所示:
public enum Event {
GOT_MUSHROOM(0),
GOT_CAPE(1),
GOT_FIRE(2),
MET_MONSTER(3);
private int value;
private Event(int value) {
this.value = value;
}
public int getValue() {
return this.value;
}
}
public class MarioStateMachine {
private int score;
private State currentState;
private static final State[][] transitionTable = {
{SUPER, CAPE, FIRE, SMALL},
{SUPER, CAPE, FIRE, SMALL},
{CAPE, CAPE, CAPE, SMALL},
{FIRE, FIRE, FIRE, SMALL}
};
private static final int[][] actionTable = {
{+100, +200, +300, +0},
{+0, +200, +300, -100},
{+0, +0, +0, -200},
{+0, +0, +0, -300}
};
public MarioStateMachine() {
this.score = 0;
this.currentState = State.SMALL;
}
public void obtainMushRoom() {
executeEvent(Event.GOT_MUSHROOM);
}
public void obtainCape() {
executeEvent(Event.GOT_CAPE);
}
public void obtainFireFlower() {
executeEvent(Event.GOT_FIRE);
}
public void meetMonster() {
executeEvent(Event.MET_MONSTER);
}
private void executeEvent(Event event) {
int stateValue = currentState.getValue();
int eventValue = event.getValue();
this.currentState = transitionTable[stateValue][eventValue];
this.score += actionTable[stateValue][eventValue];
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState;
}
}状态机实现方式三:状态模式
在查表法的代码实现中,事件触发的动作只是简单的积分加减,所以,我们用一个int类型的二维数组actionTable就能表示,二维数组中的值表示积分的加减值。但是,如果要执行的动作并非这么简单,而是一系列复杂的逻辑操作(比如加减积分、写数据库,还有可能发送消息通知等等),我们就没法用如此简单的二维数组来表示了。这也就是说,查表法的实现方式有一定局限性。
虽然分支逻辑的实现方式不存在这个问题,但它又存在前面讲到的其他问题,比如分支判断逻辑较多,导致代码可读性和可维护性不好等。实际上,针对分支逻辑法存在的问题,我们可以使用状态模式来解决。
状态模式通过将事件触发的状态转移和动作执行,拆分到不同的状态类中,来避免分支判断逻辑。我们还是结合代码来理解这句话。
利用状态模式,我们来补全MarioStateMachine类,补全后的代码如下所示。
其中,IMario是状态的接口,定义了所有的事件。SmallMario、SuperMario、CapeMario、FireMario是IMario接口的实现类,分别对应状态机中的4个状态。原来所有的状态转移和动作执行的代码逻辑,都集中在MarioStateMachine类中,现在,这些代码逻辑被分散到了这4个状态类中。
public interface IMario { //所有状态类的接口
State getName();
//以下是定义的事件
void obtainMushRoom();
void obtainCape();
void obtainFireFlower();
void meetMonster();
}
public class SmallMario implements IMario {
private MarioStateMachine stateMachine;
public SmallMario(MarioStateMachine stateMachine) {
this.stateMachine = stateMachine;
}
@Override
public State getName() {
return State.SMALL;
}
@Override
public void obtainMushRoom() {
stateMachine.setCurrentState(new SuperMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 100);
}
@Override
public void obtainCape() {
stateMachine.setCurrentState(new CapeMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower() {
stateMachine.setCurrentState(new FireMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster() {
// do nothing...
}
}
public class SuperMario implements IMario {
private MarioStateMachine stateMachine;
public SuperMario(MarioStateMachine stateMachine) {
this.stateMachine = stateMachine;
}
@Override
public State getName() {
return State.SUPER;
}
@Override
public void obtainMushRoom() {
// do nothing...
}
@Override
public void obtainCape() {
stateMachine.setCurrentState(new CapeMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower() {
stateMachine.setCurrentState(new FireMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster() {
stateMachine.setCurrentState(new SmallMario(stateMachine));
stateMachine.setScore(stateMachine.getScore() - 100);
}
}
// 省略CapeMario、FireMario类...
public class MarioStateMachine {
private int score;
private IMario currentState; // 不再使用枚举来表示状态
public MarioStateMachine() {
this.score = 0;
this.currentState = new SmallMario(this);
}
public void obtainMushRoom() {
this.currentState.obtainMushRoom();
}
public void obtainCape() {
this.currentState.obtainCape();
}
public void obtainFireFlower() {
this.currentState.obtainFireFlower();
}
public void meetMonster() {
this.currentState.meetMonster();
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState.getName();
}
public void setScore(int score) {
this.score = score;
}
public void setCurrentState(IMario currentState) {
this.currentState = currentState;
}
}上面的代码实现不难看懂,我只强调其中的一点,即MarioStateMachine和各个状态类之间是双向依赖关系。MarioStateMachine依赖各个状态类是理所当然的,但是,反过来,各个状态类为什么要依赖MarioStateMachine呢?这是因为,各个状态类需要更新MarioStateMachine中的两个变量,score和currentState。
实际上,上面的代码还可以继续优化,我们可以将状态类设计成单例,毕竟状态类中不包含任何成员变量。但是,当将状态类设计成单例之后,我们就无法通过构造函数来传递MarioStateMachine了,而状态类又要依赖MarioStateMachine,那该如何解决这个问题呢?
实际上,在第42讲单例模式的讲解中,我们提到过几种解决方法,你可以回过头去再查看一下。在这里,我们可以通过函数参数将MarioStateMachine传递进状态类。根据这个设计思路,我们对上面的代码进行重构。重构之后的代码如下所示:
public interface IMario {
State getName();
void obtainMushRoom(MarioStateMachine stateMachine);
void obtainCape(MarioStateMachine stateMachine);
void obtainFireFlower(MarioStateMachine stateMachine);
void meetMonster(MarioStateMachine stateMachine);
}
public class SmallMario implements IMario {
private static final SmallMario instance = new SmallMario();
private SmallMario() {}
public static SmallMario getInstance() {
return instance;
}
@Override
public State getName() {
return State.SMALL;
}
@Override
public void obtainMushRoom(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(SuperMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 100);
}
@Override
public void obtainCape(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(CapeMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 200);
}
@Override
public void obtainFireFlower(MarioStateMachine stateMachine) {
stateMachine.setCurrentState(FireMario.getInstance());
stateMachine.setScore(stateMachine.getScore() + 300);
}
@Override
public void meetMonster(MarioStateMachine stateMachine) {
// do nothing...
}
}
// 省略SuperMario、CapeMario、FireMario类...
public class MarioStateMachine {
private int score;
private IMario currentState;
public MarioStateMachine() {
this.score = 0;
this.currentState = SmallMario.getInstance();
}
public void obtainMushRoom() {
this.currentState.obtainMushRoom(this);
}
public void obtainCape() {
this.currentState.obtainCape(this);
}
public void obtainFireFlower() {
this.currentState.obtainFireFlower(this);
}
public void meetMonster() {
this.currentState.meetMonster(this);
}
public int getScore() {
return this.score;
}
public State getCurrentState() {
return this.currentState.getName();
}
public void setScore(int score) {
this.score = score;
}
public void setCurrentState(IMario currentState) {
this.currentState = currentState;
}
}实际上,像游戏这种比较复杂的状态机,包含的状态比较多,我优先推荐使用查表法,而状态模式会引入非常多的状态类,会导致代码比较难维护。相反,像电商下单、外卖下单这种类型的状态机,它们的状态并不多,状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能会比较复杂,所以,更加推荐使用状态模式来实现。
迭代器模式
定义
迭代器模式,也叫游标模式,用来遍历集合对象。这里说的“集合对象”,我们也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如,数组、链表、树、图、跳表。不过,很多编程语言都将迭代器作为一个基础的类库,直接提供出来了。在平时开发中,特别是业务开发,我们直接使用即可,很少会自己去实现一个迭代器。不过,知其然知其所以然,弄懂原理能帮助我们更好的使用这些工具类,所以,我觉得还是有必要学习一下这个模式。
我们知道,大部分编程语言都提供了多种遍历集合的方式,比如for循环、foreach循环、迭代器等。所以,今天我们除了讲解迭代器的原理和实现之外,还会重点讲一下,相对于其他遍历方式,利用迭代器来遍历集合的优势。
一个完整的迭代器模式,一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。容器中需要定义iterator()方法,用来创建迭代器。迭代器接口中需要定义hasNext()、currentItem()、next()三个最基本的方法。容器对象通过依赖注入传递到迭代器类中。
遍历集合一般有三种方式:for循环、foreach循环、迭代器遍历。后两种本质上属于一种,都可以看作迭代器遍历。相对于for循环遍历,利用迭代器来遍历有下面三个优势:
- 迭代器模式封装集合内部的复杂数据结构,开发者不需要了解如何遍历,直接使用容器提供的迭代器即可;
- 迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一;
- 迭代器模式让添加新的遍历算法更加容易,更符合开闭原则。除此之外,因为迭代器都实现自相同的接口,在开发中,基于接口而非实现编程,替换迭代器也变得更加容易。
原理和实现
在开篇中我们讲到,它用来遍历集合对象。这里说的“集合对象”也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如数组、链表、树、图、跳表。迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。
迭代器是用来遍历容器的,所以,一个完整的迭代器模式一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。对于迭代器模式,我画了一张简单的类图,你可以看一看,先有个大致的印象。
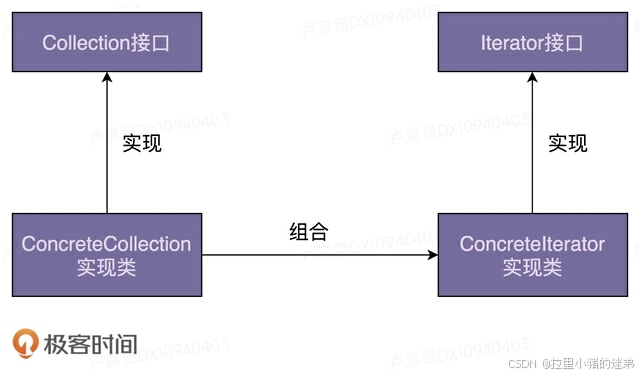
接下来,我们通过一个例子来具体讲,如何实现一个迭代器。
开篇中我们有提到,大部分编程语言都提供了遍历容器的迭代器类,我们在平时开发中,直接拿来用即可,几乎不大可能从零编写一个迭代器。不过,这里为了讲解迭代器的实现原理,我们假设某个新的编程语言的基础类库中,还没有提供线性容器对应的迭代器,需要我们从零开始开发。现在,我们一块来看具体该如何去做。
我们知道,线性数据结构包括数组和链表,在大部分编程语言中都有对应的类来封装这两种数据结构,在开发中直接拿来用就可以了。假设在这种新的编程语言中,这两个数据结构分别对应ArrayList和LinkedList两个类。除此之外,我们从两个类中抽象出公共的接口,定义为List接口,以方便开发者基于接口而非实现编程,编写的代码能在两种数据存储结构之间灵活切换。
现在,我们针对ArrayList和LinkedList两个线性容器,设计实现对应的迭代器。按照之前给出的迭代器模式的类图,我们定义一个迭代器接口Iterator,以及针对两种容器的具体的迭代器实现类ArrayIterator和ListIterator。
我们先来看下Iterator接口的定义。具体的代码如下所示:
// 接口定义方式一
public interface Iterator {
boolean hasNext();
void next();
E currentItem();
}
// 接口定义方式二
public interface Iterator {
boolean hasNext();
E next();
}Iterator接口有两种定义方式。
在第一种定义中,next()函数用来将游标后移一位元素,currentItem()函数用来返回当前游标指向的元素。在第二种定义中,返回当前元素与后移一位这两个操作,要放到同一个函数next()中完成。
第一种定义方式更加灵活一些,比如我们可以多次调用currentItem()查询当前元素,而不移动游标。所以,在接下来的实现中,我们选择第一种接口定义方式。
现在,我们再来看下ArrayIterator的代码实现,具体如下所示。代码实现非常简单,不需要太多解释。你可以结合着我给出的demo,自己理解一下。
public class ArrayIterator implements Iterator {
private int cursor;
private ArrayList arrayList;
public ArrayIterator(ArrayList arrayList) {
this.cursor = 0;
this.arrayList = arrayList;
}
@Override
public boolean hasNext() {
return cursor != arrayList.size(); //注意这里,cursor在指向最后一个元素的时候,hasNext()仍旧返回true。
}
@Override
public void next() {
cursor++;
}
@Override
public E currentItem() {
if (cursor >= arrayList.size()) {
throw new NoSuchElementException();
}
return arrayList.get(cursor);
}
}
public class Demo {
public static void main(String[] args) {
ArrayList names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
Iterator iterator = new ArrayIterator(names);
while (iterator.hasNext()) {
System.out.println(iterator.currentItem());
iterator.next();
}
}
}在上面的代码实现中,我们需要将待遍历的容器对象,通过构造函数传递给迭代器类。实际上,为了封装迭代器的创建细节,我们可以在容器中定义一个iterator()方法,来创建对应的迭代器。为了能实现基于接口而非实现编程,我们还需要将这个方法定义在List接口中。具体的代码实现和使用示例如下所示:
public interface List {
Iterator iterator();
//...省略其他接口函数...
}
public class ArrayList implements List {
//...
public Iterator iterator() {
return new ArrayIterator(this);
}
//...省略其他代码
}
public class Demo {
public static void main(String[] args) {
List names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
Iterator iterator = names.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.currentItem());
iterator.next();
}
}
}对于LinkedIterator,它的代码结构跟ArrayIterator完全相同,我这里就不给出具体的代码实现了,你可以参照ArrayIterator自己去写一下。
结合刚刚的例子,我们来总结一下迭代器的设计思路。总结下来就三句话:迭代器中需要定义hasNext()、currentItem()、next()三个最基本的方法。待遍历的容器对象通过依赖注入传递到迭代器类中。容器通过iterator()方法来创建迭代器。
这里我画了一张类图,如下所示。实际上就是对上面那张类图的细化,你可以结合着一块看。
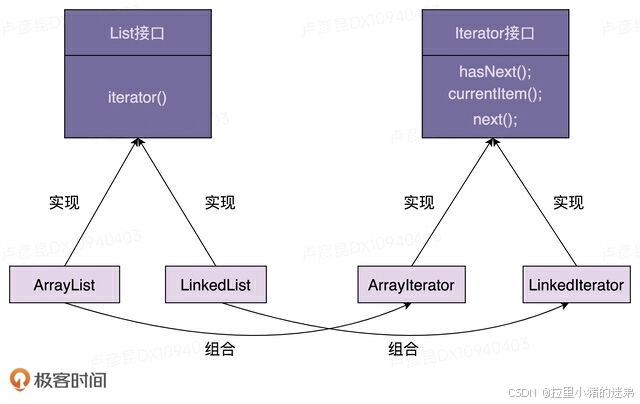
迭代器模式的优势
迭代器的原理和代码实现讲完了。接下来,我们来一块看一下,使用迭代器遍历集合的优势。
一般来讲,遍历集合数据有三种方法:for循环、foreach循环、iterator迭代器。对于这三种方式,我拿Java语言来举例说明一下。具体的代码如下所示:
List names = new ArrayList<>();
names.add("xzg");
names.add("wang");
names.add("zheng");
// 第一种遍历方式:for循环
for (int i = 0; i < names.size(); i++) {
System.out.print(names.get(i) + ",");
}
// 第二种遍历方式:foreach循环
for (String name : names) {
System.out.print(name + ",")
}
// 第三种遍历方式:迭代器遍历
Iterator iterator = names.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + ",");//Java中的迭代器接口是第二种定义方式,next()既移动游标又返回数据
}实际上,foreach循环只是一个语法糖而已,底层是基于迭代器来实现的。也就是说,上面代码中的第二种遍历方式(foreach循环代码)的底层实现,就是第三种遍历方式(迭代器遍历代码)。这两种遍历方式可以看作同一种遍历方式,也就是迭代器遍历方式。
从上面的代码来看,for循环遍历方式比起迭代器遍历方式,代码看起来更加简洁。那我们为什么还要用迭代器来遍历容器呢?为什么还要给容器设计对应的迭代器呢?原因有以下三个。
首先,对于类似数组和链表这样的数据结构,遍历方式比较简单,直接使用for循环来遍历就足够了。但是,对于复杂的数据结构(比如树、图)来说,有各种复杂的遍历方式。比如,树有前中后序、按层遍历,图有深度优先、广度优先遍历等等。如果由客户端代码来实现这些遍历算法,势必增加开发成本,而且容易写错。如果将这部分遍历的逻辑写到容器类中,也会导致容器类代码的复杂性。
前面也多次提到,应对复杂性的方法就是拆分。我们可以将遍历操作拆分到迭代器类中。比如,针对图的遍历,我们就可以定义DFSIterator、BFSIterator两个迭代器类,让它们分别来实现深度优先遍历和广度优先遍历。
其次,将游标指向的当前位置等信息,存储在迭代器类中,每个迭代器独享游标信息。这样,我们就可以创建多个不同的迭代器,同时对同一个容器进行遍历而互不影响。
最后,容器和迭代器都提供了抽象的接口,方便我们在开发的时候,基于接口而非具体的实现编程。当需要切换新的遍历算法的时候,比如,从前往后遍历链表切换成从后往前遍历链表,客户端代码只需要将迭代器类从LinkedIterator切换为ReversedLinkedIterator即可,其他代码都不需要修改。除此之外,添加新的遍历算法,我们只需要扩展新的迭代器类,也更符合开闭原则。
在遍历的同时增删集合元素会发生什么?
在通过迭代器来遍历集合元素的同时,增加或者删除集合中的元素,有可能会导致某个元素被重复遍历或遍历不到。不过,并不是所有情况下都会遍历出错,有的时候也可以正常遍历,所以,这种行为称为结果不可预期行为或者未决行为,也就是说,运行结果到底是对还是错,要视情况而定。
怎么理解呢?我们通过一个例子来解释一下。我们还是延续上一节课实现的ArrayList迭代器的例子。为了方便你查看,我把相关的代码都重新拷贝到这里了。
public interface Iterator {
boolean hasNext();
void next();
E currentItem();
}
public class ArrayIterator implements Iterator {
private int cursor;
private ArrayList arrayList;
public ArrayIterator(ArrayList arrayList) {
this.cursor = 0;
this.arrayList = arrayList;
}
@Override
public boolean hasNext() {
return cursor < arrayList.size();
}
@Override
public void next() {
cursor++;
}
@Override
public E currentItem() {
if (cursor >= arrayList.size()) {
throw new NoSuchElementException();
}
return arrayList.get(cursor);
}
}
public interface List {
Iterator iterator();
}
public class ArrayList implements List {
//...
public Iterator iterator() {
return new ArrayIterator(this);
}
//...
}
public class Demo {
public static void main(String[] args) {
List names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator iterator = names.iterator();
iterator.next();
names.remove("a");
}
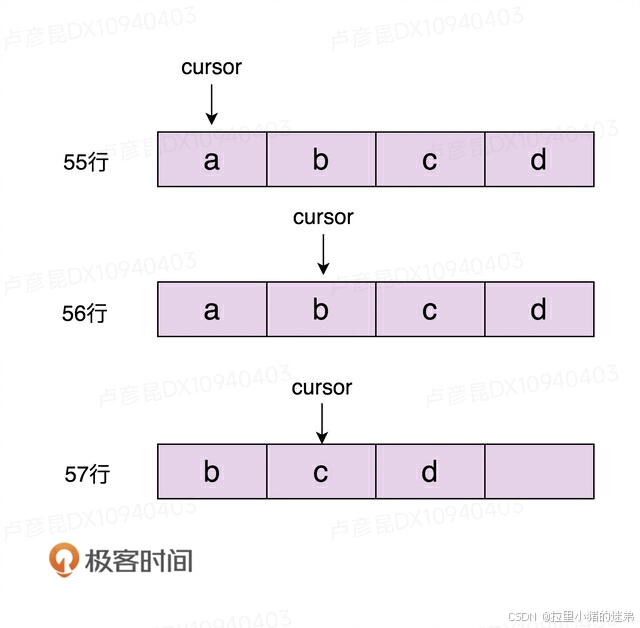
}我们知道,ArrayList底层对应的是数组这种数据结构,在执行完第55行代码的时候,数组中存储的是a、b、c、d四个元素,迭代器的游标cursor指向元素a。当执行完第56行代码的时候,游标指向元素b,到这里都没有问题。
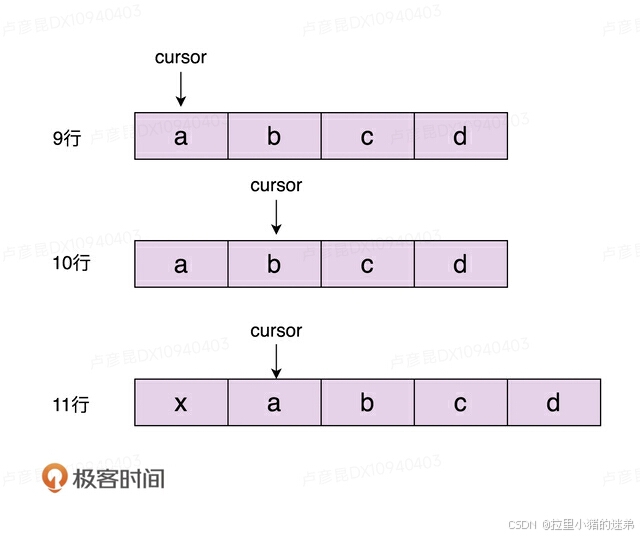
为了保持数组存储数据的连续性,数组的删除操作会涉及元素的搬移(详细的讲解你可以去看我的另一个专栏《数据结构与算法之美》)。当执行到第57行代码的时候,我们从数组中将元素a删除掉,b、c、d三个元素会依次往前搬移一位,这就会导致游标本来指向元素b,现在变成了指向元素c。原本在执行完第56行代码之后,我们还可以遍历到b、c、d三个元素,但在执行完第57行代码之后,我们只能遍历到c、d两个元素,b遍历不到了。
对于上面的描述,我画了一张图,你可以对照着理解。
不过,如果第57行代码删除的不是游标前面的元素(元素a)以及游标所在位置的元素(元素b),而是游标后面的元素(元素c和d),这样就不会存在任何问题了,不会存在某个元素遍历不到的情况了。
所以,我们前面说,在遍历的过程中删除集合元素,结果是不可预期的,有时候没问题(删除元素c或d),有时候就有问题(删除元素a或b),这个要视情况而定(到底删除的是哪个位置的元素),就是这个意思。
在遍历的过程中删除集合元素,有可能会导致某个元素遍历不到,那在遍历的过程中添加集合元素,会发生什么情况呢?还是结合刚刚那个例子来讲解,我们将上面的代码稍微改造一下,把删除元素改为添加元素。具体的代码如下所示:
public class Demo {
public static void main(String[] args) {
List names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator iterator = names.iterator();
iterator.next();
names.add(0, "x");
}
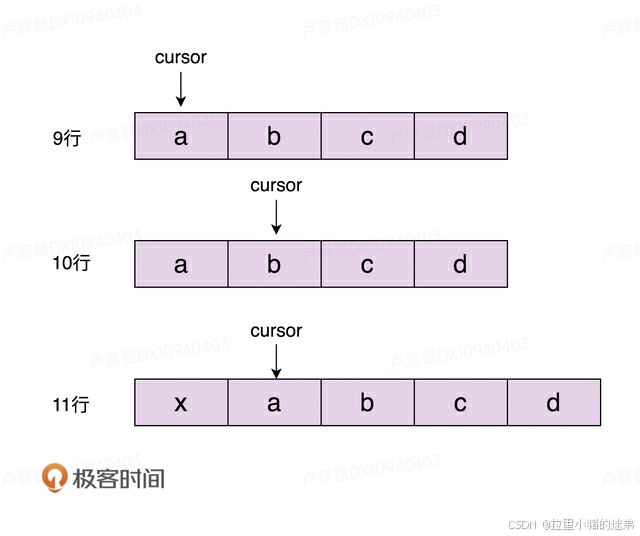
}在执行完第10行代码之后,数组中包含a、b、c、d四个元素,游标指向b这个元素,已经跳过了元素a。在执行完第11行代码之后,我们将x插入到下标为0的位置,a、b、c、d四个元素依次往后移动一位。这个时候,游标又重新指向了元素a。元素a被游标重复指向两次,也就是说,元素a存在被重复遍历的情况。
跟删除情况类似,如果我们在游标的后面添加元素,就不会存在任何问题。所以,在遍历的同时添加集合元素也是一种不可预期行为。
同样,对于上面的添加元素的情况,我们也画了一张图,如下所示,你可以对照着理解。
如何应对遍历时改变集合导致的未决行为?
当通过迭代器来遍历集合的时候,增加、删除集合元素会导致不可预期的遍历结果。实际上,“不可预期”比直接出错更加可怕,有的时候运行正确,有的时候运行错误,一些隐藏很深、很难debug的bug就是这么产生的。那我们如何才能避免出现这种不可预期的运行结果呢?
有两种比较干脆利索的解决方案:一种是遍历的时候不允许增删元素,另一种是增删元素之后让遍历报错。
实际上,第一种解决方案比较难实现,我们要确定遍历开始和结束的时间点。遍历开始的时间节点我们很容易获得。我们可以把创建迭代器的时间点作为遍历开始的时间点。但是,遍历结束的时间点该如何来确定呢?
你可能会说,遍历到最后一个元素的时候就算结束呗。但是,在实际的软件开发中,每次使用迭代器来遍历元素,并不一定非要把所有元素都遍历一遍。如下所示,我们找到一个值为b的元素就提前结束了遍历。
public class Demo {
public static void main(String[] args) {
List names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator iterator = names.iterator();
while (iterator.hasNext()) {
String name = iterator.currentItem();
if (name.equals("b")) {
break;
}
}
}
}你可能还会说,那我们可以在迭代器类中定义一个新的接口finishIteration(),主动告知容器迭代器使用完了,你可以增删元素了,示例代码如下所示。但是,这就要求程序员在使用完迭代器之后要主动调用这个函数,也增加了开发成本,还很容易漏掉。
public class Demo {
public static void main(String[] args) {
List names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator iterator = names.iterator();
while (iterator.hasNext()) {
String name = iterator.currentItem();
if (name.equals("b")) {
iterator.finishIteration();//主动告知容器这个迭代器用完了
break;
}
}
}
}实际上,第二种解决方法更加合理。Java语言就是采用的这种解决方案,增删元素之后,让遍历报错。接下来,我们具体来看一下如何实现。
怎么确定在遍历时候,集合有没有增删元素呢?我们在ArrayList中定义一个成员变量modCount,记录集合被修改的次数,集合每调用一次增加或删除元素的函数,就会给modCount加1。当通过调用集合上的iterator()函数来创建迭代器的时候,我们把modCount值传递给迭代器的expectedModCount成员变量,之后每次调用迭代器上的hasNext()、next()、currentItem()函数,我们都会检查集合上的modCount是否等于expectedModCount,也就是看,在创建完迭代器之后,modCount是否改变过。
如果两个值不相同,那就说明集合存储的元素已经改变了,要么增加了元素,要么删除了元素,之前创建的迭代器已经不能正确运行了,再继续使用就会产生不可预期的结果,所以我们选择fail-fast解决方式,抛出运行时异常,结束掉程序,让程序员尽快修复这个因为不正确使用迭代器而产生的bug。
上面的描述翻译成代码就是下面这样子。你可以结合着代码一起理解我刚才的讲解。
public class ArrayIterator implements Iterator {
private int cursor;
private ArrayList arrayList;
private int expectedModCount;
public ArrayIterator(ArrayList arrayList) {
this.cursor = 0;
this.arrayList = arrayList;
this.expectedModCount = arrayList.modCount;
}
@Override
public boolean hasNext() {
checkForComodification();
return cursor < arrayList.size();
}
@Override
public void next() {
checkForComodification();
cursor++;
}
@Override
public Object currentItem() {
checkForComodification();
return arrayList.get(cursor);
}
private void checkForComodification() {
if (arrayList.modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
//代码示例
public class Demo {
public static void main(String[] args) {
List names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator iterator = names.iterator();
iterator.next();
names.remove("a");
iterator.next();//抛出ConcurrentModificationException异常
}
}如何在遍历的同时安全地删除集合元素?
像Java语言,迭代器类中除了前面提到的几个最基本的方法之外,还定义了一个remove()方法,能够在遍历集合的同时,安全地删除集合中的元素。不过,需要说明的是,它并没有提供添加元素的方法。毕竟迭代器的主要作用是遍历,添加元素放到迭代器里本身就不合适。
我个人觉得,Java迭代器中提供的remove()方法还是比较鸡肋的,作用有限。它只能删除游标指向的前一个元素,而且一个next()函数之后,只能跟着最多一个remove()操作,多次调用remove()操作会报错。我还是通过一个例子来解释一下。
public class Demo {
public static void main(String[] args) {
List names = new ArrayList<>();
names.add("a");
names.add("b");
names.add("c");
names.add("d");
Iterator iterator = names.iterator();
iterator.next();
iterator.remove();
iterator.remove(); //报错,抛出IllegalStateException异常
}
}现在,我们一块来看下,为什么通过迭代器就能安全的删除集合中的元素呢?源码之下无秘密。我们来看下remove()函数是如何实现的,代码如下所示。稍微提醒一下,在Java实现中,迭代器类是容器类的内部类,并且next()函数不仅将游标后移一位,还会返回当前的元素。
public class ArrayList {
transient Object[] elementData;
private int size;
public Iterator iterator() {
return new Itr();
}
private class Itr implements Iterator {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
Itr() {}
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
}在上面的代码实现中,迭代器类新增了一个lastRet成员变量,用来记录游标指向的前一个元素。通过迭代器去删除这个元素的时候,我们可以更新迭代器中的游标和lastRet值,来保证不会因为删除元素而导致某个元素遍历不到。如果通过容器来删除元素,并且希望更新迭代器中的游标值来保证遍历不出错,我们就要维护这个容器都创建了哪些迭代器,每个迭代器是否还在使用等信息,代码实现就变得比较复杂了。
在通过迭代器来遍历集合元素的同时,增加或者删除集合中的元素,有可能会导致某个元素被重复遍历或遍历不到。不过,并不是所有情况下都会遍历出错,有的时候也可以正常遍历,所以,这种行为称为结果不可预期行为或者未决行为。实际上,“不可预期”比直接出错更加可怕,有的时候运行正确,有的时候运行错误,一些隐藏很深、很难debug的bug就是这么产生的。
有两种比较干脆利索的解决方案,来避免出现这种不可预期的运行结果。一种是遍历的时候不允许增删元素,另一种是增删元素之后让遍历报错。第一种解决方案比较难实现,因为很难确定迭代器使用结束的时间点。第二种解决方案更加合理。Java语言就是采用的这种解决方案。增删元素之后,我们选择fail-fast解决方式,让遍历操作直接抛出运行时异常。
像Java语言,迭代器类中除了前面提到的几个最基本的方法之外,还定义了一个remove()方法,能够在遍历集合的同时,安全地删除集合中的元素。
扩展-如何实现一个支持“快照”功能的迭代器模式?
理解这个问题最关键的是理解“快照”两个字。所谓“快照”,指我们为容器创建迭代器的时候,相当于给容器拍了一张快照(Snapshot)。之后即便我们增删容器中的元素,快照中的元素并不会做相应的改动。而迭代器遍历的对象是快照而非容器,这样就避免了在使用迭代器遍历的过程中,增删容器中的元素,导致的不可预期的结果或者报错。
接下来,我举一个例子来解释一下上面这段话。具体的代码如下所示。容器list中初始存储了3、8、2三个元素。尽管在创建迭代器iter1之后,容器list删除了元素3,只剩下8、2两个元素,但是,通过iter1遍历的对象是快照,而非容器list本身。所以,遍历的结果仍然是3、8、2。同理,iter2、iter3也是在各自的快照上遍历,输出的结果如代码中注释所示。
List list = new ArrayList<>();
list.add(3);
list.add(8);
list.add(2);
Iterator iter1 = list.iterator();//snapshot: 3, 8, 2
list.remove(new Integer(2));//list:3, 8
Iterator iter2 = list.iterator();//snapshot: 3, 8
list.remove(new Integer(3));//list:8
Iterator iter3 = list.iterator();//snapshot: 3
// 输出结果:3 8 2
while (iter1.hasNext()) {
System.out.print(iter1.next() + " ");
}
System.out.println();
// 输出结果:3 8
while (iter2.hasNext()) {
System.out.print(iter1.next() + " ");
}
System.out.println();
// 输出结果:8
while (iter3.hasNext()) {
System.out.print(iter1.next() + " ");
}
System.out.println();如果由你来实现上面的功能,你会如何来做呢?下面是针对这个功能需求的骨架代码,其中包含ArrayList、SnapshotArrayIterator两个类。对于这两个类,我只定义了必须的几个关键接口,完整的代码实现我并没有给出。你可以试着去完善一下,然后再看我下面的讲解。
public ArrayList implements List {
// TODO: 成员变量、私有函数等随便你定义
@Override
public void add(E obj) {
//TODO: 由你来完善
}
@Override
public void remove(E obj) {
// TODO: 由你来完善
}
@Override
public Iterator iterator() {
return new SnapshotArrayIterator(this);
}
}
public class SnapshotArrayIterator implements Iterator {
// TODO: 成员变量、私有函数等随便你定义
@Override
public boolean hasNext() {
// TODO: 由你来完善
}
@Override
public E next() {//返回当前元素,并且游标后移一位
// TODO: 由你来完善
}
}解决方案一
我们先来看最简单的一种解决办法。在迭代器类中定义一个成员变量snapshot来存储快照。每当创建迭代器的时候,都拷贝一份容器中的元素到快照中,后续的遍历操作都基于这个迭代器自己持有的快照来进行。具体的代码实现如下所示:
public class SnapshotArrayIterator implements Iterator {
private int cursor;
private ArrayList snapshot;
public SnapshotArrayIterator(ArrayList arrayList) {
this.cursor = 0;
this.snapshot = new ArrayList<>();
this.snapshot.addAll(arrayList);
}
@Override
public boolean hasNext() {
return cursor < snapshot.size();
}
@Override
public E next() {
E currentItem = snapshot.get(cursor);
cursor++;
return currentItem;
}
}这个解决方案虽然简单,但代价也有点高。每次创建迭代器的时候,都要拷贝一份数据到快照中,会增加内存的消耗。如果一个容器同时有多个迭代器在遍历元素,就会导致数据在内存中重复存储多份。不过,庆幸的是,Java中的拷贝属于浅拷贝,也就是说,容器中的对象并非真的拷贝了多份,而只是拷贝了对象的引用而已。关于深拷贝、浅拷贝,我们在第47讲中有详细的讲解,你可以回过头去再看一下。
那有没有什么方法,既可以支持快照,又不需要拷贝容器呢?
解决方案二
我们再来看第二种解决方案。
我们可以在容器中,为每个元素保存两个时间戳,一个是添加时间戳addTimestamp,一个是删除时间戳delTimestamp。当元素被加入到集合中的时候,我们将addTimestamp设置为当前时间,将delTimestamp设置成最大长整型值(Long.MAX_VALUE)。当元素被删除时,我们将delTimestamp更新为当前时间,表示已经被删除。
注意,这里只是标记删除,而非真正将它从容器中删除。
同时,每个迭代器也保存一个迭代器创建时间戳snapshotTimestamp,也就是迭代器对应的快照的创建时间戳。当使用迭代器来遍历容器的时候,只有满足addTimestamp
如果元素的addTimestamp>snapshotTimestamp,说明元素在创建了迭代器之后才加入的,不属于这个迭代器的快照;如果元素的delTimestamp
这样就在不拷贝容器的情况下,在容器本身上借助时间戳实现了快照功能。具体的代码实现如下所示。注意,我们没有考虑ArrayList的扩容问题,感兴趣的话,你可以自己完善一下。
public class ArrayList implements List {
private static final int DEFAULT_CAPACITY = 10;
private int actualSize; //不包含标记删除元素
private int totalSize; //包含标记删除元素
private Object[] elements;
private long[] addTimestamps;
private long[] delTimestamps;
public ArrayList() {
this.elements = new Object[DEFAULT_CAPACITY];
this.addTimestamps = new long[DEFAULT_CAPACITY];
this.delTimestamps = new long[DEFAULT_CAPACITY];
this.totalSize = 0;
this.actualSize = 0;
}
@Override
public void add(E obj) {
elements[totalSize] = obj;
addTimestamps[totalSize] = System.currentTimeMillis();
delTimestamps[totalSize] = Long.MAX_VALUE;
totalSize++;
actualSize++;
}
@Override
public void remove(E obj) {
for (int i = 0; i < totalSize; ++i) {
if (elements[i].equals(obj)) {
delTimestamps[i] = System.currentTimeMillis();
actualSize--;
}
}
}
public int actualSize() {
return this.actualSize;
}
public int totalSize() {
return this.totalSize;
}
public E get(int i) {
if (i >= totalSize) {
throw new IndexOutOfBoundsException();
}
return (E)elements[i];
}
public long getAddTimestamp(int i) {
if (i >= totalSize) {
throw new IndexOutOfBoundsException();
}
return addTimestamps[i];
}
public long getDelTimestamp(int i) {
if (i >= totalSize) {
throw new IndexOutOfBoundsException();
}
return delTimestamps[i];
}
}
public class SnapshotArrayIterator implements Iterator {
private long snapshotTimestamp;
private int cursorInAll; // 在整个容器中的下标,而非快照中的下标
private int leftCount; // 快照中还有几个元素未被遍历
private ArrayList arrayList;
public SnapshotArrayIterator(ArrayList arrayList) {
this.snapshotTimestamp = System.currentTimeMillis();
this.cursorInAll = 0;
this.leftCount = arrayList.actualSize();;
this.arrayList = arrayList;
justNext(); // 先跳到这个迭代器快照的第一个元素
}
@Override
public boolean hasNext() {
return this.leftCount >= 0; // 注意是>=, 而非>
}
@Override
public E next() {
E currentItem = arrayList.get(cursorInAll);
justNext();
return currentItem;
}
private void justNext() {
while (cursorInAll < arrayList.totalSize()) {
long addTimestamp = arrayList.getAddTimestamp(cursorInAll);
long delTimestamp = arrayList.getDelTimestamp(cursorInAll);
if (snapshotTimestamp > addTimestamp && snapshotTimestamp < delTimestamp) {
leftCount--;
break;
}
cursorInAll++;
}
}
}实际上,上面的解决方案相当于解决了一个问题,又引入了另外一个问题。ArrayList底层依赖数组这种数据结构,原本可以支持快速的随机访问,在O(1)时间复杂度内获取下标为i的元素,但现在,删除数据并非真正的删除,只是通过时间戳来标记删除,这就导致无法支持按照下标快速随机访问了。如果你对数组随机访问这块知识点不了解,可以去看我的《数据结构与算法之美》专栏,这里我就不展开讲解了。
现在,我们来看怎么解决这个问题:让容器既支持快照遍历,又支持随机访问?
解决的方法也不难,我稍微提示一下。我们可以在ArrayList中存储两个数组。一个支持标记删除的,用来实现快照遍历功能;一个不支持标记删除的(也就是将要删除的数据直接从数组中移除),用来支持随机访问。对应的代码我这里就不给出了,感兴趣的话你可以自己实现一下。(居然不给!等我以后回顾时补上)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 设计模式-行为型-常用-2:职责链模式、状态模式、迭代器模式

发表评论 取消回复