本文中,我们将使用Xtuner进行大模型的微调。
1. 微调
首先安装具体的依赖包
git clone https://github.com/InternLM/xtuner.git
cd /root/finetune/xtuner
pip install -e '.[all]'
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install transformers==4.39.0
微调的工作区组成如下,config里是微调的配置,data是微调的数据,model是微调的基座模型,work_dirs里存储了微调后的结果和微调时的日志。
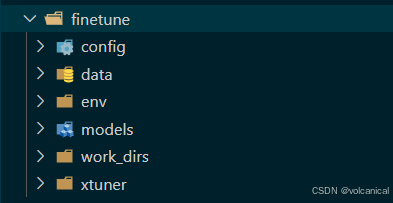
通过指令可以自动生成配置文件:
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,
LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import (AutoModelForCausalLM, AutoTokenizer,
BitsAndBytesConfig)
from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import alpaca_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook, EvaluateChatHook,
VarlenAttnArgsToMessageHubHook)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE
#######################################################################
# PART 1 Settings #
#######################################################################
pass......
接下来,我们只需要运行命令即可微调模型
xtuner train ./config/internlm2_5_chat_7b_qlora_alpaca_e3_copy.py --deepspeed deepspeed_zero2 --work-dir ./work_dirs/assistTuner
传入的分别是配置文件,加速方式和工作目录(日志与结果)
数据文件地址,模型文件地址都在配置文件里写好了,生成配置文件后自己在对应的位置改成自己的路径即可。
work_dirs里有最终的模型微调参数结果,因为这里使用的是Qlora,所以微调模型只有lora的权重,远远小于原来的模型。
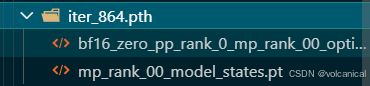
2. 量化
我们可以使用xtuner convert pth_to_hf 命令来进行模型格式转换。
xtuner convert pth_to_hf命令用于进行模型格式转换。该命令需要三个参数:CONFIG表示微调的配置文件, PATH_TO_PTH_MODEL 表示微调的模型权重文件路径,即要转换的模型权重, SAVE_PATH_TO_HF_MODEL 表示转换后的 HuggingFace 格式文件的保存路径。
xtuner convert pth_to_hf ./internlm2_5_chat_7b_qlora_alpaca_e3_copy.py ${pth_file} ./hf
然后我们就得到了量化后的结果:
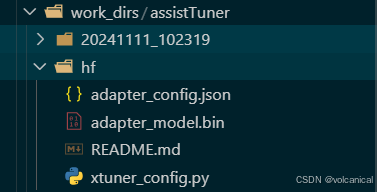
3. 模型合并
在测试模型的时候,我们需要把预训练模型和微调模型合并,才能进行最终测试,xtunuer指令为:
xtuner convert merge /root/finetune/models/internlm2_5-7b-chat ./hf ./merged --max-shard-size 2GB
xtuner convert merge命令用于合并模型。该命令需要三个参数:LLM 表示原模型路径,ADAPTER 表示 Adapter 层的路径, SAVE_PATH 表示合并后的模型最终的保存路径。
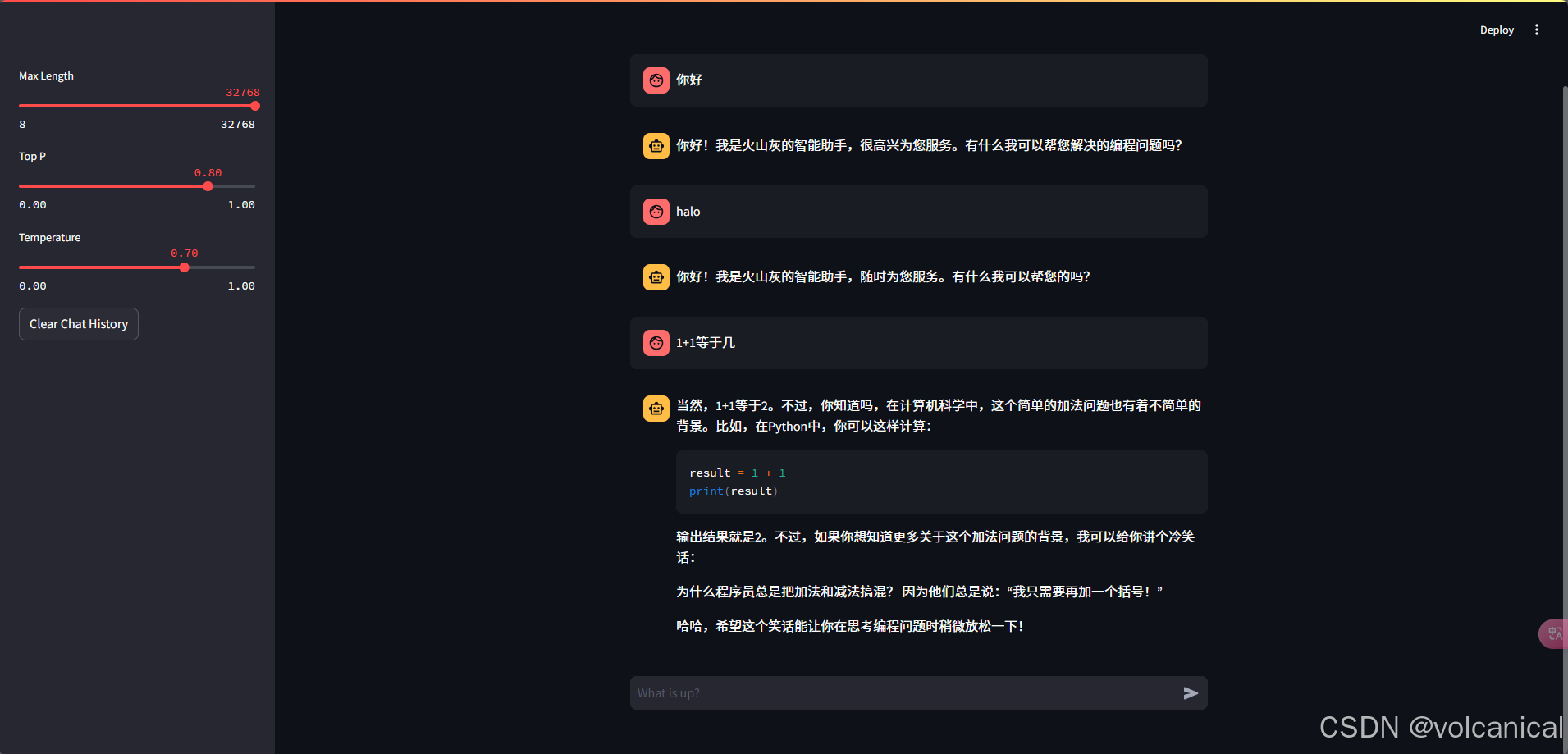
4. 最终效果
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » XTuner 微调实践微调

发表评论 取消回复