卷积神经网络——paddle部分
本文部分为paddle框架以及部分理论分析,torch框架对应代码可见卷积神经网络——pytorch与paddle实现卷积神经网络
import paddle
print("paddle version:",paddle.__version__)
paddle version: 2.6.1
图像卷积的基本原理
图像卷积运算实际上是在进行图像空间域的滤波。卷积层是CNN的核心组件,通过卷积运算提取特征。卷积运算是指从图像的左上角开始,开一个与模板(也称为卷积核或滤波器)同样大小的活动窗口,窗口图像与模板像元对应起来相乘再相加,并用计算结果代替窗口中心的像元亮度值。然后,活动窗口向右移动一列(或一行),并作同样的运算。以此类推,从左到右、从上到下,即可得到一幅新图像。
二维离散卷积公式用于描述两个二维信号(在图像处理中通常是一个图像和一个滤波器或卷积核)之间的卷积运算。给定一个二维图像信号 f [ i , j ] f[i, j] f[i,j] 和一个二维滤波器 h [ k , l ] h[k, l] h[k,l],二维离散卷积的结果 g [ x , y ] g[x, y] g[x,y] 可以通过以下公式计算:
g [ x , y ] = ∑ k = − ∞ ∞ ∑ l = − ∞ ∞ f [ i , j ] ⋅ h [ x − i , y − j ] g[x, y] = \sum_{k=-\infty}^{\infty} \sum_{l=-\infty}^{\infty} f[i, j] \cdot h[x-i, y-j] g[x,y]=k=−∞∑∞l=−∞∑∞f[i,j]⋅h[x−i,y−j]
其中, i i i 和 j j j 表示图像中像素的坐标,而 x x x 和 y y y 表示卷积结果中像素的坐标。实际上,在离散环境中,图像的尺寸是有限的,所以卷积核 h [ k , l ] h[k, l] h[k,l] 只在有限的区域内非零,因此上述求和实际上也只在有限的范围内进行。
更具体地,如果我们有一个 M × N M \times N M×N 的图像和一个 m × n m \times n m×n 的滤波器,那么对于输出图像中的每个位置 ( x , y ) (x, y) (x,y),卷积操作可以定义为:
g [ x , y ] = ∑ k = 0 m − 1 ∑ l = 0 n − 1 f [ x + k − m / 2 , y + l − n / 2 ] ⋅ h [ k , l ] g[x, y] = \sum_{k=0}^{m-1} \sum_{l=0}^{n-1} f[x+k-m/2, y+l-n/2] \cdot h[k, l] g[x,y]=k=0∑m−1l=0∑n−1f[x+k−m/2,y+l−n/2]⋅h[k,l]
在实际应用中,我们还需要处理边界条件,例如通过填充(如零填充)或裁剪图像边缘。下方动图过程来源于CoolGPU’s Blog,展示了卷积运算的过程。
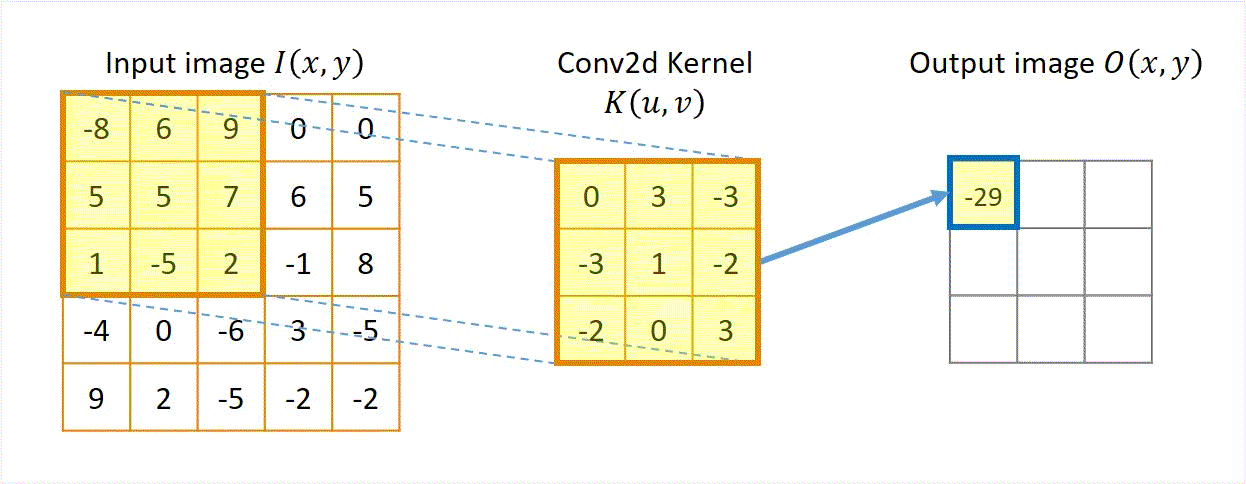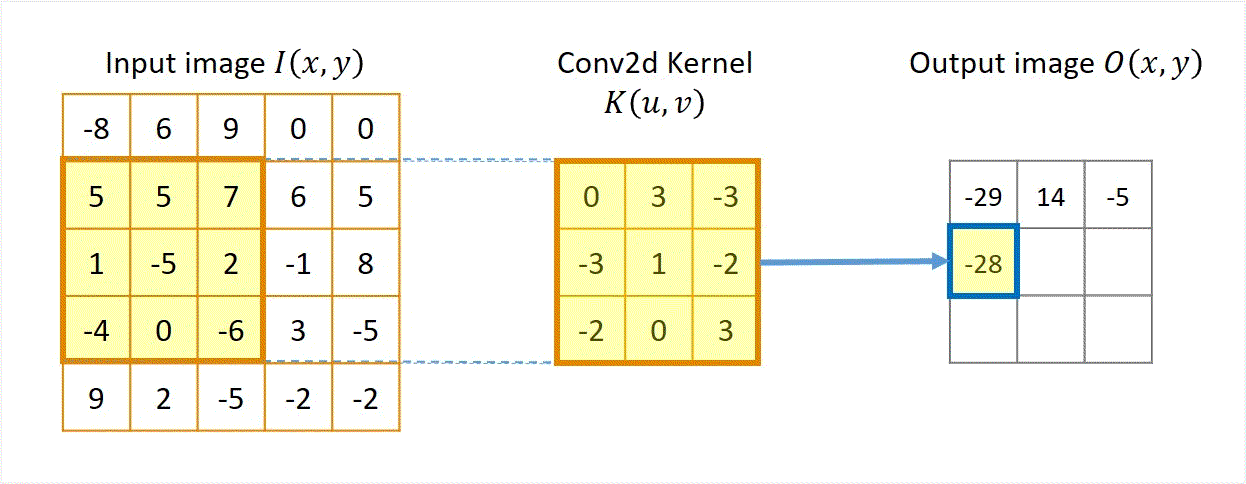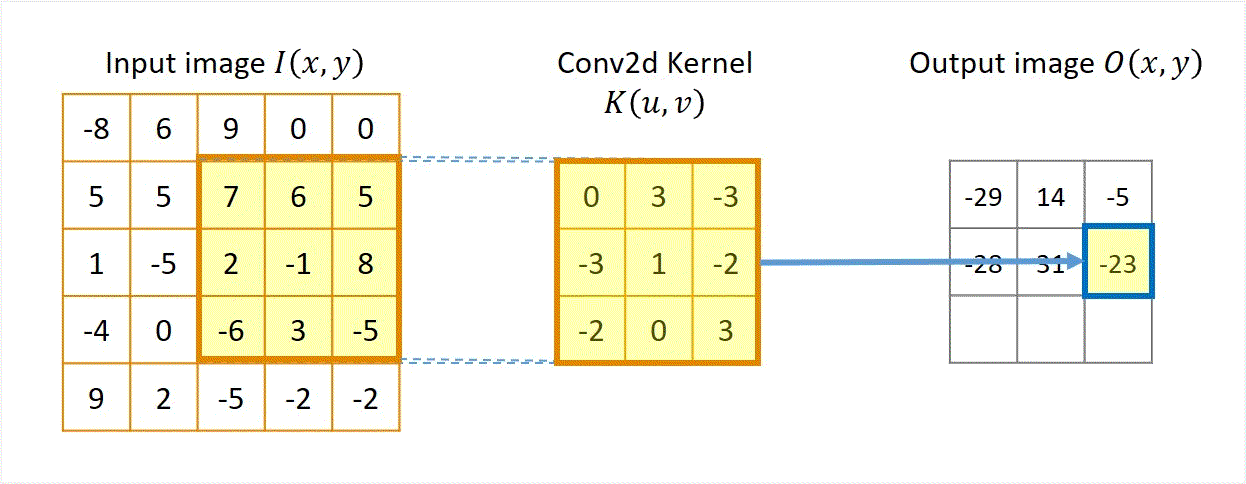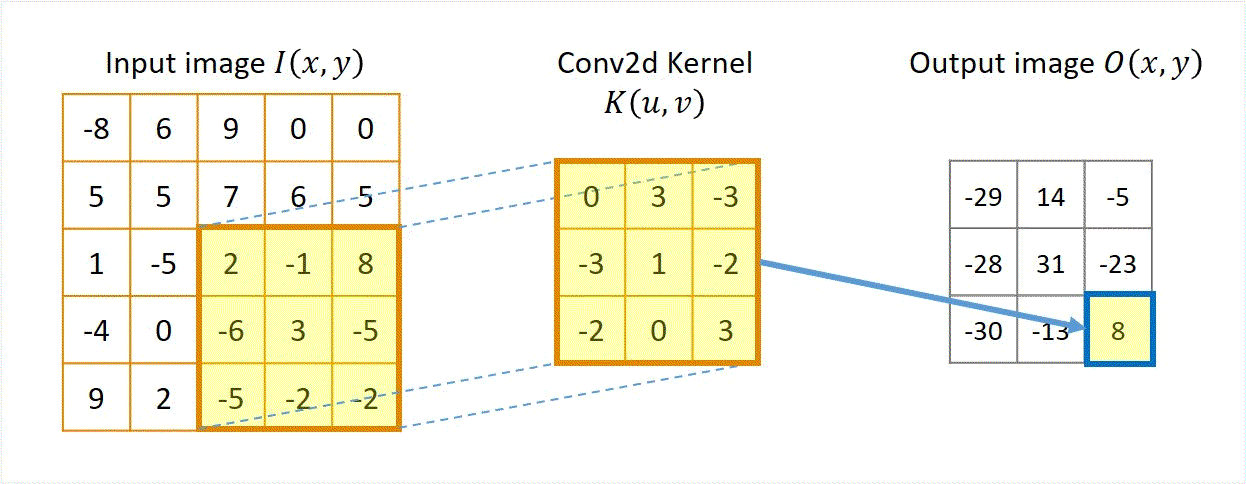
该过程展示了一张 1 × 5 × 5 1 \times 5 \times 5 1×5×5的图像,以及一个 3 × 3 3 \times 3 3×3的卷积核。在卷积运算中,我们首先将卷积核在图像上滑动,每次滑动一个像素的距离。在每次滑动中,我们计算卷积核与图像对应位置像素的乘积,并将这些乘积相加得到一个值,作为卷积运算的结果。最后,我们将这些结果拼接在一起,得到一个新的 1 × 3 × 3 1 \times 3 \times 3 1×3×3的图像。
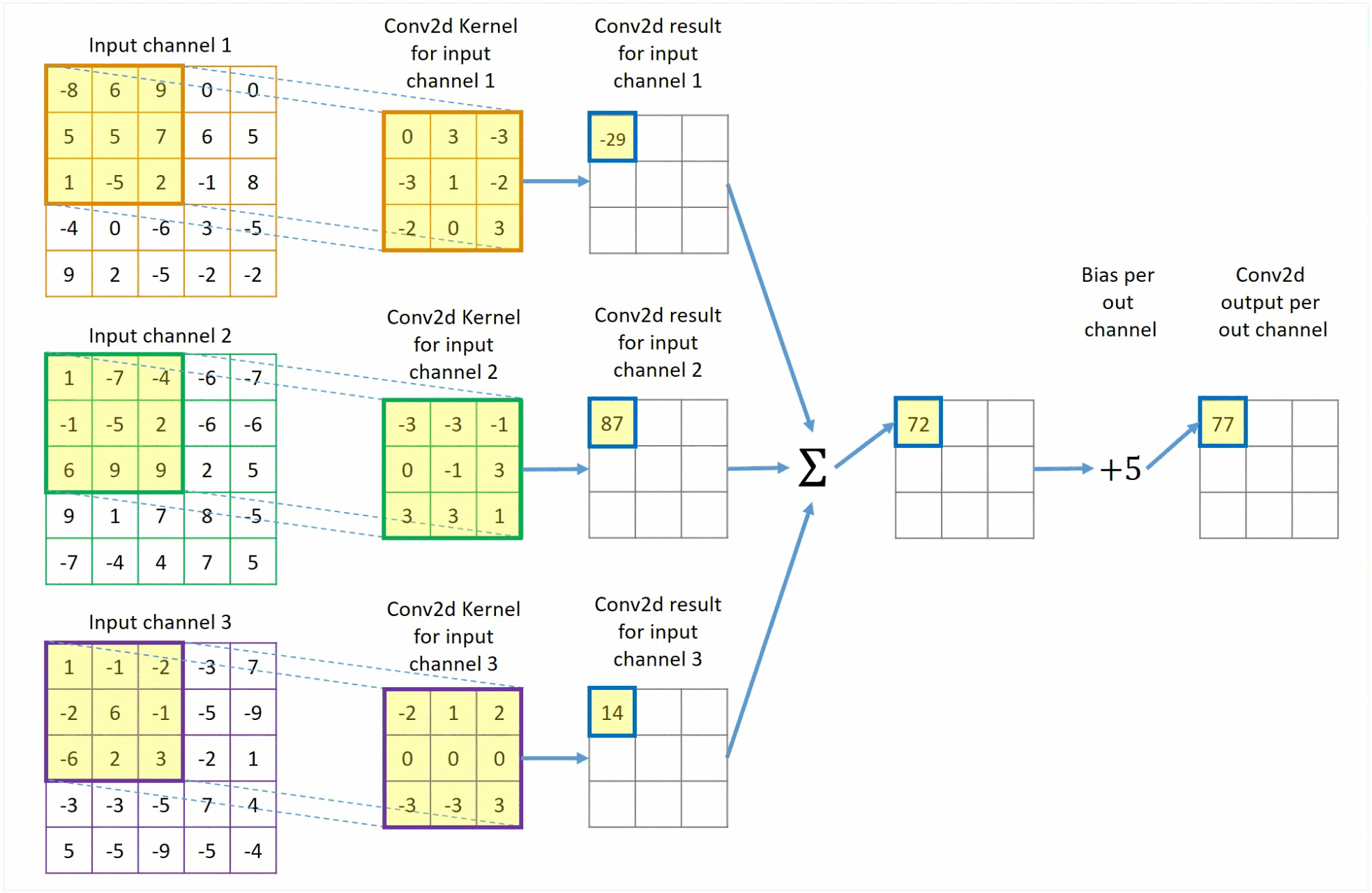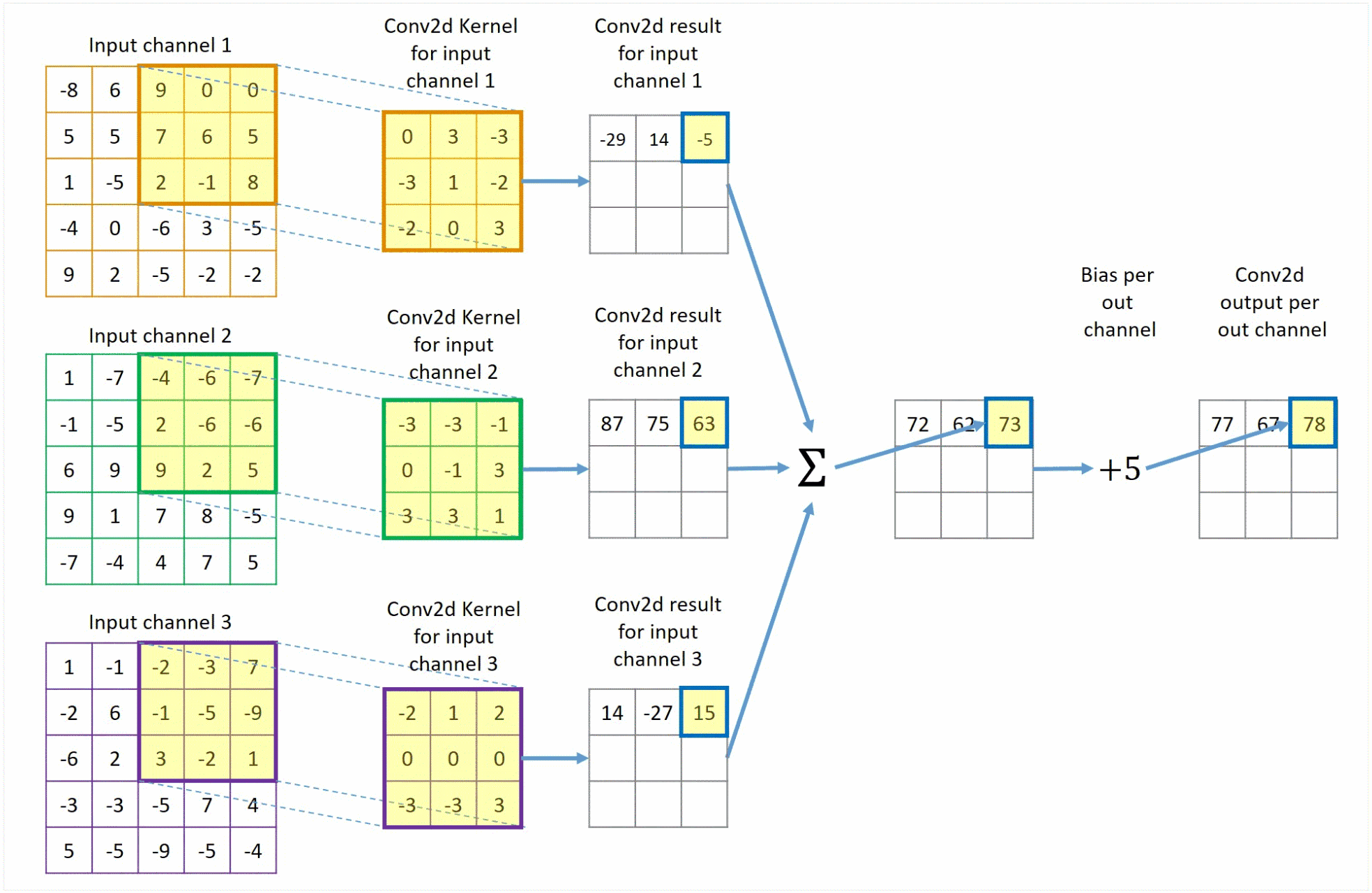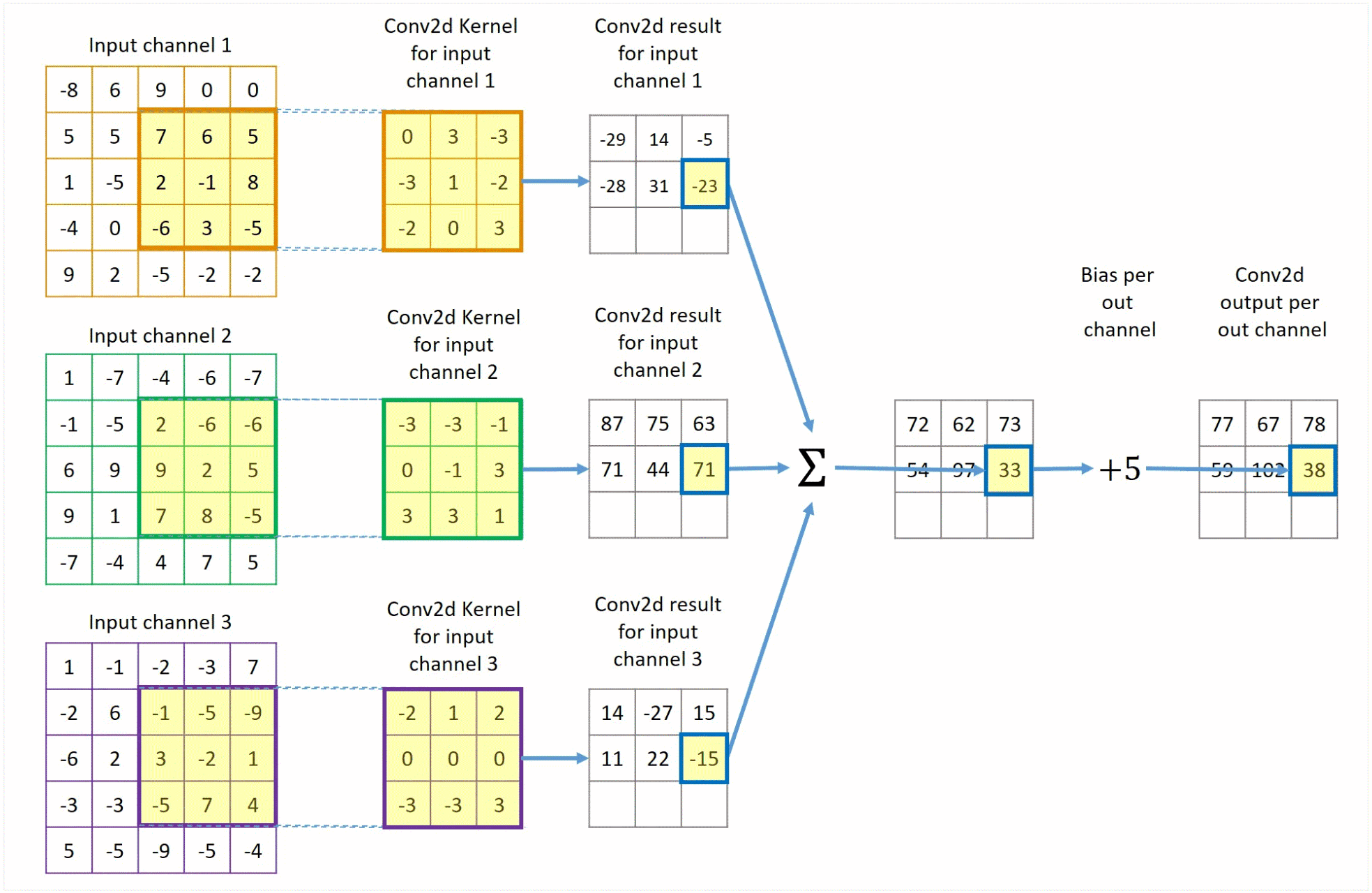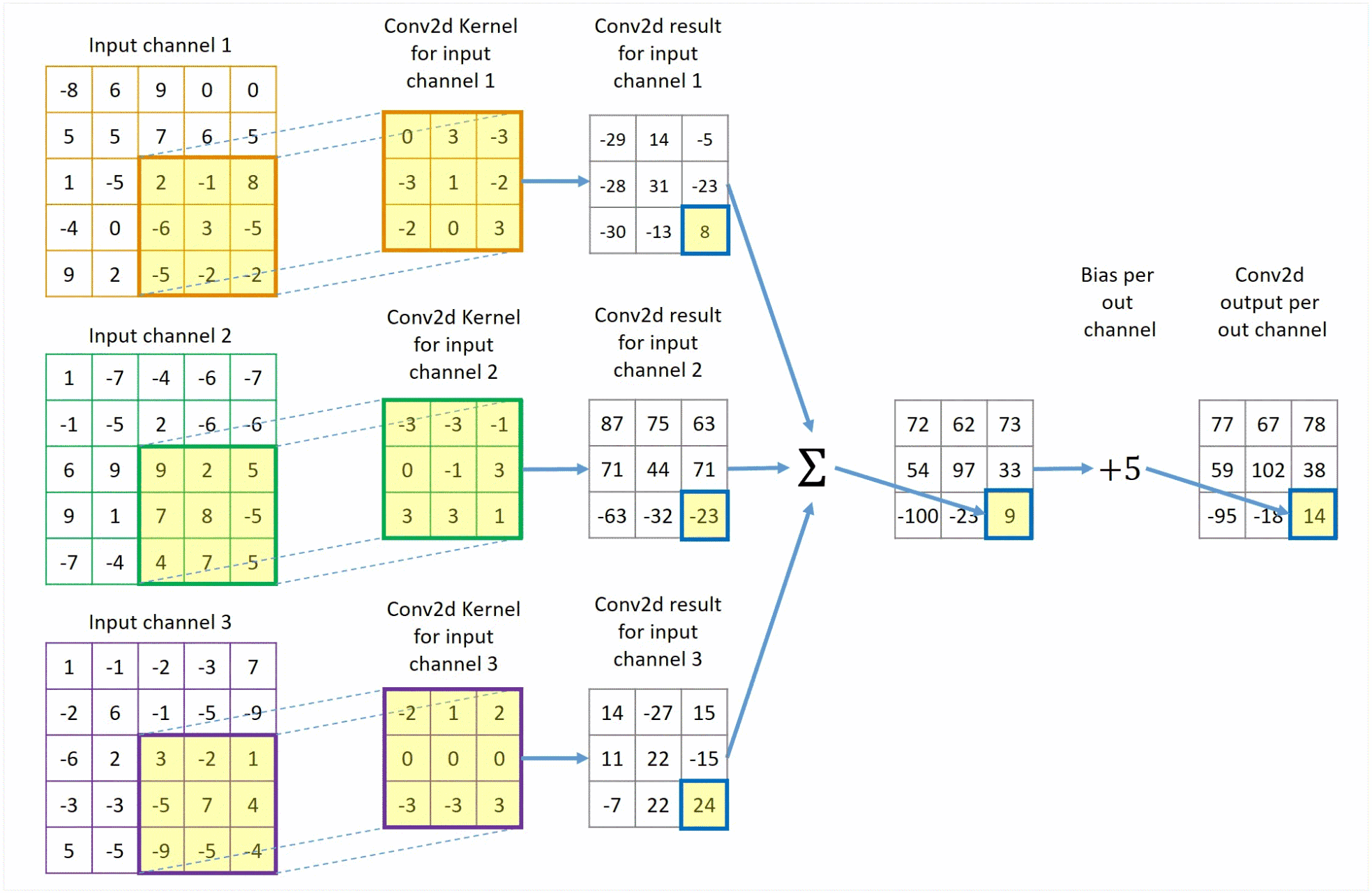
该过程展示了一张
3
×
5
×
5
3 \times 5 \times 5
3×5×5的图像,即该图像有三个通道,以及一个
3
×
3
×
3
3 \times 3 \times 3
3×3×3的卷积核。卷积核与图像进行卷积运算。最后,将这些结果对应值加在一起,算上偏置项,得到一个新的
1
×
3
×
3
1 \times 3 \times 3
1×3×3的图像。
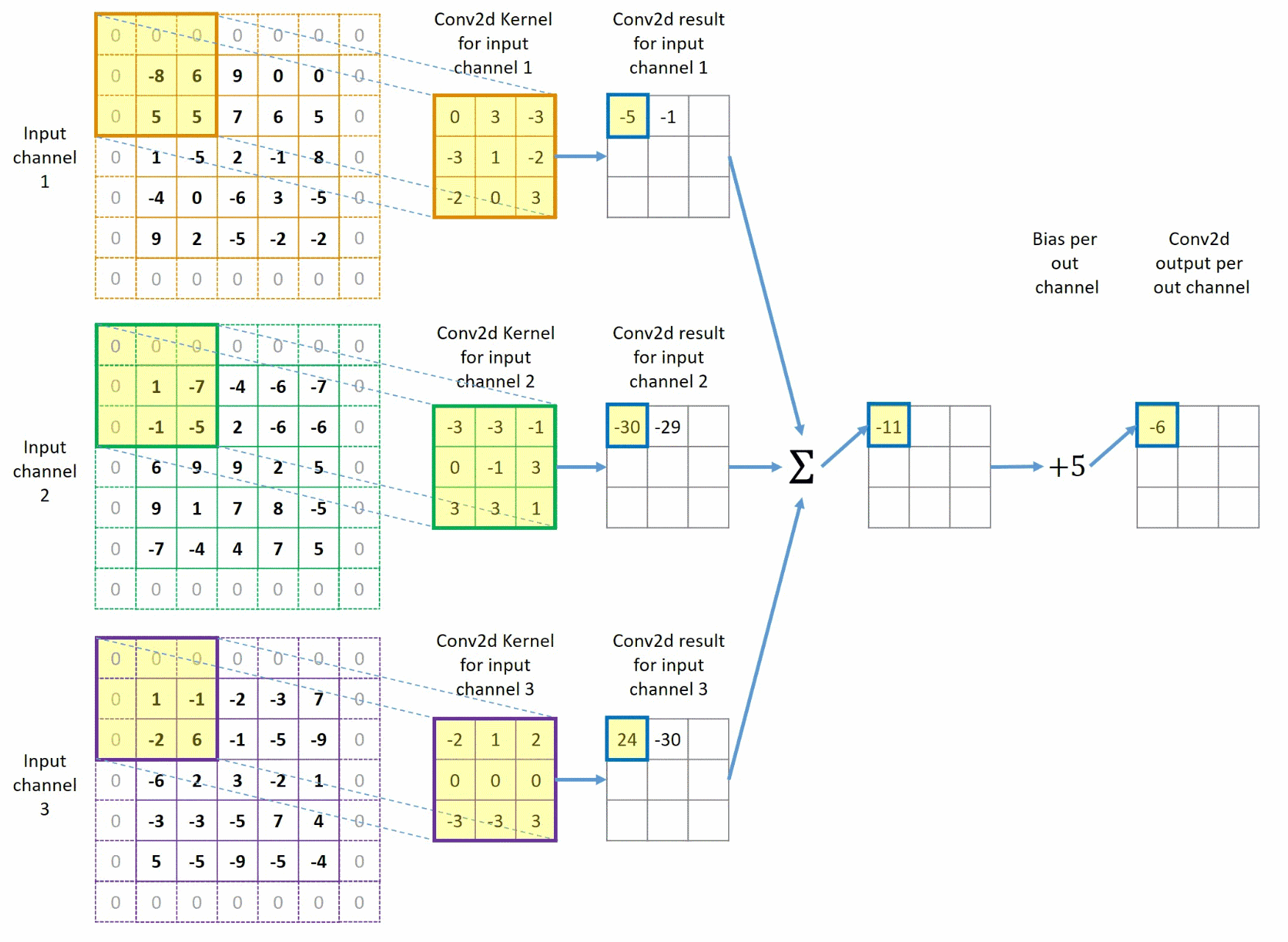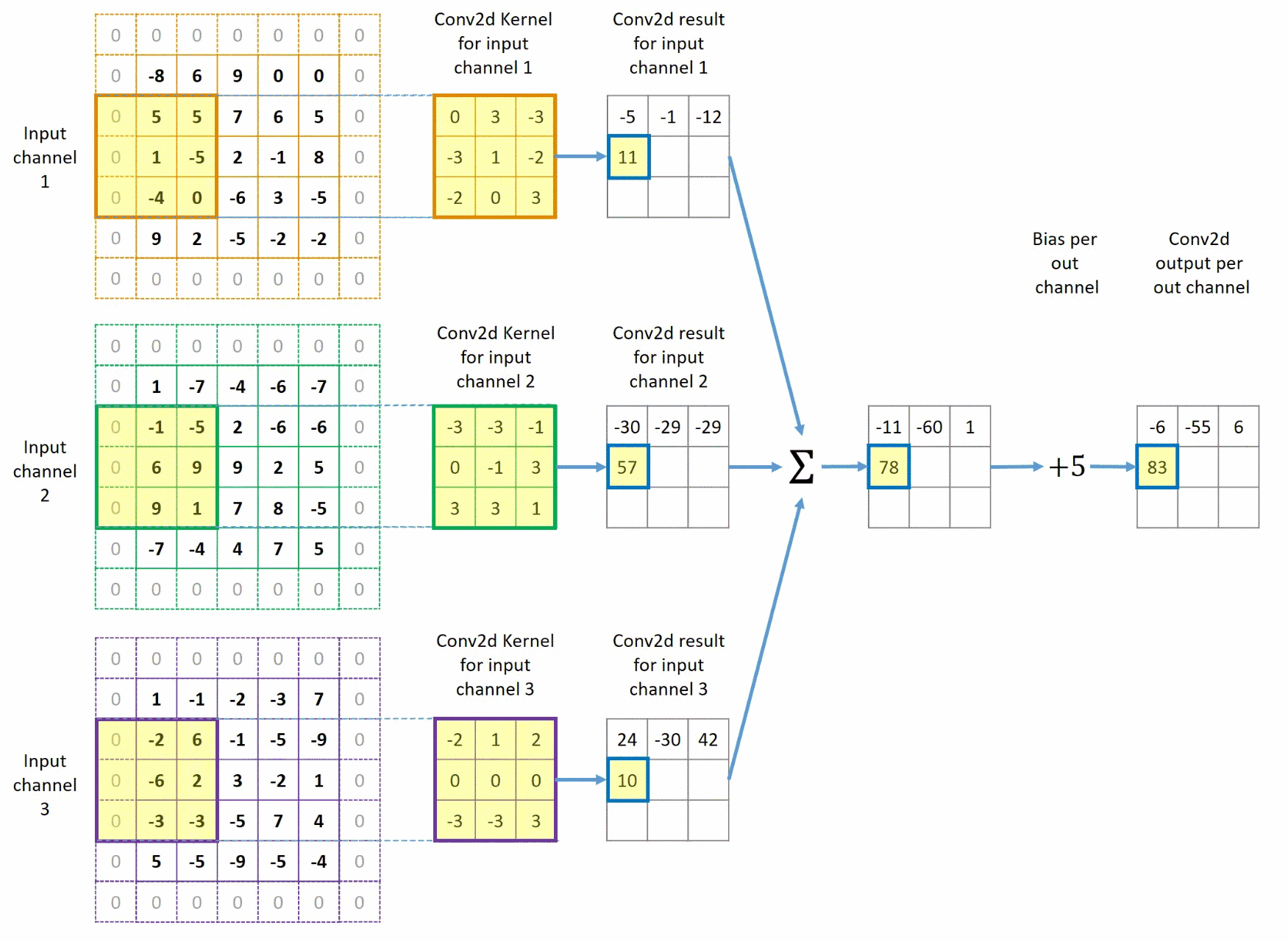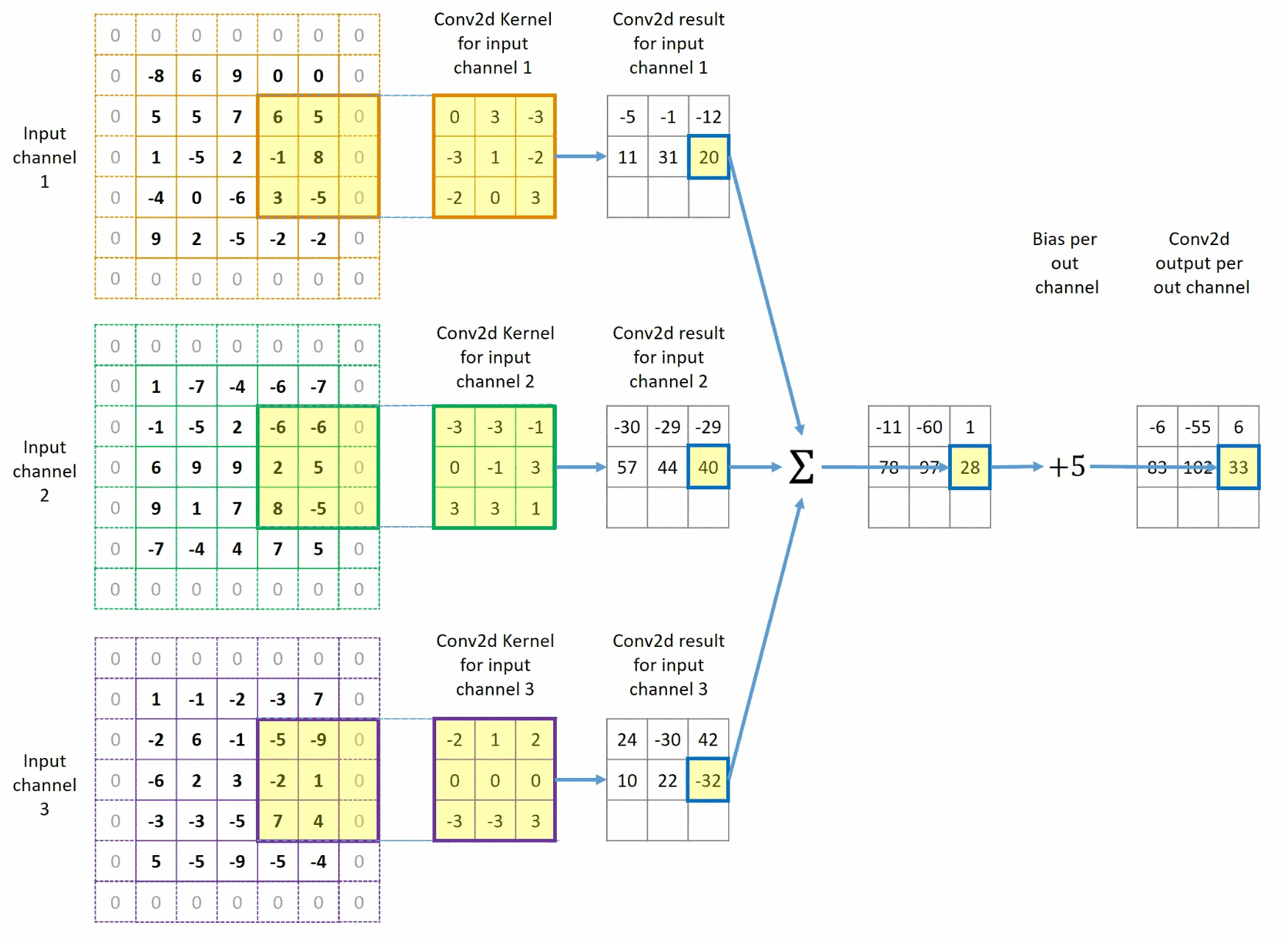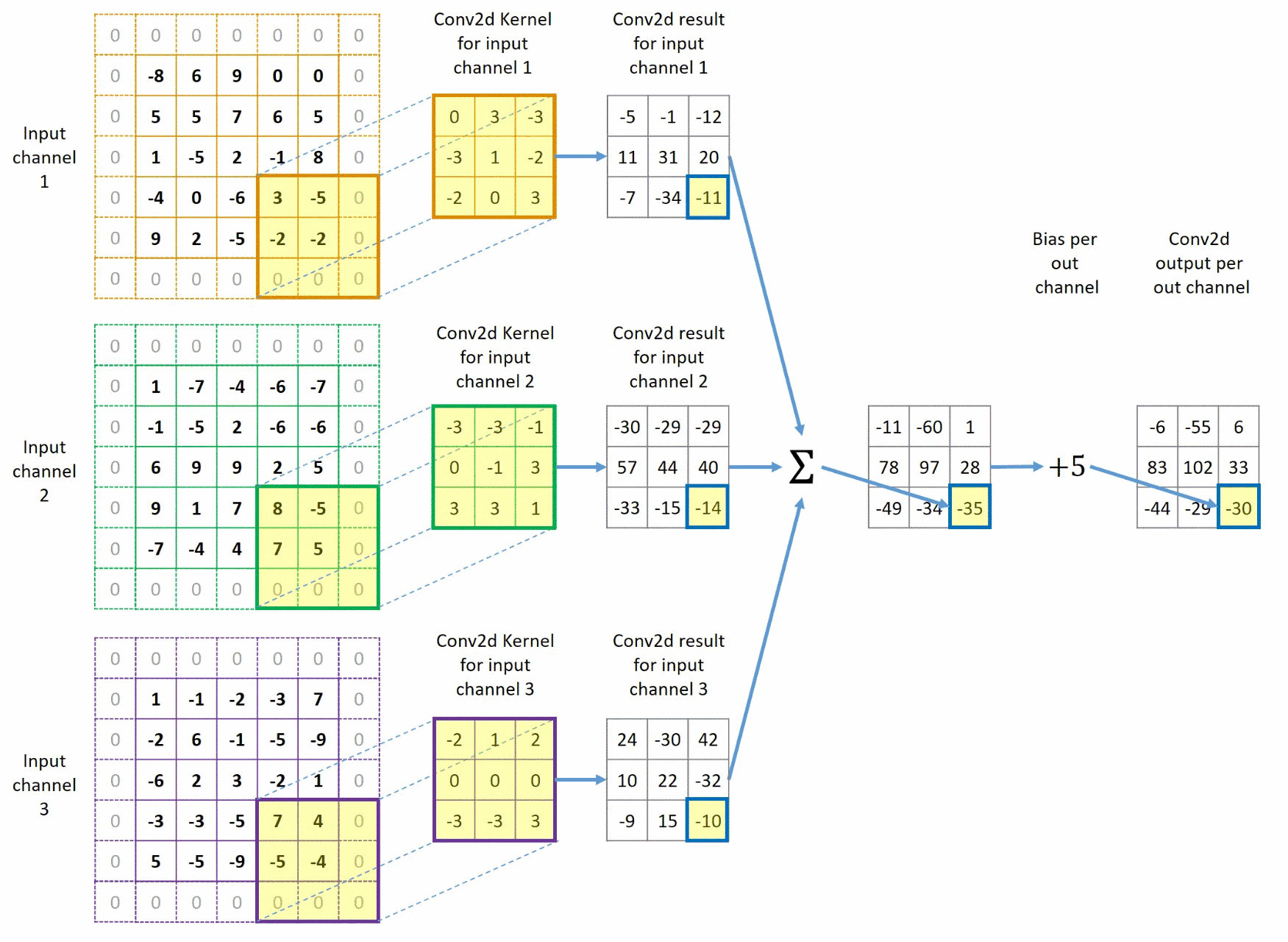
该过程与上方过程类似,但此时,我们给图像外边填充了一圈0,同时卷积核每次移动步长变为2,这样我们最终也得到了一个 1 × 3 × 3 1 \times 3 \times 3 1×3×3的图像。
卷积层设计及其梯度反向传播
首先我们导入一张图片,然后利用卷积层对其进行滤波,提取特征。
import cv2
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# 展示图像
image = cv2.imread('img/cells.png')
plt.imshow(image)

可以看到,该图片为 1133 × 1700 × 3 1133 \times 1700 \times 3 1133×1700×3的形状,我们将其转化为 1 × 3 × 1133 × 1700 1 \times 3 \times 1133 \times 1700 1×3×1133×1700的形式
# 将 ndarray 转换为 tensor
tensor = paddle.to_tensor(image)
tensor = paddle.cast(tensor, 'float32') # 将数据类型转化为float
tensor = paddle.transpose(tensor, perm=[2, 0, 1]) # 先将 channels 维度移到最前面,变为 (channels, height, width)
tensor = paddle.unsqueeze(tensor, axis=0)
接下来我们设计一个卷积层,实现图像的卷积操作。
import paddle.nn as nn
import paddle.nn.functional as F
class ConvLayer(nn.Layer):
'''
卷积层设计
'''
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(ConvLayer, self).__init__()
# 构建卷积核
self.kernel = self.create_parameter(shape=[out_channels, in_channels, kernel_size, kernel_size],
default_initializer=nn.initializer.Normal())
# 构建偏置项
self.bias = self.create_parameter(shape=[out_channels],
default_initializer=nn.initializer.Normal())
self.stride = stride
self.padding = padding
def forward(self, x):
# 使用paddle.nn.functional.conv2d执行卷积操作
out = F.conv2d(x, self.kernel, bias=self.bias, stride=self.stride, padding=self.padding)
return out
接下来,我们利用该卷积层,实现对图像在空间域的均值滤波,让我们来试试吧!
from paddle.vision.transforms import Compose, Normalize, ToTensor
conv = ConvLayer(in_channels=1, out_channels=1, kernel_size=3, stride=1, padding=1)
# 构建均值滤波卷积核
conv.kernel.set_value(paddle.ones_like(conv.kernel))
conv.bias.set_value(paddle.zeros_like(conv.bias))
out_1 = conv(tensor[0, 0, :, :].reshape([1, 1, 1133, 1700]))
out_2 = conv(tensor[0, 1, :, :].reshape([1, 1, 1133, 1700]))
out_3 = conv(tensor[0, 2, :, :].reshape([1, 1, 1133, 1700]))
# 分析可知,每一个像素由9个值相加得到,我们对每一个像素除以9
out_1 = out_1 / 9
out_2 = out_2 / 9
out_3 = out_3 / 9
# 合并输出的结果,注意PaddlePaddle的cat操作默认是在第0维进行,所以需要指定axis
out = paddle.concat([out_1, out_2, out_3], axis=0)
# 将out转化为ndarray,调整形状,并转置
out = out.numpy().transpose((0, 2, 3, 1)) # 从tensor中取出数据,调整形状
out = out.reshape(3, 1133, 1700).transpose((1, 2, 0)) # 重新调整形状以匹配所需的输出尺寸
out = out.astype(np.uint8) # 转化为整形数组
# 使用matplotlib显示图像
plt.imshow(out)

这样,我们就利用卷积神经网络实现了图像的均值滤波过程。
卷积神经网络解决分类问题的简单实现
从上述过程可以看到,卷积实际上是对图像进行某种滤波,提取图像特征的过程。下方我们将利用卷积神经网络,实现对图像的分类任务。首先我们导入数据集,并构建卷积神经网络。
import paddle
import paddle.nn as nn
import paddle.optimizer as optim
from paddle.io import DataLoader
from paddle.vision.datasets import MNIST
from paddle.vision.transforms import ToTensor
# 构建数据集
train_dataset = MNIST(mode='train', transform=ToTensor())
test_dataset = MNIST(mode='test', transform=ToTensor())
# 构建数据加载器
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 构建卷积神经网络
class CNN(nn.Layer):
def __init__(self):
super(CNN, self).__init__()
# 构建卷积层
self.conv1 = nn.Conv2D(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2D(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)
# 构建全连接层
self.fc1 = nn.Linear(32 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 卷积操作
x = paddle.nn.functional.relu(self.conv1(x))
x = paddle.nn.functional.max_pool2d(x, kernel_size=2, stride=2)
x = paddle.nn.functional.relu(self.conv2(x))
x = paddle.nn.functional.max_pool2d(x, kernel_size=2, stride=2)
# 展平操作
x = paddle.reshape(x, [x.shape[0], -1])
# 全连接操作
x = paddle.nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
# 构建模型实例
model = CNN()
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(parameters=model.parameters(), learning_rate=0.001)
# 训练模型
model.train()
for epoch in range(5):
for imgs, labels in train_loader():
outputs = model(imgs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
optimizer.clear_grad()
# 测试模型
model.eval()
total = 0
correct = 0
for imgs, labels in test_loader():
outputs = model(imgs)
_, predicted = paddle.topk(outputs, k=1, axis=1)
total += labels.shape[0]
correct += paddle.sum(paddle.equal(predicted, labels)).numpy()
print('Accuracy: %.2f %%' % (100 * correct / total))
Accuracy: 98.85 %
可以看到该模型具有较高的精度,我们不妨将图像进行的每一次操作呈现出来,看看卷积层到底提取了什么样的特征。
首先我们将模型参数保存下来。
# 保存模型参数到文件
paddle.save(model.state_dict(), 'data/model_CNN_parameters.pdparams')
接下来,我们就可以在任意时间点加载这次训练好的模型了。
# 加载模型参数
params = paddle.load('data/model_CNN_parameters.pdparams')
model = CNN()
model.set_dict(params)
([], [])
让我们看看每一次操作时,图像的特征变换
# 加载某个图片
img = imgs[3, :].reshape([1, 1, 28, 28]) # Paddle中通常需要明确指定batch size维度
img_numpy = img.numpy()
img_numpy = img_numpy.transpose(0, 2, 3, 1) # 如果需要转换为HWC格式以适配matplotlib等库
# 将图像数据放缩到0~255范围
img_numpy = 255 * img_numpy
# 转化为整形数组
img_numpy = img_numpy.astype(np.uint8)
# 使用matplotlib显示图像
plt.imshow(img_numpy[0], cmap='gray') # 假设是单通道灰度图像
plt.show()
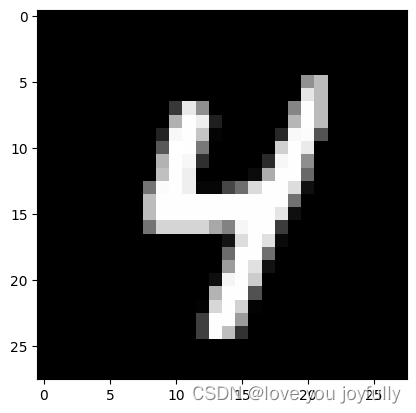
人类可以较明显的识别出该数字是几,让我们将图像送入网络看看网络的识别结果。
test_out = model(imgs[3, :].reshape([1, 1, 28, 28]))
prediction = paddle.argmax(test_out)
prediction
Tensor(shape=[], dtype=int64, place=Place(gpu:0), stop_gradient=True,
4)
可以看到,网络的识别结果也是准确的。让我们将网络每一步图像处理进行的操作展示出来。
x_out1 = paddle.nn.functional.relu(model.conv1(imgs[3, :].reshape([1, 1, 28, 28])))
x_out2 = paddle.nn.functional.max_pool2d(x_out1, kernel_size=2, stride=2)
x_out3 = paddle.nn.functional.relu(model.conv2(x_out2))
x_out4 = paddle.nn.functional.max_pool2d(x_out3, kernel_size=2, stride=2)
import math
def transform_imag(img):
# 将tensor格式转换为合适的图片
_, channels, cols, rows = img.shape
img = img.numpy()
img = img.transpose(0, 2, 3, 1)
# 将图像放缩到0~255
img = 255 * img
img = img.astype(np.uint8) # 转化为整形数组
return img[0]
def show_Features(img):
# 展示img中包含的特征
c, r, channels = img.shape
cols = round(math.sqrt(channels))
for i in range(channels):
plt.subplot(cols, math.ceil(channels / cols), i+1)
plt.imshow(img[:, :, i].reshape(c, r, 1))
plt.show()
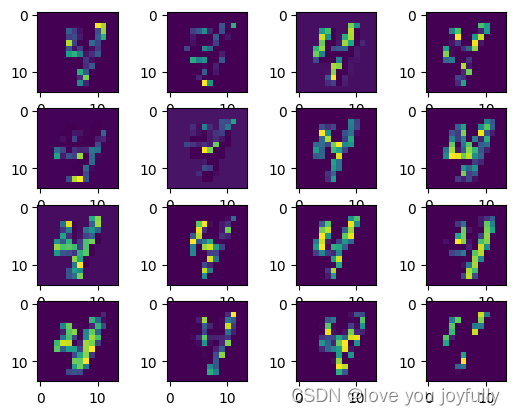
img1 = transform_imag(x_out1)
show_Features(img1)

img2 = transform_imag(x_out2)
show_Features(img2)
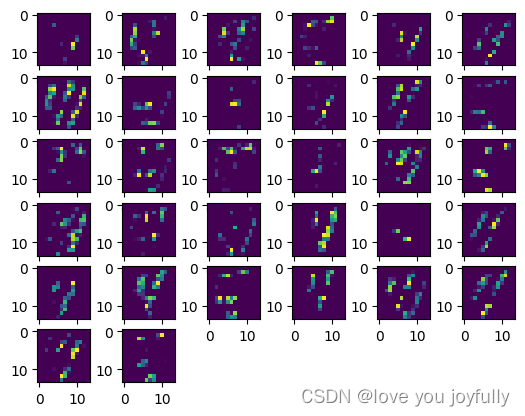
img3 = transform_imag(x_out3)
show_Features(img3)
img4 = transform_imag(x_out4)
show_Features(img4)
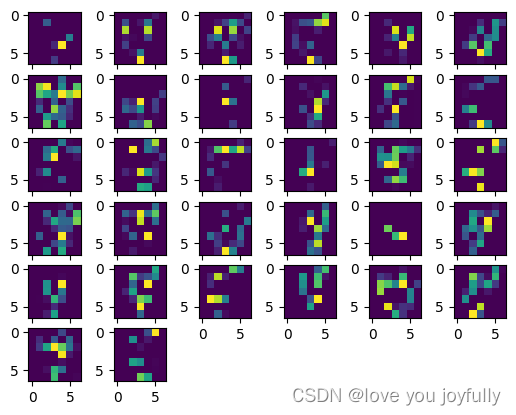
可以看到,网络图像越到后边层,各图像内容越简单且越抽象。
本文部分为paddle框架以及部分理论分析,torch框架对应代码可见卷积神经网络——pytorch与paddle实现卷积神经网络
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 卷积神经网络——paddle部分

发表评论 取消回复