RNN存在的问题
因为RNN模型的BPTT反向传导的链式求导,导致需要反复乘以一个也就是说会出现指数级别的问题:
- 梯度爆炸:如果
的话,那么连乘的结果可能会快速增长,导致梯度爆炸
- 梯度消失:如果
的话,连乘的结果会迅速衰减到零,导致梯度消失
存在以上问题导致RNN无法获得上下文的长期依赖信息
改进网络——GRU
GRU,即门控循环单元(Gated Recurrent Unit)
1、GRU的基本结构
GRU通过两种门组件和两种记忆状态解决了梯度消失
(1)两种门组件
① 重置门
重置门(reset gate),记为

这个门决定了上一时间步的记忆状态如何影响当前时间步的候选记忆内容。
计算时会结合前一时间步的隐藏状态 

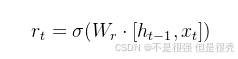
② 更新门
更新门(update gate),记为 
这个门决定了上一时间步的记忆状态有多少需要传递到当前时间步,以及当前的输入信息有多少需要加入到新的记忆状态中
同样,它也是基于
(2)两种记忆状态
① 候选记忆状态
候选记忆状态(candidate memory),记为 
这是基于当前输入
其中的重置门决定了如何“重置”旧的记忆状态,以便更好地整合新信息。对应的数学表达如下:
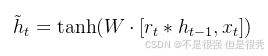
② 最终记忆状态
最终记忆状态(hidden state)记为 
通过结合更新门的输出和候选记忆状态以及上一时间步的记忆状态来计算得出的。其中更新门决定了新旧记忆的混合比例。对应的数学表达如下:
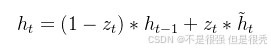
一下表格汇总了上述公式用到的符号表示:
| 符号 | 解释 |
 | 更新门 |
 | 重置门 |
 | 当前时刻的隐藏状态 |
 | 候选隐藏状态 |
| 前一时刻的隐藏状态 |
 | 当前时刻的输入 |
 | 对应的训练参数 |
 | sigmoid激活函数 |
 | Hadamard积(按元素乘积)运算符 |
(3)网络结构
了解了公式推导,还是不能直观的清楚GRU到底长什么样子,下面我们逐层递加的研究一下GRU的网络结构
① 更新门和重置门的结构
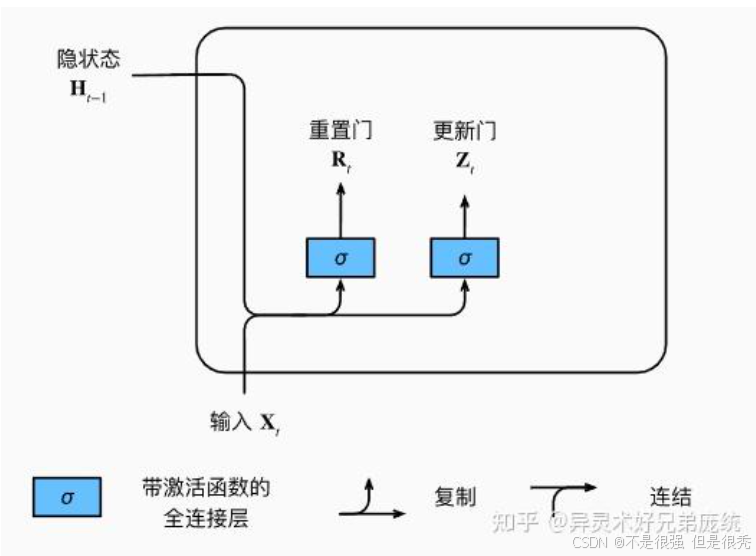
上图描述了门控循环单元中的重置门和更新门的输入
输入是由 当前时间步的输入 和 前一时间步的隐状态 给出
两个门的输出是由 使用sigmoid激活函数的两个全连接层给出
② 候选隐藏状态的结构
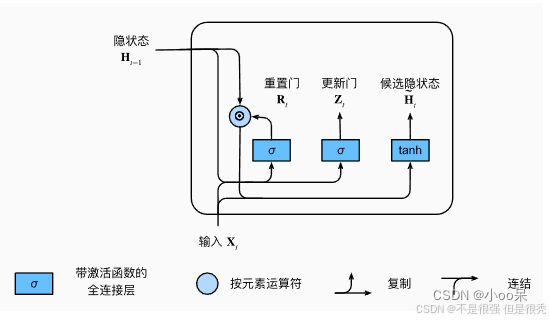
在重置门和更新门的基础上加入了候选隐状态
重置门结果通过作用在前一时间步的隐状态上来影响候选隐状态
③ GRU的循环块结构
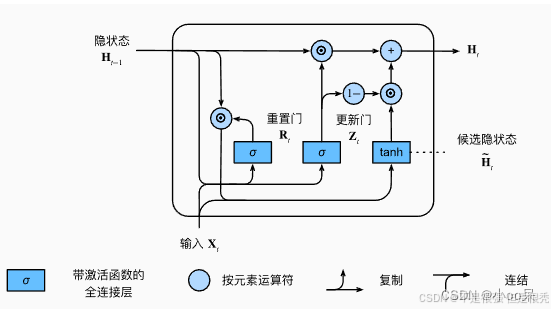
更新门结果作用在隐状态和候选隐状态上
更新门结果作为一个比例来调节 隐状态 和 候选隐状态
2、门控循环单元特征
-
重置门有助于捕获序列中的短期依赖关系;
-
更新门有助于捕获序列中的长期依赖关系。
3、GRU为什么可以缓解RNN梯度问题
在传统的RNN中,由于长时间依赖问题,反向传播过程中梯度可能会因连续乘以小于1的数而变得非常小,导致早期时间步的权重几乎不更新,这就是梯度消失问题。
而GRU通过其独特的门控机制,特别是更新门和重置门的设计,能够更加灵活地控制信息流:
更新门:有助于模型决定在每一步中应该保留多少之前时刻的信息。它可以让模型在需要的时候保持激活状态,这样有助于后续的梯度传递而不会随时间迅速减小。如果更新门接近1,那么梯度可以在很多时间步内传递而不衰减,使得长期依赖的信息得到保留。
重置门:帮助模型决定忽略多少之前的信息。重置门可以用来减少那些不太相关信息的影响,从而保护模型不会把注意力放在不相关的长期依赖上。当选择忽略一些不相关的信息时,梯度将不会在这部分信息上进行传递,这有助于集中于更相关的信息,并有助于梯度完整地在其他相关部分传递。
因为有了这样的机制,GRU能够在每次更新中将梯度既不是完全传递也不是完全阻断,而是能够在相关的部分进行传递。这样在优化过程中,即使对于较长的序列,也能够更加稳定地保留梯度,防止了梯度极端消失,这对于学习长期依赖至关重要。因此,GRU往往在处理长序列数据时比传统RNN更加有效。
改进网络——LSTM
长短期记忆网络(LSTM)是一种解决隐变量模型长期信息保存和短期输入缺失问题的方法
有趣的是,长短期记忆网络的设计比门控循环单元稍微复杂一些, 却比门控循环单元早诞生了近20年。
在统计学中,隐变量或称潜变量,潜在变量,与观测变量相对,指的是不可观测的随机变量。
潜变量可以通过使用数学模型依据观测得的数据被推断出来。用潜在变量解释观测变量的数学模型称为潜变量模型。 有些情况下,潜变量和现实中的一些因素是有关系的。测量这些因素理论上可行,实际上却很困难。这些情况里通常使用“隐变量(hidden variables)”这个词。
另外一些情况下,潜变量指的是抽象概念,例如分类、行为、心理状态、数据结构等等。在这些情况下人们用 hypothetical variables 或者 hypothetical constructs 指代潜变量。
使用潜变量的好处之一是潜变量能用来降低数据的维度。大量的观测变量能够被整合起来成为一个潜变量来表示深层次的概念,使得观测数据更容易理解。
1、LSTM的基本结构
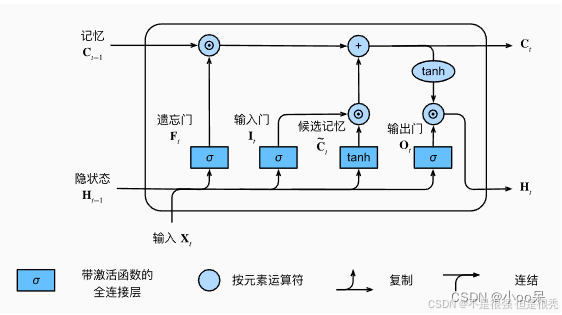
(1)输入门
输入门(Input Gate)记为 
其中 




(2)遗忘门
遗忘门(Forget Gate)记为 
其中 

(3)细胞状态
细胞状态(Cell State)记为 
它通过点积运算结合遗忘门和前一时间步的细胞状态,以及输入门和一个新的候选记忆状态来更新。
候选记忆状态是由当前输入和一个输入的权重矩阵通过tanh激活函数得到的。 数学表达式为:
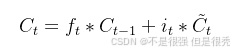
候选细胞状态,记为
隐藏状态,记为
(4)输出门
输出门(Output Gate)记为 
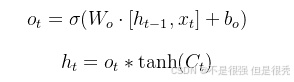
其中 

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 秃姐学AI系列之:GRU——门控循环单元 | LSTM——长短期记忆网络

发表评论 取消回复