redis是单线程架构还是多线程架构
Redis 的核心操作是单线程架构,但在某些场景中也会使用多线程。
Redis 的大部分操作(如键值存储、查询、更新等)是通过单线程完成的,即所有客户端的请求在 Redis 中按顺序执行。这种设计主要出于以下考虑:
- 避免锁竞争:单线程架构可以避免多线程并发操作导致的数据一致性问题,不需要加锁处理,降低了复杂性。
- 提升性能:单线程架构减少了锁管理的开销,并且借助高效的 I/O 多路复用(如
epoll),能够实现高性能的数据读写。 - 适合 I/O 密集型场景:Redis 的数据主要存储在内存中,单线程模式足以满足大多数读写需求。
Redis 在某些场景下(例如持久化、异步删除、网络 I/O)会使用多线程,以提升整体性能:
- DB/AOF 持久化:当 Redis 将数据写入磁盘(如快照或日志)时,通常会使用多线程来避免持久化操作阻塞主线程。
- 异步删除:在删除较大的数据对象(如大型集合)时,Redis 会启用后台线程来完成删除,避免阻塞主线程的读写。
- I/O 多线程:在 Redis 6.0 之后,引入了多线程的网络 I/O,Redis 能在接收数据时使用多线程进行处理,从而提高并发量。
单线程的redis为什么这么快
- 1.大部分操作基于内存,有高效的数据结构(简单动态字符串 双向链表 压缩列表 哈希表 跳跃表 整数数组)
- 2.选择单线程,避免了多线程上下文切换和竞争
- 3.redis底层采用io多路复用技术,能够保证大量并发下的效率,提高系统的吞吐量
Redis6.x 之后为何引入了多线程?
Redis 6.x 引入多线程,主要是为了解决网络 I/O 成为瓶颈的问题,从而提高 Redis 的并发处理能力,尤其在处理大量并发连接和数据传输时。单线程 I/O 的瓶颈主要是这样的:Redis 是单线程模型处理所有任务,包括网络 I/O和数据操作。由于网络 I/O 也在单线程内完成,所有请求的处理顺序被严格限制在一个线程中。这样一来,即使 Redis 数据操作本身非常快,大量的并发请求和网络传输的频繁切换也会成为性能瓶颈,造成 I/O 阻塞,从而延长响应时间。
虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了, 执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。多线程可以让多个客户端请求的 I/O 操作并行进行,从而减少 I/O 阻塞和等待的时间。
Redis6.x多线程的实现机制?
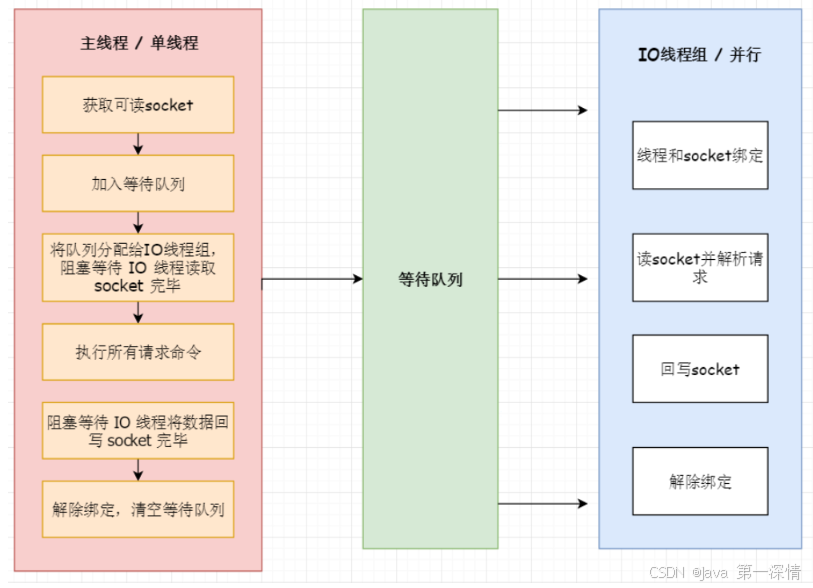
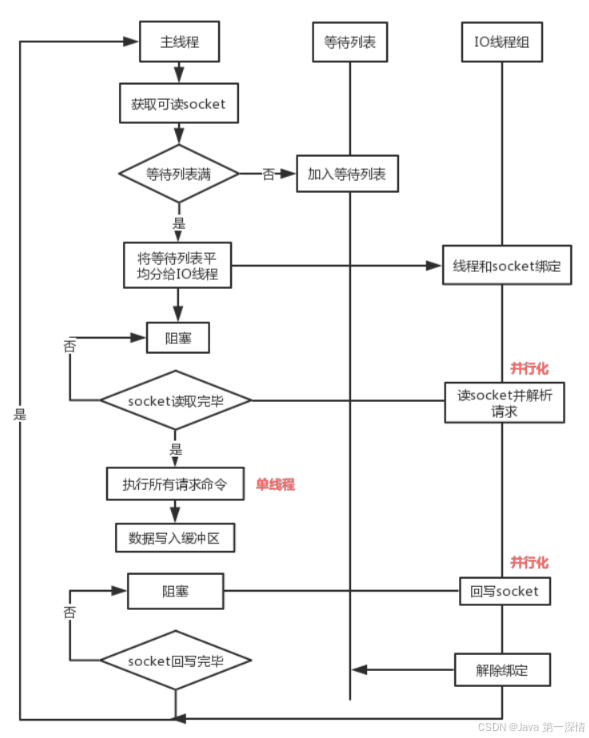
流程简述如下:
- 主线程负责接收建立连接请求,获取 Socket 放入全局等待读处理队列。
- 主线程处理完读事件之后,通过 RR(Round Robin)将这些连接分配给这些 IO 线程。
- 主线程阻塞等待 IO 线程读取 Socket 完毕。
- 主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行。
- 主线程阻塞等待 IO 线程将数据回写 Socket 完毕。
- 解除绑定,清空等待队列。
Redis6.x默认是否开启了多线程?
Redis6.0 的多线程默认是禁用的,只使用主线程
如需开启需要修改 redis 配置文件 redis.conf :
io-threads-do-reads yes开启多线程后,还需要设置线程数,否则是不生效的。同样需要修改 redis 配置文件 redis.conf :
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,造成数据库的压力倍增的情况
例:发起为id值为 -1 的数据或 id 为特别大不存在的数据
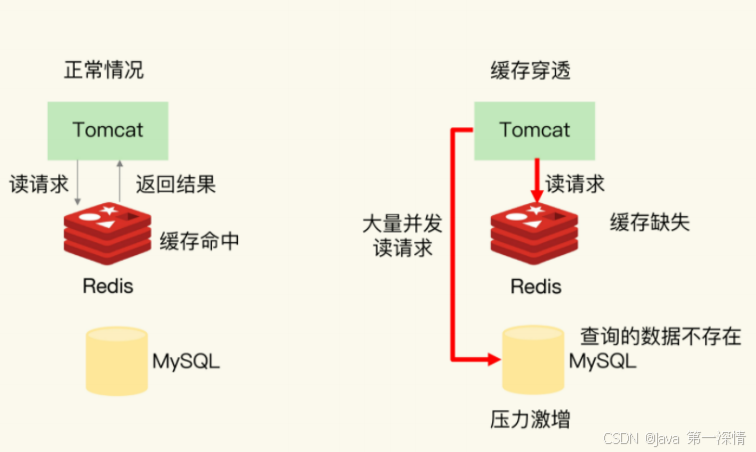
解决方案:
(1)接口层增加校验,比如用户鉴权校验,参数做校验 比如:id 做基础校验,id <=0的直接拦截
(2)对于像ID为负数的非法请求直接过滤掉,采用布隆过滤器(Bloom Filter)
(3)针对在数据库中找不到记录的,我们仍然将该空数据存入缓存中,当然一般会设置一个较短的过期时间
缓存雪崩
缓存服务器宕机或者大量缓存集中某个时间段失效,导致请求全部去到数据库,造成数据库压力倍增的情况,这个是针对多个key而言
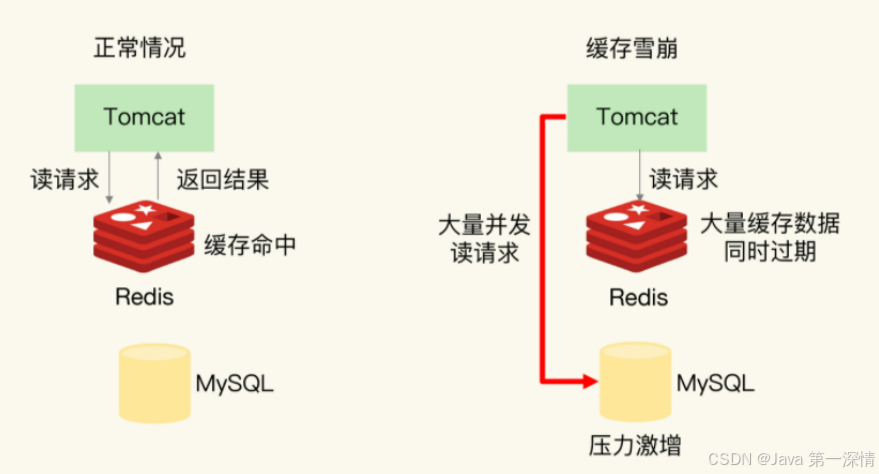
解决:
(1)实现缓存高可用,通过redis cluster将热点数据均匀分布在不同的Redis库中也能避免全部失效的问题
(2)批量往Redis存数据的时候,把每个Key的失效时间都加个随机值
setRedis(Key,value,time + Math.random() * 10000);缓存击穿
redis过期后的一瞬间,有大量用户请求同一个缓存数据,导致这些请求都去请求数据库,造成数据库压力倍增的情,针对一个key而言
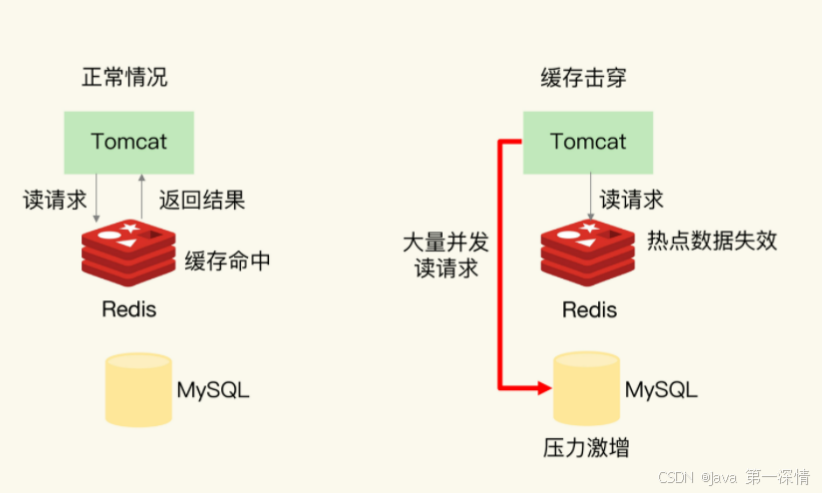
缓存击穿与缓存雪崩的区别是:击穿针对的是某一热门key缓存,而雪崩针对的是大量缓存的集中失效
解决方案就是热点数据用不过期
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Redis经典面试题-深度剖析

发表评论 取消回复