一、前言
GLM-4是智谱AI团队于2024年1月16日发布的基座大模型,旨在自动理解和规划用户的复杂指令,并能调用网页浏览器。其功能包括数据分析、图表创建、PPT生成等,支持128K的上下文窗口,使其在长文本处理和精度召回方面表现优异,且在中文对齐能力上超过GPT-4。与之前的GLM系列产品相比,GLM-4在各项性能上提高了60%,并且在指令跟随和多模态功能上有显著强化,适合于多种应用场景。尽管在某些领域仍逊于国际一流模型,GLM-4的中文处理能力使其在国内大模型中占据领先地位。该模型的研发历程自2020年始,经过多次迭代和改进,最终构建出这一高性能的AI系统。
在开源模型应用落地-glm模型小试-glm-4-9b-chat-快速体验(一)已经掌握了glm-4-9b-chat的基本入门。
在开源模型应用落地-glm模型小试-glm-4-9b-chat-批量推理(二)已经掌握了glm-4-9b-chat的批量推理。
在开源模型应用落地-glm模型小试-glm-4-9b-chat-Gradio集成(三)已经掌握了如何集成Gradio进行页面交互。
在开源模型应用落地-glm模型小试-glm-4-9b-chat-vLLM集成(四)已经掌握了如何使用vLLM进行推理加速。
在开源模型应用落地-glm模型小试-glm-4-9b-chat-tools使用(五)已经掌握了如何在vLLM环境下,正确使用tools。
本篇将介绍如何对glm-4-9b-chat模型进行压力测试。
二、术语
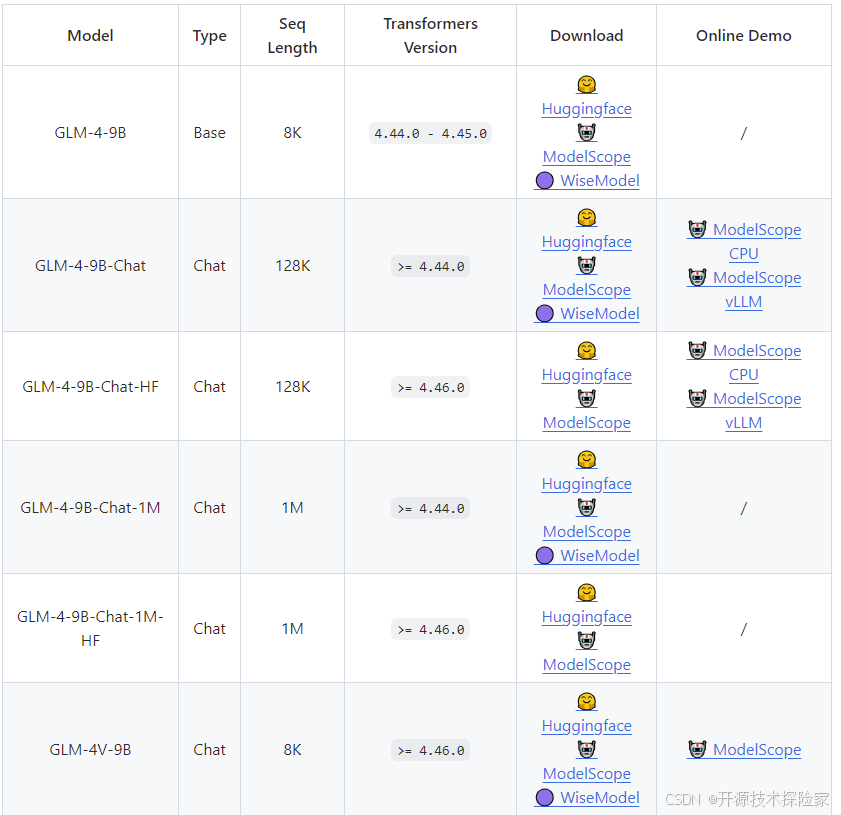
2.1.GLM-4-9B
是智谱 AI 推出的一个开源预训练模型,属于 GLM-4 系列。它于 2024 年 6 月 6 日发布,专为满足高效能语言理解和生成任务而设计,并支持最高 1M(约两百万字)的上下文输入。该模型拥有更强的基础能力,支持26种语言,并且在多模态能力上首次实现了显著进展。
GLM-4-9B的基础能力包括:
- 中英文综合性能提升 40%,在特别的中文对齐能力、指令遵从和工程代码等任务中显著增强
- 较 Llama 3 8B 的性能提升,尤其在数学问题解决和代码编写等复杂任务中表现优越
- 增强的函数调用能力,提升了 40% 的性能
- 支持多轮对话,还支持网页浏览、代码执行、自定义工具调用等高级功能,能够快速处理大量信息并给出高质量的回答
2.2.GLM-4-9B-Chat
是智谱 AI 在 GLM-4-9B 系列中推出的对话版本模型。它设计用于处理多轮对话,并具有一些高级功能,使其在自然语言处理任务中更加高效和灵活。
2.3.压力测试
是指对模型在高负载或极端条件下进行的性能评估。这种测试的目标是确定模型在处理大量请求时的响应时间、资源消耗、准确性和稳定性。
模型压力测试的主要目标
1. 评估响应时间:测量模型在接收多个并发请求时的推理时间,以及在高负载情况下的延迟。
2. 资源使用情况:评估CPU、内存、GPU等资源的消耗,了解模型在高并发情况下对硬件资源的要求。
3. 稳定性和可靠性:检查模型在负载增加时是否能够持续提供准确的输出,识别潜在的崩溃或故障点。
4. 错误处理能力:测试模型在处理异常输入或极端情况时的表现,分析模型是否能够正确处理不确定性。
5. 扩展性:评估模型在增加负载或数据量时的扩展能力,判断是否需要进行优化或升级。
三、前置条件
3.1.基础环境及前置条件
1. 操作系统:centos7
2. NVIDIA Tesla V100 32GB CUDA Version: 12.2
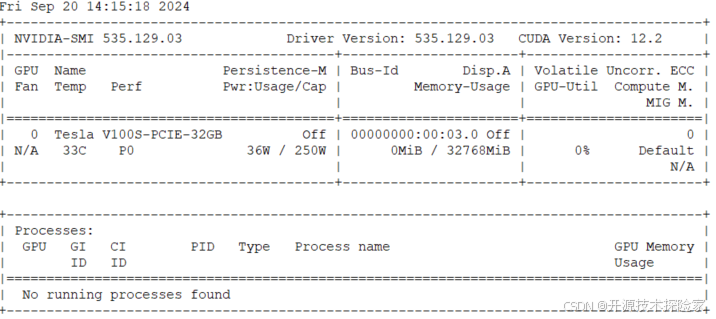
3.最低硬件要求

3.2.下载模型
huggingface:
https://huggingface.co/THUDM/glm-4-9b-chat/tree/main
ModelScope:
使用git-lfs方式下载示例:
3.3.创建虚拟环境
conda create --name glm4 python=3.10
conda activate glm43.4.安装依赖库
pip install torch>=2.5.0
pip install torchvision>=0.20.0
pip install transformers>=4.46.0
pip install sentencepiece>=0.2.0
pip install jinja2>=3.1.4
pip install pydantic>=2.9.2
pip install timm>=1.0.9
pip install tiktoken>=0.7.0
pip install numpy==1.26.4
pip install accelerate>=1.0.1
pip install sentence_transformers>=3.1.1
pip install einops>=0.8.0
pip install pillow>=10.4.0
pip install sse-starlette>=2.1.3
pip install bitsandbytes>=0.43.3四、技术实现
4.1.代码实现
# -*- coding: utf-8 -*-
import time
from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer, BitsAndBytesConfig
import torch
from threading import Thread
modelPath = "/data/model/glm-4-9b-chat"
def loadTokenizer():
tokenizer = AutoTokenizer.from_pretrained(modelPath, paddsing_side="left", trust_remote_code=True)
return tokenizer
def loadModel():
model = AutoModelForCausalLM.from_pretrained(
modelPath,
torch_dtype=torch.float16,
trust_remote_code=True,
device_map="auto").eval()
return model
def stress_test(token_len, n, num_gpu):
device = torch.device(f"cuda:{num_gpu - 1}" if torch.cuda.is_available() and num_gpu > 0 else "cpu")
tokenizer = loadTokenizer()
model = loadModel()
times = []
decode_times = []
print("Warming up...")
vocab_size = tokenizer.vocab_size
warmup_token_len = 20
random_token_ids = torch.randint(3, vocab_size - 200, (warmup_token_len - 5,), dtype=torch.long)
start_tokens = [151331, 151333, 151336, 198]
end_tokens = [151337]
input_ids = torch.tensor(start_tokens + random_token_ids.tolist() + end_tokens, dtype=torch.long).unsqueeze(0).to( device)
attention_mask = torch.ones_like(input_ids, dtype=torch.float16).to(device)
position_ids = torch.arange(len(input_ids[0]), dtype=torch.float16).unsqueeze(0).to(device)
warmup_inputs = {
'input_ids': input_ids,
'attention_mask': attention_mask,
'position_ids': position_ids
}
with torch.no_grad():
_ = model.generate(
input_ids=warmup_inputs['input_ids'],
attention_mask=warmup_inputs['attention_mask'],
max_new_tokens=2048,
do_sample=True,
repetition_penalty=1.0,
eos_token_id=[151329, 151336, 151338]
)
print("Warming up complete. Starting stress test...")
for i in range(n):
random_token_ids = torch.randint(3, vocab_size - 200, (token_len - 5,), dtype=torch.long)
input_ids = torch.tensor(start_tokens + random_token_ids.tolist() + end_tokens, dtype=torch.long).unsqueeze(
0).to(device)
attention_mask = torch.ones_like(input_ids, dtype=torch.bfloat16).to(device)
position_ids = torch.arange(len(input_ids[0]), dtype=torch.bfloat16).unsqueeze(0).to(device)
test_inputs = {
'input_ids': input_ids,
'attention_mask': attention_mask,
'position_ids': position_ids
}
streamer = TextIteratorStreamer(
tokenizer=tokenizer,
timeout=36000,
skip_prompt=True,
skip_special_tokens=True
)
generate_kwargs = {
"input_ids": test_inputs['input_ids'],
"attention_mask": test_inputs['attention_mask'],
"max_new_tokens": 512,
"do_sample": True,
"repetition_penalty": 1.0,
"eos_token_id": [151329, 151336, 151338],
"streamer": streamer
}
start_time = time.time()
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
first_token_time = None
all_token_times = []
for _ in streamer:
current_time = time.time()
if first_token_time is None:
first_token_time = current_time
times.append(first_token_time - start_time)
all_token_times.append(current_time)
t.join()
end_time = time.time()
avg_decode_time_per_token = len(all_token_times) / (end_time - first_token_time) if all_token_times else 0
decode_times.append(avg_decode_time_per_token)
print(
f"Iteration {i + 1}/{n} - Prefilling Time: {times[-1]:.4f} seconds - Average Decode Time: {avg_decode_time_per_token:.4f} tokens/second")
torch.cuda.empty_cache()
avg_first_token_time = sum(times) / n
avg_decode_time = sum(decode_times) / n
print(f"\nAverage First Token Time over {n} iterations: {avg_first_token_time:.4f} seconds")
print(f"Average Decode Time per Token over {n} iterations: {avg_decode_time:.4f} tokens/second")
return times, avg_first_token_time, decode_times, avg_decode_time
if __name__ == "__main__":
token_len = 1000
n = 3
num_gpu = 1
times, avg_first_token_time, decode_times, avg_decode_time = stress_test(token_len, n, num_gpu)
print(f'times: {times}, avg_first_token_time: {avg_first_token_time}, decode_times: {decode_times}, avg_decode_time: {avg_decode_time}')4.2.调用结果
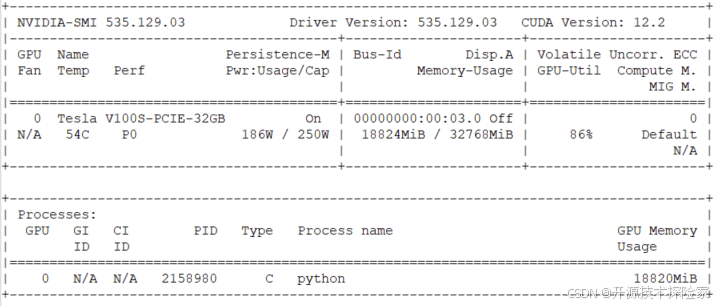

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 开源模型应用落地-glm模型小试-glm-4-9b-chat-压力测试(六)

发表评论 取消回复