sqoop脚本如下:
sqoop import -D mapred.job.queue.name=highway \
-D mapreduce.map.memory.mb=4096 \
-D mapreduce.map.java.opts=-Xmx3072m \
--connect "jdbc:oracle:thin:@//1.2.3.4.5:61521/LZY2" \
--username root \
--password '123456' \
--query "SELECT
ZBDM
,ZBMC
,TO_CHAR(TJSJ, 'YYYY') AS tjsj_year
,TO_CHAR(TJSJ, 'MM') AS tjsj_month
,TO_CHAR(TJSJ, 'DD') AS tjsj_day
,TO_CHAR(TJSJ, 'YYYY-MM-DD HH24:MI:SS') AS TJSJ
......
,TO_CHAR(INPUTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INPUTTIME
,UUID
,TO_CHAR(INSERTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INSERTTIME
FROM LZJHGX.T_JSZX_TF_KJ2_LL
WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD') AND \$CONDITIONS" \
--split-by ROWNUM \
--boundary-query "select 1 as MIN , sum(1) as MAX from LZJHGX.T_JSZX_TF_KJ2_LL" \
--hcatalog-database dw \
--hcatalog-table ods_pre_T_JSZX_TF_KJ2_LL \
--hcatalog-storage-stanza 'stored as orc' \
--num-mappers 8--query 参数的查询语句在Oracle中查询得到共计24563660数据,而加载到hive表dw.ods_pre_T_JSZX_TF_KJ2_LL中只有3070458数据。
24563660/8=3070457.5
这种巧合,刚好是一个mapper的向上取整量。这肯定有问题的,查看对应application的containers发现其实执行过程中是有做了split的:
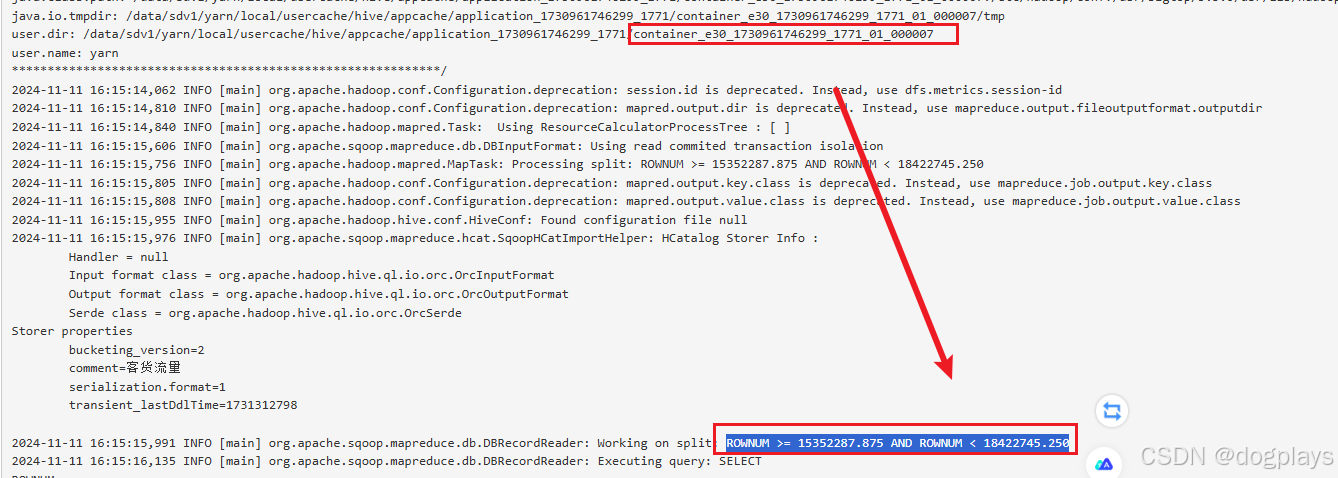
例如mapper7,范围为:
ROWNUM >= 15352287.875 AND ROWNUM < 18422745.250
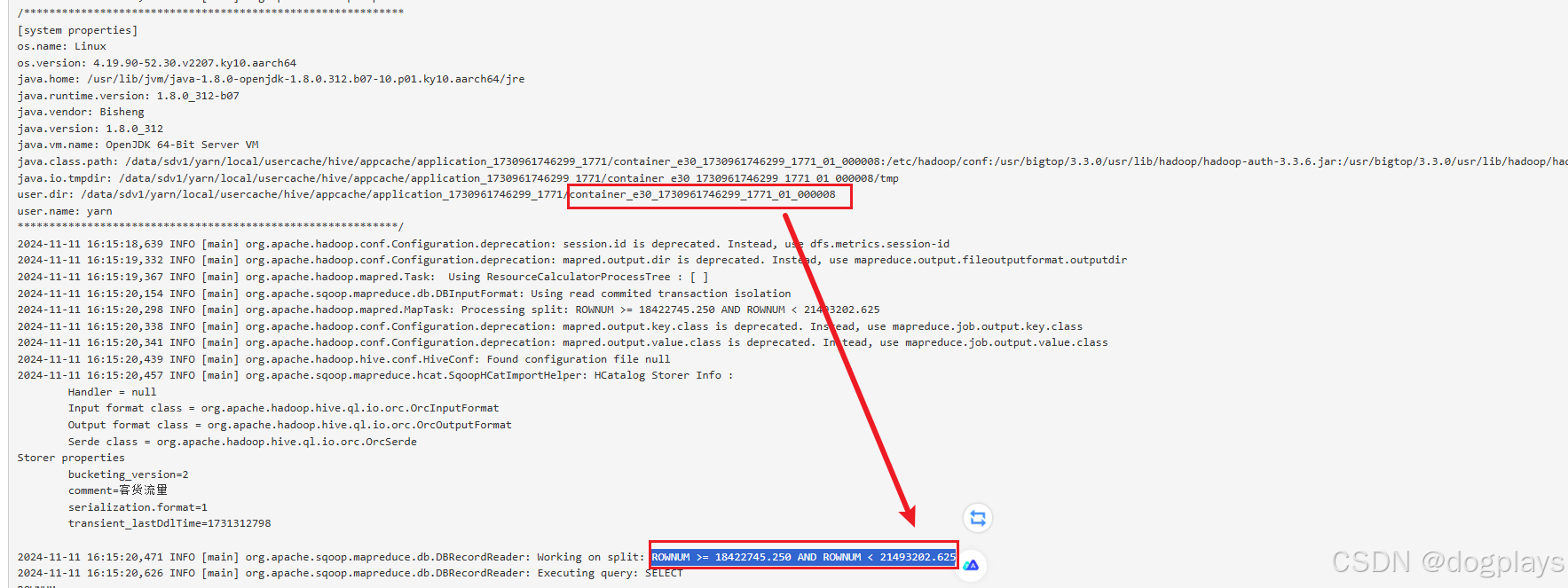
这是mapper8,范围为:
ROWNUM >= 18422745.250 AND ROWNUM < 21493202.625
但问题出现在Executing query,我把container7的语句放在Oracle中去执行,是没有返回任何结果集的:
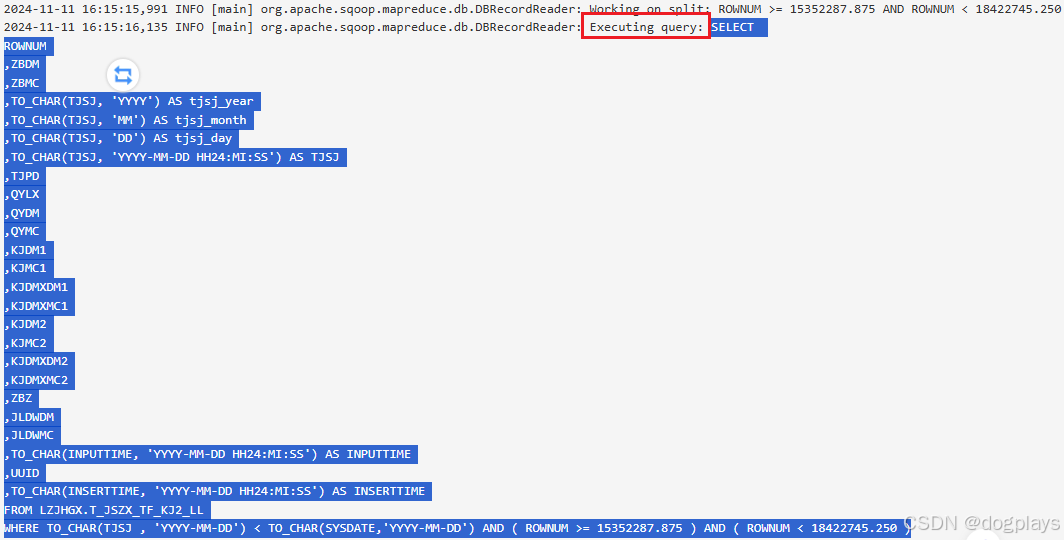
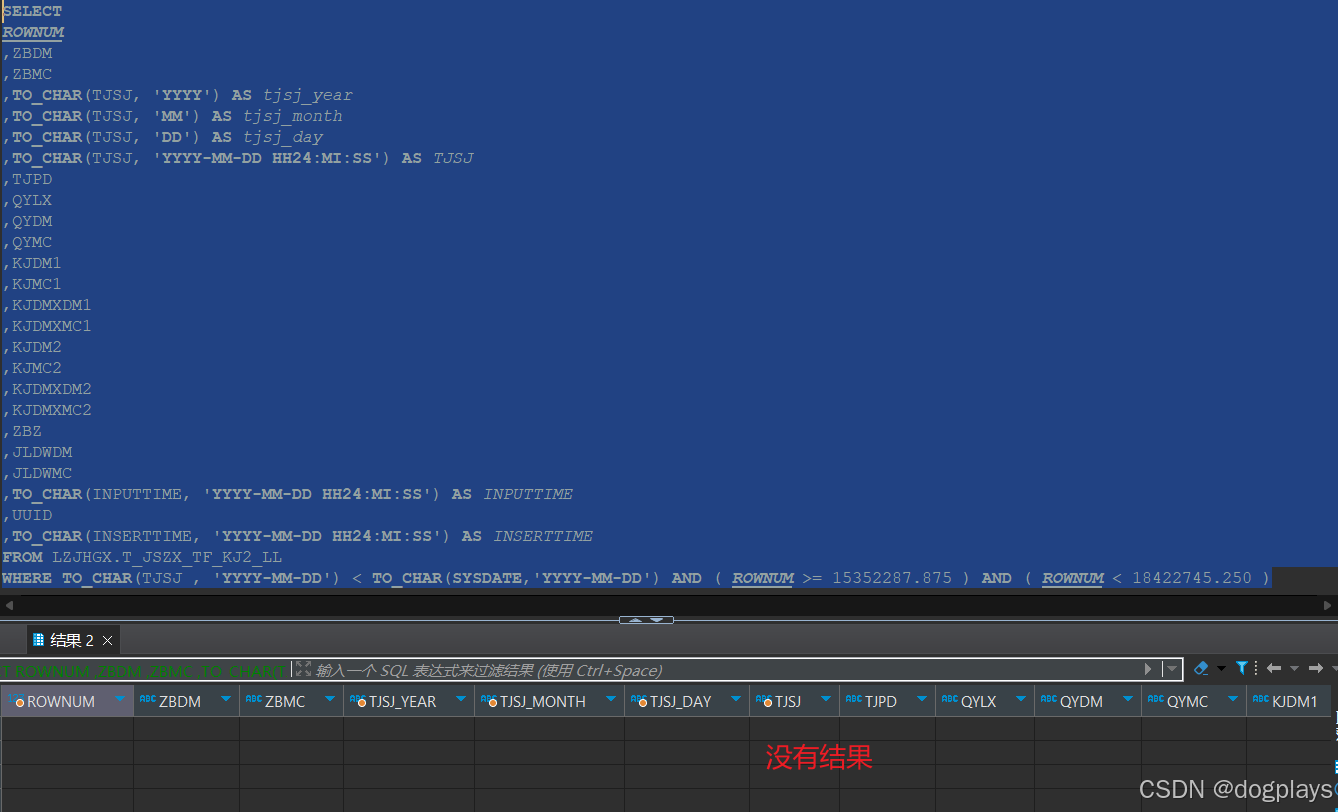
但是container1中的Executing query查询却有结果集返回
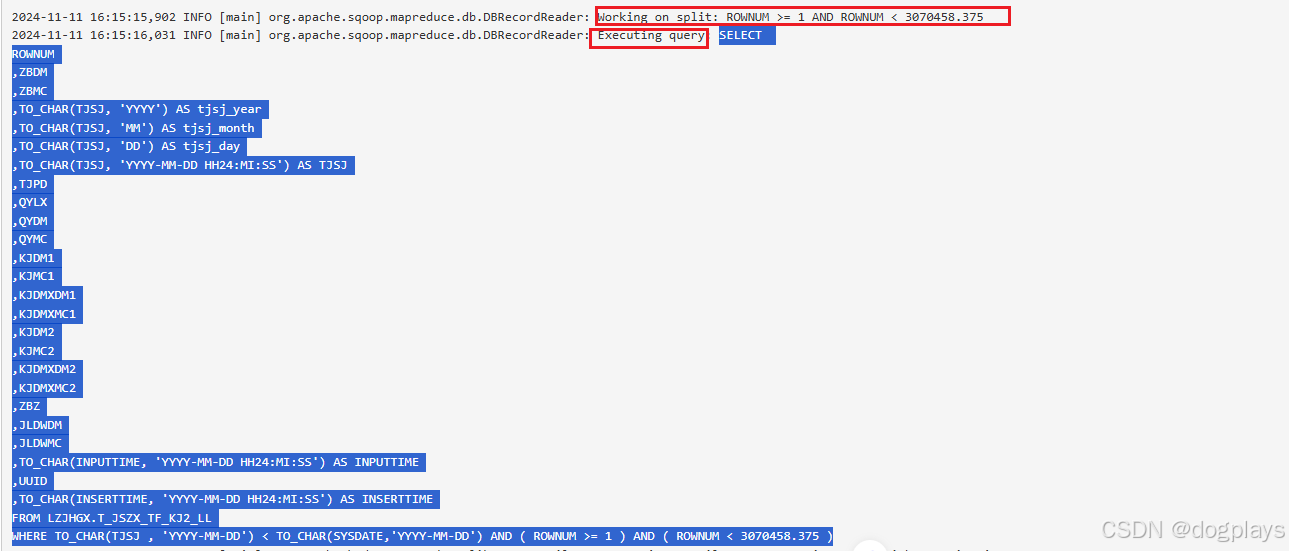
这几个container中执行的Executing query查询,唯一不同的是条件ROWNUM的范围
AND ( ROWNUM >= 1 ) AND ( ROWNUM < 3070458.375 )
那么ROWNUM到底是什么?为什么AND ( ROWNUM >= 1 ) AND ( ROWNUM < 3070458.375 )有结果集返回,而ROWNUM >= 18422745.250 AND ROWNUM < 21493202.625却没有?
要明白其中的原因,必须要明白Oracle中的ROWNUM到底是什么?
先看一组Oracle查询:
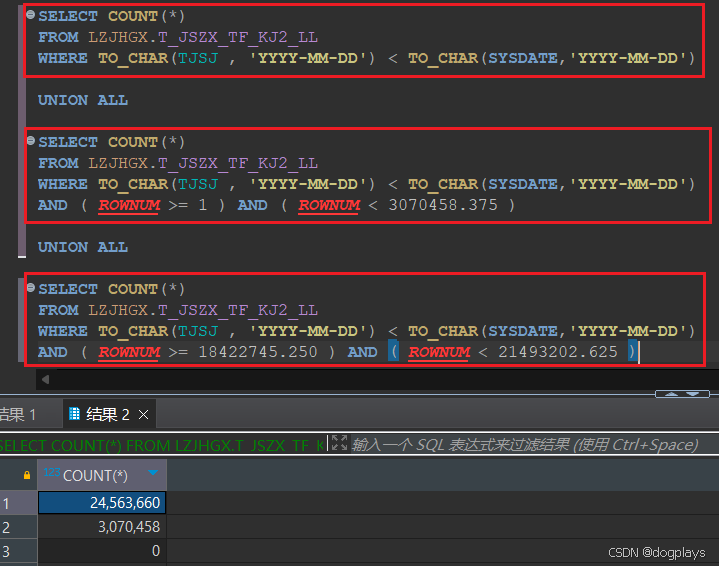
Oracle 的 ROWNUM 是一个特殊的伪列,它按查询返回的顺序动态分配给结果集中的每一行。因此,ROWNUM 仅在行被提取时分配,而不是基于数据表中的实际行号。
-
第一部分查询:
SELECT COUNT(*) FROM LZJHGX.T_JSZX_TF_KJ2_LL WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD')- 这一部分返回符合
TJSJ条件的所有记录数,结果为24,563,660。这表明符合条件的记录总数就是这么多。
- 这一部分返回符合
-
第二部分查询:
SELECT COUNT(*) FROM LZJHGX.T_JSZX_TF_KJ2_LL WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD') AND ( ROWNUM >= 1 ) AND ( ROWNUM < 3070458.375 )- 这里你试图获取
ROWNUM在1和3,070,458.375范围内的行数。然而,ROWNUM在分配时是严格递增的,它只能用于获取从头开始的连续行。也就是说,只要有ROWNUM< 3,070,458.375 的限制,查询将返回符合条件的头3,070,458行。 - 因此,这个查询实际上在返回总符合条件的前
3,070,458行。
- 这里你试图获取
-
第三部分查询:
SELECT COUNT(*) FROM LZJHGX.T_JSZX_TF_KJ2_LL WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD') AND ( ROWNUM >= 18422745.250 ) AND ( ROWNUM < 21493202.625 )- 这里的问题是,由于
ROWNUM的工作方式,ROWNUM永远不会满足>= 18422745.250和< 21493202.625这样的区间查询。ROWNUM是从1开始的递增序列,如果你直接使用ROWNUM >= 某值的条件,那么 Oracle 会从头重新生成行号,这种逻辑不支持从特定行号直接开始。因此,这个查询会返回 0 结果。
- 这里的问题是,由于
主要原因总结:
- ROWNUM 是一个动态生成的递增伪列,只能用于从查询的第一行依次生成,不能用来表示实际的物理行号。
- 当你用条件
ROWNUM >= 某值时,Oracle 会从第一个满足WHERE条件的行开始计算,无法跳过之前的行。
解决办法:所以在数据量很大时需要多个mapper并发执行时ROWNUM万万不能作为splitby字段,否则会出现数据量缺少,只有一个mapper数据量的问题。
方法1(不推荐):在--query利用开窗函数排序,数据量大时,非常消耗资源
方法2(推荐):将ROWNUM嵌套进子查询中,作为查询结果集中的一个字段,修改后的sqoop脚本如下:
sqoop import -D mapred.job.queue.name=highway \
-D mapreduce.map.memory.mb=4096 \
-D mapreduce.map.java.opts=-Xmx3072m \
-D sqoop.export.records.per.statement=1000 \
--fetch-size 10000 \
--connect "jdbc:oracle:thin:@//localhost:61521/LZY2" \
--username LZSHARE \
--password '123456' \
--query "SELECT * FROM(
SELECT
ROWNUM as splitby_column
,ZBDM
,ZBMC
,TO_CHAR(TJSJ, 'YYYY') AS tjsj_year
,TO_CHAR(TJSJ, 'MM') AS tjsj_month
,TO_CHAR(TJSJ, 'DD') AS tjsj_day
,TO_CHAR(TJSJ, 'YYYY-MM-DD HH24:MI:SS') AS TJSJ
,TJPD
......
,JLDWMC
,TO_CHAR(INPUTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INPUTTIME
,UUID
,TO_CHAR(INSERTTIME, 'YYYY-MM-DD HH24:MI:SS') AS INSERTTIME
FROM LZJHGX.T_JSZX_TF_KJ2_LL
WHERE TO_CHAR(TJSJ , 'YYYY-MM-DD') < TO_CHAR(SYSDATE,'YYYY-MM-DD')) a WHERE \$CONDITIONS" \
--split-by splitby_column \
--hcatalog-database dw \
--hcatalog-table ods_pre_T_JSZX_TF_KJ2_LL \
--hcatalog-storage-stanza 'stored as orc' \
--num-mappers 20本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » sqoop import将Oracle数据加载至hive,数据量变少,只能导入一个mapper的数据量

发表评论 取消回复