点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(正在更新…)
章节内容
上节我们完成了如下的内容:
- KMeans 基于轮廓系数来选择 n_clusters
Prometheus
架构设计
Prometheus 的核心架构设计简单明了,包括以下组件:
- Prometheus Server:负责采集、存储时间序列数据,并提供查询服务。它通过 HTTP 协议从指定的服务端点(targets)拉取数据。
- Exporter:负责将不同系统的监控指标转换为 Prometheus 可读取的格式,比如 node_exporter 可以监控主机的 CPU、内存等资源,blackbox_exporter 可以进行网站的可达性检查。
- Alertmanager:用来处理 Prometheus 产生的报警。当满足指定的报警条件时,Alertmanager 可以将报警信息发送到邮件、Slack、PagerDuty 等多种渠道。
- Pushgateway:适用于短生命周期的批处理任务,将数据主动推送给 Prometheus。
- 客户端库(Client Libraries):允许开发者在应用程序代码中直接定义并记录自定义的监控指标,如请求数、延迟等。
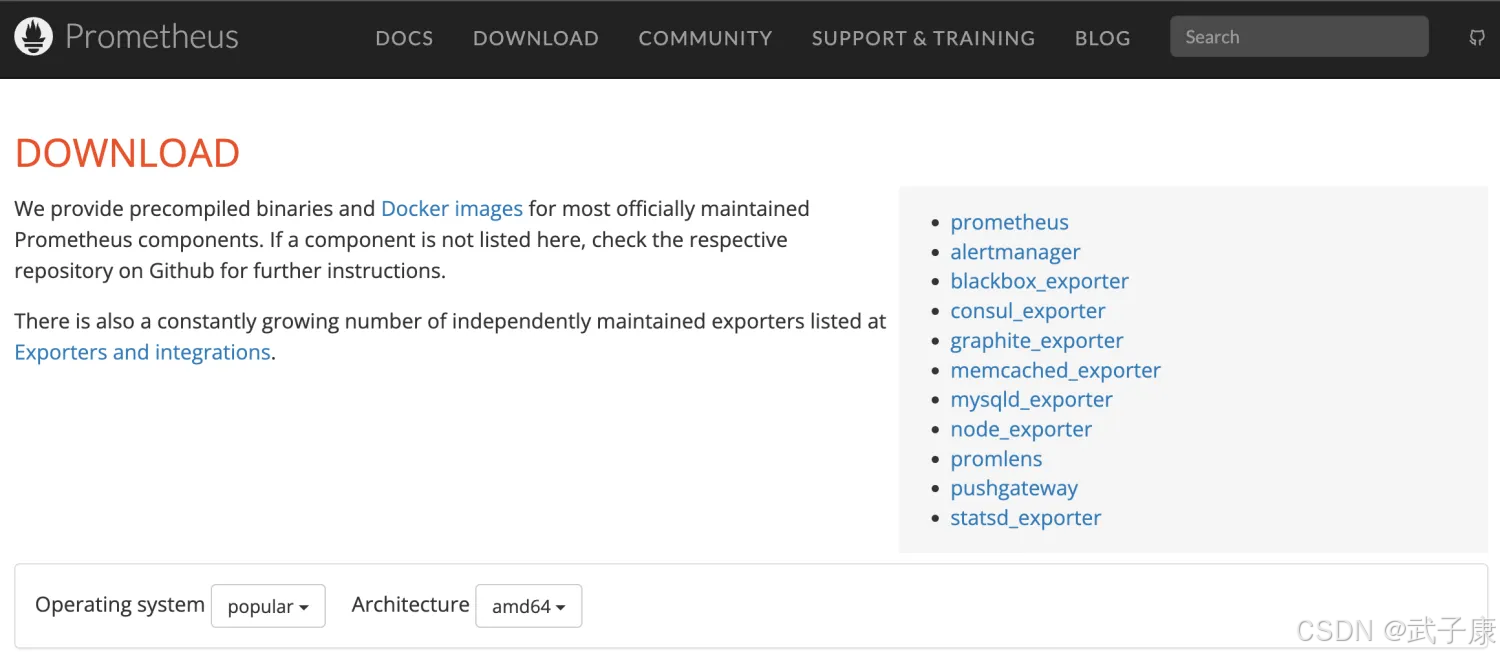
官方网站
https://prometheus.io/download/
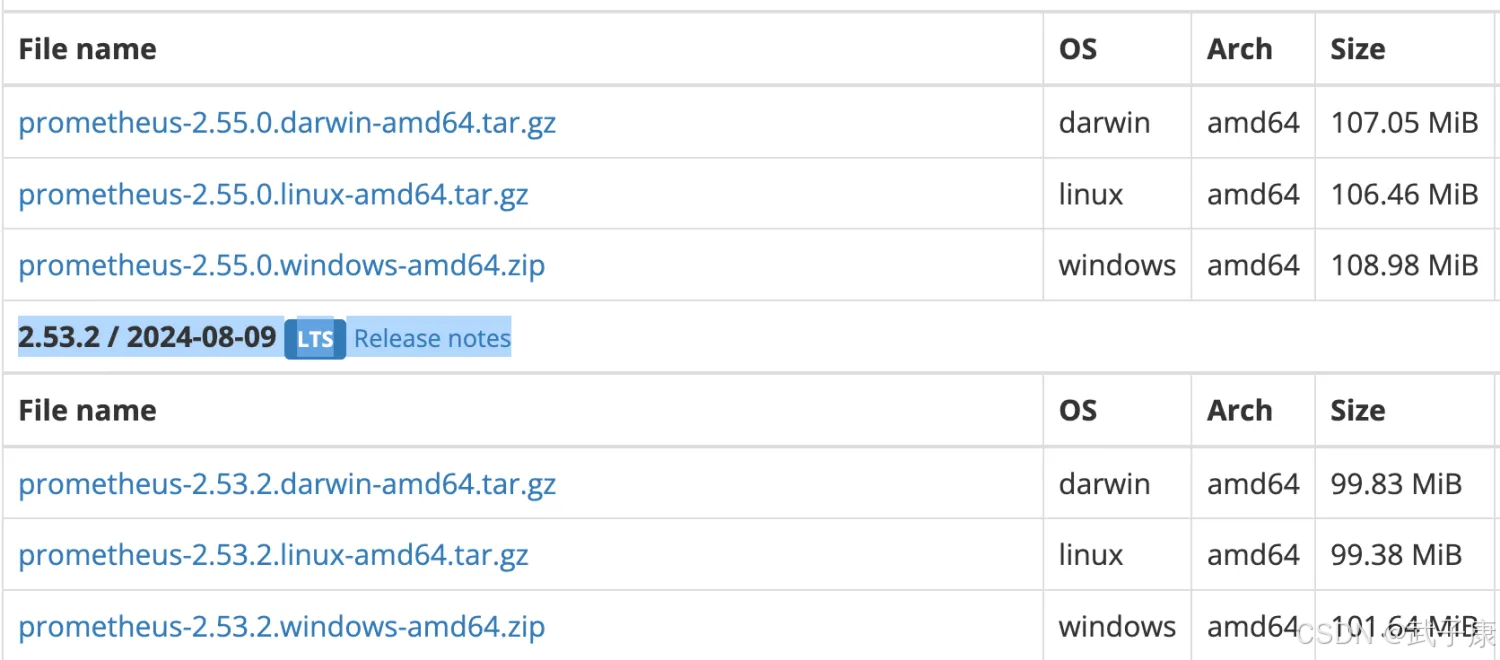
这里用 2.53.2
数据模型
Prometheus 的数据模型基于键值对存储时间序列数据。它的数据单位是 时间序列,每个时间序列由 唯一的 metric 名称 和一组 标签(labels) 组成。标签使得用户可以灵活地标记和筛选数据,比如 http_requests_total{method=“GET”, status=“200”} 表示获取到的 HTTP 请求总数。
数据采集方式
Prometheus 的数据采集采用 Pull 模型,即 Prometheus 定期从指定的目标端点(targets)拉取数据。这种模型对分布式系统尤其适用,因为可以灵活配置并自动发现服务(通过与 Kubernetes 集成),无需每个服务都主动上报数据。
查询语言(PromQL)
Prometheus 提供了一种强大的查询语言 PromQL,用于查询和分析存储的数据。PromQL 允许用户对数据进行复杂的运算和聚合,例如:
- rate(http_requests_total[5m]):计算过去 5 分钟的 HTTP 请求速率。
- avg_over_time(cpu_usage[1h]):计算过去 1 小时的 CPU 使用率平均值。 PromQL 支持过滤、聚合、运算符、时间窗口等操作,使得用户可以灵活地分析监控数据。
应用场景
- 在业务层作用埋点系统:支持多种语言(Go、Python、Ruby 等等),我们可以通过客户端对核心业务进行埋点,如下单流程、添加购物车等等
- 在应用层作用监控系统:一些主流应用可以通过官方或者第三方的导出器,来对这些应用做核心指标的收集,如 Redis、MySQL
- 在系统层用作系统监控除了常用软件,Prometheus 也有相关系统层和网络层 exporter,用于监控服务器或者网络
- 集成其他监控 Prometheus 还可以通过各种 exporter,集成其他的监控系统,收集监控数据,如 AWS CloudWatch、JMX、Pingdom 等等。
我们需要完成:
- 在监控服务器上安装 Prometheus
- 在被监控的环境上安装 export
- 安装 Grafana
下载配置
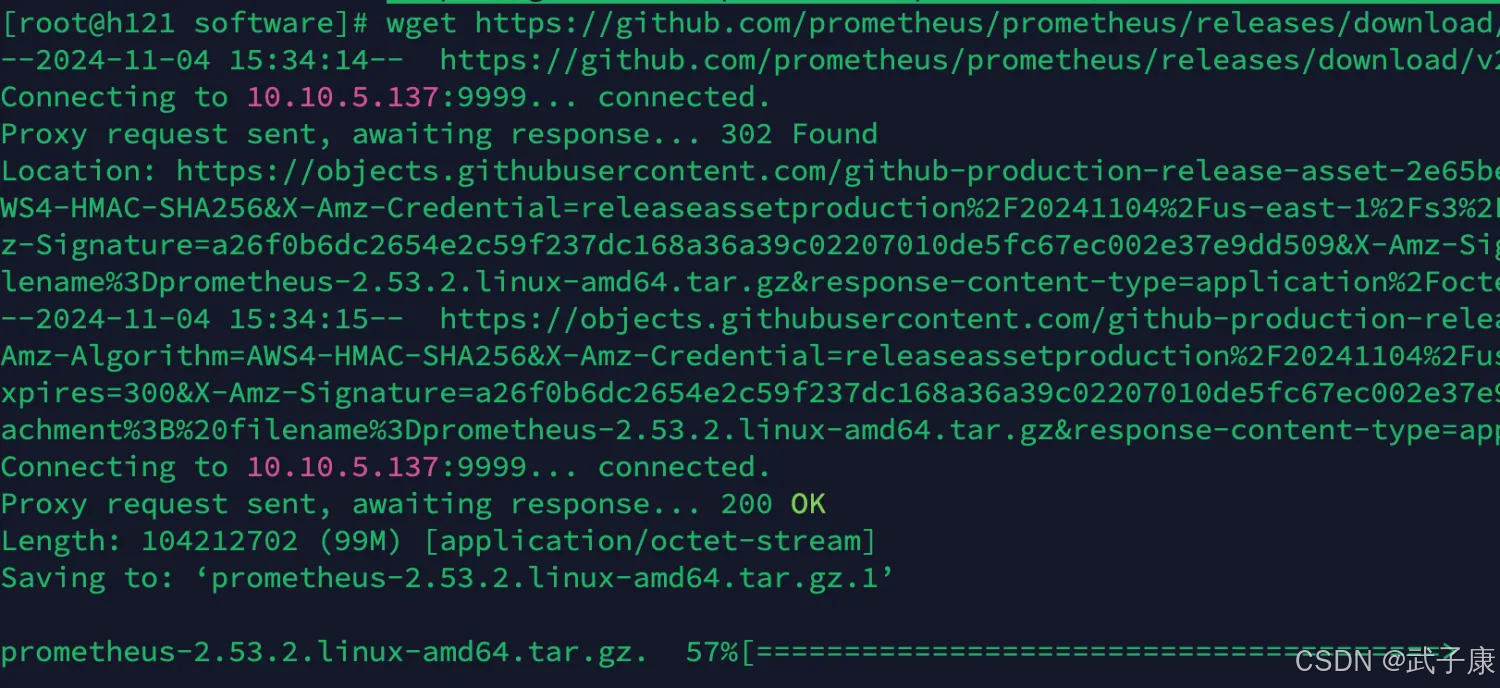
cd /opt/software
wget https://github.com/prometheus/prometheus/releases/download/v2.53.2/prometheus-2.53.2.linux-amd64.tar.gz
执行结果如下所示:
解压配置
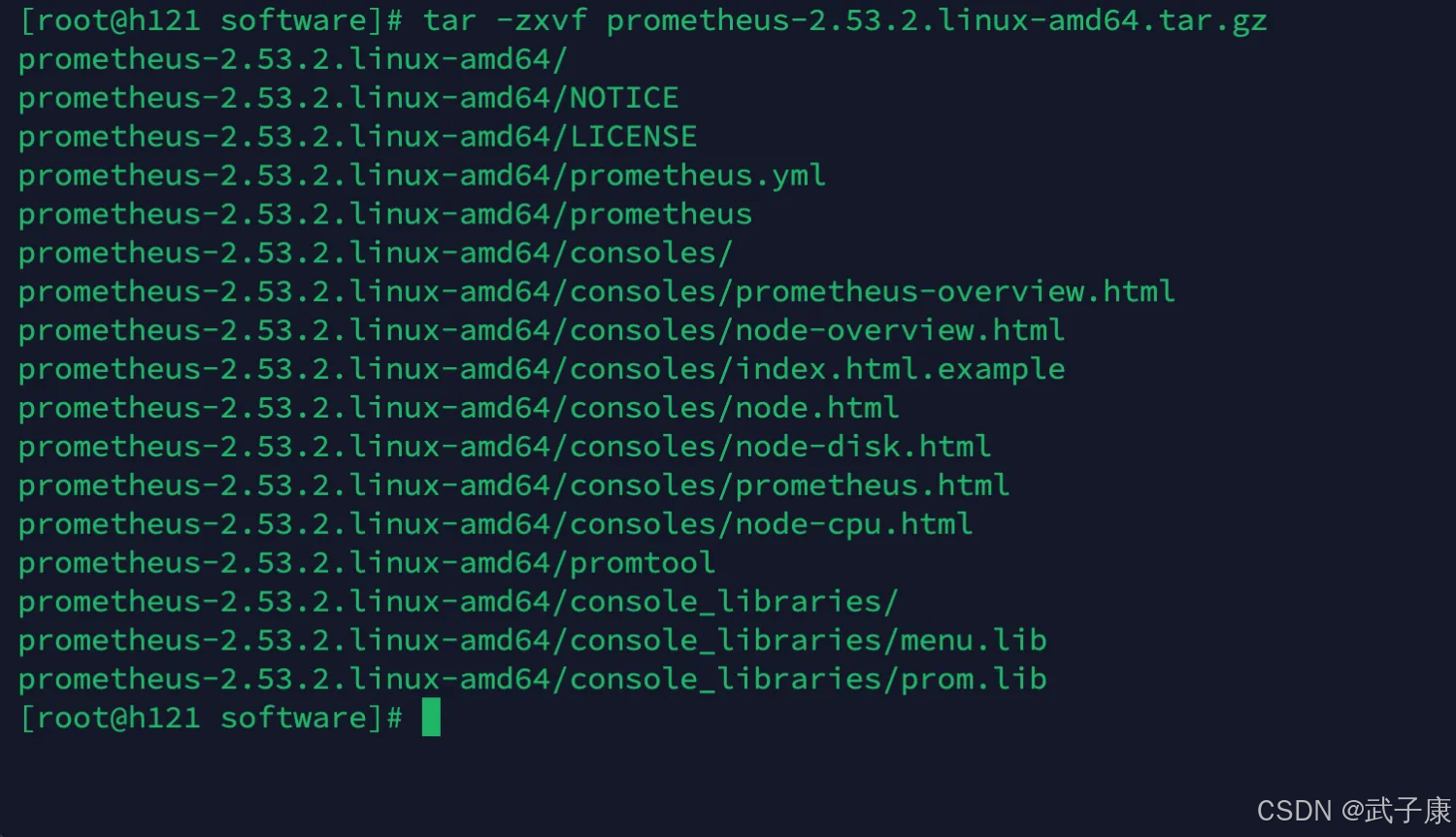
tar -zxvf prometheus-2.53.2.linux-amd64.tar.gz
mv prometheus-2.53.2.linux-amd64 ../servers/
执行结果如下所示:
修改配置
解压配置,修改配置文件,在项目对应目录下:
cd /opt/servers/prometheus-2.53.2.linux-amd64
vim prometheus.yml
执行的结果如下所示:
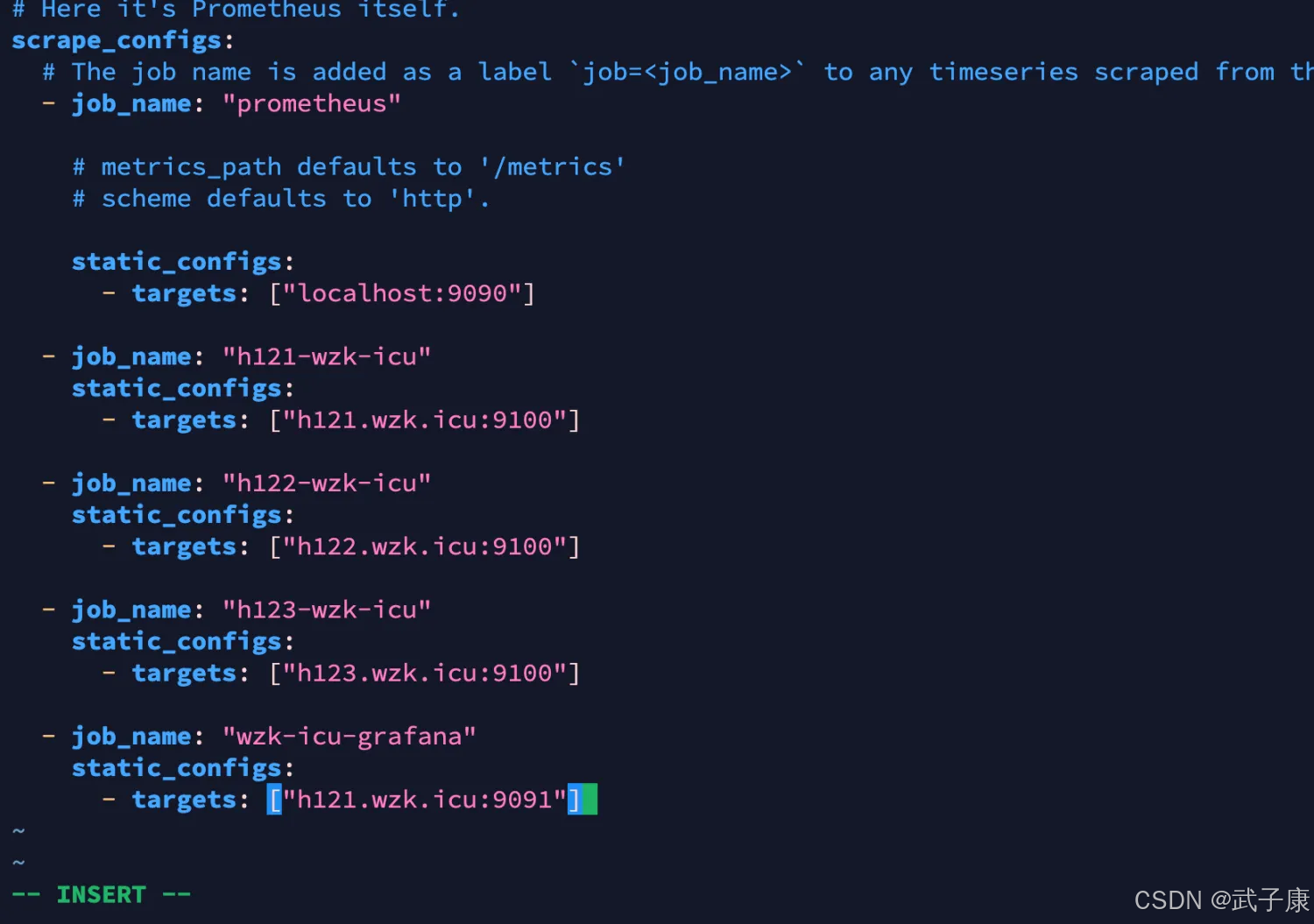
我们需要进行一些配置:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "h121-wzk-icu"
static_configs:
- targets: ["h121.wzk.icu:9100"]
- job_name: "h122-wzk-icu"
static_configs:
- targets: ["h122.wzk.icu:9100"]
- job_name: "h123-wzk-icu"
static_configs:
- targets: ["h123.wzk.icu:9100"]
- job_name: "wzk-icu-grafana"
static_configs:
- targets: ["h121.wzk.icu:9091"]
对应的内容如下图所示:
启动服务
配置完成后,只需要运行起来这个软件:
cd /opt/servers/prometheus-2.53.2.linux-amd64
./prometheus
执行结果如下图所示:
我们通过 URL可以看到自带的监控界面:
http://h121.wzk.icu:9090/
访问结果如下所示:
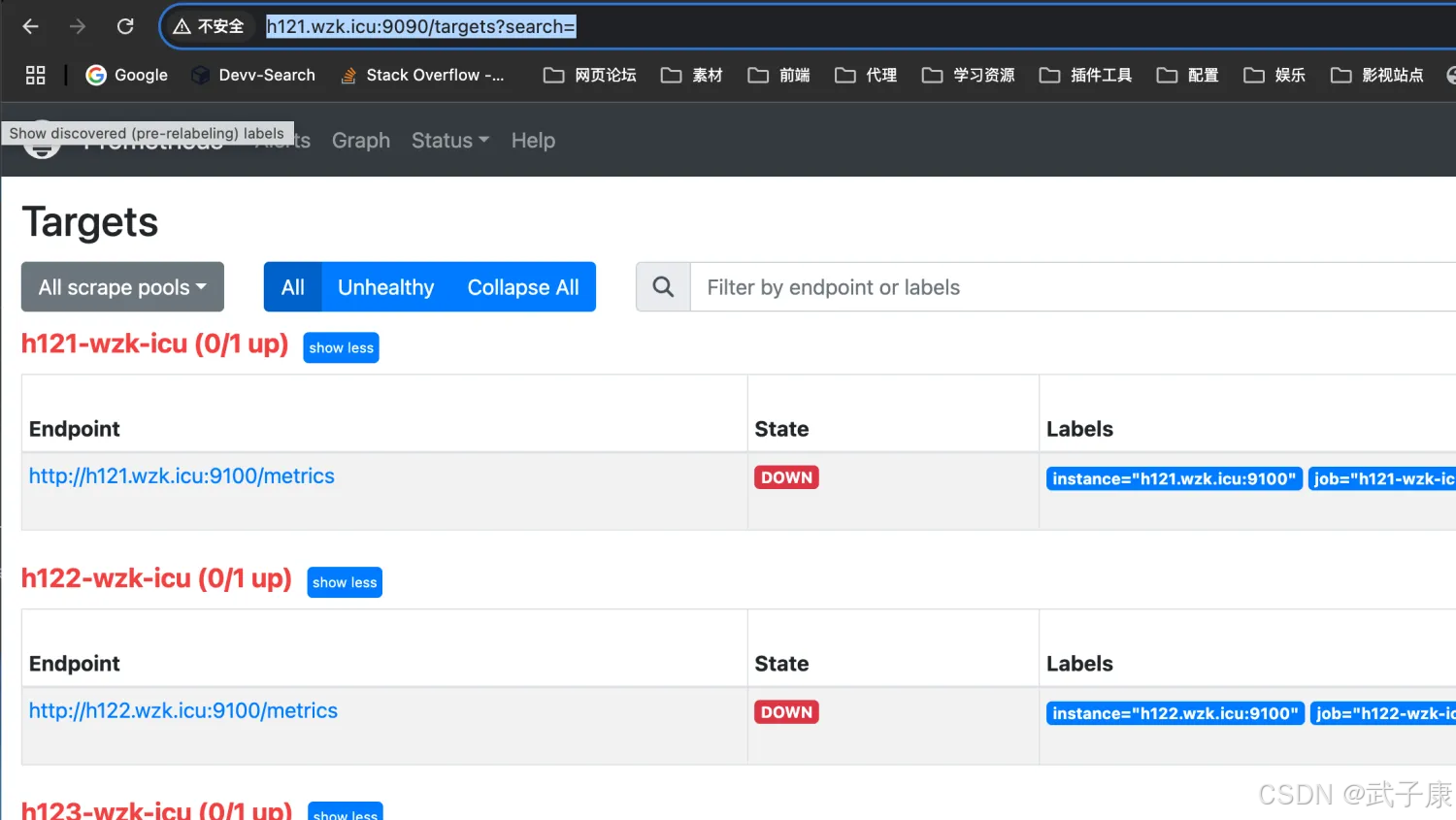
我们选择 Targets 选项:
http://h121.wzk.icu:9090/targets?search=
可以看到如下的内容:
Alerting 和通知
Prometheus 可以基于查询结果设定报警规则,比如当 CPU 使用率超过 80% 持续一定时间,就可以触发报警。Prometheus 的 Alertmanager 负责管理和路由报警,支持去重、分组、静默处理等功能,帮助团队更高效地处理报警事件。Alertmanager 可以与多个通知平台集成,如 Slack、邮件、PagerDuty、OpsGenie 等。
存储机制
Prometheus 的数据默认会保存在本地磁盘中,使用 TSDB(时间序列数据库) 存储引擎,以时间块的形式进行存储和压缩。为了满足长时间的数据保留和查询需求,Prometheus 也支持通过远程存储(如 Cortex、Thanos)扩展数据的持久化和高可用性。
服务发现
Prometheus 提供了多种服务发现机制,能够自动发现新的监控目标。它支持静态配置、DNS 服务发现、文件服务发现以及多种平台的自动发现,比如 Kubernetes、Consul、Amazon EC2、Azure 等,使得 Prometheus 能够动态地发现容器、Pod、VM 等新资源,减少运维人员的手动操作。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据-217 Prometheus 安装配置 启动服务 监控服务

发表评论 取消回复