一、前言
可见光图像与红外图像融合(VIF)通过结合热红外图像与可见光图像的丰富纹理,提供了一个全面可靠的场景描述。然而,传统的VIF系统可能在极端光照和高动态运动场景中捕获过曝或欠曝的图像,进而导致融合结果下降。如下图的左侧图像所示。
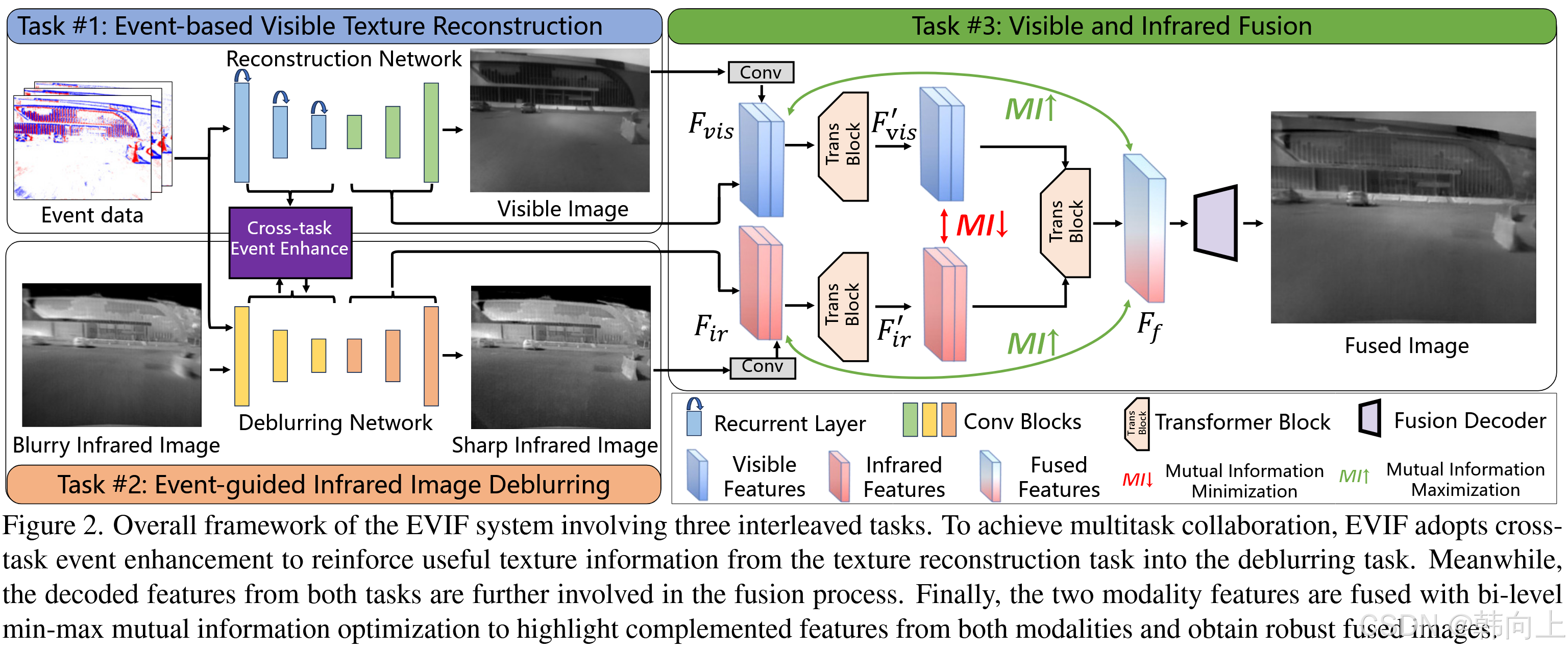
为解决上述提到的问题,在本文中提出事件驱动的可见光和红外融合系统,在该系统中采用了可见光事件相机代替传统的基于帧的相机。可见光事件相机具有低延迟和高动态范围的特点,在极端光照和高速运动的场景下,事件相机都具有较高的鲁棒性。为了提高多模态数据融合质量,作者开发了一个多任务协作框架,该框架会同时执行基于事件的可见光纹理重建、事件引导的红外图像去模糊和红外图像-可见光图像融合。利用任务间的协同作用,增强融合效果,并设计最小-最大互信息优化来实现更高的融合质量。

二、方法
2.1 问题定义
假设有一个连续的事件流 ε \varepsilon ε,它的时间范围在区间 [ t 0 , t 1 ] [t_0,t_1] [t0,t1]内,在这段事件流中存在一组运动模糊帧段 I i r = { I i ∣ i = 1 , 2 , . . . , M } I_{ir}=\{I_i|i=1,2,...,M\} Iir={Ii∣i=1,2,...,M}。每个 I i I_i Ii都有一个曝光时间窗口 [ t i , t i + δ ] ∈ [ t 0 , t 1 ] [t_i,t_i+\delta]\in[t_0,t_1] [ti,ti+δ]∈[t0,t1],其中 δ \delta δ是红外相机的曝光时间长度。 E V I F EVIF EVIF的目标是为每个红外帧 I i r i I_{ir}^i Iiri产生清晰的红外-可见光融合图像 I f i I^i_f Ifi。这项任务涉及事件流 ε \varepsilon ε中提取同步的可见光纹理和运动线索,并将其与 I i r I_{ir} Iir集成,以创建对场景的清晰、全面的描述。
2.2 框架描述
图2展示本文提出的EVIF系统的整体框架。该框架联合完成三个任务(纹理重建、红外图像去模糊以及红外-可见光图像融合),每个任务都是通过特定的网络来实现。基于事件的纹理重建和图像去模糊在其他工作中已经进行了很好的研究。本篇工作采用E2VID 和EFNet作为任务相关的网络,重点放在如何协调他们之间的协同作用。首先,作者设计了一种跨任务事件增强的方法,旨在有效利用重建任务中提取到的有用的纹理特征。然后使用这些特征来辅助红外图像去模糊。最后从前两个任务中编码的特征被发送到融合网络,该网络采用双层最小-组大互信息优化机制来实现稳健的融合。
对于每个输入的模糊的红外图像
I
i
r
i
I_{ir}^i
Iiri,在曝光时间窗口内捕获的事件片段
ϵ
t
i
t
I
+
δ
\epsilon_{t_i}^{t_I+\delta}
ϵtitI+δ被视为输入事件输入。在去模糊网络中,直接将
ϵ
t
i
t
I
+
δ
\epsilon_{t_i}^{t_I+\delta}
ϵtitI+δ作为输入,而纹理重建网络则将
ϵ
t
i
t
I
+
δ
\epsilon_{t_i}^{t_I+\delta}
ϵtitI+δ按事件分成
K
K
K个片段处理,从而得到一组K个事件特征和重建的可见光图像。在融合过程中,仅使用中间第
K
+
1
2
\frac{K+1}{2}
2K+1个可见光图像。
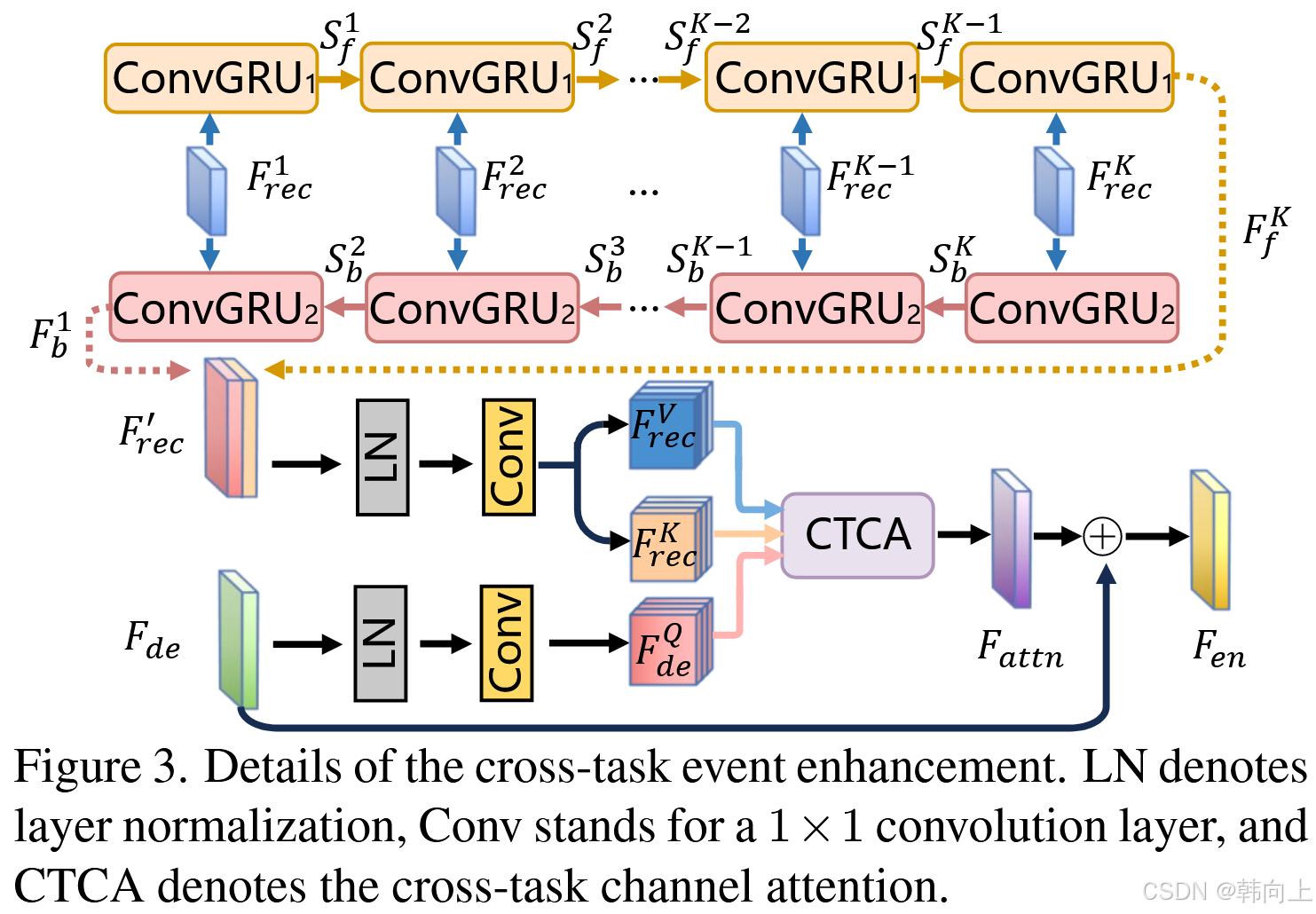
2.3 跨任务事件增强
由于事件的去模糊网络的主要目的是从事件中揭示潜在的运动线索,因此事件中固有的纹理特征可能无法在去模糊网络中得到充分利用。考虑到这一点,作者提出了一个跨任务的事件增强方法。它旨在增强基于事件的红外图像去模糊网络中的事件纹理特征,主要方法是利用可见光纹理重建模型中学习到纹理特征。
跨任务事件增强模块的结构如图3所示,给定来自事件重建网络的
K
K
K个事件特征
{
F
r
e
c
i
∣
i
=
1
,
2
,
.
.
.
,
K
}
\{F_{rec}^i|i=1,2,...,K\}
{Freci∣i=1,2,...,K},。为总结每个
F
r
e
c
i
F_{rec}^i
Freci内的空间纹理,并同时考虑它们之间的相关性,使用了两个ConvGRU以双向递归的方式从
F
r
e
c
i
F_{rec}^i
Freci中提取空间-时间特征:
S
f
i
+
1
,
F
f
i
+
1
=
C
o
n
v
G
R
U
1
(
S
f
i
,
F
r
e
c
i
)
S
b
i
−
1
,
F
b
i
−
1
=
C
o
n
v
G
R
U
2
(
S
b
i
,
F
r
e
c
i
)
S_f^{i+1},F_f^{i+1}=ConvGRU_1(S_f^i,F_{rec}^i) \\ S_b^{i-1},F_b^{i-1}=ConvGRU_2(S_b^i,F_{rec}^i)
Sfi+1,Ffi+1=ConvGRU1(Sfi,Freci)Sbi−1,Fbi−1=ConvGRU2(Sbi,Freci)
其中
S
f
i
S_f^i
Sfi和
S
b
i
S_b^i
Sbi是前向和后向隐藏状态,
F
f
i
F_f^i
Ffi和
F
b
i
F_b^i
Fbi是GRUs的输出特征。然后沿着通道维度堆叠端点特征
F
f
K
F_f^K
FfK和
F
b
1
F_b^1
Fb1,形成一个统一的特征
F
r
e
c
′
F_{rec}'
Frec′,它包含了丰富的纹理信息。
在得到
F
r
e
c
′
F_{rec}'
Frec′之后,下一步是将
F
r
e
c
′
F_{rec}'
Frec′中的纹理信息合并到去模糊网络的事件特征
F
d
e
F_{de}
Fde中。考虑到直接将
F
r
e
c
′
F_{rec}'
Frec′与
F
d
e
F_{de}
Fde直接相加或相乘或concat可能会破坏原始
F
d
e
F_{de}
Fde中的运动线索,因为这两个特征对应着不同的任务,它们关注的重点也不同。为解决这个问题,作者设计了一个跨任务通道注意力(CTCA)来合并
F
r
e
c
′
F_{rec}'
Frec′和
F
d
e
F_{de}
Fde。与从单一输入生成Q、K、V不同,CTCA从
F
d
e
F_{de}
Fde计算查询特征
F
d
e
Q
F_{de}^Q
FdeQ, 而键特征
F
r
e
c
K
F^K_{rec}
FrecK和值特征
F
r
e
c
V
F^V_{rec}
FrecV都是从
F
r
e
c
′
F_{rec}'
Frec′中获得。所有三个特征都被重塑成大小
(
h
w
)
×
c
(hw)\times c
(hw)×c。然后沿通道维度执行注意力计算:
F
a
t
t
n
=
F
r
e
c
V
S
o
f
t
m
a
x
(
(
F
d
e
Q
)
T
F
r
e
c
K
h
w
)
F_{attn}=F_{rec}^V \ Softmax(\frac{(F^Q_{de})^TF_{rec}^K}{\sqrt{hw}})
Fattn=FrecV Softmax(hw(FdeQ)TFrecK)
最终,
F
a
t
t
n
F_{attn}
Fattn和
F
d
e
F_{de}
Fde被添加以获得增强的事件特征
F
e
n
F_{en}
Fen, 用于去模糊网络中的进一步处理。
创新点1:使用了一个双向ConvGRU操作,GRU的特点是具有记忆,也即在
F
f
K
F_f^K
FfK中保留最新输入信息
F
r
e
c
K
F_{rec}^K
FrecK的同时也融入了前K-1个特征。可以同时考虑过去和未来的时间信息,增强空间特征提取能力,优化特征融合。
创新点2:设计了一个CTCA的跨任务通道注意力。它通过生成查询、键和值特征进行注意力计算,避免了不同任务特征分布差异导致的原始信息丢失问题,进而更有效的融合特征。
2.4 通过互信息优化的融合
可见光和红外图像融合的目标是保留红外模态中捕获的显著目标的同时,获取包含丰富可见光纹理场景细节的图像。因此有效利用两种模态中包含的互补信息是确定融合过程性能的关键因素。必须使用合适的策略来平衡特征的独特性和完整性。
- 一方面。理想的特征融合应该是在每种模态中突出不同的信息,同时减少跨模态共有的冗余信息。
- 另一方面,融合结果中必须保留原始的模态信息,以避免潜在的信息丢失。
在本文中,作者采用最小最大互信息的方式来优化两种模态特征之间的互信息。
如图2所示,在获得重建的可见光图像和去模糊的清晰的红外图像后,分别将这两个图像输入卷积层,并将卷积层输出的特征与之前任务网络的解码器输出连接起来。连接后的结果包括浅层的特征表示和深层表示,分别产生可见光和红外的可靠特征
F
v
i
s
F_{vis}
Fvis和
F
i
r
F_{ir}
Fir。然后对i这两个模态特征施加互信息优化,以鼓励它们进行互补学习。
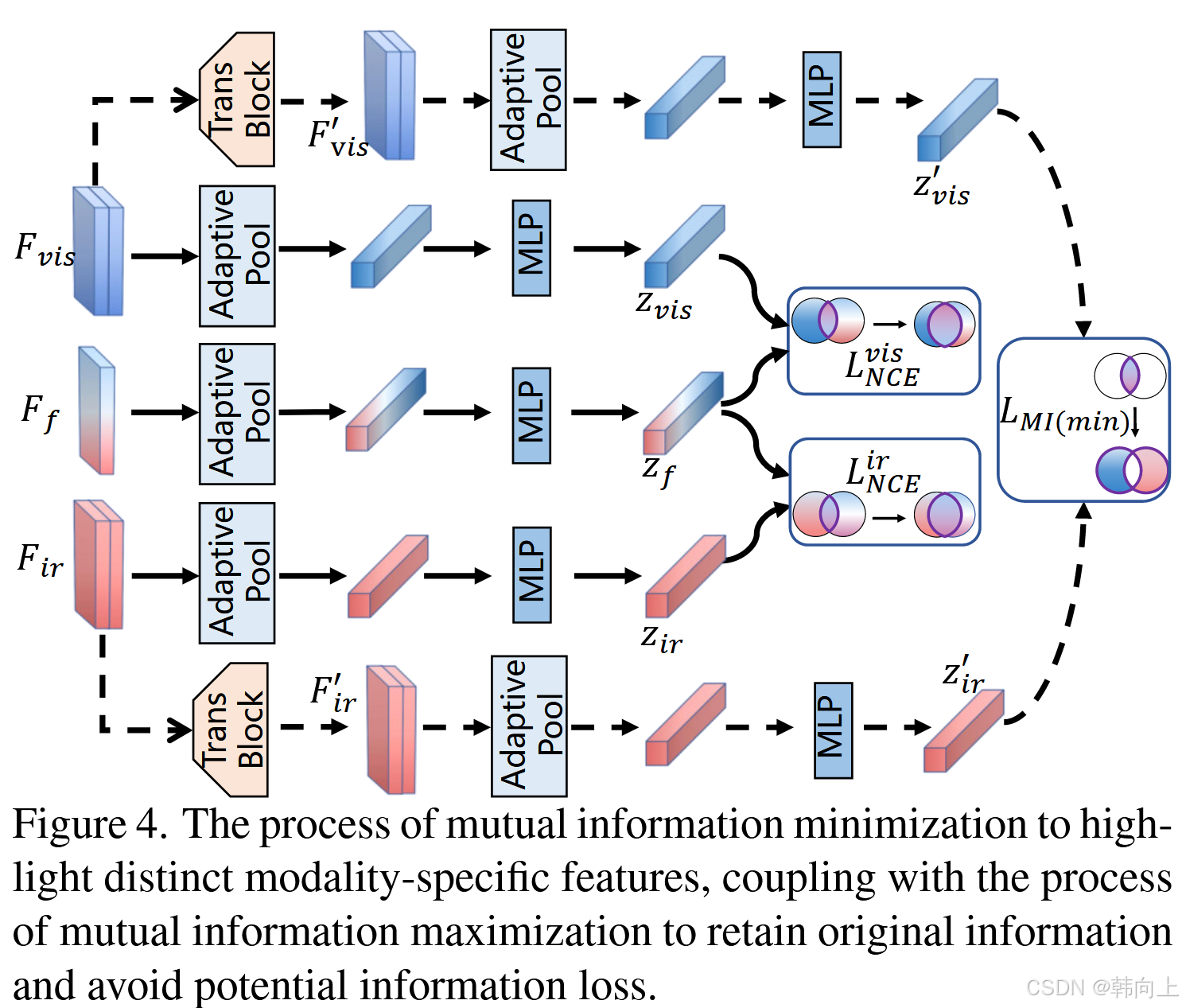
具体来说,将得到的特征
F
v
i
s
F_{vis}
Fvis和
F
i
r
F_{ir}
Fir传进Trans Block,构建具有长距离空间依赖的特征
F
v
i
s
′
F_{vis}'
Fvis′和
F
i
r
′
F_{ir}'
Fir′。然后,对这两个模态的特征施加互信息最小化,以减少冗余并突出模态的不同信息。如图4所示,
F
v
i
s
′
F_{vis}'
Fvis′和
F
i
r
′
F_{ir}'
Fir′通过Apaptive pool将其拉成以为向量,通过MLP层获得
z
v
i
s
′
z_{vis}'
zvis′和
z
i
r
′
z_{ir}'
zir′。它们之间的互信息表示为:
M
I
(
z
v
i
s
′
,
z
i
r
′
)
=
H
(
z
v
i
s
′
)
+
H
(
z
i
r
′
)
−
H
(
z
v
i
s
′
,
z
i
r
′
)
,
MI(z_{vis}',z_{ir}')=H(z'_{vis})+H(z_{ir}')-H(z_{vis}',z_{ir}'),
MI(zvis′,zir′)=H(zvis′)+H(zir′)−H(zvis′,zir′),
其中
H
(
z
v
i
s
)
H(z_{vis})
H(zvis)和
H
(
z
i
r
′
)
H(z_{ir}')
H(zir′)表示
z
v
′
i
s
z'_vis
zv′is和
z
i
r
′
z_{ir}'
zir′的边缘熵 ,
H
^
(
z
i
r
′
,
z
v
i
s
′
)
\hat{H}(z'_{ir},z'_{vis})
H^(zir′,zvis′)是从
z
v
i
s
′
z'_{vis}
zvis′到
z
i
r
′
z_{ir}'
zir′的联合熵。为了计算
M
I
(
z
v
i
s
′
,
z
i
r
′
)
MI(z_{vis}',z_{ir}')
MI(zvis′,zir′),作者使用KL散度来计算边缘熵,并通过互信息最小化损失:
L
M
I
(
z
v
i
s
′
,
z
i
r
′
)
=
H
^
(
z
v
i
s
′
,
z
i
r
′
)
+
H
^
(
z
i
r
′
,
z
v
i
s
′
)
−
(
K
L
(
z
v
i
s
′
∣
∣
z
i
r
′
)
+
K
L
(
z
i
r
′
∣
∣
z
v
i
s
′
)
)
L_{MI}(z_{vis}',z_{ir}')=\hat{H}(z_{vis}',z_{ir}')+\hat{H}(z_{ir}',z_{vis}')-(KL(z_{vis}'||z_{ir}')+KL(z_{ir}'||z_{vis}'))
LMI(zvis′,zir′)=H^(zvis′,zir′)+H^(zir′,zvis′)−(KL(zvis′∣∣zir′)+KL(zir′∣∣zvis′))
其中
H
^
(
z
i
r
′
,
z
v
i
s
′
)
\hat{H}(z_{ir}',z_{vis}')
H^(zir′,zvis′)是从
z
v
i
s
′
z_{vis}'
zvis′到
z
i
r
′
z_{ir}'
zir′的交叉熵。
通过最小化
F
v
i
s
′
F_{vis}'
Fvis′和
F
i
r
′
F_{ir}'
Fir′之间的互信息,可以突出不同的模态特征。然后我们将
F
v
i
s
′
F_{vis}'
Fvis′和
F
i
r
′
F_{ir}'
Fir′连接起来,并使用另一个转换器块融合它们以获得
F
f
F_f
Ff。然后,仅最小化互信息可能会导致潜在的信息丢失,因为网络会为达到较低的
L
M
I
L_{MI}
LMI丢弃一些重要的特征。为缓解该问题,需要在
F
f
F_f
Ff和原始模态特征
F
v
i
s
F_{vis}
Fvis和
F
i
r
F_{ir}
Fir之间施加互信息最大化。如图4所示,分别从
F
f
,
F
v
i
s
和
F
i
r
F_f, F_{vis}和F_{ir}
Ff,Fvis和Fir获得三个潜向量
z
f
,
z
v
i
s
和
z
i
r
z_f, z_{vis}和z_{ir}
zf,zvis和zir。为实现最大互信息,将每个
{
z
v
i
s
,
z
f
}
\{z_{vis},z_f\}
{zvis,zf}视为正样本,而将同一批次中的其他样本视为负样本:
L
N
C
E
v
i
s
=
−
∑
i
=
1
N
l
o
g
e
x
p
(
z
f
i
T
z
v
i
s
i
)
∑
j
=
1
,
j
≠
i
N
e
x
p
(
z
f
i
T
z
v
i
s
j
)
L_{NCE}^{vis}=-\sum_{i=1}^N log\frac{exp(z_{f_i}^Tz_{vis_i})}{\sum_{j=1, j\neq i}^Nexp(z^T_{f_i}z_{vis_j})}
LNCEvis=−i=1∑Nlog∑j=1,j=iNexp(zfiTzvisj)exp(zfiTzvisi)
其中N表示批量大小,
z
v
i
s
i
z_{vis_i}
zvisi和
z
f
i
z_{f_i}
zfi表示批次中第i个对应嵌入。
(那么我们该怎么理解这个公式呢?具体来说,对于每个样本
i
i
i, 计算其正样本(也就是自身样本)的相似度得分,即
e
x
p
(
z
f
i
T
z
v
i
s
i
)
exp(z_{f_i}^Tz_{vis_i})
exp(zfiTzvisi), 与负样本(即批次中除自身外的其他所有样本)的相似度得分, 也即
∑
j
=
1
,
j
≠
i
N
e
x
p
(
z
f
i
T
z
v
i
s
j
)
\sum_{j=1, j\neq i}^Nexp(z^T_{f_i}z_{vis_j})
∑j=1,j=iNexp(zfiTzvisj)。 这个方程的目标是实现最小化,这相当于增加正样本间的相似度,同时减少负样本的相似度,从而达到最大化互信息的目的。)
红外模态的
L
N
C
E
i
r
L_{NCE}^{ir}
LNCEir的定义类似。值得注意的是,最小化损失
L
M
I
L_{MI}
LMI和最大化损失
L
N
C
E
L_{NCE}
LNCE是不同的,因为最小化损失通常是通过调整最小化界限而不是最小化本身来完成的,因此不能用
−
L
M
I
-L_{MI}
−LMI来代替
L
N
C
E
L_{NCE}
LNCE。
这种通过优化最小最大互信息的方式确保了融合特征捕获两种模态的基本特征,并能够平衡它们的唯一性和完整性。
2.5 进度式训练
总的来说,EVIF的训练遵循三阶段方法,三个任务依次逐步学习。在每个阶段,保持前几个阶段的训练任务与新任务一起进行。对于可见光纹理重建和去模糊任务,使用L2损失训练损失。在纹理细节网络重建完成后,进一步去训练去模糊网络,并进行夸任务事件增强。最后,训练融合网络,训练网络的损失函数如下所示:
L
f
u
s
e
=
γ
1
L
S
S
I
M
+
γ
2
L
M
I
+
γ
(
L
N
C
E
v
i
s
+
L
N
C
E
i
r
)
L_{fuse}=\gamma_1L_{SSIM}+\gamma_2L_{MI}+\gamma(L_{NCE}^{vis}+L_{NCE}^{ir})
Lfuse=γ1LSSIM+γ2LMI+γ(LNCEvis+LNCEir)
L
S
S
I
M
L_{SSIM}
LSSIM是融合图像与重建任务和去模糊任务之间的SSIM损失。
三 实验
3.1数据集和硬件系统
为了彻底验证本文所提方法的有效性,作者分别在合成数据集和真实数据集上进行了仿真实验。
合成数据:在多光谱数据集KAIST上模拟高速动态场景,平均每7帧形成一张模糊的红外帧和可见光帧。事件是由ESIM模拟器生成。
真实数据:构建了一个由DAVIS346事件相机和一个红外相机组成的混合相机系统。然后在各种复杂场景(如深夜低光环境和高速车辆上的机载捕获)下捕获数据。

3.2 实验结果
为验证模型的性能,作者将模型与传统的VIF方法做了对比,与近期研究表现良好的深度学习的方法进行了对比。还做了消融实验,验证跨任务事件增强效果和最小最大互信息优化的效果。
3.2.1 对比实验结果
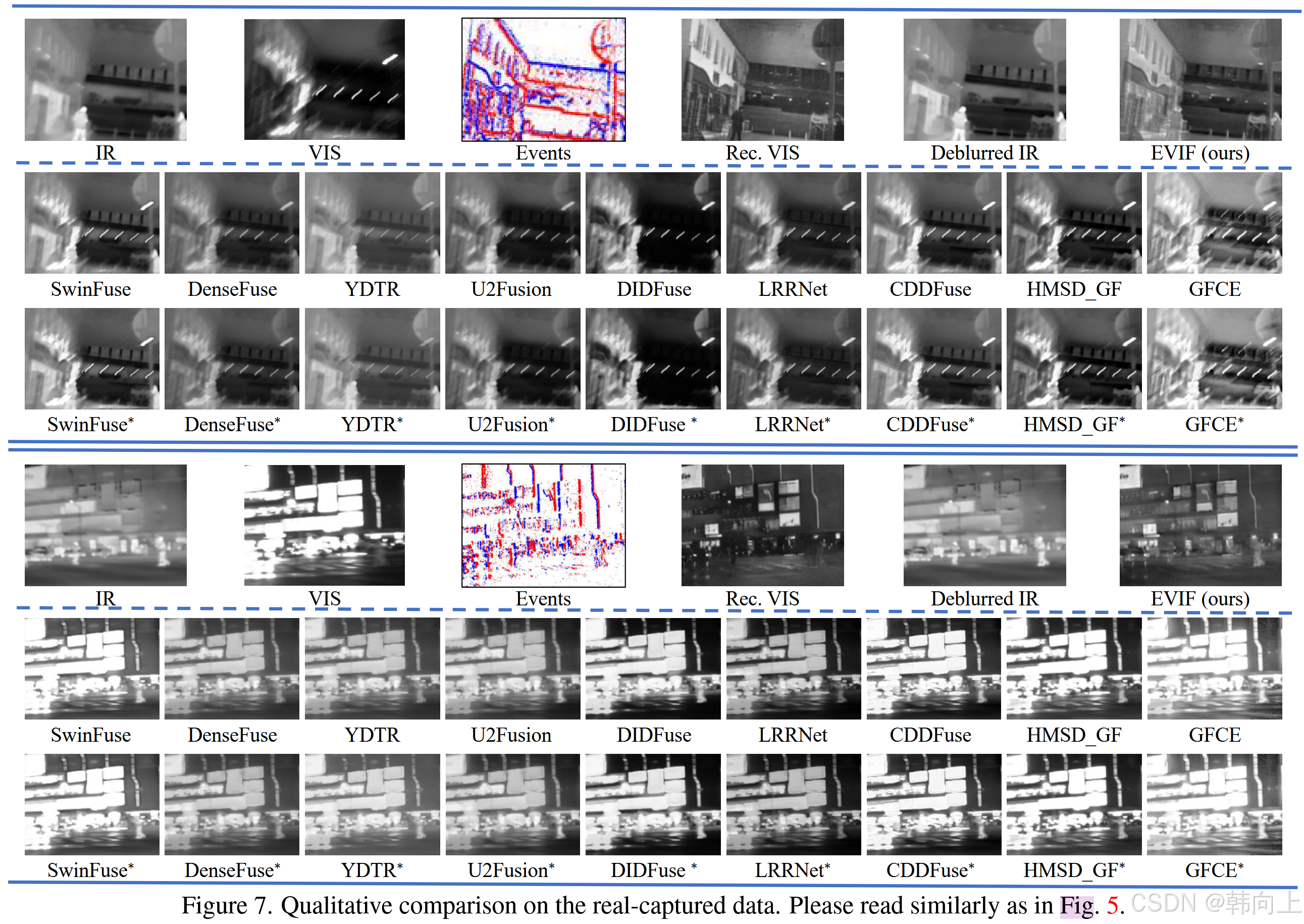
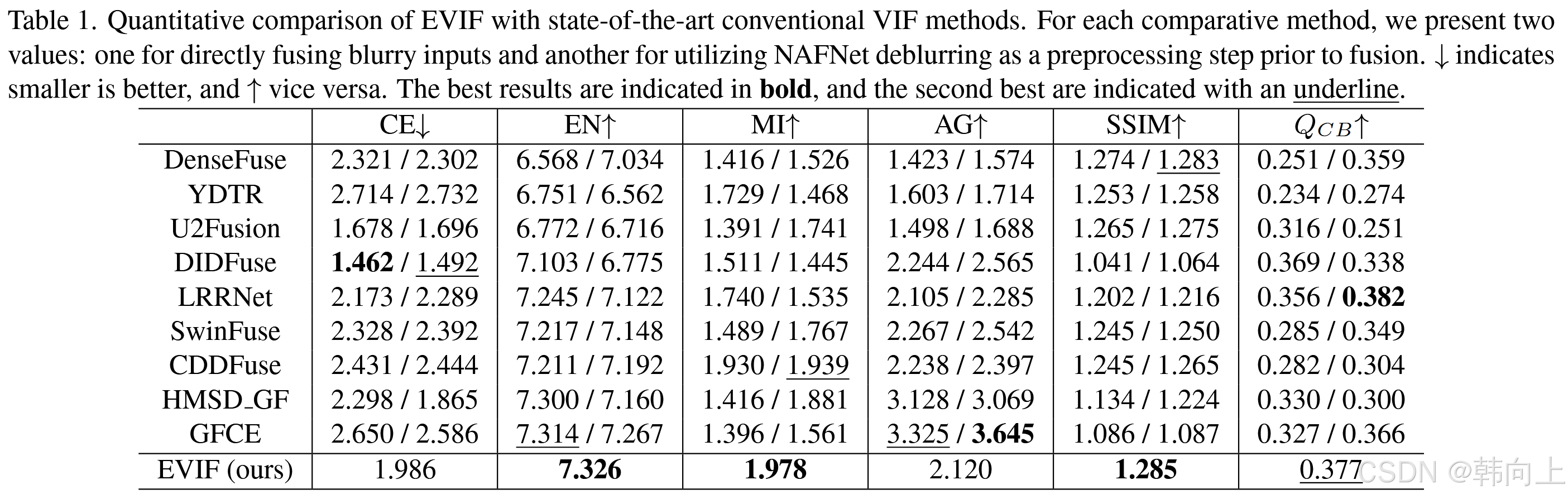
图5是不同方法在合成数据集上的实验结果,表1是对应的定量结果。图7是对比方法在真实数据集上的实验结果。

3.2.2 消融实验
跨任务事件增强:目的是验证跨任务事件增强对红外图像去模糊性能的影响。图8是定性结果,表二是定量结果。首先可以看到从事件中提取的运动线索确实可以促进去模糊任务的性能。其次,从细节重建网络中引入的运动线索确实能够促进红外图像的去模糊效果,证明了跨任务互补特征能够促进模型的鲁棒性。
最小最大互信息优化:目的验证该优化在突出双光的互补信息,同时减少信息损失的合理性。如图9所示,在不使用MI优化时。融合后的图像仅是两种图像的均值;如果仅仅MI最小化则会导致信息的丢失,仅仅使用最大化时,网络则会引入多余的冗余信息。



四 结论
在这篇文章中,作者提出了一个新的基于事件驱动的可见光和红外融合系统。
- 事件相机具有低延迟和高动态范围的特点,能够处理极端光照环境和高动态运动场景下图像模糊和过曝问题。
- 开发了一个多任务协同框架,包括可见光纹理细节重建、红外图像去模糊以及红外-可见光图像融合这三个任务。其中设计了跨任务事件增强模块用于将纹理细节重建任务中的特征辅助红外图像去模糊任务;在融合过程中设计了最小-最大互信息优化旨在突出双光的互补信息,同时减少信息损失。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读-Event-based Visible and Infrared Fusion via Multi-task Collaboration

发表评论 取消回复