我自己的原文哦~ https://blog.51cto.com/whaosoft/12362395
一、不同的电平信号的MCU怎么通信?
下面这个“电平转换”电路,理解后令人心情愉快。电路设计其实也可以很有趣。
先说一说这个电路的用途:当两个MCU在不同的工作电压下工作(如MCU1 工作电压5V;MCU2 工作电压3.3V),那么MCU1 与MCU2之间怎样进行串口通信呢?很明显是不能将对应的TX、RX引脚直接相连的,否测可能造成较低工作电压的MCU烧毁!
下面的“电平双向转换电路”就可以实现不同VDD(芯片工作电压)的MCU之间进行串口通信。

该电路的核心在于电路中的MOS场效应管(2N7002)。他和三极管的功能很相似,可做开关使用,即可控制电路的通和断。不过比起三极管,MOS管有挺多优势,后面将会详细讲起。下图是MOS管实物3D图和电路图。简单的讲,要让他当做开关,只要让Vgs(导通电压)达到一定值,引脚D、S就会导通,Vgs没有达到这个值就截止。
那么如何将2N7002应用到上面电路中呢,又起着什么作用呢?下面我们来分析一下。
如果沿着a、b两条线,将电路切断。那么MCU1的TX引脚被上拉为5V,MCU2的RX引脚也被上拉为3.3V。2N7002的S、D引脚(对应图中的2、3引脚)截止就相当于a、b两条线,将电路切断。也就是说,此电路在2N7002截止的时候是可以做到,给两个MCU引脚输送对应的工作电压。
下面进一步分析:
数据传输方向MCU1-->MCU2。
1. MCU1 TX发送高电平(5V),MCU2 RX配置为串口接收引脚,此时2N7002的S、D引脚(对应图中的2、3引脚)截止,2N7002里面的二极管3-->2方向不通。那么MCU2 RX被VCC2上拉为3.3V。
2. MCU1 TX发送低电平(0V),此时2N7002的S、D引脚依然截止,但是2N7002里面的二极管2-->3方向通,即VCC2、R2、2N7002里的二极管、MCU1 TX组成一个回路。2N7002的2引脚被拉低,此时MCU2 RX为0V。该电路从MCU1到MCU2方向,数据传输,达到了电平转换的效果。
接下来分析
数据传输方向MCU2-->MCU1
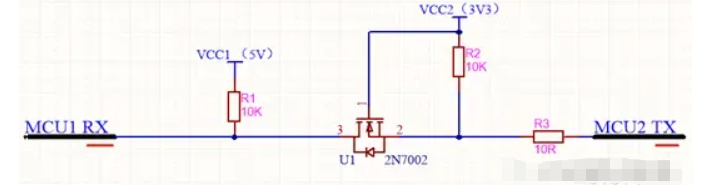
1. MCU2 TX发送高电平(3.3V),此时Vgs(图中1、2引脚电压差)电压差约等于0,2N7002截止,2N7002里面的二极管3-->2方向不通,此时MCU1 RX引脚被VCC1上拉为5V。
2. MCU2 TX发送低电平(0V),此时Vgs(图中1、2引脚电压差)电压差约等于3.3V,2N7002导通,2N7002里面的二极管3-->2方向不通,VCC1、R1、2N7002里的二极管、MCU2 TX组成一个回路。2N7002的3引脚被拉低,此时MCU1 RX为0V。
该电路从MCU2到MCU1方向,数据传输,达到了电平转换的效果。
到此,该电路就分析完了,这是一个双向的串口电平转换电路。
MOS的优势:
1、场效应管的源极S、栅极G、漏极D分别对应于三极管的发射极e、基极b、集电极c,它们的作用相似,图一所示是N沟道MOS管和NPN型晶体三极管引脚,图二所示是P沟道MOS管和PNP型晶体三极管引脚对应图。
2、场效应管是电压控制电流器件,由VGS控制ID,普通的晶体三极管是电流控制电流器件,由IB控制IC。MOS管道放大系数是(跨导gm)当栅极电压改变一伏时能引起漏极电流变化多少安培。晶体三极管是电流放大系数(贝塔β)当基极电流改变一毫安时能引起集电极电流变化多少。
3、场效应管栅极和其它电极是绝缘的,不产生电流;而三极管工作时基极电流IB决定集电极电流IC。因此场效应管的输入电阻比三极管的输入电阻高的多。
4、场效应管只有多数载流子参与导电;三极管有多数载流子和少数载流子两种载流子参与导电,因少数载流子浓度受温度、辐射等因素影响较大,所以场效应管比三极管的温度稳定性好。
5、场效应管在源极未与衬底连在一起时,源极和漏极可以互换使用,且特性变化不大,而三极管的集电极与发射极互换使用时,其特性差异很大,b 值将减小很多。
6、场效应管的噪声系数很小,在低噪声放大电路的输入级及要求信噪比较高的电路中要选用场效应管。
7、场效应管和普通晶体三极管均可组成各种放大电路和开关电路,但是场效应管制造工艺简单,并且又具有普通晶体三极管不能比拟的优秀特性,在各种电路及应用中正逐步的取代普通晶体三极管,目前的大规模和超大规模集成电路中,已经广泛的采用场效应管。
8、输入阻抗高,驱动功率小:由于栅源之间是二氧化硅(SiO2)绝缘层,栅源之间的直流电阻基本上就是SiO2绝缘电阻,一般达100MΩ左右,交流输入阻抗基本上就是输入电容的容抗。由于输入阻抗高,对激励信号不会产生压降,有电压就可以驱动,所以驱动功率极小(灵敏度高)。一般的晶体三极管必需有基极电压Vb,再产生基极电流Ib,才能驱动集电极电流的产生。晶体三极管的驱动是需要功率的(Vb×Ib)。
9、开关速度快:MOSFET的开关速度和输入的容性特性的有很大关系,由于输入容性特性的存在,使开关的速度变慢,但是在作为开关运用时,可降低驱动电路内阻,加快开关速度(输入采用了后述的“灌流电路”驱动,加快了容性的充放电的时间)。MOSFET只靠多子导电,不存在少子储存效应,因而关断过程非常迅速,开关时间在10—100ns之间,工作频率可达100kHz以上,普通的晶体三极管由于少数载流子的存储效应,使开关总有滞后现象,影响开关速度的提高(目前采用MOS管的开关电源其工作频率可以轻易的做到100K/S~150K/S,这对于普通的大功率晶体三极管来说是难以想象的)。
10、无二次击穿:由于普通的功率晶体三极管具有当温度上升就会导致集电极电流上升(正的温度~电流特性)的现象,而集电极电流的上升又会导致温度进一步的上升,温度进一步的上升,更进一步的导致集电极电流的上升这一恶性循环。而晶体三极管的耐压VCEO随管温度升高是逐步下降,这就形成了管温继续上升、耐压继续下降最终导致晶体三极管的击穿,这是一种导致电视机开关电源管和行输出管损坏率占95%的破环性的热电击穿现象,也称为二次击穿现象。MOS管具有和普通晶体三极管相反的温度~电流特性,即当管温度(或环境温度)上升时,沟道电流IDS反而下降。例如;一只IDS=10A的MOS FET开关管,当VGS控制电压不变时,在250C温度下IDS=3A,当芯片温度升高为1000C时,IDS降低到2A,这种因温度上升而导致沟道电流IDS下降的负温度电流特性,使之不会产生恶性循环而热击穿。也就是MOS管没有二次击穿现象,可见采用MOS管作为开关管,其开关管的损坏率大幅度的降低,近两年电视机开关电源采用MOS管代替过去的普通晶体三极管后,开关管损坏率大大降低也是一个极好的证明。
11、MOS管导通后其导通特性呈纯阻性:普通晶体三极管在饱和导通是,几乎是直通,有一个极低的压降,称为饱和压降,既然有一个压降,那么也就是;普通晶体三极管在饱和导通后等效是一个阻值极小的电阻,但是这个等效的电阻是一个非线性的电阻(电阻上的电压和流过的电流不能符合欧姆定律),而MOS管作为开关管应用,在饱和导通后也存在一个阻值极小的电阻,但是这个电阻等效一个线性电阻,其电阻的阻值和两端的电压降和流过的电流符合欧姆定律的关系,电流大压降就大,电流小压降就小,导通后既然等效是一个线性元件,线性元件就可以并联应用,当这样两个电阻并联在一起,就有一个自动电流平衡的作用,所以MOS管在一个管子功率不够的时候,可以多管并联应用,且不必另外增加平衡措施(非线性器件是不能直接并联应用的)。
二、STM32单片机的堆栈
堆栈是内存中一段连续的存储区域,用来保存一些临时数据:嵌入式开发中更接近底层的汇编与C语言。堆栈操作由PUSH、POP两条指令来完成。而程序内存可以分为几个区:
- 栈区(stack)
- 堆区(Heap)
- 全局区(static)
- 文字常亮区程序代码区
程序编译之后,全局变量,静态变量已经分配好内存空间,在函数运行时,程序需要为局部变量分配栈空间,当中断来时,也需要将函数指针入栈,保护现场,以便于中断处理完之后再回到之前执行的函数。
栈是从高到低分配,堆是从低到高分配。
普通单片机与STM32单片机中堆栈的区别
普通单片机启动时,不需要用bootloader将代码从ROM搬移到RAM。
但是STM32单片机需要。
这里我们可以先看看单片机程序执行的过程,单片机执行分三个步骤:
- 取指令
- 分析指令
- 执行指令
根据PC的值从程序存储器读出指令,送到指令寄存器。然后分析执行执行。这样单片机就从内部程序存储器去代码指令,从RAM存取相关数据。
RAM取数的速度是远高于ROM的,但是普通单片机因为本身运行频率不高,所以从ROM取指令慢并不影响。
而STM32的CPU运行的频率高,远大于从ROM读写的速度。所以需要用bootloader将代码从ROM搬移到RAM。
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。
其实堆栈就是单片机中的一些存储单元,这些存储单元被指定保存一些特殊信息,比如地址(保护断点)和数据(保护现场)。
如果非要给他加几个特点的话那就是:
- 这些存储单元中的内容都是程序执行过程中被中断打断时,事故现场的一些相关参数。如果不保存这些参数,单片机执行完中断函数后就无法回到主程序继续执行了。
- 这些存储单元的地址被记在了一个叫做堆栈指针(SP)的地方。
结合STM32的开发讲述堆栈
从上面的描述可以看得出来,在代码中是如何占用堆和栈的。可能很多人还是无法理解,这里再结合STM32的开发过程中与堆栈相关的内容来进行讲述。
如何设置STM32的堆栈大小?
在基于MDK的启动文件开始,有一段汇编代码是分配堆栈大小的。
这里重点知道堆栈数值大小就行。还有一段AREA(区域),表示分配一段堆栈数据段。数值大小可以自己修改,也可以使用STM32CubeMX数值大小配置,如下图所示。
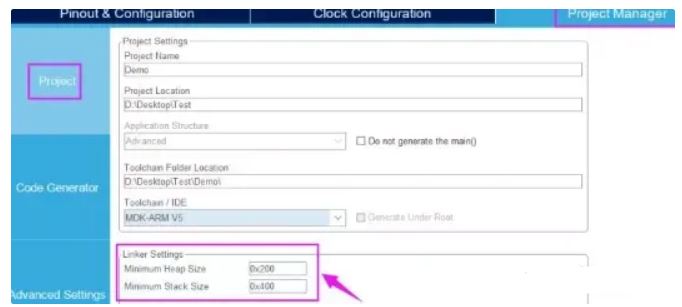
STM32F1默认设置值0x400,也就是1K大小。
Stack_Size EQU 0x400函数体内局部变量:
void Fun(void){ char i; int Tmp[256]; //...}局部变量总共占用了256*4 + 1字节的栈空间。所以,在函数内有较多局部变量时,就需要注意是否超过我们配置的堆栈大小。
函数参数:
void HAL_GPIO_Init(GPIO_TypeDef *GPIOx, GPIO_InitTypeDef *GPIO_Init)这里要强调一点:传递指针只占4字节,如果传递的是结构体,就会占用结构大小空间。提示:在函数嵌套,递归时,系统仍会占用栈空间。
堆(Heap)的默认设置0x200(512)字节。
Heap_Size EQU 0x200大部分人应该很少使用malloc来分配堆空间。虽然堆上的数据只要程序员不释放空间就可以一直访问,但是,如果忘记了释放堆内存,那么将会造成内存泄漏,甚至致命的潜在错误。
MDK中RAM占用大小分析
经常在线调试的人,可能会分析一些底层的内容。这里结合MDK-ARM来分析一下RAM占用大小的问题。在MDK编译之后,会有一段RAM大小信息:
这里4+6=1640,转换成16进制就是0x668,在进行在调试时,会出现:
这个MSP就是主堆栈指针,一般我们复位之后指向的位置,复位指向的其实是栈顶:
而MSP指向地址0x20000668是0x20000000偏移0x668而得来。具体哪些地方占用了RAM,可以参看map文件中【Image Symbol Table】处的内容:
三、学习STM32时为什么要学习汇编?
不同的平台的汇编代码是不一样的,最早的汇编在50年代就发明了,比很多人的父母的年龄都大,老掉牙,不用学习怎么写汇编。一个公司有一个人知道怎么写汇编就够了。但要学习读汇编
为什么学习汇编?
性能
直接翻译为机器语言,性能最高。优秀的C语言效率只能达到汇编的80%左右。其他高级语言跟汇编一比差得更远。语言越高级性能越差。很多bootloader和BIOS用汇编写,汇编操作的是电脑,手机刚刚上电时,硬件和初始化的那些命令,它们的性能的要求比较高,效率高开机速度更快。
分析问题
个人认为,编程人与机器对话,我们写C,写JAVA,但是电脑并不认识这些语言,电脑只认识0和1;所以需要一个人来翻译这些语言,这个翻译官就是编译器,但是编译器不能百分之百准确的表达程序员的意思,也就是所谓的翻译有反义。例如,编译器为了性能好一点,可能会优化变量和语句,这个过程可能好心办坏事,把有用的操作优化了。因此只有看懂一些汇编语句,才能分析程序真正执行的流程。在问题难以定位的情况下,汇编可能是分析问题的最后一根稻草。
帮助理解硬件
有些学校的单片机课程是以汇编进行教学的,主要原因就是汇编更贴近硬件。不过我不赞成这种做法,C语言能快速做出一点东西,有利于学生在放弃之前,增加成就感,好坚持下去。但是汇编确实更贴近硬件。
LDR指令
为了便于理解下文,先介绍下LDR指令,其格式如下:
LDR{条件} 目的寄存器 <存储器地址>作用:将 存储器地址 所指地址处连续的4个字节(1个字)的数据传送到目的寄存器中。LDR指令的寻址方式比较灵活,实例如下:
LDR R0,[R1] ;将存储器地址为R1的字数据读入寄存器R0。
LDR R0,[R1,R2] ;将存储器地址为R1+R2的字数据读入寄存器R0。
LDR R0,[R1,#8] ;将存储器地址为R1+8的字数据读入寄存器R0。
LDR R0,[R1],R2 ;将存储器地址为R1的字数据读入寄存器R0,并将R1+R2的值存入R1。
LDR R0,[R1],#8 ;将存储器地址为R1的字数据读入寄存器R0,并将R1+8的值存入R1。
LDR R0,[R1,R2]! ;将存储器地址为R1+R2的字数据读入寄存器R0,并将R1+R2的值存入R1。
LDR R0,[R1,LSL #3] ;将存储器地址为R1*8的字数据读入寄存器R0。
LDR R0,[R1,R2,LSL #2] ;将存储器地址为R1+R2*4的字数据读入寄存器R0。
LDR R0,[R1,R2,LSL #2]!;将存储器地址为R1+R2*4的字数据读入寄存器R0,并将R1+R2*4的值存入R1。
LDR R0,[R1],R2,LSL #2 ;将存储器地址为R1的字数据读入寄存器R0,并将R1+R2*4的值存入R1。
LDR R0,Label ;Label为程序标号,Label必须是当前指令的-4~4KB范围内。要注意的是:
LDR Rd,[Rn],#0x04 ;这里Rd不允许是R15。另外LDRB 的指令格式与LDR相似,只不过它是将存储器地址中的8位(1个字节)读到目的寄存器中。LDRH的指令格式也与LDR相似,它是将内存中的16位(半字)读到目的寄存器中。
LDR R0,=0xff这里的LDR不是arm指令,而是伪指令。这个时候与MOVE很相似,只不过MOV指令后的立即数是有限制的。这个立即数必须是0X00-OXFF范围内的数经过偶数次右移得到的数,所以MOV用起来比较麻烦,因为有些数不那么容易看出来是否合法。
如何在KEIL下阅读汇编
按d进入debug模式,在view下选择disassembly window 。
看光标,c文件下指向了main函数的第一行。
汇编窗口也指向了对应的语句。但是,在执行C语言的第一行之前,仍然有许多操作要做,比如变量放在哪?在哪里调用了main函数等,这些操作都被集成开发环境IDE给封装起来了。我们必须知道,在执行main函数之前,有许多事情要做,只不过,初学的时候不必理会。以下是C语言源码,功能是点亮LED。
//main.c
#include
int main(void)
{
RCC->APB2ENR |= RCC_APB2ENR_IOPBEN;
GPIOB->CRL &= ~(0xf<<(1*4));
GPIOB->CRL |= 0x2<<(1*4);
GPIOB->ODR &= ~(1<<1);
return 0;
}
//main.h
#define RCC_APB2ENR (*(unsigned int *)0x40021018)
#define GPIOB_CRL (*(unsigned int *)0x40010c00)
#define GPIOB_ODR (*(unsigned int *)0x40010c0c)汇编窗口往上翻,确实很多语句,先看这几行代码的汇编:
先说最常用的两句汇编:
LDR r0,[r1] r0 = *r1
STR r0,[r1] *r1 = r0
MOV r0,r1 r1->r0拷贝从内存0x0800 017c的32位数据拷贝到r0:
r0 = * 0x0800 017c我们看到的 1000 4002其实 就是0x4002 1000。这里边有个知识点叫做大小端模式,以下简单讲解,不能理解就记住。

这个数据是在地址是这么存放的:
7C 7D 7E 7F
00 10 02 40
实际数据是0x4002 1000
* 0x0800 017c=0x4002 1000然后r0的值+0x18也就是24 因为这个是第6号(第6号就是第7个的意思)元素
得到r0 = *0x4002 1018,r0的值由一个地址,变成了地址所存放的数据。
然后是或0x08操作,结果再复制给r0,*0x4002 1018 |=0x08
给r1分配地址,这个地址也是0x4002 1000, r1 = *0x4002 1000
把r0存放的值,(不是r0的地址,)存到r1+18的空间上
*(r1+0x18) = r0
*0x4002 1018 = (*0x4002 1018 |=0x08)
*0x4002 1018|=0x08
最终结果:地址4002 1018的数,执行了或0x08的操作。再分析下一句 :
前两句给r0分配空间,r0 = *0x4001 0c00
然后用BIC清除数据位,把4-7位清零,结果再赋值给r0。
*0x4001 0c00 &= ~(0xf0)
r1 = *0x4001 0c00
*0x4001 0c00 &= ~(0xf0)剩下的不再详细分析,直接给答案 :
***0x4001 0c00 |= 0x20
0x4001 0c0c &= ~(0x02)*最终,可以看到C语句被翻译成了意料之中的汇编语句,自己的意图被机器准确的理解了。
四、嵌入式软件定时器的实现
1 什么是软件定时器
软件定时器是用程序模拟出来的定时器,可以由一个硬件定时器模拟出成千上万个软件定时器,这样程序在需要使用较多定时器的时候就不会受限于硬件资源的不足,这是软件定时器的一个优点,即数量不受限制。
但由于软件定时器是通过程序实现的,其运行和维护都需要耗费一定的CPU资源,同时精度也相对硬件定时器要差一些。
2 软件定时器的实现原理
在Linux,uC/OS,FreeRTOS等操作系统中,都带有软件定时器,原理大同小异。典型的实现方法是:通过一个硬件定时器产生固定的时钟节拍,每次硬件定时器中断到,就对一个全局的时间标记加一,每个软件定时器都保存着到期时间。
程序需要定期扫描所有运行中的软件定时器,将各个到期时间与全局时钟标记做比较,以判断对应软件定时器是否到期,到期则执行相应的回调函数,并关闭该定时器。
以上是单次定时器的实现,若要实现周期定时器,即到期后接着重新定时,只需要在执行完回调函数后,获取当前时间标记的值,加上延时时间作为下一次到期时间,继续运行软件定时器即可。
3 基于STM32的软件定时器
3.1 时钟节拍
软件定时器需要一个硬件时钟源作为基准,这个时钟源有一个固定的节拍(可以理解为秒针的每次滴答),用一个32位的全局变量tickCnt来记录这个节拍的变化:
static volatile uint32_t tickCnt = 0; //软件定时器时钟节拍每来一个节拍就对tickCnt加一(记录滴答了多少下):
/* 需在定时器中断内执行 */
void tickCnt_Update(void)
{
tickCnt++;
}一旦开始运行,tickCnt将不停地加一,而每个软件定时器都记录着一个到期时间,只要tickCnt大于该到期时间,就代表定时器到期了。
3.2 数据结构
软件定时器的数据结构决定了其执行的性能和功能,一般可分为两种:数组结构和链表结构。什么意思呢?这是(多个)软件定时器在内存中的存储方式,可以用数组来存,也可以用链表来存。
两者的优劣之分就是两种数据结构的特性之分:数组方式的定时器查找较快,但数量固定,无法动态变化,数组大了容易浪费内存,数组小了又可能不够用,适用于定时事件明确且固定的系统;链表方式的定时器数量可动态增减,易造成内存碎片(如果没有内存管理),查找的时间开销相对数组大,适用于通用性强的系统,Linux,uC/OS,FreeRTOS等操作系统用的都是链表式的软件定时器。
本文使用数组结构:
static softTimer timer[TIMER_NUM]; //软件定时器数组数组和链表是软件定时器整体的数据结构,当具体到单个定时器时,就涉及软件定时器结构体的定义,软件定时器所具有的功能与其结构体定义密切相关,以下是本文中软件定时器的结构体定义:
typedef struct softTimer {
uint8_t state; //状态
uint8_t mode; //模式
uint32_t match; //到期时间
uint32_t period; //定时周期
callback *cb; //回调函数指针
void *argv; //参数指针
uint16_t argc; //参数个数
}softTimer;定时器的状态共有三种,默认是停止,启动后为运行,到期后为超时。
typedef enum tmrState {
SOFT_TIMER_STOPPED = 0, //停止
SOFT_TIMER_RUNNING, //运行
SOFT_TIMER_TIMEOUT //超时
}tmrState;模式有两种:到期后就停止的是单次模式,到期后重新定时的是周期模式。
typedef enum tmrMode {
MODE_ONE_SHOT = 0, //单次模式
MODE_PERIODIC, //周期模式
}tmrMode;不管哪种模式,定时器到期后,都将执行回调函数,以下是该函数的定义,参数指针argv为void指针类型,便于传入不同类型的参数。
typedef void callback(void *argv, uint16_t argc);上述结构体中的模式state和回调函数指针cb是可选的功能,如果系统不需要周期执行的定时器,或者不需要到期后自动执行某个函数,可删除此二者定义。
3.3 定时器操作
3.3.1 初始化
首先是软件定时器的初始化,对每个定时器结构体的成员赋初值,虽说static变量的初值为0,但个人觉得还是有必要保持初始化变量的习惯,避免出现一些奇奇怪怪的BUG。
void softTimer_Init(void)
{
uint16_t i;
for(i=0; i<TIMER_NUM; i++) {
timer[i].state = SOFT_TIMER_STOPPED;
timer[i].mode = MODE_ONE_SHOT;
timer[i].match = 0;
timer[i].period = 0;
timer[i].cb = NULL;
timer[i].argv = NULL;
timer[i].argc = 0;
}
}3.3.2 启动
启动一个软件定时器不仅要改变其状态为运行状态,同时还要告诉定时器什么时候到期(当前tickCnt值加上延时时间即为到期时间),单次定时还是周期定时,到期后执行哪个函数,函数的参数是什么,交代好这些就可以开跑了。
void softTimer_Start(uint16_t id, tmrMode mode, uint32_t delay, callback *cb, void *argv, uint16_t argc)
{
assert_param(id < TIMER_NUM);
assert_param(mode == MODE_ONE_SHOT || mode == MODE_PERIODIC);
timer[id].match = tickCnt_Get() + delay;
timer[id].period = delay;
timer[id].state = SOFT_TIMER_RUNNING;
timer[id].mode = mode;
timer[id].cb = cb;
timer[id].argv = argv;
timer[id].argc = argc;
}上面函数中的assert_param()用于参数检查,类似于库函数assert()。
3.3.3 更新
本文中软件定时器有三种状态:停止,运行和超时,不同的状态做不同的事情。停止状态最简单,啥事都不做;运行状态需要不停地检查有没有到期,到期就执行回调函数并进入超时状态;超时状态判断定时器的模式,如果是周期模式就更新到期时间,继续运行,如果是单次模式就停止定时器。这些操作都由一个更新函数来实现:
void softTimer_Update(void)
{
uint16_t i;
for(i=0; i<TIMER_NUM; i++) {
switch (timer[i].state) {
case SOFT_TIMER_STOPPED:
break;
case SOFT_TIMER_RUNNING:
if(timer[i].match <= tickCnt_Get()) {
timer[i].state = SOFT_TIMER_TIMEOUT;
timer[i].cb(timer[i].argv, timer[i].argc); //执行回调函数
}
break;
case SOFT_TIMER_TIMEOUT:
if(timer[i].mode == MODE_ONE_SHOT) {
timer[i].state = SOFT_TIMER_STOPPED;
} else {
timer[i].match = tickCnt_Get() + timer[i].period;
timer[i].state = SOFT_TIMER_RUNNING;
}
break;
default:
printf("timer[%d] state error!\r\n", i);
break;
}
}
}3.3.4 停止
如果定时器跑到一半,想把它停掉,就需要一个停止函数,操作很简单,改变目标定时器的状态为停止即可:
void softTimer_Stop(uint16_t id)
{
assert_param(id < TIMER_NUM);
timer[id].state = SOFT_TIMER_STOPPED;
}3.3.5 读状态
又如果想知道一个定时器是在跑着呢还是已经停下来?也很简单,返回它的状态:
uint8_t softTimer_GetState(uint16_t id)
{
return timer[id].state;
}或许这看起来很怪,为什么要返回,而不是直接读?别忘了在前面3.2节中定义的定时器数组是个静态全局变量,该变量只能被当前源文件访问,当外部文件需要访问它的时候只能通过函数返回,这是一种简单的封装,保持程序的模块化。
3.4 测试
最后,当然是来验证一下我们的软件定时器有没达到预想的功能。
定义三个定时器:
定时器TMR_STRING_PRINT只执行一次,1s后在串口1打印一串字符;
定时器TMR_TWINKLING为周期定时器,周期为0.5s,每次到期都将取反LED0的状态,实现LED0的闪烁;
定时器TMR_DELAY_ON执行一次,3s后点亮LED1,跟第一个定时器不同的是,此定时器的回调函数是个空函数nop(),点亮LED1的操作通过主循环中判断定时器的状态来实现,这种方式在某些场合可能会用到。
static uint8_t data[] = {1,2,3,4,5,6,7,8,9,0};
int main(void)
{
USART1_Init(115200);
TIM4_Init(TIME_BASE_MS);
TIM4_NVIC_Config();
LED_Init();
printf("I just grabbed a spoon.\r\n");
softTimer_Start(TMR_STRING_PRINT, MODE_ONE_SHOT, 1000, stringPrint, data, 5);
softTimer_Start(TMR_TWINKLING, MODE_PERIODIC, 500, LED0_Twinkling, NULL, 0);
softTimer_Start(TMR_DELAY_ON, MODE_ONE_SHOT, 3000, nop, NULL, 0);
while(1) {
softTimer_Update();
if(softTimer_GetState(TMR_DELAY_ON) == SOFT_TIMER_TIMEOUT) {
LED1_On();
}
}
}五、STM32单片机的启动过程
STM32启动流程。如果读者朋友已经有过汇编相关基础,能够够好理解本文内容。汇编语言是比C语言更接近机器底层的编程语言,能让我们更好的理解和操纵硬件底层。
STM32三种启动模式
下好程序后,重启芯片时,SYSCLK的第4个上升沿,BOOT引脚的值将被锁存,这就是所谓的启动过程。
STM32上电或者复位后,代码区始终从0x00000000开始,其实就是将存储空间的地址映射到0x00000000中。三种启动模式如下:
- 从主闪存存储器启动,将主Flash地址0x08000000映射到0x00000000,这样代码启动之后就相当于从0x08000000开始。主闪存存储器是STM32内置的Flash,作为芯片内置的Flash,是正常的工作模式。一般我们使用JTAG或者SWD模式下载程序时,就是下载到这个里面,重启后也直接从这启动程序。
- 从系统存储器启动。首先控制BOOT0、BOOT1管脚,复位后,STM32与上述两种方式类似,从系统存储器地址0x1FFF F000开始执行代码。系统存储器是芯片内部一块特定的区域,芯片出厂时在这个区域预置了一段Bootloader,就是通常说的ISP程序。这个区域的内容在芯片出厂后没有人能够修改或擦除,即它是一个ROM区。启动的程序功能由厂家设置。系统存储器存储的其实就是STM32自带的bootloader代码。
- 从内置SRAM启动,将SRAM地址0x20000000映射到0x00000000,这样代码启动之后就相当于从0x20000000开始。内置SRAM,也就是STM32的内存,既然是SRAM,自然也就没有程序存储的能力了,这个模式一般用于程序调试。假如我只修改了代码中一个小小的地方,然后就需要重新擦除整个Flash,比较的费时,可以考虑从这个模式启动代码,用于快速的程序调试,等程序调试完成后,在将程序下载到SRAM中。
用户可以通过设置BOOT1和BOOT0引脚的状态,来选择在复位后的启动模式。STM32三种启动模式对应的存储介质均是芯片内置的,如下图:
串口下载程序原理
从系统存储器启动,这种模式启动的程序功能是由厂家设置的。一般来说,这种启动方式用的比较少。系统存储器是芯片内部一块特定的区域,STM32在出厂时,由ST在这个区域内部预置了一段BootLoader,也就是我们常说的ISP程序,这是一块ROM,出厂后无法修改。
一般来说,我们选用这种启动模式时,是为了从串口下载程序,因为在厂家提供的BootLoader中,提供了串口下载程序的固件,可以通过这个BootLoader将程序下载到系统的Flash中。
这个下载方式需要以下步骤:
- 将BOOT0设置为1,BOOT1设置为0,然后按下复位键,这样才能从系统存储器启动BootLoader;
- 在BootLoader的帮助下,通过串口下载程序到Flash中;
- 程序下载完成后,又有需要将BOOT0设置为GND,手动复位,这样,STM32才可以从Flash中启动。
从汇编代码分析STM32启动过程
STM32的启动文件与编译器有关,不同编译器,它的启动文件不同。虽然启动文件(汇编)代码各有不同,但它们原理类似,都属于汇编程序。拿基于MDK-ARM的启动文件来举例,说一下要点内容。在基于MDK的启动文件开始,有一段汇编代码是分配堆栈大小的。
这里重点知道堆栈数值大小就行。还有一段AREA(区域),表示分配一段堆栈数据段。可以使用STM32CubeMX对上面的数值大小进行配置:
在IAR中,是通过工程配置堆栈大小:
看下面的汇编代码,程序上电之后,是跳到Reset_Handler这个位置。
Reset_Handler开始执行,再来看如下Reset_Handler汇编代码。在启动的时候,执行了SystemInit这个函数。
执行完SystemInit函数,初始化了系统时钟,之后跳转到main函数执行。
六、嵌入式代码注入漏洞浅析
随着互联网的发展,嵌入式设备正分布在一个充满可以被攻击者利用的源代码级安全漏洞的环境中。因此,嵌入式软件开发人员应该了解不同类型的安全漏洞——特别是代码注入。
术语“代码注入”意味着对程序的常规数据输入可以被制作成“包含代码”,并且该程序可以被欺骗来执行该代码。代码注入缺陷意味着黑客可以劫持现有进程,并以与原始进程相同的权限执行任何他们喜欢的代码。
在许多嵌入式系统中,进程需要以最高的权限运行,因此成功的代码注入攻击可以完全控制机器以及窃取数据,导致设备发生故障,将其作为其僵尸网络成员或使其永久无法使用。
代码注入漏洞的关键方面是:
该程序从输入通道读取数据
该程序将数据视为代码并对其进行编译
在大多数情况下,程序故意像执行代码一样执行数据是不寻常的,但将数据用于构造有意执行的对象却很常见。
1 格式化字符串漏洞
大多数C程序员熟悉printf函数。大体上,这些格式字符串后跟一个其他参数的列表,并且该格式字符串被解释为一组指令,用于将剩余的参数呈现为字符串。大多数用户知道如何编写最常用的格式说明符:例如字符串,小数和浮点数——%s,%d,%f——但是不知道还有其他格式字符串指令可以被滥用。
以下是printf函数通常被滥用的一种方式。有些程序员习惯编译字符串如下:
printf(str);
虽然这将在大部分时间内都具有所期望的效果,但它是错误的,因为printf的第一个参数将被编译为格式字符串。所以,如果str包含任何格式说明符,它们就将被这样编译。例如,如果str包含'%d',它会将printf参数列表中的下一个值解释为整数,并将其转换为字符串。在这种情况下,没有更多的参数,但机器在执行的时候并不了解这一点; 它所知道的全部是,函数的一些参数已经被推送到堆栈。
因为在C运行时没有机制可以告诉机器已经没有更多的参数了,所以printf将简单地选择恰好在堆栈中的下一个项目,将其编译为一个整数并打印出来。很容易看出,这可以用来从栈中打印任意数量的信息。例如,如果str包含'%d%d%d%d',则将会打印堆栈上接下来四个字的值。
虽然这是一个代码注入安全漏洞,但由于它唯一可能造成的伤害就是可以被用来获取栈中的数据,所以它还是可以被原谅的。可如果位于那里的是敏感数据(如密码或证书密钥),情况就会变得很糟;而且由于攻击者还可以在那里写入任意内存地址,因此情况还可能会变得更糟。
使这种糟糕情况的发生成为可能的是格式说明符'%n'。通常,相应的参数是指向整数的指针。当格式字符串为了建立结果字符串而被编译时,一遇到'%n',到目前为止写入的字节数就被放置到由该指针所指示的存储单元中了。例如,在下面的printf完成之后,i中的值将为4:
printf(“1234%n”,&i);
如果函数的实际参数比格式说明符更少,那么printf会将任何在堆栈上的数据作为参数编译。因此,如果攻击者可以控制格式字符串,那么它们可以将基本上任意的值写入堆栈位置。因为堆栈是局部变量所在的位置,所以它们的值可以被改变。如果这些变量中有一些是指针,那么这个平台甚至可以到达其他非堆栈地址。
真正对攻击者来说有价值的目标是让攻击者控制程序的执行部分。如果一个局部变量是一个函数指针,则攻击者可以通过该指针的后续调用来编写代码,实现自己的目标。当函数返回时,攻击者还可以将指令要被送达的地址覆盖重写。
2 避免代码注入
避免代码注入的最佳方法是通过设计。如果您可以使用一种永远不会出现漏洞的语言,那么这是最好的因为您的代码在构建时就是对一切攻击免疫的。或者您可以通过设计代码来禁止可能导致这些问题的接口。不幸的是,在嵌入式系统中,这些选择并不总是可行的。即使C是一种危险的语言,充斥着漏洞,但它仍然是许多组织架构的首选语言。鉴于此,开发人员应该了解其他避免代码注入的方法。
应该遵循的两个黄金规则以防止代码注入漏洞:
1.如果你可以避免的话,尽量不要将数据像代码一样编译;
2.如果你无法避免的话,请确保在使用数据之前验证数据是否良好。
为避免格式字符串的漏洞,这些规则中的第一个是最合适的; 你可以编写代码如下:
printf(“%s”,str);
这样,str的内容只被视为数据。这是最不费脑子的办法,只要你能找到所有应该做出这种修改的地方。但这对于大型程序来说可能是棘手的,特别是对于第三方代码库。
3 测试漏洞
测试这些类型的漏洞可能很困难; 即使能实现非常高的代码覆盖率的测试也不能触发这些问题。测试安全漏洞时,测试人员必须采取一个攻击者的心态。诸如模糊测试的技术可能是有用的,但是该技术通常太随机,无法高度可靠。
静态分析可以有效地发现代码注入漏洞。注意到早期生成的静态分析工具(如lint及其后代衍生产品)很不擅长发现这样的漏洞,因为想要实现精确的查找漏洞就需要完成整个程序的路径敏感分析。
最近出现的先进的静态分析工具更加有效。静态分析工具厂商对于哪些接口有危险,寻找目标的知识基础以及如何有效地进行这些工作已经积累了丰富的经验。
这里使用的关键技术是污染分析或危险信息流分析。这些工具通过首先识别潜在风险数据的来源,并对信息进行追踪,了解信息是如何通过代码不经过验证就流入正在使用的位置的。 同时这也是能实现整个流程可视化的最好工具。
4 结论
代码注入漏洞是危险的安全问题,因为它们可能允许攻击者中断程序,有时甚至完全控制程序。那些关心如何在一个充满潜在恶意的互联网环境中确保他们的嵌入式代码能够安全使用的开发人员,应该将这样的代码注入漏洞,在开发周期和严格的代码检查中尽早消除。而上面提到的高级静态分析工具是被推荐使用的。
来源:http://www.newelectronics.co.uk/electronics-technology/code-injection-a-common-vulnerability/150031/
七、如何优化单片机程序
1 程序结构优化
1.1 程序的书写结构
虽然书写格式并不会影响生成的代码质量,但是在实际编写程序时还是应该遵循一定的书写规则,一个书写清晰、明了的程序,有利于以后的维护。
在书写程序时,特别是对于While、for、do…while、if…else、switch…case 等语句或这些语句嵌套组合时,应采用“缩格”的书写形式。
1.2 标识符
程序中使用的用户标识符除要遵循标识符的命名规则以外,一般不要用代数符号(如a、b、x1、y1)作为变量名,应选取具有相关含义的英文单词(或缩写)或汉语拼音作为标识符,以增加程序的可读性,如:count、number1、red、work 等。
1.3 程序结构
C 语言是一种高级程序设计语言,提供了十分完备的规范化流程控制结构。因此在采用C 语言设计单片机应用系统程序时,首先要注意尽可能采用结构化的程序设计方法,这样可使整个应用系统程序结构清晰,便于调试和维护。
对于一个较大的应用程序,通常将整个程序按功能分成若干个模块,不同模块完成不同的功能。
各个模块可以分别编写,甚至还可以由不同的程序员编写,一般单个模块完成的功能较为简单,设计和调试也相对容易一些。在C 语言中,一个函数就可以认为是一个模块。
所谓程序模块化,不仅是要将整个程序划分成若干个功能模块,更重要的是,还应该注意保持各个模块之间变量的相对独立性,即保持模块的独立性,尽量少使用全局变量等。对于一些常用的功能模块,还可以封装为一个应用程序库,以便需要时可以直接调用。
但是在使用模块化时,如果将模块分成太细太小,又会导致程序的执行效率变低(进入和退出一个函数时保护和恢复寄存器占用了一些时间)。
1.4 定义常数
在程序化设计过程中,对于经常使用的一些常数,如果将它直接写到程序中去,一旦常数的数值发生变化,就必须逐个找出程序中所有的常数,并逐一进行修改,这样必然会降低程序的可维护性。因此,应尽量当采用预处理命令方式来定义常数,而且还可以避免输入错误。
1.5 减少判断语句
能够使用条件编译(ifdef)的地方就使用条件编译而不使用if 语句,有利于减少编译生成的代码的长度。
1.6 表达式
对于一个表达式中各种运算执行的优先顺序不太明确或容易混淆的地方,应当采用圆括号明确指定它们的优先顺序。一个表达式通常不能写得太复杂,如果表达式太复杂,时间久了以后,自己也不容易看得懂,不利于以后的维护。
1.7 函数
对于程序中的函数,在使用之前,应对函数的类型进行说明,对函数类型的说明必须保证它与原来定义的函数类型一致,对于没有参数和没有返回值类型的函数应加上“void”说明。如果需要缩短代码的长度,可以将程序中一些公共的程序段定义为函数。
如果需要缩短程序的执行时间,在程序调试结束后,将部分函数用宏定义来代替。注意,应该在程序调试结束后再定义宏,因为大多数编译系统在宏展开之后才会报错,这样会增加排错的难度。
1.8 尽量少用全局变量,多用局部变量
因为全局变量是放在数据存储器中,定义一个全局变量,MCU 就少一个可以利用的数据存储器空间,如果定义了太多的全局变量,会导致编译器无足够的内存可以分配;而局部变量大多定位于MCU 内部的寄存器中,在绝大多数MCU 中,使用寄存器操作速度比数据存储器快,指令也更多更灵活,有利于生成质量更高的代码,而且局部变量所能占用的寄存器和数据存储器在不同的模块中可以重复利用。
1.9 设定合适的编译程序选项
许多编译程序有几种不同的优化选项,在使用前应理解各优化选项的含义,然后选用最合适的一种优化方式。通常情况下一旦选用最高级优化,编译程序会近乎病态地追求代码优化,可能会影响程序的正确性,导致程序运行出错。
因此应熟悉所使用的编译器,应知道哪些参数在优化时会受到影响,哪些参数不会受到影响。
2 代码的优化
2.1 选择合适的算法和数据结构
应熟悉算法语言。将比较慢的顺序查找法用较快的二分查找法或乱序查找法代替,插入排序或冒泡排序法用快速排序、合并排序或根排序代替,这样可以大大提高程序执行的效率。
选择一种合适的数据结构也很重要,比如在一堆随机存放的数据中使用了大量的插入和删除指令,比使用链表要快得多。数组与指针具有十分密切的关系,一般来说指针比较灵活简洁,而数组则比较直观,容易理解。对于大部分的编译器,使用指针比使用数组生成的代码更短,执行效率更高。
但是在Keil 中则相反,使用数组比使用的指针生成的代码更短。
2.2 使用尽量小的数据类型
能够使用字符型(char)定义的变量,就不要使用整型(int)变量来定义;能够使用整型变量定义的变量就不要用长整型(long int),能不使用浮点型(float)变量就不要使用浮点型变量。
当然,在定义变量后不要超过变量的作用范围,如果超过变量的范围赋值,C 编译器并不报错,但程序运行结果却错了,而且这样的错误很难发现。
2.3 使用自加、自减指令
通常使用自加、自减指令和复合赋值表达式(如a-=1 及a+=1 等)都能够生成高质量的程序代码,编译器通常都能够生成inc 和dec 之类的指令,而使用a=a+1 或a=a-1之类的指令,有很多C 编译器都会生成2~3个字节的指令。
2.4 减少运算的强度
可以使用运算量小但功能相同的表达式替换原来复杂的的表达式。如下:
(1)求余运算
a=a%8;
可以改为:
a=a&7;
说明:位操作只需一个指令周期即可完成,而大部分的C 编译器的“%”运算均是调用子程序来完成,代码长、执行速度慢。通常,只要求是求2n 方的余数,均可使用位操作的方法来代替。
(2)平方运算
a=pow(a,2.0);
可以改为:
a=a*a;
说明:在有内置硬件乘法器的单片机中(如51 系列),乘法运算比求平方运算快得多,因为浮点数的求平方是通过调用子程序来实现的,在自带硬件乘法器的AVR 单片机中,如ATMega163 中,乘法运算只需2 个时钟周期就可以完成。
即使是在没有内置硬件乘法器的AVR单片机中,乘法运算的子程序比平方运算的子程序代码短,执行速度快。如果是求3 次方,如:
a=pow(a,3.0);
更改为:
a=a*a*a;
则效率的改善更明显。
(3)用移位实现乘除法运算
a=a*4;
b=b/4;
可以改为:
a=a<<2;
b=b>>2;
说明:通常如果需要乘以或除以2n,都可以用移位的方法代替。在ICCAVR 中,如果乘以2n,都可以生成左移的代码,而乘以其它的整数或除以任何数,均调用乘除法子程序。
用移位的方法得到代码比调用乘除法子程序生成的代码效率高。实际上,只要是乘以或除以一个整数,均可以用移位的方法得到结果,如:
a=a*9
可以改为:
a=(a<<3)+a
2.5 循环
(1)循环语对于一些不需要循环变量参加运算的任务可以把它们放到循环外面,这里的任务包括表达式、函数的调用、指针运算、数组访问等,应该将没有必要执行多次的操作全部集合在一起,放到一个init 的初始化程序中进行。
(2)延时函数 通常使用的延时函数均采用自加的形式:
两个函数的延时效果相似,但几乎所有的C 编译对后一种函数生成的代码均比前一种代码少1~3 个字节,因为几乎所有的MCU 均有为0转移的指令,采用后一种方式能够生成这类指令。在使用while 循环时也一样,使用自减指令控制循环会比使用自加指令控制循环生成的代码更少1~3 个字母。
但是在循环中有通过循环变量“i”读写数组的指令时,使用预减循环时有可能使数组超界,要引起注意。
(3)while 循环和do…while 循环 用while 循环时有以下两种循环形式:
在这两种循环中,使用do…while循环编译后生成的代码的长度短于while循环。
2.6 查表
在程序中一般不进行非常复杂的运算,如浮点数的乘除及开方等,以及一些复杂的数学模型的插补运算,对这些即消耗时间又消费资源的运算,应尽量使用查表的方式,并且将数据表置于程序存储区。
如果直接生成所需的表比较困难,也尽量在启动时先计算,然后在数据存储器中生成所需的表,后面在程序运行直接查表就可以了,减少了程序执行过程中重复计算的工作量。
2.7 其它
比如使用在线汇编及将字符串和一些常量保存在程序存储器中,均有利于优化。
3 乘除法优化
目前单片机的市场竞争很激烈,许多应用出于性价比的考虑,选择使用程序存储空间较小(如1K,2K)的小资源8位MCU芯片进行开发。一般情况下,这类MCU没有硬件乘法、除法指令,在程序必须使用乘除法运算时,如果单纯依靠编译器调用内部函数库来实现,常常会有代码量偏大、执行效率偏低的缺点。
上海晟矽微电子推出的MC30、MC32系列MCU,采用了RISC架构,在小资源8位MCU领域有广大的用户群和广泛的应用,本文就以晟矽微电的这两个系列产品的指令集为例,结合汇编与C编译平台,给大家介绍一种既省时又节约资源的乘除法算法。
3.1 乘法篇
单片机中的乘法是二进制的乘法,也就是把乘数的各个位与被乘数相乘,然后再相加得出,因为乘数和被乘数都是二进制,所以实际编程时每一步的乘法可以用移位实现。
例如:乘数R3=01101101,被乘数R4=11000101,乘积R1R0。步骤如下:
1、清空乘积R1R0;
2、乘数的第0位是1,那被乘数R4需要乘上二进制数1,也就是左移0位,加到R1R0里;
3、乘数的第1位是0,忽略;
4、乘数的第2位是1,那被乘数R4需要乘上二进制数100,也就是左移2位,加到R1R0里;
5、乘数的第3位是1,那被乘数R4需要乘上二进制数1000,也就是左移3位,加到R1R0里;
6、乘数的第4位是0,忽略;
7、乘数的第5位是1,那被乘数R4需要乘上二进制数100000,也就是左移5位,加到R1R0里;
8、乘数的第6位是1,那被乘数R4需要乘上二进制数1000000,也就是左移6位,加到R1R0里;
9、乘数的第7位是0,忽略;
10、这时候R1R0里的值就是最后的乘积,至此算法完成。
以上例子运算结果:
R1R0 = R3 * R4= (R4<<6)+(R4<<5)+(R4<<3)+(R4<<2)+R4 = 101001111100001
实际运算流程图见下图:
在实际的程序设计过程中,程序优化有两个目标,提高程序运行效率,和减少代码量。我们来看下本文提供的汇编算法和普通C语言编程的效率和代码量对比。
下表是程序运行效率的对比数据(可能会有小的偏差),很明显汇编编译出来的运行时间要比C语言减少很多。
下表是程序代码量的对比数据(可能会有小的偏差),汇编占用的程序空间也要比C语言小很多。
综上两点,本文介绍的乘法算法各方面使用情况都要比C编译好很多。如果大家在使用过程中,原有的程序不能满足应用需求,例如遇到程序空间不够或者运行时间太久等问题,都可以按照以上方式进行优化。
汇编语言最接近机器语言的。在汇编语言中可以直接操作寄存器,调整指令执行顺序。由于汇编语言直接面对硬件平台,而不同的硬件平台的指令集及指令周期均有较大差异,这样会对程序的移植和维护造成一定的不便,所以我们针对精简指令集做了乘法运算的例程,便于大家的移植和理解。
3.2 除法篇
单片机中的除法也是二进制的除法,和现实中数学的除法类似,是从被除数的高位开始,按位对除数进行相除取余的运算,得出的余数再和之后的被除数一起再进行新的相除取余的运算,直到除不尽为止,因为单片机中的除法是二进制的,每个步骤除出来的商最大只有1,所以我们实际编程时可以把每一步的除法看作减法运算。
例如:被除数R3R4=1100110001101101,除数R5=11000101,商R1R0,余数R2。步骤如下:
1、清空商R1R0,余数R2;
2、被除数放开最高位,第15位,为1,1比除数小,商为0,余数R2为1;
3、上一步余数并上被除数次高位,第14位,得11,11仍然比除数小,商为0,余数R2为11
4、直到放开第8位后,得11001100,比除数大,商得1,余数R2为111;
5、上一步余数并上被除数第7位,得1110,没有除数大,商为0,余数R2为1110;
6、上一步余数并上被除数第6位,得11101,没有除数大,商为0,余数R2为11101;
7、按照以上步骤,直到放开了被除数得第3位,得11101101,比除数大,商为1,余数R2为101000;
8、上一步余数并上被除数第2位,得1010001,没有除数大,商为0,余数R2为1010001;
9、上一步余数并上被除数第1位,得10100010,没有除数大,商为0,余数R2为10100010;
10、上一步余数并上被除数第0位,得101000101,比除数大,商为1,余数R2为10000000;
11、然后把以上所有步骤中得商从左至右依次排列就是最后的商100001001,余数为最后算得的余数10000000。
以上例子运算结果:R1R0 = R3R4 / R5 = 100001001 ;R2 = R3R4 % R5 = 10000000
实际运算流程图见下图:
除法运算的效率,代码量见以下表格
下表是程序运行效率和代码量的对比数据(可能会有小的偏差),很明显本文提供的汇编算法要优化的很多。
所以对于除法运算,本文提供的方法也是相对较优的。
以下是针对精简指令集做的除法运算,16/8位的例程,便于大家的移植和理解。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 51c嵌入式~单片机合集2

发表评论 取消回复