目录
目录
2.3fit、fit_transform、transform
2.3fit、fit_transform、transform
1.特征工程
1.1特征工程概念
对特征进行相关的处理
特征工程是将任意数据转换为可用于机器学习的数字特征,如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。
1.2特征工程的步骤
(1)特征提取, 如果不是像dataframe那样的数据,要进行特征提取,比如字典特征提取,文本特征提取
(2)无量纲化(预处理)
(3)特征降维
1.3特征工程-特征提取
稀疏矩阵
稀疏矩阵是指一个矩阵中大部分元素为零,只有少数元素是非零的矩阵。
三元组表 (Coordinate List, COO):三元组表就是一种稀疏矩阵类型数据,存储非零元素的行索引、列索引和值:
(行,列) 数据
非稀疏矩阵(稠密矩阵)
非稀疏矩阵,或称稠密矩阵,是指矩阵中非零元素的数量与总元素数量相比接近或相等。
1.3.1字典特征提取
- 创建转换器对象
sklearn.feature_extraction.DictVectorizer(sparse=True)
参数:
sparse=True返回类型为csr_matrix的稀疏矩阵
sparse=False表示返回的是数组,数组可调用.toarray()方法将稀疏矩阵转换为数组
-
转换器对象:
transfer=fit_transform(data)
转换器对象调用fit_transform(data)函数,返回转化后的矩阵或数组
- 获取特征名
transfer.get_feature_names_out()
import numpy as np
from sklearn.feature_extraction import DictVectorizer
'''
字典列表特征提取
'''
data = [{'city': '成都', 'age': 30, 'temperature': 20},
{'city': '重庆', 'age': 33, 'temperature': 60},
{'city': '北京', 'age': 42, 'temperature': 80},
{'city': '上海', 'age': 22, 'temperature': 70}, ]
# 转为稀疏矩阵
transfer = DictVectorizer(sparse=True)
date_new = transfer.fit_transform(data)
print(date_new,'\n')
# 不转成三元组的形式:toarray()
print(date_new.toarray(),'\n')
# 不转成三元组表的形式:sparse=False
transfer = DictVectorizer(sparse=False)
# 特征
print(transfer.get_feature_names_out())
date_new = transfer.fit_transform(data)
print(date_new,'\n')
1.3.2文本特征提取
-
英文文本提取
transfer = CountVectorizer(stop_words=[ ])
data = transfer.fit_transform(documents)
关键字参数stop_words,表示词的黑名单
fit_transform函数的返回值为稀疏矩阵
-
中文文本提取
下载jiaba
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
API
jieba.cut(str)
import jieba
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
def chinese_cut(text):
data = jieba.cut(text)
data_lt = list(data)
data_str = " ".join(data_lt)
return data_str
documents = [
"这是第一份文件",
"此文档是第二个文档",
"这是第三个",
"这是第一份文件吗 "
]
data_new = [chinese_cut(i) for i in documents]
transfer = CountVectorizer(stop_words=[])
data_final = transfer.fit_transform(data_new)
df = pd.DataFrame(data=data_final.toarray(),columns=transfer.get_feature_names_out())
print(df)1.3.3TF-IDF文本特征词的稀有程度特征提取
词频(Term Frequency, TF),使词数归一化
TF = 该词在文章中出现的次数 / 文章词总数
逆文档频率(Inverse Document Frequency, IDF), 反映了该词在整个文档集合中的稀有程度
IDF = lg( 文档总数 / 包含该词的文档数+1 )
包含该词的文档数+1:使分母不为0
TF-IDF=TF*IDF
- API
transfer = TfidfVectorizer(stop_words=[' '])
ti_idf = transfer.fit_transform(data_new)
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
def chinese_cut(text):
data = jieba.cut(text)
data_lt = list(data)
data_str = " ".join(data_lt)
return data_str
documents = [
"这是第一份文件",
"此文档是第二个文档",
"这是第三个",
"这是第一份文件吗 "
]
data_new = [chinese_cut(i) for i in documents]
transfer = TfidfVectorizer(stop_words=['这是'])
ti_idf = transfer.fit_transform(data_new)
df = pd.DataFrame(data=ti_idf.toarray(),columns=transfer.get_feature_names_out())
print(df)2.无量纲化
无量纲,即没有单位的数据
2.1归一化
公式
将原始数据映射到指定区间(默认为0-1)
x-xmin / xmax-xmin = y-a / b-a
原始数据的数值范围:[xmin,xmax]
指定区间:[a,b]
将原始数据x映射到指定区间的结果为:y
API
sklearn.preprocessing.MinMaxScaler(feature_range)
参数:feature_range默认=(0,1) 为归一化后的值域,可以自定义
fit_transform函数归一化的原始数据类型可以是list、DataFrame和ndarray, 不可以是稀疏矩阵
fit_transform函数的返回值为ndarray
示例
from sklearn.preprocessing import MinMaxScaler
data = [[2, 5, 4],
[6, 1, 9],
[3, 0, 7]]
transfer = MinMaxScaler(feature_range=(0, 1))
scaler_data = transfer.fit_transform(data)
print(scaler_data)缺点
最大值和最小值易受到异常点影响,所以鲁棒性较差。
2.2标准化
在机器学习中,标准化是一种数据预处理技术,也称为数据归一化或特征缩放。它的目的是将不同特征的数值范围缩放到统一的标准范围,以便更好地适应一些机器学习算法,特别是那些对输入数据的尺度敏感的算法。
公式
最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。
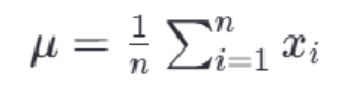
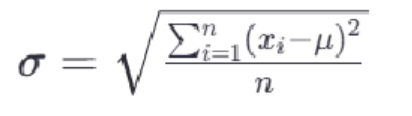
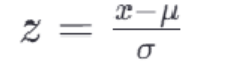
其中,z是转换后的数值,x是原始数据的值,μ是该特征的均值,σ是该特征的标准差
API
sklearn.preprocessing.StandardScale
transfer = StandardScaler()
与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray
示例
df = pd.DataFrame(
data=[[1, 2, 3, 4],
[2, 1, 3, 4],
[3, 2, 3, 4],
[4, 2, 3, 4]]
)
# 实例化一个转换器
transfer = StandardScaler()
# DataFrame进行标准化
standard_data = transfer.fit_transform(data)
print(standard_data, '\n')
# 将DF转化为list,进行标准化
df_lt = df.values.tolist()
standard_data = transfer.fit_transform(df_lt)
print(standard_data, '\n')
# 将DF转化为ndarray,进行标准化
df_arr = df.values
standard_data = transfer.fit_transform(df_arr)
print(standard_data, '\n')2.3fit、fit_transform、transform
fit、fit_transform和transform有不同的作用:
fit:
这个方法用来计算数据的统计信息,比如均值和标准差(在
StandardScaler的情况下)。
fit仅用训练集上。
transform:
这个方法使用已经通过
fit方法计算出的统计信息来转换数据。可以应用于任何数据集,包括训练集、验证集或测试集,
使用的统计信息必须来自于训练集。
fit_transform:
这个方法相当于先调用
fit再调用transform,但是它在内部执行得更高效。仅在训练集上使用
一旦scaler对象在X_train使用fit(),就已经得到统计信息。对于测试集X_test,只需要使用transform方法,因为我们不希望在测试集上重新计算任何统计信息,也不希望测试集的信息影响到训练过程。如果我们对X_test也使用fit_transform,测试集的信息就可能会影响到训练过程。
总结来说:常常是先fit(x_train)然后再transform(x_text)
3.特征降维
目的:降低数据集的维度,保留重要信息。
特征降维的好处:
减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
特征降维的方式:
-
特征选择
-
从原始特征集中挑选出最相关的特征
-
-
主成份分析(PCA)
-
主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
-
3.1特征选择
3.1.1低方差过滤特征选择
from sklearn.feature_selection import VarianceThreshold
transfer = VarianceThreshold(threshold)
from sklearn.feature_selection import VarianceThreshold
df = pd.DataFrame(
data=[[1, 2, 5, 4],
[2, 1, 3, 6],
[3, 2, 3, 4],
[4, 2, 3, 4]],
columns=['f1', 'f2', 'f3', 'f4']
)
# 定义一个低方差过滤器
transfer = VarianceThreshold(threshold=0.6)
vt_data = transfer.fit_transform(df)
print(vt_data)3.1.2相关系数特征选择
from scipy.stats import pearsonr
statistic,pvalue=pearsonr(data[" "], data[" "])
from scipy.stats import pearsonr
df = pd.DataFrame(
data=[[1, -2, 5, 4],
[2, -1, 3, 6],
[3, -2, 3, 4],
[4, -2, 3, 4]],
columns =['f1','f2','f3','f4']
)
r1 = pearsonr(df['f1'],df['f2'])
# 相关性
print(r1.statistic)#皮尔逊相关系数
print(r1.pvalue)#零假设,为非负数,越小越相关
3.2主成份分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
API
from sklearn.decomposition import PCA
transfer=PCA(n_components=None)
参数:
n_components:
实参为小数:表示降维后保留百分之多少的信息
实参为整数:表示减少到多少特征
from sklearn.decomposition import PCA
import numpy as np
data =np.random.rand(3,4)
# print(data)
transfer = PCA(n_components=2)
data_new = transfer.fit_transform(data)
print(data_new)from sklearn.decomposition import PCA
import numpy as np
data =np.random.rand(3,4)
# print(data)
transfer = PCA(n_components=0.8)
data_new = transfer.fit_transform(data)
print(data_new)本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习基础02

发表评论 取消回复