案例背景
杭州是真没啥美食呀.....但是 总是还是有好吃的店家,于是就发挥专业长处,进行一下分析,看看杭帮菜的一些特点。。例如看看品种分布啊,类型分布啊,行政区的分布啊,店铺评分的一些分布啊,一些推荐菜的特点呀,平均消费价格呀等等。
数据介绍
本次数据来自美团爬虫所有杭州地区的店家他们的评分,城市行政区经纬度,店铺评分,推荐菜,地理位置链接,平均消费营业时间等。

下面就对这些数据进行预处理,然后进行一些可视化的分析。
这个案例还是很适合学习做数据分析或者是做一些作业展示的。需要本次案例的全部数据文件和代码的同学还是可以参考:杭帮菜分析
代码实现
首先还是读导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
plt.rcParams ['font.sans-serif'] ='SimHei' #显示中文
plt.rcParams ['axes.unicode_minus']=False #显示负号读取数据
df=pd.read_excel('本帮浙江菜.xlsx').iloc[:,:-3]
df.head(3)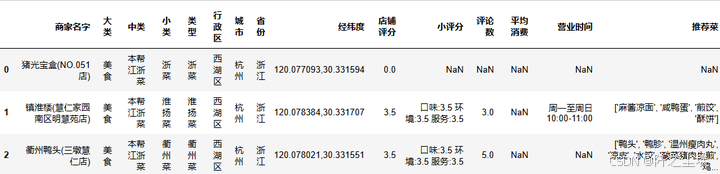
后面那些地址链接我感觉没啥用,就没有读取进来。
数据清洗,构建特征
可以看到小评分里面是口味,环境和服务三个选项,那么我们都得把它单独提取出来。
提取小评分
def extract_scores(text):
scores = text.split()
if len(scores) == 3:
try:
taste = float(scores[0].split(":")[1])
environment = float(scores[1].split(":")[1])
service = float(scores[2].split(":")[1])
return taste, environment, service
except ValueError:
return None, None, None
else:
return None, None, None
df[['口味', '环境', '服务']] =df['小评分'].fillna('口味:0.0 环境:0.0 服务:0.0').apply(extract_scores).apply(pd.Series).replace(0, np.nan)营业时是一个文本字符串儿,我们得单独把它的时间提取出来。
提取时间
def extract_times(time_range):
if time_range:
pattern = r'(\d{2}:\d{2})-(\d{2}:\d{2})'
matches = re.findall(pattern, time_range)
if matches:
start_time = matches[0][0]
end_time = matches[-1][1]
return start_time, end_time
else:
return np.nan, np.nan
else:
return np.nan, np.nan
def time_to_decimal(time_str):
if pd.isna(time_str): # 检查是否为 np.nan
return np.nan
hour, minute = map(int, time_str.split(':'))
decimal_time = hour + minute / 60
return decimal_time
time_to_decimal(extract_times('周一至周日 10:00-11:00')[0])提取函数自定义好了之后,我们要把开始时间和结束时间变成时间类型的格式
df[['开始时间','结束时间']]=df['营业时间'].astype('str').apply(extract_times).apply(pd.Series).replace('00:00','24:00')
df['开始时间'] = df['开始时间'].apply(time_to_decimal)
df['结束时间'] = df['结束时间'].apply(time_to_decimal)## 归一下类别,有的类别是差不多的意思,但是文本不一样,我们给他整合一下。
df['类型']=df['类型'].astype('str').replace('本帮江浙菜','浙菜').replace('苏帮菜','苏浙菜').replace('南京菜','苏浙菜').replace('无锡菜','苏浙菜')然后查看一下分布
df['类型'].value_counts()
可以看到杭州的这些店家,基本上还是浙江菜比较多,然后是衢州菜,再是苏浙菜,然后是一些其他类似周边的江浙沪的一些菜系。
下面我们将评分变成标签,也就是根据不同的分数单位给这个店评上一些星级。
### 评分分级
bins = [2.5, 3.0, 3.5, 4.0, 4.5, 5.0]
labels = ['准三星店铺', '三星店铺', '准四星店铺', '四星店铺', '准五星店铺']
# 将评分分箱并计算每个箱子中的数量
df['店铺等级'] = pd.cut(df['店铺评分'], bins=bins, labels=labels)
查看分布
df['店铺等级'].value_counts()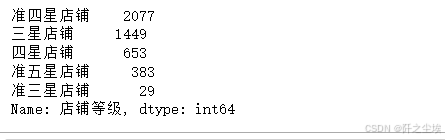
差不多清洗完了,下面我们进行整合,对数据进行处理,选取需要的特征
df=df[['商家名字','行政区','类型', '开始时间', '结束时间','评论数','店铺等级','店铺评分', '平均消费','口味', '环境', '服务', '推荐菜']]
df.head()
### 将有店铺评分的店分开,因为有的店铺可能是刚开店或者是爬取的时候有缺失,他是没有评分的,所以我们将它分开
df1=df[df['店铺评分']!=0]
df1.head()
好了,清洗整理完成!!!最多的是什么下面就开始进行可视化分析了。
可视化数据分析
简单描述性统计看看:
df.describe()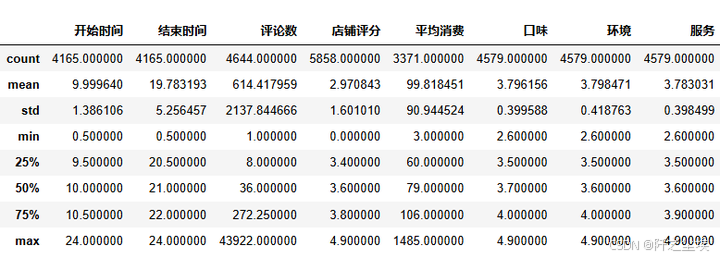
我们按照下面这个思路来进行可视化的画图:
-
1.单变量:区域,类型,营业时间,评论数量,消费,评分,星级,推荐菜的词云图,店铺名称词云图
-
2.分组聚合:星级——(评论数量,消费,三个小评分)
-
3.分组聚合:地区——(评论数量,消费,评分)
-
4.多变量:(人均消费和评分,人均消费和评论数量) (热力图)
-
5.类别散点图:星级——(评论数量,消费,三个小评分)
单变量
不同行政区
首先查看不同行政区的店铺数量
### 区分布
p1=df['行政区'].value_counts()
plt.figure(figsize = (6,3),dpi=128)
sns.barplot(x=p1.index,y=p1)
plt.ylabel('数量')
plt.xlabel('行政区')
plt.xticks(fontsize=9,rotation=45)
plt.title("不同行政区的店铺数量")
plt.show()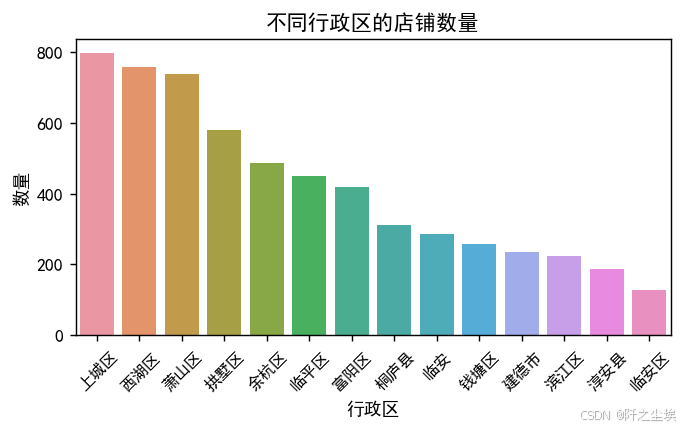
还可以画这种树图
import squarify
fig = plt.figure(figsize = (6,4),dpi=128)
ax = fig.add_subplot(111)
plot = squarify.plot(sizes = p1, # 方块面积大小
label = p1.index, # 指定标签
#color = colors, # 指定自定义颜色
alpha = 0.8, # 指定透明度
value = p1, # 添加数值标签
edgecolor = 'white', # 设置边界框
linewidth =0.1 # 设置边框宽度
)
# 设置标题大小
ax.set_title('不同行政区的店铺数量',fontsize = 18)
# 去除坐标轴
ax.axis('off')
# 去除上边框和右边框刻度
ax.tick_params(top = 'off', right = 'off')
# 显示图形
plt.show()
可以看到在上城区,西湖区,萧山区的店铺数量是比较多的,其次是临平富阳拱墅跟余杭剩下的一些区,美食店铺较少。
菜的类型
p2=df['类型'].value_counts()
plt.figure(figsize = (5,3),dpi=128)
sns.barplot(x=p2.index,y=p2)
plt.ylabel('数量')
plt.xlabel('菜色类型')
plt.xticks(fontsize=9,rotation=45)
plt.title("不同菜色类型的店铺数量")
plt.show()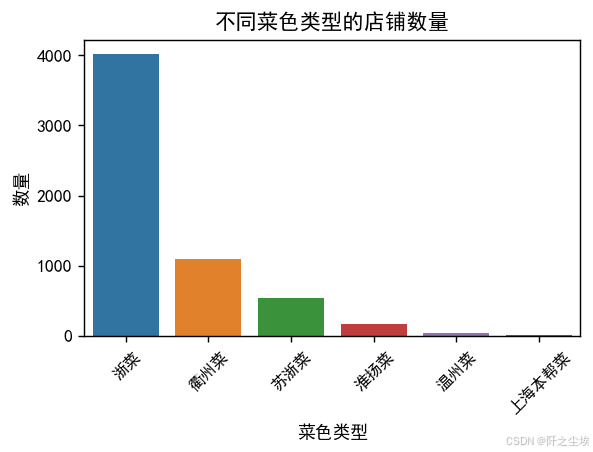
import squarify
fig = plt.figure(figsize = (6,4),dpi=128)
ax = fig.add_subplot(111)
plot = squarify.plot(sizes = p2, # 方块面积大小
label = p2.index, # 指定标签
#color = colors, # 指定自定义颜色
alpha = 0.8, # 指定透明度
value = p2, # 添加数值标签
edgecolor = 'white', # 设置边界框
linewidth =0.1 # 设置边框宽度
)
# 设置标题大小
ax.set_title('不同菜色类型的店铺数量',fontsize = 18)
# 去除坐标轴
ax.axis('off')
# 去除上边框和右边框刻度
ax.tick_params(top = 'off', right = 'off')
# 显示图形
plt.show()
可以看到杭州地区还是杭邦菜多All我觉得那个goI want选择什么?好有特色。,其次是衢州菜,剩下是一些苏浙旁边的一些菜系。
营业时间
### 营业时间
plt.figure(figsize=(8, 3),dpi=128)
plt.subplot(1, 2, 1)
sns.histplot(df['开始时间'], kde=True, color='skyblue', bins=24)
plt.title('店铺开始营业时间')
plt.subplot(1, 2, 2)
sns.histplot(df['结束时间'], kde=True, color='salmon', bins=24)
plt.title('店铺结束营业时间')
# 显示图形
plt.tight_layout()
plt.show()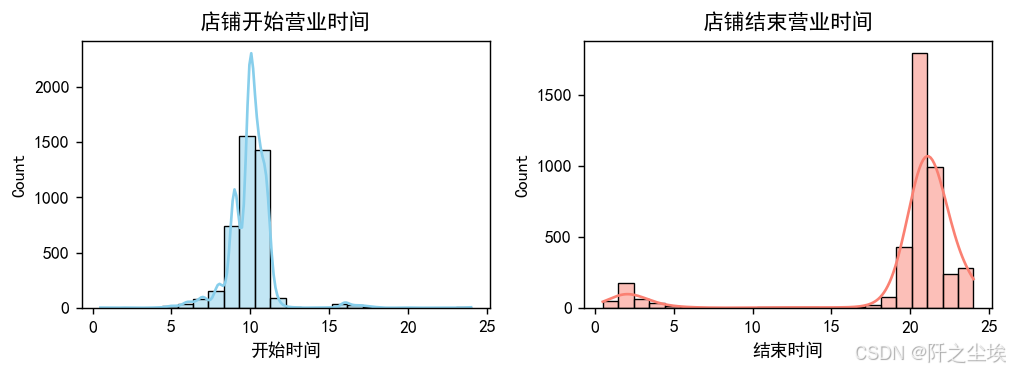
可以看到绝大多数店铺他们的营业时间都是在早上10点左右,他们的结束时间都是在晚上9点左右。
评论数量
我们来查看一下这么多店家他们的评论数量的一个分布。
plt.figure(figsize=(5, 3),dpi=128)
sns.boxplot(df['评论数'], color='skyblue')
plt.title('评论数量')
plt.show()
极大值太多了,分布很不均匀,分箱查看一下:
# 对评论数进行分箱并计算每个箱子中的观测数量
pd.cut(df['评论数'],range(0, 45001, 5000)).value_counts().sort_index().reset_index().set_axis(['评论数量的区间','店铺数量'],axis='columns')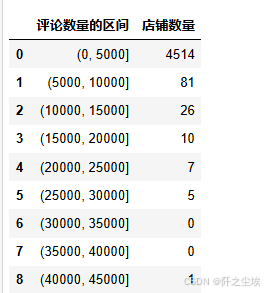
我们可以看到绝大多数的店铺的评论都是在0~5000条左右,有一个极端的店铺在4万条以上的评论。
#查看这个4w条评论以上最受欢迎的店是谁
df[df['评论数']>40000]
emm,没吃过,可能是一个比较大的酒店吧。
店铺的等级
### 店铺的等级
p3=df['店铺等级'].value_counts()
plt.figure(figsize = (5,3),dpi=128)
sns.barplot(x=p3.index,y=p3,)
plt.ylabel('数量')
plt.xlabel('星级')
plt.xticks(fontsize=9,rotation=45)
plt.title("不同星级店铺数量")
plt.show()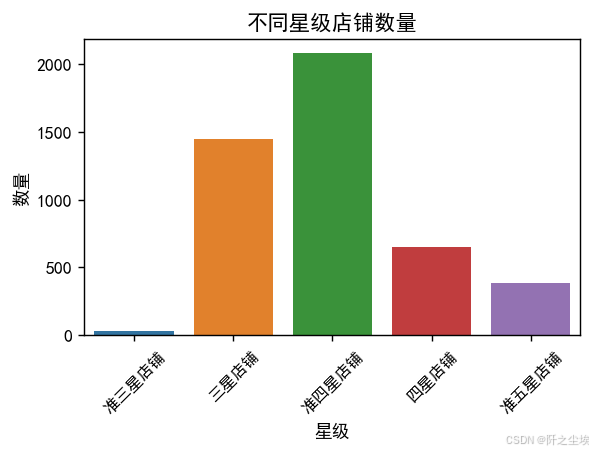
我们可以看到美团上这么多的店家,大概准四星店铺是较多的,其次就是三星店铺和四星店铺。评分比较差的准三星店铺和评分较高的准五星店铺数量较少。
上面是柱状图,我们还可以变成百分比。画了百分比饼图。
plt.figure(figsize=(4,4),dpi=128)
colors=['tomato','orange','royalblue','lime','pink','brown']
plt.pie(p3,labels=p3.index,autopct="%1.3f%%",shadow=True,colors=colors) #带阴影,某一块里中心的距离
#plt.title("不同星级店铺")
plt.show()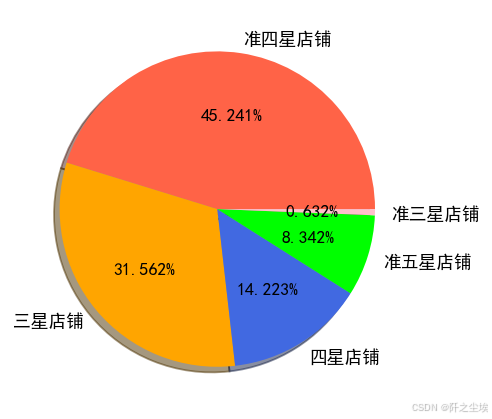
得到的结论和上面类似。
店铺评分
我们还可以对店铺评分画一个直方图
### 对应的评分的
plt.figure(figsize=(8, 3),dpi=128)
plt.subplot(1, 2, 1)
sns.histplot(df1['店铺评分'], kde=True, color='skyblue', bins=30)
plt.title('店铺评分分布')
plt.show()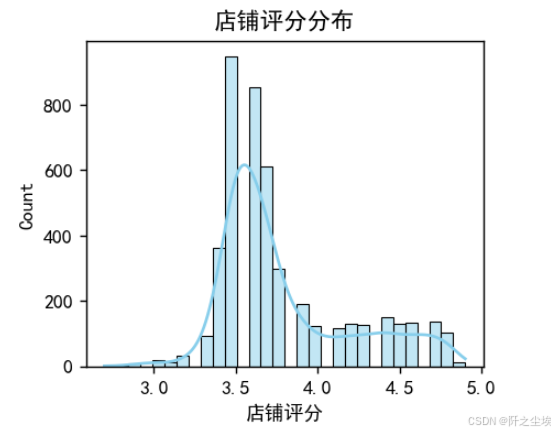
#3.5左右评分的店最多。
三个小评分
三个小评分也画图看看。
### 营业时间
plt.figure(figsize=(10, 3),dpi=128)
plt.subplot(1, 3, 1)
sns.histplot(df['口味'], kde=True, color='skyblue', bins=20)
plt.title('口味')
plt.subplot(1, 3, 2)
sns.histplot(df['环境'], kde=True, color='yellow', bins=20)
plt.title('环境')
plt.subplot(1, 3, 3)
sns.histplot(df['服务'], kde=True, color='springgreen', bins=20)
plt.title('服务')
# 显示图形
plt.tight_layout()
plt.show()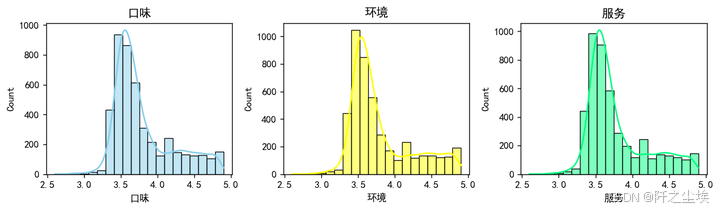
感觉分布类似,同样的店家,可能可为环境服务的评分都是差不多的。
平均消费箱线图
### 平均消费箱线图
plt.figure(figsize=(8, 3),dpi=128)
plt.subplot(1, 2, 1)
sns.histplot(df1['平均消费'], kde=True, color='tomato', bins=40)
plt.title('店铺平均消费的分布')
plt.show()
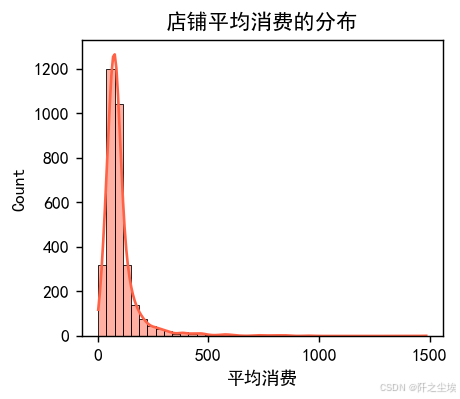
大部分都在100附近,也就是人均大概消费一百块左右,存在很多店铺有极大值,分箱看看。
pd.cut(df['平均消费'],range(0,1001,100)).value_counts().sort_index().reset_index().set_axis(['平均消费的区间','店铺数量'],axis='columns')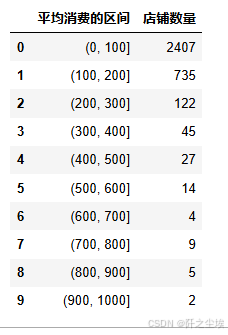
可以看到还是有很多店铺人均消费特别高的,有两个店铺人均消费甚至达到了900以上,太夸张了,吃不起。
店铺名称词云图
先把店铺名称字符串联合,然后再进行结巴分词。画出词云图。
#定义随机生成颜色函数
def randomcolor():
colorArr = ['1','2','3','4','5','6','7','8','9','A','B','C','D','E','F']
color ="#"+''.join([random.choice(colorArr) for i in range(6)])
return color
import jieba,random
from collections import Counter
from wordcloud import WordCloud
from PIL import Image
all_titles = ' '.join(df['商家名字'])
# Word segmentation
seg_list = jieba.cut(all_titles, cut_all=False)
seg_text = ' '.join(seg_list)
#对分词文本做高频词统计
word_counts = Counter(seg_text.split())
word_counts_updated=word_counts.most_common()
#过滤标点符号
non_chinese_pattern = re.compile(r'[^\u4e00-\u9fa5]')
# 过滤掉非中文字符的词汇
filtered_word_counts_regex = [item for item in word_counts_updated if not non_chinese_pattern.match(item[0])]
filtered_word_counts_regex[:5]
# Generate word cloud
from matplotlib import colors
mask = np.array(Image.open('c1.png'))
wordcloud = WordCloud(font_path='simhei.ttf', background_color='white', mask = mask,#colormap=colors.ListedColormap([randomcolor() for i in range(20)]),
max_words=100, # Limits the number of words to 100
max_font_size=40)
wordcloud = wordcloud.generate_from_frequencies(dict(filtered_word_counts_regex))
# Display the word cloud
plt.figure(figsize=(8,5),dpi=256)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
可以看到既然是餐馆,酒店,饭店嘛,那么他们店铺名称词频高的肯定还是饭店这些,还有一些餐厅江南饮食风味之类的。但是衢州这个词居然出现频率也很高,说明杭州市区里面的衢州菜真的挺多的。
推荐菜的统计
每家都有各自的推荐菜,我们把所有店铺的推荐菜合并到一个列表,然后统计每种菜出现的次数。
nested_list =df['推荐菜'].to_list()
flat_list = []
for sublist in nested_list:
# 检查当前元素是否为字符串类型且不为空
if isinstance(sublist, str) and sublist != 'nan':
# 使用eval函数将字符串转换为列表,并将其中的元素逐个添加到大列表中
flat_list.extend(eval(sublist))
print(len(flat_list))画出柱状图
p4=pd.Series(flat_list).value_counts()[:20]
plt.figure(figsize=(8,6),dpi=128)
sns.barplot(y=p4.index,x=p4,orient="h")
plt.xlabel('数量')
plt.ylabel('推荐菜')
plt.xticks(fontsize=10,rotation=45)
plt.title("推荐菜前20的数量")
plt.show()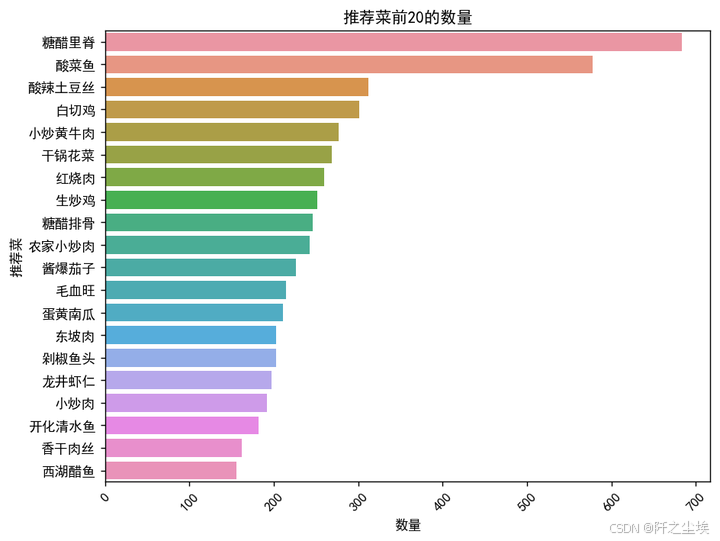
可以看到推荐菜最多的是糖醋里脊跟酸菜鱼。遥遥领先,也就是说杭州很多家店铺基本上他们的招牌推荐菜都是这些菜,剩下的什么白切鸡,小炒黄牛肉,糖醋排骨都是一些很常见的江南的家常菜。
画出词云图
mask = np.array(Image.open('c2.png'))
wordcloud = WordCloud(font_path='simhei.ttf', background_color='white', mask = mask,colormap=colors.ListedColormap([randomcolor() for i in range(20)]),
max_words=100, # Limits the number of words to 100
max_font_size=40) #.generate(seg_text) #文本可以直接生成,但是不好看
wordcloud = wordcloud.generate_from_frequencies(dict(pd.Series(flat_list).value_counts()))
# Display the word cloud
plt.figure(figsize=(10,8),dpi=256)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
出现次数越多,这个词就越大,因此从这个图可以很清楚的看到受欢迎的是哪些菜。
单个变量的分析到这里就结束了,下面我们进行一些分组聚合评价可视化。
分组聚合 星级
我们对不同店铺等级进行一个分组,然后去聚合其他的变量,看一看分布情况进行对比。
df.groupby(['店铺等级'])[['评论数','平均消费','口味','环境','服务']].describe().T#.mean()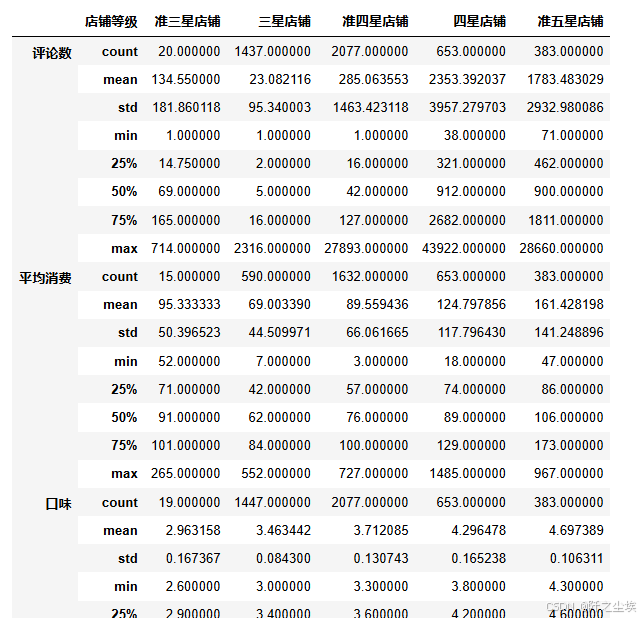
可以看到不同星级的店家,他们的评论数量,平均消费口味等等变量的一个统计情况,当然看表格还是不直观,我们下面还是进行一些可视化。
(df.groupby(['店铺等级'])[['评论数','平均消费','店铺评分']].mean().sort_values('店铺评分',ascending=False).style#.background_gradient(text_color_threshold=0.5)
.bar(color='#5CADAD')
)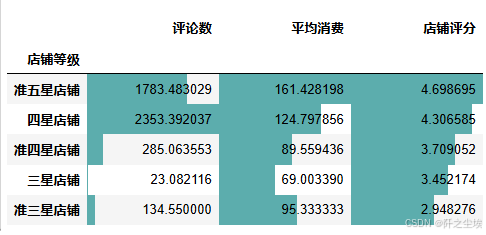
四星店铺的平均评论数量最多,准五星的消费最多。
我们画出他们对应的小提琴图
columns=['评论数','平均消费']#,'口味','环境','服务']
fig = plt.figure(figsize=(12,4), dpi=256) # 指定绘图对象宽度和高度
for i in range(2):
plt.subplot(1,2, i + 1) # 2行3列子图
ax = sns.violinplot(x='店铺等级',y=columns[i],width=0.8,saturation=0.9,lw=0.8,palette="Set2",orient="v",inner="box",data=df)
#plt.xlabel((['客户群' + str(i) for i in range(5)]),fontsize=20)
plt.ylabel(columns[i], fontsize=14)
plt.show()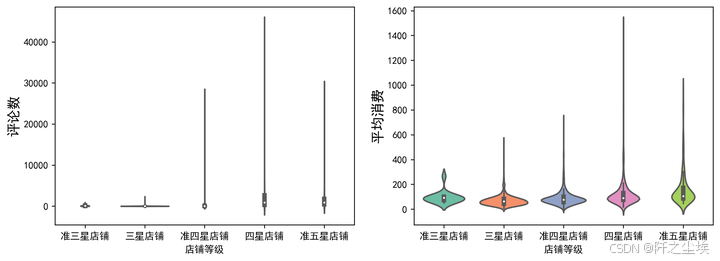
从这张图可以看到不同店家他们的评论数量跟平均消费数量的一个分布,当然由于这里的分布很极端,所以可能图标展示的不是很明显。反正整体上而言,四星店铺跟准五星店铺的消费还是高于一些其他的店铺的。
评论数量极大值很多,平均消费从均值来看是店铺星级越高消费越高,而且分布越分散,方差越大(极大值很多)
我们还可以看不同星级的店铺,他们的口味,环境,服务三个小评分的情况。
columns=['口味','环境','服务']
fig = plt.figure(figsize=(16,4), dpi=256) # 指定绘图对象宽度和高度
for i in range(3):
plt.subplot(1,3, i + 1) # 2行3列子图
ax = sns.violinplot(x='店铺等级',y=columns[i],width=0.8,saturation=0.9,lw=0.8,palette="Set2",orient="v",inner="box",data=df)
#plt.xlabel((['客户群' + str(i) for i in range(5)]),fontsize=20)
plt.ylabel(columns[i], fontsize=12)
plt.tight_layout()
plt.show()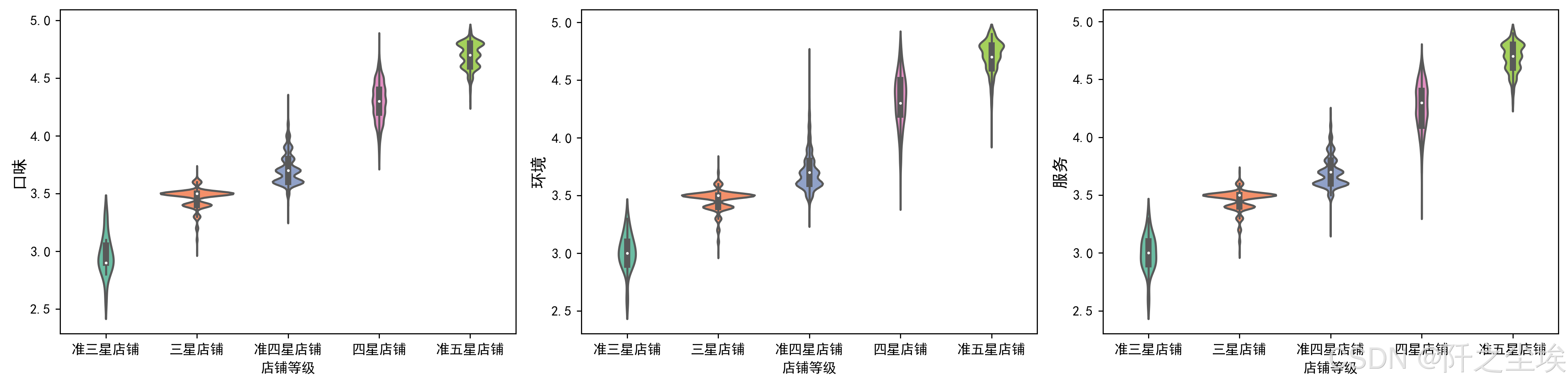
三个小评分分布差不多,都是店铺星级越高,小评分越高。
分组聚合 地区
对不同地区去进行一个分组,然后对比他们的一些评论,消费,评分等等情况。
df.groupby(['行政区'])[['评论数','平均消费','店铺评分']].describe().T#.mean()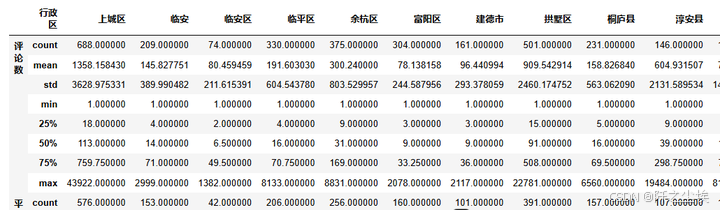
还是一样的,表格不直观,我们进行一些可视化。
(df.groupby(['行政区'])[['评论数','平均消费','店铺评分']].mean().style#.background_gradient(text_color_threshold=0.5)
.background_gradient(subset=['评论数'], cmap='Blues') # 指定色系
.background_gradient(subset=['平均消费'], cmap='pink') # 指定色系
.background_gradient(subset=['店铺评分'], cmap='YlGn') # 指定色系
)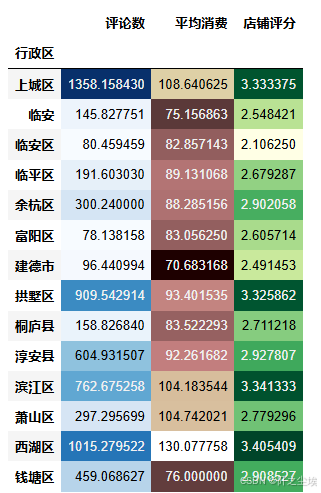
从这里我们就可以清楚地看出上城区的店铺他们的评论数量是较多的,平均消费也是最高的。店铺评分是西湖区的店铺平均评分最高。临安区的店铺评分最低。富阳区的评论数量是最少的。临安区的平均消费是最低的。
当然这样没排序不太好看,我们下面排序一下再来进行可视化。
再来看不同地区的评论数量平均消费店铺评分进行排序。
(df.groupby(['行政区'])[['评论数','平均消费','店铺评分']].mean().sort_values('店铺评分',ascending=False).style#.background_gradient(text_color_threshold=0.5)
.bar(color='tomato')
)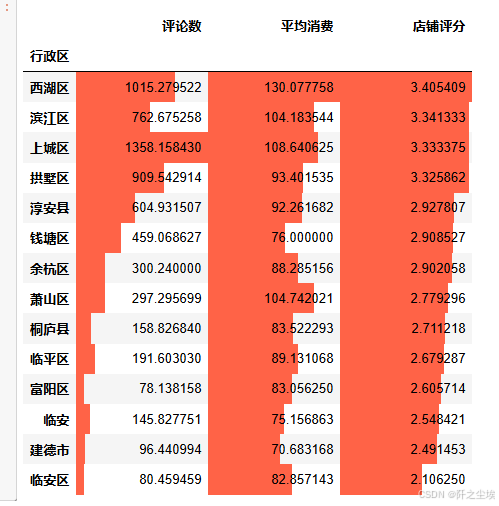
和我上面得到的结论一致。
西湖区,滨江区,上城区,拱墅区 四个区的评分较高 西湖区,滨江区,上城区,萧山区,的平均消费较高 西湖区,上城区,拱墅区 的评论数量较多。
上面只展示了均值,我们下面要展示完整的分布,就得画一些箱线图。
columns = ['评论数', '平均消费']
fig = plt.figure(figsize=(8, 6), dpi=256)
for i in range(2):
plt.subplot(2, 1, i + 1)
ax = sns.boxplot(x='行政区', y=columns[i], width=0.8, saturation=0.9, linewidth=0.8, palette="Set2", orient="v", data=df)
plt.ylabel(columns[i], fontsize=14)
plt.tight_layout()
plt.show()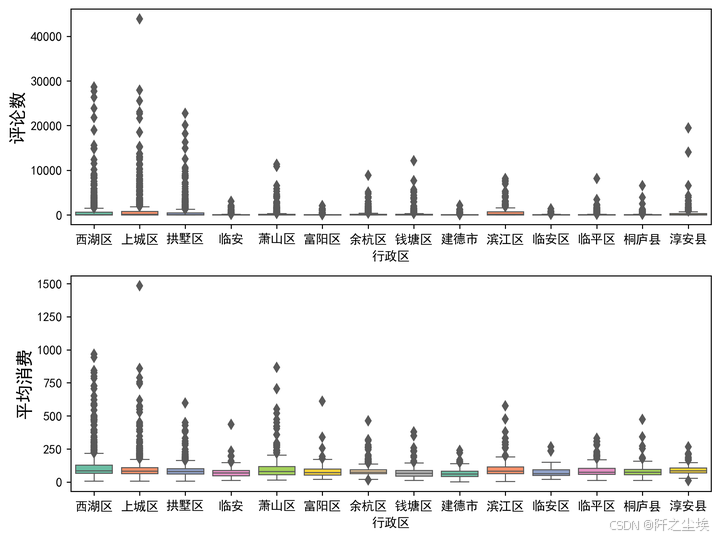
由于有很多极大值,所以说这个箱体被压的比较扁平。可能也不太好进行对比。
分组聚合分析到这里,我们下面来进行一些多变量的分析
多变量
首先肯定是数值型变量的一个相关性热力图。
correlation_matrix = df.corr()
plt.figure(figsize=(7, 7),dpi=128)
sns.heatmap(correlation_matrix, annot=True, fmt=".2f")
# 显示图表
plt.show()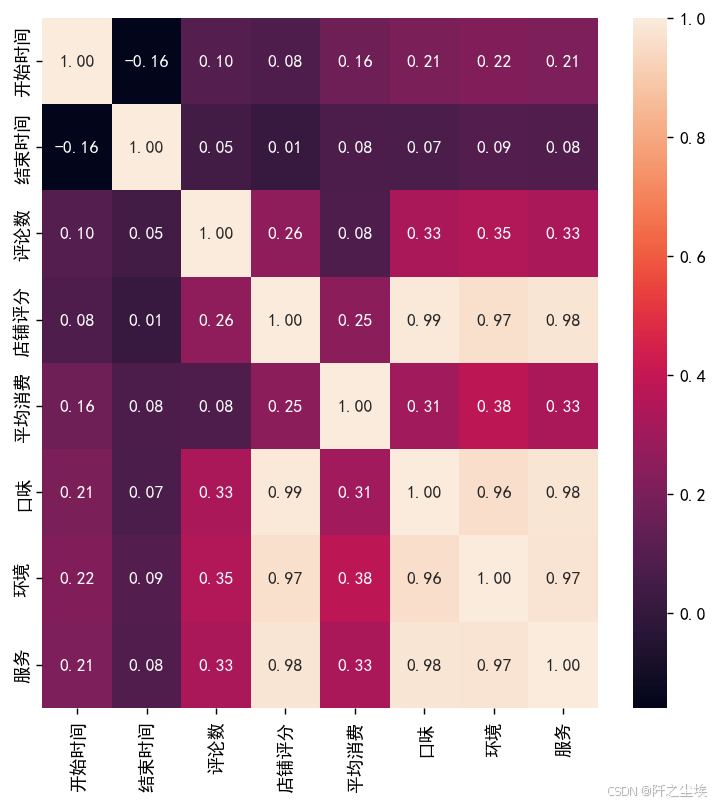
-
可以看到三个小评分和店铺总评分是高度相关的
-
平均消费和环境相关性最高
-
评论数量和平均消费与三个小评分有中等的相关性
-
评论数量和平均消费没啥相关性
-
店铺评分和评论数量还有平均消费相关性都只有0.25左右,不是很大。
然后再画平均消费跟店铺评分的六边形箱体图六边形箱体图。
plt.figure(figsize=(8,6),dpi=256)
sns.jointplot(data=df1, x="平均消费", y="店铺评分", kind='hex')
plt.show()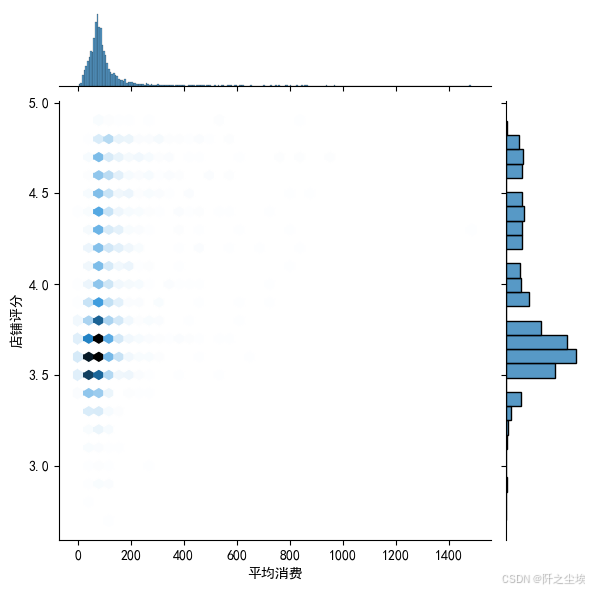
然后是平均消费跟评论数的六边形箱体图。
plt.figure(figsize=(8,6),dpi=256)
sns.jointplot(data=df1, x="平均消费", y="评论数", kind='hex')
plt.show()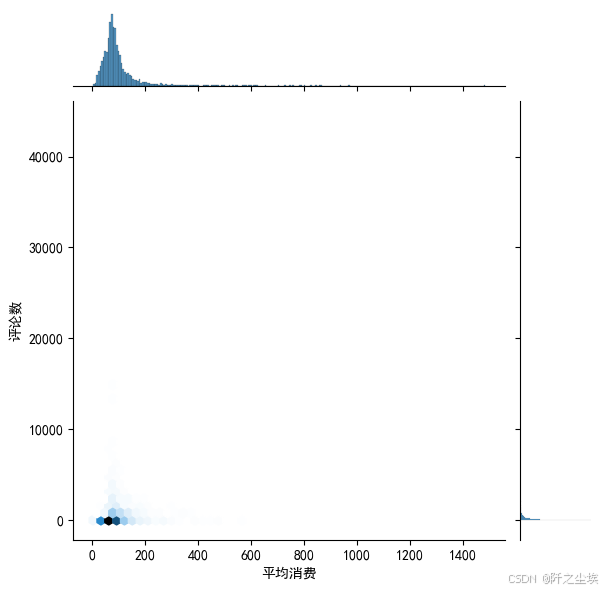
变量存在很多极大值,看起来效果不是很好,换成散点图
plt.figure(figsize=(6,4),dpi=128)
sns.scatterplot(data=df1, y="平均消费", x="店铺评分")
plt.show()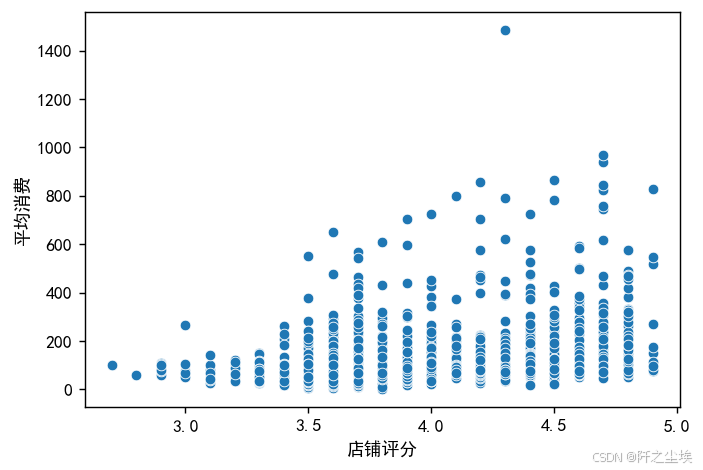
店铺评分平均消费相关性不是很大,但整体而言一般是评分较高的店铺消费会偏高一点
下面是评论数跟店铺评分散点图
plt.figure(figsize=(6,4),dpi=128)
sns.scatterplot(data=df1, y="评论数", x="店铺评分")
plt.show()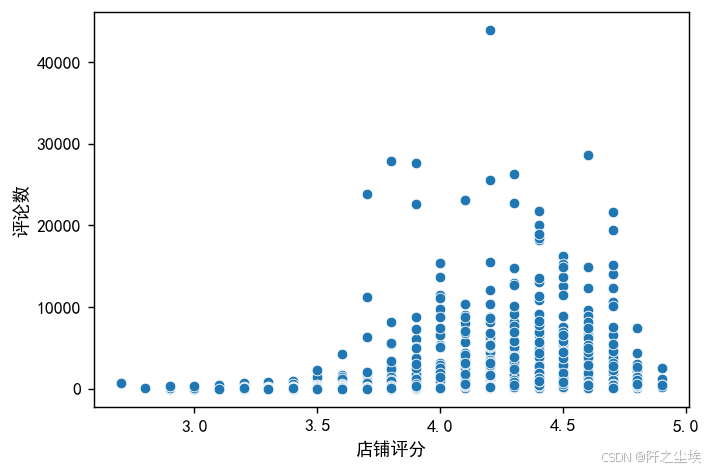
可以看到也是类似的,大体上店铺评分较高的店铺,他们的评论数量也就会越多。
还有是平均消费跟评论数量
plt.figure(figsize=(6,4),dpi=128)
sns.scatterplot(data=df1, y="平均消费", x="评论数")
plt.show()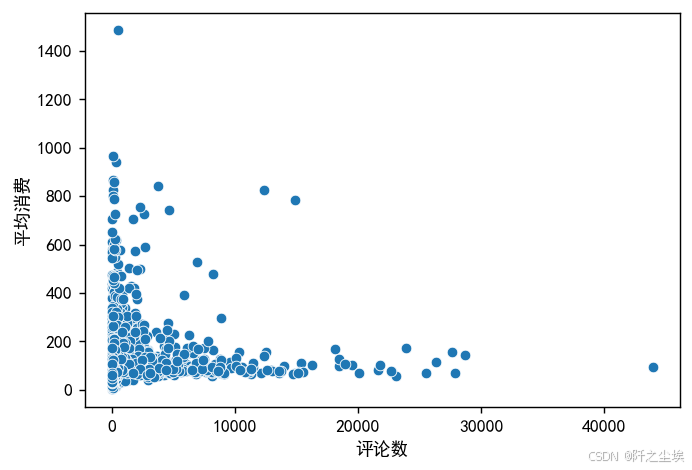
这两个就没有太多的明显的线性关系了。
类别散点图
我们的店铺等级是不同的类别,那么这些不同类别的情况下,所有的变量两两之间的一个分布,我们可以画一个整体的散点图来进行观察。
sns.pairplot(df1[['评论数', '平均消费','口味','环境','服务','店铺等级']], diag_kind='kde', hue='店铺等级')
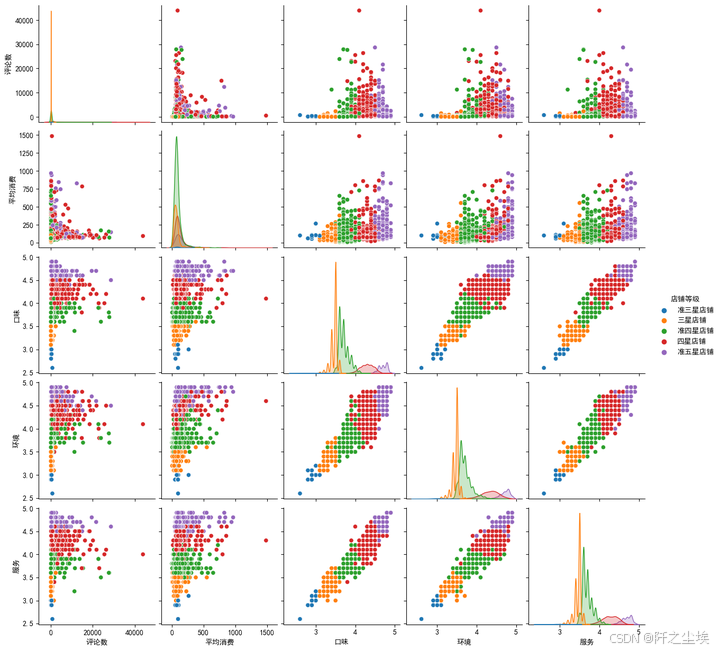
还有三个小评分和店铺等级的关系
sns.pairplot(df1[['口味','环境','服务','店铺等级']], diag_kind='hist', hue='店铺等级',kind='reg')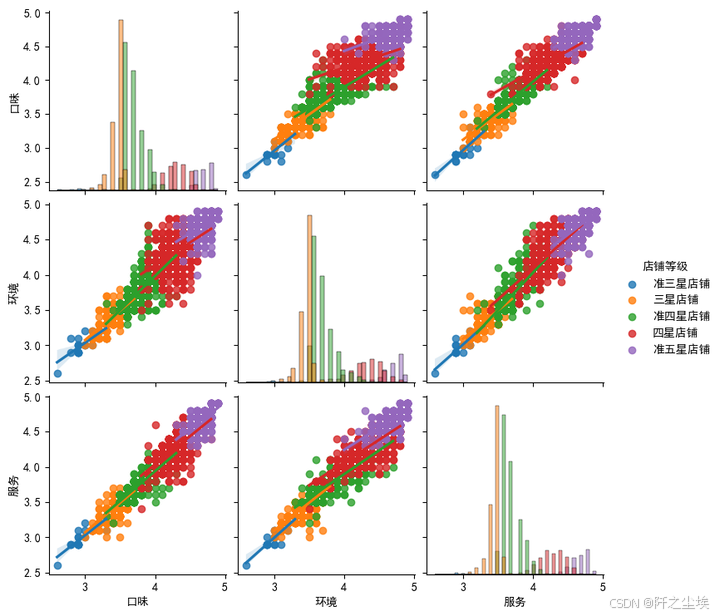
还是和前面结论一样,三个小评分和店铺等级高度相关,评论数量和平均消费和店铺等级相关性不大。
本案例得到什么结论倒是次要的,主要是画图的一些方法,怎么对数据进行一些预处理,然后画单变量的图,多变量的图,分组聚合的图,这些都是需要有一定的思维和代码技巧的。很适合有一定pandas基础的同学学习数据的可视化。
需要本次案例的全部数据文件和代码的同学还是可以参考:杭帮菜分析
以前的数据分析案例文章可以参考:python数据分析案例
创作不易,看官觉得写得还不错的话点个关注和赞吧,本人会持续更新python数据分析领域的代码文章~(需要定制类似代码可私信)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python数据分析案例64——杭帮菜美食探索数据分析可视化

发表评论 取消回复