介绍:
Redis Cluster通过分片(sharding)来实现数据的分布式存储,每个master节点都负责一部分数据槽(slot)。
当一个master节点出现故障时,Redis Cluster能够自动将故障节点的数据槽转移到其他健康的master节点上,从而保证集群的可用性和数据的完整性。
为了实现故障转移,Redis Cluster需要至少3个master节点。这是因为在选举新的master节点时,需要超过半数的master节点同意才能成功。如果只有两个master节点,当一个节点出现故障时,就无法满足选举新master节点的条件。
本方案采用StatefulSet进行redis的部署。它为了解决有状态服务的问题,它所管理的Pod拥有固定的Pod名称,启停顺序。在Deployment中,与之对应的服务是service,而在StatefulSet中与之对应的headless service,headless service,即无头服务,与service的区别就是它没有Cluster IP,解析它的名称时将返回该Headless Service对应的全部Pod的Endpoint列表。
如果在k8s上搭建Redis sentinel,当master节点宕机后,sentinel选择新的节点当主节点,当原master恢复后,此时无法再次成为集群节点。因为在物理机上部署时,sentinel探测以及更改配置文件都是以IP的形式,集群复制也是以IP的形式,但是在容器中,虽然采用的StatefulSet的Headless Service来建立的主从,但是主从建立后,master、slave、sentinel记录还是解析后的IP,但是pod的IP每次重启都会改变,所有sentinel无法识别宕机后又重新启动的master节点,所以一直无法加入集群,虽然可以通过固定pod IP或者使用NodePort的方式来固定,或者通过sentinel获取当前master的IP来修改配置文件。 sentinel实现的是高可用Redis主从,检测Redis Master的状态,进行主从切换等操作,但是在k8s中,无论是dc或者ss,都会保证pod以期望的值进行运行,再加上k8s自带的活性检测,当端口不可用或者服务不可用时会自动重启pod或者pod的中的服务,所以当在k8s中建立了Redis主从同步后,相当于已经成为了高可用状态,并且sentinel进行主从切换的时间不一定有k8s重建pod的时间快。
yaml配置
vim一个配置文件redis-cluster.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-cluster-conf
namespace: cspy-test
data:
redis.conf: |
appendonly yes
cluster-enabled yes
cluster-config-file /var/lib/redis/nodes.conf
cluster-node-timeout 5000
dir /var/lib/redis
port 6379
---
#Headless service是StatefulSet实现稳定网络标识的基础
apiVersion: v1
kind: Service
metadata:
name: redis-cluster-service
namespace: cspy-test
labels:
app: redis-cluster
spec:
ports:
- name: redis-cluster-port
port: 6379
clusterIP: None
selector:
app: redis-cluster
---
#通过StatefulSet创建6个redis的pod ,实现3主3从的redis集群
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster-app
namespace: cspy-test
spec:
serviceName: "redis-cluster-service"
replicas: 6
selector:
matchLabels:
app: redis-cluster
appCluster: redis-cluster
template:
metadata:
labels:
app: redis-cluster
appCluster: redis-cluster
spec:
nodeSelector: #todo 去掉,由于资源不足才需要再master
kubernetes.io/hostname: "rwa-test1"
tolerations: #todo 去掉
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule" #todo 去掉
containers:
- name: redis-cluster
image: "redis:6.2.6-alpine"
imagePullPolicy: IfNotPresent
command:
- "redis-server"
args:
- "/etc/redis/redis.conf"
- "--protected-mode"
- "no"
resources:
requests:
cpu: "100m"
memory: "100Mi"
ports:
- name: redis
containerPort: 6379
protocol: "TCP"
- name: cluster
containerPort: 16379
protocol: "TCP"
volumeMounts:
- name: "redis-cluster-conf"
mountPath: "/etc/redis"
- name: "redis-cluster-data"
mountPath: "/var/lib/redis"
volumes:
- name: "redis-cluster-conf"
configMap:
name: "redis-cluster-conf"
items:
- key: "redis.conf"
path: "redis.conf"
volumeClaimTemplates:
- metadata:
name: redis-cluster-data
spec:
accessModes: [ "ReadWriteMany" ]
storageClassName: "nfs-storage1" #todo,改为自己的nfs
resources:
requests:
storage: 100Mi #todo资源不足才用100
---
apiVersion: v1
kind: Service
metadata:
name: redis-cluster-access-service
namespace: cspy-test
labels:
app: redis-cluster
spec:
type: NodePort
ports:
- name: redis-cluster-port
protocol: "TCP"
port: 6379
targetPort: 6379
nodePort: 30479
selector:
app: redis-cluster
appCluster: redis-cluster
运行
运用文件
kubectl apply -f redis-cluster.yaml
查看pod
# kubectl get pods -o wide -n cspy-test | grep redis
redis-cluster-app-0 1/1 Running 0 38s 10.244.0.167 rwa-test1 <none> <none>
redis-cluster-app-1 1/1 Running 0 32s 10.244.0.168 rwa-test1 <none> <none>
redis-cluster-app-2 1/1 Running 0 28s 10.244.0.169 rwa-test1 <none> <none>
redis-cluster-app-3 1/1 Running 0 24s 10.244.0.170 rwa-test1 <none> <none>
redis-cluster-app-4 1/1 Running 0 19s 10.244.0.171 rwa-test1 <none> <none>
redis-cluster-app-5 1/1 Running 0 16s 10.244.0.172 rwa-test1 <none> <none>
初始化集群
初始化集群采用redis-trib这个工具,直接yum安装redis-trib这个软件,执行初始化
yum -y install redis-trib
redis-trib create --replicas 1 10.244.0.167:6379 10.244.0.168:6379 10.244.0.169:6379 10.244.0.170:6379 10.244.0.171:6379 10.244.0.172:6379
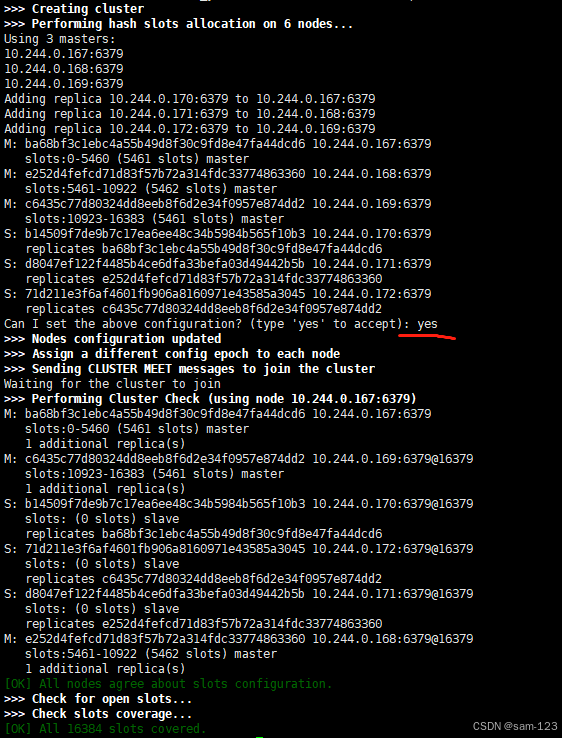
验证集群状态,集群节点状态为OK,共有6个节点
#kubectl exec -ti redis-cluster-app-0 -n cspy-test -- redis-cli -c
>cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:6
cluster_my_epoch:1
cluster_stats_messages_ping_sent:306
cluster_stats_messages_pong_sent:300
cluster_stats_messages_sent:606
cluster_stats_messages_ping_received:295
cluster_stats_messages_pong_received:306
cluster_stats_messages_meet_received:5
cluster_stats_messages_received:606
>role
1) "master"
2) (integer) 266
3) 1) 1) "10.244.0.170"
2) "6379"
3) "266"
>cluster nodes
c6435c77d80324dd8eeb8f6d2e34f0957e874dd2 10.244.0.169:6379@16379 master - 0 1731492697504 3 connected 10923-16383
b14509f7de9b7c17ea6ee48c34b5984b565f10b3 10.244.0.170:6379@16379 slave ba68bf3c1ebc4a55b49d8f30c9fd8e47fa44dcd6 0 1731492698407 1 connected
71d211e3f6af4601fb906a8160971e43585a3045 10.244.0.172:6379@16379 slave c6435c77d80324dd8eeb8f6d2e34f0957e874dd2 0 1731492697404 3 connected
d8047ef122f4485b4ce6dfa33befa03d49442b5b 10.244.0.171:6379@16379 slave e252d4fefcd71d83f57b72a314fdc33774863360 0 1731492697000 2 connected
ba68bf3c1ebc4a55b49d8f30c9fd8e47fa44dcd6 10.244.0.167:6379@16379 myself,master - 0 1731492697000 1 connected 0-5460
e252d4fefcd71d83f57b72a314fdc33774863360 10.244.0.168:6379@16379 master - 0 1731492696400 2 connected 5461-10922
redis主从切换测试
删除一个pod为redis的master
# kubectl delete pods redis-cluster-app-1
pod “redis-cluster app-0” deleted
删除pod后,k8s会自动重建一个名称为“redis-cluster-app-1”并加入到集群中,但IP不一定是原来的IP;再次通过cluster nodes或者role查看集群角色,redis-cluster-app-1由master变为salve,集群整体依然是6个
参考:https://blog.csdn.net/hlroliu/article/details/105859200
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » k8s上部署redis高可用集群

发表评论 取消回复