Flume 自定义 Interceptor 开发案例
- 案例需求分析
案例需求:实时监控指定文件,即只要应用程序向这个文件里面写数据,Source 组件就可以获取到该信息,自定义 Interceptor 区分“国产电影”和“外国电影”,将其分别发往不同的 Channel,最后上传到 HDFS 中。
需求分析:该实训是,使用 Exec Source 接收外部数据源,HDFS 作为 Sink。Flume 使用 tail 命令从指定文件尾部读取,将每行作为一个 Event,根据 Interceptor 的设置发往不同的 Channel 中缓存,最后存入 HDFS 不同的目录中。过程如下图所示:
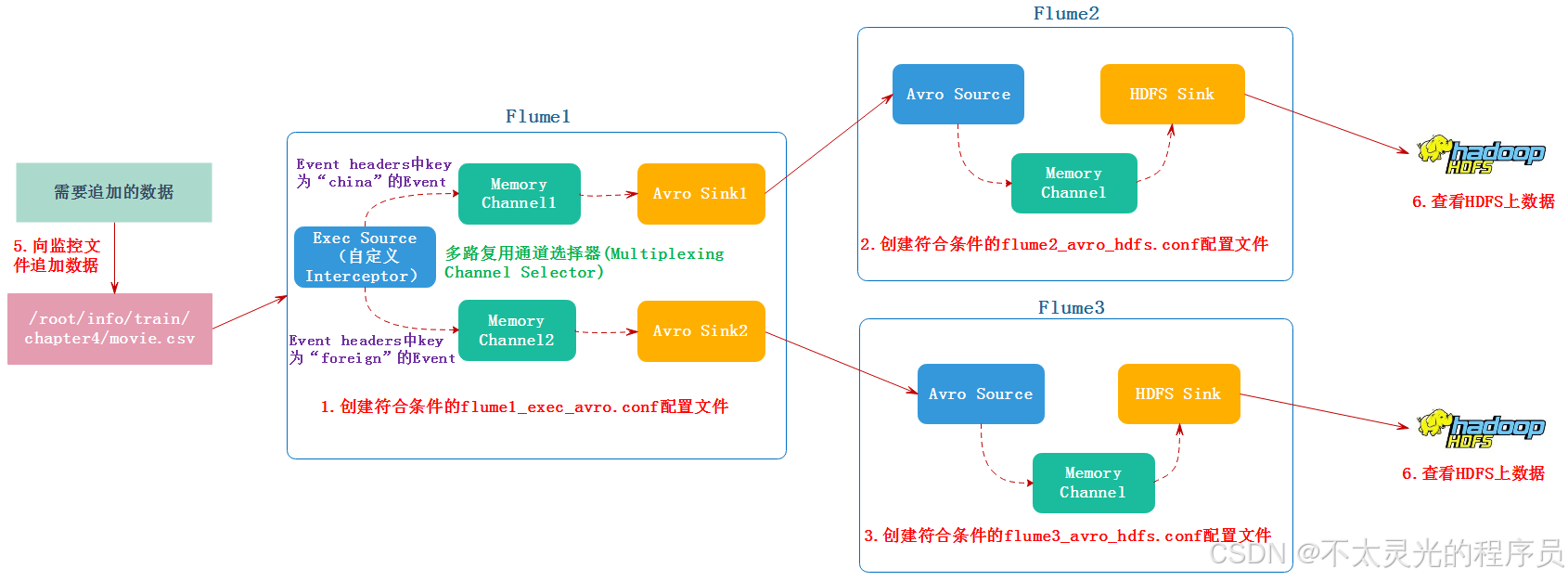
- 自定义 Interceptor 的步骤
自定义拦截器需要实现 org.apache.flume.interceptor.Interceptor 接口以及与之相关的 org.apache.flume.interceptor.Interceptor.Builder 接口,其中,Interceptor 接口是主要定义过滤/拦截方法的接口,Builder 是创建该对应拦截器的接口。具体步骤如下:
(1)创建 Java 项目,导入 Flume 的 jar 包;
(2)自定义拦截器类 MovieInterceptor 实现 Flume 提供的 Interceptor 接口,并在其中定义一个静态内部类 MyBuilder,实现 Interceptor 的内部接口 Builder。区中:
Interceptor 的实现类有四个方法:initialize() 为初始化方法,intercept(Event event) 用来处理单个 Event,intercept(List events) 用来处理多个 Event,close() 用来关闭资源。
Builder 的实现类有两个方法:build() 用来构造自己的拦截器对象,configure() 可以获取我们自己编写的 agent 文件中的配置。
(3)将自定义的拦截器打成 jar 包放到 $FLUME_HOME/lib 目录下。
(4)配置 Flume 采集方案。
(5)使用指定采集方案启动 Flume。
(6)往监控文件中写入测试数据。
(7)查看采集结果。
一、Flume 自定义 Interceptor
- Interceptor 介绍
Interceptor 是 Flume 中默认支持的拦截器,Interceptor 是在 Source 之后 Channel 之前拦截数据,可以在其中追加参数也可以过滤无效数据。官方提供的拦截器有:
Timestamp Interceptor:在 Event 的 headers 中添加一个 timestamp 为 key,value 为当前的时间戳的键值对。这个拦截器在 Sink 为 HDFS 时很有用。
Host Interceptor:在 Event 的 headers 中添加一个 host 为 key,value 为当前机器 ip/主机名 的键值对。
Static Interceptor:在 Event 的 headers 中自定义添加一个 key/value 键值对。
Regex Filtering Interceptor:通过正则表达式来过滤或者包含 body 匹配的 Events。
Regex Extractor Interceptor:通过正则表达式来提取 body 中的内容并添加到 headers 中。
2. Interceptor 实现
自定义拦截器需要实现 org.apache.flume.interceptor.Interceptor 接口以及与之相关的 org.apache.flume.interceptor.Interceptor.Builder 接口,其中,Interceptor 接口是主要定义过滤/拦截方法的接口,Builder 是创建该对应拦截器的接口。
Interceptor 接口主要方法:
(1) public void initialize():初始化,可以为空。
(2)public Event intercept(Event event):处理单个 Event,必须实现。Event 是 Flume 处理数据的数据结构,数据以 byte 存在 Event 的 body 中。该方法实现将“制片地区”包含“中国”的 Event 的 headers 赋值为“china”,其余赋值为“foreign”。
(3)public List intercept(List events):批量处理 Event,必须实现。内部调用处理单个 Event 的方法。
(4) public void close():关闭资源,可以为空。
Builder 接口主要方法:
(1) public Interceptor build():创建拦截器实例对象,必须实现。
(2) public void configure(Context context):可以获取我们自己编写的 agent 文件中的配置,可以为空。
二、Flume 配置讲解
- Flume Source 配置讲解
(1)Exec Source 配置讲解
Exec Source 在启动时运行给定的 Unix 命令,并期望该进程在标准输出上连续生成数据。如果进程因任何原因退出,则 Source 也会退出并且不会继续生成数据。这意味着诸如 cat [named pipe] 或 tail -F [file] 之类的命令会产生所需的结果,而 date 这种命令可能不会,因为前两个命令(tail 和 cat)能产生持续的数据流,而后者(date 这种命令)只会产生单个 Event 并退出。必需的参数已用粗体标明:
属性名称 默认值 描述
channels – 与 Source 绑定的 Channel,多个用空格分开
type – 组件类型名称,需要是 exec
command – 使用的系统命令,一般是 cat 或者 tail
selector.type replicating 配置 Channel 选择器。可选值:replicating 或 multiplexing,分别表示: 复制、多路复用
selector.* – Channel 选择器的相关属性,具体属性根据设定的 selector.type 值不同而不同
interceptors – 该 Source 所使用的拦截器,多个用空格分开
interceptors.* – 拦截器的相关属性
(2)Avro Source 配置讲解
Avro Source 监听 Avro 端口并接收从外部 Avro 客户端发送来的数据流。如果与上一层 Agent 的 Avro Sink 配合使用就组成了一个分层的拓扑结构。利用 Avro Source 可以实现多级流动、扇出流、扇入流等效果。以下是必需的参数:
属性名称 默认值 描述
channels – 与 Source 绑定的 Channel,多个用空格分开
type – 组件类型名称,需要是 avro
bind – 要监听的主机名或 IP 地址
port – 要监听的服务端口
2. Flume Sink 配置讲解
(1)Avro Sink 配置讲解
Avro Sink 可以作为 Flume 分层收集特性的下半部分。发送到此 Sink 的 Flume Event 将转换为 Avro Event 发送到配置的主机/端口上。Event 从配置的 Channel 中批量获取,数量根据配置的 batch-size 而定。以下是必需的参数:
属性名称 默认值 描述
channel – 与 Sink 绑定的 Channel
type – 组件类型名称,需要是 avro
bind – 要监听的主机名或 IP 地址
port – 要监听的服务端口
(2)HDFS Sink 配置讲解
HDFS Sink 将 Event 写入 Hadoop 分布式文件系统(也就是 HDFS)。它目前支持创建文本和序列文件,以及两种类型的压缩文件。
HDFS Sink 可以根据写入的时间、文件大小或 Event 数量定期滚动文件(关闭当前文件并创建新文件)。它还可以根据 Event 发生的时间戳或系统时间等属性对数据进行存储/分区。存储文件的 HDFS 目录路径可以使用格式转义序列,这些转义序列将被 HDFS Sink 进行动态地替换,以生成用于存储 Event 的目录或文件名。使用 HDFS Sink 时需要安装 Hadoop,以便 Flume 可以使用 Hadoop jar 与 HDFS 集群进行通信。请注意, 需要使用支持 sync() 调用的 Hadoop 版本。
以下是支持的转义序列:
转义序列 描述
%{host} Event header 中 key 为 host 的值。这个 host 可以是任意的 key,只要 header 中有就能读取,比如 %{aabc} 将读取 header 中 key 为 aabc 的值
%t 毫秒值的时间戳(同 System.currentTimeMillis() 方法)
%a 星期的缩写(Mon、Tue 等)
%A 星期的全拼(Monday、 Tuesday 等)
%b 月份的缩写(Jan、 Feb 等)
%B 月份的全拼(January、February 等)
%c 日期和时间(Mon Feb 14 23:05:25 2022)
%d 月份中的某一天(00到31)
%e 没有填充的月份中的某一天(1到31)
%D 日期,与%m/%d/%y相同 ,例如:02/14/22
%H 小时(00到23)
%I 小时(01到12)
%j 一年中的一天(001到366)
%k 小时(0到23),注意跟 %H的区别
%m 月份(01到12)
%n 没有填充的月份(1到12)
%M 分钟(00到59)
%p am或者pm
%s unix时间戳,是秒值。比如 2022-02-14 18:15:49 的 unix 时间戳是:1644833749
%S 秒(00到59)
%y 一年中的最后两位数(00到99),比如1998年的%y就是98
%Y 年份(2010这种格式)
%z +hhmm,数字时区(比如:-0400)
%[localhost] Agent 实例所在主机的 hostname
%[IP] Agent 实例所在主机的 IP 地址
%[FQDN] Agent 实例所在主机的规范 hostname
注意,%[localhost]、%[IP] 和 %[FQDN] 这三个转义序列实际上都是用 Java 的 API 来获取的,在某些网络环境下可能会获取失败。
正在打开的文件会在名称末尾加上“.tmp”的后缀。文件关闭后,会自动删除此扩展名。这样容易排除目录中的那些已完成的文件。必需的参数已用粗体标明:
属性名称 默认值 描述
channel – 与 Sink 绑定的 Channel
type – 组件类型名称,需要是 hdfs
hdfs.path – HDFS 目录路径(例如:hdfs://namenode/flume/hivedata/)
hdfs.filePrefix FlumeData Flume 在 HDFS 文件夹下创建新文件的固定前缀
hdfs.fileSuffix – Flume 在 HDFS 文件夹下创建新文件的后缀(比如:.avro,注意这个“.”不会自动添加,需要显式配置)
hdfs.inUsePrefix – Flume 正在写入的临时文件前缀,默认没有
hdfs.inUseSuffix .tmp Flume 正在写入的临时文件后缀
hdfs.emptyInUseSuffix false 如果设置为 false 上面的 hdfs.inUseSuffix 参数在写入文件时会生效,并且写入完成后会在目标文件上移除 hdfs.inUseSuffix 配置的后缀。如果设置为 true 则上面的 hdfs.inUseSuffix 参数会被忽略,写文件时不会带任何后缀
hdfs.rollInterval 30 当前文件写入达到该值时间后触发滚动创建新文件(0表示不按照时间来分割文件),单位:秒
hdfs.rollSize 1024 当前文件写入达到该大小后触发滚动创建新文件(0表示不根据文件大小来分割文件),单位:字节
hdfs.rollCount 10 当前文件写入 Event 达到该数量后触发滚动创建新文件(0表示不根据 Event 数量来分割文件)
hdfs.idleTimeout 0 关闭非活动文件的超时时间(0表示禁用自动关闭文件),单位:秒
hdfs.batchSize 100 在将文件刷新到 HDFS 之前写入文件的 Event 数
hdfs.codeC – 压缩编解码器。可选值:gzip 、 bzip2 、 lzo 、 lzop 、 snappy
hdfs.fileType SequenceFile 文件格式。目前支持: SequenceFile 、 DataStream 、 CompressedStream 。 DataStream 不会压缩文件,不需要设置hdfs.codeC;CompressedStream 必须设置 hdfs.codeC 参数
hdfs.writeFormat Writable 文件写入格式。可选值: Text 、 Writable 。在使用 Flume 创建数据文件之前设置为 Text,否则 Apache Impala(孵化)或 Apache Hive 无法读取这些文件
hdfs.useLocalTimeStamp false 使用日期时间转义序列时是否使用本地时间戳(而不是使用 Event headers 中的时间戳)
serializer TEXT Event 转为文件使用的序列化器。其他可选值有: avro_event 或其他 EventSerializer.Builderinterface 接口的实现类的全限定类名
serializer.* 根据上面 serializer 配置的类型来根据需要添加序列化器的参数
3. Flume Channel 配置讲解
Memory Channel 配置讲解
Memory Channel 是把 Event 队列存储到内存上,队列的最大数量就是 capacity 的设定值。它非常适合对吞吐量有较高要求的场景,但也是有代价的,当发生故障的时候会丢失当时内存中的所有 Event。必需的参数已用粗体标明:
属性名称 默认值 说明
type – 组件类型名称,需要是 memory
capacity 100 存储在 Channel 中的最大 Event 数
transactionCapacity 100 Channel 将从 Source 接收或向 Sink 传递的每一个事务中的最大 Event 数(capacity>= transactionCapacity)
4. Flume Channel Selectors 配置讲解
Multiplexing Channel Selector 配置讲解
Multiplexing Channel Selector(多路复用通道选择器)参数如下:
属性名称 描述 设置值
selector.type replicating 组件类型名称,需要是 multiplexing
selector.header flume.selector.header 想要进行匹配的 Event headers 属性的名字
selector.default – 指定一个默认的 Channel。如果没有被规则匹配到,默认会发到这个 Channel 上
selector.mapping.* – 一些匹配规则
一、创建 Java 项目
- 新建 Java 项目
打开 Eclipse,将 Eclipse 工作目录设置为 /root/eclipse-workspace,创建名为 “myinterceptor” 的Java Project,在 “myinterceptor” 项目下创建名为 com.hongyaa.flume 的 package 包。
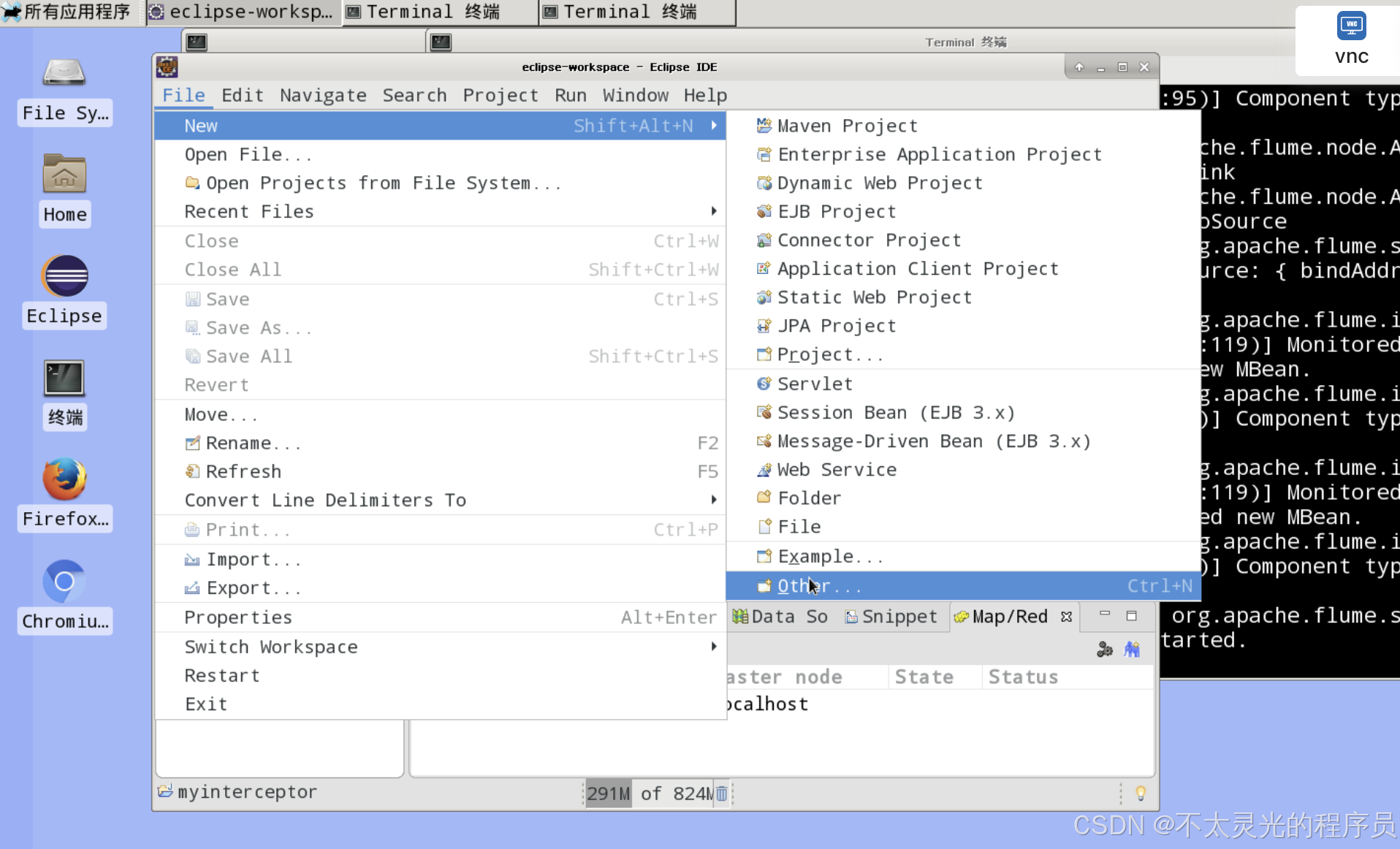
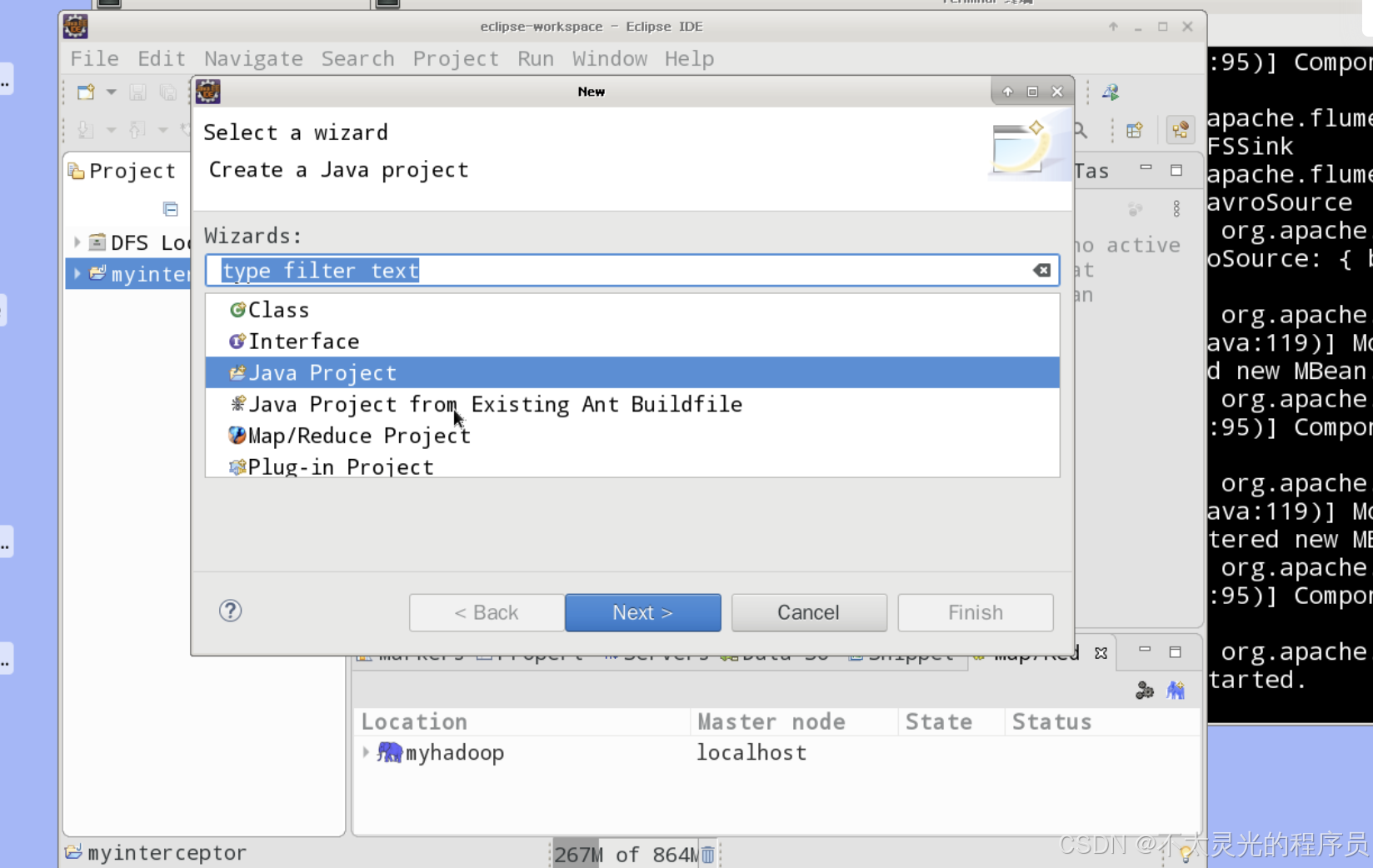
- 导入依赖 jar 包
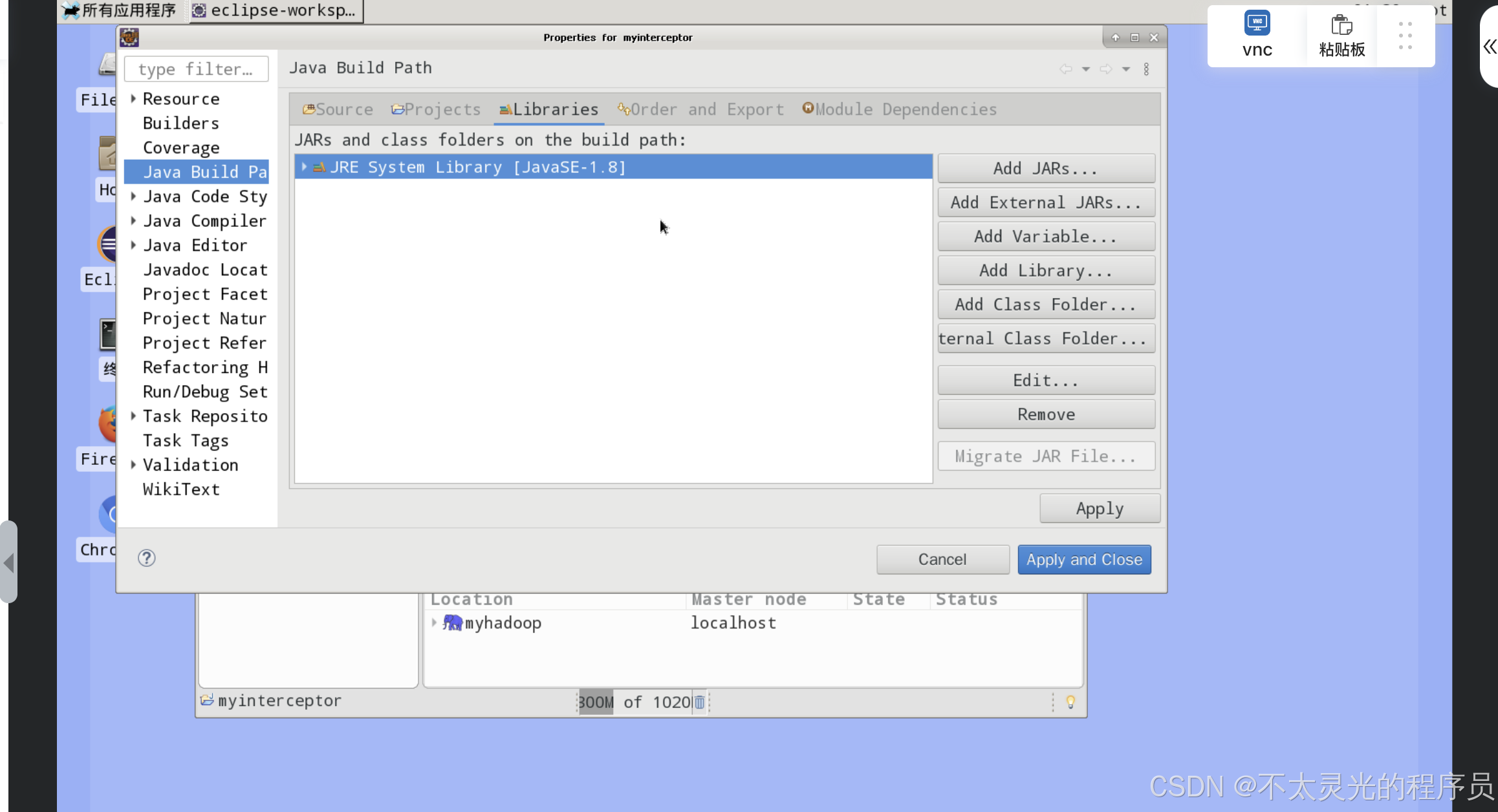
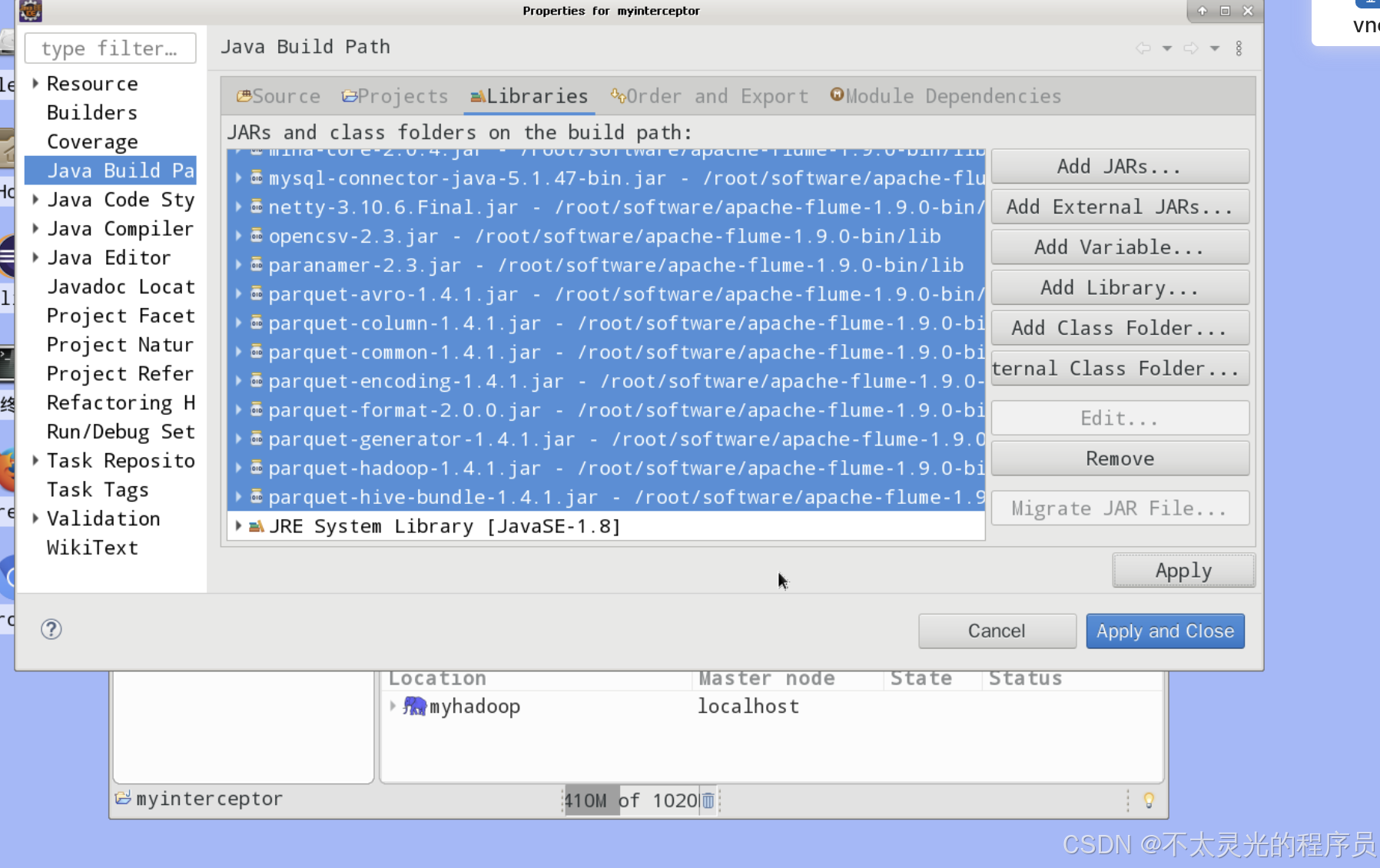
右键“myinterceptor”项目—>选择“Build Path”—>“Configure Build Path”。之后弹出“Properties for myinterceptor”对话框,选择“Libraries”界面,之后单击“Add External JARs…”。弹出“JAR Selection”对话框,选择“+ Other Locations”—>“Computer”,进入“/root/software/apache-flume-1.9.0-bin/lib”目录,全选 lib 目录下的所有包,然后单击“open”,最后单击“Apply and Close”应用并关闭窗口。
二、自定义拦截器实现
自定义拦截器需要实现 org.apache.flume.interceptor.Interceptor 接口以及与之相关的 org.apache.flume.interceptor.Interceptor.Builder 接口,其中,Interceptor 接口是主要定义过滤/拦截方法的接口,Builder 是创建该对应拦截器的接口。
Interceptor 接口主要方法:
(1) public void initialize():初始化,可以为空。
(2)public Event intercept(Event event):处理单个 Event,必须实现。Event 是 Flume 处理数据的数据结构,数据以 byte 存在 Event 的 body 中。该方法实现将“制片地区”包含“中”的 Event 的 headers 赋值为“china”,其余赋值为“foreign”。
(3)public List intercept(List events):批量处理 Event,必须实现。内部调用处理单个 Event 的方法。
(4) public void close():关闭资源,可以为空。
Builder 接口主要方法:
(1) public Interceptor build():创建拦截器实例对象,必须实现。
(2) public void configure(Context context):可以获取我们自己编写的 agent 文件中的配置,可以为空。
三、编写拦截器类
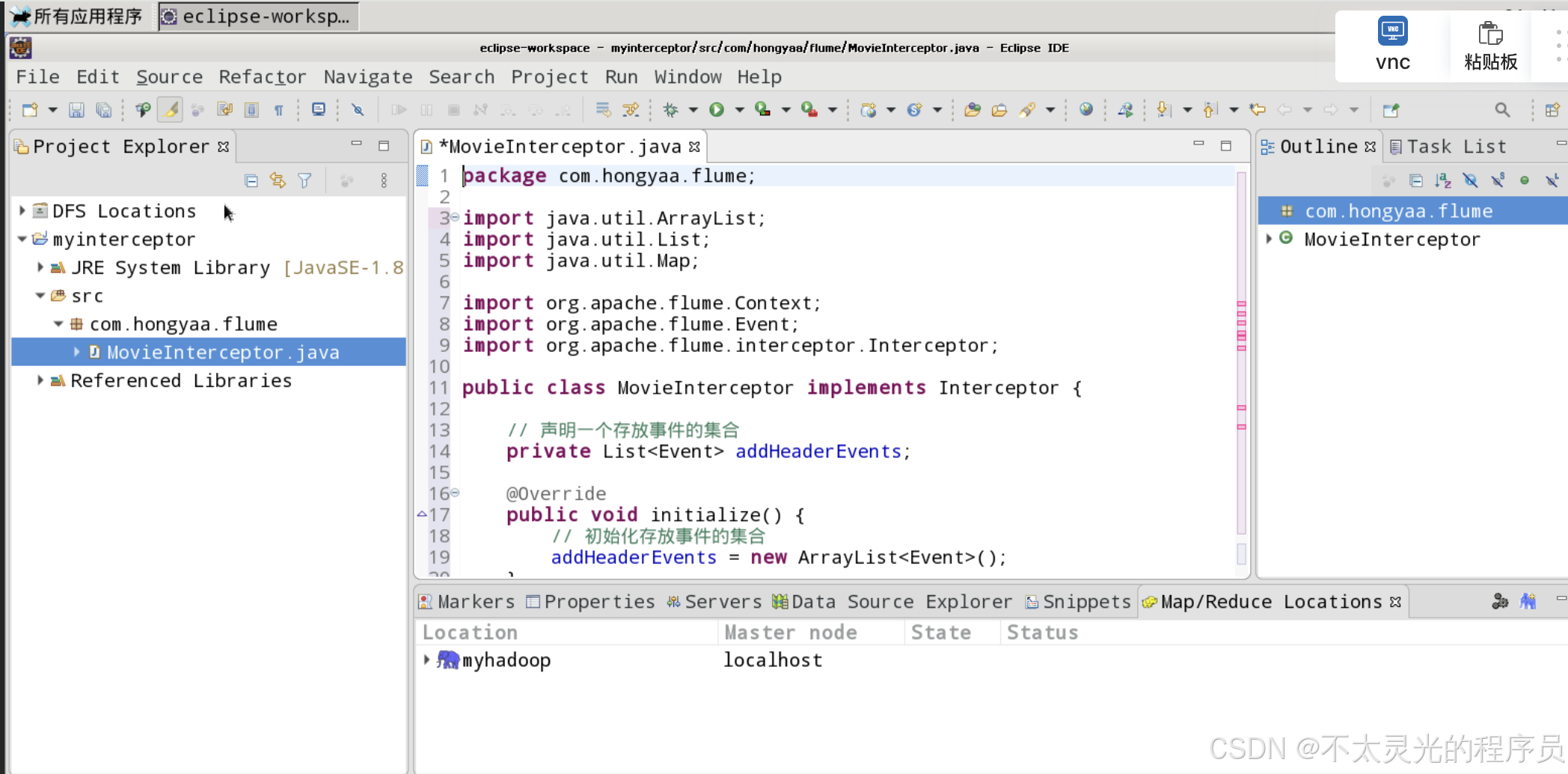
在 com.hongyaa.flume 包下创建一个名为 MovieInterceptor 的 class 文件。在该拦截器类中,我们提取监控文件中“制片地区”字段,以“制片地区”是否包含“中国”字符串来区分“国产电影”和“外国电影”。若是“国产电影”则将 Event headers 中 key 对应的 value 值设置为 “china”,若是“外国电影”则将 Event headers 中 key 对应的 value 值设置为 “foreign”。自定义拦截器类代码参考如下:
package com.hongyaa.flume;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
public class MovieInterceptor implements Interceptor {
// 声明一个存放事件的集合
private List<Event> addHeaderEvents;
@Override
public void initialize() {
// 初始化存放事件的集合
addHeaderEvents = new ArrayList<Event>();
}
/**
* 单个事件拦截
*/
@Override
public Event intercept(Event event) {
// 1. 获取event中的头信息
Map<String, String> headers = event.???;
// 2. 获取event中的body信息,body是数据的载体
String body = new String(event.???);
// 3. 获取“制片地区”
String area = body.???(",")[5];
// 4. 根据“制片地区”中是否包含“中国”来决定添加怎样的头信息
if (area.???("中国")) {
headers.???("area", "china");// 添加头信息
} else {
headers.???("area", "foreign");// 添加头信息
}
// 5. 返回事件
return event;
}
/**
* 批量事件拦截
*/
@Override
public List<Event> intercept(List<Event> events) {
// 1. 清空集合
addHeaderEvents.???;
// 2. 遍历events集合
for (Event event : events) {
// 3. 为每个事件添加头信息
addHeaderEvents.???(intercept(event));
}
// 4. 返回结果
return addHeaderEvents;
}
@Override
public void close() {
// do nothing
}
/**
* 相当于自定义Interceptor的工厂类
* 在Flume采集配置文件中通过指定该Builder来创建Interceptor对象
*
*/
public static class MyBuilder implements Interceptor.Builder {
@Override
public void configure(Context context) {
// do nothing
}
@Override
public Interceptor build() {
return new MovieInterceptor(); // 创建MovieInterceptor对象
}
}
}
四、jar 包准备
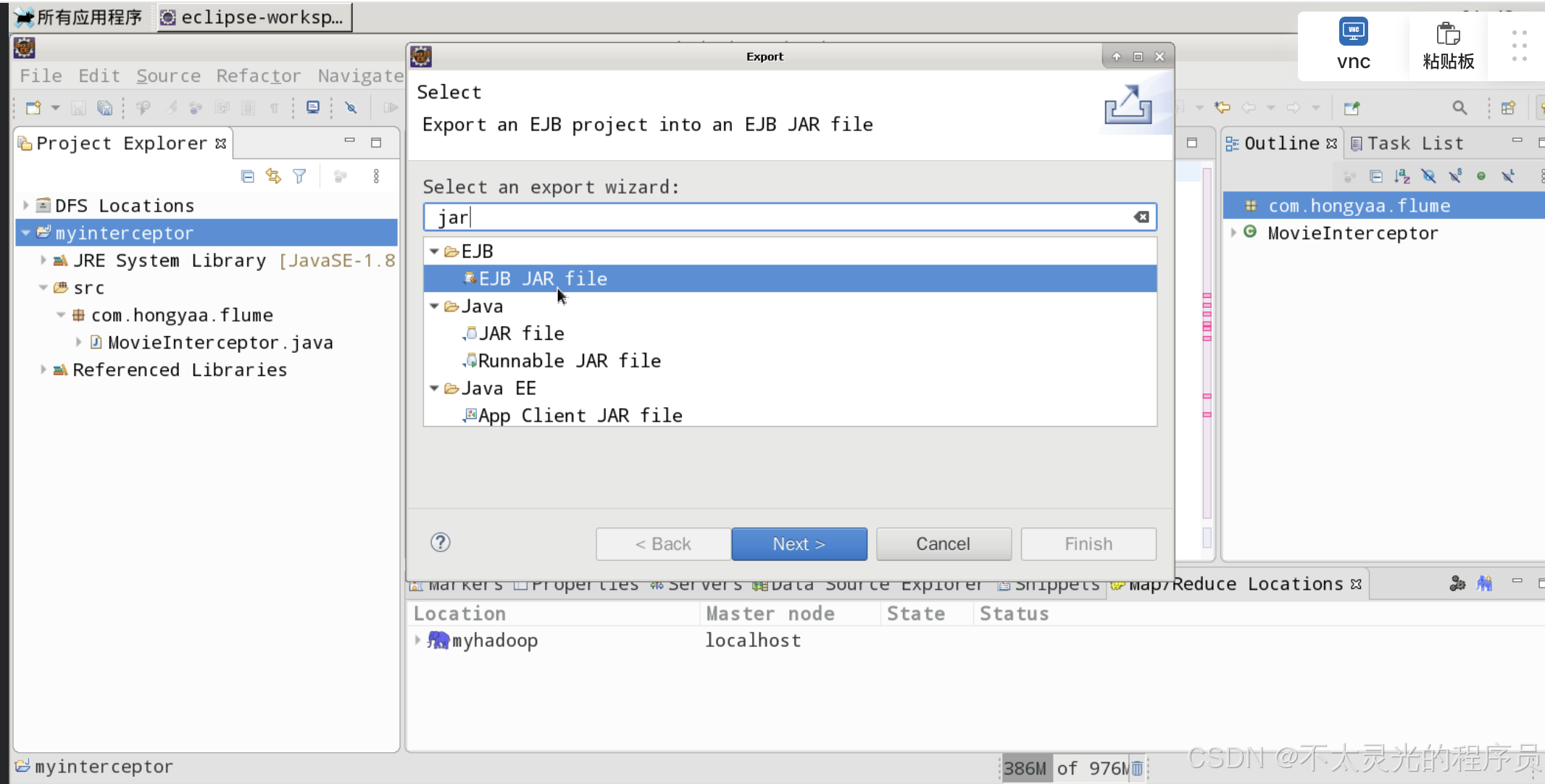
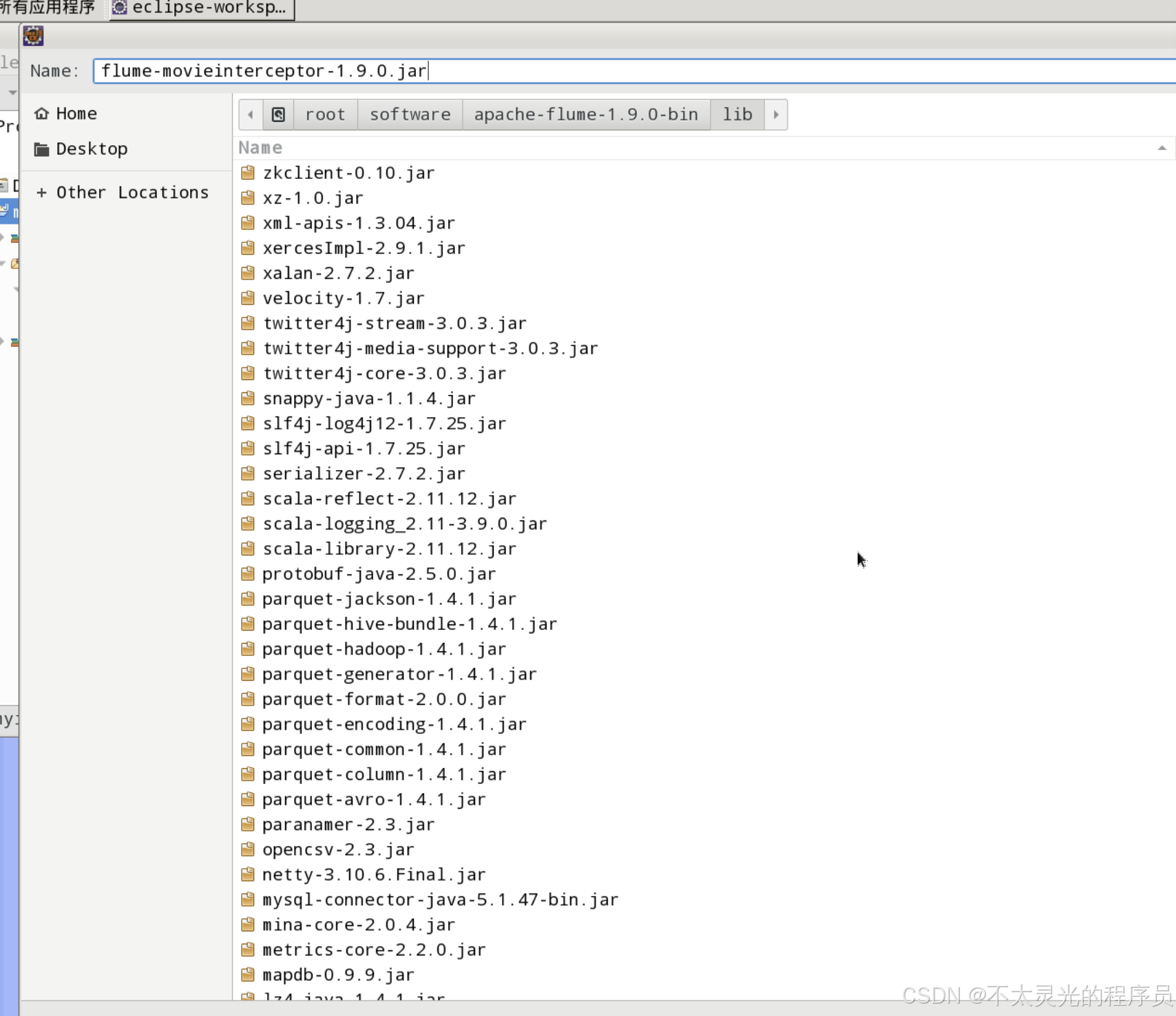
右键“myinterceptor”项目 ->选择 “Export” ,在弹出的 “Export" 对话框中,选择 “Java”->“JAR file”->“Next”。展开项目 “myinterceptor”,勾选包 “com.hongyaa.flume”,jar 包的保存路径为 /root/software/apache-flume-1.9.0-bin/lib,名称为 flume-movieinterceptor-1.9.0.jar,最后点击“Finish”。
-
创建 Agent 配置文件(Exec Source + MovieInterceptor + Memory Channel + Avro Sink)
进入 /root/software/apache-flume-1.9.0-bin/conf 目录,使用 touch 命令创建一个名为 flume1_exec_avro.conf 的配置文件。 -
查看端口
使用 netstat -nlp | grep 6666 命令查看 6666 和 6667 端口是否被占用。 -
编辑配置文件 flume1_exec_avro.conf
使用 vim 命令打开 flume1_exec_avro.conf 文件,在里面添加如下配置:
(1)配置 Flume Agent——a1
首先,我们需要为 a1 命名/列出组件,将数据源(Source)、缓冲通道(Channel)和接收器(Sink)分别命名为 execSource、 mc1 、 mc2 、 avroSink1 和 avroSink2。
(2)描述和配置 Exec Source
Exec Source 在启动时运行给定的 Unix 命令,并期望该进程在标准输出上连续生成数据。如果进程因任何原因退出,则 Source 也会退出并且不会继续生成数据。这意味着诸如 cat [named pipe] 或 tail -F [file] 之类的命令会产生所需的结果,而 date 这种命令可能不会,因为前两个命令(tail 和 cat)能产生持续的数据流,而后者(date 这种命令)只会产生单个 Event 并退出。
我们需要为 execSource 设置以下属性:
属性名称 描述 设置值
channels 与 Source 绑定的 Channel mc1 mc2
type 数据源的类型 exec
command 所使用的系统命令,一般是 cat 或者 tail tail -F /root/info/train/chapter4/movie.csv
interceptors 该 Source 所使用的拦截器,多个用空格分开 movieinter
interceptors.movieinter.type 拦截器类型 com.hongyaa.flume.MovieInterceptor$MyBuilder
selector.type 配置 Channel 选择器。可选值:replicating 或 multiplexing,分别表示: 复制、多路复用 multiplexing
selector.header 配置 Event headers 中的 key area
selector.mapping.china 配置 Event headers 中 key 对应的 value,如果是“china”就发往 mc1 mc1
selector.mapping.foreign 配置 Event headers 中 key 对应的 value,如果是“foreign”就发往 mc2 mc2
(3)描述和配置 Avro Sink
Avro Sink 可以作为 Flume 分层收集特性的下半部分。发送到此 Sink 的 Flume Event 将转换为 Avro Event 发送到配置的主机/端口上。Event 从配置的 Channel 中批量获取,数量根据配置的 batch-size 而定。
我们需要为 avroSink1 设置以下属性:
属性名称 描述 设置值
channel 与 Sink 绑定的 Channel mc1
type 接收器的类型 avro
hostname 要监听的主机名或 IP 地址 localhost(本机)
port 要监听的服务端口 6666(任意可用端口)
我们需要为 avroSink2 设置以下属性:
属性名称 描述 设置值
channel 与 Sink 绑定的 Channel mc2
type 接收器的类型 avro
hostname 要监听的主机名或 IP 地址 localhost(本机)
port 要监听的服务端口 6667(任意可用端口)
(4)描述和配置 Memory Channel
Memory Channel 是把 Event 队列存储到内存上,队列的最大数量就是 capacity 的设定值。它非常适合对吞吐量有较高要求的场景,但也是有代价的,当发生故障的时候会丢失当时内存中的所有 Event。
我们需要为 mc1 和 mc2 分别设置以下属性:
属性名称 描述 设置值
type 缓冲通道的类型 memory
capacity 存储在 Channel 中的最大 Event 数,默认值100 1000
transactionCapacity Channel 将从 Source 接收或向 Sink 传递的每一个事务中的最大 Event 数(capacity>= transactionCapacity),默认值100 100
vim flume1_exec_avro.conf
a1.sources = execSource
a1.channels = mc1 mc2
a1.sinks = avroSink1 avroSink2
a1.sources.execSource.channels = mc1 mc2
a1.sources.execSource.type = exec
a1.sources.execSource.command = tail -F /root/info/train/chapter4/movie.csv
a1.sources.execSource.interceptors = movieinter
a1.sources.execSource.interceptors.movieinter.type = com.hongyaa.flume.MovieInterceptor$MyBuilder
a1.sources.execSource.selector.type = multiplexing
a1.sources.execSource.selector.header = area
a1.sources.execSource.selector.mapping.china = mc1
a1.sources.execSource.selector.mapping.foreign = mc2
a1.sinks.avroSink1.channel = mc1
a1.sinks.avroSink1.type = avro
a1.sinks.avroSink1.hostname = localhost
a1.sinks.avroSink1.port = 6666
a1.sinks.avroSink2.channel = mc2
a1.sinks.avroSink2.type = avro
a1.sinks.avroSink2.hostname = localhost
a1.sinks.avroSink2.port = 6667
a1.channels.mc1.type = memory
a1.channels.mc1.capacity = 1000
a1.channels.mc1.transactionCapacity = 100
a1.channels.mc2.type = memory
a1.channels.mc2.capacity = 1000
a1.channels.mc2.transactionCapacity = 100
vim flume2_avro_hdfs.conf
a2.sources = avroSource
a2.channels = memoryChannel
a2.sinks = HDFSSink
a2.sources.avroSource.channels = memoryChannel
a2.sources.avroSource.type = avro
a2.sources.avroSource.bind = localhost
a2.sources.avroSource.port = 6666
## Describe the sink
#与 Sink绑定的 Channel
a2.sinks.HDFSSink.channel = memoryChannel
# 接收器的类型为 hdfs类型,输出目的地是HDFS
a2.sinks.HDFSSink.type = hdfs
# 数据存放在HDFS上的目录
a2.sinks.HDFSSink.hdfs.path = hdfs://localhost:9000/flumedata/china/%Y-%m-%d
# 文件的固定前缀为 hivelogs-
a2.sinks.HDFSSink.hdfs.filePrefix = china
# 按时间间隔滚动文件,默认30s,此处设置为 60s
a2.sinks.HDFSSink.hdfs.rollInterval = 0
# 按文件大小滚动文件,默认1024字节,此处设置为5242880字节 ( 5M)
a2.sinks.HDFsSink.hdfs.rollSize = 134217728
# 当Event个数达到该数量时,将临时文件滚动成目标文件,默认是10,0表示文件的滚动与Event数量无关
a2.sinks.HDFSSink.hdfs.rollCount =0
# 文件格式,默认为SequenceFile,但里面的内容无法直接打开浏览,所以此处设置为DataStream
a2.sinks.HDFSSink.hdfs.fileType = DataStream
# 文件写入格式,默认为Writable,此处设置为Text
a2.sinks.HDFSSink.hdfs.writeFormat = Text
# HDFS Sink是否使用本地时间,默认为false,此处设置为true
a2.sinks.HDFSSink.hdfs.useLocalTimeStamp = true
a2.channels.memoryChannel.type = memory
a2.channels.memoryChannel.capacity = 1000
a2.channels.memoryChannel.transactionCapacity = 100
vim flume3_avro_hdfs.conf
a3.sources = avroSource
a3.channels = memoryChannel
a3.sinks = HDFSSink
a3.sources.avroSource.channels = memoryChannel
a3.sources.avroSource.type = avro
a3.sources.avroSource.bind = localhost
a3.sources.avroSource.port = 6667
## Describe the sink
#与 Sink绑定的 Channel
a3.sinks.HDFSSink.channel = memoryChannel
# 接收器的类型为 hdfs类型,输出目的地是HDFS
a3.sinks.HDFSSink.type = hdfs
# 数据存放在HDFS上的目录
a3.sinks.HDFSSink.hdfs.path = hdfs://localhost:9000/flumedata/foreign/%Y-%m-%d
# 文件的固定前缀为 hivelogs-
a3.sinks.HDFSSink.hdfs.filePrefix = foreign
# 按时间间隔滚动文件,默认30s,此处设置为 60s
a3.sinks.HDFSSink.hdfs.rollInterval = 0
# 按文件大小滚动文件,默认1024字节,此处设置为5242880字节 ( 5M)
a3.sinks.HDFsSink.hdfs.rollSize = 134217728
# 当Event个数达到该数量时,将临时文件滚动成目标文件,默认是10,0表示文件的滚动与Event数量无关
a3.sinks.HDFSSink.hdfs.rollCount =0
# 文件格式,默认为SequenceFile,但里面的内容无法直接打开浏览,所以此处设置为DataStream
a3.sinks.HDFSSink.hdfs.fileType = DataStream
# 文件写入格式,默认为Writable,此处设置为Text
a3.sinks.HDFSSink.hdfs.writeFormat = Text
# HDFS Sink是否使用本地时间,默认为false,此处设置为true
a3.sinks.HDFSSink.hdfs.useLocalTimeStamp = true
a3.channels.memoryChannel.type = memory
a3.channels.memoryChannel.capacity = 1000
a3.channels.memoryChannel.transactionCapacity = 100
flume-ng agent -c conf/ -f conf/flume3_avro_hdfs.conf -n a3 -Dflume.root.logger=INFO,console
flume-ng agent -c conf/ -f conf/flume2_avro_hdfs.conf -n a2 -Dflume.root.logger=INFO,console
flume-ng agent -c conf/ -f conf/flume1_exec_avro.conf -n a1 -Dflume.root.logger=INFO,console
cat /root/info/train/chapter4/test.csv >> /root/info/train/chapter4/movie.csv
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Flume实操】4 Flume 自定义 Interceptor 开发案例

发表评论 取消回复