随着计算机科学的飞速发展,以图像为主的多媒体信息迅速成为重要的信息传递媒介, 在图像中,文字信息(如新闻标题等字幕) 包含了丰富的高层语义信息,提取出这些文字, 对于图像高层语义的理解、索引和检索非常有帮助。图像文字提取又分为动态图像文字提取和静态图像文字提取两种,其中,静态图像文字提取是动态图像文字提取的基础,其应用范围更为广泛,对它的研究具有基础性,
所以本文主要讨论静态图像的文字提取技 术。静态图像中的文字可分成两大类: 一种是图像中场景本身包含的文字, 称为场景文字; 另一种是图像后期制作中加入的文字, 称为人工文字,如右图所示。场景文字由于其出现的位置、小、颜色和形态的随机性, 一般难于检测和提取;而人工文字则字体较规范、大小有一定的限度且易辨认,颜色为单色, 相对与前者更易被检测和提取,
又因其对图像内容起到说明总结的作用,故适合用来做图像的索引和检索关键字。对图像中场景文字的研究难度大,目前这方面的研究成果与文献也不是很丰富,本文主要讨论图像中人工文字提取技术。

静态图像中文字(本文特指人工文字,下同)具有以下主要特征:
- 文字位于前端,且不会被遮挡;
- 文字一般是单色的;
- 文字大小在一幅图片中固定,并且宽度和高度大体相同,从满足人眼视觉感受的角度来说,图像中文字的尺寸既不会过大也不会过小;
- 文字的分布比较集中;
- 文字的排列一般为水平方向或垂直方向;
多行文字之间,以及单行内各个字之间存在不同于文字区域的空隙。在静态图片文字的检测与提取过程中, 一般情况下都是依据上述特征进行处理的。
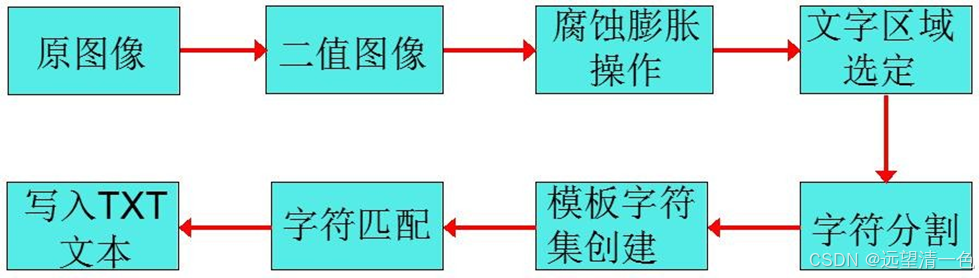
静态图像文字提取一般分为以下步骤:文字区域检测与定位、文字分割与文字提取、文字后处理。其流程如图1所示。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 基于MATLAB的图片中文字的提取及识别

发表评论 取消回复