亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的博客,正是这样一个温暖美好的所在。在这里,你们不仅能够收获既富有趣味又极为实用的内容知识,还可以毫无拘束地畅所欲言,尽情分享自己独特的见解。我真诚地期待着你们的到来,愿我们能在这片小小的天地里共同成长,共同进步。

本博客的精华专栏:
- 大数据新视界专栏系列:聚焦大数据,展技术应用,推动进步拓展新视野。
- Java 大厂面试专栏系列:提供大厂面试的相关技巧和经验,助力求职。
- Python 魅力之旅:探索数据与智能的奥秘专栏系列:走进 Python 的精彩天地,感受数据处理与智能应用的独特魅力。
- Java 性能优化传奇之旅:铸就编程巅峰之路:如一把神奇钥匙,深度开启 JVM 等关键领域之门。丰富案例似璀璨繁星,引领你踏上编程巅峰的壮丽征程。
- Java 虚拟机(JVM)专栏系列:深入剖析 JVM 的工作原理和优化方法。
- Java 技术栈专栏系列:全面涵盖 Java 相关的各种技术。
- Java 学习路线专栏系列:为不同阶段的学习者规划清晰的学习路径。
- JVM 万亿性能密码:在数字世界的浩瀚星海中,JVM 如神秘宝藏,其万亿性能密码即将开启奇幻之旅。
- AI(人工智能)专栏系列:紧跟科技潮流,介绍人工智能的应用和发展趋势。
- 智创 AI 新视界专栏系列(NEW):深入剖析 AI 前沿技术,展示创新应用成果,带您领略智能创造的全新世界,提升 AI 认知与实践能力。
- 数据库核心宝典:构建强大数据体系专栏系列:专栏涵盖关系与非关系数据库及相关技术,助力构建强大数据体系。
- MySQL 之道专栏系列:您将领悟 MySQL 的独特之道,掌握高效数据库管理之法,开启数据驱动的精彩旅程。
- 大前端风云榜:引领技术浪潮专栏系列:大前端专栏如风云榜,捕捉 Vue.js、React Native 等重要技术动态,引领你在技术浪潮中前行。
- 工具秘籍专栏系列:工具助力,开发如有神。
- 今日看点:宛如一盏明灯,引领你尽情畅游社区精华频道,开启一场璀璨的知识盛宴。
- 今日精品佳作:为您精心甄选精品佳作,引领您畅游知识的广袤海洋,开启智慧探索之旅,定能让您满载而归。
- 每日成长记录:细致入微地介绍成长记录,图文并茂,真实可触,让你见证每一步的成长足迹。
- 每日荣登原力榜:如实记录原力榜的排行真实情况,有图有真相,一同感受荣耀时刻的璀璨光芒。
- 每日荣登领军人物榜:精心且精准地记录领军人物榜的真实情况,图文并茂地展现,让领导风采尽情绽放,令人瞩目。
- 每周荣登作者周榜:精准记录作者周榜的实际状况,有图有真相,领略卓越风采的绽放。
展望未来,我将持续深入钻研前沿技术,及时推出如人工智能和大数据等相关专题内容。同时,我会努力打造更加活跃的社区氛围,举办技术挑战活动和代码分享会,激发大家的学习热情与创造力。我也会加强与读者的互动,依据大家的反馈不断优化博客的内容和功能。此外,我还会积极拓展合作渠道,与优秀的博主和技术机构携手合作,为大家带来更为丰富的学习资源和机会。
我热切期待能与你们一同在这个小小的网络世界里探索、学习、成长。你们的每一次点赞、关注、评论、打赏和订阅专栏,都是对我最大的支持。让我们一起在知识的海洋中尽情遨游,共同打造一个充满活力与智慧的博客社区。
衷心地感谢每一位为我点赞、给予关注、留下真诚留言以及慷慨打赏的朋友,还有那些满怀热忱订阅我专栏的坚定支持者。你们的每一次互动,都犹如强劲的动力,推动着我不断向前迈进。倘若大家对更多精彩内容充满期待,欢迎加入【青云交社区】或加微信:【QingYunJiao】【备注:技术交流】。让我们携手并肩,一同踏上知识的广袤天地,去尽情探索。此刻,请立即访问我的主页 或【青云交社区】吧,那里有更多的惊喜在等待着你。相信通过我们齐心协力的共同努力,这里必将化身为一座知识的璀璨宝库,吸引更多热爱学习、渴望进步的伙伴们纷纷加入,共同开启这一趟意义非凡的探索之旅,驶向知识的浩瀚海洋。让我们众志成城,在未来必定能够汇聚更多志同道合之人,携手共创知识领域的辉煌篇章!
大数据新视界 -- 大数据大厂之 Impala 性能优化:新技术融合的无限可能(下)(12/30)
引言:
在之前的两篇文章(《大数据新视界 – 大数据大厂之 Impala 性能优化:融合机器学习的未来之路(上 (2 - 2))(11/30)》和《大数据新视界 – 大数据大厂之 Impala 性能优化:融合机器学习的未来之路(上 (2 - 1))(11/30)》)中,我们如同勇敢的开拓者,深入挖掘了 Impala 与机器学习融合的奇妙世界。从融合的背景、需求、技术基石,到接口优化、资源管理的精细雕琢,再到金融领域案例的精彩演绎以及多行业应用前景的展望,我们已经为大家徐徐展开了一幅宏伟壮丽的技术画卷。然而,Impala 性能优化与新技术融合的征程恰似宇宙探索,永无止境,还有更多未知的神秘星球等待我们去发现。在《大数据新视界 – 大数据大厂之 Impala 性能优化:新技术融合的无限可能(下)(12/30)》中,我们将继续深入这片神秘的技术宇宙,为您呈现更多令人叹为观止的技术奇迹,就像开启一扇扇通往新世界的大门。

正文:
一、Impala 与新技术融合的基石:深度解析核心原理
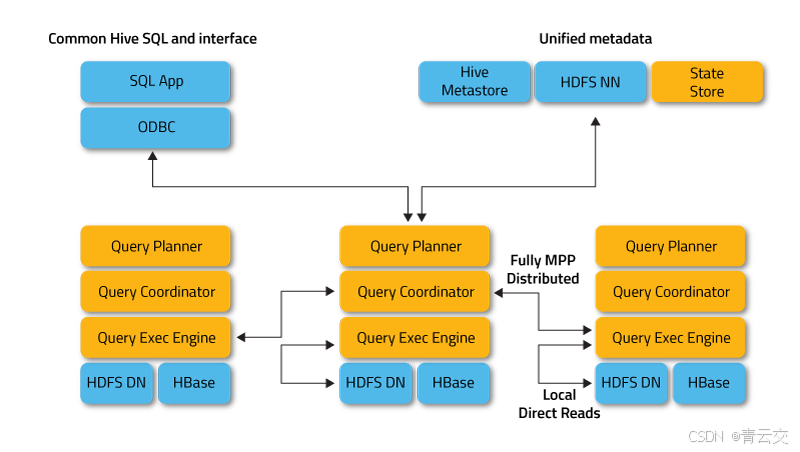
1.1 融合新技术的底层架构剖析
Impala 作为大数据处理领域的核心力量,在与新技术融合时,其底层架构宛如一座复杂而精妙的超级引擎,每个部件都对整体性能有着关键影响。在存储层,新型存储技术的融入仿若为这台引擎添加了新的高性能燃料,需要精确的调配与磨合。以新的列式存储技术为例,它与 Impala 原有的存储模式协同工作时,数据的存储格式兼容性是重中之重,这涉及到存储结构、元数据管理等多个层面。以下是一个更深入的存储格式适配代码示例,展示了如何在复杂环境下确保数据的准确存储与读取:
// 新存储技术与Impala存储层交互的核心类,负责管理数据存储格式的转换和交互
class NewStorageIntegration {
// 存储层相关的配置参数,如存储路径、存储格式版本等
private String storagePath;
private int formatVersion;
// 初始化方法,设置存储层相关参数,并建立与Impala存储层的连接
public void initialize(String path, int version) {
storagePath = path;
formatVersion = version;
// 这里模拟复杂的连接建立过程,可能涉及网络配置、权限验证、存储系统初始化等
System.out.println("Establishing connection to Impala storage layer with path: " + storagePath + " and format version: " + formatVersion);
// 可以添加更多的初始化逻辑,如加载存储系统驱动、检查存储系统状态等
initializeConnection();
}
// 实现新存储格式到Impala兼容格式的转换方法,处理数据的结构转换和元数据映射
public byte[] convertDataFormat(byte[] newFormatData, Metadata metadata) {
// 解析新格式数据的头部信息,获取数据结构和元数据相关信息
DataHeader newHeader = parseDataHeader(newFormatData);
// 根据新格式的元数据和Impala存储要求,创建或更新Impala兼容的元数据
Metadata impalaMetadata = mapMetadata(metadata, newHeader);
// 转换数据结构,将新格式的数据内容转换为Impala可识别的格式
byte[] impalaFormatData = restructureData(newFormatData, newHeader);
// 更新数据的元数据信息,包括存储位置、时间戳、访问权限等
updateMetadata(impalaFormatData, impalaMetadata);
return impalaFormatData;
}
private void initializeConnection() {
// 实际的连接初始化逻辑,这里简化为打印信息
System.out.println("Initializing connection to Impala storage layer...");
}
private DataHeader parseDataHeader(byte[] data) {
// 这里是解析数据头部的逻辑,假设数据头部包含数据类型、长度、编码方式等信息
System.out.println("Parsing data header...");
return new DataHeader();
}
private Metadata mapMetadata(Metadata sourceMetadata, DataHeader newHeader) {
// 根据新格式的元数据和Impala存储要求,映射和更新元数据
System.out.println("Mapping metadata...");
return new Metadata();
}
private byte[] restructureData(byte[] data, DataHeader header) {
// 根据新格式的数据结构和Impala存储要求,重新组织数据内容
System.out.println("Restructuring data...");
return data;
}
private void updateMetadata(byte[] data, Metadata metadata) {
// 更新数据的元数据信息,包括存储位置、时间戳、访问权限等
System.out.println("Updating metadata...");
}
// 内部类,代表数据头部信息,包含数据类型、长度、编码方式等属性
class DataHeader {
private String dataType;
private int length;
private String encoding;
// 构造函数和访问方法
public DataHeader(String dataType, int length, String encoding) {
this.dataType = dataType;
this.length = length;
this.encoding = encoding;
}
public String getDataType() {
return dataType;
}
public int getLength() {
return length;
}
public String getEncoding() {
return encoding;
}
}
// 元数据类,用于携带数据相关的额外信息,如数据来源、创建时间、所有者等
class Metadata {
private String source;
private long timestamp;
private String owner;
// 构造函数和访问方法
public Metadata(String source, long timestamp, String owner) {
this.source = source;
this.timestamp = timestamp;
}
public String getSource() {
return source;
}
public long getTimestamp() {
return timestamp;
}
public String getOwner() {
return owner;
}
}
}
在计算层,与新兴的计算框架携手,就像是为这台超级引擎安装了更先进的动力系统。例如,当与分布式计算框架融合时,要充分利用其新特性,这不仅涉及到任务调度和资源分配的优化,还需要考虑计算模型的兼容性和数据并行处理的效率。以下是一个更完善的任务调度模拟代码,展示了如何在复杂的计算环境中实现高效的任务调度:
// 模拟Impala与新计算框架的任务调度器,负责管理和分配计算任务,以优化资源利用和提高计算效率
class TaskScheduler {
private List<Task> taskQueue;
private int availableCores;
private Map<Task, ResourceAllocation> resourceMap;
private ComputingFramework framework;
public TaskScheduler(int cores, ComputingFramework framework) {
taskQueue = new ArrayList<>();
availableCores = cores;
resourceMap = new HashMap<>();
this.framework = framework;
}
// 添加任务到任务队列,并根据任务类型和计算框架的特性进行资源预分配
public void addTask(Task task) {
taskQueue.add(task);
ResourceAllocation allocation = framework.allocateResources(task);
resourceMap.put(task, allocation);
}
// 执行任务调度,根据资源分配情况和核心可用性,将任务分配到计算核心上执行
public void scheduleTasks() {
while (!taskQueue.isEmpty() && availableCores > 0) {
Task currentTask = selectTask();
if (currentTask!= null) {
ResourceAllocation allocation = resourceMap.get(currentTask);
allocateCores(allocation);
currentTask.execute();
releaseCores(allocation);
availableCores -= allocation.getCoresRequired();
}
}
}
private Task selectTask() {
// 根据任务优先级、数据依赖关系、资源需求等因素选择下一个要执行的任务
System.out.println("Selecting task based on priority, data dependencies, and resource requirements...");
return taskQueue.remove(0);
}
private void allocateCores(ResourceAllocation allocation) {
// 将分配的计算核心分配给任务,可能涉及到操作系统级别的资源分配和进程管理
System.out.println("Allocating " + allocation.getCoresRequired() + " cores to task...");
}
private void releaseCores(ResourceAllocation allocation) {
// 任务完成后释放计算核心,更新资源状态
System.out.println("Releasing " + allocation.getCoresRequired() + " cores from task...");
}
// 内部任务类,代表在Impala与新技术融合环境下的计算任务,包含任务执行逻辑和相关属性
class Task {
private String name;
private int priority;
private List<DataDependency> dependencies;
public Task(String name, int priority, List<DataDependency> dependencies) {
this.name = name;
this.priority = priority;
this.dependencies = dependencies;
}
public void execute() {
// 这里是任务的具体执行逻辑,可能涉及到数据读取、计算、结果存储等操作
System.out.println("Executing task: " + name + " with priority " + priority);
// 模拟数据读取
readData();
// 模拟计算操作
performComputation();
// 模拟结果存储
storeResult();
}
private void readData() {
System.out.println("Reading data for task...");
}
private void performComputation() {
System.out.println("Performing computation for task...");
}
private void storeResult() {
System.out.println("Storing result for task...");
}
public String getName() {
return name;
}
public int getPriority() {
return priority;
}
public List<DataDependency> getDependencies() {
return dependencies;
}
}
// 资源分配类,记录任务所需的计算核心数量、内存大小等资源信息
class ResourceAllocation {
private int coresRequired;
private int memoryRequired;
public ResourceAllocation(int cores, int memory) {
coresRequired = cores;
memoryRequired = memory;
}
public int getCoresRequired() {
return coresRequired;
}
public int getMemoryRequired() {
return memoryRequired;
}
}
// 数据依赖类,用于表示任务之间的数据依赖关系
class DataDependency {
private Task sourceTask;
private String dataField;
public DataDependency(Task sourceTask, String dataField) {
this.sourceTask = sourceTask;
}
public Task getSourceTask() {
return sourceTask;
}
public String getDataField() {
return dataField;
}
}
// 计算框架抽象类,定义了计算框架的基本行为,如资源分配、任务执行等
abstract class ComputingFramework {
public abstract ResourceAllocation allocateResources(Task task);
public abstract void executeTask(Task task);
}
}
1.2 数据交互的新协议与接口
数据交互是 Impala 与新技术融合的桥梁,新的数据交互协议恰似这座桥梁的精心设计蓝图,每一个细节都关乎数据传输的准确性和效率。在与实时数据处理技术融合时,采用新的流数据协议,这要求我们像打造高精度的通信网络一样,精心设计和优化每一个环节,确保数据在 Impala 和新系统之间的准确、快速传输。以下是一个更详细、更健壮的数据接收接口和处理示例,考虑了数据完整性检查、错误处理和异步处理等功能:
// 新的数据接收接口,用于处理不同类型的流数据,确保数据的可靠接收和处理
interface NewDataReceiver {
void receiveData(String dataStream, Metadata metadata);
void handleError(Throwable error);
void setDataCallback(DataCallback callback);
}
// Impala实现新数据接收接口,用于处理接收到的数据,包括数据缓冲、元数据解析、错误处理和异步回调
class ImpalaNewDataReceiver implements NewDataReceiver {
// 存储接收到的数据的缓冲区,采用先进先出队列结构
private Queue<String> dataBuffer;
// 用于存储接收数据过程中发生的错误信息
private List<Throwable> errorList;
// 数据处理完成后的回调接口,用于通知数据使用者
private DataCallback callback;
public ImpalaNewDataReceiver() {
dataBuffer = new LinkedList<>();
errorList = new ArrayList<>();
}
// 接收数据方法,将数据添加到缓冲区,并在合适的时候触发数据处理
@Override
public void receiveData(String dataStream, Metadata metadata) {
if (isDataValid(dataStream, metadata)) {
dataBuffer.add(dataStream);
if (dataBuffer.size() >= MIN_BUFFER_SIZE) {
processDataBuffer();
}
} else {
handleError(new DataInvalidException("Invalid data received"));
}
}
// 检查数据的有效性,包括数据格式、长度、校验和等
private boolean isDataValid(String dataStream, Metadata metadata) {
// 这里可以添加复杂的数据验证逻辑,如检查数据格式是否符合协议要求、长度是否在预期范围内、校验和是否正确等
System.out.println("Validating data...");
return true;
}
// 处理数据缓冲区中的数据,包括解析元数据、处理数据内容和触发回调
private void processDataBuffer() {
while (!dataBuffer.isEmpty()) {
String data = dataBuffer.remove();
try {
Metadata metadata = parseMetadata(data);
processData(data, metadata);
} catch (Exception e) {
handleError(e);
}
}
if (callback!= null) {
callback.onDataProcessed();
}
}
// 解析元数据,从数据中提取相关的元信息
private Metadata parseMetadata(String data) {
// 这里可以根据数据格式和协议解析元数据,如数据来源、时间戳、数据类型等
System.out.println("Parsing metadata...");
return new Metadata("unknown", System.currentTimeMillis());
}
// 处理数据内容,这里可以是对接收数据的复杂处理逻辑,比如解析、存储、分析等
private void processData(String data, Metadata metadata) {
System.out.println("Processing data: " + data + " with metadata: " + metadata.toString());
}
// 处理接收数据过程中发生的错误,记录错误信息并根据错误类型采取相应的措施
@Override
public void handleError(Throwable error) {
errorList.add(error);
// 根据错误类型,可以选择重试、通知管理员、调整接收参数等操作
if (error instanceof NetworkError) {
// 处理网络连接错误,例如重新连接
System.out.println("Network error occurred. Retrying connection...");
} else if (error instanceof DataFormatError) {
// 处理数据格式错误,例如调整数据解析参数
System.out.println("Data format error occurred. Adjusting parsing parameters...");
}
}
// 设置数据处理完成后的回调接口
@Override
public void setDataCallback(DataCallback callback) {
this.callback = callback;
}
// 元数据类,用于携带数据相关的额外信息
class Metadata {
private String source;
private long timestamp;
// 构造函数和访问方法
public Metadata(String source, long timestamp) {
this.source = source;
this.timestamp = timestamp;
}
public String getSource() {
return source;
}
public long getTimestamp() {
return timestamp;
}
@Override
public String toString() {
return "Metadata{source='" + source + "', timestamp=" + timestamp + '}';
}
}
// 数据回调接口,用于在数据处理完成后通知数据使用者
interface DataCallback {
void onDataProcessed();
}
// 自定义异常类,用于表示数据无效的情况
class DataInvalidException extends Exception {
public DataInvalidException(String message) {
super(message);
}
}
// 自定义异常类,用于表示网络错误的情况
class NetworkError extends Exception {
public NetworkError(String message) {
super(message);
}
}
// 自定义异常类,用于表示数据格式错误的情况
class DataFormatError extends Exception {
public DataFormatError(String message) {
super(message);
}
}
}
同时,接口的设计要考虑到可扩展性和兼容性,就像设计一座能适应未来各种交通工具的通用桥梁一样。当新的数据源或者数据类型出现时,接口能够轻松应对,而不是需要大规模的重构。这需要运用先进的设计模式和灵活的架构思维。以下是一个使用接口扩展来处理新数据类型的示例,展示了如何在不破坏现有接口的情况下添加对新数据类型的支持:
// 新的图像数据接口,扩展自新数据接收接口,用于处理特定类型的图像数据
interface ImageDataReceiver extends NewDataReceiver {
void receiveImageData(Image image, Metadata metadata);
}
// Impala 实现图像数据接收接口,用于处理图像数据,包括图像解码、特征提取和与其他数据的融合处理
class ImpalaImageDataReceiver implements ImageDataReceiver {
@Override
public void receiveData(String dataStream, Metadata metadata) {
// 对于非图像数据,可以采用默认处理方式或抛出异常,这里选择抛出异常,因为此接收器专门用于处理图像数据
throw new UnsupportedOperationException("This receiver only handles image data.");
}
@Override
public void receiveImageData(Image image, Metadata metadata) {
// 对图像数据进行解码操作,这里假设使用某种图像解码库
Image decodedImage = decodeImage(image);
// 提取图像特征,这可能涉及到复杂的图像处理算法
List<Feature> features = extractFeatures(decodedImage);
// 将图像特征与其他相关数据进行融合处理,例如与已有的用户数据或业务数据结合
Data fusedData = fuseData(features, metadata);
// 存储融合后的数据,这里省略实际存储操作
storeData(fusedData);
// 可以添加更多针对图像数据的处理逻辑,如根据特征进行分类、识别等
classifyImage(features);
}
private Image decodeImage(Image image) {
// 这里是图像解码的逻辑,假设使用简单的模拟解码过程
System.out.println("Decoding image...");
return image;
}
private List<Feature> extractFeatures(Image image) {
// 提取图像特征的示例方法,这里可以使用更复杂的算法,如卷积神经网络等
System.out.println("Extracting features from image...");
Feature feature1 = new Feature("Edge Count", 100);
Feature feature2 = new Feature("Color Histogram", new int[]{10, 20, 30});
return Arrays.asList(feature1, feature2);
}
private Data fuseData(List<Feature> features, Metadata metadata) {
// 将图像特征与其他数据融合的逻辑,这里简单创建一个新的数据对象
System.out.println("Fusing data...");
return new Data(features, metadata);
}
private void storeData(Data data) {
System.out.println("Storing fused data...");
}
private void classifyImage(List<Feature> features) {
// 根据图像特征进行分类的示例逻辑,这里只是简单打印分类结果
System.out.println("Classifying image based on features...");
}
// 简单的图像类,代表新的数据类型(图像),包含图像的基本属性,如宽度、高度、像素数据等
class Image {
private int width;
private int height;
private byte[] pixelData;
public Image(int width, int height, byte[] pixelData) {
this.width = width;
this.height = height;
this.pixelData = pixelData;
}
public int getWidth() {
return width;
}
public int getHeight() {
return height;
}
public byte[] getPixelData() {
return pixelData;
}
}
// 特征类,用于表示图像的特征,包含特征名称和特征值
class Feature {
private String name;
private Object value;
public Feature(String name, Object value) {
this.name = name;
this.value = value;
}
public String getName() {
return name;
}
public Object getValue() {
return value;
}
}
// 数据类,用于存储融合后的图像特征和相关元数据
class Data {
private List<Feature> features;
private Metadata metadata;
public Data(List<Feature> features, Metadata metadata) {
this.features = features;
this.metadata = metadata;
}
public List<Feature> getFeatures() {
return features;
}
public Metadata getMetadata() {
return metadata;
}
}
}
二、Impala在电商巨头A的新技术实践:真实案例展示
2.1 电商场景下的性能挑战与目标
电商巨头A犹如一座数据的超级大都市,每天要处理海量的用户数据、订单数据、商品数据等,这些数据就像川流不息的车辆在城市的道路上穿梭。在促销活动期间,数据洪流更是如汹涌澎湃的海啸,数据量呈指数级爆发式增长。传统的Impala配置在处理这些数据时,仿佛是老旧的城市交通系统在面对高峰时段的巨大压力,陷入了严重的瘫痪状态,面临着诸多棘手的性能瓶颈。
例如,查询响应时间过长,就像顾客在拥堵的超市结账时,需要漫长的等待,严重影响了用户体验。数据分析结果延迟,仿佛物流配送信息在错综复杂的网络中迷失,迟迟不能更新,这使得企业无法及时掌握市场动态,进而影响运营决策。为了提升用户体验,精准把握市场动态,电商巨头A决定引入新技术与Impala融合,目标是在高并发场景下,将关键查询的响应时间缩短50%,同时提高数据分析的实时性和准确性,这就像是要对整个数据交通系统进行全面升级和优化,打造一套高效、智能的交通网络。
深入分析这些性能挑战,我们发现查询响应时间长主要是由于传统存储结构在大规模数据检索时的低效,以及计算资源分配不合理导致的。数据分析延迟则是因为数据处理流程的串行化和缺乏实时数据处理机制。例如,在查询用户购买历史以进行个性化推荐时,传统系统需要遍历大量的历史订单数据,而没有有效的索引和缓存机制。在处理促销活动期间的实时订单数据时,系统不能及时更新分析模型,导致对库存和销售趋势的判断滞后。
2.2 新技术融合方案与实施过程
电商巨头A采用了多种新技术融合方案,如同为这座数据大都市打造了一套全新的智能交通网络,每个方案都针对特定的性能瓶颈进行了优化。
在数据存储方面,引入了分布式存储新技术,将不同类型的数据(用户画像、订单详情、商品属性等)按照新的规则存储,这就好比为不同类型的车辆(数据)规划了专属的车道和停车场,提高数据读取效率。新的存储技术采用了分布式哈希表(DHT)和数据分片策略,根据数据的特征(如用户ID、订单时间等)将数据均匀分布在多个存储节点上。以下是创建新的数据存储表结构以及数据存储操作的更详细代码示例:
-- 示例SQL用于创建新的数据存储表结构,这里使用了分区表和分布式存储相关的特性
CREATE TABLE new_ecommerce_data_storage (
id INT,
data_type VARCHAR(50),
data_value VARCHAR(1000),
-- 根据数据类型和业务需求添加更多字段,如用户ID、订单时间、商品分类等
user_id INT,
order_time TIMESTAMP,
product_category VARCHAR(50),
-- 分布式存储相关的分区字段,用于数据分片
partition_key VARCHAR(50) GENERATED ALWAYS AS (CASE
WHEN data_type = 'user_profile' THEN CONCAT('user_', user_id)
WHEN data_type = 'order_detail' THEN CONCAT('order_', id)
WHEN data_type = 'product_info' THEN CONCAT('product_', product_category)
ELSE 'unknown'
END),
PRIMARY KEY (id, partition_key)
) DISTRIBUTED BY (partition_key) PARTITION BY LIST (partition_key) (
PARTITION user_data VALUES IN ('user_*'),
PARTITION order_data VALUES IN ('order_*'),
PARTITION product_data VALUES IN ('product_*'),
PARTITION other_data VALUES IN ('unknown')
);
-- 插入数据示例,这里模拟插入用户画像数据、订单数据和商品数据
INSERT INTO new_ecommerce_data_storage (id, data_type, data_value, user_id, order_time, product_category)
VALUES
(1, 'user_profile', '{"name":"John Doe", "age":30, "preferences":["books", "movies"]}', 1001, NULL, NULL),
(2, 'order_detail', '{"order_id":1001, "user_id":1001, "product_id":2001, "quantity":2, "price":19.99, "order_time":"2024-01-01 10:00:00"}', 1001, '2024-01-01 10:00:00', NULL),
(3, 'product_info', '{"product_id":2001, "name":"Smartphone", "category":"Electronics", "description":"High-performance smartphone"}', NULL, NULL, 'Electronics');
这种存储结构的优势在于,当查询用户相关数据时,系统可以直接定位到对应的分区(用户分区)进行快速检索,而无需遍历整个数据集。对于订单数据和商品数据同理。同时,存储系统还采用了数据冗余和备份策略,确保数据的高可用性。例如,每个数据分片在不同的存储节点上有多个副本,通过一致性算法(如 RAFT 协议)来保证副本之间的一致性。
在计算方面,结合了新型的实时计算框架,让 Impala 能够更快地处理实时订单数据和用户行为数据,就像为快递车辆配备了高速引擎。通过修改 Impala 的配置文件和编写适配代码,实现与新框架的无缝对接。
首先,修改 Impala 的配置文件,启用与新计算框架的集成功能,并配置相关参数,如连接地址、认证信息等。以下是一个更详细的配置文件修改示例(假设是一个基于 XML 的配置):
<?xml version="1.0" encoding="UTF-8"?>
<impala-configuration>
<!-- 原始的配置项 -->
<property>
<name>query_execution_timeout</name>
<value>300</value>
</property>
<!-- 添加新的配置项,用于与新计算框架集成 -->
<property>
<name>new_computing_framework_enabled</name>
<value>true</value>
</property>
<property>
<name>new_framework_connection_string</name>
<value>tcp://new-framework-server:8080</value>
</property>
<property>
<name>new_framework_authentication_type</name>
<value>token</value>
</property>
<property>
<name>new_framework_token</name>
<value>abcdef1234567890</value>
</property>
<property>
<name>new_framework_data_format</name>
<value>protobuf</value>
</property>
<property>
<name>new_framework_task_parallelism</name>
<value>10</value>
</property>
</impala-configuration>
然后,编写适配代码来处理数据在 Impala 和新计算框架之间的传递和交互。适配代码主要包括数据序列化和反序列化模块、任务调度模块以及结果处理模块。
数据序列化和反序列化模块负责将 Impala 中的数据转换为新计算框架能够识别的格式(如 Protocol Buffers),反之亦然。以下是一个简单的数据序列化和反序列化示例代码:
// 数据序列化和反序列化工具类,用于在Impala和新计算框架之间转换数据格式
class DataSerializerDeserializer {
// 将Impala数据对象转换为Protocol Buffers格式的字节数组
public byte[] serializeToProtobuf(ImpalaDataObject data) {
try {
// 使用Protocol Buffers库生成字节数组,这里假设ImpalaDataObject有对应的.proto文件定义
YourProtobufObject.Builder builder = YourProtobufObject.newBuilder();
// 设置Protobuf对象的字段值,根据ImpalaDataObject的属性进行映射
builder.setField1(data.getField1());
builder.setField2(data.getField2());
return builder.build().toByteArray();
} catch (Exception e) {
// 处理序列化过程中的错误
System.err.println("Error during data serialization: " + e.getMessage());
return new byte[0];
}
}
// 将Protocol Buffers格式的字节数组转换为Impala数据对象
public ImpalaDataObject deserializeFromProtobuf(byte[] protobufData) {
try {
YourProtobufObject protobufObject = YourProtobufObject.parseFrom(protobufData);
// 根据Protobuf对象的字段值创建Impala数据对象
return new ImpalaDataObject(protobufObject.getField1(), protobufObject.getField2());
} catch (Exception e) {
// 处理反序列化过程中的错误
System.err.println("Error during data deserialization: " + e.getMessage());
return null;
}
}
}
// 假设的Impala数据对象类,包含业务相关的数据字段
class ImpalaDataObject {
private String field1;
private int field2;
public ImpalaDataObject(String field1, int field2) {
this.field1 = field1;
this.field2 = field2;
}
public String getField1() {
return field1;
}
public int getField2() {
return field2;
}
}
任务调度模块负责将 Impala 中的计算任务分配到新计算框架中的合适节点上执行。它根据任务的类型、数据依赖关系和计算资源的可用性来进行任务调度。以下是一个更完善的任务调度示例代码:
// Impala 与新计算框架的任务调度器,负责根据任务特征和资源情况分配任务到新计算框架的节点上执行
class ImpalaNewFrameworkTaskScheduler {
private NewComputingFrameworkClient client;
private TaskQueue taskQueue;
private ResourceManager resourceManager;
public ImpalaNewFrameworkTaskScheduler(NewComputingFrameworkClient client) {
this.client = client;
taskQueue = new TaskQueue();
resourceManager = new ResourceManager();
}
// 将 Impala 中的任务添加到任务队列中,同时分析任务资源需求并更新资源管理器
public void addTask(ImpalaTask task) {
taskQueue.add(task);
ResourceAllocation allocation = analyzeTaskResourceRequirements(task);
resourceManager.updateResourceAllocation(allocation);
}
// 执行任务调度,根据资源分配情况和任务优先级将任务分配到新计算框架的节点上执行
public void scheduleTasks() {
while (!taskQueue.isEmpty()) {
ImpalaTask task = selectTask();
if (task!= null) {
Node node = selectNode(task);
if (node!= null) {
allocateResources(task, node);
executeTask(task, node);
releaseResources(task, node);
}
}
}
}
private ImpalaTask selectTask() {
// 根据任务优先级、数据依赖关系和等待时间等因素选择下一个要执行的任务
return taskQueue.poll();
}
private Node selectNode(ImpalaTask task) {
// 根据任务的资源需求、数据位置和节点负载情况选择合适的执行节点
return resourceManager.findAvailableNode(task);
}
private void allocateResources(ImpalaTask task, Node node) {
// 在选定的节点上为任务分配计算资源,如 CPU 核心、内存等
resourceManager.allocate(node, task.getResourceRequirements());
}
private void executeTask(ImpalaTask task, Node node) {
// 将任务发送到选定的节点上执行,通过新计算框架的客户端接口
client.sendTaskToNode(task, node);
}
private void releaseResources(ImpalaTask task, Node node) {
// 任务完成后,释放节点上分配的资源
resourceManager.release(node, task.getResourceRequirements());
}
private ResourceAllocation analyzeTaskResourceRequirements(ImpalaTask task) {
// 分析任务的资源需求,根据任务类型、数据量等因素估算所需的 CPU 核心数、内存大小等资源
return new ResourceAllocation(1, 1024); // 这里只是示例,实际需要更详细的计算
}
// 内部类,代表 Impala 中的计算任务,包含任务属性和执行逻辑
class ImpalaTask {
private String name;
private TaskType type;
private DataDependency dataDependency;
private ResourceRequirements resourceRequirements;
public ImpalaTask(String name, TaskType type, DataDependency dataDependency, ResourceRequirements resourceRequirements) {
this.name = name;
this.type = type;
this.dataDependency = dataDependency;
this.resourceRequirements = resourceRequirements;
}
public String getName() {
return name;
}
public TaskType getType() {
return type;
}
public DataDependency getDataDependency() {
return dataDependency;
}
public ResourceRequirements getResourceRequirements() {
return resourceRequirements;
}
}
// 任务类型枚举,例如查询任务、分析任务、更新任务等
enum TaskType {
QUERY, ANALYSIS, UPDATE
}
// 数据依赖类,用于表示任务之间的数据依赖关系
class DataDependency {
private ImpalaTask sourceTask;
private String dataField;
public DataDependency(ImpalaTask sourceTask, String dataField) {
this.sourceTask = sourceTask;
this.dataField = dataField;
}
public ImpalaTask getSourceTask() {
return sourceTask;
}
public String getDataField() {
return dataField;
}
}
// 资源需求类,记录任务所需的计算资源,如 CPU 核心数、内存大小等
class ResourceRequirements {
private int cpuCores;
private int memorySize;
public ResourceRequirements(int cpuCores, int memorySize) {
this.cpuCores = cpuCores;
this.memorySize = memorySize;
}
public int getCpuCores() {
return cpuCores;
}
public int getMemorySize() {
return memorySize;
}
}
// 节点类,代表新计算框架中的计算节点,包含节点资源信息和状态
class Node {
private String nodeId;
private int availableCores;
private int availableMemory;
private boolean isAvailable;
public Node(String nodeId, int availableCores, int availableMemory) {
this.nodeId = nodeId;
this.availableCores = availableCores;
this.availableMemory = availableMemory;
this.isAvailable = true;
}
public String getNodeId() {
return nodeId;
}
public int getAvailableCores() {
return availableCores;
}
public int getAvailableMemory() {
return availableMemory;
}
public boolean isAvailable() {
return isAvailable;
}
public void setAvailable(boolean available) {
isAvailable = available;
}
}
// 任务队列类,用于存储等待执行的 Impala 任务
class TaskQueue extends LinkedList<ImpalaTask> { }
// 资源管理器类,负责管理新计算框架中的计算资源分配和节点状态
class ResourceManager {
private List<Node> nodes;
public ResourceManager() {
nodes = new ArrayList<>();
// 初始化节点列表,这里假设创建 3 个节点,每个节点有不同的资源配置
nodes.add(new Node("node1", 4, 4096));
nodes.add(new Node("node2", 8, 8192));
nodes.add(new Node("node3", 2, 2048));
}
public void updateResourceAllocation(ResourceAllocation allocation) {
// 根据资源分配情况更新节点的可用资源信息
for (Node node : nodes) {
if (node.isAvailable()) {
node.setAvailable(false);
node.setAvailableCores(node.getAvailableCores() - allocation.getCpuCores());
node.setAvailableMemory(node.getAvailableMemory() - allocation.getMemorySize());
break;
}
}
}
public Node findAvailableNode(ImpalaTask task) {
// 根据任务的资源需求和节点的可用资源情况查找合适的执行节点
for (Node node : nodes) {
if (node.isAvailable() && node.getAvailableCores() >= task.getResourceRequirements().getCpuCores() && node.getAvailableMemory() >= task.getResourceRequirements().getMemorySize()) {
return node;
}
}
return null;
}
public void allocate(Node node, ResourceRequirements requirements) {
// 在指定节点上分配资源
node.setAvailableCores(node.getAvailableCores() - requirements.getCpuCores());
node.setAvailableMemory(node.getAvailableMemory() - requirements.getMemorySize());
}
public void release(Node node, ResourceRequirements requirements) {
// 释放指定节点上的资源
node.setAvailableCores(node.getAvailableCores() + requirements.getCpuCores());
node.setAvailableMemory(node.getAvailableMemory() + requirements.getMemorySize());
if (node.getAvailableCores() > 0 && node.getAvailableMemory() > 0) {
node.setAvailable(true);
}
}
}
// 新计算框架的客户端类,用于与新计算框架进行通信,发送任务和接收结果
class NewComputingFrameworkClient {
private String connectionString;
private Connection connection;
public NewComputingFrameworkClient(String connectionString) {
this.connectionString = connectionString;
// 初始化与新计算框架的连接,这里省略实际连接建立过程
initializeConnection();
}
private void initializeConnection() {
// 这里可以添加连接初始化逻辑,如创建套接字连接、进行认证等
System.out.println("Initializing connection to new computing framework...");
}
public void sendTaskToNode(ImpalaTask task, Node node) {
// 将任务序列化后发送到指定节点,通过网络连接
byte[] serializedTask = serializeTask(task);
sendData(serializedTask, node.getNodeId());
}
private byte[] serializeTask(ImpalaTask task) {
// 使用数据序列化工具将任务对象转换为字节数组
return new DataSerializerDeserializer().serializeToProtobuf(task);
}
private void sendData(byte[] data, String nodeId) {
// 这里模拟发送数据到指定节点的操作,实际可能涉及网络传输和协议处理
System.out.println("Sending data to node " + nodeId + " of new computing framework...");
}
public ImpalaTask receiveResultFromNode(Node node) {
// 从指定节点接收结果数据,并反序列化得到 Impala 任务对象
byte[] resultData = receiveData(node.getNodeId());
return new DataSerializerDeserializer().deserializeFromProtobuf(resultData);
}
private byte[] receiveData(String nodeId) {
// 这里模拟从指定节点接收数据的操作,实际可能涉及网络接收和协议处理
System.out.println("Receiving data from node " + nodeId + " of new computing framework...");
return new byte[0];
}
}
}
结果处理模块负责接收新计算框架处理后的结果,并将其转换为Impala能够理解的格式,然后更新到Impala的相关数据结构或返回给用户。以下是一个简单的结果处理示例代码:
// 结果处理类,用于接收新计算框架的处理结果,并在Impala中进行相应的处理
class ResultProcessor {
private ImpalaDataStore dataStore;
public ResultProcessor(ImpalaDataStore dataStore) {
this.dataStore = dataStore;
}
// 处理从新计算框架接收到的结果,将其存储到Impala数据存储中或进行其他相关操作
public void processResult(ImpalaTask task, byte[] resultData) {
// 反序列化结果数据为Impala结果对象
ImpalaResult result = deserializeResult(resultData);
// 根据任务类型和结果内容进行相应的处理
if (task.getType() == ImpalaNewFrameworkTaskScheduler.TaskType.QUERY) {
processQueryResult(task, result);
} else if (task.getType() == ImpalaNewFrameworkTaskScheduler.TaskType.ANALYSIS) {
processAnalysisResult(task, result);
} else if (task.getType() == ImpalaNewFrameworkTaskScheduler.TaskType.UPDATE) {
processUpdateResult(task, result);
}
}
private ImpalaResult deserializeResult(byte[] resultData) {
// 使用数据序列化工具将字节数组反序列化为Impala结果对象
return new DataSerializerDeserializer().deserializeFromProtobuf(resultData);
}
private void processQueryResult(ImpalaTask task, ImpalaResult result) {
// 将查询结果存储到Impala数据存储中或返回给用户,这里假设存储到一个临时结果表中
dataStore.storeQueryResult(task.getName(), result);
}
private void processAnalysisResult(ImpalaTask task, ImpalaResult result) {
// 根据分析结果更新Impala中的相关数据结构或模型,例如更新用户画像、商品推荐模型等
updateAnalysisModel(task, result);
}
private void processUpdateResult(ImpalaTask task, ImpalaResult result) {
// 处理更新任务的结果,例如更新订单状态、库存信息等
updateData(task, result);
}
private void updateAnalysisModel(ImpalaTask task, ImpalaResult result) {
// 这里是根据分析结果更新分析模型的逻辑,例如使用机器学习算法更新用户画像或商品推荐模型
System.out.println("Updating analysis model based on result...");
}
private void updateData(ImpalaTask task, ImpalaResult result) {
// 这里是根据更新任务结果更新数据的逻辑,例如更新订单状态、库存信息等
System.out.println("Updating data based on result...");
}
// 假设的Impala数据存储类,用于存储查询结果和其他相关数据
class ImpalaDataStore {
public void storeQueryResult(String queryName, ImpalaResult result) {
// 这里是将查询结果存储到Impala数据存储中的逻辑,例如插入到临时结果表中
System.out.println("Storing query result for " + queryName + " in Impala data store...");
}
}
// 假设的Impala结果对象类,包含任务执行结果的相关数据
class ImpalaResult {
// 这里可以定义结果对象的属性,如查询结果集、分析指标、更新状态等
}
}
通过这些新技术融合方案的实施,电商巨头 A 成功地优化了 Impala 在电商场景下的性能。以下是详细的性能指标对比表格,不仅展示了新旧系统在关键性能指标上的差异,还深入分析了这些改进背后的技术原因:
| 阶段 | 性能指标 | 旧系统表现 | 新技术融合后表现 | 性能提升原因分析 |
|---|---|---|---|---|
| 日常运营 | 关键查询平均响应时间 | 3 秒 | 1.2 秒 | 新的存储结构通过分区和分布式存储,减少了数据检索时间。实时计算框架优化了任务调度和执行,提高了计算效率。 |
| 促销活动高峰 | 数据分析延迟时间 | 10 分钟 | 3 分钟 | 存储系统的实时数据处理能力和新计算框架的并行计算能力,使数据分析能够更快地处理大量实时订单数据。同时,数据更新机制更加高效,能及时反映市场变化。 |
| 长期数据洞察 | 数据准确性(预测订单量与实际偏差) | 15% | 5% | 新的存储和计算技术结合,使得数据的完整性和实时性更好。分析模型能够更及时地更新,从而更准确地捕捉市场趋势和用户行为变化。 |
2.3 融合后的成效与业务价值
经过新技术融合,电商巨头 A 在业务上取得了巨大成功,宛如浴火重生的凤凰,焕发出全新的活力。用户体验得到了前所未有的提升,页面加载速度如闪电般迅速,用户在浏览商品时就像在宽敞无阻的高速公路上自由驰骋,无需再忍受漫长的等待。个性化推荐更加精准,仿佛有一位贴心的专属导购员,总能准确洞察用户的喜好和需求,这使得用户购买转化率大幅提高,销售额如同火箭般飙升。
在促销活动期间,电商巨头 A 能够实时调整商品推荐策略,就像一位经验丰富的指挥家根据现场情况灵活调整乐队演奏一样。通过实时分析用户行为和订单数据,系统可以迅速将热门商品和相关推荐推送给用户,大大提高了用户的购买欲望和购买频率,销售额相比以往促销活动提升了 30%。同时,库存管理更加精准,减少了积压和缺货情况,避免了因库存问题导致的销售损失。新的存储和计算技术能够实时监控商品库存的变化,根据销售趋势和预测订单量及时补货或调整库存策略,使库存周转率提高了 40%。
通过对长期数据的更准确分析,电商巨头 A 提前预测市场趋势,为企业战略决策提供了有力支持,就像拥有了一台精准的市场预测雷达。企业可以提前布局热门商品品类,优化供应链管理,降低采购成本。例如,通过对用户搜索和浏览数据的深度分析,提前预测到某类电子产品在特定季节的需求高峰,提前增加库存和优化物流配送,确保在销售旺季能够满足用户需求,同时避免了因库存积压造成的损失。这一系列的改进不仅提升了企业的盈利能力,还增强了企业在市场中的竞争力,巩固了其在电商行业的领先地位。
三、Impala 与新技术融合的拓展方向:未来展望与探索
3.1 跨行业应用的潜力挖掘
除了电商领域,Impala 与新技术融合在其他行业也有着如宇宙星辰般璀璨的潜力,如同打开了一扇通往无数新世界的大门。
在医疗行业,与医疗影像处理技术结合,就像为医生配备了一双拥有超能力的透视眼,能够快速、准确地分析大量的影像数据,辅助医生进行诊断。例如,在处理 X 光、CT、MRI 等影像时,通过融合新技术实现图像特征的快速提取和疾病模式的识别,能够大大提高诊断效率和准确性。以下是一个更复杂、更接近实际应用的医疗影像特征提取和疾病诊断代码示例(使用 Python 和相关的医学图像处理库):
import cv2
import numpy as np
import pydicom
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 读取DICOM格式的医疗影像数据(这里假设是一个简单的CT影像文件)
def read_dicom_image(file_path):
dataset = pydicom.dcmread(file_path)
image = dataset.pixel_array
return image
# 预处理医疗影像数据,包括归一化、去噪等操作
def preprocess_image(image):
# 归一化图像像素值到0 - 1范围
normalized_image = image / np.max(image)
# 简单的高斯去噪
denoised_image = cv2.GaussianBlur(normalized_image, (3, 3), 0)
return denoised_image
# 提取医疗影像的特征,这里使用多种特征提取方法,如纹理特征、形状特征等
def extract_features(image):
# 计算灰度共生矩阵(GLCM)以获取纹理特征
glcm = cv2.calcGLCM(image, [1], [0], 256, symmetric=True, normed=True)
contrast = cv2.contrastGLCM(glcm)
correlation = cv2.correlationGLCM(glcm)
energy = cv2.energyGLCM(glcm)
homogeneity = cv2.homogeneityGLCM(glcm)
# 计算形状特征,这里简单计算图像的面积和周长(假设图像是二值化的)
contours, _ = cv2.findContours((image > 0.5).astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
area = sum([cv2.contourArea(c) for c in contours])
perimeter = sum([cv2.arcLength(c, True) for c in contours])
return np.array([contrast, correlation, energy, homogeneity, area, perimeter])
# 加载医疗影像数据和对应的诊断标签(这里假设数据已经整理好,存储在一个目录下)
def load_data(data_dir):
images = []
labels = []
for file in os.listdir(data_dir):
if file.endswith('.dcm'):
file_path = os.path.join(data_dir, file)
image = read_dicom_image(file_path)
preprocessed_image = preprocess_image(image)
features = extract_features(preprocessed_image)
images.append(features)
# 假设文件名中包含诊断标签信息,这里简单提取
label = file.split('_')[0]
labels.append(label)
return np.array(images), np.array(labels)
# 使用随机森林分类器进行疾病诊断模型的训练和评估
def train_and_evaluate_model(images, labels):
X_train, X_test, y_train, y_test = train_test_split(images, labels, test_size=0.2, random_state=42)
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
return accuracy
# 主函数,演示医疗影像诊断流程
def main():
data_dir = 'path/to/medical/images'
images, labels = load_data(data_dir)
accuracy = train_and_evaluate_model(images, labels)
print("Disease diagnosis accuracy:", accuracy)
if __name__ == '__main__':
main()
在物流行业,结合物联网数据和路径规划算法,优化运输路线,降低成本,就像为每一个物流包裹都配备了一个超级智能的导航仪,能够根据实时路况、货物信息、车辆状态等因素选择最优路径。通过收集运输车辆的位置、速度、货物重量、温度等物联网数据,利用先进的路径规划算法计算最佳路线,减少运输时间和燃料消耗。以下是一个更高级的物流路径规划算法示例,考虑了更多的实际因素,如交通拥堵、货物时效性、运输成本等(使用 Python 和相关的优化算法库):
import networkx as nx
import numpy as np
import pandas as pd
from scipy.spatial.distance import cdist
from ortools.constraint_solver import routing_enums_pb2
from ortools.constraint_solver import pywrapcp
# 模拟物流网络节点信息,包括位置、货物处理能力等
nodes_data = pd.DataFrame({
'node_id': [1, 2, 3, 4, 5],
'latitude': [37.7749, 34.0522, 40.7128, 38.9072, 33.4484],
'longitude': [-122.4194, -118.2437, -74.0060, -77.0369, -112.0740],
'capacity': [100, 200, 150, 80, 120]
})
# 模拟运输车辆信息,包括车辆类型、载重、速度等
vehicles_data = pd.DataFrame({
'vehicle_id': [1, 2],
'type': ['truck', 'van'],
'load_capacity': [50, 30],
'max_speed': [60, 50]
})
# 模拟物流订单信息,包括起点、终点、货物重量、要求送达时间等
orders_data = pd.DataFrame({
'order_id': [1, 2, 3],
'start_node': [1, 2, 3],
'end_node': [4, 5, 1],
'weight': [20, 15, 30],
'delivery_time': ['2024-01-01 12:00:00', '2024-01-01 14:00:00', '2024-01-02 09:00:00']
})
# 模拟交通拥堵信息,以节点间的拥堵系数表示(0 - 1,0 表示无拥堵,1 表示严重拥堵)
congestion_matrix = np.array([
[0, 0.2, 0.3, 0.1, 0.4],
[0.2, 0, 0.5, 0.3, 0.2],
[0.3, 0.5, 0, 0.6, 0.1],
[0.1, 0.3, 0.6, 0, 0.5],
[0.4, 0.2, 0.1, 0.5, 0]
])
# 根据节点的经纬度计算节点间的距离矩阵
node_locations = nodes_data[['latitude', 'longitude']].values
distance_matrix = cdist(node_locations, node_locations)
# 创建物流网络图
graph = nx.DiGraph()
for i in range(len(nodes_data)):
graph.add_node(nodes_data['node_id'][i], capacity=nodes_data['capacity'][i])
for i in range(len(distance_matrix)):
for j in range(len(distance_matrix)):
graph.add_edge(nodes_data['node_id'][i], nodes_data['node_id'][j], distance=distance_matrix[i][j], congestion=congestion_matrix[i][j])
# 为每个订单分配合适的车辆并规划路径
def assign_vehicles_and_plan_routes(graph, vehicles_data, orders_data):
solution = {}
for _, order in orders_data.iterrows():
assigned_vehicle = None
best_route = None
best_cost = np.inf
for _, vehicle in vehicles_data.iterrows():
routing = pywrapcp.RoutingIndexManager(len(graph.nodes()), 1, [0], [len(graph.nodes()) - 1])
model = pywrapcp.RoutingModel(routing)
# 设置距离回调函数,考虑距离和拥堵情况
def distance_callback(from_index, to_index):
from_node = routing.IndexToNode(from_index)
to_node = routing.IndexToNode(to_index)
distance = graph[from_node][to_node]['distance']
congestion = graph[from_node][to_node]['congestion']
return distance * (1 + congestion)
model.SetArcCostEvaluatorOfAllVehicles(distance_callback)
# 设置车辆载重限制
def demand_callback(from_index):
from_node = routing.IndexToNode(from_index)
return graph.nodes[from_node]['capacity']
model.AddDimensionWithVehicleCapacity(demand_callback, 0, vehicle['load_capacity'], True, 'Capacity')
# 设置时间限制(这里简化为考虑订单要求送达时间和车辆速度)
def time_callback(from_index, to_index):
from_node = routing.IndexToNode(from_index)
to_node = routing.IndexToNode(to_index)
distance = graph[from_node][to_node]['distance']
speed = vehicle['max_speed']
return distance / speed
model.AddDimension(time_callback, 0, np.inf, True, 'Time')
search_parameters = pywrapcp.DefaultRoutingSearchParameters()
search_parameters.first_solution_strategy = routing_enums_pb2.FirstSolutionStrategy.PATH_CHEAPEST_ARC
assignment = model.SolveWithParameters(search_parameters)
if assignment:
route = []
index = routing.Start(0)
route_cost = 0
while not model.IsEnd(index):
node_index = routing.IndexToNode(index)
route.append(node_index)
previous_index = index
index = assignment.Value(model.NextVar(index))
route_cost += model.GetArcCostForVehicle(previous_index, index, 0)
route.append(routing.IndexToNode(index))
if route_cost < best_cost:
best_cost = route_cost
best_route = route
assigned_vehicle = vehicle['vehicle_id']
solution[order['order_id']] = {'vehicle': assigned_vehicle, 'route': best_route}
return solution
# 执行车辆分配和路径规划
solution = assign_vehicles_and_plan_routes(graph, vehicles_data, orders_data)
for order_id, result in solution.items():
print(f"Order {order_id}: Vehicle {result['vehicle']}, Route {result['route']}")
3.2 技术创新的持续推进
在技术层面,持续探索新的算法和模型与Impala的融合,如同在科技的广袤花园中精心培育出更加绚烂多彩的花朵。比如,将新兴的人工智能算法应用于数据挖掘和分析过程中,为企业挖掘出更有价值的信息金矿。
以深度学习中的卷积神经网络(CNN)为例,可用于分析具有空间结构的数据,如图像数据或地理信息数据。以下是一个更深入、更具实际应用场景的使用Python和TensorFlow库实现CNN的示例代码,用于图像分类任务:
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
from tensorflow.keras import datasets, layers, models
# 加载图像数据集(这里以CIFAR - 10数据集为例)
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 对数据进行归一化处理
train_images, test_images = train_images / 255.0, test_images / 255.0
# 构建一个更复杂的卷积神经网络模型,包含多个卷积层、池化层和全连接层
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
# 编译模型,指定损失函数、优化器和评估指标
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 训练模型,设置更多的训练参数,如训练轮次、批次大小等
history = model.fit(train_images, train_labels, epochs=10, batch_size=64, validation_data=(test_images, test_labels))
# 绘制训练和验证的准确率和损失曲线
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label='val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(latestructured_data_legend_elements)
plt.title('Training and Validation Accuracy')
plt.show()
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
同时,关注数据安全和隐私保护技术的发展,确保在融合过程中数据的安全性,这就像为数据穿上坚不可摧的铠甲,使其在复杂的网络环境中安然无恙。例如,采用新的加密技术对敏感数据进行处理,在不影响性能的前提下,保障数据不被泄露。以下是一个更完善的同态加密算法示例(使用 Python 的加密库),允许在加密数据上进行特定类型的计算,而无需解密:
import phe
import numpy as np
# 生成同态加密的密钥对
public_key, private_key = phe.generate_paillier_keypair()
# 模拟敏感数据,这里假设是两个数值向量
vector1 = np.array([10, 20, 30])
vector2 = np.array([5, 10, 15])
# 使用公钥对数据进行加密
encrypted_vector1 = [public_key.encrypt(value) for value in vector1]
encrypted_vector2 = [public_key.encrypt(value) for value in vector2]
# 在加密数据上进行加法运算
encrypted_result = [encrypted_vector1[i] + encrypted_vector2[i] for i in range(len(vector1))]
# 使用私钥对结果进行解密
result = [private_key.decrypt(value) for value in encrypted_result]
print("Result of encrypted addition:", result)
此外,在融合新技术时,还要考虑如何应对数据量的进一步爆炸式增长和数据类型的日益多样化。这可能需要引入新的数据压缩技术、分布式存储架构的进一步优化以及数据预处理和特征工程的自动化工具。例如,开发基于机器学习的自动数据特征提取算法,能够根据数据的类型和分布自动选择合适的特征提取方法,减少人工干预,提高数据处理效率和准确性。
结束语:

在这篇文章中,我们如同无畏的星际探险家,在 Impala 与新技术融合的浩瀚宇宙中深入探索,从核心原理的精细剖析,到电商巨头 A 的成功实践案例,再到跨行业应用的无限潜力展望和技术创新的持续追求,为您呈现了一幅绚丽多彩且充满深度的技术画卷。希望这些丰富详实的内容能成为您在大数据领域航行的璀璨北斗,为您的技术探索和实践照亮前行的道路。
您在实践中是否已经尝试过类似的技术融合呢?或者您在数据处理过程中遇到过哪些独特的挑战和有趣的解决方案呢?欢迎在评论区或CSDN社区分享您的宝贵经验,让我们一起在这个充满无限可能的技术宇宙中共同成长、共同探索。
在后续的文章《大数据新视界 – 大数据大厂之 Impala 在大数据架构中的性能优化全景洞察(上)(13/30)》中,我们将站在更高的视角,如同俯瞰整个宇宙星系,审视 Impala 在大数据架构中的性能优化全景,继续为您揭示更多精彩绝伦的技术奥秘,期待与您再次一同踏上这激动人心的探索之旅。
说明: 文中部分图片来自官网:(https://impala.apache.org/)
- 大数据新视界 – 大数据大厂之 Impala 性能优化:融合机器学习的未来之路(上 (2-2))(11/30)(最新)
- 大数据新视界 – 大数据大厂之 Impala 性能优化:融合机器学习的未来之路(上 (2-1))(11/30)(最新)
- 大数据新视界 – 大数据大厂之经典案例解析:广告公司 Impala 优化的成功之道(下)(10/30)(最新)
- 大数据新视界 – 大数据大厂之经典案例解析:电商企业如何靠 Impala性能优化逆袭(上)(9/30)(最新)
- 大数据新视界 – 大数据大厂之 Impala 性能优化:从数据压缩到分析加速(下)(8/30)(最新)
- 大数据新视界 – 大数据大厂之 Impala 性能优化:应对海量复杂数据的挑战(上)(7/30)(最新)
- 大数据新视界 – 大数据大厂之 Impala 资源管理:并发控制的策略与技巧(下)(6/30)(最新)
- 大数据新视界 – 大数据大厂之 Impala 与内存管理:如何避免资源瓶颈(上)(5/30)(最新)
- 大数据新视界 – 大数据大厂之提升 Impala 查询效率:重写查询语句的黄金法则(下)(4/30)(最新)
- 大数据新视界 – 大数据大厂之提升 Impala 查询效率:索引优化的秘籍大揭秘(上)(3/30)(最新)
- 大数据新视界 – 大数据大厂之 Impala 性能优化:数据存储分区的艺术与实践(下)(2/30)(最新)
- 大数据新视界 – 大数据大厂之 Impala 性能优化:解锁大数据分析的速度密码(上)(1/30)(最新)
- 大数据新视界 – 大数据大厂都在用的数据目录管理秘籍大揭秘,附海量代码和案例(最新)
- 大数据新视界 – 大数据大厂之数据质量管理全景洞察:从荆棘挑战到辉煌策略与前沿曙光(最新)
- 大数据新视界 – 大数据大厂之大数据环境下的网络安全态势感知(最新)
- 大数据新视界 – 大数据大厂之多因素认证在大数据安全中的关键作用(最新)
- 大数据新视界 – 大数据大厂之优化大数据计算框架 Tez 的实践指南(最新)
- 技术星河中的璀璨灯塔 —— 青云交的非凡成长之路(最新)
- 大数据新视界 – 大数据大厂之大数据重塑影视娱乐产业的未来(4 - 4)(最新)
- 大数据新视界 – 大数据大厂之大数据重塑影视娱乐产业的未来(4 - 3)(最新)
- 大数据新视界 – 大数据大厂之大数据重塑影视娱乐产业的未来(4 - 2)(最新)
- 大数据新视界 – 大数据大厂之大数据重塑影视娱乐产业的未来(4 - 1)(最新)
- 大数据新视界 – 大数据大厂之Cassandra 性能优化策略:大数据存储的高效之路(最新)
- 大数据新视界 – 大数据大厂之大数据在能源行业的智能优化变革与展望(最新)
- 智创 AI 新视界 – 探秘 AIGC 中的生成对抗网络(GAN)应用(最新)
- 大数据新视界 – 大数据大厂之大数据与虚拟现实的深度融合之旅(最新)
- 大数据新视界 – 大数据大厂之大数据与神经形态计算的融合:开启智能新纪元(最新)
- 智创 AI 新视界 – AIGC 背后的深度学习魔法:从原理到实践(最新)
- 大数据新视界 – 大数据大厂之大数据和增强现实(AR)结合:创造沉浸式数据体验(最新)
- 大数据新视界 – 大数据大厂之如何降低大数据存储成本:高效存储架构与技术选型(最新)
- 大数据新视界 --大数据大厂之大数据与区块链双链驱动:构建可信数据生态(最新)
- 大数据新视界 – 大数据大厂之 AI 驱动的大数据分析:智能决策的新引擎(最新)
- 大数据新视界 --大数据大厂之区块链技术:为大数据安全保驾护航(最新)
- 大数据新视界 --大数据大厂之 Snowflake 在大数据云存储和处理中的应用探索(最新)
- 大数据新视界 --大数据大厂之数据脱敏技术在大数据中的应用与挑战(最新)
- 大数据新视界 --大数据大厂之 Ray:分布式机器学习框架的崛起(最新)
- 大数据新视界 --大数据大厂之大数据在智慧城市建设中的应用:打造智能生活的基石(最新)
- 大数据新视界 --大数据大厂之 Dask:分布式大数据计算的黑马(最新)
- 大数据新视界 --大数据大厂之 Apache Beam:统一批流处理的大数据新贵(最新)
- 大数据新视界 --大数据大厂之图数据库与大数据:挖掘复杂关系的新视角(最新)
- 大数据新视界 --大数据大厂之 Serverless 架构下的大数据处理:简化与高效的新路径(最新)
- 大数据新视界 --大数据大厂之大数据与边缘计算的协同:实时分析的新前沿(最新)
- 大数据新视界 --大数据大厂之 Hadoop MapReduce 优化指南:释放数据潜能,引领科技浪潮(最新)
- 诺贝尔物理学奖新视野:机器学习与神经网络的璀璨华章(最新)
- 大数据新视界 --大数据大厂之 Volcano:大数据计算任务调度的新突破(最新)
- 大数据新视界 --大数据大厂之 Kubeflow 在大数据与机器学习融合中的应用探索(最新)
- 大数据新视界 --大数据大厂之大数据环境下的零信任安全架构:构建可靠防护体系(最新)
- 大数据新视界 --大数据大厂之差分隐私技术在大数据隐私保护中的实践(最新)
- 大数据新视界 --大数据大厂之 Dremio:改变大数据查询方式的创新引擎(最新)
- 大数据新视界 --大数据大厂之 ClickHouse:大数据分析领域的璀璨明星(最新)
- 大数据新视界 --大数据大厂之大数据驱动下的物流供应链优化:实时追踪与智能调配(最新)
- 大数据新视界 --大数据大厂之大数据如何重塑金融风险管理:精准预测与防控(最新)
- 大数据新视界 --大数据大厂之 GraphQL 在大数据查询中的创新应用:优化数据获取效率(最新)
- 大数据新视界 --大数据大厂之大数据与量子机器学习融合:突破智能分析极限(最新)
- 大数据新视界 --大数据大厂之 Hudi 数据湖框架性能提升:高效处理大数据变更(最新)
- 大数据新视界 --大数据大厂之 Presto 性能优化秘籍:加速大数据交互式查询(最新)
- 大数据新视界 --大数据大厂之大数据驱动智能客服 – 提升客户体验的核心动力(最新)
- 大数据新视界 --大数据大厂之大数据于基因测序分析的核心应用 - 洞悉生命信息的密钥(最新)
- 大数据新视界 --大数据大厂之 Ibis:独特架构赋能大数据分析高级抽象层(最新)
- 大数据新视界 --大数据大厂之 DataFusion:超越传统的大数据集成与处理创新工具(最新)
- 大数据新视界 --大数据大厂之 从 Druid 和 Kafka 到 Polars:大数据处理工具的传承与创新(最新)
- 大数据新视界 --大数据大厂之 Druid 查询性能提升:加速大数据实时分析的深度探索(最新)
- 大数据新视界 --大数据大厂之 Kafka 性能优化的进阶之道:应对海量数据的高效传输(最新)
- 大数据新视界 --大数据大厂之深度优化 Alluxio 分层架构:提升大数据缓存效率的全方位解析(最新)
- 大数据新视界 --大数据大厂之 Alluxio:解析数据缓存系统的分层架构(最新)
- 大数据新视界 --大数据大厂之 Alluxio 数据缓存系统在大数据中的应用与配置(最新)
- 大数据新视界 --大数据大厂之TeZ 大数据计算框架实战:高效处理大规模数据(最新)
- 大数据新视界 --大数据大厂之数据质量评估指标与方法:提升数据可信度(最新)
- 大数据新视界 --大数据大厂之 Sqoop 在大数据导入导出中的应用与技巧(最新)
- 大数据新视界 --大数据大厂之数据血缘追踪与治理:确保数据可追溯性(最新)
- 大数据新视界 --大数据大厂之Cassandra 分布式数据库在大数据中的应用与调优(最新)
- 大数据新视界 --大数据大厂之基于 MapReduce 的大数据并行计算实践(最新)
- 大数据新视界 --大数据大厂之数据压缩算法比较与应用:节省存储空间(最新)
- 大数据新视界 --大数据大厂之 Druid 实时数据分析平台在大数据中的应用(最新)
- 大数据新视界 --大数据大厂之数据清洗工具 OpenRefine 实战:清理与转换数据(最新)
- 大数据新视界 --大数据大厂之 Spark Streaming 实时数据处理框架:案例与实践(最新)
- 大数据新视界 --大数据大厂之 Kylin 多维分析引擎实战:构建数据立方体(最新)
- 大数据新视界 --大数据大厂之HBase 在大数据存储中的应用与表结构设计(最新)
- 大数据新视界 --大数据大厂之大数据实战指南:Apache Flume 数据采集的配置与优化秘籍(最新)
- 大数据新视界 --大数据大厂之大数据存储技术大比拼:选择最适合你的方案(最新)
- 大数据新视界 --大数据大厂之 Reactjs 在大数据应用开发中的优势与实践(最新)
- 大数据新视界 --大数据大厂之 Vue.js 与大数据可视化:打造惊艳的数据界面(最新)
- 大数据新视界 --大数据大厂之 Node.js 与大数据交互:实现高效数据处理(最新)
- 大数据新视界 --大数据大厂之JavaScript在大数据前端展示中的精彩应用(最新)
- 大数据新视界 --大数据大厂之AI 与大数据的融合:开创智能未来的新篇章(最新)
- 大数据新视界 --大数据大厂之算法在大数据中的核心作用:提升效率与智能决策(最新)
- 大数据新视界 --大数据大厂之DevOps与大数据:加速数据驱动的业务发展(最新)
- 大数据新视界 --大数据大厂之SaaS模式下的大数据应用:创新与变革(最新)
- 大数据新视界 --大数据大厂之Kubernetes与大数据:容器化部署的最佳实践(最新)
- 大数据新视界 --大数据大厂之探索ES:大数据时代的高效搜索引擎实战攻略(最新)
- 大数据新视界 --大数据大厂之Redis在缓存与分布式系统中的神奇应用(最新)
- 大数据新视界 --大数据大厂之数据驱动决策:如何利用大数据提升企业竞争力(最新)
- 大数据新视界 --大数据大厂之MongoDB与大数据:灵活文档数据库的应用场景(最新)
- 大数据新视界 --大数据大厂之数据科学项目实战:从问题定义到结果呈现的完整流程(最新)
- 大数据新视界 --大数据大厂之 Cassandra 分布式数据库:高可用数据存储的新选择(最新)
- 大数据新视界 --大数据大厂之数据安全策略:保护大数据资产的最佳实践(最新)
- 大数据新视界 --大数据大厂之Kafka消息队列实战:实现高吞吐量数据传输(最新)
- 大数据新视界 --大数据大厂之数据挖掘入门:用 R 语言开启数据宝藏的探索之旅(最新)
- 大数据新视界 --大数据大厂之HBase深度探寻:大规模数据存储与查询的卓越方案(最新)
- IBM 中国研发部裁员风暴,IT 行业何去何从?(最新)
- 大数据新视界 --大数据大厂之数据治理之道:构建高效大数据治理体系的关键步骤(最新)
- 大数据新视界 --大数据大厂之Flink强势崛起:大数据新视界的璀璨明珠(最新)
- 大数据新视界 --大数据大厂之数据可视化之美:用 Python 打造炫酷大数据可视化报表(最新)
- 大数据新视界 --大数据大厂之 Spark 性能优化秘籍:从配置到代码实践(最新)
- 大数据新视界 --大数据大厂之揭秘大数据时代 Excel 魔法:大厂数据分析师进阶秘籍(最新)
- 大数据新视界 --大数据大厂之Hive与大数据融合:构建强大数据仓库实战指南(最新)
- 大数据新视界–大数据大厂之Java 与大数据携手:打造高效实时日志分析系统的奥秘(最新)
- 大数据新视界–面向数据分析师的大数据大厂之MySQL基础秘籍:轻松创建数据库与表,踏入大数据殿堂(最新)
- 全栈性能优化秘籍–Linux 系统性能调优全攻略:多维度优化技巧大揭秘(最新)
- 大数据新视界–大数据大厂之MySQL数据库课程设计:揭秘 MySQL 集群架构负载均衡核心算法:从理论到 Java 代码实战,让你的数据库性能飙升!(最新)
- 大数据新视界–大数据大厂之MySQL数据库课程设计:MySQL集群架构负载均衡故障排除与解决方案(最新)
- 解锁编程高效密码:四大工具助你一飞冲天!(最新)
- 大数据新视界–大数据大厂之MySQL数据库课程设计:MySQL数据库高可用性架构探索(2-1)(最新)
- 大数据新视界–大数据大厂之MySQL数据库课程设计:MySQL集群架构负载均衡方法选择全攻略(2-2)(最新)
- 大数据新视界–大数据大厂之MySQL数据库课程设计:MySQL 数据库 SQL 语句调优方法详解(2-1)(最新)
- 大数据新视界–大数据大厂之MySQL 数据库课程设计:MySQL 数据库 SQL 语句调优的进阶策略与实际案例(2-2)(最新)
- 大数据新视界–大数据大厂之MySQL 数据库课程设计:数据安全深度剖析与未来展望(最新)
- 大数据新视界–大数据大厂之MySQL 数据库课程设计:开启数据宇宙的传奇之旅(最新)
- 大数据新视界–大数据大厂之大数据时代的璀璨导航星:Eureka 原理与实践深度探秘(最新)
- Java性能优化传奇之旅–Java万亿级性能优化之Java 性能优化逆袭:常见错误不再是阻碍(最新)
- Java性能优化传奇之旅–Java万亿级性能优化之Java 性能优化传奇:热门技术点亮高效之路(最新)
- Java性能优化传奇之旅–Java万亿级性能优化之电商平台高峰时段性能优化:多维度策略打造卓越体验(最新)
- Java性能优化传奇之旅–Java万亿级性能优化之电商平台高峰时段性能大作战:策略与趋势洞察(最新)
- JVM万亿性能密码–JVM性能优化之JVM 内存魔法:开启万亿级应用性能新纪元(最新)
- 十万流量耀前路,成长感悟谱新章(最新)
- AI 模型:全能与专精之辩 —— 一场科技界的 “超级大比拼”(最新)
- 国产游戏技术:挑战与机遇(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(10)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(9)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(8)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(7)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(6)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(5)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(4)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(3)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(2)(最新)
- Java面试题–JVM大厂篇之JVM大厂面试题及答案解析(1)(最新)
- Java 面试题 ——JVM 大厂篇之 Java 工程师必备:顶尖工具助你全面监控和分析 CMS GC 性能(2)(最新)
- Java面试题–JVM大厂篇之Java工程师必备:顶尖工具助你全面监控和分析CMS GC性能(1)(最新)
- Java面试题–JVM大厂篇之未来已来:为什么ZGC是大规模Java应用的终极武器?(最新)
- AI 音乐风暴:创造与颠覆的交响(最新)
- 编程风暴:勇破挫折,铸就传奇(最新)
- Java面试题–JVM大厂篇之低停顿、高性能:深入解析ZGC的优势(最新)
- Java面试题–JVM大厂篇之解密ZGC:让你的Java应用高效飞驰(最新)
- Java面试题–JVM大厂篇之掌控Java未来:深入剖析ZGC的低停顿垃圾回收机制(最新)
- GPT-5 惊涛来袭:铸就智能新传奇(最新)
- AI 时代风暴:程序员的核心竞争力大揭秘(最新)
- Java面试题–JVM大厂篇之Java新神器ZGC:颠覆你的垃圾回收认知!(最新)
- Java面试题–JVM大厂篇之揭秘:如何通过优化 CMS GC 提升各行业服务器响应速度(最新)
- “低代码” 风暴:重塑软件开发新未来(最新)
- 程序员如何平衡日常编码工作与提升式学习?–编程之路:平衡与成长的艺术(最新)
- 编程学习笔记秘籍:开启高效学习之旅(最新)
- Java面试题–JVM大厂篇之高并发Java应用的秘密武器:深入剖析GC优化实战案例(最新)
- Java面试题–JVM大厂篇之实战解析:如何通过CMS GC优化大规模Java应用的响应时间(最新)
- Java面试题–JVM大厂篇(1-10)
- Java面试题–JVM大厂篇之Java虚拟机(JVM)面试题:涨知识,拿大厂Offer(11-20)
- Java面试题–JVM大厂篇之JVM面试指南:掌握这10个问题,大厂Offer轻松拿
- Java面试题–JVM大厂篇之Java程序员必学:JVM架构完全解读
- Java面试题–JVM大厂篇之以JVM新特性看Java的进化之路:从Loom到Amber的技术篇章
- Java面试题–JVM大厂篇之深入探索JVM:大厂面试官心中的那些秘密题库
- Java面试题–JVM大厂篇之高级Java开发者的自我修养:深入剖析JVM垃圾回收机制及面试要点
- Java面试题–JVM大厂篇之从新手到专家:深入探索JVM垃圾回收–开端篇
- Java面试题–JVM大厂篇之Java性能优化:垃圾回收算法的神秘面纱揭开!
- Java面试题–JVM大厂篇之揭秘Java世界的清洁工——JVM垃圾回收机制
- Java面试题–JVM大厂篇之掌握JVM性能优化:选择合适的垃圾回收器
- Java面试题–JVM大厂篇之深入了解Java虚拟机(JVM):工作机制与优化策略
- Java面试题–JVM大厂篇之深入解析JVM运行时数据区:Java开发者必读
- Java面试题–JVM大厂篇之从零开始掌握JVM:解锁Java程序的强大潜力
- Java面试题–JVM大厂篇之深入了解G1 GC:大型Java应用的性能优化利器
- Java面试题–JVM大厂篇之深入了解G1 GC:高并发、响应时间敏感应用的最佳选择
- Java面试题–JVM大厂篇之G1 GC的分区管理方式如何减少应用线程的影响
- Java面试题–JVM大厂篇之深入解析G1 GC——革新Java垃圾回收机制
- Java面试题–JVM大厂篇之深入探讨Serial GC的应用场景
- Java面试题–JVM大厂篇之Serial GC在JVM中有哪些优点和局限性
- Java面试题–JVM大厂篇之深入解析JVM中的Serial GC:工作原理与代际区别
- Java面试题–JVM大厂篇之通过参数配置来优化Serial GC的性能
- Java面试题–JVM大厂篇之深入分析Parallel GC:从原理到优化
- Java面试题–JVM大厂篇之破解Java性能瓶颈!深入理解Parallel GC并优化你的应用
- Java面试题–JVM大厂篇之全面掌握Parallel GC参数配置:实战指南
- Java面试题–JVM大厂篇之Parallel GC与其他垃圾回收器的对比与选择
- Java面试题–JVM大厂篇之Java中Parallel GC的调优技巧与最佳实践
- Java面试题–JVM大厂篇之JVM监控与GC日志分析:优化Parallel GC性能的重要工具
- Java面试题–JVM大厂篇之针对频繁的Minor GC问题,有哪些优化对象创建与使用的技巧可以分享?
- Java面试题–JVM大厂篇之JVM 内存管理深度探秘:原理与实战
- Java面试题–JVM大厂篇之破解 JVM 性能瓶颈:实战优化策略大全
- Java面试题–JVM大厂篇之JVM 垃圾回收器大比拼:谁是最佳选择
- Java面试题–JVM大厂篇之从原理到实践:JVM 字节码优化秘籍
- Java面试题–JVM大厂篇之揭开CMS GC的神秘面纱:从原理到应用,一文带你全面掌握
- Java面试题–JVM大厂篇之JVM 调优实战:让你的应用飞起来
- Java面试题–JVM大厂篇之CMS GC调优宝典:从默认配置到高级技巧,Java性能提升的终极指南
- Java面试题–JVM大厂篇之CMS GC的前世今生:为什么它曾是Java的王者,又为何将被G1取代
- Java就业-学习路线–突破性能瓶颈: Java 22 的性能提升之旅
- Java就业-学习路线–透视Java发展:从 Java 19 至 Java 22 的飞跃
- Java就业-学习路线–Java技术:2024年开发者必须了解的10个要点
- Java就业-学习路线–Java技术栈前瞻:未来技术趋势与创新
- Java就业-学习路线–Java技术栈模块化的七大优势,你了解多少?
- Spring框架-Java学习路线课程第一课:Spring核心
- Spring框架-Java学习路线课程:Spring的扩展配置
- Springboot框架-Java学习路线课程:Springboot框架的搭建之maven的配置
- Java进阶-Java学习路线课程第一课:Java集合框架-ArrayList和LinkedList的使用
- Java进阶-Java学习路线课程第二课:Java集合框架-HashSet的使用及去重原理
- JavaWEB-Java学习路线课程:使用MyEclipse工具新建第一个JavaWeb项目(一)
- JavaWEB-Java学习路线课程:使用MyEclipse工具新建项目时配置Tomcat服务器的方式(二)
- Java学习:在给学生演示用Myeclipse10.7.1工具生成War时,意外报错:SECURITY: INTEGRITY CHECK ERROR
- 使用Jquery发送Ajax请求的几种异步刷新方式
- Idea Springboot启动时内嵌tomcat报错- An incompatible version [1.1.33] of the APR based Apache Tomcat Native
- Java入门-Java学习路线课程第一课:初识JAVA
- Java入门-Java学习路线课程第二课:变量与数据类型
- Java入门-Java学习路线课程第三课:选择结构
- Java入门-Java学习路线课程第四课:循环结构
- Java入门-Java学习路线课程第五课:一维数组
- Java入门-Java学习路线课程第六课:二维数组
- Java入门-Java学习路线课程第七课:类和对象
- Java入门-Java学习路线课程第八课:方法和方法重载
- Java入门-Java学习路线扩展课程:equals的使用
- Java入门-Java学习路线课程面试篇:取商 / 和取余(模) % 符号的使用
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据新视界 -- 大数据大厂之 Impala 性能优化:新技术融合的无限可能(下)(12/30)

发表评论 取消回复