文章目录
本节学习目标:
- 了解⽬标检测的任务
- 知道⽬标检测的常⽤数据集
- 知道⽬标检测算法的评价指标
- 掌握⾮极⼤值NMS算法的应⽤
- 了解常⽤的⽬标检测算法分类
1.目标检测
⽬标检测(Object Detection)的任务是找出图像中所有感兴趣的⽬标,并确定它们的类别和位置。
⽬标检测中能检测出来的物体取决于当前任务(数据集)需要检测的物体有哪些。假设我们的⽬标检测模型定位是检测动物(⽜、⽺、猪、狗、猫五种结果),那么模型对任何⼀张图⽚输出结果不会输出鸭⼦、书籍等其它类型结果。
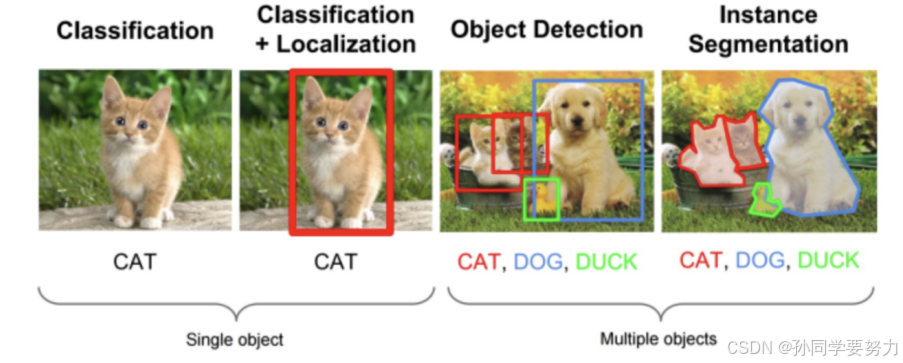
目标检测的信息位置一般有两种格式(以图片的左上角为原点(0,0))
1.极坐标表示(xmin,ymin,xmax, ymax)
- xmin,ymin:x,y坐标的最小值,即图片的左上角
- xmax,ymax:x,y坐标的最大值,即图片的右下角
2.中心点坐标表示(x_center, y_center, w, h)
- x_center, y_center:目标检测框的中心点坐标
- w,h:目标检测的宽和高
示例:假设在下面的图像中进行检测:
那⽬标检测结果的中⼼点表示形式如下所示:

2.常用的开源数据集
经典的⽬标检测数据集有两种,PASCAL VOC数据集 和 MS COCO数据集。
2.1 PASCAL VOC数据集
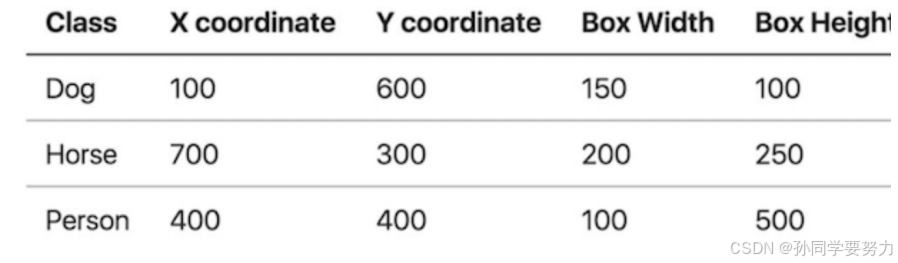
PASCAL VOC是⽬标检测领域的经典数据集。PASCAL VOC包含约10,000张带有边界框的图⽚⽤于训练和验证。PASCAL VOC数据集是⽬标检测问题的⼀个基准数据集,很多模型都是在此数据集上得到的,常⽤的是VOC2007和VOC2012两个版本数据,共20个类别,分别是:

整个数据的⽬录结构如下所示:
其中:

-
JPEGImages存放图⽚⽂件
-
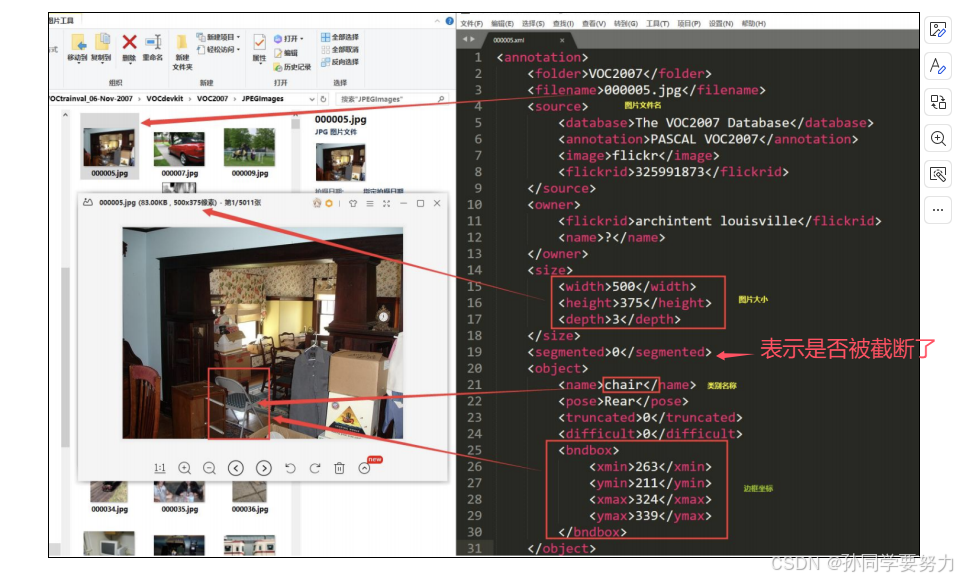
Annotations下存放的是xml⽂件,描述了图⽚信息,如下图所示,需要关注的就是节点下的数据,尤其是bndbox下的数据.xmin,ymin构成了boundingbox的左上⻆,xmax,ymax构成了boundingbox的右下⻆,也就是图像中的⽬标位置信息
-
ImageSets包含以下4个⽂件夹:
①Action下存放的是⼈的动作(例如running、jumping等等)
②Layout下存放的是具有⼈体部位的数据(⼈的head、hand、feet等等)
③Segmentation下存放的是可⽤于分割的数据。
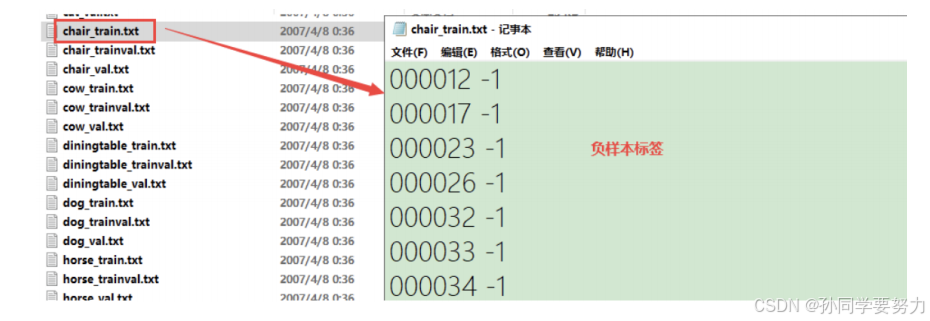
④Main下存放的是图像物体识别的数据,总共分为20类,这是进⾏⽬标检测的重点。该⽂件夹中的数据对负样本⽂件进⾏了描述。(train.txt就是训练集的数据,val.txt就是验证集的数据。)
2.2 MS COCO数据集
MS COCO的全称是Microsoft Common Objects in Context,微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛⼀样,被视为是计算机视觉领域最受关注和最权威的⽐赛之⼀。
COCO数据集是⼀个⼤型的、丰富的物体检测,分割和字幕数据集。这个数据集以场景理解为⽬标,主要从复杂的⽇常场景中截取,图像中的⽬标通过精确的分割进⾏位置的标定。图像包括91类⽬标,328,000影像和2,500,000个label。⽬前为⽌⽬标检测的最⼤数据集,提供的类别有80类,有超过33 万张图⽚,其中20 万张有标注,整个数据集中个体的数⽬
超过150 万个。
图像示例:
COCO数据集使用JSON文件来描述的。

3.目标检测常用的评价指标
3.1 IOU
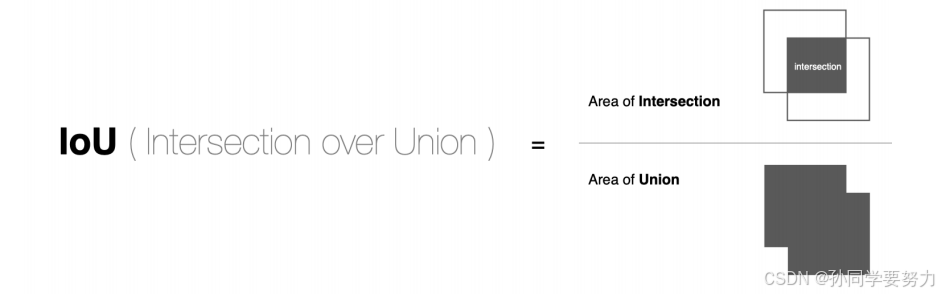
在⽬标检测算法中,IoU(intersection over union,交并⽐)是⽬标检测算法中⽤来评价2个矩形框之间相似度的指标。
IoU=两个矩阵框相交的面积/两个矩阵框相并的面积
如下图所示:
示例;
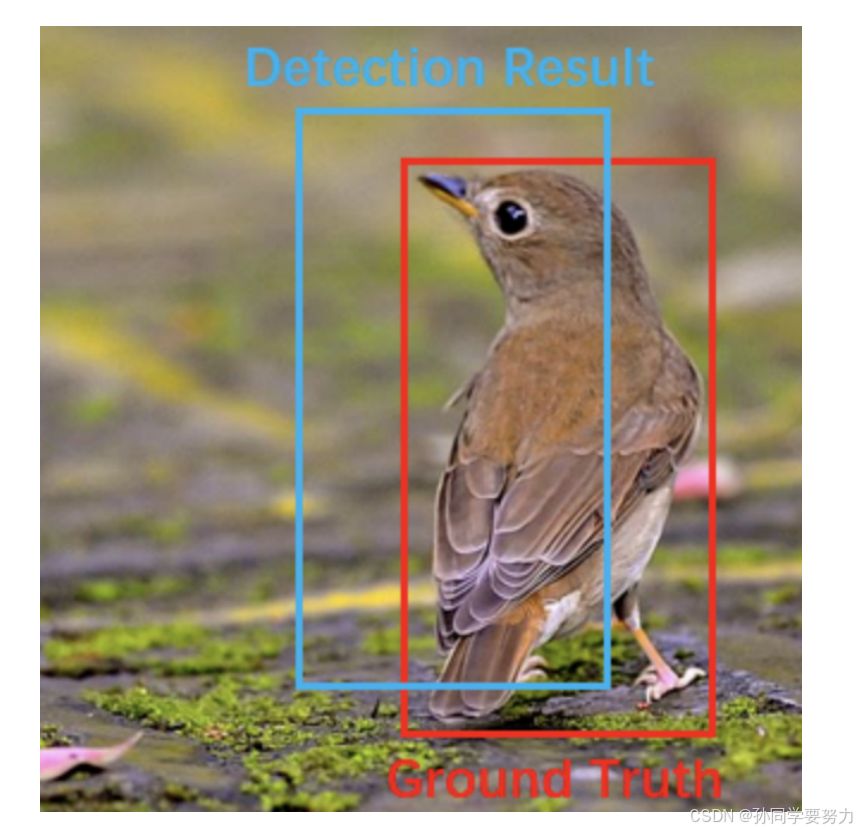
其中上图蓝⾊框框为检测结果,红⾊框框为真实标注。
那我们就可以通过预测结果与真实结果之间的交并⽐来衡量两者之间的相似度。⼀般情况下对于检测框的判定都会存在⼀个阈值,也就是 IoU 的阈值,⼀般可以设置当 IoU 的值⼤于 0.5 的时候,则可认为检测到⽬标物体。
实现方法:
import numpy as np
#定义方法来计算IOU
def IOU(box1, box2, wh=False): #wh为True时表明时中心坐标
#判断他的表示形式
if wh==False:
#极坐标表示
xmin1, ymin1, xmax1, xmax1 = box1
xmin2, ymin2, xmax2, ymax2 = box2
else:
#中心坐标表示
#获取第一个框
xmin1, ymin1 = int(box1[0] - box1[2]/2.0), int(box1[1] - box1[3]/2.0)
xmax1, ymax1 = int(box1[0] + box1[2]/2.0), int(box1[1] + box1[3]/2.0)
#第二个框
xmin2, ymin2 = int(box2[0] - box2[2]/2.0), int(box2[1] - box2[3]/2.0)
xmax2, ymax2 = int(box2[0] + box2[2]/2.0), int(box2[1] + box2[3]/2.0)
#获取交集的左上角和右下角坐标
xx1 = np.max(xmin1, xmin2)
yy1 = np.max(ymin1, ymin2)
xx2 = np.min(xmax1, xmax2)
yy2 = np.min(ymax1, ymax2)
#计算交集面积
inter_area = (np.max(0, xx2 - xx1)) * (np.max(0, yy2 - yy1))
#计算并集的面积
area1 = (xmax1 - xmin1) * (ymax1 - ymin1)
area2 = (xmax2 - xmin2) * (ymax2 - ymin2)
union_area = area1 + area2 - inter_area
#计算IOU
IOU = inter_area / (union_area + 1e-6) #防止分母为0
return IOU
3.2mAP(Mean Average Precision)
⽬标检测问题中的每个图⽚都可能包含⼀些不同类别的物体,需要评估模型的物体分类和定位性能。因此,⽤于图像分类问题的标准指标precision不能直接应⽤于此。 在⽬标检测中,mAP是主要的衡量指标。
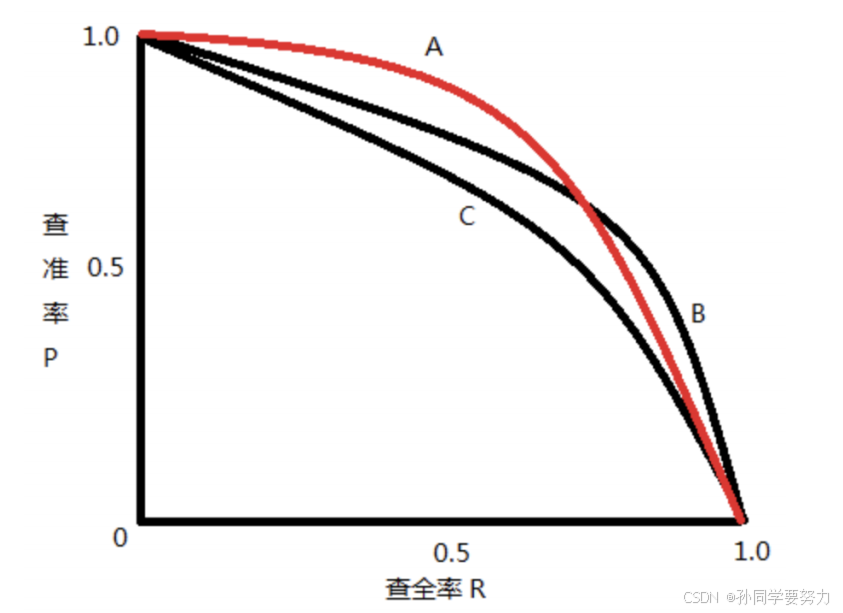
mAP是多个分类任务的AP的平均值,⽽AP(average precision)是PR曲线下的⾯积,所以在介绍mAP之前我们要先得到PR曲线。
在机器学习过程中,我们学过混淆矩阵,我们再来回顾一下混淆矩阵中的参数(TP、FP、FN、TN)
查准率、查全率

- 查准率(Precision): TP/(TP + FP)
- 查全率(Recall): TP/(TP + FN)
⼆者绘制的曲线称为 P-R 曲线
先定义两个公式,⼀个是 Precision,⼀个是 Recall,与上⾯的公式相同,扩展开来,⽤另外⼀种形式进⾏展示,其中 all detctions 代表所有预测框的数量, all ground truths (真实检测框)代表所有 GT 的数量。
AP 是计算某⼀类 P-R 曲线下的⾯积,mAP 则是计算所有类别 P-R 曲线 下⾯积的平均值。
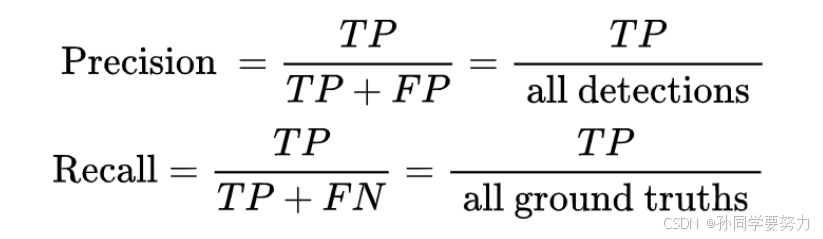
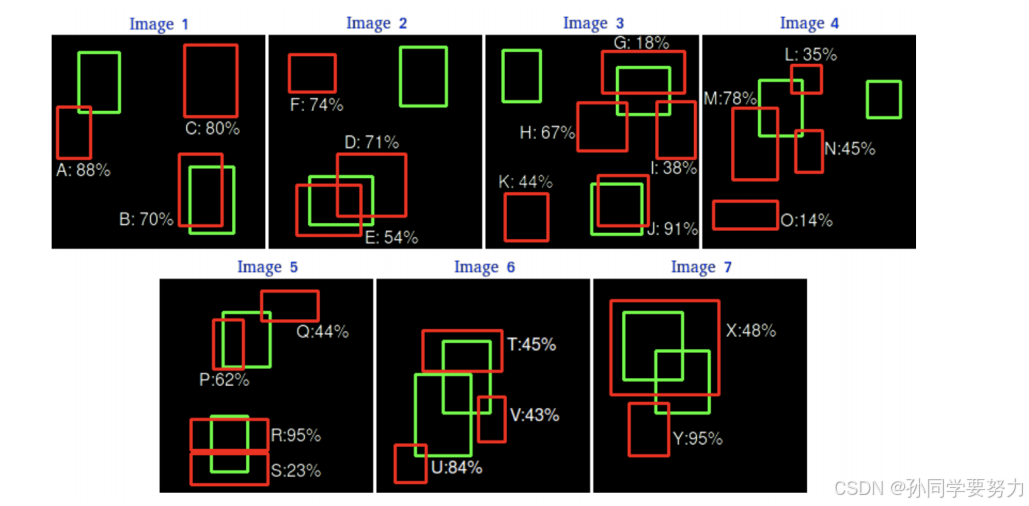
示例:假设我们有 7 张图⽚(Images1-Image7),这些图⽚有 15 个⽬标(绿⾊的框,GT 的数量,上⽂提及的 all ground truths )以及 24 个预测边框(红⾊的框,A-Y 编号表示,并且有⼀个置信度值):
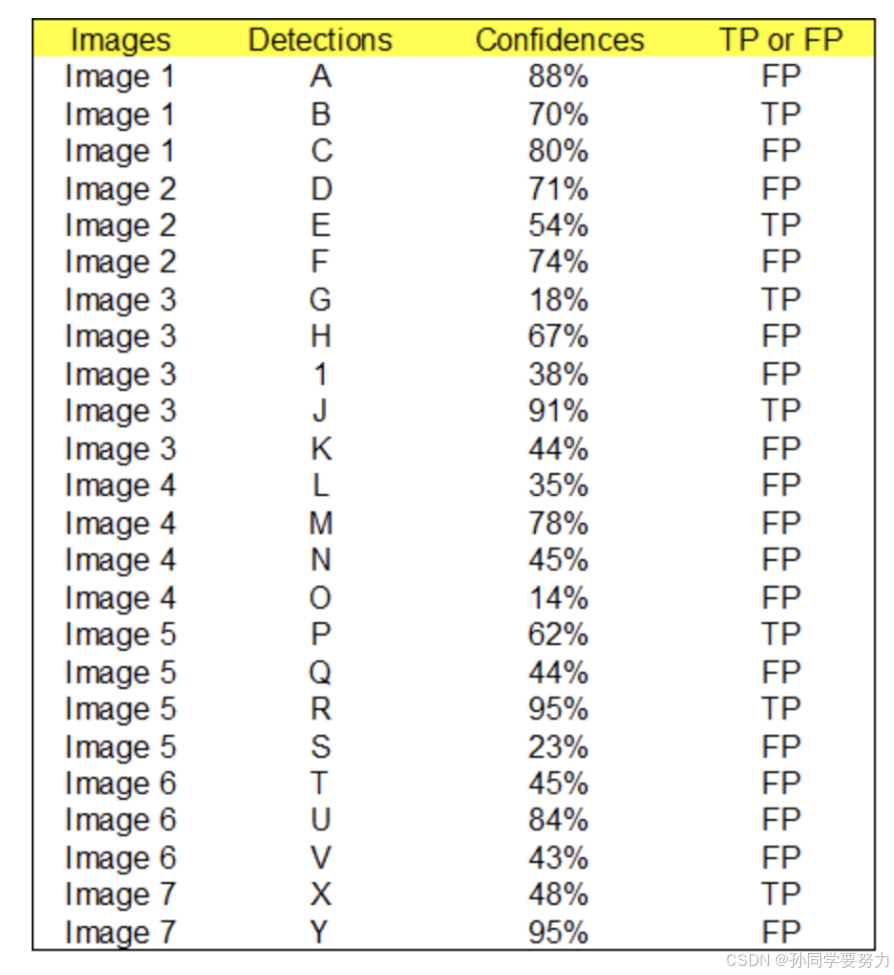
根据上图以及说明,我们可以列出以下表格,其中 Images 代表图⽚的编号,Detections 代表预测边框的编号,Confidences 代表预测边框的置信度,TP or FP 代表预测的边框是标记为 TP 还是 FP(认为预测边框与GT 的 IOU 值⼤于等于 0.3 就标记为 TP;若⼀个 GT 有多个预测边框,则认为 IOU 最⼤且⼤于等于 0.3 的预测框标记为 TP,其他的标记为FP,即⼀个 GT 只能有⼀个预测框标记为 TP),这⾥的 0.3 是随机取的⼀个值。
通过上表,我们可以绘制出 P-R 曲线(因为 AP 就是 P-R 曲线下⾯的⾯积),但是在此之前我们需要计算出 P-R 曲线上各个点的坐标,根据置信度从⼤到⼩排序所有的预测框,然后就可以计算 Precision 和 Recall 的值,⻅下表。(需要记住⼀个叫累加的概念,就是下图的 ACC TP 和ACC FP)
计算过程如下:
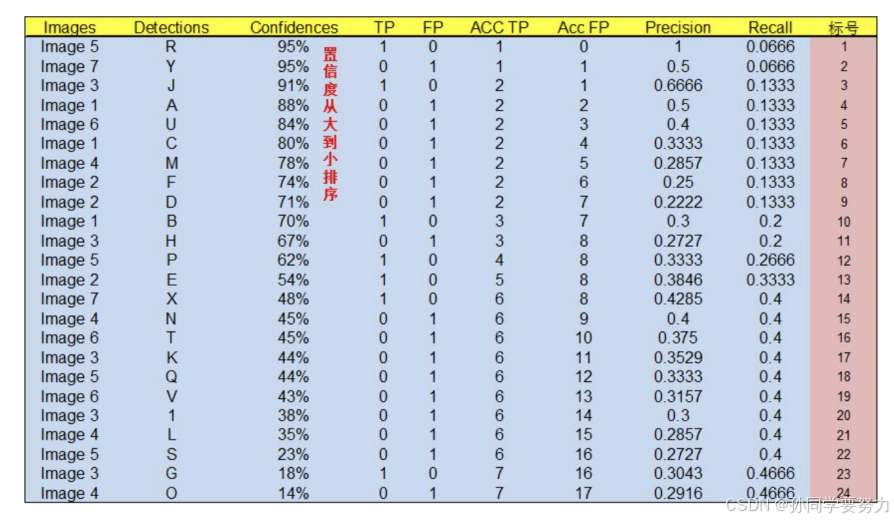
- 标号为 1 的 Precision 和 Recall 的计算⽅式:Precision=TP/(TP+FP)=1/(1+0)=1,Recall=TP/(TP+FN)=TP/( allground truths )=1/15=0.0666 ( all ground truths 上⾯有定义
过了 ) - 标号 2:Precision=TP/(TP+FP)=1/(1+1)=0.5,Recall=TP/(TP+FN)=TP/( all ground truths )=1/15=0.0666
- 标号 3:Precision=TP/(TP+FP)=2/(2+1)=0.6666,Recall=TP/(TP+FN)=TP/( all ground truths )=2/15=0.1333
- 其他的依次类推
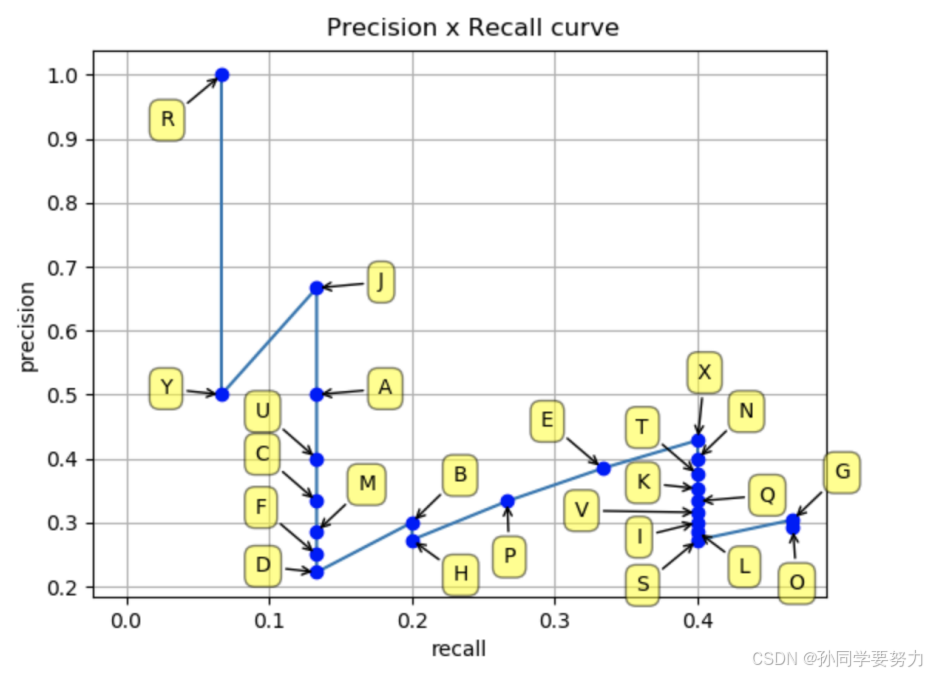
然后我们就可以绘制出P-R曲线了:
得到 P-R 曲线就可以计算 AP(P-R 曲线下的⾯积),要计算 P-R 下⽅的⾯积,有两种⽅法:
- 在VOC2010以前,只需要选取当Recall >= 0, 0.1, 0.2, …, 1共11个点时的Precision最⼤值,然后AP就是这11个Precision的平均值,取 11个点 [0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1] 的插值所得
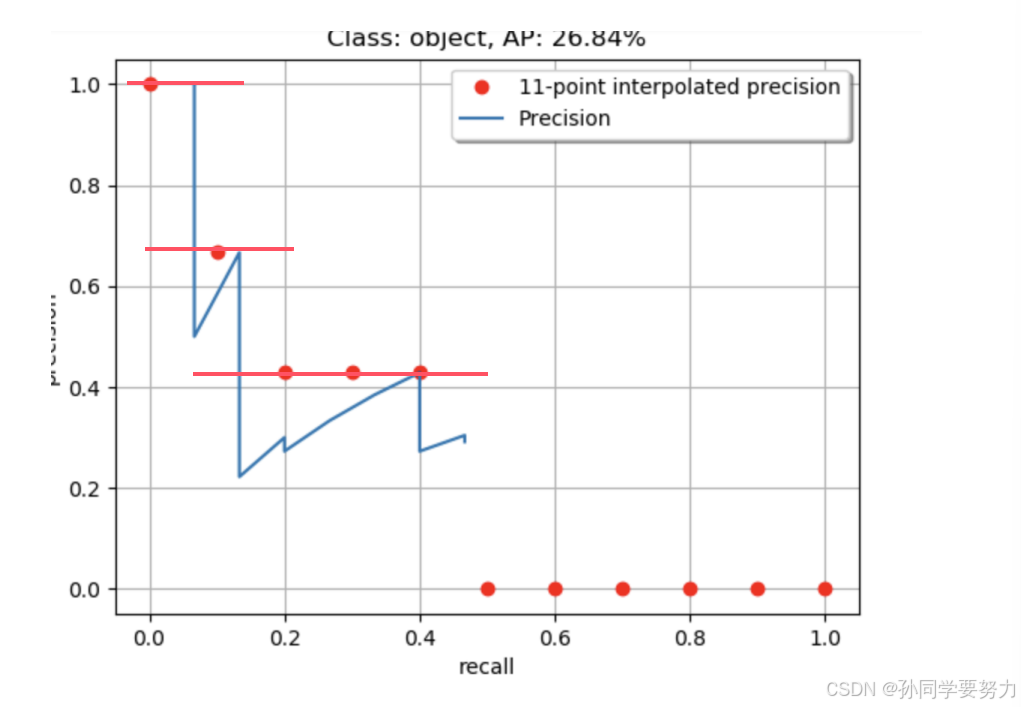
得到⼀个类别的 AP 结果如下:
要计算 mAP,就把所有类别的 AP 计算出来,然后求取平均即可。
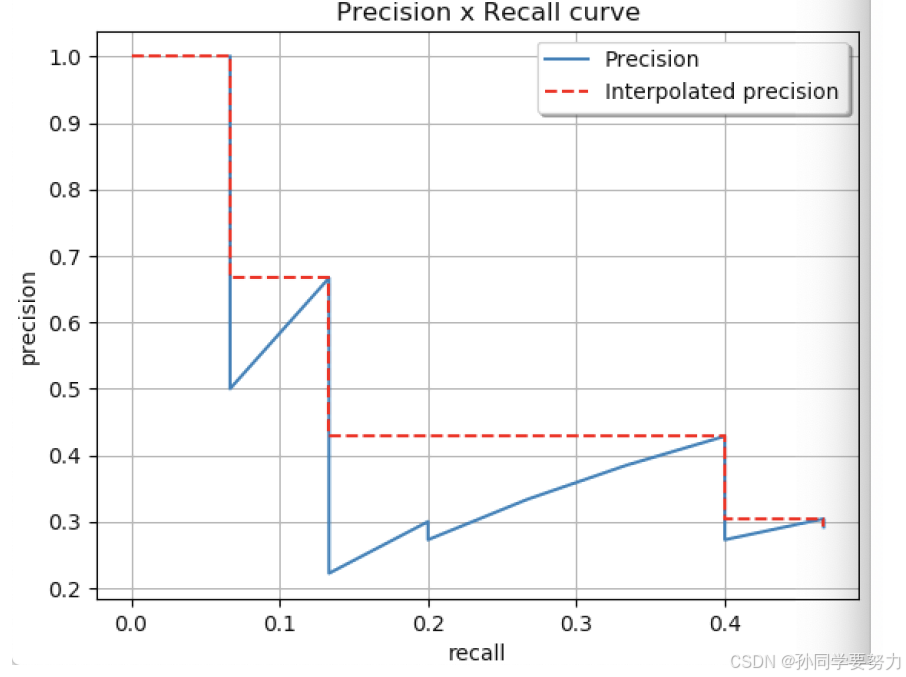
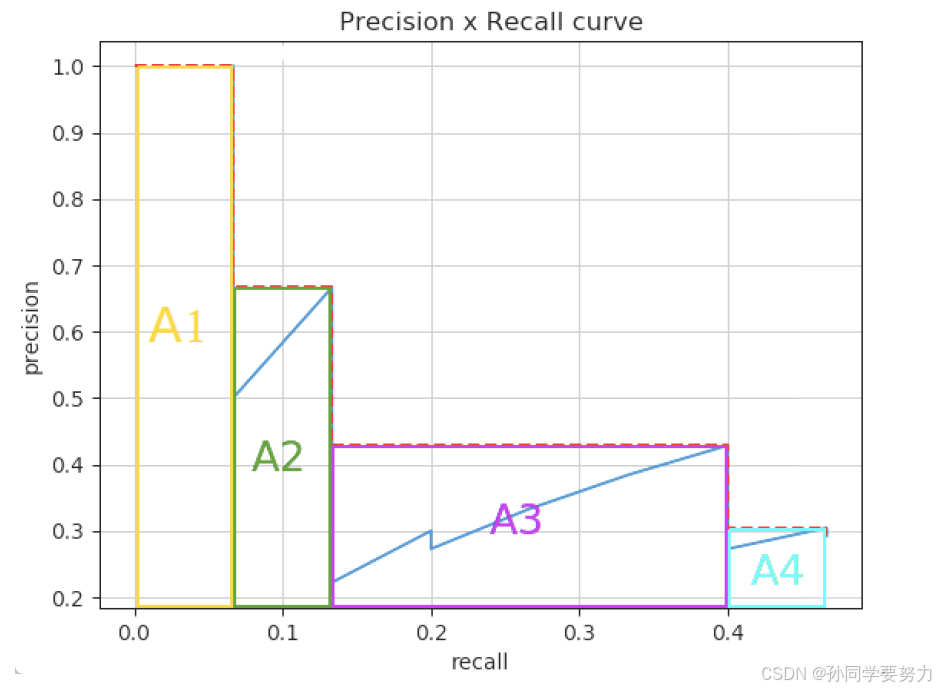
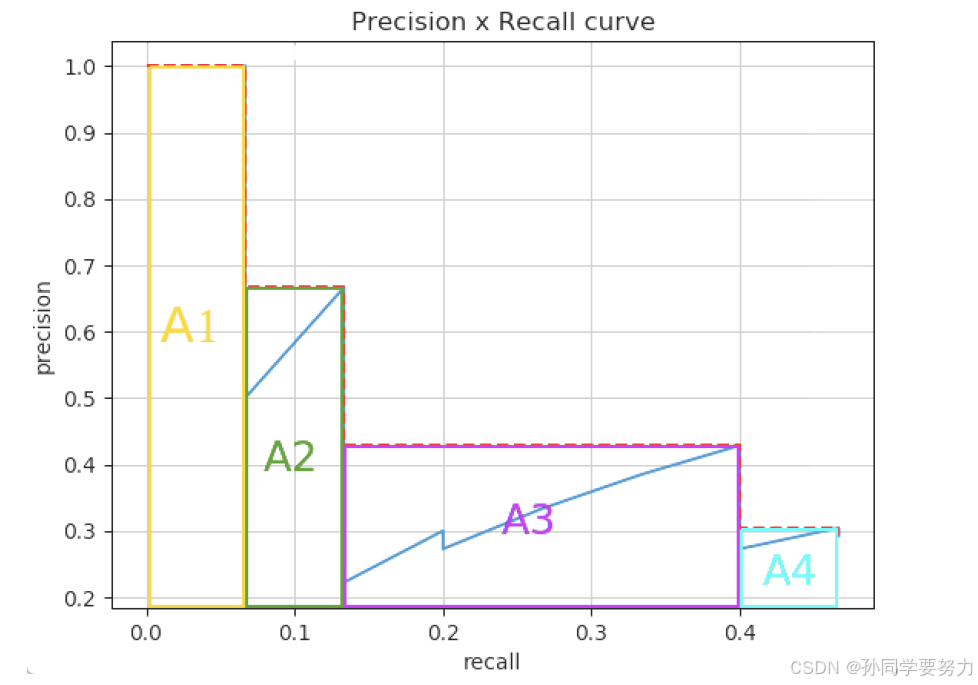
2. 在VOC2010及以后,需要针对每⼀个不同的Recall值(包括0和1),选取其⼤于等于这些Recall值时的Precision最⼤值,如下图所示:
然后计算PR曲线下⾯积作为AP值:
然后计算PR曲线下⾯积作为AP值:
计算⽅法如下所示:


4.NMS(⾮极⼤值抑制)
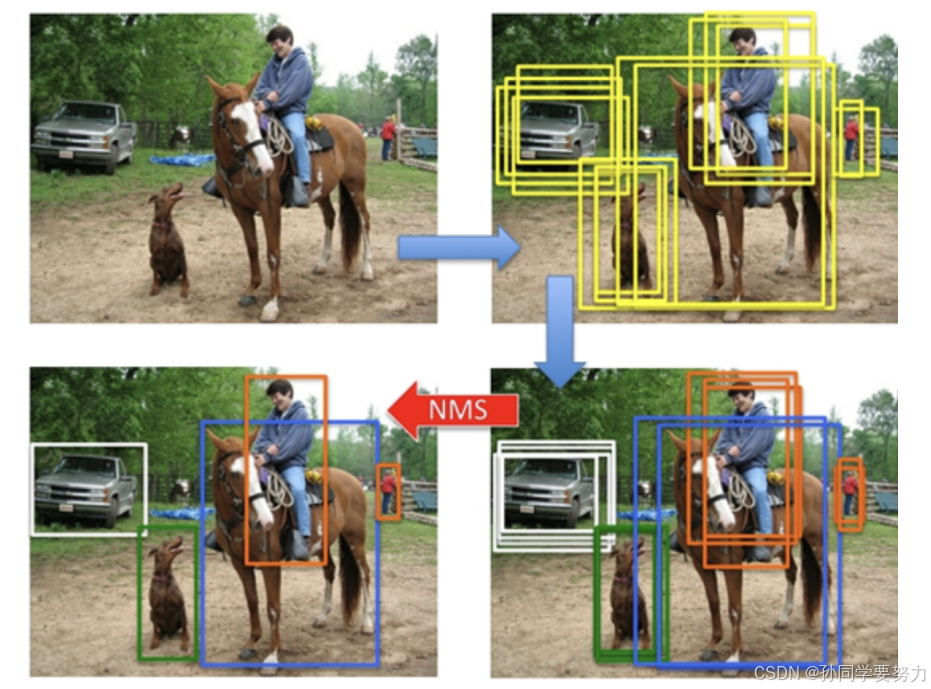
⾮极⼤值抑制(Non-Maximum Suppression,NMS),顾名思义就是抑制不是极⼤值的元素。例如在⾏⼈检测中,滑动窗⼝经提取特征,经分类器分类识别后,每个窗⼝都会得到⼀个分数。但是滑动窗⼝会导致很多窗⼝与其他窗⼝存在包含或者⼤部分交叉的情况。这时就需要⽤到NMS来选取那些邻域⾥分数最⾼(是⾏⼈的概率最⼤),并且抑制那些分数低的窗⼝。 NMS在计算机视觉领域有着⾮常重要的应⽤,如视频⽬标跟踪、数据挖掘、3D重建、⽬标识别以及纹理分析等 。在⽬标检测中,NMS的⽬的就是要去除冗余的检测框,保留最好的⼀个。
如下图所示:
NMS的原理是对于预测框的列表B及其对应的置信度S,选择具有最⼤score的检测框M,将其从B集合中移除并加⼊到最终的检测结果D中.通常将B中剩余检测框中与M的IoU⼤于阈值Nt的框从B中移除.重复这个过程,直到B为空。

使用流程如下图所示:
- ⾸先是检测出⼀系列的检测框
- 将检测框按照类别进⾏分类
- 对同⼀类别的检测框应⽤NMS获取最终的检测结果
示例:通过⼀个例⼦看些NMS的使⽤⽅法,假设定位⻋辆,算法就找出了⼀系列的矩形框,我们需要判别哪些矩形框是没⽤的,需要使⽤NMS的⽅法来实现。
假设现在检测窗⼝有:A、B、C、D、E 5个候选框,接下来进⾏迭代计算: - 第⼀轮:因为B是得分最⾼的,与B的IoU>0.5删除。ACDE中现在与B计算IoU,DE结果>0.5,剔除DE,B作为⼀个预测结果,有个检测框留下B,放⼊集合
- 第⼆轮:A的得分最⾼,与A计算IoU,C的结果>0.5,剔除C,A作为⼀个结果
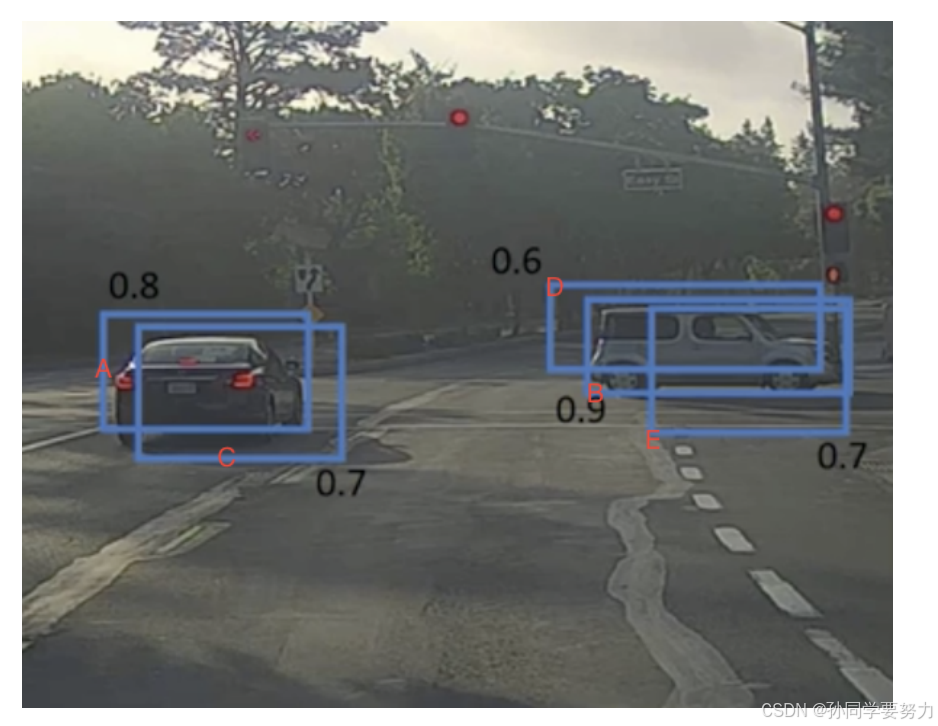
最终结果为在这个5个中检测出了两个⽬标为A和B。
单类别的NMS的实现⽅法如下所示:
def nms(boxes, score, thre):
#容错处理
if len(boxes == 0):
return [], []
#类型转换
#box是使用极坐标表示
boxes = np.array(boxes)
score = np.array(score)
#获取所有左上角和右下角坐标
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
#计算面积
areas = (x2 - x1) * (y2 - y1)
#nms过程
picked_boxes = []
picked_score = []
#排序:从小到大
order = np.argsort(score)
while order.size > 0 :
#获取最大值的索引
index = order[-1]
#最后保留下来的
picked_boxes.append(boxes[index])
picked_score.append(score[index])
#计算IOU
#计算交的面积
x11 = np.maximum(x1[index], x1[order[:-1]])
y11 = np.maximum(y1[index], y1[order[:-1]])
x22 = np.minimum(x2[index], x2[order[:-1]])
y22 = np.minimum(y2[index], y2[order[:-1]])
w = np.maximum(0.0, x22 - x11)
h = np.maximum(0.0, y22 - y11)
inter_area = w * h
#交并比
iou = inter_area / (areas[index] + areas[order[:-1]] - inter_area)
#删除冗余框
keep_boxes = np.where(iou < thre)
#更新roder
order = order[keep_boxes]
return picked_boxes, picked_score
假设有检测结果如下:
bounding = [(187, 82, 337, 317), (150, 67, 305, 282), (246,121,368,304)]
confidence_score = [0.9, 0.65, 0.8]
threshold = 0.3
picked_boxes, picked_score = nms(bounding, confidence_score, threshold)
print('阈值threshold为:', threshold)
print('NMS后得到的bbox是:', picked_boxes)
print('NMS后得到的bbox的confidences是:', picked_score)

5.⽬标检测⽅法分类
⽬标检测算法主要分为two-stage(两阶段)和one-stage(单阶段)两类:
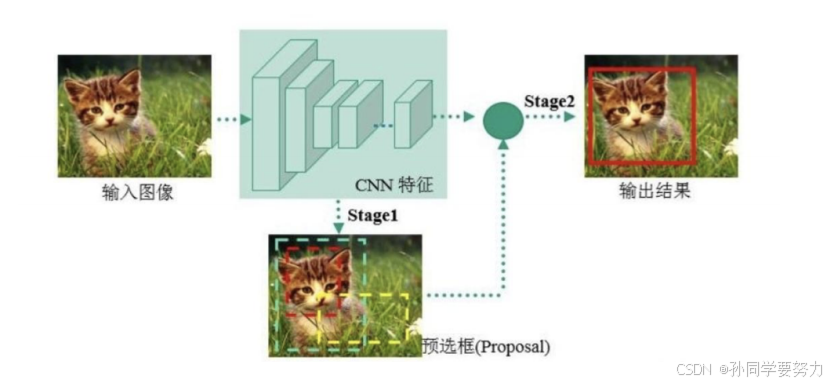
- two-stage的算法:先由算法⽣成⼀系列作为样本的候选框,再通过卷积神经⽹络进⾏样本分
类。如下图所示,主要通过⼀个卷积神经⽹络来完成⽬标检测过程,其提 取的是CNN卷积特征,进⾏候选区域的筛选和⽬标检测两部分。⽹络的准确度⾼、速度相对较慢。
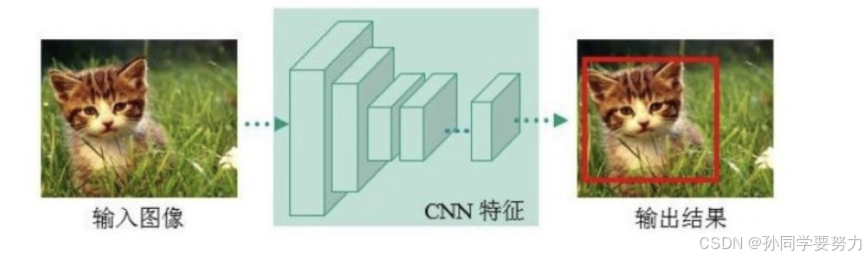
two-stages算法的代表是RCNN系列:R-CNN、Fast R-CNN⽹络到Faster R-CNN⽹络 - One-stage的算法:直接通过主⼲⽹络给出⽬标的类别和位置信息,没有使⽤候选区域的筛选
⽹路,这种算法速度快,但是精度相对Two-stage⽬标检测⽹络降低了很多。
one-stage算法的代表是: YOLO系列:YOLOv1、YOLOv2、YOLOv3、SSD等
下面会持续更新以上目标检测的方法。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 《目标检测》——基础理论知识(目标检测的数据集、评价指标:IOU、mAP、非极大抑制NMS)

发表评论 取消回复