前言
你好,我是醉墨居士,我们接下来对大语言模型一探究竟,看看大模型主要的核心的概念是什么
大语言模型必需知识概述
LLM(大语言模型)采用了Transformer架构,其中比较重要的部分有tokenizer,embedding,attention
训练流程:预训练 -> 微调 -> RLHF(基于人类反馈的强化学习)
训练方式:分布式训练,数据并行,流水并行,张量并行
高效推理能力
大语言模型目标
能够根据用户输入的文本预测并输出接下来要出现的内容,LLM简单的可以理解为是一个文本接龙的应用
模型
模型可以简单理解为一个能够模拟复杂映射关系的非线性函数,能够基于输入得到输出
上下文
其具备一个上下文窗口,用于记录历史对话,通过将上下文窗口内的数据提交给模型,模型就会返回预测的下文内容,然后并将下文内容追加到上下文窗口中,下次提问将携带该信息,上下文窗口具备一个最大长度,当上下文窗口填充满之后将会舍弃最旧的信息,就相当于一个FIFO(先进先出)队列
神经网络的神经元
神经元具备两个关键性能力
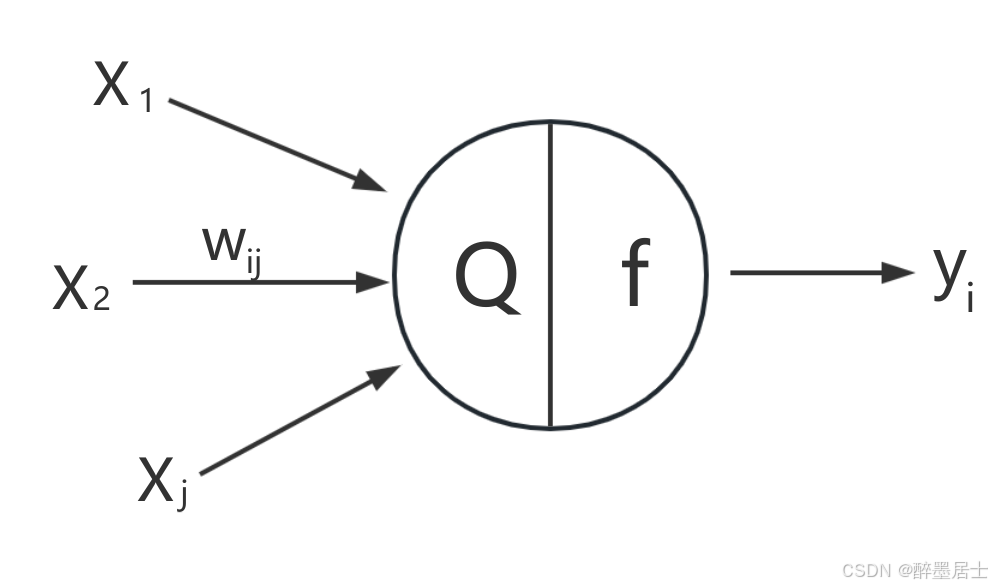
- 计算单元,基于输入参数的加权求和计算,每个输入参数都具备一个对应的参数权重
- 激活函数,对加权求和结果进行激活函数的变换,让神经元具备非线性近似的能力,提高神经元的表达能力
常见激活函数
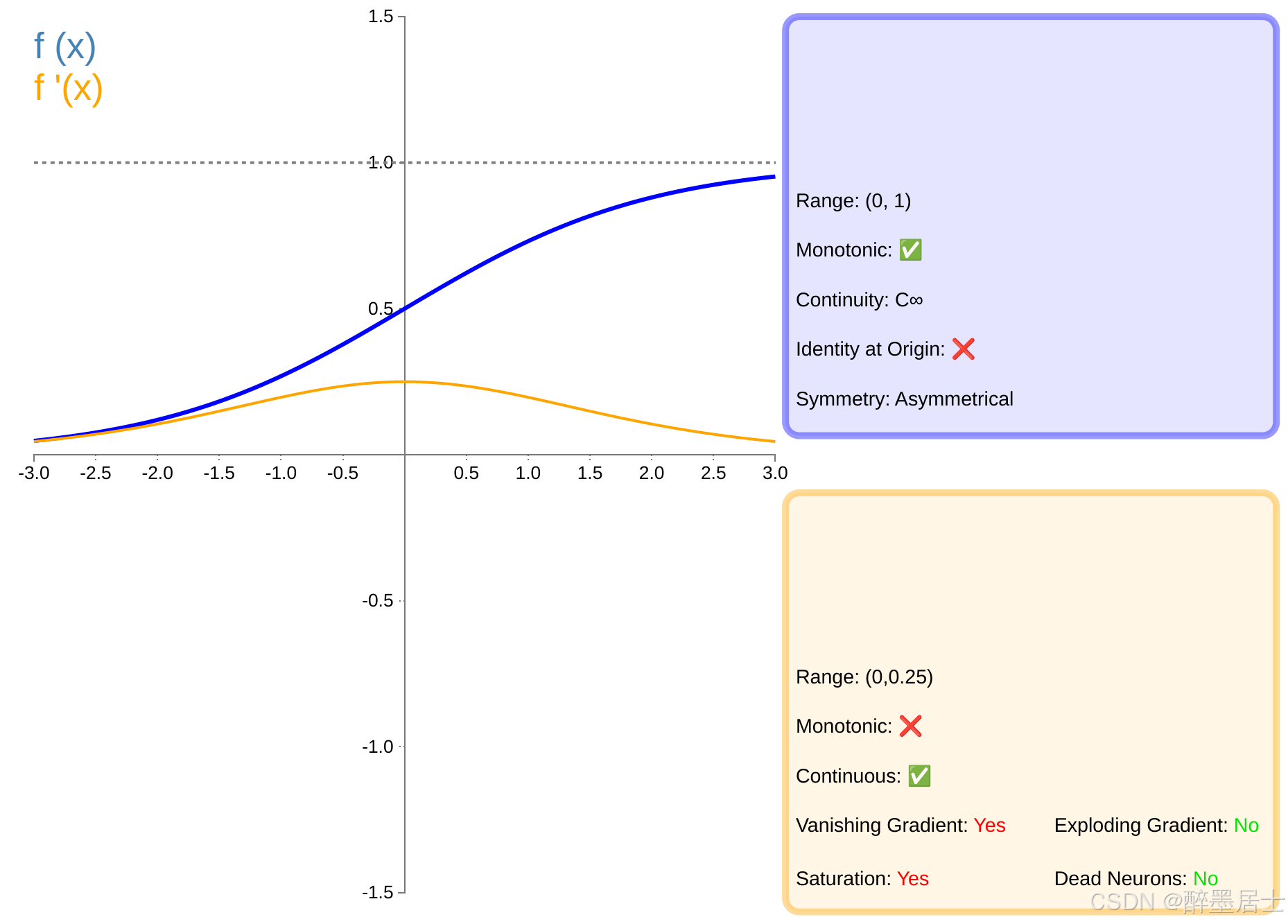
Sigmoid
-
函数表达式
-
导数表达式
-
图像
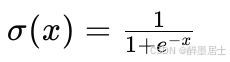
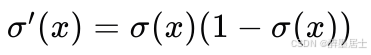
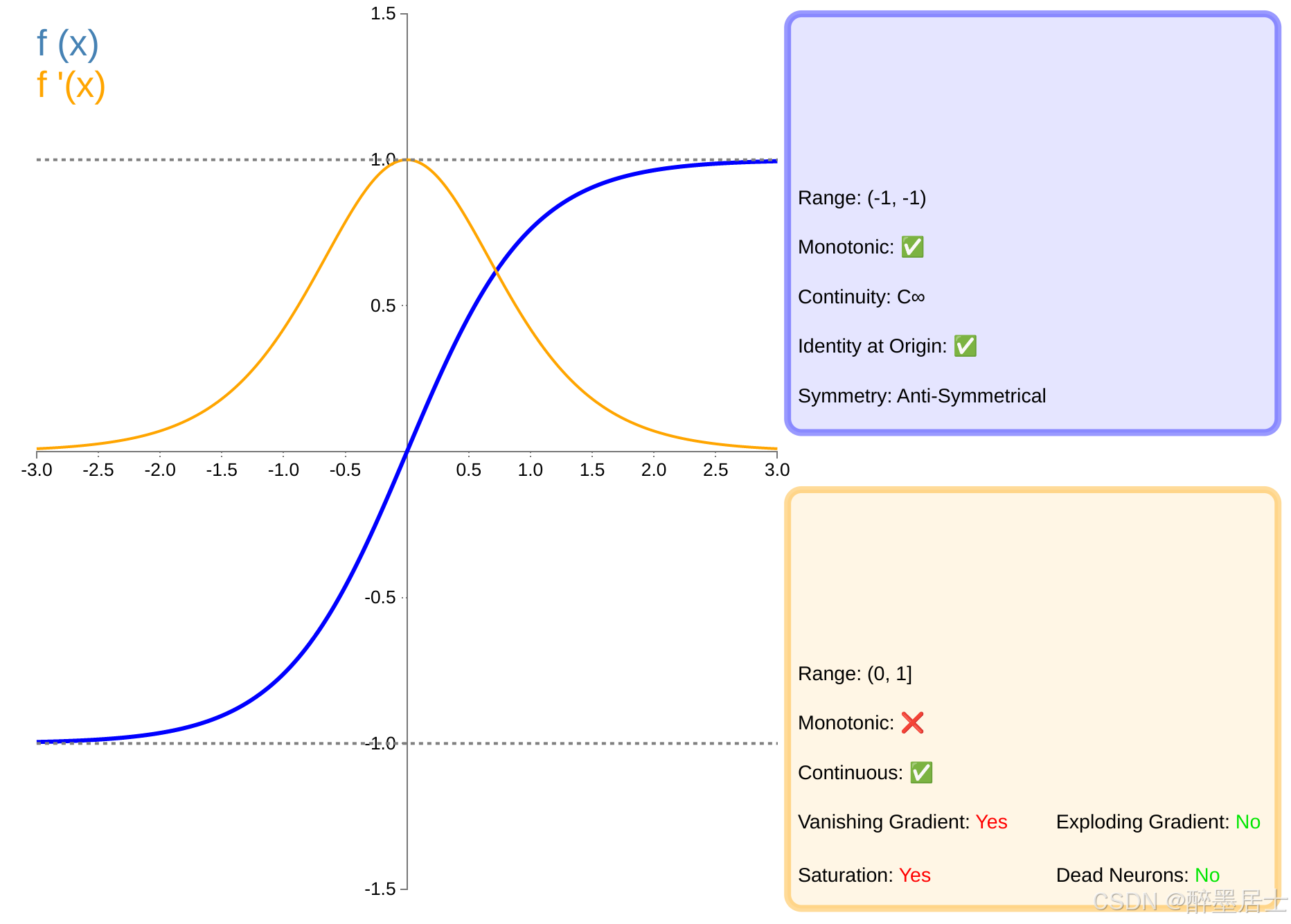
Tanh
-
函数表达式
-
导数表达式
-
图像
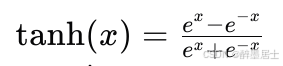
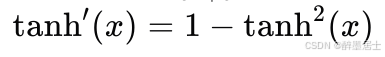
Relu
-
函数表达式
-
导数表达式
-
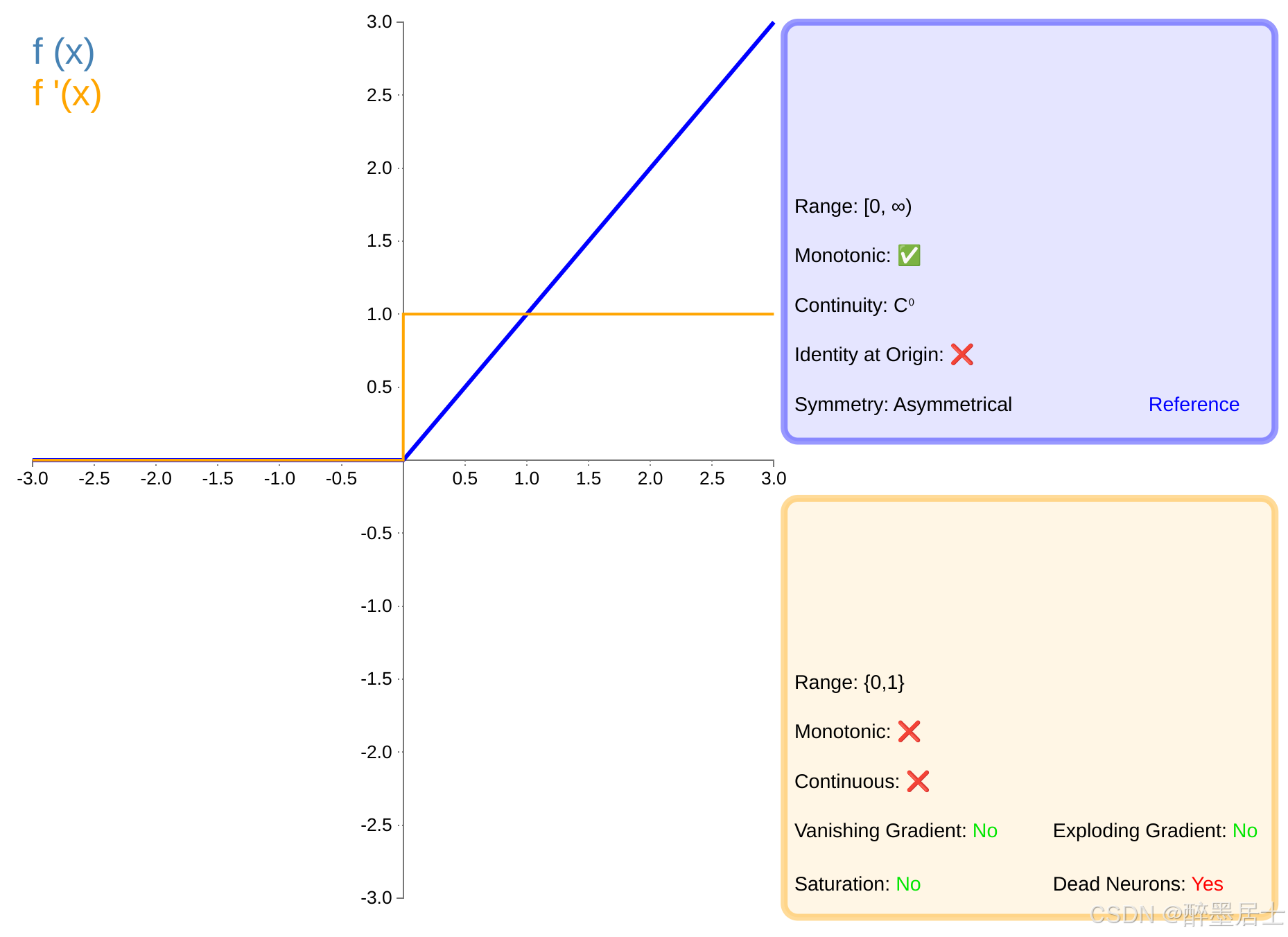
图像
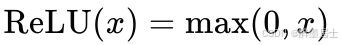
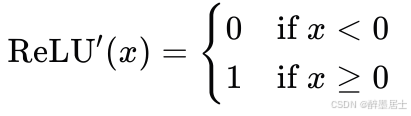
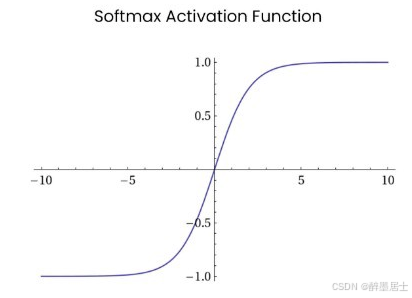
softmax
-
函数表达式
-
导数表达式
-
图像
-
说明
能够将多个输入转换成一组对应输入在[0, 1]范围内的概率值,并且输入对应的概率值之和为1,下图形象的表明了输出层经过Softmax变换的处理过程
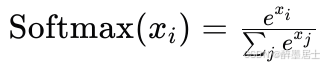
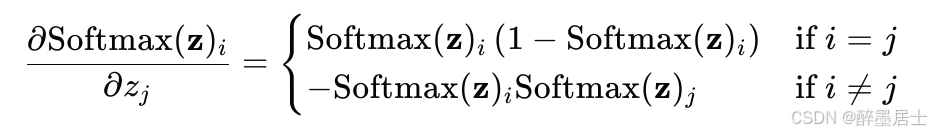
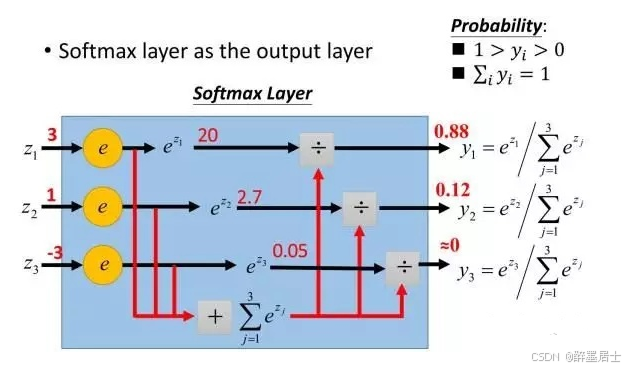
能够结合模型输出结果与理论输出结果通过交叉商执行损失函数计算损失值,评估预测结果与实际结果的偏离程度,进行梯度下降,不断缩小损失值,让模型能够不断拟合真实场景
通用近似定理
通用近似定理指出,只要神经网络包含足够多的隐层神经元,就可以使用任意精度来逼近任何预定的连续函数
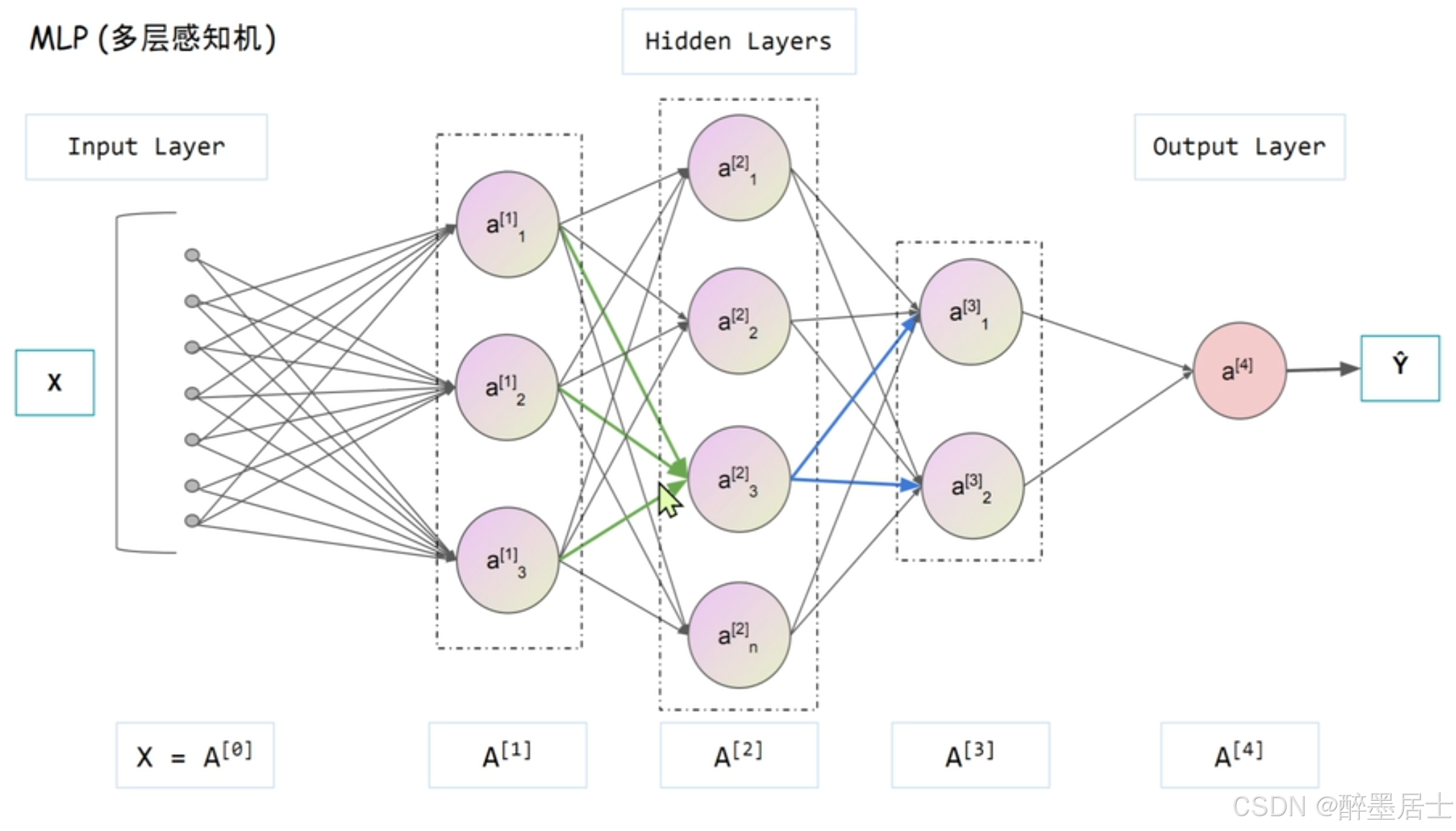
多层感知机(MLP)
多层感知机由输入层(Input Layer),隐藏层(Hidden Layers),输出层(Output Layer)
隐藏层可以是多层也可以是单层,下图就是一个三层的隐藏层。隐藏层越多,神经网络能够拟合的函数也就越复杂,其表达能力也会越强
对于多层隐藏层来说,每一层的每一个神经元能够汇总上一层输出的所有结果
拟合
对于我们的神经网络内部参数的权重在神经网络初始化的时候都是随机数,如何能够使神经网络不断拟合实际函数,这就需要引入两个概念,分别是前向传播和反向传播
-
正向传播
给定神经网络输入,计算神经网络实际输出和理想输出的损失值,评估神经网络拟合程度,从输入层开始,计算输出,然后逐层向后传递这些输出作为输出,最终根据损失函数计算实际输出与理想输出的损失值 -
反向传播
让各个神经元沿着损失函数梯度下降方向,调整和优化神经元中的权重,减少损失值,使神经网络进一步拟合真实函数,从输出层开始,计算损失函数相对于每个参数的梯度,然后逐层向前传递这些梯度以更新参数
最后
我是醉墨居士,感谢您的阅读,后续我会持续输出优质的文章,让大家一起互相进步
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大语言模型理论基础

发表评论 取消回复