八朴素贝叶斯分类
1贝叶斯分类理论
选择具有最高概率的决策
2条件概率
在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。
𝑃(𝐴|𝐵)=𝑃(B|A)𝑃(𝐴)/𝑃(𝐵)
3全概率公式
𝑃(𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)+𝑃(𝐵|𝐴′)𝑃(𝐴′)
那么条件概率的另一种写法为:
$$
P(A|B)=\frac{P(B|A)P(A)}{P(B|A)P(A)+P(B|A^,)P(A^,)}
$$
具体可以参考:
一文搞懂贝叶斯定理(原理篇) - Blogs - 廖雪峰的官方网站 (liaoxuefeng.com)
4贝叶斯推断

P(A):"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B:"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B):"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
此公式可以理解为:后验概率 = 先验概率x调整因子
即通过不断的实验结果去调整先验概率,从而得到更接近事实的后验概率。
5朴素贝叶斯推断
条件相互独立的贝叶斯推断

由于特征之间的条件独立性,可以分解为


朴素贝叶斯分类器就可以通过计算每种可能类别的条件概率和先验概率,然后选择具有最高概率的类别作为预测结果。
6拉普拉斯平滑系数
避免某些从未出现过的事件或特征的概率被估计为0,拉普拉斯平滑系数可以避免这种零概率陷阱。
$$
P(F1|C) = (Ni+α)/(N+αm)
$$
一般α取值1,m的值为总特征数量
避免因为某个从未出现过的特征的概率被预估为0,从而出现的过拟合或者预测错误
7API
sklearn.naive_bayes.MultinomialNB() estimator.fit(x_train, y_train) y_predict = estimator.predict(x_test)
eg1
#用朴素贝叶斯实现对鸢尾花的分类
from sklearn.datasets import load_iris
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
import joblib
# 实例化贝叶斯分类器
model=MultinomialNB()
# 加载鸢尾花数据集
X, y = load_iris(return_X_y=True)
# 划分数据集
x_train,x_test,y_train,y_test=train_test_split(X, y,train_size=0.8,random_state=666,stratify=y)
# 训练
model.fit(x_train,y_train)
# 评估
score=model.score(x_test,y_test)
print(score)
# 保存模型
joblib.dump(model,"./model/bayes.bin")
#加载和预测模型
model=joblib.load("./model/bayes.bin")
y_pred=model.predict([[1,2,3,4]])
print(y_pred)eg2
# 泰坦尼克的数据集 贝叶斯分类
import pandas as pd
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
data=pd.read_csv("./src/titanic/titanic.csv")
x=data[["age","sex","pclass"]]
# 数据处理
# age中的缺失值处理成众数
x["age"].fillna(x["age"].value_counts().index[0],inplace=True)
x["sex"]=[0 if i=="male" else 1 for i in x["sex"]]
# print(x)
x["pclass"]=[int(i[0]) for i in x["pclass"]]
print(x)
y=data[["survived"]]
# y
# # 创建模型
model=MultinomialNB()
# # 数据集划分
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2)
# # 训练
model.fit(x_train,y_train)
# # 评估
print(model.score(x_test,y_test))
# 预测
y=model.predict([[22,1,1]])
print(y)
九 决策树-分类
1概念
决策节点:通过条件判断而进行分支选择的节点
叶子节点:没有子节点的节点,表示最终的决策结果
决策树的深度:所有节点的最大层次数,根节点的层次数定为0
决策树优点:可视化 - 可解释能力-对算力要求低
决策树缺点:容易产生过拟合
2信息增益决策树
1.信息熵
反映信息的不确定性。信息熵越大,不确定性越大。
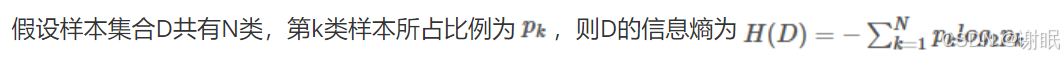
2.信息增益

3.步骤
计算根节点的信息熵-计算属性的信息增益-划分属性-剔除根节点属性,再次计算根节点信息熵和属性的信息增益
3基尼指数决策树
基尼指数(Gini Index)是决策树算法中用于评估数据集纯度的一种度量,基尼指数衡量的是数据集的不纯度,或者说分类的不确定性。
基尼指数被用来决定如何对数据集进行最优划分,以减少不纯度。
计算:
对于一个二分类问题,如果一个节点包含的样本属于正类的概率是 (p),则属于负类的概率是 (1-p)

多分类问题:

意义
-
当一个节点的所有样本都属于同一类别时,基尼指数为 0,表示纯度最高。
-
当一个节点的样本均匀分布在所有类别时,基尼指数最大,表示纯度最低。
应用:
决策树算法逐步构建一棵树,每一层的节点都尽可能地减少基尼指数,最终达到对数据集的有效分类。
4API
class sklearn.tree.DecisionTreeClassifier(....)
参数:
criterion "gini" "entropy” 默认为="gini"
当criterion取值为"gini"时采用 基尼不纯度(Gini impurity)算法构造决策树,
当criterion取值为"entropy”时采用信息增益( information gain)算法构造决策树.
max_depth int, 默认为=None 树的最大深度
# 可视化决策树
function sklearn.tree.export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
参数:
estimator决策树预估器
out_file生成的文档
feature_names节点特征属性名
功能:
把生成的文档打开,复制出内容粘贴到"http://webgraphviz.com/"中,点击"generate Graph"会生成一个树型的决策树图
eg3
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
model=DecisionTreeClassifier(criterion="entropy",max_depth=3)#entropy信息熵的方式构建决策树 默认gini构建决策树
x,y=load_iris(return_X_y=True)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
scaler=StandardScaler()
scaler.fit(x_train)
x_train=scaler.transform(x_train)
model.fit(x_train,y_train)
x_test=scaler.transform(x_test)
rank=model.score(x_test,y_test)
print(rank)
y_pred=model.predict([[1,1,1,1],[2,2,2,2]])
print(y_pred)
# 决策过程可视化
export_graphviz(model,out_file="./model/tree.dot",feature_names=["花萼长度","花萼宽度","花瓣长度","花瓣宽度"])本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习day4-朴素贝叶斯分类和决策树

发表评论 取消回复