点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(已更完)
- Kylin(已更完)
- Elasticsearch(已更完)
- DataX(已更完)
- Tez(已更完)
- 数据挖掘(已更完)
- Prometheus(已更完)
- Grafana(已更完)
- 离线数仓(正在更新…)
章节内容
上节我们完成了如下的内容:
- 业务分析
- 数据埋点
- 指标体系
- 维度拆解
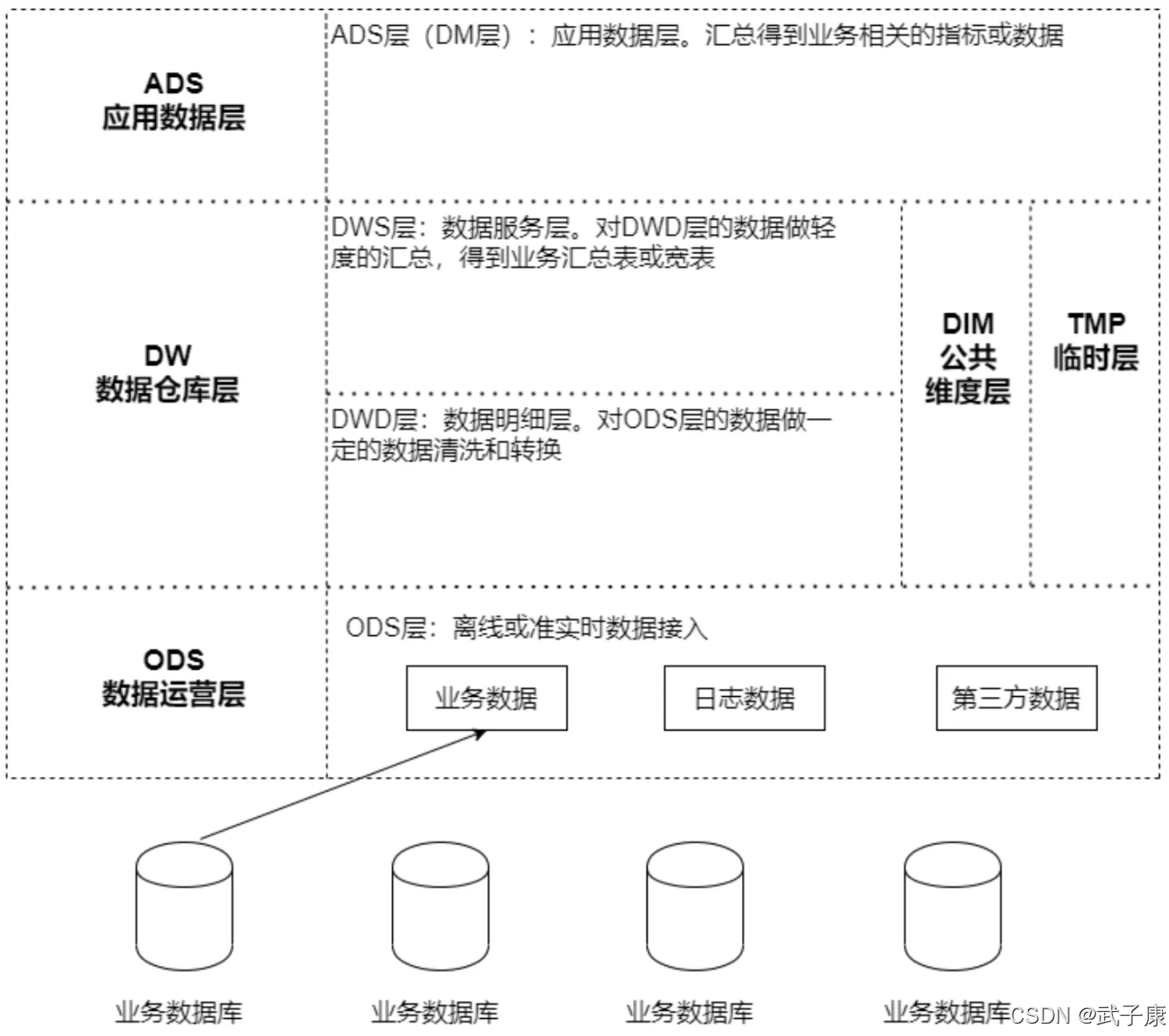
总体架构设计
技术方案选型
- 框架选型
- 软件选型
- 服务器选型
- 集群规模的估算
框架选型
Apache或第三方发行版(CDH、HDP、Fusion Insight)
Apache社区版本
优点:
- 完全开源免费
- 社区活跃
- 文档、资料详实
缺点:
- 复杂的版本管理
- 复杂的集群安装
- 复杂的集群运维
- 复杂的生态环境
第三方发行版本
CDH、HDP、Fusion Insight
Hadoop遵从Apache开源协议,用户可以免费的任意的修改并使用Hadoop,正因如此,市面上有很多厂家在ApacheHadoop的基础上开发了自己的产品,如Cloudera的CDH,Hortonworks的HDP,华为的FusionInsight等,这些产品的优点是:
- 主要功能和社区版本一致
- 版本管理清晰,比如:Cloudera、CDH3、CDH4等,后面加上补丁的版本:CDH4.1.0 patch
- 比ApacheHadoop在兼容性、安全性、稳定性上有增强,第三方发行版通常都是经过了大量的测试验证,有众多部署实例,大量的运用到各种生产环境中
- 版本更新快,如CDH每个季度会有一个Update,每一年都有一个Release
- 基于稳定版的ApacheHadoop,并应用了最新Bug修复、Feature的patch
- 提供了部署、安装、配置工具,大大提高了集群的安装效率,可以在几个小时之内安装好集群。
- 运维简单,提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速,准确,使运维工作简单,有效
主要的版本有如下的这些:
- CHD:最成型的发行版本,拥有最多的部署案例,提供强大的部署、管理和监控工具,国内使用最大的版本,拥有强大的社区支持,当遇到问题,能够通过社区、论坛等网络资源快速获取解决方法
- HDP:100%开源,可以进行二次开发,但没有CDH稳定,国内使用相对较少
- Fusion Insight:华为基于Hadoop2.7.2版开发的,坚持分层,解耦,开放的原则,得益于高可靠性,在全国各地政府、运营商、金融系统有较多案例
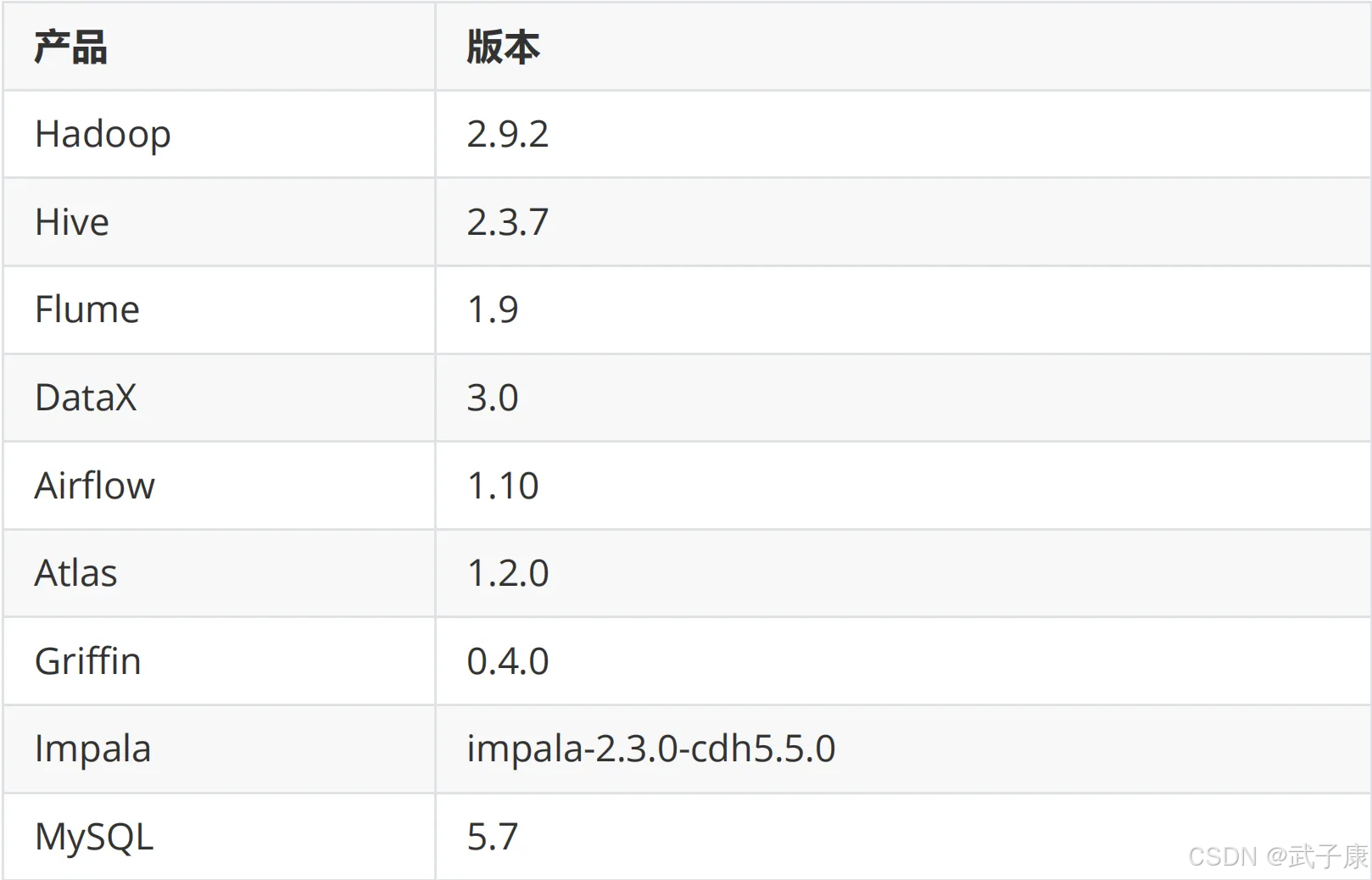
软件选型
- 数据采集:DataX、Flume、Sqoop、Logstash、Kafka
- 数据存储:HDFS、HBase
- 数据计算:Hive、MapReduce、Tez、Spark、Flink
- 调度系统:Airflow、azkaban、Oozie
- 元数据管理:Atlas
- 数据质量管理:Griffin
- 即席查询:Impala、Kylin、ClickHouse、Presto、Druid
- 其他:MySQL
框架,软件尽量不要选择最新的版本,选择半年前左右的稳定版本。
服务器选型
选择物理机还是云主机:
- 机器成本考虑:物理机的价格 > 云主机的价格
- 运维成本考虑:物理机需要有专业的运维人员,云主机的运维工作由供应商完成,运维相对容易,成本相对较低
集群规模
如何确认集群规模(假设:每台服务器20T硬盘,128GB内存)
可以从计算能力、CPU、内存、存储量等方面考虑集群规模。
假设:
- 每天的日活500万,平均每人每天有100条日志信息
- 每条日志大小1K左右
- 不考虑历史数据,半年集群不扩容
- 数据3个副本
- 离线数据仓库应用
这种情况下,需要多大的集群规模?
要分析的数据有两部分:日志数据+业务数据
- 每天日志数据量:500W1001K / 1024 / 1024 = 500G
- 半年需要存储量:500G * 3 * 180 / 1024 = 260T
- 通常要给磁盘预留 20%-30%的空间: 260*1.25 = 325T
- 数据仓库应用有1-2倍的数据膨胀325T * 1.5 = 500T
- 需要大约25个节点
其他未考虑的因素:数据压缩、业务数据
以上估算的生产环境,实际上除了生产环境以外,还需要开发测试环境,这也需要一定数量的机器。
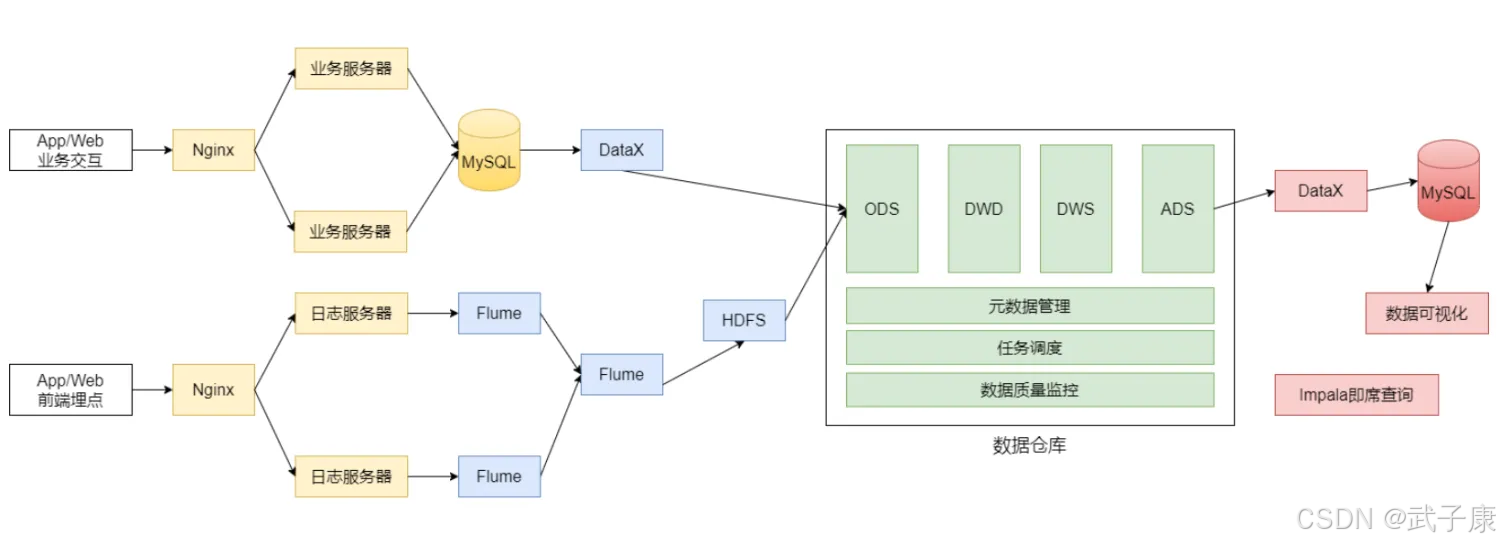
系统逻辑架构
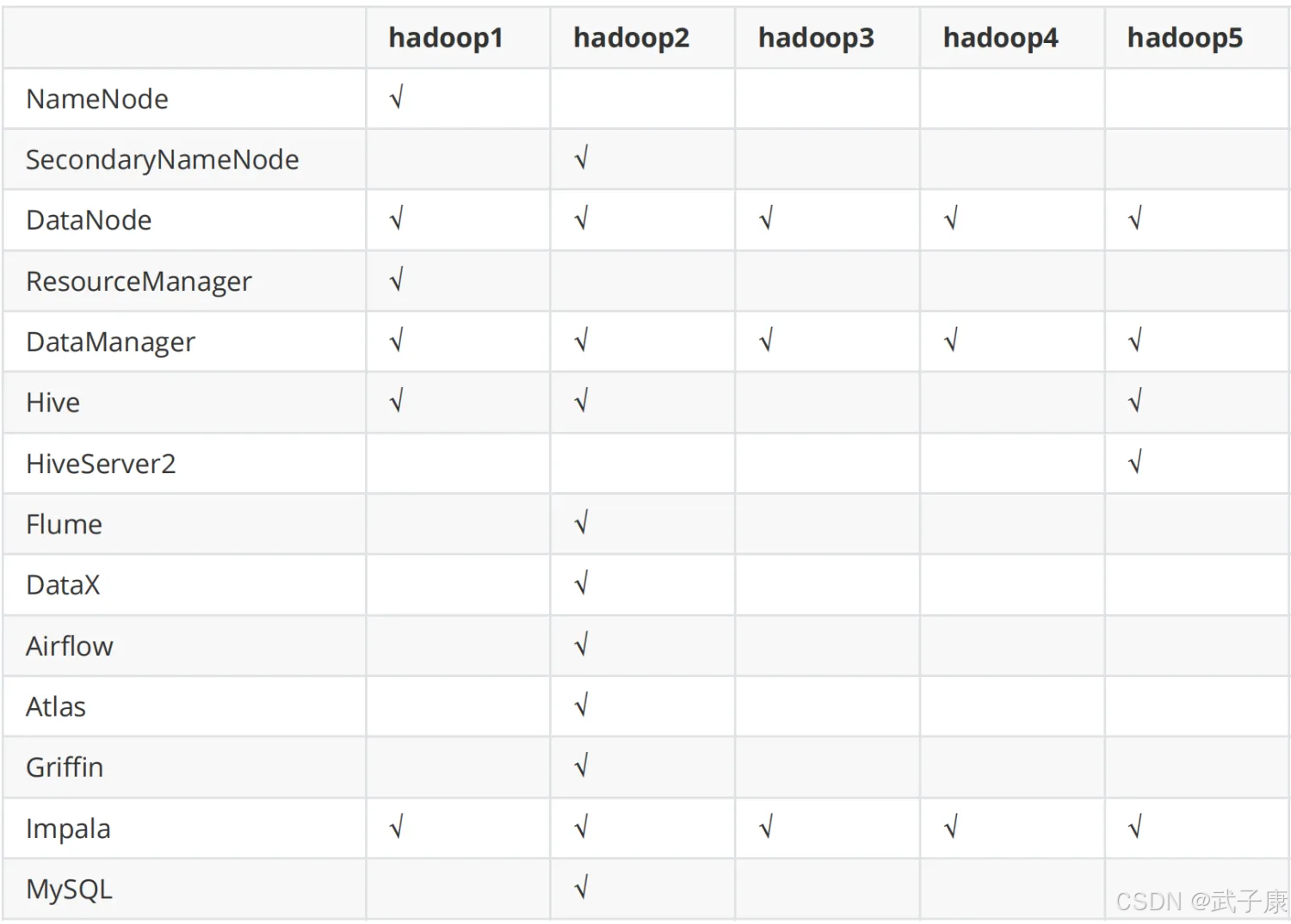
服务器软件配置如下所示:
数据仓库命名规范
数据库命名
- 命名规则:数仓对应分层
- 命名示例:ods/dwd/dws/dim/temp/ads
数仓各层对应数据库
- ods层 => ods_{业务线|业务项目}
- dw层 => dwd_{业务线|业务项目} + dws_{业务线|业务项目}
- dim => dim_维表
- ads => ads_{业务线|业务项目} (统计指标等)
- 临时数据 => temp_{业务线|业务项目}
(备注:本项目未使用)
表命名(数据库表命名)
- ODS层:ods_{业务线|业务项目}[数据来源类型]{业务}
- DWD层:dwd_{业务线|业务项目}{主题域}{子业务}
- DWS层:dws_{业务线|业务项目}{主题域}{汇总相关粒度}_{汇总时间周期}
- ADS层:ads_{业务线|业务项目}{统计业务}{报表form|热门排序topN}
- DIM层:dim_{业务线|业务项目|pub公共}_{维度}
创建数据库
我们启动Hive,进行操作:
create database if not exists ods;
create database if not exists dwd;
create database if not exists dws;
create database if not exists ads;
create database if not exists dim;
create database if not exists tmp;
执行结果如下图所示:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据-224 离线数仓 - 数仓 技术选型 版本选型 系统逻辑架构 数据库命名规范

发表评论 取消回复