文章目录
基于HDFS + Hive+mysql搭建离线数仓,最终效果能够通过可视化界面访问数仓数据
架构图
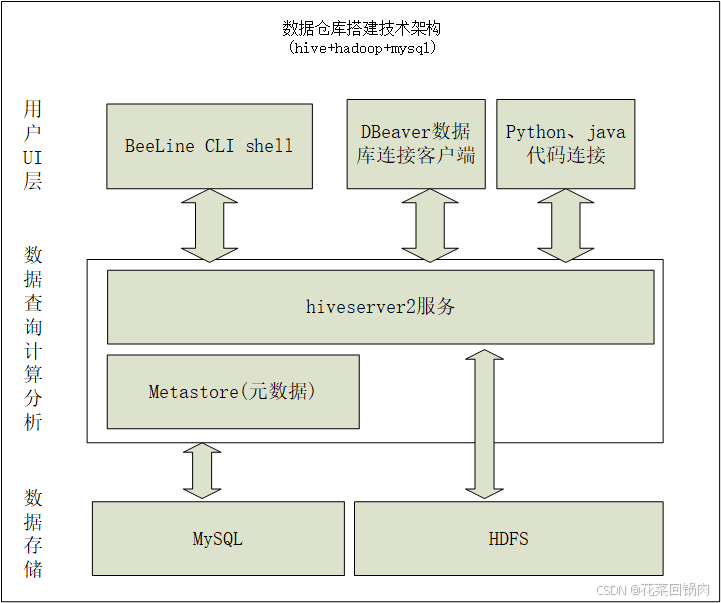
其中,
1 hive 服务包括 metastore元数据 服务和 hiveserver2服务
2 启动metastore元数据服务,metastore元数据存储在MySQL中
3 在metastore服务基础上再启动hiveserver2服务,即可通过代码、客户端、beeline shell去链接hive
4 建的库表存储到hdfs中
Hadoop搭建
由于资源不足,搭建伪分布式,利用Hadoop的HDFS分布式存储功能,可以查看搭建教程
由于资源限制 hadoop环境搭建使用的是 hadoop 用户。
参见Hadoop3.2.1安装-单机模式和伪分布式模式
Hive 搭建
Hive是一个分布式的、支持容错的数仓系统,用于大量数据分析。HMS提供了一个元数据仓库,可以很容易进行数据分析和数据驱动决策。是很多数据湖架构使用的重要的组件。Hive是基于Hadoop,可以利用HDFS存储。支持用户通过SQL语言管理数据。
MySQL搭建
搭建数仓,需要先搭建MySQL,这里不再赘述。
官网文档
https://hive.apache.org/development/gettingstarted/
下载
https://archive.apache.org/dist/hive/
这里选择的是Hive4.0版本
下载bin.tar.gz包,解压
配置
配置hive环境变量
vi /etc/profile
增加如下代码
# Hive
export HIVE_HOME=/home/datahouse/hive-4.0.0
export PATH=$PATH:$HIVE_HOME/bin
保存后,执行刷新命令
source /etc/profile
配置日志文件
# 进入配置文件目录
cd /home/datahouse/hive-4.0.0/conf
将hive-log4j2.properties.template 配置文件复制成 hive-log4j2.properties
并修改配置文件:
#配置日志路径
property.hive.log.dir = /home/datahouse/hive-4.0.0/logs
property.hive.log.file = hive.log
配置hive-site
进入到解压目录(安装目录)
# 进入到配置文件目录
cd /home/datahouse/hive-4.0.0/conf
新建 hive-site.xml文件,增加如下配置内容:
<configuration>
<!-- 指定存储元数据存储的数据库 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>xxxx</value>
</property>
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://127.0.0.1:9083</value>
<description>URI for client to connect to metastore server</description>
</property>
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>yd-ss</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- hiveserver2的高可用参数,如果不开会导致了开启tez session导致hiveserver2无法启动 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>false</value>
</property>
<!--解决Error initializing notification event poll问题-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>tez.mrreader.config.update.properties</name>
<value>hive.io.file.readcolumn.names,hive.io.file.readcolumn.ids</value>
</property>
<!--配置默认计算引擎为mr-->
<property>
<name>hive.execution.engine</name>
<value>mr</value>
</property>
<!--配置HDFS数据目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/datahouse/hive/warehouse</value>
</property>
</configuration>
其中,hive.metastore.warehouse.dir 目录,得是hdfs分布式文件系统下的目录,这个很重要,若是在Linux本地文件系统下创建该目录,后面是会报错的。下面是创建步骤:
# 切换到hadoop账户(因为hadoop是用hadoop用户部署的,所以要切换,如果是root用户部署,可以不用切换)
[root@yd-ss ~]# su hadoop
# 创建文件
[hadoop@yd-ss root]$ hdfs dfs -mkdir -p /home/datahouse/hive/warehouse
# 赋权
[hadoop@yd-ss root]$ hdfs dfs -chmod 777 /home/datahouse/hive/warehouse/
复制mysql 驱动包
找到java 连接MySQL的驱动包,上传到${HIVE_HOME}/lib 目录
可以在maven中央仓库去找,
https://mvnrepository.com/
删除日志包
删除安装路径下的/lib/log4j-slf4j-impl-2.18.0.jar
防止日志出现以下信息:
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/data/soft/apache-hive-4.0.0-beta-1-bin/lib/log4j-slf4j-impl-2.18.0.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/data/soft/hadoop-3.3.5/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
初始化元数据
# 进入到${HIVE_HOME}/bin目录,执行
schematool -initSchema -dbType mysql
初始化元数据在数据库的表信息和数据
启动metastore服务
# bin目录下执行
hive --service metastore
# 查看日志
tail -300f logs/hive.log
启动会报错

需要在/etc/hosts 文件配置 127.0.0.1 yd-ss 的解析
因为/etc/hostname 文件配置了主机名 为 yd-ss
再次启动,需要使用后台方式启动
# 将日志输出到metastore.log
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
使用hive CLI
重大变化:Hive4.0.0中,HiveCLI已经被弃用了,代替它的是Beeline。所以,启动Hive4.0.0时,会默认进入Beeline命令行界面,而不是HiveCLI
启动hiveServer2
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
报错
Caused by: org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=EXECUTE, inode="/tmp/hive/_resultscache_":hadoop:supergroup:drwx------
原因是/tmp/hive/_resultscache_目录权限问题,/tmp/hive/_resultscache_ 文件夹 所属用户hadoop,权限为所有者777,但组和其他用户权限都为0,即只有hadoop用户有rwx权限,其他用户无权限。
解决方案:登录hadoop用户,给该文件赋权
# 切换到hadoop 用户
[root@yd-ss bin]# su hadoop
#切换到 hadoop 安装目录bin下,执行赋权命令
[hadoop@yd-ss bin]$ hdfs dfs -chmod 777 /tmp/hive/_resultscache_
再次启动,即可顺利启动。当时在这个错误纠结了2天时间,关键的是在赋权这个操作上。
访问hiveserver2
通过查看启动日志,webui服务默认是在10002端口启动的,输入以下地址即可访问
http://localhost:10002/
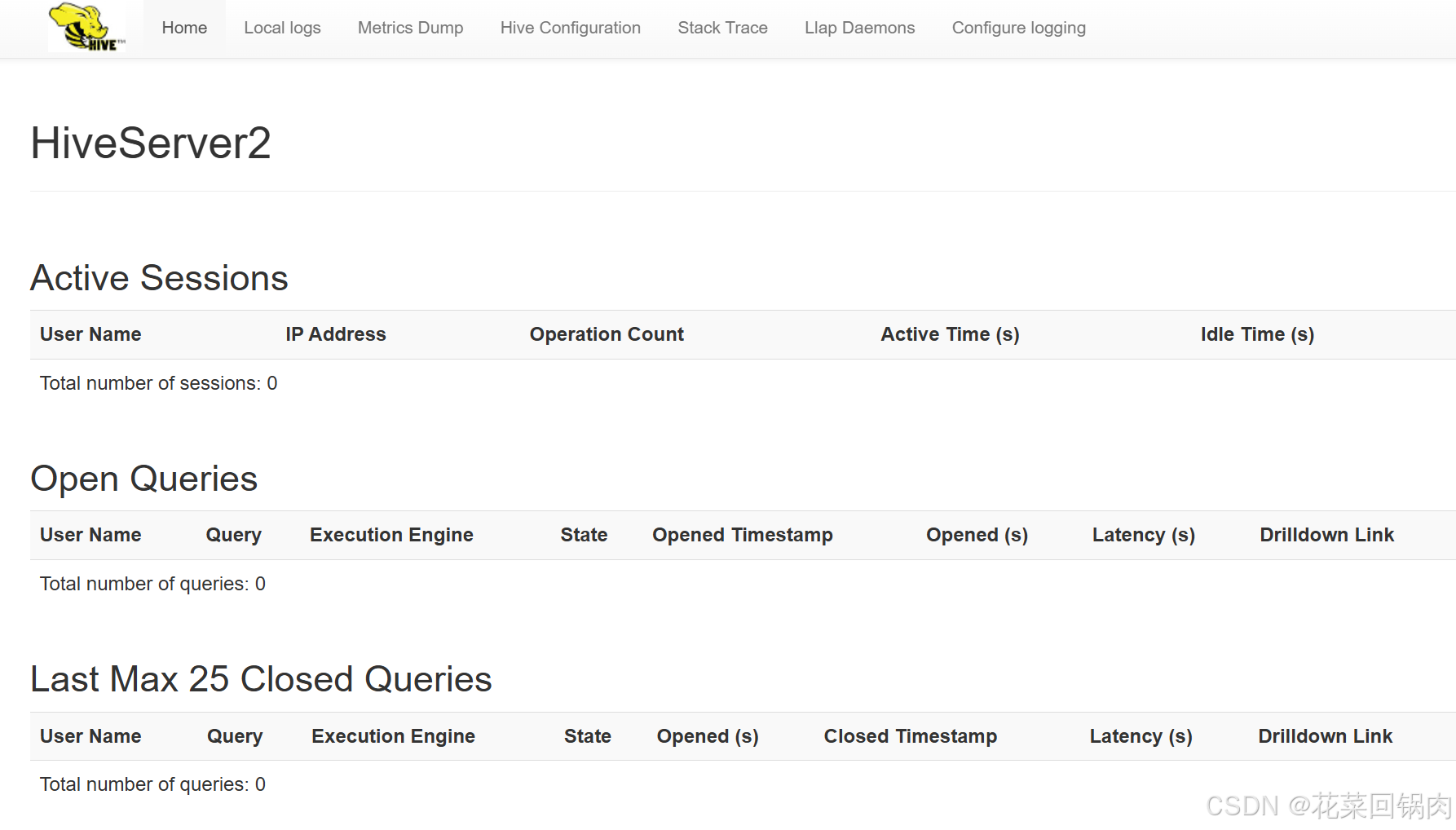
若报错,则需要在hadoop中core-site.xml配置如下参数:
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
客户端连接
beeline shell连接
# 到hive安装bin目录下执行,yd-ss代表当前主机名
beeline -u jdbc:hive2://yd-ss:10000 --verbose=true -n root
这个很类似MySQL的shell连接方式,如下:
[root@yd-ss bin]# beeline -u jdbc:hive2://yd-ss:10000 --verbose=true -n root
!connect jdbc:hive2://yd-ss:10000 root [passwd stripped]
Connecting to jdbc:hive2://yd-ss:10000
Connected to: Apache Hive (version 4.0.0)
Driver: Hive JDBC (version 4.0.0)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 4.0.0 by Apache Hive
0: jdbc:hive2://yd-ss:10000>
执行下面脚本:
CREATE DATABASE test;
show databases;
0: jdbc:hive2://yd-ss:10000> CREATE DATABASE test;
going to print operations logs
printed operations logs
Getting log thread is interrupted, since query is done!
INFO : Compiling command(queryId=root_20241113173452_2e942d82-8b36-4dcd-9212-d3bdbd72dc92): CREATE DATABASE test
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=root_20241113173452_2e942d82-8b36-4dcd-9212-d3bdbd72dc92); Time taken: 0.003 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20241113173452_2e942d82-8b36-4dcd-9212-d3bdbd72dc92): CREATE DATABASE test
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20241113173452_2e942d82-8b36-4dcd-9212-d3bdbd72dc92); Time taken: 0.147 seconds
No rows affected (0.173 seconds)
0: jdbc:hive2://yd-ss:10000> show databases;
going to print operations logs
printed operations logs
Getting log thread is interrupted, since query is done!
INFO : Compiling command(queryId=root_20241113173512_cfc13da2-518b-406c-946d-83888acf6d37): show databases
INFO : Semantic Analysis Completed (retrial = false)
INFO : Created Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=root_20241113173512_cfc13da2-518b-406c-946d-83888acf6d37); Time taken: 0.02 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=root_20241113173512_cfc13da2-518b-406c-946d-83888acf6d37): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=root_20241113173512_cfc13da2-518b-406c-946d-83888acf6d37); Time taken: 0.071 seconds
+----------------+
| database_name |
+----------------+
| default |
| test |
+----------------+
2 rows selected (0.218 seconds)
成功执行。基本和MySQL是类似的。
如下,可以看到建的库是存储到hdfs分布式文件系统中的。
[hadoop@yd-ss bin]$ hdfs dfs -ls /home/datahouse/hive/warehouse/
drwxr-xr-x - root supergroup 0 2024-11-14 10:38 /home/datahouse/hive/warehouse/test.db
Dbeaver连接
参考文章《DBeaver连接hive》
连接上后,基本就和mysql操作类似了。
经验
1 hive 包括 metastore元数据服务和hiveserver2服务;
2 hadoop服务是使用hadoop 用户部署的伪分布式模式,hive是使用root用户部署的;
3 apache下的组件是真的难用,文档不清晰,各种xml配置问题;
4 要了解hdfs分布式文件系统和Linux本地文件系统区别,否则很容易遇到文件权限问题;
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 基于Hadoop、hive的数仓搭建实践

发表评论 取消回复