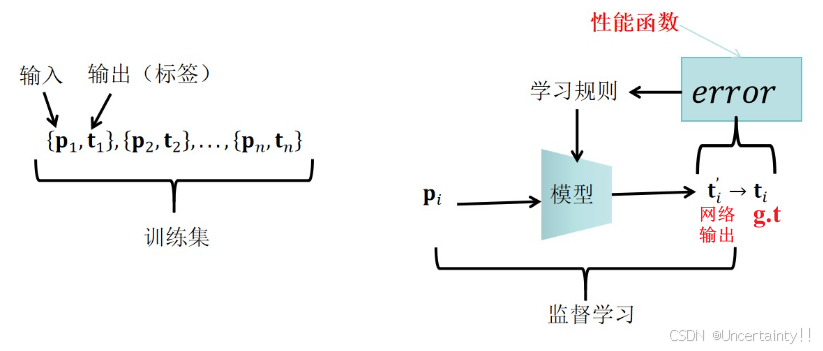
1.初识神经元
1.1 生物神经元
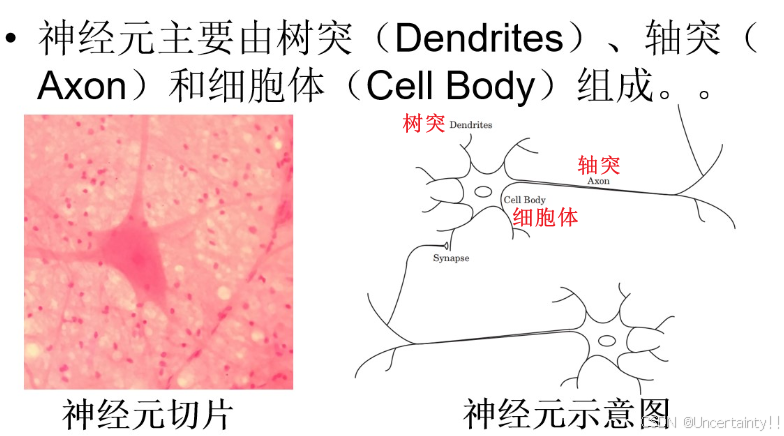
生物神经元的组成
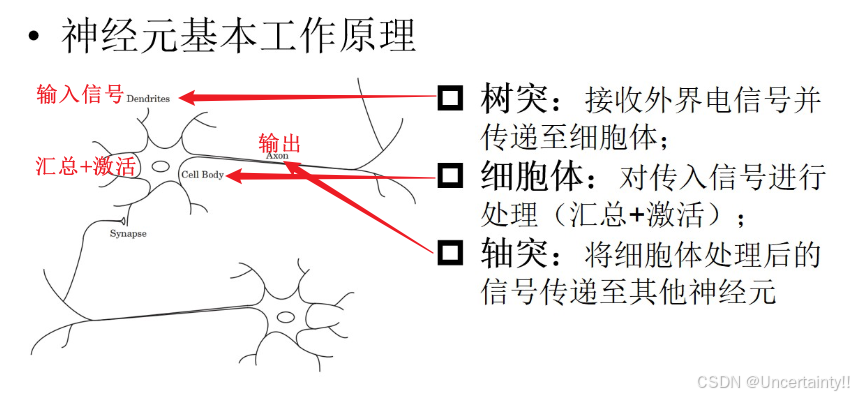
生物神经元的基本工作原理
1.2 人工神经元
人工神经元(对生物神经元的数学建模)


1.3 权重的作用
神经网络中权重的作用

1.4 偏置的作用
神经网络中偏置的作用


1.5 激活函数的作用
下图来自:Most used activation functions in Neural Networks
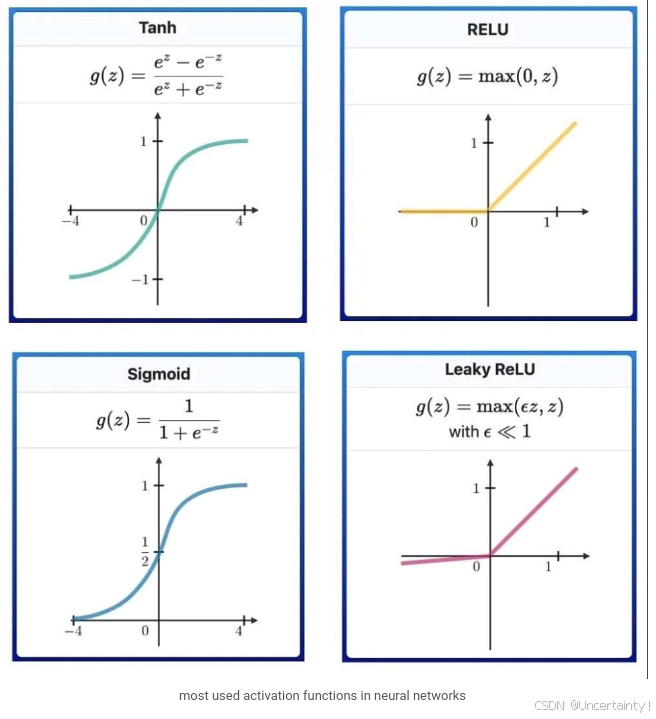
神经网络中激活函数的作用

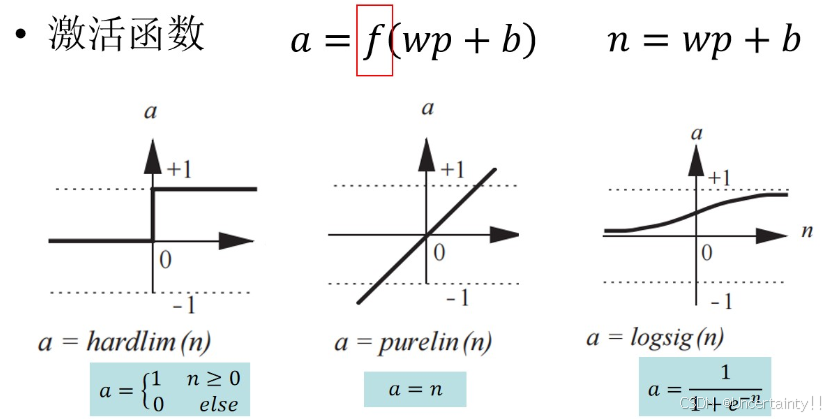

1.5.1 线性激活函数

1.5.2 非线性激活函数



2. 神经元模型
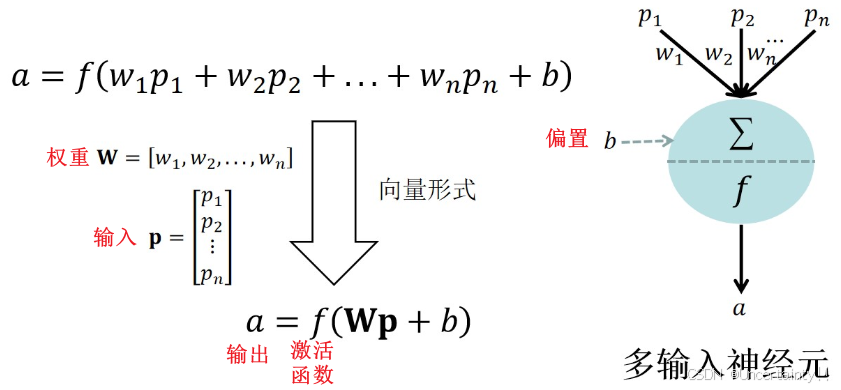
2.1 多输入单神经元模型
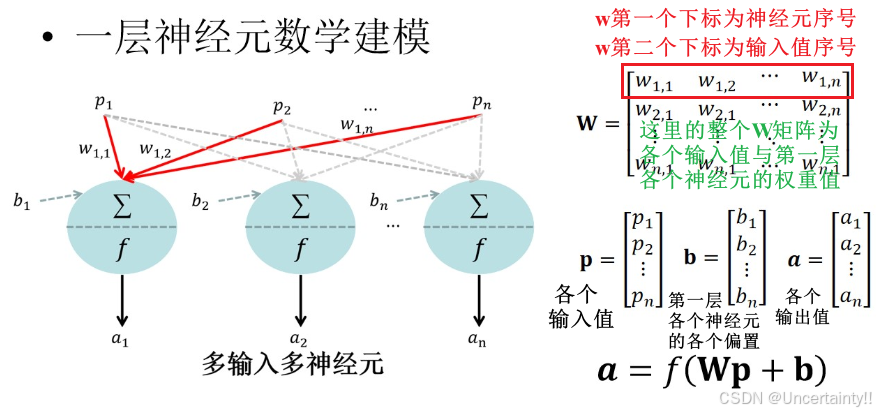
2.2 一层神经元模型
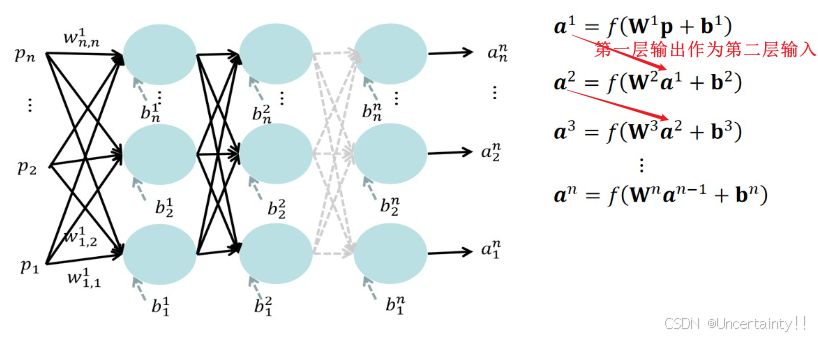
2.3 神经网络(多层神经元)模型
第一层输出作为第二层输入、第二层输出作为第三层输入、
⋯
\cdots
⋯ 层层嵌套(前向传播),所以后续需要链式法则,由内层逐层往外求导,即从输出层逐步到输入层(将梯度反向传播到输出层)
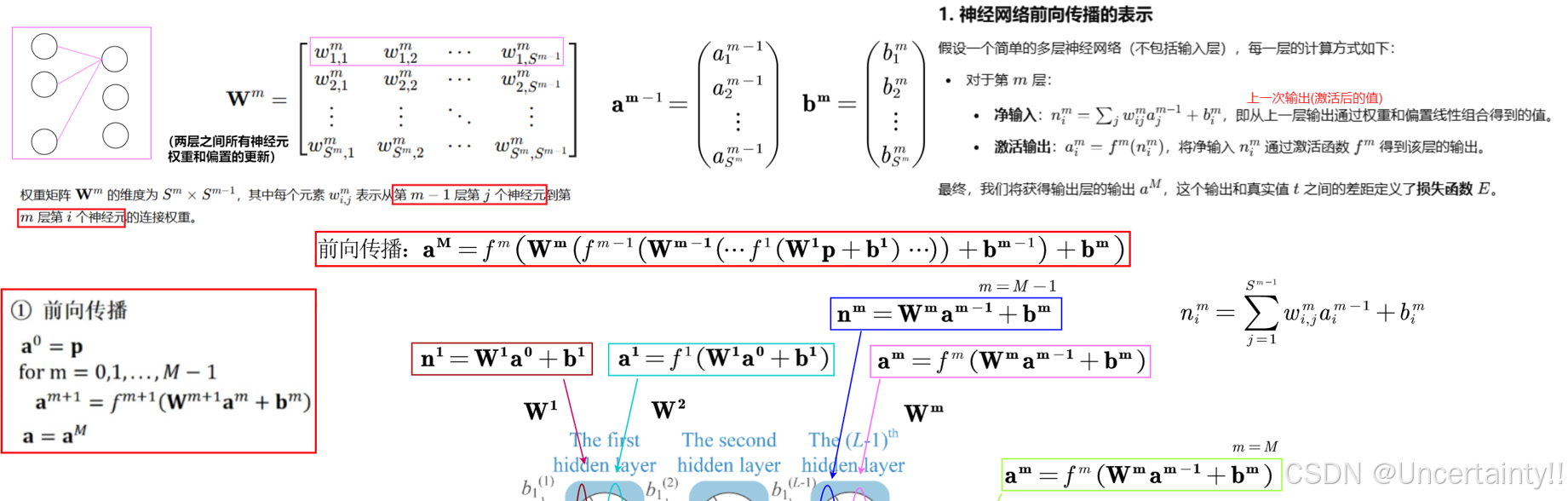
前向传播:
a
n
=
f
(
W
n
(
f
(
W
n
−
1
(
⋯
f
(
W
1
p
+
b
)
⋯
)
+
b
n
−
1
)
+
b
n
)
前向传播:\bold{a}^n=f(\bold{W}^n(f(\bold{W}^{n-1}(\cdots f(\bold{W}^1\bold{p}+\bold{b})\cdots)+\bold{b}^{n-1})+\bold{b}^n)
前向传播:an=f(Wn(f(Wn−1(⋯f(W1p+b)⋯)+bn−1)+bn)
3. 神经网络优化
3.1 损失函数(性能函数/目标函数)


关于L1和L2正则化项的作用详见附录



3.2 神经网络优化的核心思想
关于梯度和方向梯度的知识铺垫详见附录
有了损失函数,我们需要通过损失函数来优化参数(网络中所有权重Weight和偏置Bias),优化的核心思想:
将损失函数在某点处(初始权重和偏置的向量)展开,这就有了对损失函数的局部近似(梯度,线性近似)、Hessian矩阵(局部曲率近似),我们根据这个局部近似找到下一次迭代的点(权重和偏置),这一点处的损失值相比之前损失函数值下降了,由此方式不断迭代最终到达收敛点,收敛点处对应的参数就是神经网络的最优参数
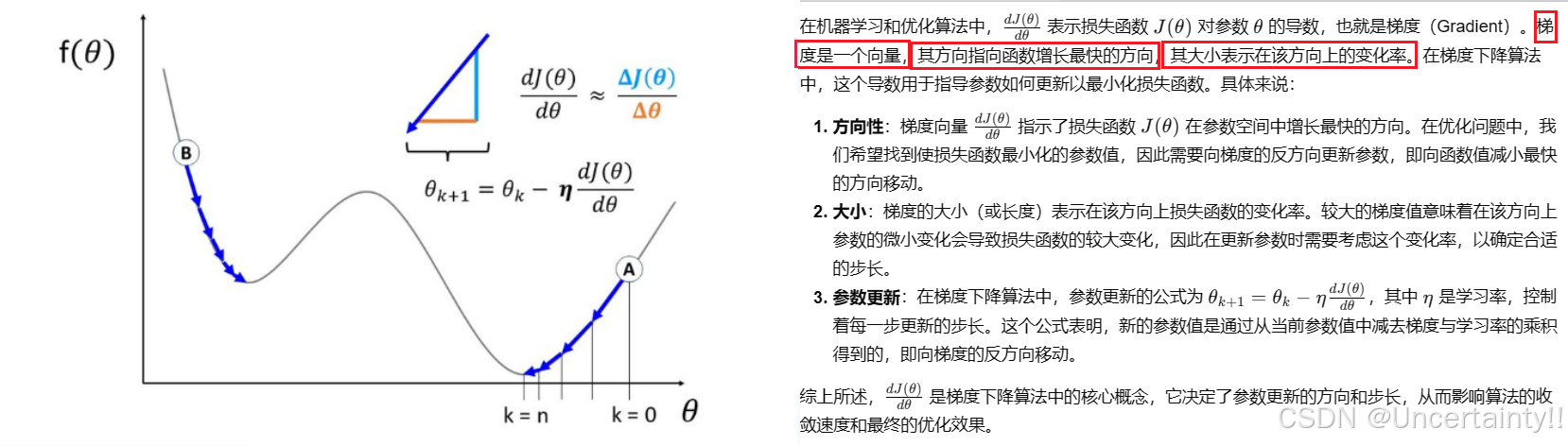
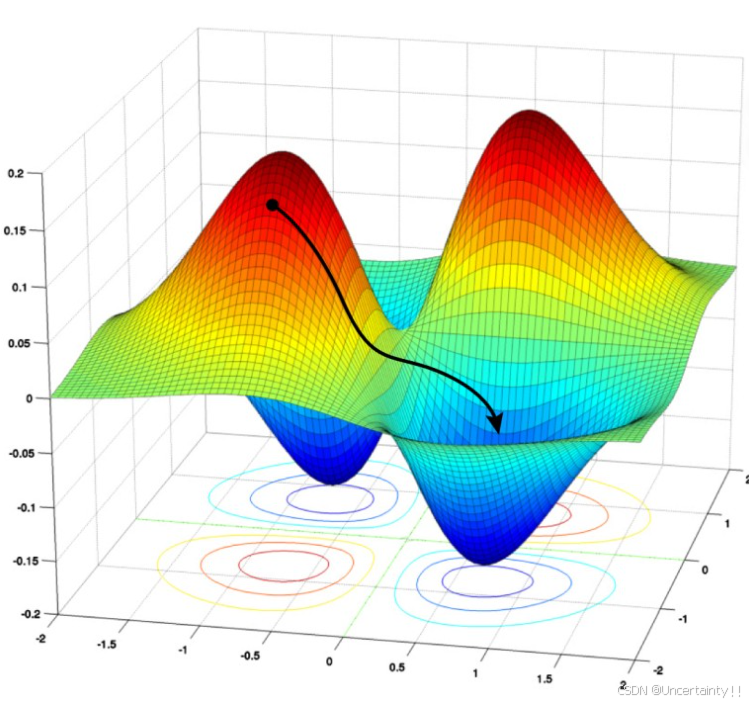
纵轴为损失、横轴为权重,横轴每个点为一个向量
x
k
\bold{x}_k
xk(k次迭代中对应网络中的所有权重)
(1)Starting Point(初始权重
x
k
\bold{x}_k
xk)
(2)Slope(梯度,
∇
L
(
x
k
)
\nabla L(\bold{x}_k)
∇L(xk))
(3)Step Size
Δ
x
k
\Delta\bold{x}_k
Δxk= Learning Rate(
α
\alpha
α)× Slope(
∇
L
(
x
k
)
\nabla L(\bold{x}_k)
∇L(xk))
(4)New Parameter = Old parameter - Step Size
x
k
+
1
=
x
k
+
Δ
x
k
=
x
k
−
α
∇
L
(
x
k
)
\bold{x}_{k+1}=\bold{x}_{k}+\Delta\bold{x}_k=\bold{x}_{k}-\alpha\nabla L(\bold{x}_k)
xk+1=xk+Δxk=xk−α∇L(xk)
(5)Convergence(收敛点)
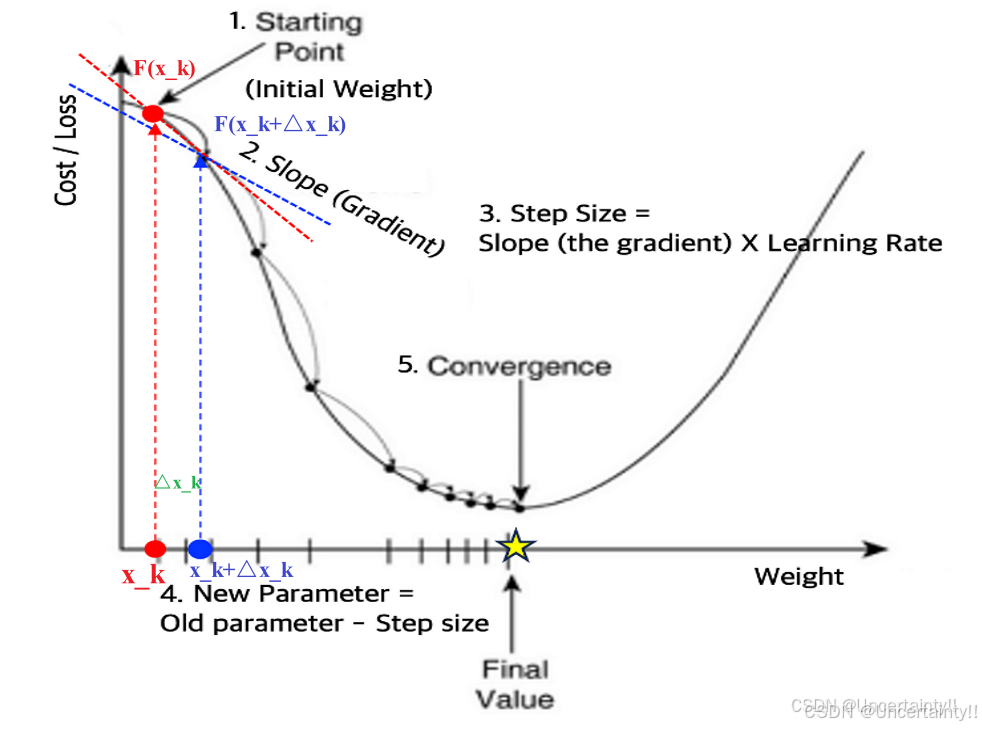


学习率(learning rate)太高或太低都不可取
常数学习率(学习率大小在整个优化期间不变)
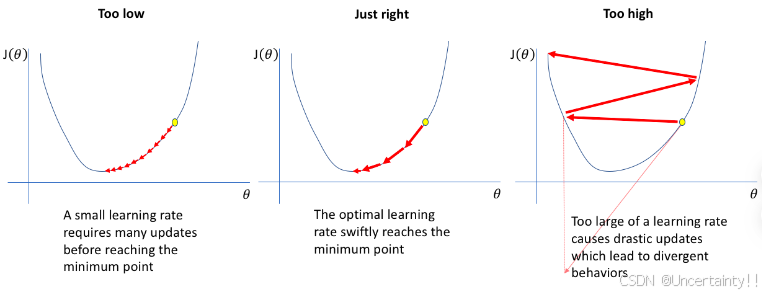
关于学习率的补充知识详见附录

动态学习率(学习率大小在整个优化期间动态变化)
学习率衰减、自适应学习率(AdaGrad、RMSprop、Adam优化算法)

3.2 损失函数的泰勒展开
我们要在损失函数上进行迭代寻找极小值,迭代就需要我们了解损失函数的局部情况,有了局部了解我们就能“逐步的下山了”,所以我们将损失函数进行泰勒展开了解其局部情况
将目标函数一元函数 F ( x ) F(x) F(x)在 x = x ∗ x=x^* x=x∗点处泰勒展开
相关博客:3Blue1Brown系列:泰勒级数(Taylor Series)
单个输入值
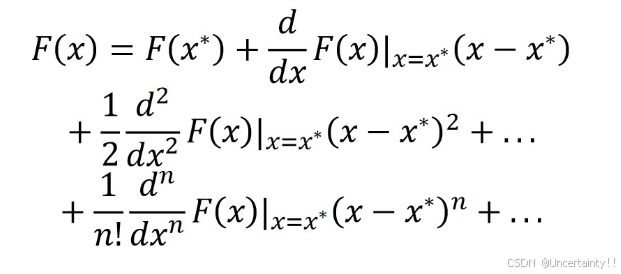
多个输入值(
x
\bold{x}
x为权重和偏置向量)
多元函数
F
(
x
)
F(\bold{x})
F(x)在
x
=
x
∗
x=x^*
x=x∗点泰勒展开
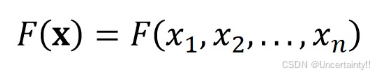
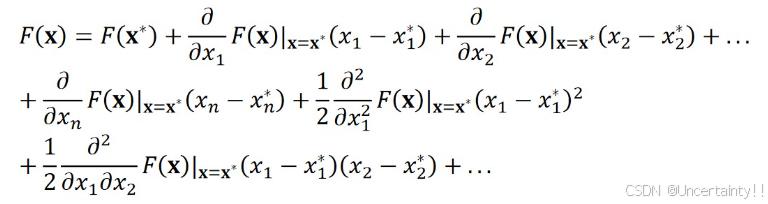




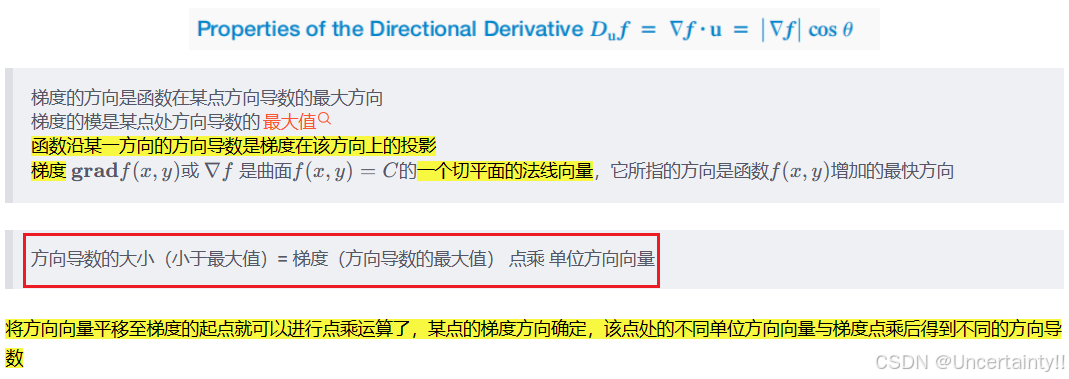
方向导数和梯度的关系
方向导数 = 梯度 ⋅ \cdot ⋅ 某个方向的单位向量
方向导数在神经网络优化中的作用



3.3 损失函数的极值情况
我们要从起始点出发到达损失函数收敛点,该收敛点(极小值点)对应最优的参数,接下来我们分析一下损失函数的极值情况
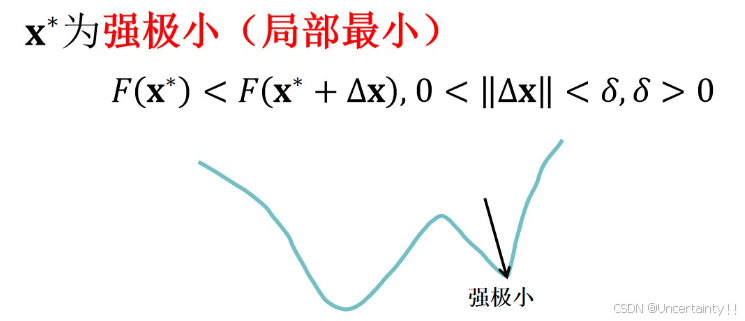
局部极小值,在
[
0
,
δ
]
[0,\delta]
[0,δ]范围内满足某点处函数值恒小于局部其他点的函数值
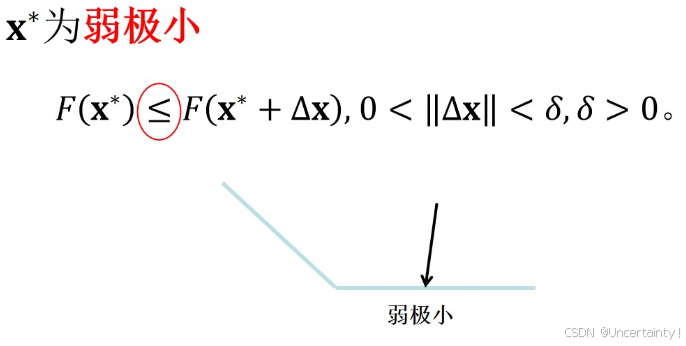
局部弱极小值,在
[
0
,
δ
]
[0,\delta]
[0,δ]范围内满足某点处函数值恒小于等于局部其他点的函数值
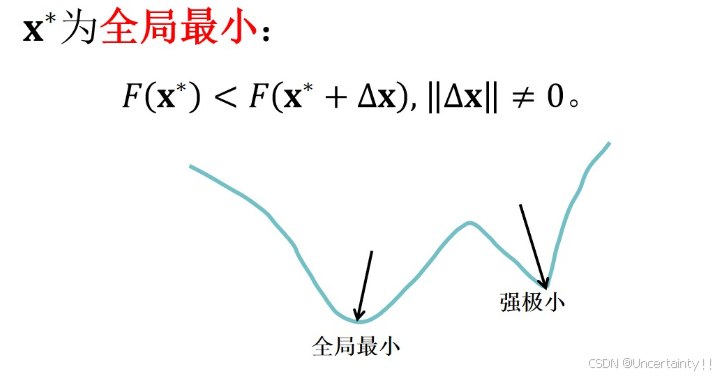
全局最小值,在整个范围内满足某点处函数值恒小于整个范围内其他点的函数值
例:1:
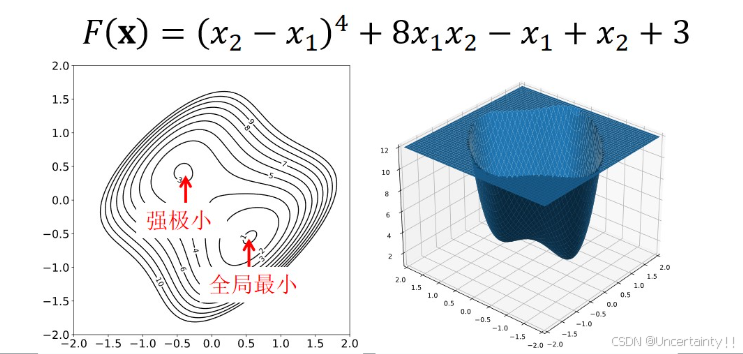
例2:
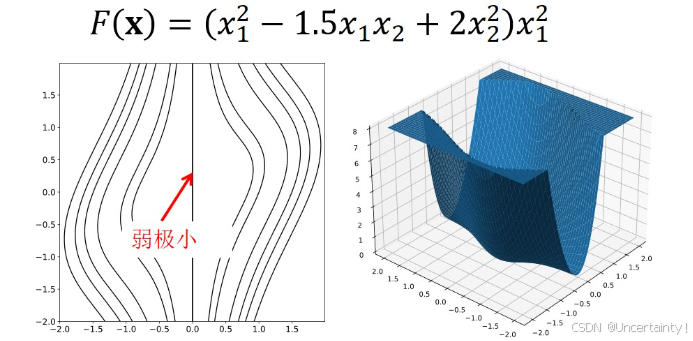
一阶必要条件 (静态点(梯度为0的点)是局部极值的候选点)

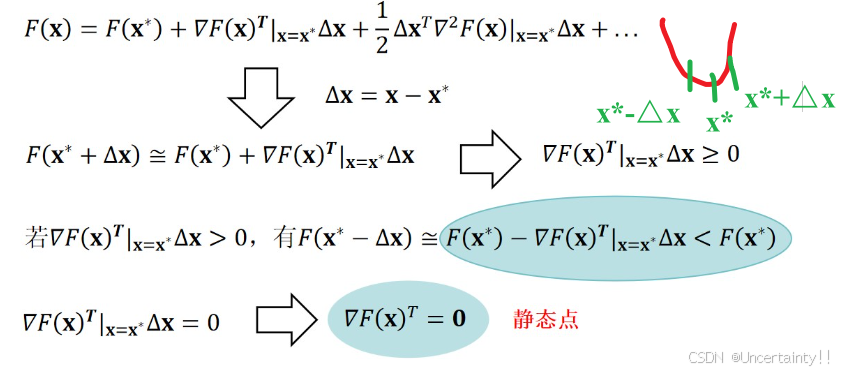
二阶必要条件静态点(梯度为0的点)是极小值的候选点)

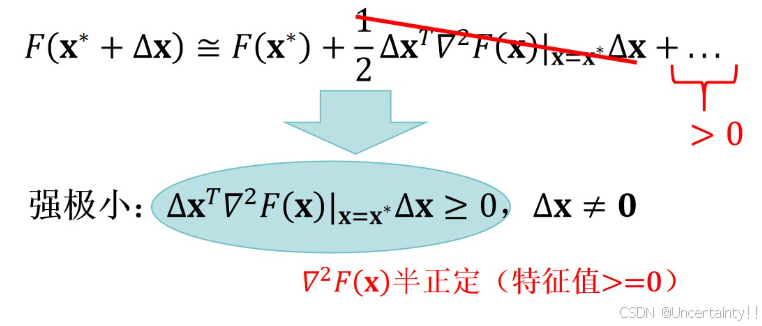
二阶充分条件 (静态点(梯度为0的点)是否为强极小值点)

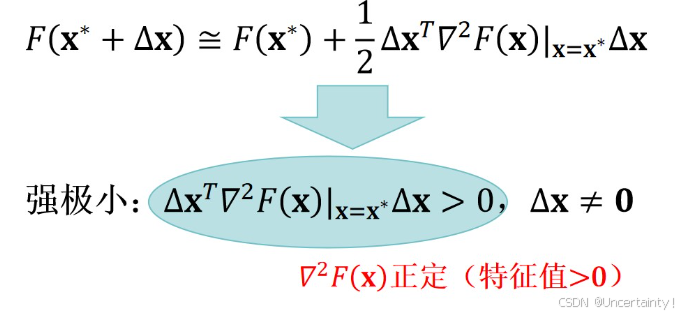
Hessian矩阵的正定性和半正定性
结合损失函数,下图几何代表损失函数在某点处的局部曲率情况
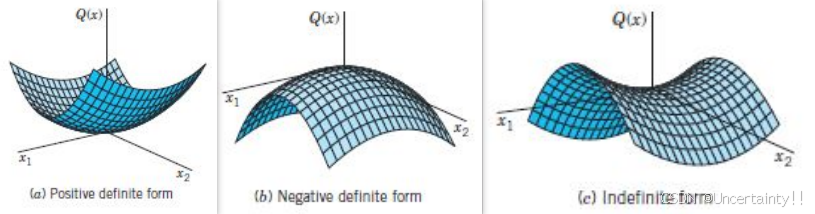
在优化问题中,判断 Hessian 矩阵的正定性和半正定性可以帮助确认我们是否找到了局部极小值。梯度下降算法可以通过 Hessian 矩阵的信息来调整步长或方向,使得算法更有效地避开鞍点,并且更快地收敛到最小值。

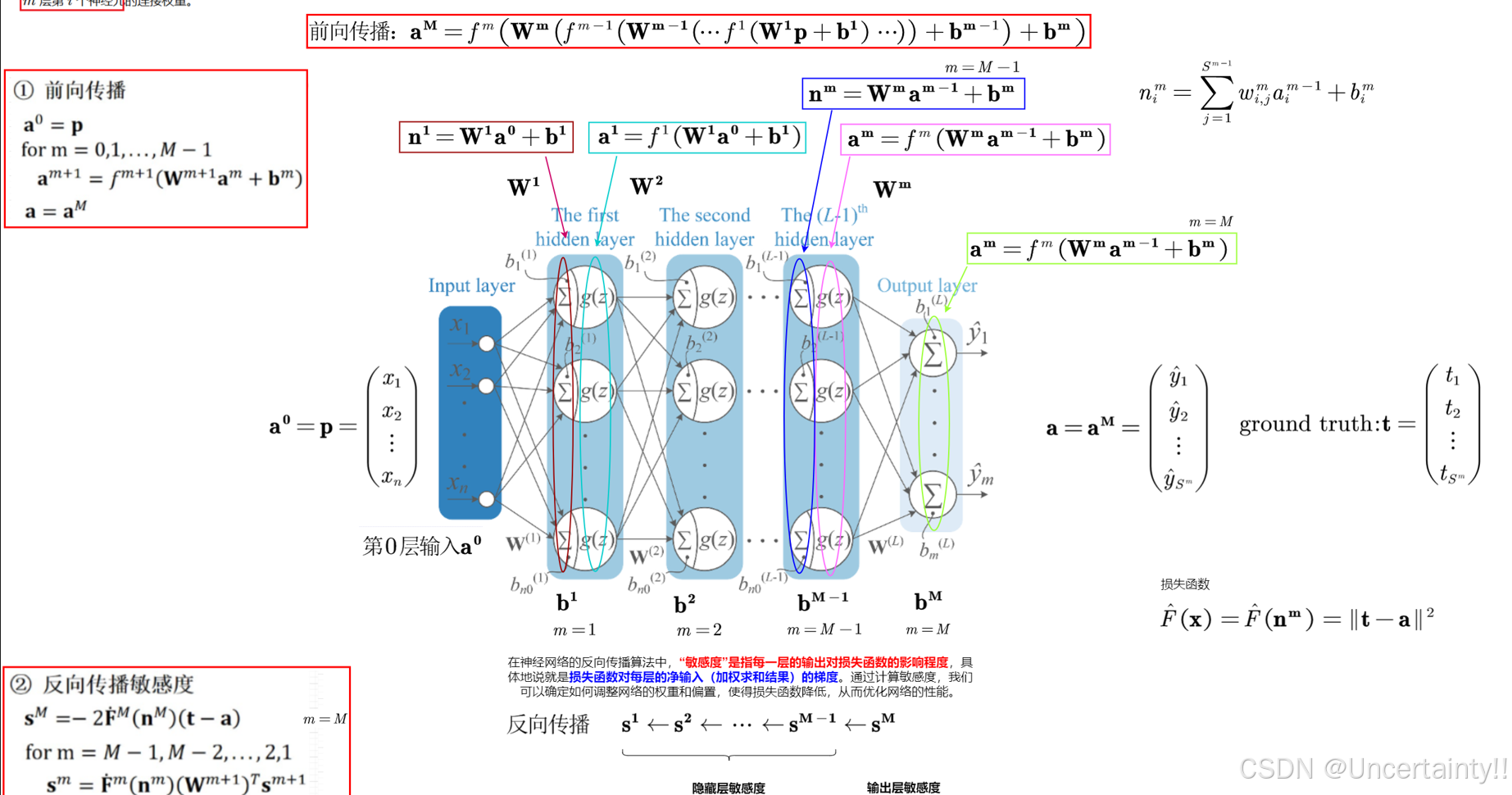
3.4 借助链式求导进行反向传播

3.4.1 前向传播


3.4.2 链式求导
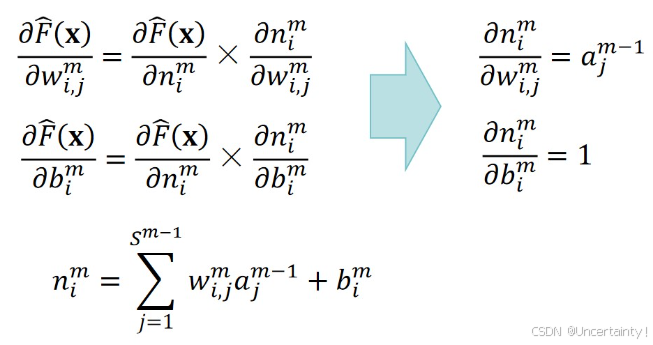



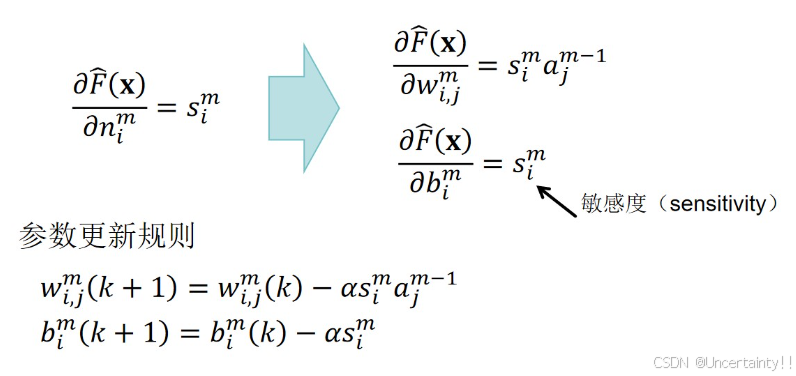

3.4.3 反向传播

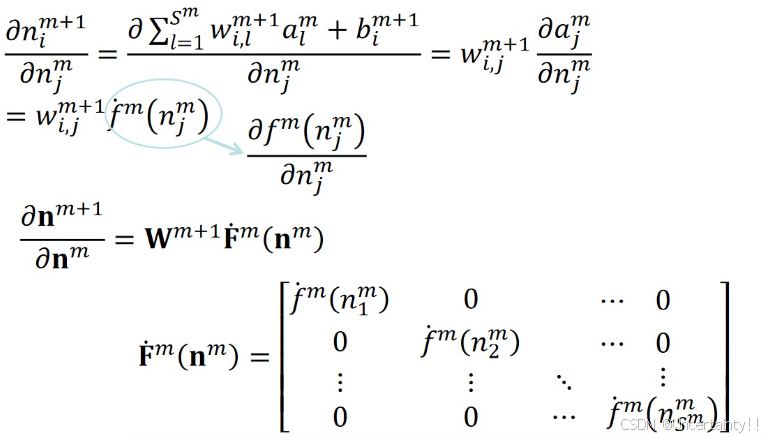
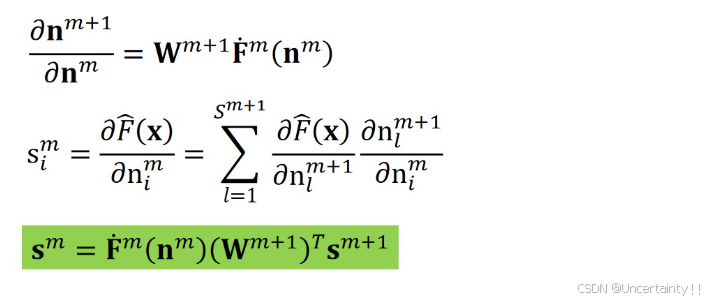
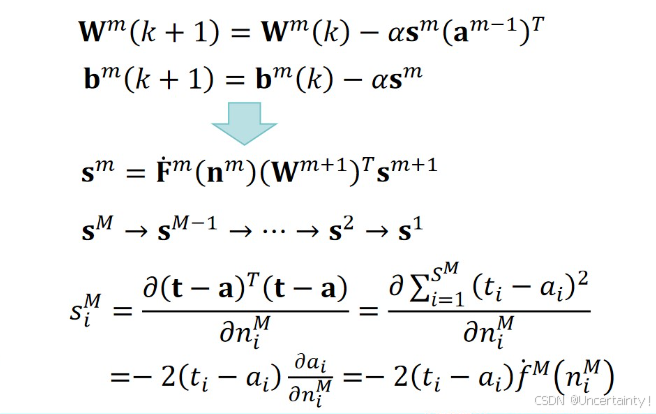
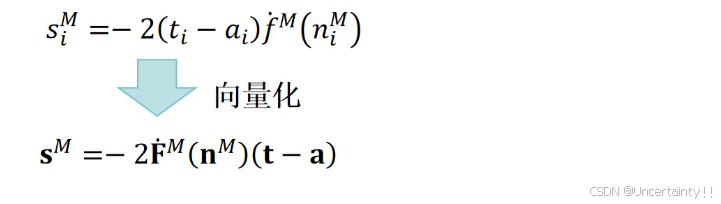
3.4.4 参数更新
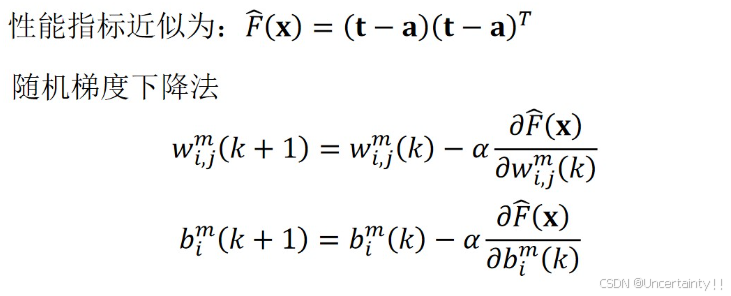

3.4.5 完整推导过程




4.实践:简单神经网络拟合函数
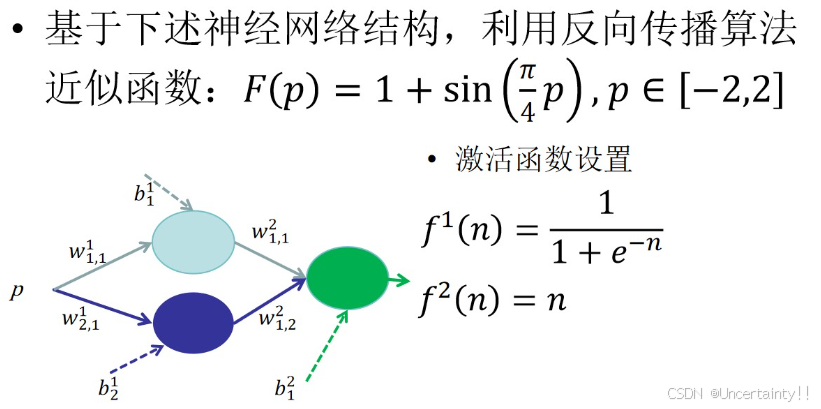
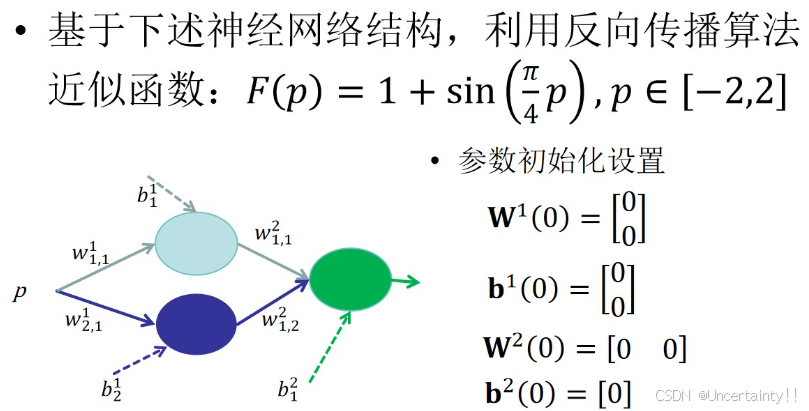
import numpy as np
import matplotlib.pyplot as plt
# 目标函数
def target_function(p):
return 1 + np.sin((np.pi / 4) * p)
# 激活函数及其导数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
# 定义神经网络
class SimpleNN:
def __init__(self, learning_rate=0.01):
# 初始化网络参数(权重和偏置),取随机小值
self.learning_rate = learning_rate
self.weights_input_hidden = np.random.randn(1, 2) # 输入到隐藏层的权重
self.bias_hidden = np.random.randn(2) # 隐藏层偏置
self.weights_hidden_output = np.random.randn(2, 1) # 隐藏层到输出层的权重
self.bias_output = np.random.randn(1) # 输出层偏置
self.loss_history = [] # 用于存储损失值
def forward(self, p):
# 前向传播
self.input = p.reshape(-1, 1) # 将输入转换为列向量
self.hidden_input = np.dot(self.input.T, self.weights_input_hidden) + self.bias_hidden # 隐藏层输入
self.hidden_output = sigmoid(self.hidden_input) # 隐藏层输出
self.final_input = np.dot(self.hidden_output, self.weights_hidden_output) + self.bias_output # 输出层输入
self.final_output = self.final_input # 输出层(线性激活)
return self.final_output
def backward(self, p, target):
# 计算损失的梯度(反向传播)
output_error = self.final_output - target # 输出层误差
d_output = output_error # 输出层激活函数为线性,所以导数为1
hidden_error = d_output * self.weights_hidden_output.T # 传播到隐藏层的误差
d_hidden = hidden_error * sigmoid_derivative(self.hidden_input) # 隐藏层激活函数为 sigmoid
# 更新权重和偏置
self.weights_hidden_output -= self.learning_rate * np.dot(self.hidden_output.T, d_output)
self.bias_output -= self.learning_rate * d_output.sum(axis=0)
self.weights_input_hidden -= self.learning_rate * np.dot(self.input, d_hidden)
self.bias_hidden -= self.learning_rate * d_hidden.flatten()
def train(self, p_data, target_data, epochs=1000):
for epoch in range(epochs):
total_loss = 0 # 记录当前epoch的总损失
for p, target in zip(p_data, target_data):
self.forward(p) # 前向传播
total_loss += np.square(self.final_output - target).item() # 计算当前样本的损失,并转为标量
self.backward(p, target) # 反向传播
avg_loss = total_loss / len(p_data) # 计算当前epoch的平均损失
self.loss_history.append(avg_loss) # 保存损失值(已转化为标量)
# 训练模型
# 生成训练数据
p_data = np.linspace(-2, 2, 100)
target_data = target_function(p_data)
# 初始化网络
nn = SimpleNN(learning_rate=0.01)
# 训练神经网络
nn.train(p_data, target_data, epochs=5000)
# 测试网络
predicted = np.array([nn.forward(p)[0][0] for p in p_data])
# 可视化结果
plt.figure(figsize=(10, 5))
# 绘制目标函数和网络预测结果
plt.subplot(1, 2, 1)
plt.plot(p_data, target_data, label='Target Function')
plt.plot(p_data, predicted, label='Neural Network Approximation')
plt.legend()
plt.xlabel("p")
plt.ylabel("F(p)")
plt.title("Function Approximation using Neural Network")
# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(np.array(nn.loss_history).flatten(), label='Loss')
plt.xlabel("Epoch")
plt.ylabel("Mean Squared Error")
plt.title("Loss Curve during Training")
plt.legend()
plt.tight_layout()
plt.show()
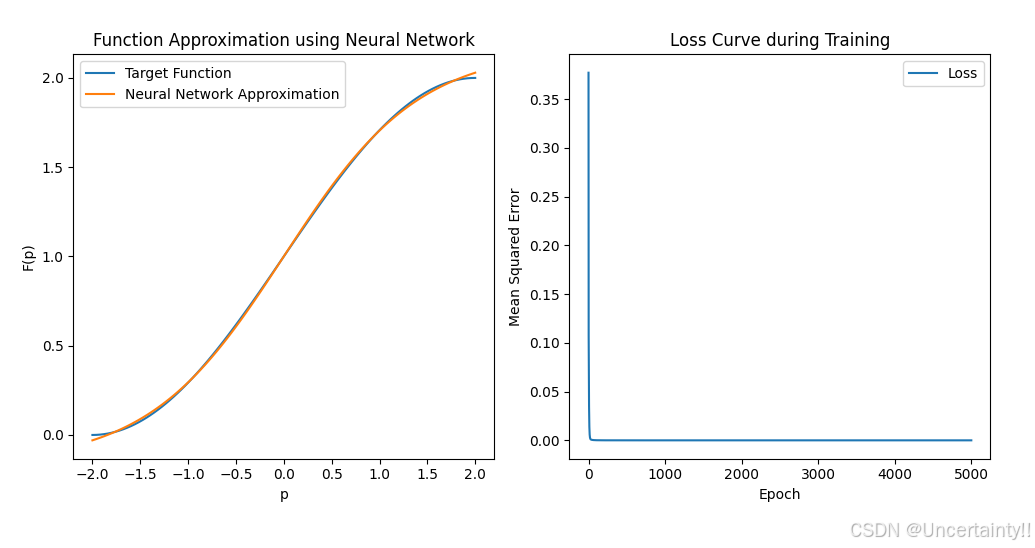
5.个人感悟
个人感悟:神经网络本质上就是一个函数,即将一个输入映射到一个输出上,通过不同权重和偏置的组合来模拟这种映射,如果这种组合恰到好处(参数最优)那么就能很好的模拟某个函数。输入输出可以是文字、图片、脑电信号等等任何你想要产生映射的两种东西,实现不同的映射就需要不同的神经网络
6.附录
6.1 L1和L2正则化项
L1 和 L2 正则化通过对模型的权重参数添加惩罚项来抑制过拟合。过拟合是指模型在训练数据上表现良好,但在新数据(测试数据)上表现不佳。通常是因为模型的参数在训练过程中过度拟合了训练数据中的噪声或偶然模式。L1 和 L2 正则化通过控制权重的大小和稀疏性,减小模型的复杂度,从而提升泛化能力。以下是详细原因:



6.2 梯度和方向导数
知识铺垫:
梯度(沿坐标轴方向的导数)
笔者之前在学习高等数学时也写过相关笔记–方向导数和梯度向量
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。–摘自:梯度
类比现实中的例子,高山流水,水所流的方向就是梯度方向,在梯度方向上能够最快速度到达山底(最优解的地方)
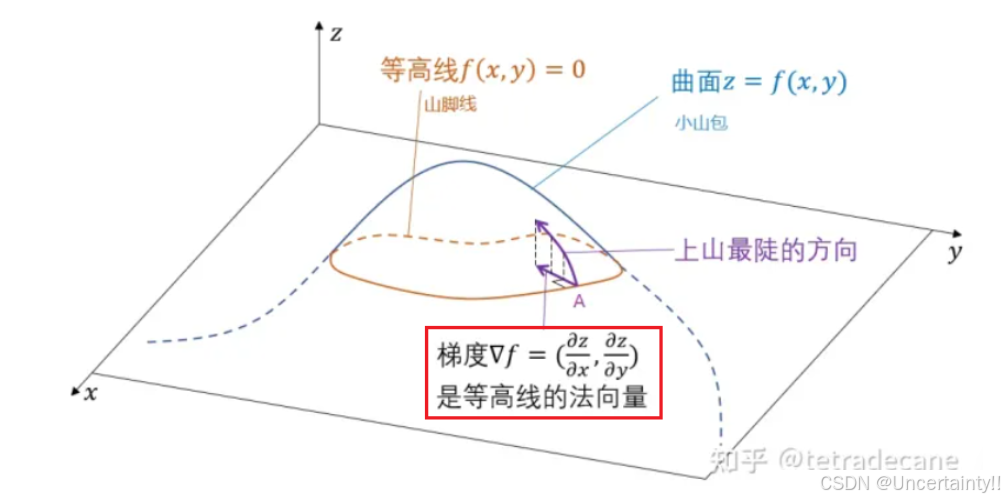
下图来自:直观上理解“梯度”与“法向量”的关系
二元函数的梯度是二维等高线的法向量
三元函数的梯度是三维等值面的法向量
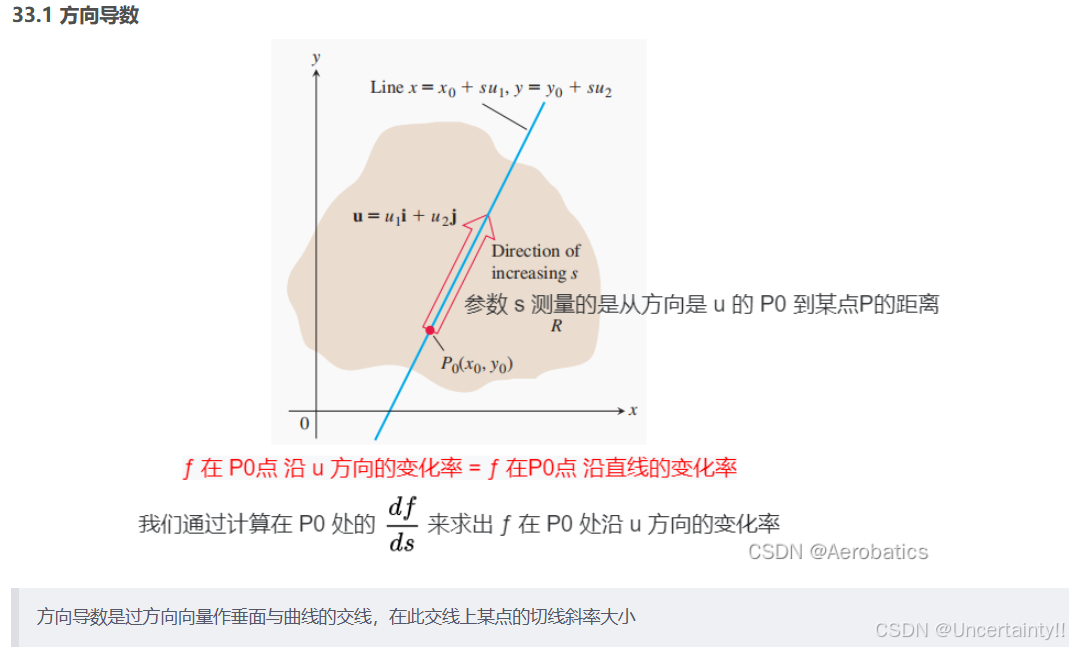
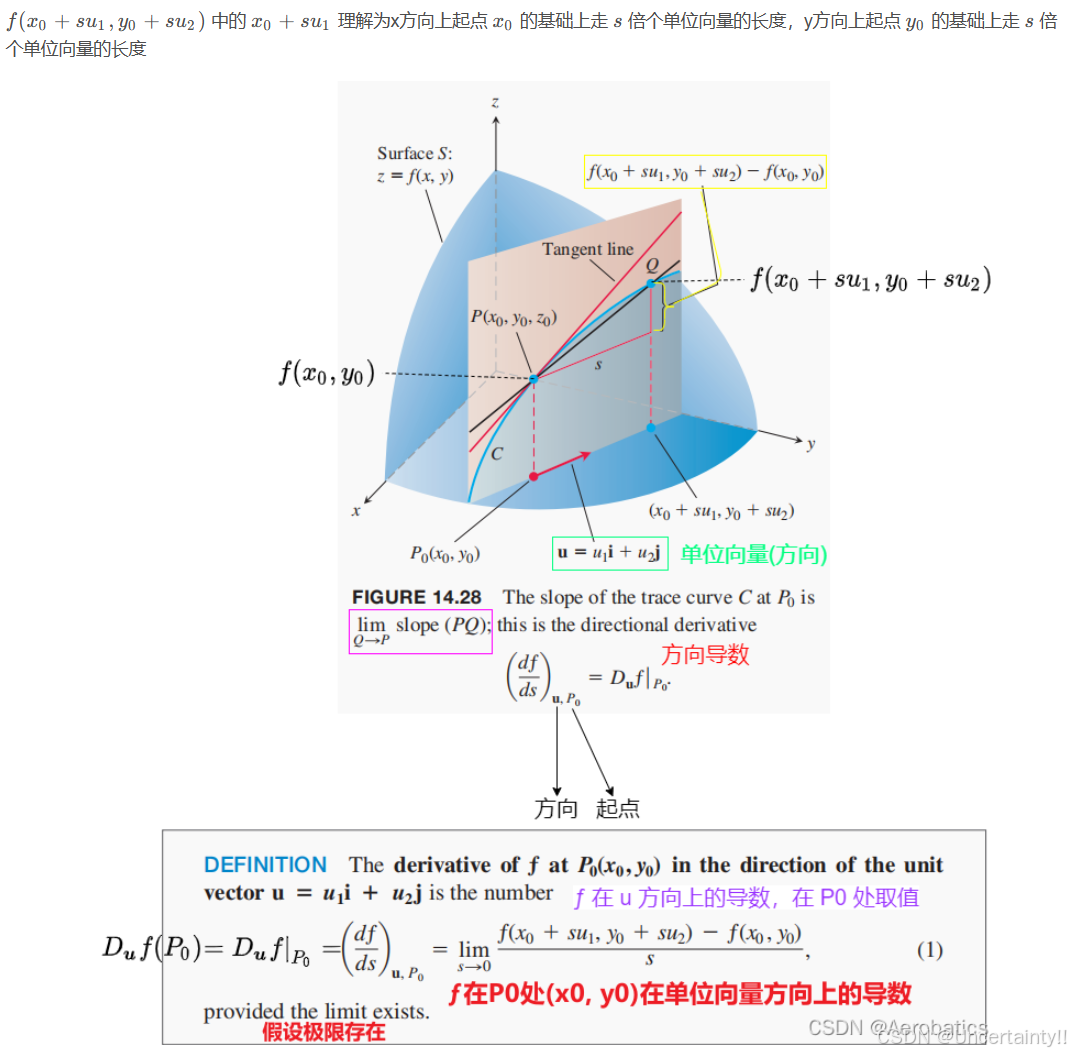
方向导数(沿指定方向的导数)

6.3 学习率
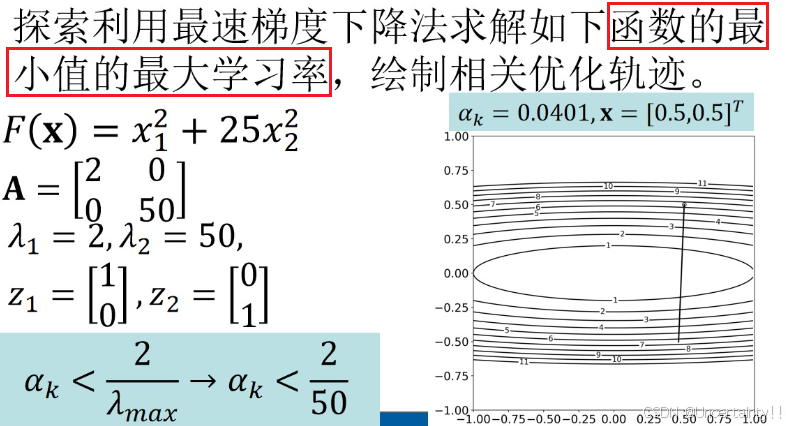
(1)最大常数学习率
如何求解损失函数的最大常数学习率?
例子:



补充:矩阵的谱半径(最大特征值
λ
max
\lambda_{\text{max}}
λmax的绝对值)





(2)动态学习率
学习率衰减(适合在模型逐渐接近最优解时提高收敛精度;)
衰减方法:指数衰减、分段衰减、根据验证机误差调整

自适应学习率(适合复杂的损失面和非平稳目标,通过动态调整每个参数的学习率,能够更快且稳定地收敛。)
AdaGrad

RMSprop

Adam

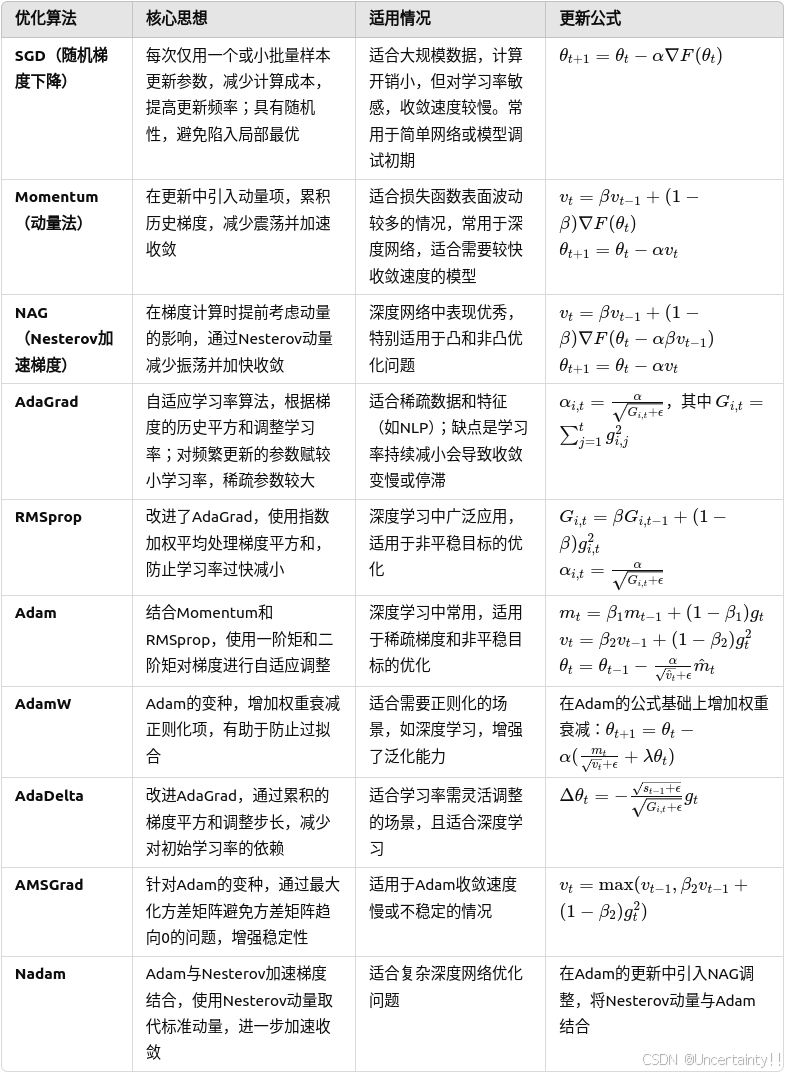
6.4 常见的神经网络优化算法
SGD、Momentum、NAG、AdaGrad、RMSprop、Adam、AdamW、AdaDelta、AMSGrad、Nadam
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 一文窥见神经网络

发表评论 取消回复