本文针对前面的讲解做一次总结
1.Redis基本特性
1.非关系型的键值对数据库,可以根据键以O(1)的时间复杂度取出或插入关联值
2.Redis的数据是存在内存中的
3.键值对中键的类型可以是字符串,整型,浮点型等,且键是唯一的
4.键值对中的值类型可以是字符串,哈希,列表,集合,排序集合等
5.Redis内置了复制,磁盘持久化,LUA脚本,事务,SSL,ACL,客户端缓存,客户端代理等功能
6.通过Redis哨兵和Redis集群模式提供高可用性
2.Redis应用场景
2.1 缓存
可以作为缓存使用,数据存在内存中,数据存取效率非常高
2.2 计数器
实现计数器功能。Redis 这种内存型数据库的读写性能非常高可以对 String 进行自增自减运算,很适合存储频繁读写的计数量。
2.3 分布式ID生成
利用自增特性一次请求一个大一点的步长如 incr 2000,缓存在本地使用,用完再请求。
2.4 海量数据统计
位图_(bitmap):存储是否参过某次活动,是否已读谋篇文章,用户是否为会员,日活统计
2.5 会话缓存
可以使用 Redis 来统一存储多台应用服务器的会话信息。当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
2.6 分布式队列/阻塞队列
List 是一个双向链表,可以通过 lpush/rpush 和 rpop/lpop 写入和读取消息。可以通过使用brpop/blpop 来实现阻塞队列。
2.7 分布式锁实现
在分布式场景下,无法使用基于进程的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的SETNX 命令实现分布式锁。
2.8 热点数据存储
最新评论,最新文章列表,使用list 存储,ltrim取出热点数据,删除老数据。
2.9 社交类需求
Set 可以实现交集,从而实现共同好友等功能,Set通过求差集,可以进行好友推荐,文章推荐。
2.10 排行榜
sorted set可以实现有序性操作,从而实现排行榜等功能。
2.11 延迟队列
使用sorted set(zset),使用 【当前时间戳 +需要延迟的时长】做score,消息内容作为元素,调用zadd来生产消息,消费者使用zrangbyscore获取当前时间之前的数据做轮询处理。消费完再删除任务 rem keymember
3.Redis键(Key)存储
所有的键都是String类型,都存储在buf里面,参考下面DB存储结构
4.Redis(Value)DB存储
redis的数据结构更偏向于map,在redis更具象化叫做dict,通过key找到value,存储海量数据;存储结构包括
1.数组:O(1)
2.链表: O(N)
4.1 String
Redis 3.2以前
C语言中使用字符串数组存储 char buf[] = "xiehao\0";但是C语言有个问题,在read键时,可能会漏读String键的长度,所以redis重新定义了一个SDS存储方式:
如下以键“xiehao”的键的存储位案例分析;
在 C语言中存储 C:char data[] = "xiehao\0",默认结尾会带一个“\0”;
SDS:
free:0
len:6
char buf [] = "xiehao"
当扩容free长度不够时,
将键"xiehao"变成"xiehao123",数组长度会自动计算多一些( 6+3)*2 =18
SDS:
free: 9
len :9
char buf[]="xiehao123"
当扩容free长度够用时,
如果再次扩容变成"xiehao123456",则增加了3个长度,判断free剩余长度可以容纳,则直接使用free,不需要扩容
SDS:
free: 6
len :12
char buf[]="xiehao123456"
当扩容到1024 *1024(也就是内存为1M时)则不会在继续扩容;
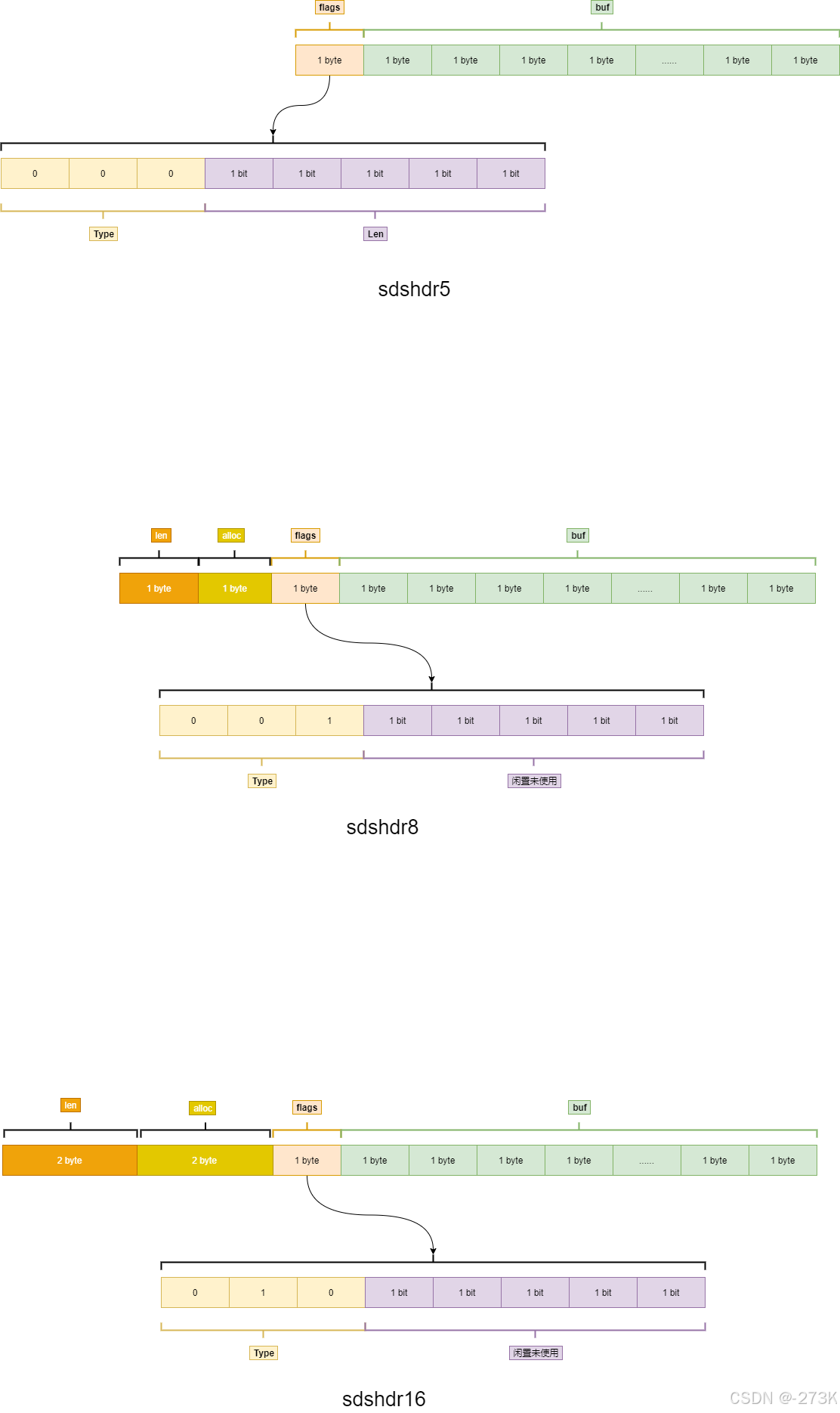
Redis 3.2后
len:长度
buf: 数据
alloc:buf分配的长度
flags:1字节 类型和业务数据长度,根据类型指向定义不同长度的内存;
类型有: sdshrd5 、 sdshrd8、 sdshrd16 、 sdshrd32 、 sdshrd64
使用SDS优点:
1.二进制安全的数据结构;
2.提供了内存预分配机制,避免了频繁的内存分配
3.兼容C语言的函数库
4.2 Hash
Hash数据结构根据Hash(key)进行随机散列,并且将hash值变成自然数,这样可以将自然数作为索引来定位数据,大大提高效率;若发生hash碰撞,则进行链表关联;
例如:
创建一个大的数组:
arr[4]
hash( key)->自然数[大]%4=「0,arr.size]
1.任意相同的输入,一定能得到相同的输出
2.不同的输入,有可能得到相同的输出
定义3个键值对 (k1,v1)(k2,v2),(k3,v3)
hash(k1)%4=0
hash(k2)%4=1
hash(k3)%4=1
arr[0]->(k1,v1,next->null)
arr[1]->(k3,v3,next ->k2 )(k2,v2,next ->null)
链表 :redis:头插入方式
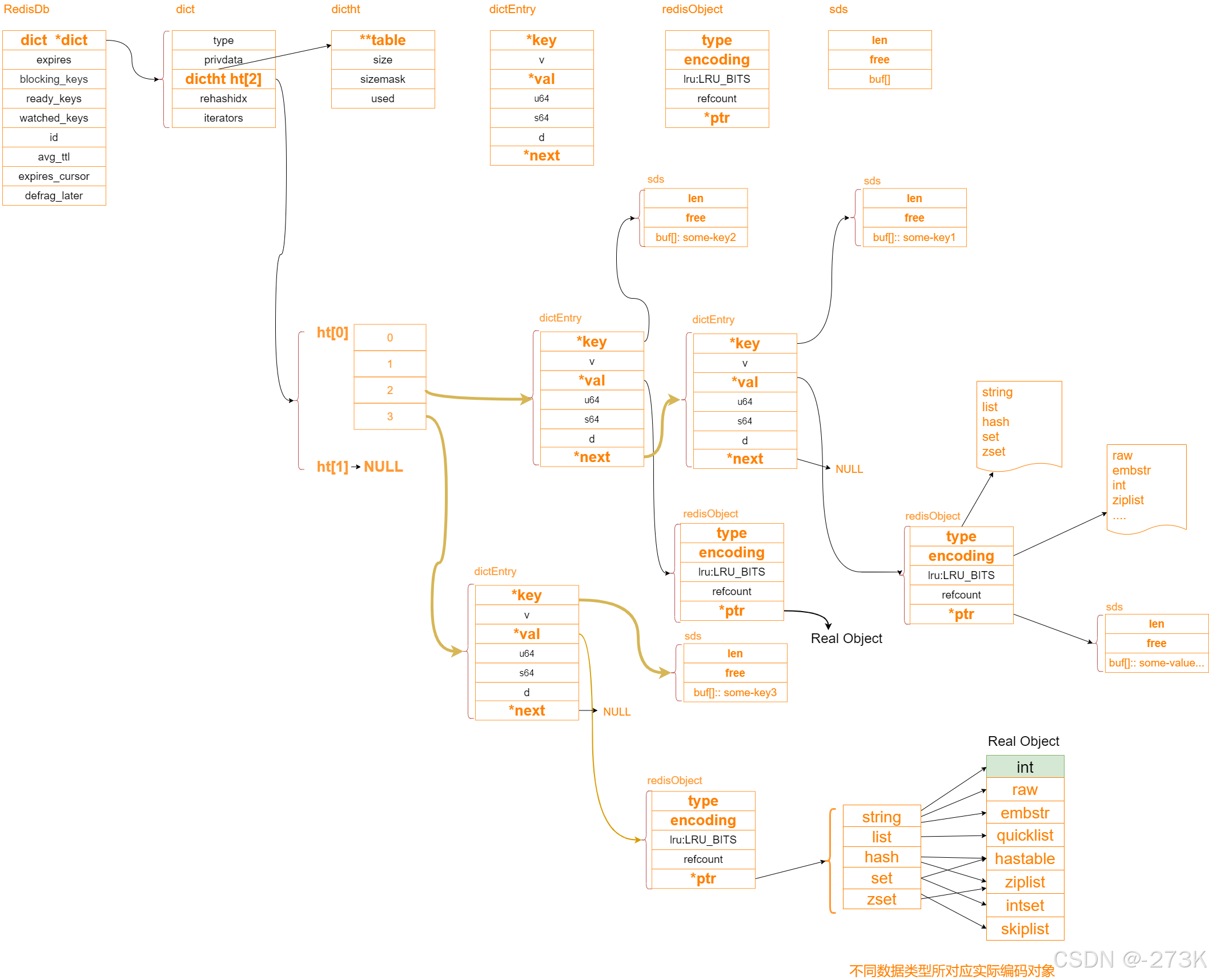
Redis 有16个DB
typedef struct redisDb{
dict *dict; (k-v)
dict *expires; (过期时间)
dict *blocking keys; (阻塞队列)
dict *ready keys; (客户端)
dict *watched_keys; (事务处理)
int id; (SELECT * 命令 - 数据库索引)
long long avg_ttl; (数据统计、遍历等)
unsigned long expires_cursor;
list *defrag _later;
}redisDb;
typedef struct dict{
dictType *type; (类型)
void *privdata;
dictht ht[2]; (扩容)
long rehashidx; (渐进式rehash)
unsigned long iterators;
}dict;
typedef struct dictht{
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}dictht;
typedef struct dictEntry{
void *key;
union{
void *val;
uint64t u64;
int64t s64;
double d;
}V;
struct dictEntry *next;
}dictEntry;
typedef struct redisObject{
unsigned type:4; (约束类型)
unsigned encoding:4; (数据类型)
unsigned Iru:LRU BITS;
int refcount;
void *ptr; (数据存储位置)
}robj;
4.3 List
List存储结构采用quickList(双端链表) 和 zipList存储;数据结构K-V(array)
zipList
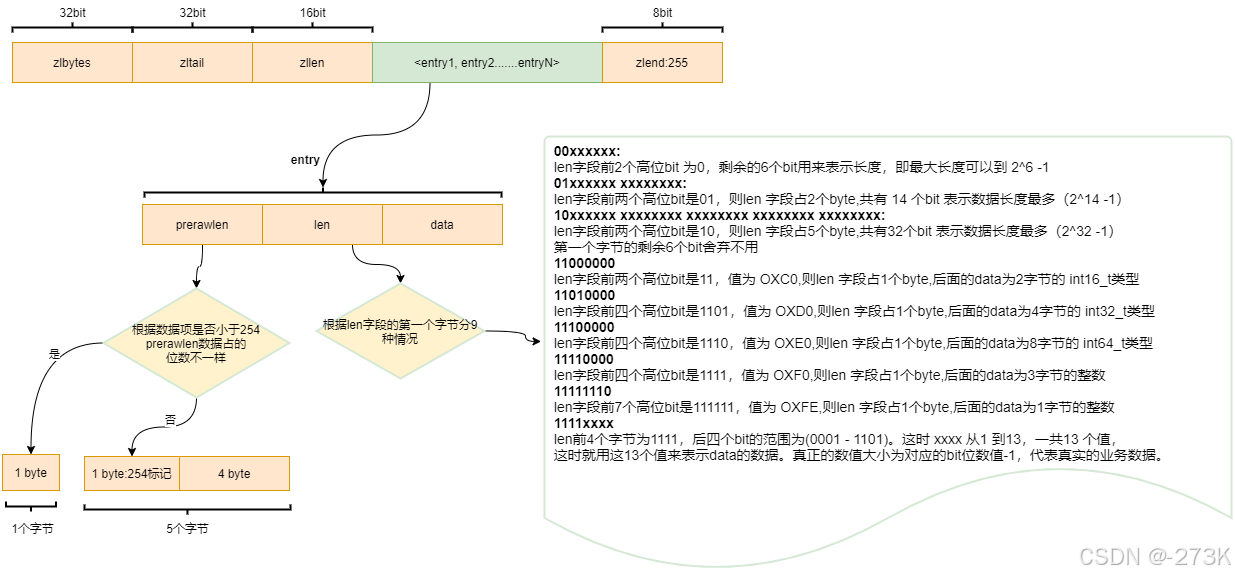
zibytes: 4字节 存多少数据
zltail:尾节点的索引
zllen:有多少元素
zlend:1字节 数据结尾标识
prerawlen: 前一个数据的信息
len: 当前数据的类型
data:当前的数据
quickList:
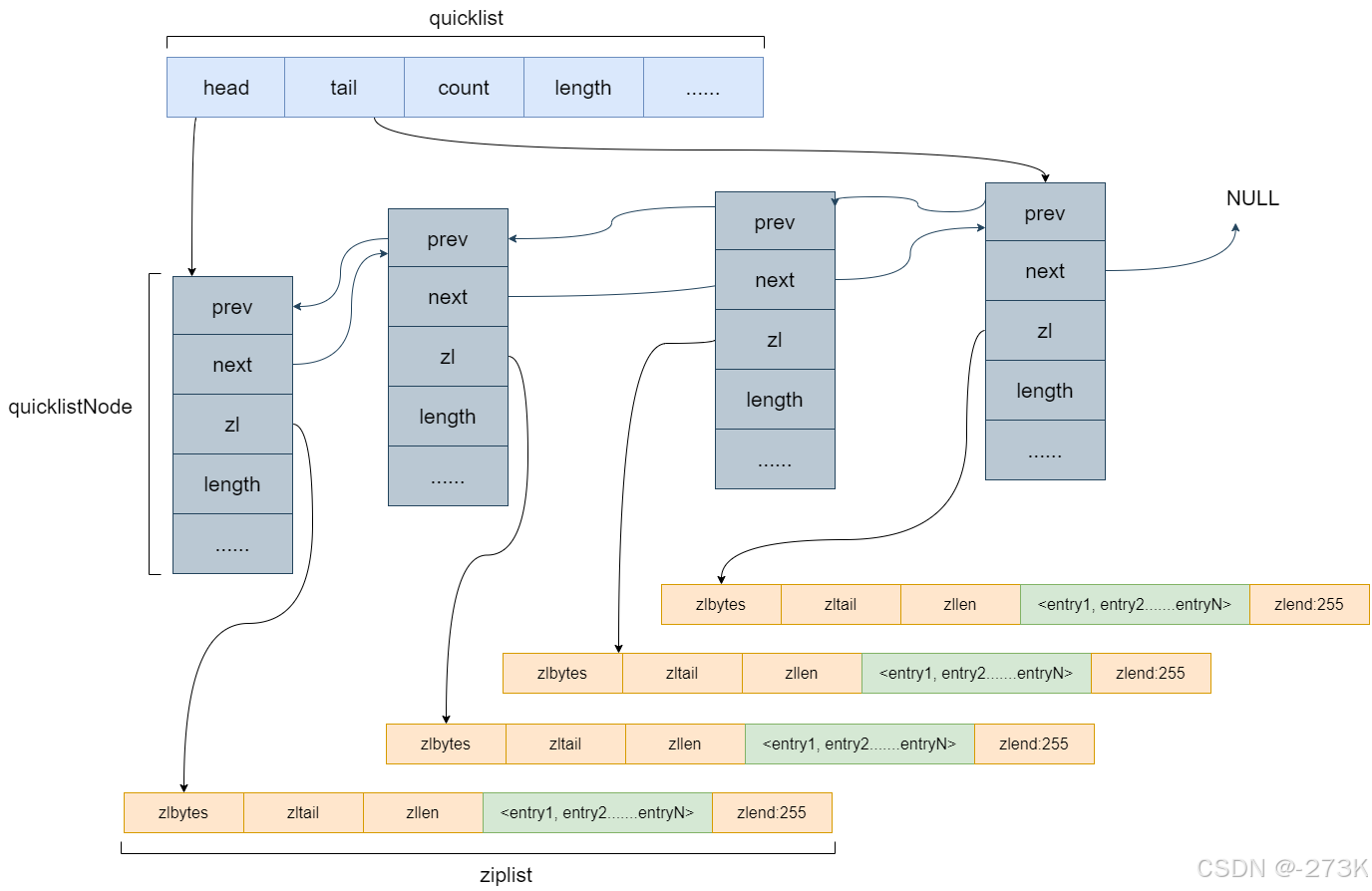
head:
tail
count:
length:
quickListNode:节点数据
zl:ziplist的数据
单个ziplist节点最大能存储 8kb ,超过则进行分裂,将数据存储在新的ziplist节点中
hash

4.4 Set
Set为无序的,自动去重的集合数据类型,Set 数据结构底层实现为一个value为x`的字典(dict),当数据可以用整形表示时,Set集合将被编码为intset数据结构。两个条件任意满足时Set将用hashtable存储数据。K - V(array)
1:元素个数大于set-max-intset-entries;
2:元素无法用整形表示;
typedef struct intset{
uint32t encoding;
uint32t length;
int8t contents[];
}intset;
encoding:编码类型
length:元素个数
contents[]:元素存储
整数集合是一个有序的,存储整型数据的结构。整型集合在Redis中可以保存int16t,int32 t,int64t类型的整型数据,并且可以保证集合中不会出现重复数据。

4.5 Zset
ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为字典(dict)+跳表(skiplist),当数据比较少时,用ziplist编码结构存储。K-V(array)
zipList

zset-max-ziplist-entries 128/元素个数超过128,将用skiplist编码
zset-max-ziplist-value64//单个元素大小超过64 byte,将用skiplist编码
skipList
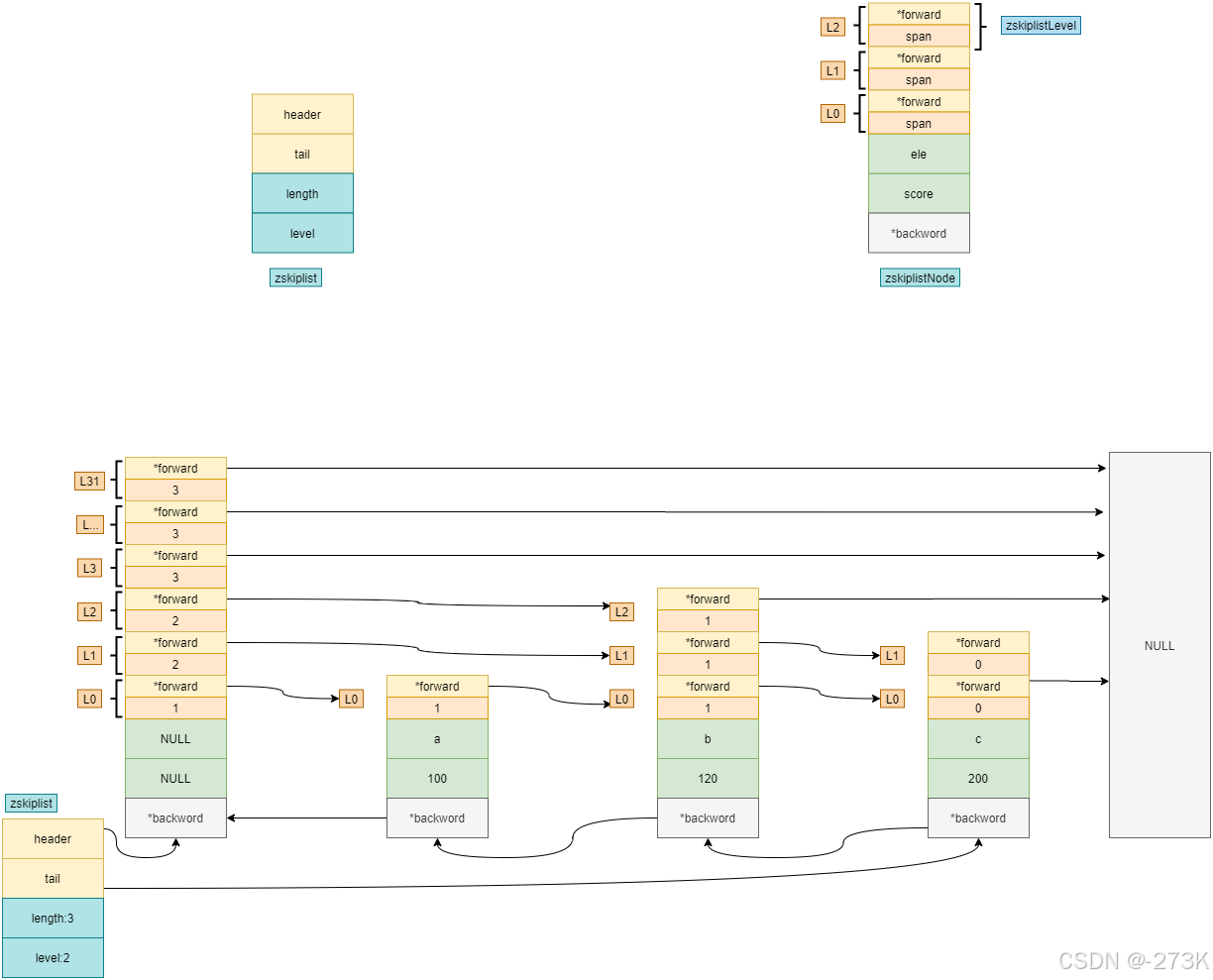
typedef struct zskiplist{
struct zskiplistNode *header,(头节点,做索引,不存数据)
*t ail; (尾节点,会
存数据)
unsigned long length;(元素个数)
int level; (层高)
}zskiplist;
跳表算法:
数据项:N
index1 : N/2
index2 : N/2^2
index3: N/2^3
indexk: N/2^k
N/2^K = 2
2^K = N/2
k = log2 N/2
k = logN
ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 字典(dict) + 跳表(skiplist) ,当数据比较少时,用ziplist编码结构存储。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 36.Redis核心设计原理

发表评论 取消回复