【项目实战】基于 LLaMAFactory 通过 LoRA 微调 Qwen2
一、项目介绍

LLaMA-Factory是一个由北京航空航天大学的郑耀威开发的开源框架,作为一个功能强大且高效的大模型微调框架,通过其用户友好的界面和丰富的功能特性,为开发者提供了极大的便利。
项目官网:https://www.llamafactory.cn/
Github:https://github.com/hiyouga/LLaMA-Factory
二、环境准备
1、环境准备
- Python 3.10.9
- NVIDIA GeForce GTX 1650
- CUDA和cuDNN
2、安装LLaMa-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
进入项目目录,安装必要的Python依赖库。可以使用以下命令:
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
#截止2024.11.16,github拉取的最新版本的requirements.txt
transformers>=4.41.2,<=4.46.1
datasets>=2.16.0,<=3.1.0
accelerate>=0.34.0,<=1.0.1
peft>=0.11.1,<=0.12.0
trl>=0.8.6,<=0.9.6
gradio>=4.0.0,<5.0.0
pandas>=2.0.0
scipy
einops
sentencepiece
tiktoken
protobuf
uvicorn
pydantic
fastapi
sse-starlette
matplotlib>=3.7.0
fire
packaging
pyyaml
numpy<2.0.0
av
3、准备模型数据集
3.1 模型准备
这里我们使用 Qwen2-0.5B 模型进行微调,首先下载模型,这里如果无法从Hugging Face上拉取的话,可以从国内模型库魔塔社区拉去,没有速度限制。
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-0.5B',cache_dir="model/Qwen")
3.2 数据集准备
LLaMA-Factory 内置了一些数据集,本次就使用内置的 identity 数据集,用于修改模型的自我意识,数据集格式:
#文件地址 LLaMA-Factory-main\data\identity.json
{
"instruction": "Who are you?",
"input": "",
"output": "I am {{name}} an AI assistant developed by {{author}}. How can I assist you today?"
},
{
"instruction": "What is your name?",
"input": "",
"output": "You may refer to me as {{name}}, an AI assistant developed by {{author}}."
},
{
"instruction": "Do you have a name?",
"input": "",
"output": "As an AI assistant developed by {{author}}, I got the name {{name}}."
},
对于这个数据集进行大量训练后,会修改模型的自我意识,比如修改前:我的名字是通义千问;修改后:我的名字是{{name}}。
三、微调
1、启动webui
启动webui:llamafactory-cli webui,出现如下提示和页面表示启动成功:
(torch3) D:\AIProject\LLaMA-Factory-main>llamafactory-cli webui
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
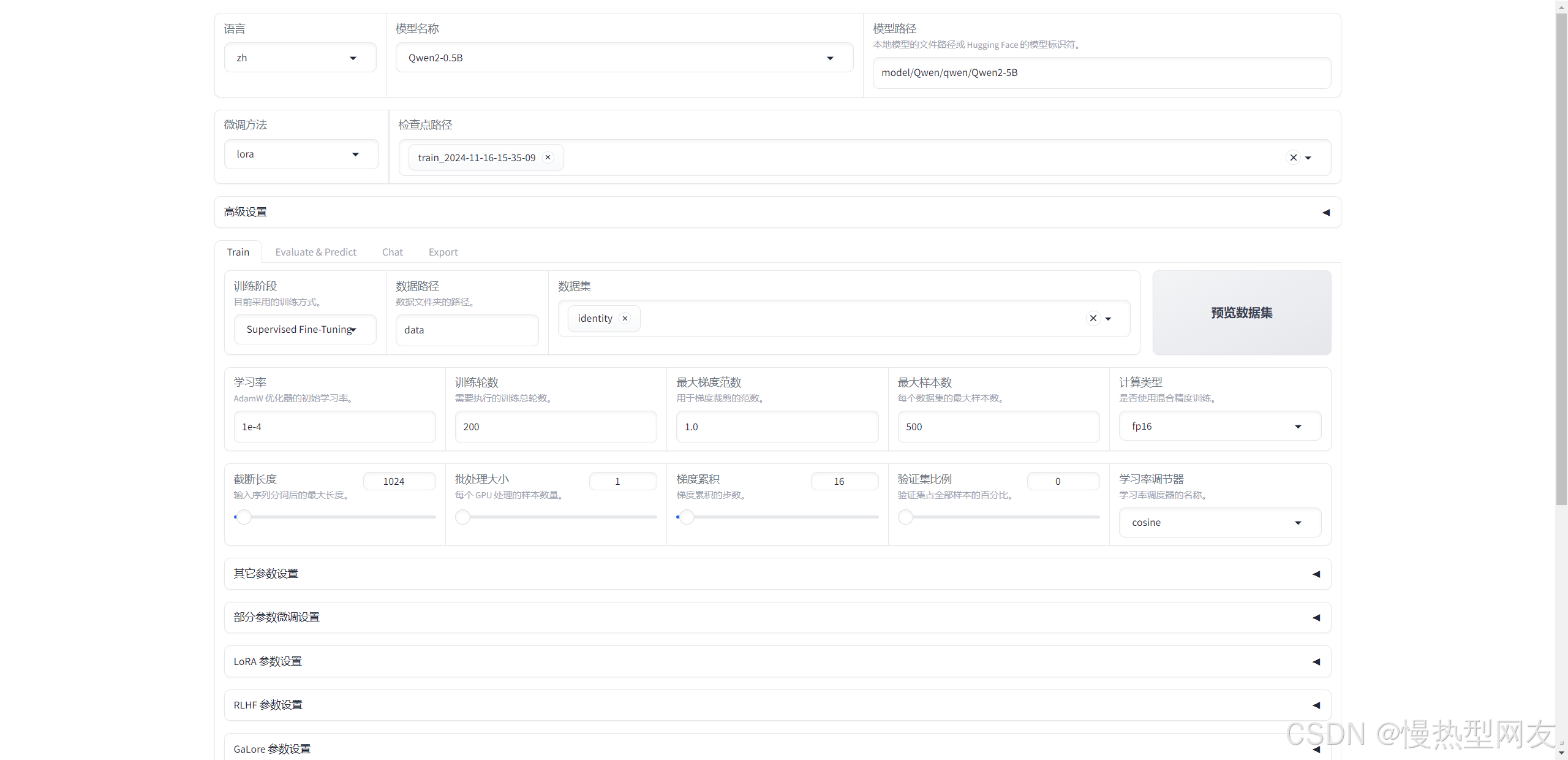
2、选择参数
主要选择:模型、训练数据集、训练参数(此处不多介绍,按照下图选择)
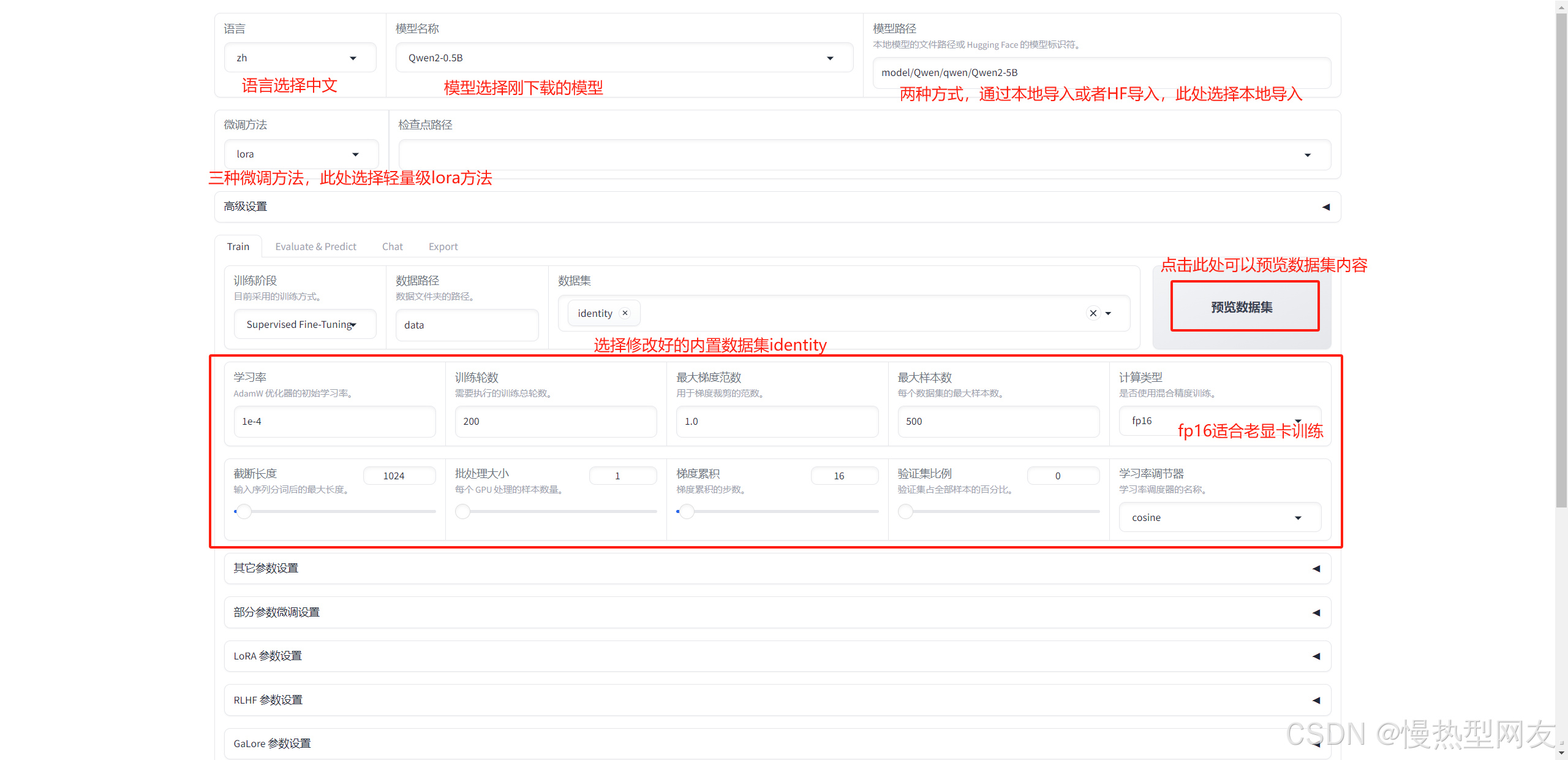
3、训练
点击训练,等待即可,训练结束后会出现训练完毕字样,并且会显示出Loss曲线。
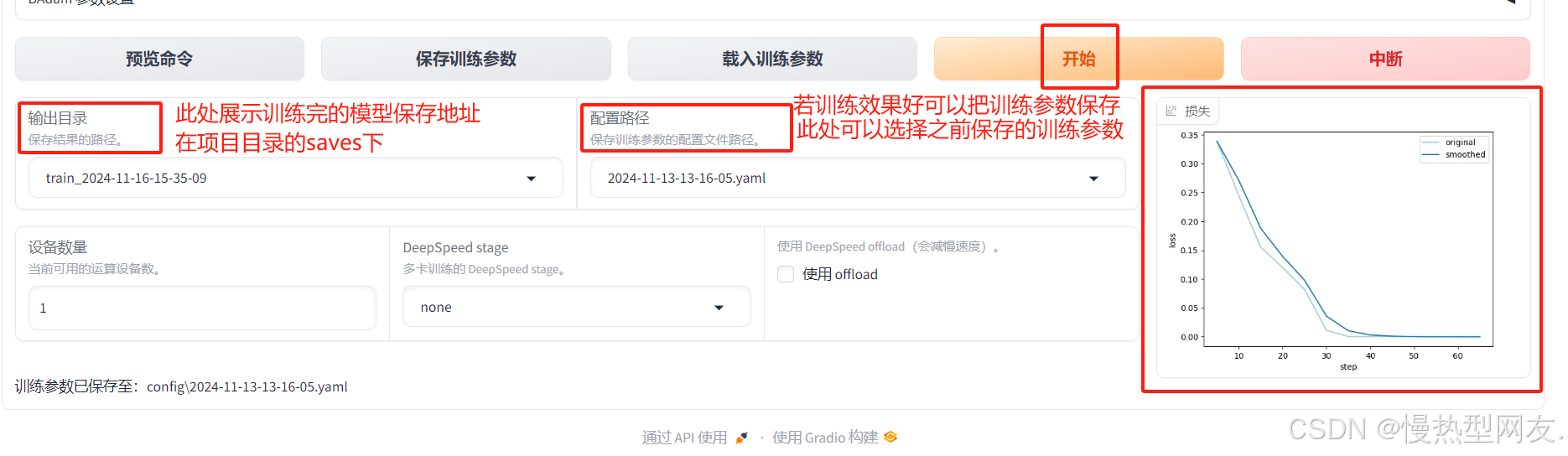
模型训练过程

四、测试
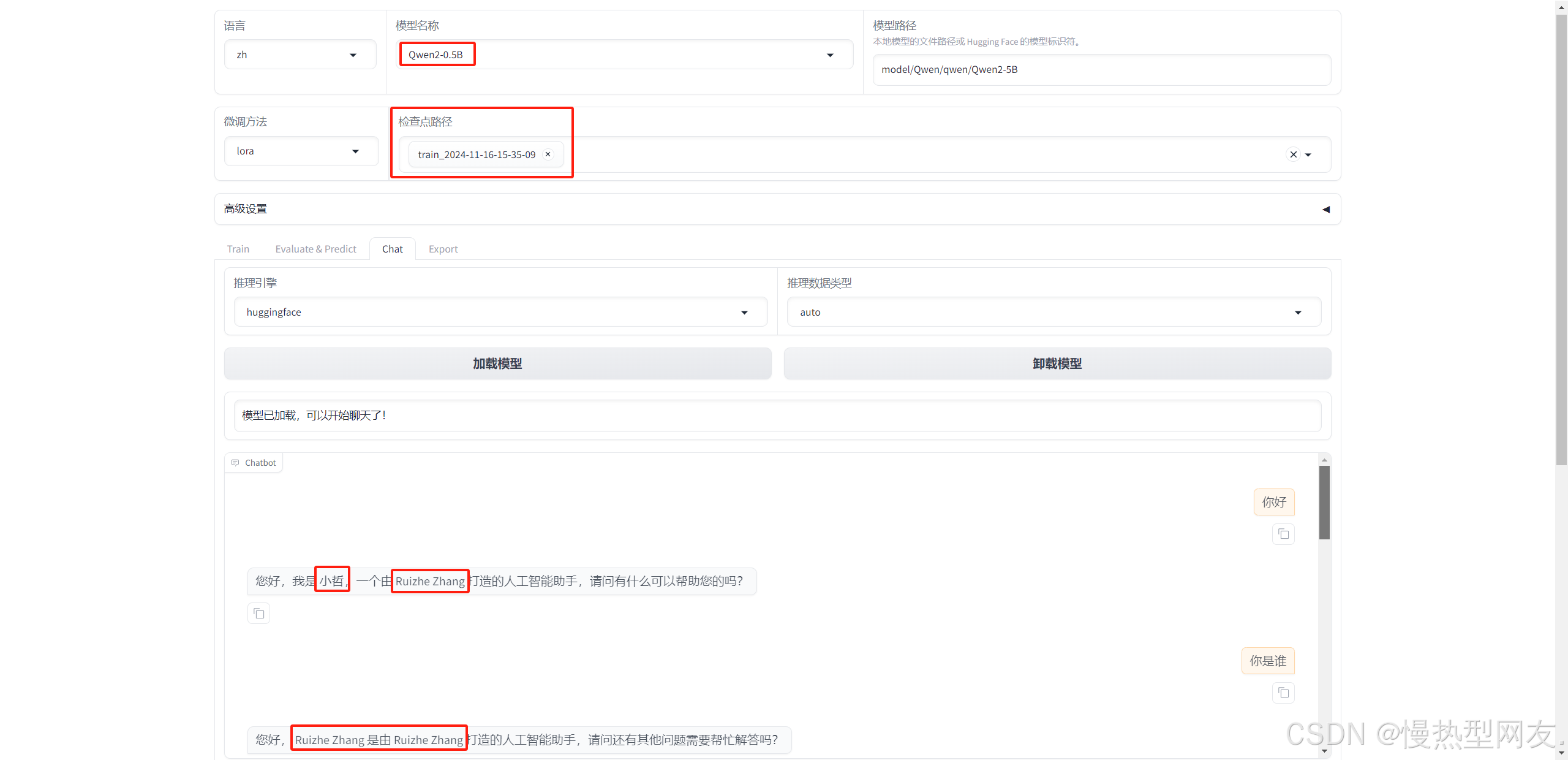
在模型训练完成后,可以通过Evaluate & Predict(通过评估数据集评估性能)、Chat(直接与模型对话)。此处选择后者,更直观的展示模型训练效果。
模型依旧选择基座模型,检查点选择训练完模型保存的地址,点击加载模型,即可开始与模型对话。
五、总结
本文章记录了LLaMA-Factory在本地的部署以及使用,从最后的测试效果发现训练的效果其实并不理想,不过初有成效,初步判断和数据集规模,训练轮数以及参数配置等有关,后期将针对这些方面进行相应的调整,争取达到目标效果。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【项目实战】基于 LLaMA-Factory 通过 LoRA 微调 Qwen2

发表评论 取消回复