一、Python模块
1、模块概念
在编程的时候,先创建一个 .py 文件,这个文件就称之为 一个模块 Module。
2、模块的使用
①使用 import 语句
# 语法格式
import A
# 若A是一个包的话,可以这样写
import A.函数名②使用 from...import...语句
# 语法格式
# 只导入一个模块的某个属性或方法
from 模块名/包名 import 属性名, 函数名小练习
假设你正在编写一个 py_a 模块,其中包含一个名为 Animal 的基类和一个名为Dog 的子类。现在你想在另一个 py_b 文件中部分导入这两个东西,并在子类中调用基类的方法。请编写一个示例代码,展示如何实现这种部分导入。
# 这是 py_a.py 模块:
class Animal(object):
def __init__(self, name):
self.name = name
def __str__(self):
return self.name
def speak(self):
print(f'{self.name}在咆哮!')
class Dog(Animal):
def __init__(self, name, age, host):
super().__init__(name)
self.age = age
self.host = host
def __str__(self):
return f'{super().__str__()},{self.age},{self.host}'# 这是 py_b.py 模块
from py_a import Dog
d = Dog("啸天犬", 3000, "二郎神")
print(d)
d.speak()
#【运行结果】:
# 啸天犬,3000,二郎神
# 啸天犬在咆哮!3、Python中的包
①什么是包?
把模块组织到一起的方法,即创建一个包。
“模块”就是 一个 .py 文件;
“包”就是一个包含 __init__.py文件的 文件夹,文件夹中可以包含子包或者模块。
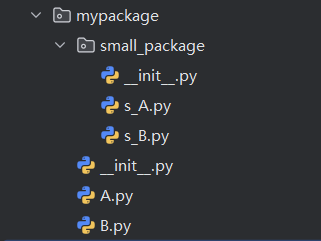
创建包的目的不是为了运行,而是为了被导入使用;
包的本质就是模块,因此可以将包当做模块来导入。
包是不能像普通模块那样被执行代码,所以包提供了一个__init__.py文件;
导入包就会执行 __init__.py 文件,这也是 __init__.py 文件存在的意义。
②包的使用
# 导入格式:
from 包名.子包名.模块名 import 模块中的函数名
from 包名.模块名 import 模块名中的函数名③导入自定义包
导入自定义的包,必须确保包在Python的搜索路径中。
Python在导入包时会查找特定的目录列表,这个列表通常包括:
- 当前脚本所在的目录。
- 环境变量 PYTHONPATH 中指定的目录。
- Python安装目录中的库目录,如 Lib/site-packages。
为了确保你的自定义包可以被导入,你需要确保它的目录在上述列表中的一个。
4、Python常用标准库
下面是一些 Python3 中常用的标准库:
| 模块名称 | 模块描述 |
| os | os 模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。 |
| sys | sys 模块提供了与 Python 解释器和系统相关的功能,例如解释器的版本和路径,以及与 stdin、stdout 和 stderr 相关的信息。 |
| time | time 模块提供了处理时间的函数,例如获取当前时间、格式化日期和时间、计时等。 |
| datetime | datetime 模块提供了更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等。 |
| math | math 模块提供了数学函数,例如三角函数、对数函数、指数函数、常数等。 |
| json | json 模块提供了 JSON 编码和解码函数,可以将 Python 对象转换为 JSON 格式,并从 JSON 格式中解析出 Python 对象。 |
| numpy | 一个用于维度数组计算的库 |
| opencv | 一个用于计算机视觉的库 |
| matplotlib | 一个用于数据可视化的库(绘图) |
| scikit-learn | 一个用于机器学习的库 |
| tensorflow | 一个用于深度学习的库 |
| threading | 一个用于设置多线程的库 |
二、迭代器 与 生成器
1、迭代器
①迭代器概念
迭代是python访问集合中元素的一种方式,迭代器是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。
迭代器只能往前,不能后退。
迭代器有两个基本的方法:iter() 和 next()。
s = "Hello!"
# iter() 方法:把序列转换成 迭代器
it = iter(s)
print(type(it))
# next() 方法:获取迭代器的下一个元素(只能往前,不能后退)
try:
while True:
print(next(it))
except StopIteration:
print("迭代已结束")
#【运行结果】:
# <class 'str_ascii_iterator'>
# H
# e
# l
# l
# o
# !
# 迭代已结束
②StopIteration说明:
StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况;
在__next__()方法中,可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
③创建一个迭代器
把一个类作为一个迭代器使用,需要在类中实现两个方法 iter() 与 next() ;
iter() 方法 返回一个特殊的迭代器对象,这个迭代器对象实现了 next() 方法并通过 StopIteration 异常标识迭代的完成。
next() 方法 返回下一个迭代器对象。
# 创建一个返回数字的迭代器,起始值为10,逐步递增10;
# 即:起始值是10,步长值为10。
class MyNum:
def __iter__(self):
self.a = 10
return self
def __next__(self):
if self.a <= 100:
x = self.a
self.a += 10
return x
else:
raise StopIteration("迭代已完成")
# 实例化对象
my_class = MyNum()
my_iter = iter(my_class)
try:
while True:
print(next(my_iter))
except Exception as e:
print(e)
#【运行结果】:
# 10
# 20
# 30
# 40
# 50
# 60
# 70
# 80
# 90
# 100
# 迭代已完成2、生成器
在python中,使用了 yield 函数就被称为 生成器。
yield 是一个关键字,用于定义生成器函数,生成器函数是一种特殊的函数,可以在迭代过程中逐步产生值,而不是一次性返回所有结果。
与普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单的理解“生成器就是一个迭代器”。
每次使用 yield 语句生产一个值之后,函数都将暂停执行,内存释放出来,等待再次唤醒。
【yield 语句和 return 语句的差别】:
yield语句返回的是可迭代对象,而return返回的是不可迭代对象。
每次调用生成器的 next() 方法或者使用 for 或 while 循环进行迭代时,函数会从上次暂停的地方继续执行,直到再次遇见 yield 语句。
def create_fun(n):
while n>0:
yield n
n -= 1
create_iter = create_fun(5)
print(next(create_iter))
for i in create_iter:
print(i)
#【运行结果】:
# 5
# 4
# 3
# 2
# 1总结:
生成器的优势是它们是按需生成值,避免一次性生成大量数据并占用大量内存。
此外,生成器还可以与其他迭代工具(如:for循环)无缝衔接配合使用,提供了更加简洁和高效的迭代方式。
3、练习
练习1:
实现一个自定义迭代器类 MyRange ,其功能类似于内置的 range() 函数。要求:支持步长参数,并且只能从0开始迭代。
class MyRange:
def __init__(self, stop, step):
self.start = 0
self.stop = stop
self.step = step
def __iter__(self):
return self
def __next__(self):
if self.start < self.stop:
x = self.start
self.start += self.step
return x
else:
raise StopIteration('迭代已完成')
my_range = MyRange(8, 2)
for num in my_range:
print(num)
#【运行结果】:
# 0
# 2
# 4
# 6练习2:
使用生成器实现一个函数fibonacci(n),该函数返回一个生成斐波那契数列的生成器。其中 n 表示生成斐波那契数列的元素个数。
def fibonacci(n):
a, b = 1, 1
while n:
yield a
a, b = b, a+b
n -= 1
fib_iter = fibonacci(8)
for i in fib_iter:
print(i)
#【运行结果】:
# 1
# 1
# 2
# 3
# 5
# 8
# 13
# 21三、正则表达式
①什么是正则表达式?
正则表达式是一个特殊的字符序列,它能方便的检查一个字符串是否与某种模式匹配。
re 模块使Python语言拥有全部的正则表达式功能。
②注意事项
正则表达式中遇见 \ 为转义字符,自动转义。
若在前面加 r ,说明是原生字符串,不转义。
1、re.match函数
re.match() 是从字符串的起始位置匹配一个模式,匹配不成功就返回 None;
若匹配到了数据,则使用 group(num) 或 groups() 来提取数据。
语法格式:
re.match(pattern, string, flags=0)
参数说明:
pattern 需要匹配的正则表达式;
string 匹配的字符串;
flags 标志位,用于控制正则表达式的匹配方式;,
如:是否区分大小写,多行匹配等
group(num=0) 匹配整个字符串,可以设置参数;
groups() 返回一个元组,包含所有小组字符串的元组;import re
s = "Hello world, hello Python!"
# match 从开始位置匹配
result = re.match('Hello', s)
print(result.group())
#【运行结果】:
# Hello2、re.search函数
re.search() 扫描整个字符串并返回第一个成功匹配的字符串。
import re
s1 = 'Hello world, Hello Python!'
s2 = 'Python hello, world hello!'
# search 扫描整个字符串,返回第一个匹配的结果
sch_1 = re.search('Hello', s1)
print(sch_1, sch_1.group())
sch_2 = re.search('hello', s2)
print(sch_2, sch_2.group())
#【运行结果】:
# <re.Match object; span=(0, 5), match='Hello'> Hello
# <re.Match object; span=(7, 12), match='hello'> hello3、re.findall函数
re.findall() 匹配整个字符串,返回string中所有与pattern相匹配的全部子串;
返回形式为数组。
import re
s1 = 'Python hello, World hello!'
s2 = 'Hello world, hello python!'
# findall 扫描整个字符串,返回所有匹配的结果
fet_1 = re.findall('hello', s1)
print(fet_1)
fet_2 = re.findall('world', s2)
print(fet_2)
#【运行结果】:
# ['hello', 'hello']
# ['world']4、matchr,search,findall区别
①re.match()
从首字母匹配,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None;
②re.search()
匹配整个字符串,直到找到一个对应匹配(若有多个,也只返回第一个);
③re.findall()
返回匹配到的所有子串。
5、正则表达式修饰符-可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。
修饰符被指定为一个可选的标志。如 re.I | re.M 被设置成 I 和 M 标志。
| 修饰符 | 描述 |
| re.I | 使匹配对大小写不敏感。 |
| re.L | 做本地化识别(locale-aware)匹配。 |
| re.M | 多行匹配,影响 ^ 和 $。 |
| re.S | 使 . 匹配包括换行在内的所有字符。 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B。 |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
import re
s = 'Good good study, Day day up'
ret = re.findall('good', s, re.I)
print(ret)
#【运行结果】:
# ['Good', 'good']6、正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式。
①字母和数字表示他们自身。
②一个正则表达式模式中的字母和数字匹配同样的字符串。
③多数字母和数字前加一个反斜杠时会拥有不同的含义。
④标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
⑤反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以最好使用原始字符串来表示它们。
| 匹配单个字符 | 说明 |
| . | 匹配任意1个字符,除了\n |
| [] | 匹配[]列举的字符 |
| \d | 匹配数字,相当于[0-9] |
| \D | 匹配非数字,相当于[^0-9] |
| \s | 匹配空白,即空白,tab键,相当于[\t\n\r\f\v] |
| \S | 匹配非空白,相当于[^\t\n\r\f\v] |
| \w | 匹配非特殊字符,即a-z A-Z 0-9 _ 汉字 数字等,相当于[a-zA-Z0-9] |
| \W | 匹配特殊字符,即非汉字 非数字 非字母等,相当于[^a-zA-Z0-9] |
import re
s = '__ 88 hello 66 &world&&'
ret1 = re.findall('.', s)
print(ret1)
# ['_', '_', ' ', '8', '8', ' ', 'h', 'e', 'l', 'l', 'o', ' ', '6', '6', ' ', '&', 'w', 'o', 'r', 'l', 'd', '&', '&']
ret2 = re.findall('[h6]', s)
print(ret2)
# ['h', '6', '6']
ret3 = re.findall(r'\d', s)
print(ret3)
# ['8', '8', '6', '6']
ret4 = re.findall(r'\D', s)
print(ret4)
# ['_', '_', ' ', ' ', 'h', 'e', 'l', 'l', 'o', ' ', ' ', '&', 'w', 'o', 'r', 'l', 'd', '&', '&']
ret5 = re.findall(r'\w', s)
print(ret5)
# ['_', '_', '8', '8', 'h', 'e', 'l', 'l', 'o', '6', '6', 'w', 'o', 'r', 'l', 'd']
ret6 = re.findall(r'\W', s)
print(ret6)
# [' ', ' ', ' ', ' ', '&', '&', '&']| 匹配多个字符 | 说明 |
| * | 匹配前一个字符出现0次或多次 |
| + | 匹配前一个字符出现1次或多次 |
| ? | 匹配前一个字符出现1次或0次 |
| {m} | 匹配前一个字符出现m次 |
| {m,n} | 匹配前一个字符出现m到n次:{0, },{1, },{0,1} |
import re
# 匹配出一个字符串第一个字母为大写字符,后面都是小写字母并且这些小写字母可有可无
def fun1(s:str):
ret = re.match(r'[A-Z][a-z]*', s)
if ret:
print(ret.group())
else:
print("匹配不成功")
s = 'Abcd777'
fun1(s)
#【运行结果】:
# Abcdimport re
# 匹配变量名是否有效
def fun2(name:str):
ret = re.match(r'[A-Za-z_]+[\w]*', name)
if ret:
print(ret.group())
else:
print("变量命名不合法")
name = '_a '
fun2(name)
#【运行结果】:
# _aimport re
# 匹配出8到20位的密码,可以是大小写英文字母、数字、下划线
def fun3(pwd:str):
ret = re.match(r'\w{8,20}', pwd)
if ret:
print(ret.group())
else:
print("密码不正确")
fun3('12345678')
#【运行结果】:
# 12345678| 开头和结尾 | 说明 |
| ^ | 出现在正则表达式中,匹配开头 |
| 出现在[]中, 表示取反 | |
| $ | 匹配结尾 |
| \b | 表示匹配单词测边界 |
| \bword 可以匹配word words 不匹配sword | |
| word\b 可以匹配word sword 不匹配words | |
| \bword\b 匹配word |
import re
# 匹配163.com的邮箱地址
# 以^确定开头
# 通过$来确定末尾
my_email = 'itisatest@163.com'
ret = re.match(r'^\w{4,20}@163\.com$', my_email)
print(ret.group())
#【运行结果】:
# itisatest@163.com| 匹配分组 | 说明 |
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个元素 |
| \num | 引用 分组num 匹配的字符串 |
| (?P<name>) | 给分组起别名 |
| (?P=name) | 引用 别名为name的分组 匹配的字符串 |
import re
# 匹配出 163、126、qq 邮箱
my_email = 'itisatest@qq.com'
ret = re.match(r'^\w{4,20}@(163|126|qq)\.com$', my_email)
print(ret.group())
# 匹配出 <html><h1>www.bawei.com</h1></html>
ret = re.match(r"<(\w*)><(\w*)>.*</\2></\1>", "<html><h1>www.hqyj.com</h1></html>")
print(ret.group())
# 匹配出 <html><h1>www.bawei.com</h1></html>
ret = re.match(r"<(?P<name1>\w*)><(?P<name2>\w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.hqyj.com</h1></html>")
print(ret.group())
#【运行结果】:
# itisatest@qq.com
# <html><h1>www.hqyj.com</h1></html>
# <html><h1>www.hqyj.com</h1></html>注意贪婪模式和非贪婪模式:
【贪婪】是尝试匹配尽可能多的字符。
【非贪婪】是尝试匹配尽可能少的字符。
解决方式:非贪婪操作符问号 ?,用在 * ,+,? 的后面,要求正则匹配的越少越好。
import re
s = 'abcdef123456'
ret = re.match(r'\w+', s)
print(ret.group())
#【运行结果】:
# abcdef123456
ret = re.match(r'\w+?', s)
print(ret.group())
#【运行结果】:
# a7、一个简单的示例
import re
my_email = input('输入邮箱:')
# 1、输入邮箱,邮箱验证: 6-16位非特殊字符的163邮箱。
if re.match(r'^\w{6,16}@163\.com$', my_email):
phone_num = input("输入手机号:")
# 2、输入手机号,进行手机号验证。11位数字,第一位是1,第二位是2到9,其余0到9
if re.match(r'^1[3-9]\d{9}$', phone_num):
user_name = input("请输入用户名:")
# 3、输入用户名,不少于非特殊4位字符。
if re.match(r'^\w{4,}$', user_name):
nickname = input("输入昵称:")
# 4、输入昵称,不少于2个字符.
if re.match(r'^\w{2,}$', nickname):
# 5、输入密码,必须包含字母、数字,特殊符号。
pwd = input("输入密码:")
if re.match(r'^.{6}$', pwd):
# 6、输入正确则提示注册成功,不正确则重新输入。
print("注册成功")
else:
print("密码不正确,请重新输入")
else:
print("昵称不正确,请重新输入")
else:
print("用户名不正确,请重新输入")
else:
print("手机号不正确,请重新输入")
else:
print("邮箱不正确,请重新输入")8、re.split函数
功能:分割
import re
s = 'user:张三 pwd:888666'
ret = re.split(r':| ', s)
print(ret)
#【运行结果】:
# ['user', '张三', 'pwd', '888666']9、re.sub函数
功能:替换
import re
s = 'i am jack, i am 18 year, i like eat!'
ret = re.sub(r"i", "I", s)
print(ret)
#【运行结果】:
# I am jack, I am 18 year, I lIke eat!本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » python高级之模块、迭代器与生成器和正则表达式

发表评论 取消回复