目录
PD and PE:INTRODUCTION AND ADVANCED METHODS
4.1 Chain of thought prompting
4.2 Encouraging the model to be factual through other means
4.3 Explicitly ending the prompt instructions
4.5 Use the AI to correct itself
4.6 Generate different opinions
4.7 Keeping state + role playing
4.8 Teaching an algorithm in the prompt
4.9 The order of the examples and the prompt
5.5 Streamlining Complex Tasks with Chains
5.6 Guiding LLM Outputs with Rails
5.7 Streamlining Prompt Design with Automatic Prompt Engineering
5.8 Augmenting LLMs through External Knowledge - RAG
6.1 Prompt Engineering Techniques for Agents
6.1.1 Reasoning without Observation (ReWOO)
6.1.3 Dialog-Enabled Resolving Agents (DERA)
7.Prompt Engineering Tools and Frameworks
本文讨论了 Prompt 设计和 Prompt 工程(PE)的相关内容,包括其基本概念、LLM 的局限、设计技巧和方法、高级 PE 以及相关工具和框架等方面。
关键要点包括:
-
Prompt 的定义和构成:Prompt 是用户提供的用于指导 LLM 输出的文本型输入,由 Instructions、Questions、Input Data 和 Examples 构成,其中 Instructions 和 Questions 是必要的。
-
LLM 的局限:包括缺乏持久的上下文记忆、输出具有随机性、缺乏实时更新能力、可能生成“幻觉”、计算成本高、资源需求大以及专业领域性能欠佳。
-
Prompt 设计技巧和方法:如思维链提示、事实性增强、明确结束指令提示、强硬、自我纠正、生成不同意见、保持状态和角色扮演、通过提示词指导 LLM 学习、注意 Prompt 投喂顺序、提供性等。
-
高级 PE:涵盖推理链、思维树、自我审查、专家提示、链式结构、Rails 引导 LLM 输出、自动提示词工程、通过外部知识增强 LLM 等。
-
工具和框架:介绍了 LangChain、Semantic Kernel、Guidance Library、Nemo Guardrails、LlamaIndex、FastRAG、Auto-GPT、AutoGen 等用于 Prompt 工程的工具和框架。
PD and PE:INTRODUCTION AND ADVANCED METHODS
1.Instructions
Prompt Design 和 PE 依然成为了最大限度的发挥LLM潜力的关键。针对于此,本文介绍了核心概念、思想链、模型反思等先进技术,以及基于LLM代理背后的原理。同时提供了关于PE 的工具调查。
2.Basic Knowledge - Prompt
2.1 Prompt
Prompt是由用户提供的用于指导LLM输出的文本型输入。Prompt可以是简单的问题也可以是复杂的描述甚至特定任务。比如DALLE-3等文生图大模型的Prompt通常是描述性的,而GPT-4或者Gemini等LLM Prompt可以简单的问题描述也可以是复杂的、特定任务的描述。
Prompt = Instructions + Questions + Input Data + Examples,但是其中Instructions 和 Questions 是必要的,而其他Elements 是可有可无的。
暂时无法在飞书文档外展示此内容
2.2 Prompt Cases
-
Instructions + questions :
“How should I write my college admission essay? Give me suggestions about the different sections I should include, what tone I should use, and what expressions I should avoid.”
-
Instructions + input:
“Given the following information about me, write a 4 paragraph college essay: I am originally from Barcelona, Spain. While my childhood had different traumatic events, such as the death of my father when I was only 6, I still think I had quite a happy childhood.. During my childhood, I changed schools very often, and attended all kinds of schools, from public schools to very religious private ones. One of the most “exotic” things I did during those years is to spend a full school year studying 6th grade in Twin Falls, Idaho, with my extended family. I started working very early on. My first job, as an English teacher, was at age 13. After that, and throughout my studies, I worked as a teacher, waiter, and even construction worker.”
-
Question + Examples:
“Here are some examples of TV shows I really like: Breaking Bad, Peaky Blinders, The Bear. I did not like Ted Lasso. What other shows do you think I might like?”
2.3 Prompt Engineering
Prompt engineering:
-
At its core, a prompt is the textual interface through which users communicate their desires to the model.
-
The essence of prompt engineering lies in crafting the optimal prompt to achieve a specific goal with a generative model.
PE 不是简单的 Prompt 构建,可以彻底改变 ML 的某些方面,超越特征或架构工程等传统方法。
3. LLM 的局限
大型语言模型 (LLM),包括基于 Transformer 架构的模型,已成为推进自然语言处理的关键。这些模型在大量数据集上进行了预先训练以预测后续标记,表现出卓越的语言能力。但是 LLM 的固有限制仍然影响其应用和有效性。
Limitaions:
-
缺乏持久的上下文记忆
-
输出具有随机性,可能导致不一致
-
基于历史数据,缺乏实时更新能力
-
可能生成“幻觉”(即虚假的内容)
-
计算成本高,资源需求大
-
专业领域性能欠佳
4. Prompt 设计技巧和方法
4.1 Chain of thought prompting
思维链:通过强制模型遵循一系列“推理”步骤来明确鼓励模型是事实/正确的。
Prompt form:

4.2 Encouraging the model to be factual through other means
事实性增强:通过提供参考来源提示模型生成更真实的信息。
通过提示模型引用正确的来源来为模型指明正确的方向。可以有效地缓解-可能会产生不真实或错误的幻觉知识问题。
4.3 Explicitly ending the prompt instructions
明确结束指令提示::
基于 GPT 的 LLM 有一个特殊的消息 <|endofprompt|> ,它指示语言模型将代码后面的内容解释为完成任务。

强硬:LLM 是很聪明的,可以通过加粗或者大写英文单词或者字母,甚至加感叹号等方式增强你的语气,那么它就会更遵循你的Prompt。


4.5 Use the AI to correct itself
自我纠正:让LLM生成Response,然后再让LLM 去纠正自己的错误,优化Response。
论文Figure 9 and 10。
4.6 Generate different opinions
LLM 如果是基于自己的认知的话,对于真假和对错的判断能力比较差,但是LLM 非常擅长提供很多方面的建议和意见,This can be a great tool when brainstorming and understanding different possible points of views on a topic.
4.7 Keeping state + role playing
LLM 的会话功能可以保持长时间保持一个状态,如果你赋予它有个角色,那么他会接受同时保持。
4.8 Teaching an algorithm in the prompt
通过提示词指导LLM学习。因为LLM具有很强的上下文学习能力。

4.9 The order of the examples and the prompt
Prompt 指导LLM学习或者完成某种特定的任务时,对于多步骤或者周期相对长一些的任务,不同的prompt 投喂顺序对于LLM的学习和理解能力是由较为明显的偏差的,进而导致response效果不同。
4.10 Affordances
提供性:可供性是在提示中定义的函数,并且明确指示模型在响应时使用。
当然这只是针对于你设定的特定任务。但是我认为LLM能够正确get到point,并作出响应应该是提供Function的前提。
5. Advanced PE
5.1 Chain of Thought (CoT)
推理链(思维链)::CoT通过将复杂问题分解为多步推理序列来提升LLM的逻辑推理能力。
-
零次推理链(Zero-Shot CoT):模型没有示例指导,自行展开问题解决步骤。
-
手动推理链(Manual CoT):使用示例作为模板,模型严格遵循特定的推理步骤。这种方法可以显著提高推理的可靠性,但需要设计复杂的提示模板。
应用:CoT技术适用于需要逻辑推理和多步骤思考的问题,如数学问题或复杂的决策任务。
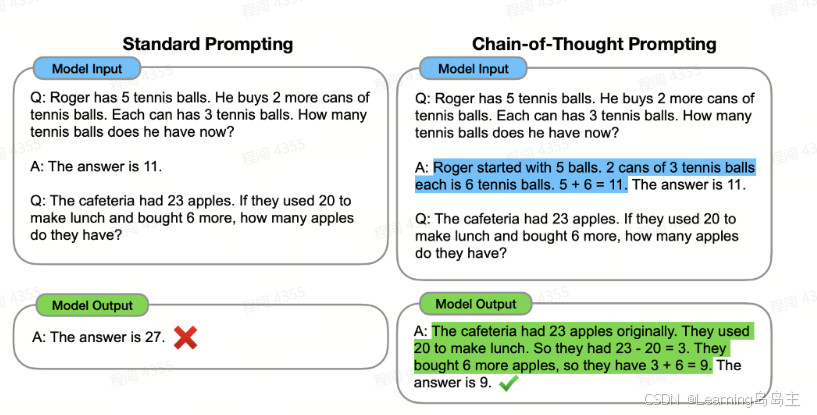
模型输入:在模型输入中,提供了直接的数学问题,但没有提示模型进行分步推理。
-
示例问题1:Roger有5个网球,他又买了两个装有3个网球的罐子。他现在有多少个网球?
-
示例问题2:餐厅有23个苹果,用了20个来做午餐,又买了6个,餐厅现在有多少个苹果?
模型输出:在标准提示下,模型直接尝试给出答案,没有分步进行计算,导致错误的答案。
-
示例问题1的答案是正确的,因为这个问题相对简单,模型可以直接给出11的答案。
-
示例问题2的答案是错误的,模型回答为27,而正确答案应该是9。标准提示方法在此失败,模型没有进行正确的分步计算。
Chain-of-Thought Prompting:
模型输入:在推理链提示方法中,模型被引导分步解决问题。这种方法让模型先理解并计算各个步骤,再给出最终答案。
-
示例问题1:模型分步描述了Roger一开始有5个球,再加上2个罐子,每罐有3个网球,总共加上6个,最终得出11。
-
示例问题2:模型解释餐厅最初有23个苹果,用了20个,剩下3个,又买了6个,总共有9个苹果。
模型输出:在推理链提示下,模型的输出更准确,因为它详细描述了每一步的计算,最终得到正确的答案。
-
示例问题1和问题2都得出了正确的答案。
5.2 Tree of Thought (ToT)
思维树(树状思维):
-
ToT 的核心是创建“思维树”,它代表了推理的分支路径。
-
思维树中的每个分支都是解决问题的不同可能方案或假设。
-
模型可以独立探索这些不同的分支,类似于人类在做决策前会权衡多种选择或视角。
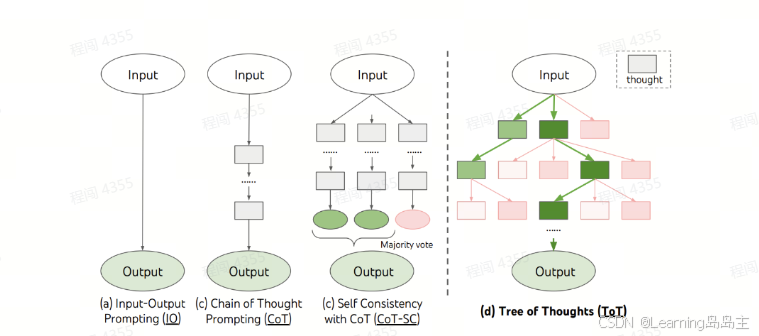
-
在此模式下,模型只接受一个输入,然后直接给出输出结果。
-
IO方法简单直接,但在需要复杂推理的任务中往往表现不佳,因为它没有多步骤的推理或上下文积累的能力。
Chain of Thought Prompting (CoT):
-
CoT 是链式思维提示,通过让模型生成一个逐步推理过程来改进输出。
-
模型在输出最终答案之前生成一系列中间推理步骤,帮助其更好地理解问题。
-
例如,模型可能会在计算总值之前先算出每一个部分的数值,然后将这些数值相加。
-
CoT 方法相比 IO 提升了推理质量。
Self-Consistency with CoT (CoT-SC):
-
Self-Consistency 是在 CoT 的基础上进行的改进。
-
在 CoT-SC 中,模型生成多条不同的推理路径,并基于这些路径得出多种输出。
-
最终对输出进行“投票”来确定最可能的正确答案(即选出多数路径的结果作为最终答案)。
-
利用了模型生成多样化路径的能力,可以更有效地纠正潜在的错误。
Tree of Thoughts (ToT):
-
ToT 是一种更高级的推理结构,通过将推理过程构建成一棵“思维树”来探索多种不同的推理路径。这种方法不像 CoT 和 CoT-SC 那样是线性的,而是通过树结构提供多个分支和节点。
-
在这个结构中,每个节点(绿色或粉色方块)代表思维过程中的一个“想法”或步骤。
-
树的分支表示模型在解决问题时所选择的不同推理路径,每个分支代表一条不同的逻辑路径。
-
ToT 允许模型同时探索多个解决方案,使其能够更全面地考虑潜在的解答路径。树的最终输出是综合考虑所有分支后的最优解。
Summary:
-
IO 是最简单的,没有中间推理步骤。
-
CoT 提供了线性推理链条,帮助模型进行分步推理。
-
CoT-SC 引入了多次推理并使用多数投票法,提高了准确性。
-
ToT 则通过树状结构探索所有可能的推理路径,使得模型能够从不同角度推理问题,从而提升复杂问题的解答能力。
5.3 Reflection
自我审查:
让LLM在生成初始回答后,进行自我审查,以检测并改进其输出中的潜在错误、不一致或其他需要改进的地方。这种过程类似于人类的自我编辑,模型会对自己的回答进行评估,并在发现问题时,生成更连贯、可靠的改进版本。
具体流程:
-
生成初始回答:模型首先根据输入生成一个初步的回答。
-
自我审查:然后模型会被提示对这个回答进行审视,从而进行自我评估。这一步模型会检查回答中的逻辑一致性、事实准确性以及回答的相关性。
-
标记问题并改进:如果模型识别到初始回答中的错误或可以改进之处,它会尝试重新回答这个问题,从而生成一个优化的版本。这样,经过几个迭代的反思和修改,模型的最终回答可以更接近理想答案。
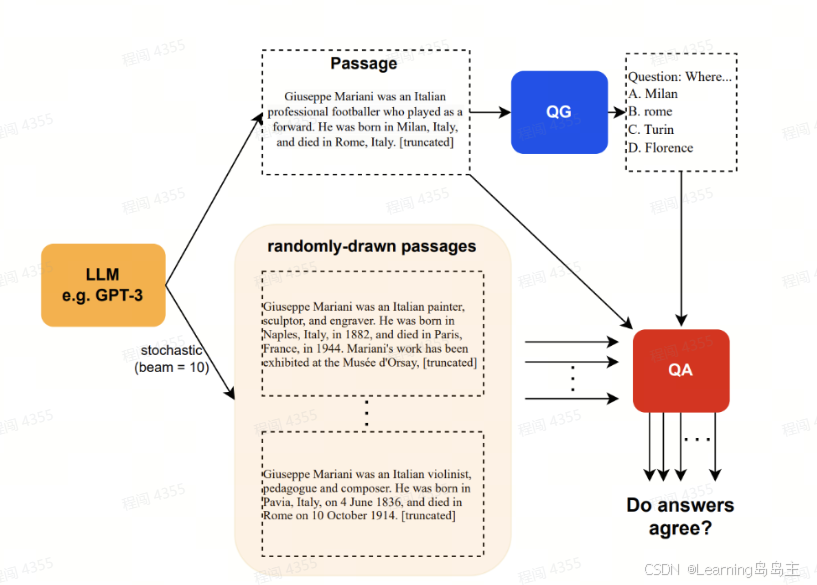
-
该模型被要求生成关于某个主题的不同段落。这里的例子是关于“Giuseppe Mariani”的不同描述。模型生成了多个段落,段落中的信息略有不同,这些段落被放在图中“随机生成的段落”(randomly-drawn passages)方框中。
-
LLM生成段落时,使用了随机性(stochastic性)和一定的束搜索(beam search),例如束宽为10(beam=10),意味着模型在生成每句话时有10种不同选择,从而生成内容不同但主题一致的段落。
生成问题 (QG):
-
通过一个问题生成模块(QG),从上面生成的段落中抽取信息生成问题。例如,从段落中提取“出生地”这一信息,生成一个选择题问题:
-
问题:“Where was Giuseppe Mariani born?”(Giuseppe Mariani出生在哪里?)
-
选项:A. Milan,B. Rome,C. Turin,D. Florence。
-
-
问题生成模块(QG)使用LLM生成的文本段落内容,并自动生成相应的问题和答案选项。
回答问题 (QA):
-
在生成问题后,进入“QA”模块(即问答模块)。
-
在QA模块中,每个生成的问题会被输入到LLM中。LLM会根据它生成的不同段落来回答这个问题。
-
这一步的目的是从不同段落中找到LLM对同一问题的回答,并检查回答的一致性。
答案一致性检查:
-
“Do answers agree?”部分用于检查不同段落生成的答案是否一致。
-
如果LLM在所有不同的段落中对同一个问题(如出生地问题)的答案一致,那么可以认为LLM的回答有较高的可靠性。
-
如果不同段落生成的答案不一致,则可能存在信息不一致的问题,这表明模型的生成内容在特定事实上的稳定性不足,可能会出现混淆或矛盾的信息。
5.4 Expert Prompting
专家提示:
通过模拟多领域专家的响应来增强大型语言模型(LLM)的功能,使其能够生成更加深入和富有洞见的回答。
多专家策略:
Expert Prompting的一个关键点是“多专家策略”,即引导LLM从多个专家视角出发,整合各方面的知识来回答复杂问题。通过引入多个专家观点,模型生成的答案不仅在深度上得到提升,同时还减少了单一视角的偏见,增强了回答的客观性和全面性。这样的回答更具层次感,能够更好地反映实际问题的复杂性。
例如,回答一个医疗问题时,模型可能会被引导模拟不同专家的角色,如临床医生、医学研究员和公共卫生专家。这种方法有助于提供更加丰富和全面的回答,因为它结合了多个领域的专业知识,而不仅仅是单一视角的见解。
5.5 Streamlining Complex Tasks with Chains
链式结构:
在处理复杂任务时,可以通过“链式结构”将一个大任务分解成多个小步骤,每个步骤由单独的组件处理。这些组件串联在一起,前一个组件的输出作为后一个组件的输入,形成一个完整的工作流。
 5.6 Guiding LLM Outputs with Rails
5.6 Guiding LLM Outputs with Rails
Rails引导LLM输出:
在高级提示工程(Prompt Engineering)中,Rails 是一种通过预设的约束来引导大型语言模型(LLMs)输出内容的策略,以确保生成的内容具有相关性、安全性和事实准确性。这种方法采用一套规则或模板(通常称为 Canonical Forms),作为模型输出的框架,确保生成的响应符合特定的标准或要求。
Rails类型:
-
主题 Rail(Topical Rails):设计用于让 LLM 聚焦于特定的主题或领域,避免输出内容偏离主题或包含不相关的信息。例如,在教育工具中,主题 Rail 可确保输出内容始终与教学相关。
-
事实核查 Rail(Fact-Checking Rails):旨在减少错误信息的传播,通过引导 LLM 生成基于证据的响应,避免未经证实的陈述。它可以在新闻聚合服务等场景中使用,确保信息的准确性。
-
越狱防护 Rail(Jailbreaking Rails):防止 LLM 生成规避操作限制或违反道德准则的内容。这在互动应用中非常关键,可以防止模型生成不良或有害的内容。
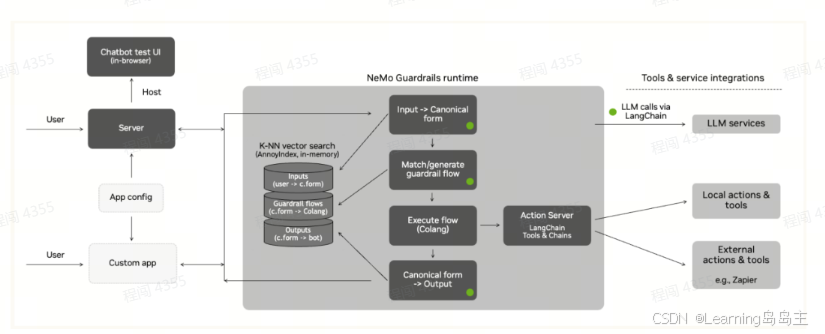
流程介绍:
进入 NeMo Guardrails 运行时环境后,用户输入会被转换成统一的“规范形式”,以确保输入数据结构一致。随后,系统通过 K-NN 向量搜索匹配用户输入的相似度,检索或生成与之相对应的“guardrail flow”,即一种对模型输出进行约束的流程。这些 guardrail 流程定义了系统如何根据不同输入做出反应,确保响应符合预设规则和期望输出格式。该流程由 Colang 描述和执行,从而对 LLM 生成的输出施加限制。
在 Guardrails 流程执行的过程中,Action Server(操作服务器)基于 LangChain 提供的工具和链条,进一步支持流程中需要的特定操作。Action Server 可以通过 LangChain 连接大型语言模型(LLM)服务,从而使系统具备强大的自然语言处理能力。此外,Action Server 还可以调用本地工具和外部服务(例如 Zapier),以便与其他系统集成,满足复杂的功能需求。
执行流程生成的结果会被重新转换成规范形式,并输出至用户界面或自定义应用,完成一次闭环交互。通过这种分层结构和集成多种服务的设计,NeMo Guardrails runtime 能够在不同环境中为 LLM 提供稳定、安全、符合规则的输出,使得对话系统或其他应用中的 AI 模型可以安全、精确地满足用户需求。
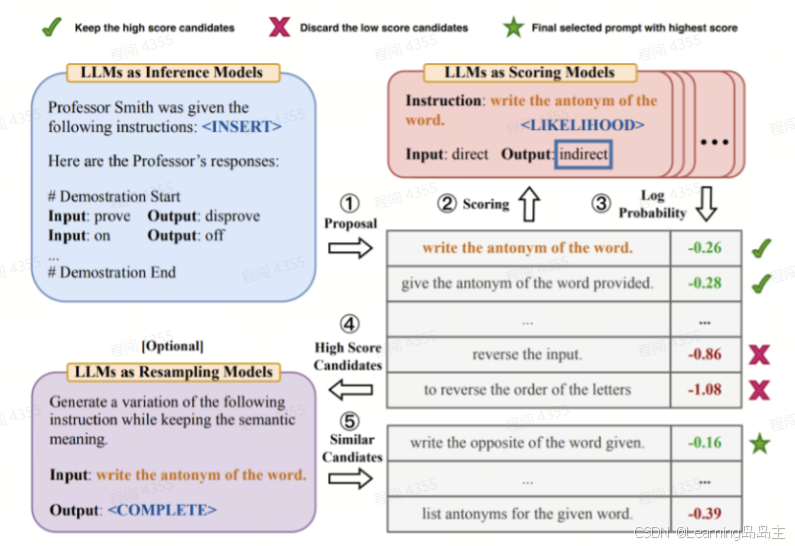
5.7 Streamlining Prompt Design with Automatic Prompt Engineering
自动提示词工程(APE):
-
提示生成:LLM(大型语言模型)首先会基于特定任务生成各种提示。这些提示通过模型的语言数据库和上下文理解生成,并且多样化,以覆盖不同的表达和引导方式。
-
提示评分:在生成提示后,每个提示会根据一些关键指标进行评分,这些指标可能包括提示的清晰度、具体性以及是否能够引导模型生成期望的输出。评分阶段确保只有最有效的提示进入下一步的优化环节。
-
优化和迭代:在评分的基础上,系统会对提示进行细化和调整,使其更加贴合任务要求。这一优化过程是迭代的,即模型会不断生成、评估和调整提示,逐步提升提示质量。
自动提示工程 (APE) 等创新可能会在未来几年成为标准实践。
 5.8 Augmenting LLMs through External Knowledge - RAG
5.8 Augmenting LLMs through External Knowledge - RAG
RAG:
RAG 通过动态整合外部知识来扩展 LLM,从而利用初始训练数据中未包含的最新或专业信息来丰富模型的响应。 RAG 的运行方式是根据输入提示制定查询,并利用这些查询从不同来源或知识获取相关信息。
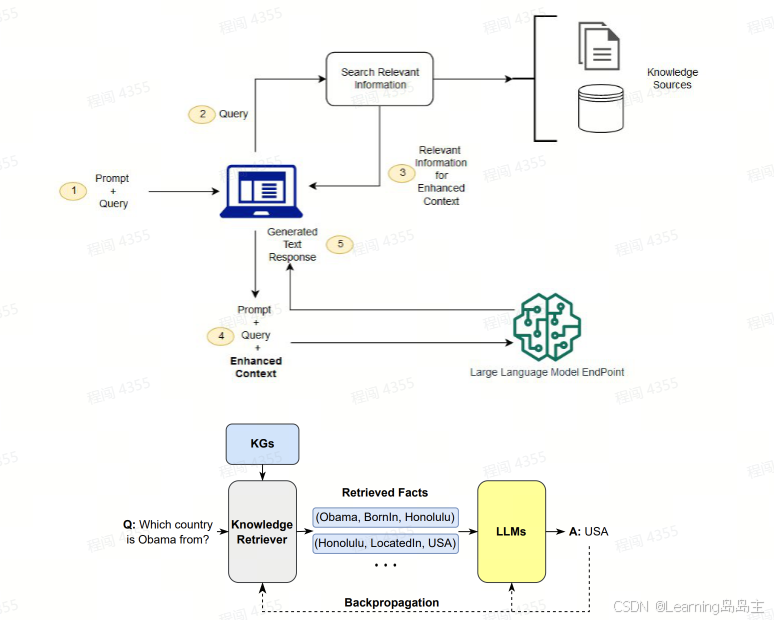
RAG-aware提示设计有助于引导模型高效利用检索到的内容,从而生成更准确、相关性更高的回答。
6.LLM Agents 大模型代理
LLM Agent:
LLM代理(Large Language Model Agents)是基于大型语言模型(LLM)的智能实体,能够在环境中自动执行复杂任务,不仅仅是生成简单的响应,还能通过决策和工具利用能力进行操作。这些代理可以访问外部工具和服务,根据上下文输入和预定义目标做出明智的决策。例如,LLM代理可以通过API获取天气信息或执行购买行为,从而在外部世界中实现交互和执行。
6.1 Prompt Engineering Techniques for Agents
基于代理的提示词功能技术:
-
Reasoning without Observation (ReWOO):允许LLM在没有立即访问外部数据的情况下构建推理计划,依赖结构化的推理框架,在相关数据可用时执行。这种方法特别适用于数据检索代价高昂或不确定的场景。
-
Reason and Act (ReAct):通过在推理轨迹中加入可执行步骤,将推理与操作紧密结合,实现动态的任务解决方式。
-
Dialog-Enabled Resolving Agents (DERA):DERA是一种多代理框架,其中多个具备特定角色的代理通过对话协作解决查询和决策,能够以类似于人类决策过程的方式处理复杂的查询。
6.1.1 Reasoning without Observation (ReWOO)
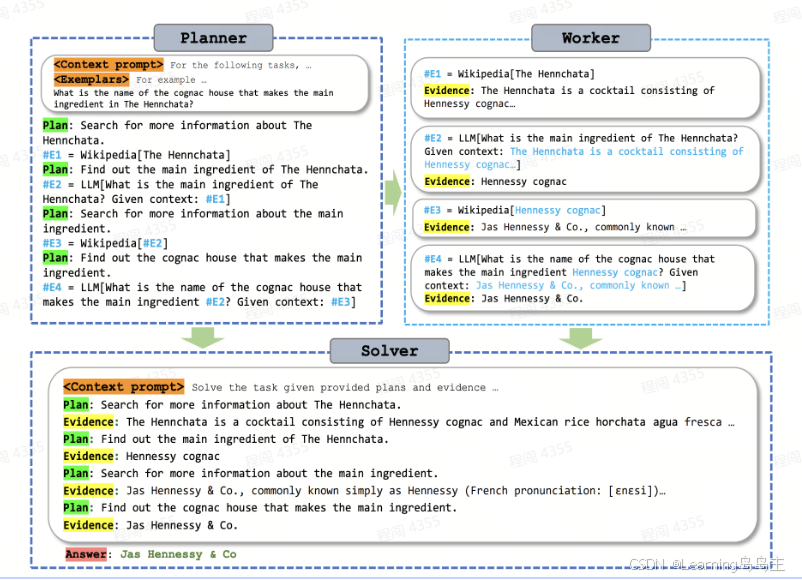
Planner:
规划器的任务是生成一系列的查询步骤(计划)来解决给定的任务。它的输入是一个<Context prompt>,其中包含了任务的描述和目标。这个任务是要找出"使Hennchata的主要成分的干邑酒厂的名字"
worker:
Worker模块负责执行Planner提出的各个查询步骤,并提供相应的证据(Evidence)。每次Worker执行一个查询时,它将搜索的结果返回给Planner或直接记录在证据列表中。
Solver:
Solver模块的任务是将从Worker模块获得的所有计划和证据进行整合,以生成最终答案。
6.1.2 Reason and Act (ReAct)

虚线以上为测试问题1,以下为测试问题2。
6.1.3 Dialog-Enabled Resolving Agents (DERA)
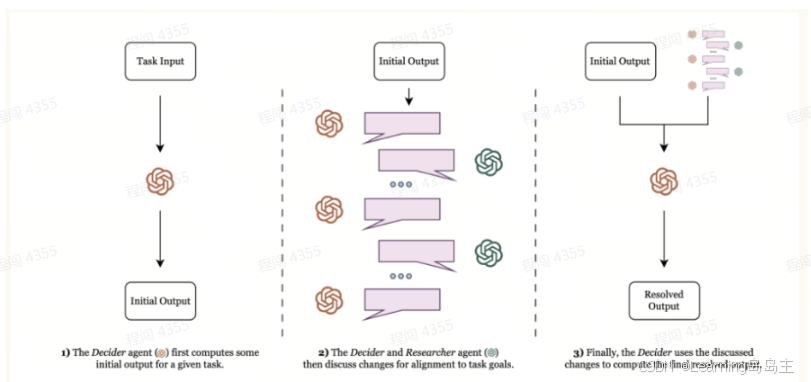
三个阶段:
-
Decider智能体生成初始输出
-
Decider和Researcher智能体讨论调整
-
Decider生成最终优化的输出
7.Prompt Engineering Tools and Frameworks
这部分介绍了一些工具和框架,它们用于简化和增强提示工程的实现。
主要工具和框架:
1. LangChain:
LangChain 是提示工程工具集的核心组件之一。它最初专注于实现“链”(Chains),即一系列连接在一起的提示,用于处理复杂的多步骤任务。
随着功能的扩展,LangChain 现在支持更多的特性,包括代理(Agents)和网络浏览功能。它在开发复杂的大型语言模型(LLM)应用程序中扮演着不可或缺的角色,适用于构建灵活的提示链和交互式任务。
2. Semantic Kernel(微软):
Semantic Kernel 提供了强大的工具集,支持技能开发和任务规划,同时还包括链式处理、索引和内存访问等功能。
其多语言支持使其在不同用户群体中具有广泛的吸引力,尤其适合需要在多种编程语言中实现提示工程的开发者。
3. Guidance Library(微软):
Guidance Library 提供了现代化的模板语言,专门用于提示工程。它的设计与当前的提示工程技术进展相一致。
该库支持复杂的提示模板设置,使开发者能够创建结构化的提示,更好地控制 LLM 输出的格式和内容。
4. Nemo Guardrails(英伟达):
Nemo Guardrails 专注于构建“Rails”(导轨),确保 LLM 在预定义的规则和安全边界内操作。这有助于提高 LLM 输出的安全性和可靠性。
通过在 LLM 输出时加入 Rails,可以避免生成偏离主题或不符合预期的内容,适合需要高安全性和一致性的应用场景。
5. LlamaIndex:
LlamaIndex 专注于 LLM 应用的数据管理。它提供了管理大量数据所需的工具,简化了数据集成的过程。
这一工具对于需要大量外部数据支持的 LLM 应用非常关键,确保数据可以高效地被模型利用。
6. FastRAG(英特尔):
FastRAG 是一种改进版的检索增强生成(RAG)方法,包含了更先进的实现,专门用于需要高效数据检索和集成的任务。
FastRAG 可以加快信息检索的速度,并提高信息集成的准确性,适合复杂的检索增强型生成任务。
7. Auto-GPT:
Auto-GPT 专注于设计 LLM 代理(Agents),使开发者可以简化复杂 AI 代理的创建过程。 它拥有用户友好的界面和全面的功能,为创建能够自动完成多步骤任务的 LLM 代理提供了极大的便利。
8. AutoGen(微软):
AutoGen 是专门用于设计多代理系统的工具,支持多代理协同工作。它在提示工程的生态系统中补充了多代理设计的能力。
这一工具在需要多个代理共同完成任务的复杂系统中尤其有用。
Conclusion
随着 LLM 和生成式人工智能的发展,及时的设计和工程只会变得更加重要。我们讨论了检索增强生成(RAG)等基础和前沿方法--下一波智能应用的重要工具。随着提示设计和工程技术的快速发展,像这样的资源将为早期技术提供一个历史视角。请记住,这里介绍的自动提示工程 (APE) 等创新技术在未来几年可能会成为标准实践。请参与塑造这些令人兴奋的发展轨迹!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Prompt设计技巧和高级PE

发表评论 取消回复