maven依赖文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.lh.pblh123</groupId>
<artifactId>spark2024</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<!-- 设置国内maven下载镜像源-->
<repositories>
<repository>
<id>alimaven</id>
<name>aliyun maven</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.4.4</version>
<exclusions> <!--设置日志级别-->
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.4.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.4.4</version> <!-- 请根据实际版本调整 -->
</dependency>
<!-- 添加spark streaming依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.4.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>2.12.17</scalaVersion>
<args>
<arg>-target:jvm-1.8</arg>
</args>
</configuration>
</plugin>
</plugins>
</build>
</project>源码如下:
package cn.lh.pblh123.spark2024.theorycourse.charpter8
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.{StreamingQueryException, Trigger}
object StructureNetworkWordCount {
def main(args: Array[String]): Unit = {
if (args.length != 1 || args(0).trim.isEmpty) {
System.err.println(s"Usage: ${this.getClass.getSimpleName} <master_url>")
System.exit(5)
}
val murl = args(0)
val spark = SparkSession.builder().appName(s"${this.getClass.getSimpleName}").master(murl).getOrCreate()
// 从配置文件或环境变量中读取主机名和端口号
val host = sys.env.getOrElse("SOCKET_HOST", "localhost")
val port = sys.env.getOrElse("SOCKET_PORT", "9999").toInt
try {
val lines = readSocketStream(spark, host, port)
import spark.implicits._
// 导入Spark隐式转换,使得可以使用Spark SQL和Dataset相关操作
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream.outputMode("complete")
.format("console")
.trigger(Trigger.ProcessingTime("5 seconds"))
.start()
query.awaitTermination()
} catch {
case e: StreamingQueryException =>
println(s"Streaming query failed with exception: ${e.getMessage}")
// 可以在这里添加更多的错误处理逻辑,例如重试机制
case e: Exception =>
println(s"An unexpected error occurred: ${e.getMessage}")
// 可以在这里添加更多的错误处理逻辑
}
spark.stop()
}
/**
* 读取 Socket 流数据
*
* @param spark SparkSession 实例
* @param host 主机名
* @param port 端口号
* @return 读取的 DataFrame
*/
def readSocketStream(spark: SparkSession, host: String, port: Int): org.apache.spark.sql.DataFrame = {
// 读取来自指定主机和端口的socket数据流
spark.readStream.format("socket")
.options(Map("host" -> host, "port" -> port.toString))
.load()
}
// 待优化代码如下
// val lines = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
}
终端启动nc服务
(base) pblh123@LeginR7:~$ nc -lk 9999
i like hadoop
i like spark
你好世界 你
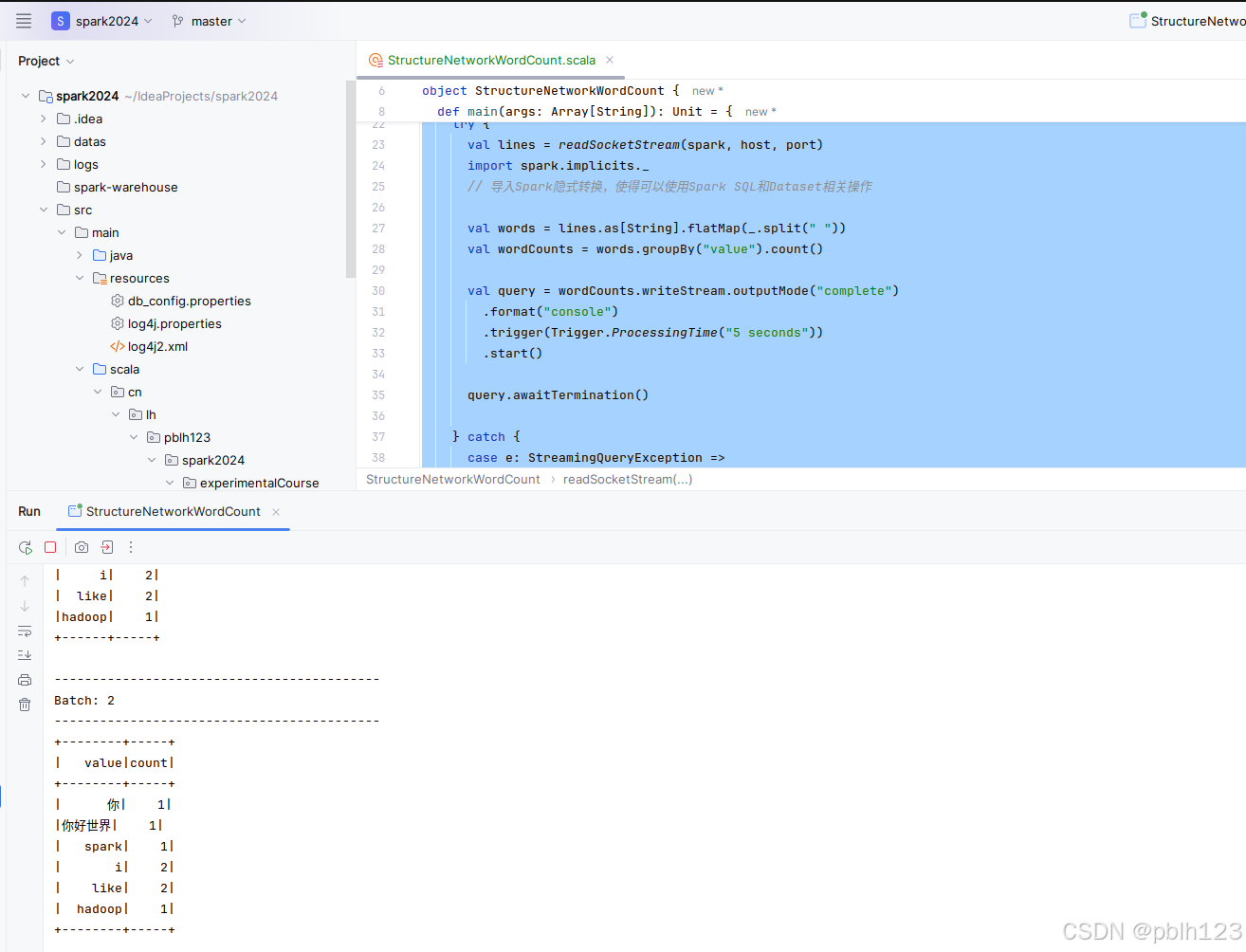
代码运行效果如下,需要先启动nc服务后在启动
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 基于Spark3.4.4开发StructuredStreaming读取socket数据

发表评论 取消回复