1. 自编码器简介
自编码器(Autoencoder)是一种无监督学习的神经网络模型,旨在学习数据的有效表示。自编码器的主要组成部分包括编码器和解码器,二者共同工作以实现数据的压缩和重构。以下是自编码器的详细介绍:
1.1 自编码器的工作原理
自编码器的基本原理是将输入数据通过编码器映射到一个低维的潜在空间表示(latent representation),然后通过解码器将这个低维表示重构为原始数据。自编码器的训练目标是最小化输入数据和重构数据之间的差异,通常使用均方误差(MSE)或交叉熵作为损失函数。
-
编码器:编码器负责将输入数据压缩成低维表示。它通常由多个神经网络层组成,通过逐层提取特征,最终输出一个较小的表示向量。
-
解码器:解码器负责将低维表示转换回原始数据的维度。它的结构通常与编码器对称,使用转置卷积(deconvolution)或上采样(upsampling)等操作来逐步恢复数据的形状。
1.2 自编码器在音频的应用
自编码器在音频领域的应用越来越受到关注,尤其是在音频信号处理、特征提取和生成模型等方面。以下是自编码器在音频领域的一些主要应用:
当然可以!以下是将您提供的内容转换为项目符号格式的版本:
自编码器在音频领域的应用
-
音频特征提取:
- 自编码器可以用于从原始音频信号中提取有效的特征表示。
- 通过训练自编码器,模型能够学习到音频信号中的重要特征,这些特征可以用于后续的分类、识别或生成任务。
- 例如,在语音识别中,自编码器可以帮助提取语音信号的关键特征,从而提高识别的准确性。
-
音频降噪:
- 去噪自编码器(Denoising Autoencoder)在音频处理中的应用非常广泛。
- 通过向输入音频信号添加噪声并训练模型从噪声中恢复原始信号,去噪自编码器可以有效地减少背景噪声或其他干扰。
- 这种方法在音乐制作、语音通信和听力辅助设备中尤为重要,可以提高音频的清晰度和可懂度。
-
音频生成:
- 变分自编码器(Variational Autoencoder, VAE)在音频生成方面展现了巨大的潜力。
- 通过学习音频数据的潜在分布,VAE 可以生成与训练数据相似的新音频样本。
- 这在音乐生成、声音合成和音效设计中具有重要应用,例如,VAE 可以用于生成新的音乐片段,或合成特定类型的声音效果。
-
音频分类与识别:
- 自编码器可以用于音频信号的分类和识别任务。
- 通过将音频信号映射到低维特征空间,自编码器可以帮助提高分类器的性能。
- 例如,在音乐流派分类或情感识别中,自编码器可以提取音频信号中的重要特征,从而提高模型的准确性。
-
语音合成与转换:
- 自编码器在语音合成和转换任务中也有应用。
- 通过训练自编码器将输入语音信号映射到潜在空间,模型可以实现语音的风格转换或语音合成。
- 这种技术可以用于语音助手、语音翻译和个性化语音生成等场景。
-
音频异常检测:
- 自编码器可以用于检测音频信号中的异常或不正常的部分。
- 例如,在工业设备的声音监测中,自编码器可以学习正常设备的声音特征,并通过重构误差检测到异常声音。
- 这种方法可以用于故障检测和维护预测。
如果您需要进一步的修改或有其他问题,请随时告诉我!
1.3 自编码器的优缺点
优点:
- 自编码器可以自动学习数据的特征表示,无需人工特征提取。
- 适用于高维数据,能够捕捉复杂的非线性关系。
- 具有良好的重构能力,可以用于去噪和异常检测。
缺点:
- 训练自编码器需要大量的数据,以避免过拟合。
- 在某些情况下,可能会学习到冗余的特征表示,导致重构效果不佳。
- 对于特定任务,可能需要设计合适的网络结构和超参数。
1.4 本文目标
在本博客中,我们将实现一个简单的卷积自编码器,使用 PyTorch 框架处理 MNIST 数据集(手写数字图像)。我们将详细介绍模型的结构、训练过程和损失计算,并使用可视化工具展示网络结构及其性能。
接下来,我们将介绍卷积自编码器的具体实现,包括编码器和解码器的结构、每一层的数据维度,以及训练过程中的注意事项。
2. 自编码器的结构
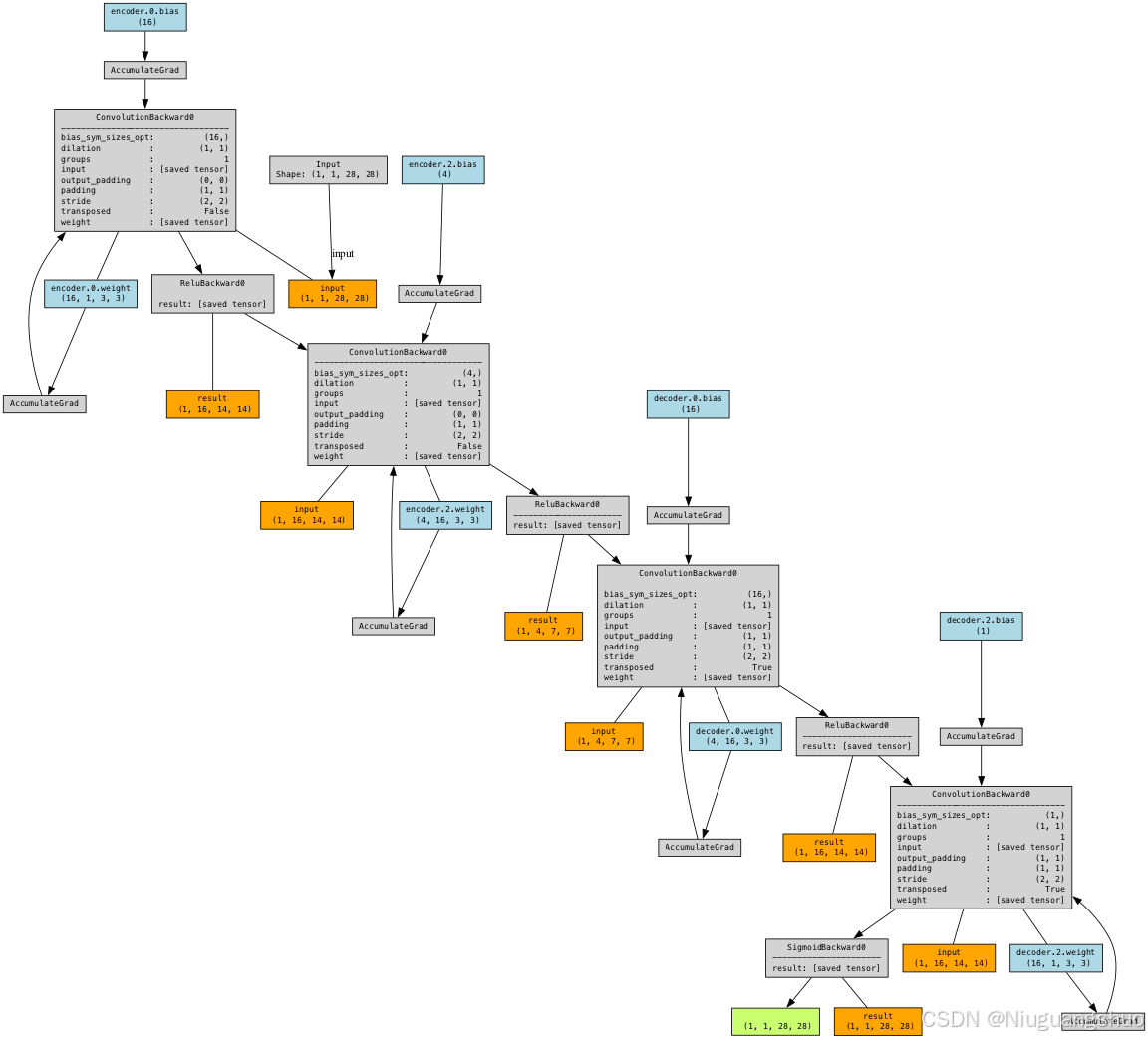
2.1 编码器
编码器是自编码器的第一部分,它负责将输入图像转换为低维表示。我们的编码器由两个卷积层组成,每个卷积层后面跟着 ReLU 激活函数。具体结构如下:
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1), # 16 x 14 x 14
nn.ReLU(),
nn.Conv2d(16, 4, kernel_size=3, stride=2, padding=1), # 4 x 7 x 7
nn.ReLU()
)
-
第一层卷积:
- 输入通道数:1(灰度图像)
- 输出通道数:16
- 卷积核大小:3x3
- 步幅:2
- 填充:1
- 输出形状:
(batch_size, 16, 14, 14)(经过卷积操作后,图像大小减半)
-
第二层卷积:
- 输入通道数:16
- 输出通道数:4
- 卷积核大小:3x3
- 步幅:2
- 填充:1
- 输出形状:
(batch_size, 4, 7, 7)(再次减半)
2.2 解码器
解码器是自编码器的第二部分,它负责将低维表示重构为原始输入图像。我们的解码器也由两个转置卷积层组成,每个转置卷积层后面跟着 ReLU 激活函数。具体结构如下:
self.decoder = nn.Sequential(
nn.ConvTranspose2d(4, 16, kernel_size=3, stride=2, padding=1, output_padding=1), # 16 x 14 x 14
nn.ReLU(),
nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=1, output_padding=1), # 1 x 28 x 28
nn.Sigmoid() # 使用 Sigmoid 确保输出在 [0, 1] 范围内
)
-
第一层转置卷积:
- 输入通道数:4
- 输出通道数:16
- 卷积核大小:3x3
- 步幅:2
- 填充:1
- 输出填充:1
- 输出形状:
(batch_size, 16, 14, 14)(恢复到较大的空间)
-
第二层转置卷积:
- 输入通道数:16
- 输出通道数:1
- 卷积核大小:3x3
- 步幅:2
- 填充:1
- 输出填充:1
- 输出形状:
(batch_size, 1, 28, 28)(最终恢复到原始图像大小)
最后,解码器的输出通过 Sigmoid 激活函数进行处理,确保输出值在 [0, 1] 的范围内。
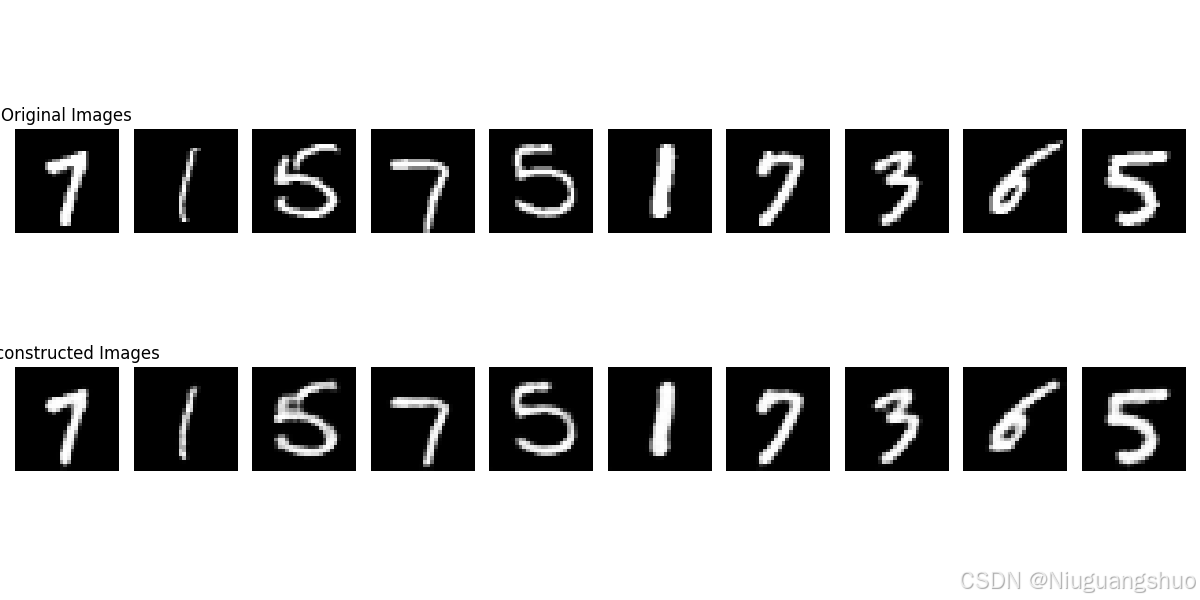
3. 代码实现
以下是完整的代码实现,包括模型定义、数据加载、训练和可视化:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import matplotlib.pyplot as plt
from torchviz import make_dot
# 设定随机种子以便复现结果
torch.manual_seed(42)
# 检查是否有可用的 MPS 设备
device = torch.device("mps" if torch.backends.mps.is_available() else "cpu")
print(f'Using device: {device}')
# 定义卷积自编码器模型
class ConvAutoencoder(nn.Module):
def __init__(self):
super(ConvAutoencoder, self).__init__()
# 编码器
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3, stride=2, padding=1), # 16 x 14 x 14
nn.ReLU(),
nn.Conv2d(16, 4, kernel_size=3, stride=2, padding=1), # 4 x 7 x 7
nn.ReLU()
)
# 解码器
self.decoder = nn.Sequential(
nn.ConvTranspose2d(4, 16, kernel_size=3, stride=2, padding=1, output_padding=1), # 16 x 14 x 14
nn.ReLU(),
nn.ConvTranspose2d(16, 1, kernel_size=3, stride=2, padding=1, output_padding=1), # 1 x 28 x 28
nn.Sigmoid() # 使用 Sigmoid 确保输出在 [0, 1] 范围内
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# 超参数
num_epochs = 30
batch_size = 128
learning_rate = 0.0005
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量并归一化到 [0, 1]
])
# 加载 MNIST 数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
# 创建自编码器模型并移动到设备
model = ConvAutoencoder().to(device)
# 定义损失函数和优化器
criterion = nn.BCELoss() # 使用二元交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练自编码器
for epoch in range(num_epochs):
for data in train_loader:
img, _ = data # 获取图像和标签
img = img.to(device) # 将输入图像移动到设备
# 前向传播
reconstructed = model(img)
# 计算损失
loss = criterion(reconstructed, img)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 测试自编码器
with torch.no_grad():
sample_data = next(iter(train_loader))[0][:10] # 选择前10个样本
sample_data = sample_data.to(device) # 将样本移动到设备
reconstructed_data = model(sample_data)
# 可视化网络结构
x = torch.randn(1, 1, 28, 28).to(device) # 创建一个随机输入张量
y = model(x) # 前向传播以生成输出
dot = make_dot(y, params=dict(model.named_parameters()), show_attrs=True, show_saved=True)
# 添加输入张量的形状
dot.node('input', 'Input\nShape: (1, 1, 28, 28)', shape='box') # 添加输入节点
dot.edge('input', str(id(x)), label='input') # 连接输入节点到模型输入
dot.render("conv_autoencoder", format="png") # 保存为 PNG 文件
# 可视化输入数据和重构数据
plt.figure(figsize=(12, 6))
# 原始图像
plt.subplot(2, 10, 1)
plt.title('Original Images')
for i in range(10):
plt.subplot(2, 10, i + 1)
plt.imshow(sample_data[i].cpu().squeeze(), cmap='gray') # 移动到 CPU 进行可视化
plt.axis('off')
# 重构图像
plt.subplot(2, 10, 11)
plt.title('Reconstructed Images')
for i in range(10):
plt.subplot(2, 10, 10 + i + 1)
plt.imshow(reconstructed_data[i].cpu().squeeze(), cmap='gray') # 移动到 CPU 进行可视化
plt.axis('off')
plt.tight_layout()
plt.show()
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 使用卷积自编码器进行图像重构

发表评论 取消回复