目录
bitpos计算Bitmaps中第一个值为targetBit的偏移量
georadiusbymember 获取指定范围内的地理位置集合
简介
本文章来学习和实践一下Redis的高级数据结构,主要包含有BitMaps、HyperLogLog、GEO三个数据结构。
高级数据结构具体方法解析
Bitmaps 位图
Redis提供的Bitmaps这个“数据结构”可以实现对位的操作。Bitmaps本身不是一种数据结构,实际上它就是字符串,但是它可以对字符串的位进行操作。
Bitmaps单独提供了一套命令,所以在Redis中使用Bitmaps和使用字符串的方法不太相同。可以把bitmaps想象成一个以位为单位的数组,数组的每个单元只能存储0和1,数组的下标在Bitmaps中叫做偏移量。
操作命令
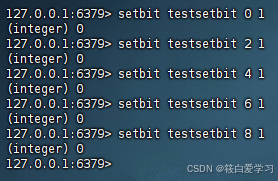
setbit设置值
setbit key offset value
设置键的第offset个位的值(从0算起)。
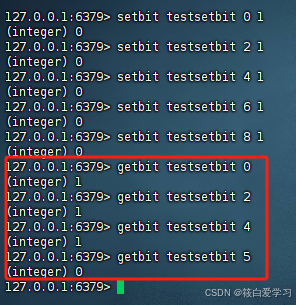
getbit获取值
getbit key offset
获取键的第offset位的值(从0开始算)。
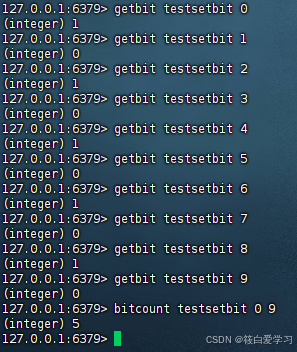
bitcount获取Bitmaps指定范围值位1的个数
bitcount key [start end]
start:偏移量
end:偏移量
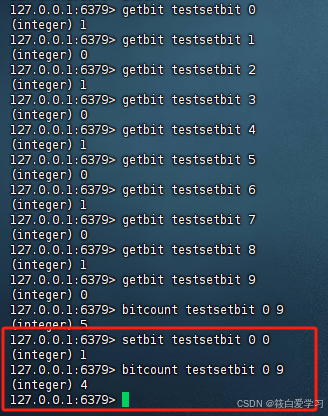
将偏移量(下标)为0的值改为0,则统计出来范围值为1的个数就会减少
bitop Bitmaps间的运算
bitop operation destkey key [key ...]
bitop是一个符合操作,它可以做多个Bitmaps的and(交集)or(并集)not(非)xor(异或)操作并将结果保存在destkey中。

bitpos计算Bitmaps中第一个值为targetBit的偏移量
bitpos key bit [start] [end]
- key:位图的键名。
- bit:要查找的位值,只能是 0 或 1。
- START(可选):开始搜索的偏移量。
- END(可选):结束搜索的偏移量。
命令返回第一个匹配指定值的位的偏移量。如果未找到匹配的位,且未指定 START 和 END 参数,则返回 -1。如果指定了 START 和 END,但在该范围内未找到匹配的位,则返回一个大于 END 的值(这实际上是Redis的一种约定,表示未找到)。
Bitmaps优势
假设网站有1亿用户,每天独立访问的用户有5千万,如果每天用集合类型和 Bitmaps分别存储活跃用户,很明显,假如用户id是Long型,64位,则集合类型占据的空间为64位x50 000 000= 400MB,而Bitmaps则需要1位×100 000 000=12.5MB,可见Bitmaps能节省很多的内存空间。
布隆过滤器
用来判断一个元素是否在一个集合中。
布隆过滤器是由一个很长的二进制向量(位数组)和一系列哈希函数组成。它主要用于判断一个元素是否存在于一个集合中,查询结果有两种:
- 这个元素可能存在于这个集合当中。
- 这个元素一定不存在于这个集合当中。
工作原理:
1.位数组:布隆过滤器使用一个长度为m的位数组,每一位都初始化为0。这些将用于表示元素的存在情况。
2.哈希函数:布隆过滤器配备了k个独立的哈希函数。每个哈希函数都会为输入的元素生成一个0到m-1之间的索引值,也就是将元素“映射”到位数组中的某个位置。
当将一个元素添加到布隆过滤器时,k个哈希函数会为该元素生成k个不同的索引值,并将位数组中的这k个位置设置为1。查询某个元素是否存在时,布隆过滤器会使用相同的k个哈希函数生成对应的k个索引值,并检查位数组中的这些位置是否都为1.如果都为1,则表示该元素可能存在;如果有任何一位为0,则可以确定该元素不存在。
布隆过滤器的误判问题
通过hash计算在数组上不一定在集合
本质是hash冲突
通过hash计算不在数组的一定不在集合(误判)
优化方案
增大数组(预估适合值)
增加hash函数
优缺点
<本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Redis自学之路—高级数据结构具体方法解析(六)

发表评论 取消回复