此内容是论文总结,重点看思路!!
文章概述
本文提出了一种快速从文本生成3D资产的新方法,通过结合3D高斯点表示、3D扩散模型和2D扩散模型的优势,实现了高效生成。该方法利用3D扩散模型生成初始几何,通过噪声点扩展和颜色扰动丰富细节,并使用2D扩散模型优化生成质量。相比现有方法,它不仅生成速度快(单GPU训练仅需15分钟),且生成资产具有更高的几何一致性和细节质量,同时支持实时渲染,为文本生成3D技术提供了更高效的解决方案。

方法特点与创新
-
结合2D和3D扩散模型:通过3D扩散模型提供几何一致性,2D扩散模型提升细节质量。
-
高效表示:采用3D高斯点表示,具有简单结构和快速渲染能力。
-
高效优化:通过SDS损失实现快速收敛,仅需少量训练时间即可生成高质量的3D资产。
-
增强步骤:引入噪声点扩展和颜色扰动,显著提升初始点云的细节。
主要方法
GaussianDreamer通过结合3D扩散模型和2D扩散模型的优势,利用3D高斯点表示实现从文本到3D的高效生成。具体方法包括两个阶段:初始化和优化。
1. 初始化(Initialization with 3D Diffusion Model Priors)
初始化阶段的目标是生成初始的3D高斯点云,作为后续优化的基础。其过程如下:
1.1 使用3D扩散模型生成粗略几何
-
根据输入文本提示,使用3D扩散模型(如Shap-E或Point-E)生成粗糙的3D资产。
-
Shap-E:基于隐式表示(如SDF)生成纹理化的三角网格。
-
Point-E:直接生成稀疏点云。
-
将生成的3D资产(如三角网格)转换为点云,包括每个点的位置和颜色。
1.2 噪声点扩展(Noisy Point Growing)
-
目的:增强点云密度以捕捉更多细节。
-
过程:
-
计算原始点云的包围盒。
-
在包围盒中随机生成额外的点云。
-
使用KDTree算法筛选与原始点云位置相近的点。
-
合并新生成的点与原始点云。
1.3 颜色扰动(Color Perturbation)
-
目的:增强点云的视觉表现力。
-
过程:对新增点的颜色进行扰动,使其颜色接近原始点,并随机加入轻微变化。
1.4 初始化3D高斯点(3D Gaussian Initialization)
-
根据增强后的点云初始化3D高斯点:
-
位置(μ):直接取点云位置。
-
颜色(c):取点云颜色。
-
透明度(α):统一初始化为0.1。
-
协方差(Σ):计算最近两点之间的距离以设置协方差。
2. 优化(Optimization with the 2D Diffusion Model)
优化阶段旨在通过2D扩散模型进一步优化3D高斯点的几何细节和外观质量。其过程如下:
2.1 渲染图像
-
利用3D高斯点的渲染方法(3D Gaussian Splatting)将点云渲染为2D图像。
-
渲染方法通过光线投射累积高斯点的颜色和透明度,生成每个像素的颜色。
2.2 使用SDS损失优化
-
SDS(Score Distillation Sampling)损失:
-
利用预训练的2D扩散模型,计算渲染图像与扩散模型生成的目标图像之间的噪声差异。
-
根据差异计算梯度,优化高斯点的参数(位置、颜色、协方差和透明度)。
-
更新过程:
-
每次迭代使用2D扩散模型生成目标图像,并通过SDS损失更新3D高斯点。
3. 渲染与实时性能
-
优化后的3D高斯点无需转换为网格结构,直接通过高斯点渲染实现实时可视化。
-
生成过程在单块GPU上仅需15分钟,显著提升了效率。
GaussianDreamer 框架的整体流程
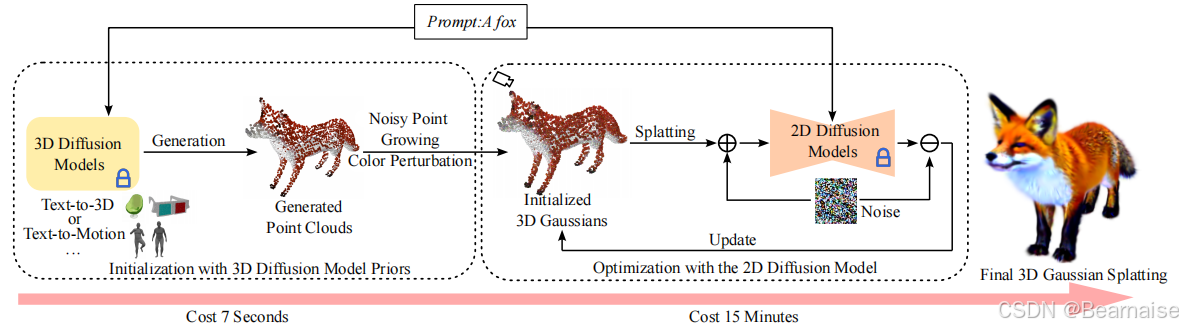
1. 初始化阶段(Initialization with 3D Diffusion Model Priors)
1.1 文本到3D点云生成
-
输入:文本提示(如 "A fox")。
-
模型:
-
使用 3D 扩散模型(例如 Text-to-3D 或 Text-to-Motion 模型)。
-
根据文本生成初始点云,点云包含点的位置和颜色信息。
1.2 噪声点扩展与颜色扰动
-
目标:提高点云的几何细节和视觉表现。
-
方法:
-
噪声点扩展:在点云包围盒中生成额外的点,增加密度。
-
颜色扰动:对新点的颜色进行随机扰动,增强视觉细节。
1.3 3D高斯点初始化
-
将增强后的点云转换为 3D 高斯点:
-
位置:使用点云位置。
-
颜色:使用扰动后的颜色。
-
透明度和协方差:根据点云分布进行初始化。
2. 优化阶段(Optimization with the 2D Diffusion Model)
2.1 渲染2D图像
- 使用 3D 高斯点通过 3D Gaussian Splatting 渲染2D图像。
2.2 优化3D高斯点
-
利用 2D扩散模型 提高生成的细节和一致性。
-
具体方法:
-
SDS损失(Score Distillation Sampling):
-
比较渲染图像与扩散模型生成图像的噪声差异。
-
根据差异计算梯度,优化 3D 高斯点的参数(如位置、颜色、透明度等)。
-
3. 结果渲染(Final 3D Gaussian Splatting)
-
输出:经过优化的 3D 高斯点直接渲染为高质量3D结果(如狐狸的逼真3D模型)。
-
时间成本:
-
7秒:生成初始点云。
-
15分钟:完成所有优化,生成最终的高质量3D模型。
噪声点扩展(Noisy Point Growing)和颜色扰动(Color Perturbation) 的过程
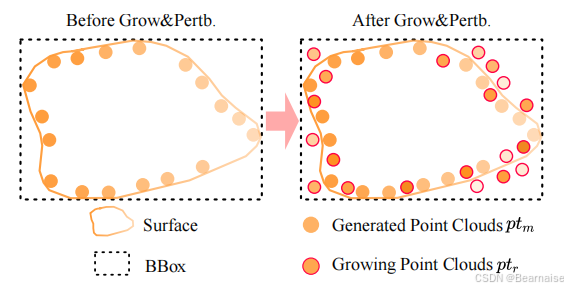
图中关键内容
- 左侧(Before Grow&Pertb.)
-
初始生成的点云(Generated Point Clouds pm)用橙色圆点表示。
-
点云分布稀疏,难以捕捉精细的几何和表面特征。
-
黑色虚线框表示点云的包围盒(BBox),其大小由点云的边界决定。
- 右侧(After Grow&Pertb.)
-
添加了新的点云(Growing Point Clouds pr),用红色圆点表示。
-
新增点云均匀分布在包围盒内部,增强了点云密度。
-
这些新增点的颜色经过扰动,变得更加多样化,提升了视觉效果。
Grow&Pertb. 过程
- 噪声点扩展(Noisy Point Growing)
-
目标:在点云稀疏区域生成更多点,提高几何细节。
-
方法:
-
在包围盒(BBox)内随机采样点。
-
通过 KDTree 筛选与原始点云距离较近的点,仅保留这些点以保持几何一致性。
-
- 颜色扰动(Color Perturbation)
-
目标:增强新增点的视觉表现,使其颜色接近原始点云但带有随机变化。
-
方法:
- 对新增点赋予接近于邻近原始点颜色的值,并加入随机扰动(如随机加减一定范围的值)。
GaussianDreamer 与其他方法(DreamFusion、Magic3D、Fantasia3D 和 ProlificDreamer)在文本到3D生成任务上的定性对比(Qualitative Comparisons)
1. 方法和时间比较
每种方法的名称和训练时间列在顶部:
-
DreamFusion:6小时(在 TPUv4 上测量)。
-
Magic3D:5.3小时(在 A100 上测量)。
-
Fantasia3D:6小时(在 RTX 3090 上测量)。
-
ProlificDreamer:数小时(具体时间未标注,但显著更慢)。
-
GaussianDreamer(Ours):15分钟(在 RTX 3090 上测量)。
结论:GaussianDreamer 的训练时间明显少于其他方法,仅需15分钟完成训练。
2. 文本提示及生成结果对比
每行展示了一组示例的文本提示和对应生成结果:
示例 1:一盘堆满巧克力饼干的盘子
-
DreamFusion、Magic3D 和 Fantasia3D:
-
生成结果未完整表现“盘子”的部分,巧克力饼干直接浮于空中或不在盘子上。
-
细节丰富度一般。
-
ProlificDreamer:
-
饼干与盘子表现较好,但颜色和细节较其他方法更加突出。
-
训练时间极长。
-
GaussianDreamer:
-
生成的饼干和盘子细节丰富,盘子纹理清晰且造型真实。
-
效果优于 DreamFusion 和 Magic3D,接近 ProlificDreamer,但训练时间显著减少。
示例 2:带茅草屋顶的可爱乡村小屋
-
DreamFusion:
-
小屋结构简单,颜色平淡,茅草屋顶缺乏细节。
-
Magic3D 和 Fantasia3D:
-
小屋屋顶的茅草纹理略显模糊,未充分体现细节。
-
ProlificDreamer:
-
小屋整体更逼真,细节表现良好,但时间成本较高。
-
GaussianDreamer:
-
生成的小屋结构完整,屋顶茅草纹理清晰,整体视觉表现最为丰富,同时训练时间远低于 ProlificDreamer。
3. 总结
-
效率:GaussianDreamer 训练时间仅为15分钟,比其他方法显著更快。
-
效果:
-
与 DreamFusion、Magic3D 和 Fantasia3D 相比,GaussianDreamer 的生成细节更丰富,物体更符合文本提示。
-
与 ProlificDreamer 相比,GaussianDreamer 在生成质量上接近或略有优势,但训练速度快了数倍。
-
适用性:GaussianDreamer 的高效率和高质量表现使其更适合时间有限的实际应用场景。
GaussianDreamer 生成的多个样本

这张图通过展示多个生成样本,证明了 GaussianDreamer 的以下能力:
-
生成质量高:结果具有丰富的细节和准确的几何结构。
-
风格灵活:能够根据文本提示生成写实或风格化的3D模型。
-
几何一致性强:不同视角下的模型保持一致性。
GaussianDreamer 与其他方法(DreamFusion、DreamAvatar、DreamWaltz 和 AvatarVerse)在生成特定角色模型(如蜘蛛侠和星战风暴兵)上的定性对比
这张图通过展示蜘蛛侠和风暴兵的生成结果,证明了 GaussianDreamer 的以下优势:
-
高效率:在大幅减少训练时间的情况下,生成质量不输甚至优于耗时更长的方法。
-
高质量生成:在几何一致性、细节表现和多视角准确性上表现出色。
-
应用潜力:其快速生成的能力和高质量模型非常适合角色建模等实际应用场景。
GaussianDreamer 在不同动作姿势下生成3D角色的效果
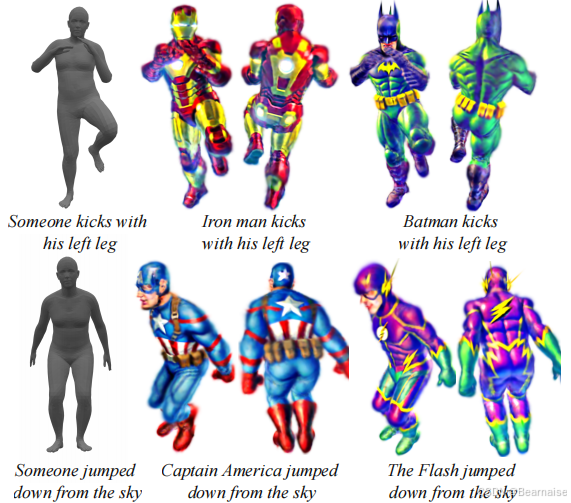
总结
-
关键能力:
-
GaussianDreamer 能够结合 SMPL 提供的动作初始化,生成具有指定动作的高质量角色。
-
模型不仅能够生成符合文本提示的动作,还能细化角色的外观和服装细节。
-
潜在应用:
-
角色建模、游戏动画和动态虚拟角色的快速生成。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » GaussianDreamer: Fast Generation from Text to 3D Gaussians——点云论文阅读(11)

发表评论 取消回复