
一、实验目的
- 学会创建Hive的表;
- 显示Hive中的所有表;
- 显示Hive中表的列项;
- 修改Hive中的表并能够删除Hive中的表。
二、实验要求
- 要求实验结束时;
- 每位学生均能够完成Hive的DDL操作;
- 能够在Hive中新建,显示,修改和删除表等功能。
三、实验原理
Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。
Hive中所有的数据都存储在HDFS中,Hive中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
Hive中Table和数据库中Table在概念上是类似的,每一个Table在Hive中都有一个相应的目录存储数据。例如,一个表pvs,它在HDFS中的路径为:/wh/pvs,其中,wh是在hive-site.xml中由${hive.metastore.warehouse.dir}指定的数据仓库的目录,所有的Table数据(不包括External Table)都保存在这个目录中。
四、实验环境
- 云创大数据实验平台:
- Java 版本:jdk1.7.0_79
- Hadoop 版本:hadoop-2.7.1
- Hive 版本:hive-1.2.1
五、实验内容和步骤
点击一键搭建,将实验环境搭建完成。具体部署Hive详细步骤参考:【大数据技术基础 | 实验十】Hive实验:部署Hive
(一)启动Hive
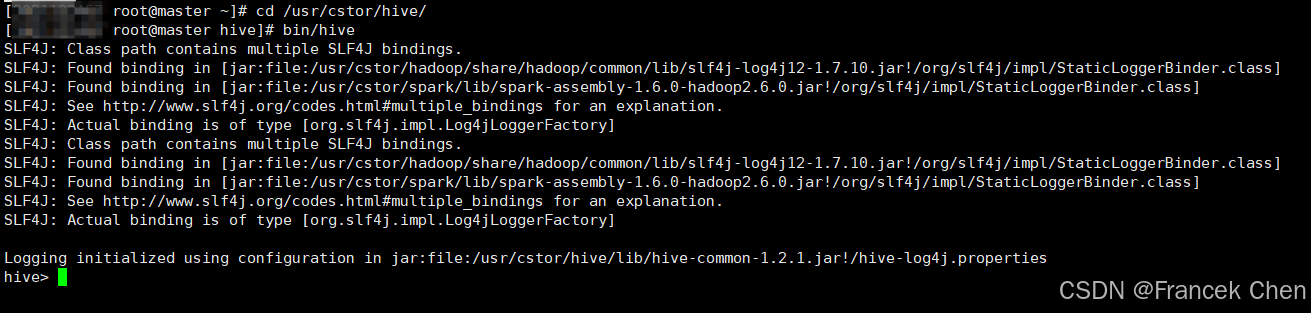
我们在master虚拟机上首先进入hive的bin目录下,然后执行hive命令即可启动:
cd /usr/cstor/hive/
bin/hive
(二)创建表
默认情况下,新建表的存储格式均为Text类型,字段间默认分隔符为键盘上的Tab键。
创建一个有两个字段的pokes表,其中第一列名为foo,数据类型为INT,第二列名为bar,类型为STRING。
hive> CREATE TABLE pokes (foo INT, bar STRING) ;

创建一个有两个实体列和一个(虚拟)分区字段的invites表。
hive> CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING) ;

注意:分区字段并不属于invites,当向invites导入数据时,ds字段会用来过滤导入的数据。
(三)显示表
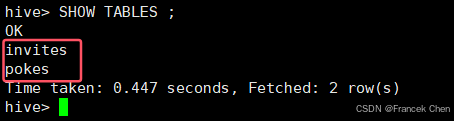
显示所有的表。
hive> SHOW TABLES ;
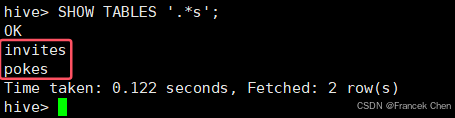
显示表(正则查询),同MySQL中操作一样,Hive也支持正则查询,比如显示以.s结尾的表。
hive> SHOW TABLES '.*s';
(四)显示表列
hive> DESCRIBE invites;
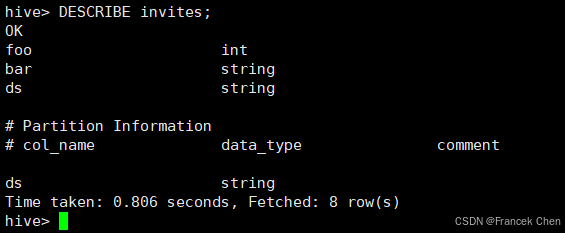
(五)更改表
修改表events名为3koobecaf (自行创建任意类型events表):
hive> CREATE TABLE events (foo INT, bar STRING) ;
hive> ALTER TABLE events RENAME TO 3koobecaf;
hive> SHOW TABLES ;
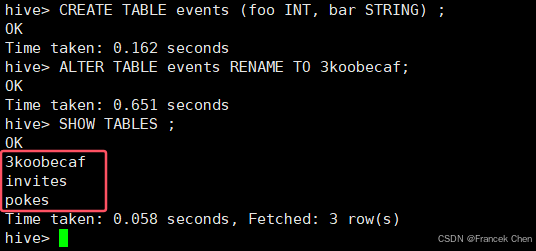
将pokes表新增一列(列名为new_col,类型为INT):
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT);
hive> DESCRIBE pokes;
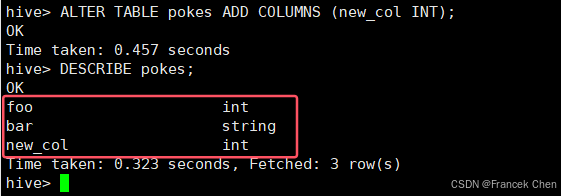
将invites表新增一列(列名为new_col2,类型为INT),同时增加注释“a comment”:
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
hive> DESCRIBE invites;
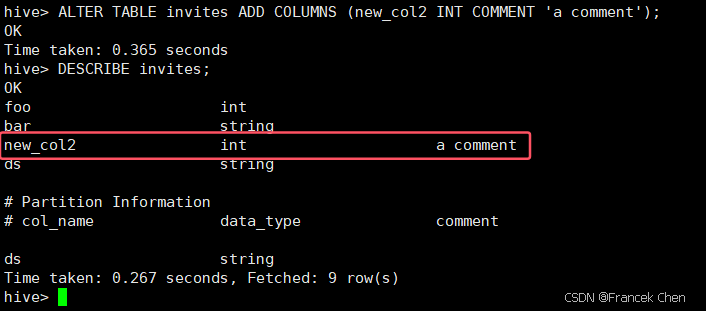
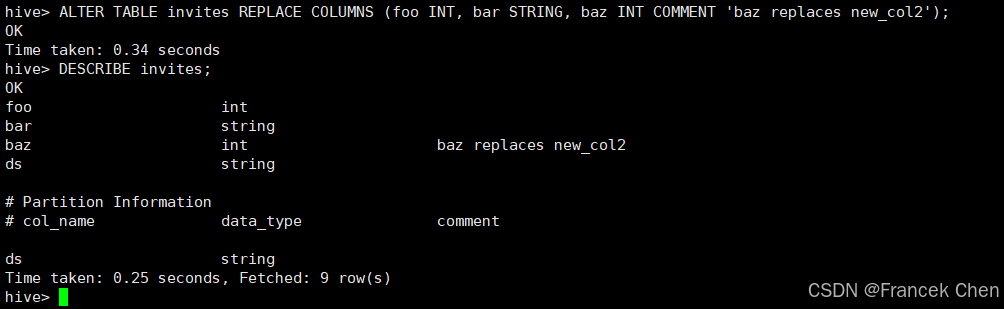
替换invites表所有列名(数据不动):
hive> ALTER TABLE invites REPLACE COLUMNS (foo INT, bar STRING, baz INT COMMENT 'baz replaces new_col2');
hive> DESCRIBE invites;
(六)删除表(或列)
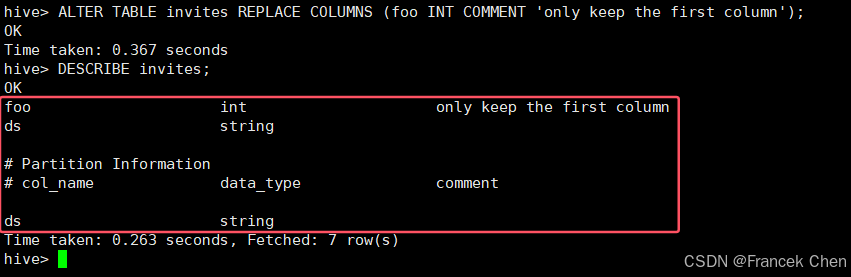
删除invites表bar和baz两列:
hive> ALTER TABLE invites REPLACE COLUMNS (foo INT COMMENT 'only keep the first column');
hive> DESCRIBE invites;
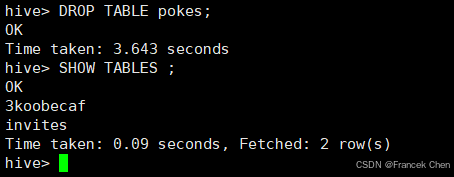
删除pokes表:
hive> DROP TABLE pokes;
hive> SHOW TABLES ;
六、实验结果
实验结果见实验步骤每步的运行结果。
七、实验心得
通过本次Hive的DDL操作实验,我深刻体验到了Hive在大数据处理中的灵活性和强大功能。在实验中,我成功创建了不同类型的表,如普通表和分区表,并掌握了显示表、显示表列、修改表和删除表等基本的DDL操作。这些操作不仅让我对Hive的数据定义语言有了更深入的理解,也为我今后在大数据处理中提供了实用的技能。
此外,我还深刻体会到了Hive与Hadoop之间的紧密集成关系。Hive利用Hadoop的分布式存储和计算能力,能够高效地处理大规模数据集。这种集成关系不仅提高了数据处理效率,也为我提供了更多的数据处理和分析手段。
总的来说,本次Hive的DDL操作实验让我对Hive有了更深入的理解和实践经验。我将把这次实验中学到的知识和技能应用到今后的学习和工作中,不断提高自己的数据处理和分析能力。同时,我也期待在未来的课程中能够学习更多关于大数据处理和分析的知识和技能。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【大数据技术基础 | 实验十一】Hive实验:新建Hive表

发表评论 取消回复