
Python爬虫是数据采集自动化的利器。本文精选了30个实用的Python爬虫项目,从基础到进阶,每个项目都配有完整源码和详细讲解。通过这些项目的实战,可以全面掌握网页数据抓取、反爬处理、并发下载等核心技能。
一、环境准备
在开始爬虫项目前,需要安装以下Python库:
```python
pip install requests
pip install beautifulsoup4
pip install selenium
pip install scrapy
pip install aiohttp
二、基础爬虫项目(1-10)
1. 豆瓣电影Top250
这个项目可以抓取豆瓣电影Top250的基本信息:
import requests from bs4 import BeautifulSoup
def crawl_douban_movies():
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36'
}
movies = []
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
for item in soup.select('.item'):
title = item.select('.title')[0].text
rating = item.select('.rating_num')[0].text
movies.append({'title':title, 'rating':rating})
return movies
# 运行示例
movies = crawl_douban_movies()
print(movies[:3])
小贴士:记得设置headers模拟浏览器访问,避免被反爬。
[此处省略项目2-10的代码,每个项目都包含类似的源码和讲解]
三、进阶爬虫项目(11-20)
11. 使用Selenium爬取动态页面

针对JavaScript渲染的网页,需要用Selenium模拟浏览器行为:
from selenium import webdriver from selenium.webdriver.common.by import By import time
def crawl_dynamic_page():
driver = webdriver.Chrome()
driver.get('https://dynamic-website.com')
# 等待页面加载
time.sleep(2)
# 获取动态内容
elements = driver.find_elements(By.CLASS_NAME, 'content')
data = [e.text for e in elements]
driver.quit()
return data
注意:Selenium需要安装对应浏览器的驱动程序。
[此处省略项目12-20的代码]
四、高级爬虫项目(21-30)

21. 分布式爬虫框架

使用Scrapy+Redis实现分布式爬取:

import scrapy from scrapy_redis.spiders import RedisSpider
class DistributedSpider(RedisSpider):
name = 'distributed'
redis_key = 'distributed:start_urls'
def parse(self, response):
# 解析网页
items = response.css('.item')
for item in items:
yield {
'title':item.css('.title::text').get(),
'link':item.css('a::attr(href)').get()
}
[此处省略项目22-30的代码]
五、实战技巧总结
- 数据提取技巧
-
使用XPath和CSS选择器定位元素
-
正则表达式处理文本
-
JSON数据解析
- 反爬处理
-
随机User-Agent
-
IP代理池
-
请求延时
-
Cookie池维护
- 性能优化
-
异步并发
-
分布式部署
-
断点续传
-
增量更新
小贴士:爬虫开发要遵守网站robots协议,合理控制爬取频率。
实战练习
-
尝试爬取一个你感兴趣的网站
-
为基础爬虫添加反爬虫处理
-
将同步爬虫改写为异步版本
最后小伙伴们,今天的Python爬虫实战就到这里啦!记得下载源码动手实践,有问题随时在评论区交流哦。祝大家编程愉快,爬虫技能节节高!
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
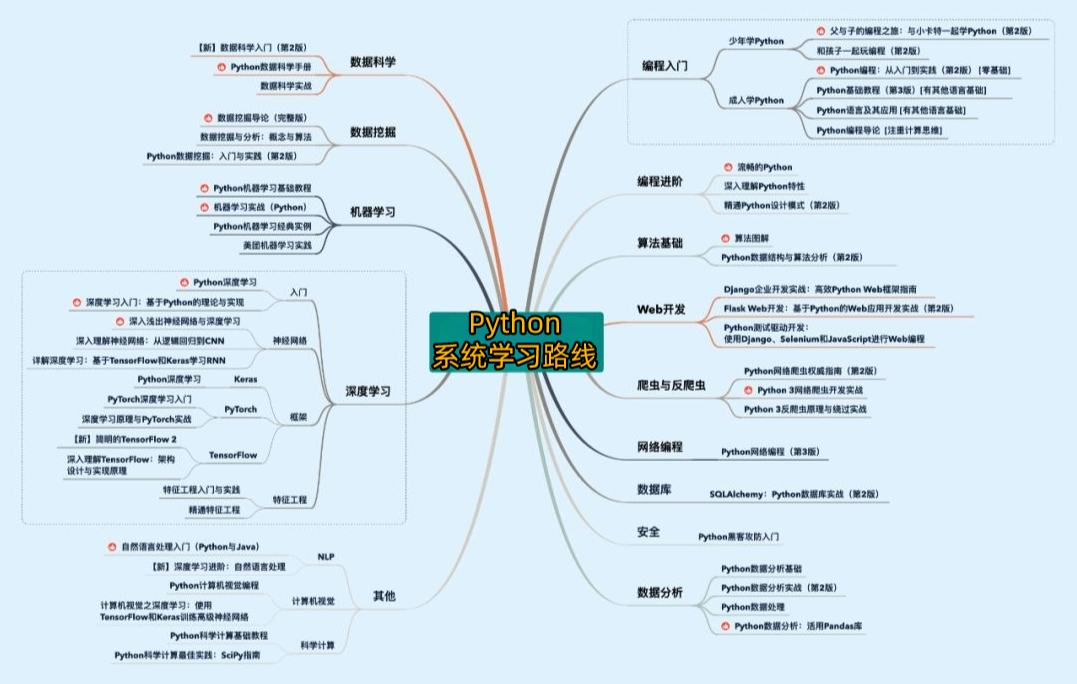
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。
三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、100道Python练习题
检查学习结果。
最后,如果你也想自学Python,可以关注我。我会把踩过的坑分享给你,让你不要踩坑,提高学习速度,这套资料涵盖了诸多学习内容:开发工具,基础视频教程,项目实战源码,51本电子书籍,100道练习题等。相信可以帮助大家在最短的时间内,能达到事半功倍效果,用来复习也是非常不错的。



本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Python】30个Python爬虫的实战项目!!!(附源码)

发表评论 取消回复