1、AlexNet
1.1 基本介绍
AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年ImageNet大规模视觉识别挑战赛(ILSVRC)中提出的,它不仅赢得了当届的比赛,还激发了后续许多创新的神经网络架构(如VGGNet、ResNet、GoogLeNet等)的开发
1.2 网络结构
AlexNet网络结构包括以下几个关键层:
- 卷积层(Convolutional Layer):使用多个卷积核提取图像特征
- 池化层(Pooling Layer):通常使用最大池化(Max Pooling)或平均池化(Average Pooling)来降低特征图的空间维度
- 全连接层(Fully Connected Layer):将特征展平铺并连接到输出层进行分类
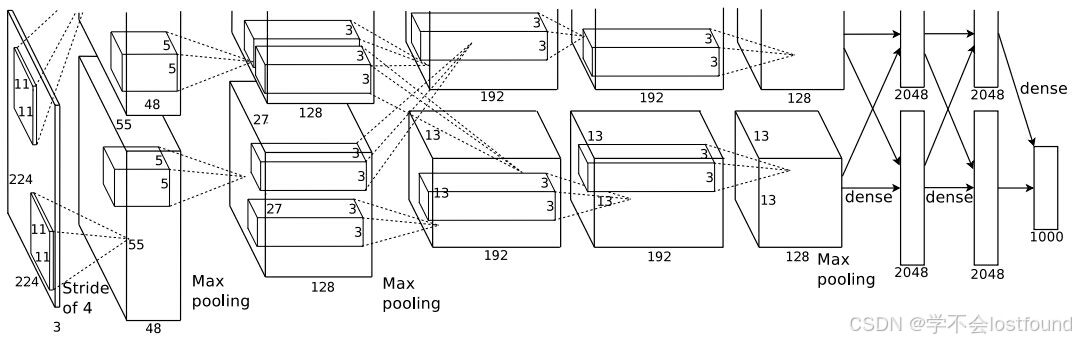
AlexNet的具体网络结构如下:
-
输入层:224x224像素的RGB三通道彩色图像
-
第一层卷积:使用96个11x11的卷积核,步长为4,边缘填充数为2,输出96x55x55的特征图【(224 + 2*2 - 11) / 4 + 1 = 55】(备注:由于是两个GPU一起跑,所以图中显示的是两个48x55x55)
-
第一层池化:3x3的最大池化,步长为2,边缘填充数为0,输出48x27x27的特征图【(55 + 2*0 - 3) / 2 + 1 = 27】(备注:同上,是两个48x27x27)
-
第二层卷积:使用256个5x5的卷积核,步长为1,边缘填充数为2,输出128x27x27的特征图【(27 + 2*2 - 5) / 1 + 1 = 27】(备注:同上,是两个128x27x27)
-
第二层池化:3x3的最大池化,步长为2,边缘填充数为0,输出128x13x13的特征图【(27 + 2*0 - 3) / 2 + 1 = 13】(备注:同上,是两个128x13x13)
-
第三层卷积:使用384个3x3的卷积核,步长为1,边缘填充数为1,输出192x13x13的特征图【(13 + 2*1 - 3) / 1 + 1 = 13】(备注:同上,是两个192x13x13)
-
第四层卷积:使用384个3x3的卷积核,步长为1,边缘填充数为1,输出192x13x13的特征图【(13 + 2*1 - 3) / 1 + 1 = 13】(备注:同上,是两个192x13x13)
-
第五层卷积:使用256个3x3的卷积核,步长为1,边缘填充数为1,输出128x13x13的特征图【(13 + 2*1 - 3) / 1 + 1 = 13】(备注:同上,是两个128x13x13)
-
第五层池化:3x3的最大池化,步长为2,边缘填充数为0,输出128x6x6的特征图【(13 + 2*0 - 3) / 2 + 1 = 6】(备注:同上,是两个128x6x6)
-
第一全连接层:将两个128x6x6的特征图展平,连接到两个2048维向量
-
第二全连接层:两个2048维全连接到两个2048维向量(每个全连接层都可以看作是在进行特征组合,即使神经元的数量相同,第二个全连接层的每个神经元也都会是前一个全连接层所有神经元的加权和,这样的设计允许网络在更高层次上组合和抽象特征)
-
第三全连接层:两个2048维全连接到1000维,代表1000个类别
1.3 创新点
- ReLU激活函数:AlexNet是第一个在每一层卷积层之后使用ReLU激活函数的网络,与sigmoid激活函数不同,ReLU不会导致梯度消失问题,并且能加快训练速度
- Dropout正则化:为了减少过拟合,AlexNet在全连接层之间引入了Dropout技术,随机丢弃一部分神经元,以减少神经元之间的依赖关系
- 数据增强和多GPU训练:为了提高模型的鲁棒性和泛化能力,AlexNet使用了数据增强技术,并使用了两个GPU进行并行计算以加速训练
1.4 网络搭建
# 引入pytorch和nn神经网络
import torch
import torch.nn as nn
class AlexNet(nn.Module):
"""
自定义一个AlexNet神经网络
"""
def __init__(self, in_channels=3, n_classes=1000):
"""
初始化
"""
super().__init__()
# 1. 特征抽取
self.feature_extractor = nn.Sequential(
# 第一层卷积
nn.Conv2d(
in_channels=in_channels,
out_channels=96,
kernel_size=11,
stride=4,
padding=2
),
nn.ReLU(inplace=True),
# 第一层池化
nn.MaxPool2d(
kernel_size=3,
stride=2,
padding=0
),
# 第二层卷积
nn.Conv2d(
in_channels=96,
out_channels=256,
kernel_size=5,
stride=1,
padding=2
),
nn.ReLU(inplace=True),
# 第二层池化
nn.MaxPool2d(
kernel_size=3,
stride=2,
padding=0
),
# 第三层卷积
nn.Conv2d(
in_channels=256,
out_channels=384,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 第四层卷积
nn.Conv2d(
in_channels=384,
out_channels=384,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 第五层卷积
nn.Conv2d(
in_channels=384,
out_channels=256,
kernel_size=3,
stride=1,
padding=1
),
# 第五层池化
nn.MaxPool2d(
kernel_size=3,
stride=2,
padding=0
)
)
# 2. 分类输出
self.classifier = nn.Sequential(
nn.Flatten(start_dim=1, end_dim=-1),
nn.Linear(in_features=256, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=n_classes)
)
def forward(self, x):
"""
前向传播
"""
# 1. 先做特征抽取
x = self.feature_extractor(x)
# 2. 再做分类回归
x = self.classifier(x)
return x2、VggNet
2.1 基本介绍
VggNet是由牛津大学的视觉几何组(Visual Geometry Group)在2014年ImageNet大规模视觉识别挑战赛(ILSVRC)中提出的,在当届比赛中取得了第二名的成绩
2.2 网络结构
VggNet网络结构同样包括以下几个关键层:
- 卷积层(Convolutional Layer):使用多个卷积核提取图像特征
- 池化层(Pooling Layer):通常使用最大池化(Max Pooling)或平均池化(Average Pooling)来降低特征图的空间维度
- 全连接层(Fully Connected Layer):将特征展平铺并连接到输出层进行分类
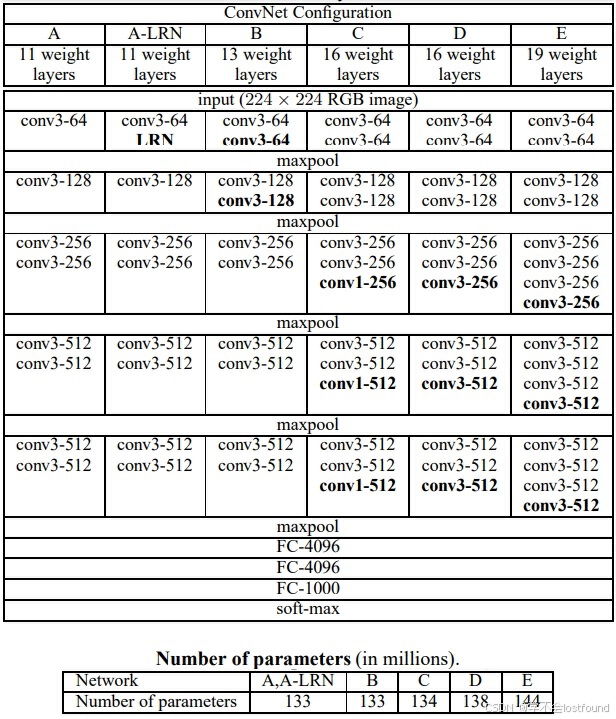
以Vgg16(即:图中D列所对应的网络)为例,具体网络结构如下:

-
输入层:224x224像素的RGB三通道彩色图像
-
卷积层C1:使用64个3x3的卷积核,步长为1,边缘填充数为1,输出64x224x224的特征图【(224 + 2*1 - 3) / 1 + 1 = 224】
-
卷积层C2:使用64个3x3的卷积核,步长为1,边缘填充数为1,输出64x224x224的特征图【(224 + 2*1 - 3) / 1 + 1 = 224】
-
池化层S1:2x2的最大池化,步长为2,边缘填充数为0,输出64x112x112的特征图【(224 + 2*0 - 2) / 2 + 1 = 112】
-
卷积层C3:使用128个3x3的卷积核,步长为1,边缘填充数为1,输出128x112x112的特征图【(112 + 2*1 - 3) / 1 + 1 = 112】
-
卷积层C4:使用128个3x3的卷积核,步长为1,边缘填充数为1,输出128x112x112的特征图【(112 + 2*1 - 3) / 1 + 1 = 112】
-
池化层S2:2x2的最大池化,步长为2,边缘填充数为0,输出128x56x56的特征图【(112 + 2*0 - 2) / 2 + 1 = 56】
-
卷积层C5:使用256个3x3的卷积核,步长为1,边缘填充数为1,输出256x56x56的特征图【(56 + 2*1 - 3) / 1 + 1 = 56】
-
卷积层C6:使用256个3x3的卷积核,步长为1,边缘填充数为1,输出256x56x56的特征图【(56 + 2*1 - 3) / 1 + 1 = 56】
-
卷积层C7:使用256个3x3的卷积核,步长为1,边缘填充数为1,输出256x56x56的特征图【(56 + 2*1 - 3) / 1 + 1 = 56】
-
池化层S3:2x2的最大池化,步长为2,边缘填充数为0,输出256x28x28的特征图【(56 + 2*0 - 2) / 2 + 1 = 28】
-
卷积层C8:使用512个3x3的卷积核,步长为1,边缘填充数为1,输出512x28x28的特征图【(28 + 2*1 - 3) / 1 + 1 = 28】
-
卷积层C9:使用512个3x3的卷积核,步长为1,边缘填充数为1,输出512x28x28的特征图【(28 + 2*1 - 3) / 1 + 1 = 28】
-
卷积层C10:使用512个3x3的卷积核,步长为1,边缘填充数为1,输出512x28x28的特征图【(28 + 2*1 - 3) / 1 + 1 = 28】
-
池化层S4:2x2的最大池化,步长为2,边缘填充数为0,输出512x14x14的特征图【(28 + 2*0 - 2) / 2 + 1 = 14】
-
卷积层C11:使用512个3x3的卷积核,步长为1,边缘填充数为1,输出512x14x14的特征图【(14 + 2*1 - 3) / 1 + 1 = 14】
-
卷积层C12:使用512个3x3的卷积核,步长为1,边缘填充数为1,输出512x14x14的特征图【(14 + 2*1 - 3) / 1 + 1 = 14】
-
卷积层C13:使用512个3x3的卷积核,步长为1,边缘填充数为1,输出512x14x14的特征图【(14 + 2*1 - 3) / 1 + 1 = 14】
-
池化层S5:2x2的最大池化,步长为2,边缘填充数为0,输出512x7x7的特征图【(14 + 2*0 - 2) / 2 + 1 = 7】
-
全连接层F14:将512x7x7的特征图展平,连接到4096维向量
-
全连接层F15:4096维全连接到4096维向量(每个全连接层都可以看作是在进行特征组合,即使神经元的数量相同,第二个全连接层的每个神经元也都会是前一个全连接层所有神经元的加权和,这样的设计允许网络在更高层次上组合和抽象特征)
-
全连接层F16:4096维全连接到1000维,代表1000个类别
2.3 创新点
-
小尺寸卷积核:VGGNet使用了较小的3x3的卷积核和较小的步幅来进行卷积操作,这样可以增加网络的深度而不增加参数数量
-
重复卷积层:VGGNet引入了多次重复使用相同配置的卷积层,这种方法简化了网络结构的设计,同时提高了特征的非线性表达能力
2.4 网络搭建
# 引入pytorch和nn神经网络
import torch
import torch.nn as nn
class Vgg16(nn.Module):
"""
自定义一个Vgg16神经网络
"""
def __init__(self, in_channels=3, n_classes=1000):
"""
初始化
"""
super().__init__()
# 1. 特征抽取
self.feature_extractor = nn.Sequential(
# 卷积层C1
nn.Conv2d(
in_channels=in_channels,
out_channels=64,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 卷积层C2
nn.Conv2d(
in_channels=64,
out_channels=64,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 池化层S1
nn.MaxPool2d(
kernel_size=2,
stride=2,
padding=0
),
# 卷积层C3
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 卷积层C4
nn.Conv2d(
in_channels=128,
out_channels=128,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 池化层S2
nn.MaxPool2d(
kernel_size=2,
stride=2,
padding=0
),
# 卷积层C5
nn.Conv2d(
in_channels=128,
out_channels=256,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 卷积层C6
nn.Conv2d(
in_channels=256,
out_channels=256,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 卷积层C7
nn.Conv2d(
in_channels=256,
out_channels=256,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 池化层S3
nn.MaxPool2d(
kernel_size=2,
stride=2,
padding=0
),
# 卷积层C8
nn.Conv2d(
in_channels=256,
out_channels=512,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 卷积层C9
nn.Conv2d(
in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 卷积层C10
nn.Conv2d(
in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 池化层S4
nn.MaxPool2d(
kernel_size=2,
stride=2,
padding=0
),
# 卷积层C11
nn.Conv2d(
in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 卷积层C12
nn.Conv2d(
in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 卷积层C13
nn.Conv2d(
in_channels=512,
out_channels=512,
kernel_size=3,
stride=1,
padding=1
),
nn.ReLU(inplace=True),
# 池化层S5
nn.MaxPool2d(
kernel_size=2,
stride=2,
padding=0
)
)
# 2. 分类输出
self.classifier = nn.Sequential(
nn.Flatten(start_dim=1, end_dim=-1),
nn.Linear(in_features=512, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Linear(in_features=4096, out_features=n_classes)
)
def forward(self, x):
"""
前向传播
"""
# 1. 先做特征抽取
x = self.feature_extractor(x)
# 2. 再做分类回归
x = self.classifier(x)
return x3、ResNet
3.1 基本介绍

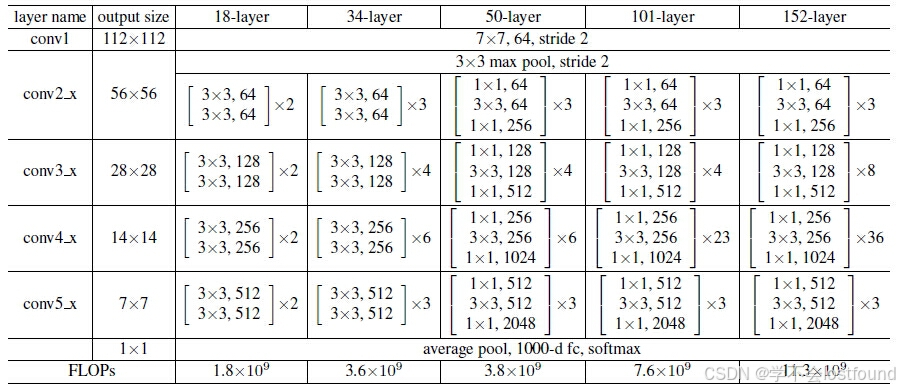
ResNet(残差网络)是由微软研究院的Kaiming He等人在2015年提出的,它在当年的ImageNet大规模视觉识别挑战赛(ILSVRC)中获得了冠军
3.2 网络结构
ResNet网络结构同样包括以下几个关键层:
- 卷积层(Convolutional Layer):使用多个卷积核提取图像特征
- 池化层(Pooling Layer):通常使用最大池化(Max Pooling)或平均池化(Average Pooling)来降低特征图的空间维度
- 全连接层(Fully Connected Layer):将特征展平铺并连接到输出层进行分类
在ResNet网络结构中,最重要的就是残差结构,残差结构可分为虚线和实线这两种类型
以ResNet-34的conv3_x中的残差矩阵为例,其虚线和实线的残差结构图分别如下
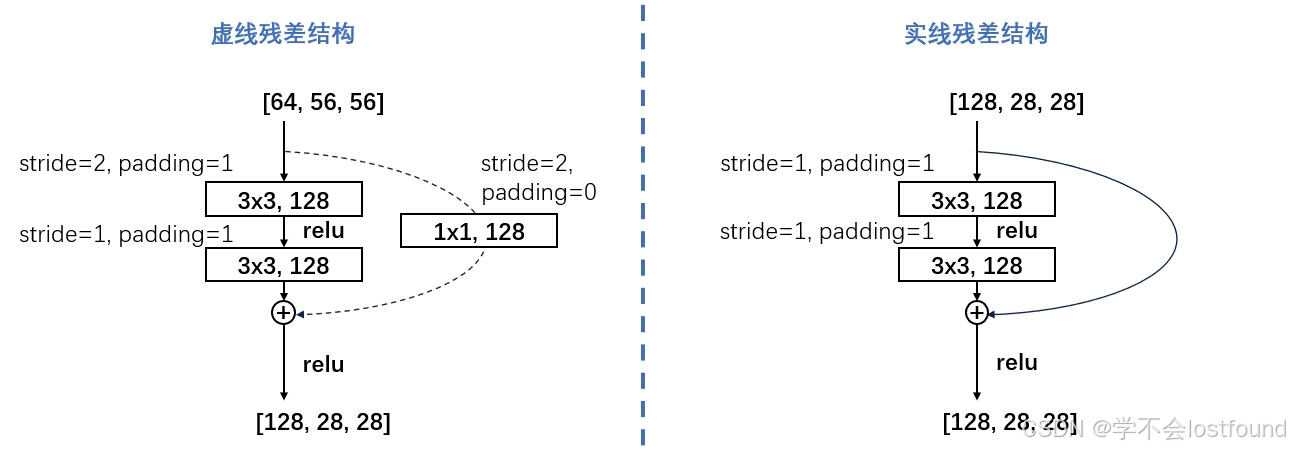
3.3 创新点
- ResNet的核心思想是残差学习,将y=F(X)调整为y=F(X)+X,这样一来,网络的目标变为学习输入和输出之间的差异,而不是直接学习映射关系,通过残差学习,可以训练非常深的网络(例如1000层)
- ResNet在每个卷积层后都使用了批量归一化(丢弃dropout),这有助于加速训练过程并提高模型的稳定性
3.4 网络搭建
3.4.1 虚线残差结构
# 引入pytorch和nn神经网络
import torch
from torch import nn
class ConvBlock(nn.Module):
"""
ResNet-34中conv3_x的虚线残差结构
实现逻辑:y = F(x) + Conv(x)
"""
def __init__(self, in_channels=64, out_channels=128):
"""
初始化
"""
super().__init__()
# 1、主线路
self.stage = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=128,
kernel_size=3,
stride=2,
padding=1,
bias=False
),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(
in_channels=128,
out_channels=out_channels,
kernel_size=3,
padding=1,
stride=1,
bias=False
),
nn.BatchNorm2d(num_features=out_channels)
)
# 2、短路层
self.shortcut = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=2,
padding=0,
bias=False
),
nn.BatchNorm2d(num_features=out_channels)
)
# 3、主线路与短路层相加后的ReLU
self.relu = nn.ReLU()
def forward(self, x):
# 1、主线路处理
f = self.stage(x)
# 2、短路层处理
s = self.shortcut(x)
# 3、两部分相加
h = f + s
# 4、输出
o = self.relu(h)
return o3.4.2 实线残差结构
# 引入pytorch和nn神经网络
import torch
from torch import nn
class IdentityBlock(nn.Module):
"""
ResNet-34中conv3_x的实线残差结构
实现逻辑:y = F(x) + x
"""
def __init__(self, in_channels=64, out_channels=128):
"""
初始化
"""
super().__init__()
# 1、主线路
self.stage = nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=128,
kernel_size=3,
stride=2,
padding=1,
bias=False
),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Conv2d(
in_channels=128,
out_channels=out_channels,
kernel_size=3,
padding=1,
stride=1,
bias=False
),
nn.BatchNorm2d(num_features=out_channels)
)
# 2、短路层(实线结构短路层无卷积)
# 3、主线路与短路层相加后的ReLU
self.relu = nn.ReLU()
def forward(self, x):
# 1、主线路处理
f = self.stage(x)
# 2、短路层处理(实线结构短路层无卷积)
# 3、两部分相加
h = f + x
# 4、输出
o = self.relu(h)
return o本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 三、计算机视觉_04AlexNet、VggNet、ResNet设计思想

发表评论 取消回复