今天学Flink的关键技术–容错机制,用一些通俗的比喻来讲这个复杂的过程。参考自《离线和实时大数据开发实战》
需要先回顾昨天发的Flink关键概念
检查点(checkpoint)
Flink容错机制的核心是分布式数据流和状态的快照,从而当分布式job由于网络、集群或者任何原因失败时,可以快速从这些分布式快照(检查点checkpoint)中快速恢复,且是轻量级的。
理解思路
Flink容错机制的关键是分组标记栏(barrier)。用河水的例子来简单类比:
- Storm是一滴一滴地处理数据;
- SparkStreaming就像水坝一样,一批一批地放水,上一批放的水处理完了,才会放下一批水;
- Flink的处理方式则更为优雅,它在水中定期地插入barrier,水仍然继续流(所以轻量)只是加了些barrier,如果源头有多个数据流,那么都会同步地增加同样的barrier。
同时在job处理的过程中,为了保证iob失败的时候可以从错误中恢复,Flink还对barrier 进行对齐(align)操作,比如某个operator有多个数据流,那么Flink会等到其多个输入流的同样的barrier 都到了(这就是align的含义),才会将对齐那一刻的状态进行保存,确保出等的时候可以恢复。当然,对齐也是有负面影响的,如果某个源头数据延迟很多,为了对其可能造成任务延迟,对齐是可以根据业务选择关闭的
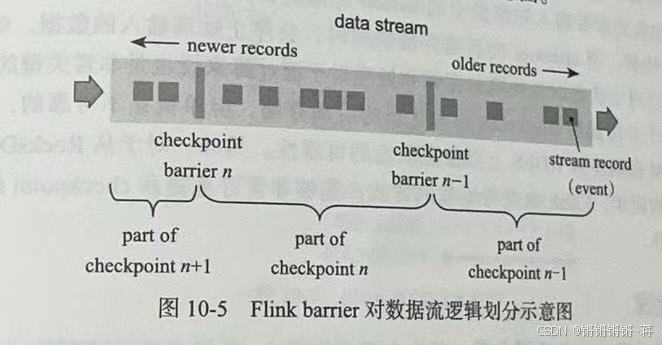
详细描述
barrier不会干扰正常数据,数据流分割成两部分,一部分进去当前检查点,一部分进入下一检查点。每个barrier带有检查点ID n,并且之前的数据都进入了这个检查点,检查点中会记录数据的进度信息即偏移量。分布式job中间的operator会接受这些数据流,当接收到带有检查点n标识的barrier时,会给所有输出流也插入一个标识n的barrier。当sink operator(DAG的终点)接收到所有输入流的barrier n时,确认检查点n 已完成。所有sink都确认检查点n完成,这个检查点才完成。
这个中间的operator,如果有多个输入流,是需要对齐
对齐操作:
- 接收到某个输入流的barrier n,就不能继续处理这个输入流后的数据,直到其余流都收到。不然检查点会和下一个混淆;
- 先不处理barrier n所属的数据流,从这些数据流接收到的数据先放缓冲区;
- 当从最后一个流提取到barrier n,operator会把等待发送的数据向后传,同时发射检查点n所属的barrier。
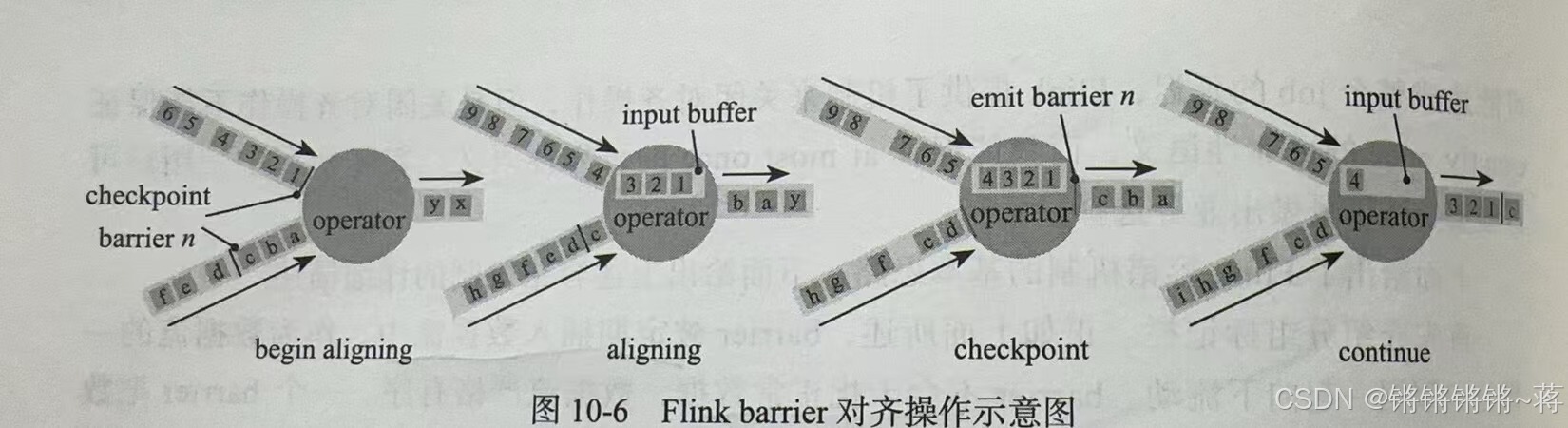
经过上述步骤,operator恢复所有输入流数据的处理,并优先处理输入缓存中的数据。
保存点(Savepoint)
检查点是由Flink自动管理的,定期创建,发生故障之后自动读取进行恢复,这是一个“自动存盘”的功能;而保存点不会自动创建,必须由用户明确地手动触发保存操作,所以就是“手动存盘”。
场景:
- 版本管理和归档存储
- 更新Flink版本
- 更新应用程序
- 调整并行度
- 暂停应用程序
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 实时数据开发 | 怎么通俗理解Flink容错机制,提到的checkpoint、barrier、Savepoint、sink都是什么

发表评论 取消回复