片上网络拓扑决定了网络中节点和通道之间的物理布局和连接。拓扑对整体网络性价比的影响是巨大的。拓扑决定了消息 必须经过的跳数(或路由器)以及跳数之间的互连长度,从而显著影响网络延迟。由于经过路由器和链路会产生功耗,因此 拓扑对跳数的影响也会直接影响网络能耗。此外,拓扑还决定了节点之间备用路径的总数,影响网络分散流量的能力,从而 支持带宽要求。
The implementation complexity cost of a topology depends on two factors:
- the number of links at each node (node degree)
- and the ease of laying out a topology on a chip (wire lengths and the number of metal layers required)
最简单的拓扑结构之一是总线,它通过一个共享通道连接一组组件。总线上的所有组件都可以观察到总线上的每条 消息;这是一种有效的broadcast medium。但是,由于共享通道会随着更多组件的添加而饱和,因此总线的可扩展性有限。
在本章中,我们将重点介绍switched topologies,其中组件之间通过一组router和link相互连接。我们首先描述几个指标,这些指标对于 在比较拓扑时开发粗略的直觉非常有用。接下来,我们将描述片上网络中几种常用的拓扑,并使用这些指标对它们进行比较。
METRICS
由于设计人员通常在构建片上网络时要做的第一个决定通常是拓扑结构的选择,因此在确定网络的其他方面(例如路由、流量控制和 微架构)之前,先快速比较不同拓扑的优劣,是非常有用的,有时候甚至是决定性的。
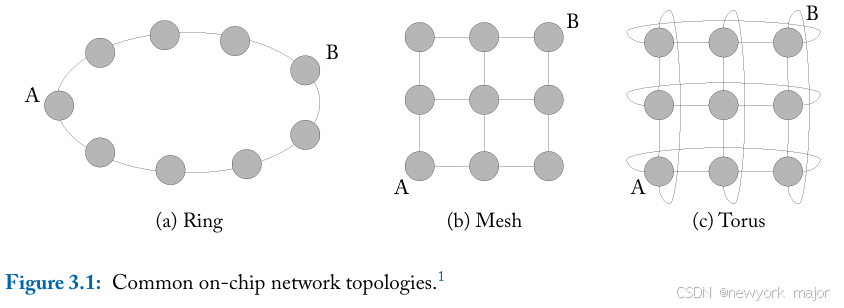
这里,我们描述了几个在比较不同拓扑时有用的抽象指标。图3.1显示了用于说明这些指标的三种常用on-chip topologies;
与traffic无关的指标
我们首先定义了一组设计时需要考虑的指标,这些指标与流经网络的流量无关。
- Degree
degree指的是每个node上的link数目;
例如,对于图3.1 中的拓扑,环形拓扑的degree为 2,因为有两个link 在每个node上;,而Torus的degree为四,因为每个节点都有四个link将其连接到 四个相邻节点;在mesh网络中,并非所有switches都具有统一的degree。
degree可以作为网络成本的一个重要参考指标,因为更高的度需要router上的更多端口, 这增加了实现的复杂性,并增加了每个router的面积/功耗开销。 每个router的端口数称为router radix;
- Bisection bandwidth
二分带宽是将网络分成两个相等部分的一条切线上的带宽。
例如,在图3.1 中,对于ring, 切开后link的条数为2,所以其bisection bandwidth为2;对于mesh,带宽为 3,对于torus,带宽为 6。
此带宽通常用于定义particular network的最坏情况下的性能,因为它限制了从系统的一端到另一端可以移动的总数据量;它也可以作为成本的一个考量因素,因为它代表了 实现网络所需的全局布线量。作为衡量指标,二分带宽对于片上网络的用处不如片外网络大, 因为global on-chip wiring相对于片外引脚带宽,片上布线被认为是丰富的;
- Diameter
网络直径是拓扑中任意两个节点之间的最大距离,其中距离是最短路径中的link数。
例如,在上述的例子中,ring型结构的diameter是4,mesh的是4,torus的是2;
此参数作为topology种的最大延迟的一个最直观的衡量;
与traffic相关的指标
接下来,我们定义一组取决于流经网络的流量(即src ‑ dst paris)的指标。
- Hop count
一条消息从源到目的地所经过的跳数,或者它所经过的link num,称之为hop count;
这是一个非常简单且有用的网络延迟的评估参数,因为每个node和link都会产生一些传播延迟,即使没有竞争也是如此。最大的hop count由network diameter给出。除了最大跳数,average hop count作为网络延迟的评估参数也非常有用。它由网络中所有可能的src‑dst pairs的平均跳数给出;
如果上述3种topolophy的node个数相同,假设每个节点向其他每个节点发送流量的概率相等,那么ring型结构相较于mesh和torus, hop count的值会更大;max hop count,ring是4,mesh也是4,而torus是2;考虑到平均hop count, ring是
, mesh是
, 而torus是
;
- Maximum channel load
此指标可用作估计网络可支持的最大带宽或网络饱和前每个节点可注入网络的最大每秒比特数 (bps) 的评估参数;
直观地说,它首先涉及确定在特定的traffic pattern下,网络中的哪个link或channel将最拥塞,因为该链路将限制整体网络带宽。 对于均匀随机流量,此链路通常位于二分切线上。
接下来,估计此channel上的负载。由于在设计的早期阶段,我们还不知道所用链路的具体情况(每个通道有多少实际互连,以及每个互连的带宽(以 bps 为单位),因此我们需要一种相对的负载测量方法。在这里,我们将其定义为相对于注入带宽。因此,当我们说通道上的负载为 2 时,这意味着该通道的负载 是注入带宽的两倍。因此,如果我们在每个节点的每个周期向网络注入一个 flit,则每个周期将有两个 flit 希望traverse this specific channel。如果瓶颈通道每个周期只能处理一个 flit,则会将网络的最大带宽限制为链路带宽的一半,即最多每隔一个周 期可以注入一个 flit。因此,maximum channel load越高,网络带宽越低。
Channel load可以通过多种方式计算,通常使用概率分析。 如果尚未确定路由和流量控制,则仍然可以通过假设理想路由(路由协议在所有可能的最短路径之间均 匀分配流量)和理想流量控制(只要有流量发往该链路,流量控制协议就使用该链路的每个周期)来计算 通道负载。
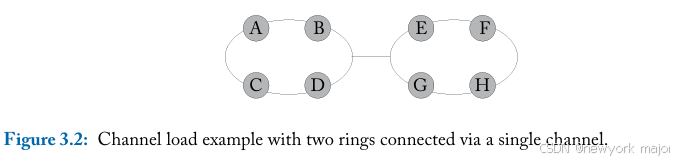
在这里,我们将通过一个简单的例子来说明这一点,但本章的其余部分将仅展示各种常见片上网 络拓扑的最大通道负载公式,而不是介绍它们的推导过程。图3.2显示了两个环通过单个通道连接的示例 网络拓扑。首先,我们假设均匀随机流量,其中每个节点都有相同的概率向网络中的每个其他节点(包括 其自身)发送流量。要计算最大通道负载,我们首先需要确定瓶颈通道。这里,它是环之间的单个通道,以粗 体显示。我们假设它是双向链路。在理想路由下,每个节点注入的流量中有一半将保留在其环内,而另一 半将穿过瓶颈通道。例如,对于节点 A 注入的每个数据包,它有1=8 的概率到达 B、C、D、E、F、G、H 或其自 身。当数据包的目的地是 A、B、C、D 时,它不会穿过瓶颈通道;当它发往 E、F、G、H 时,它会通过。因此, A 的注入带宽的1/2会穿过信道。其他节点的注入带宽的1/2也会穿过信道。因此,此瓶颈信道上的信道负载为 2。结果,网络在1/2注入带宽时饱和。向两个环添加更多节点将进一步增加信道负载,从而降低bandwidth;
- Path diversity
在给定src-dst pair之间提供多条最短路径(
,其中R表示路径多样性) 的拓扑,比在src-dst pair之间只有一条路径(
)的拓扑具有更大的路径多样性。
拓扑内的路径多样性使路由算法能够更灵活地平衡流量负载,从而减少通道负载并提高吞吐量。路径多样性还使数据包能够绕过网络中的故障。图3.1a中的ring结构,不提供路径多样性(
),因为节点对之间只有 一条最短路径。如果数据包在 A 和 B 之间顺时针传输(在图3.1a 中),它将穿越四跳;如果数据包逆时针传输,它将穿越五跳。提供更多路径只能以更长的传输距离为代价。当环中有偶数个节点时,由于存在两条最小路径,环中途两个节点的路径多样性为2。另一方面,图3.1b和 c 中的mesh和torus提供了更丰富的路径多样性,mesh在 A 和 B 之间提供了六条不同的路径,所有路径的最短距离均为四跳;
Direct Toplogies
- ring
- mesh
- torus
直接网络是指每个terminal node(例如,芯片多处理器中的core/home node/sn) 都与router相关联的网络;所有router都充当流量的sources/sinks of traffic,并充当来自其他节点的流量的switch。到目前为止,大多数片上网络设计都使用直接网络,因为在芯片上面积受限的环境中,co-locating routers with terminal nodes通常最合适。
直接拓扑可以描述为 k-ary n-cubes,其中k is the number of nodes along k-ary n-cubes each dimension, and n is the number of dimensionsl; 例如:
- 4x4的mesh, or torus,是一个4-ary 2-cube,一个16个nodes的结构;
- 8x8的mesh/torus, 是一个8-ary 2-cube,共64个nodes的结构;
- 而4x4x4的mesh/torus是一个4-ary 3-cube的结构;
- k个节点的ring, k-ary 1cubes;
此表示法假设每个维度上的节点数相同,因此节点总数为k^n 。实际上,大多数片上网络都利用可以很好地映射到平面基板的二维拓扑,否则将需要更多的金属层;对于片外网络而言, 情况并非如此,因为cables between chassis provide 3-D connectivity。在每个维度上, k 所代表的nodes,通过channel与其最近的邻居相连。ring其实可以看成一个torus结构,k-ary 1-cubes;
对于torus,所有节点的degree都相同;但是对于mesh,网络边缘的节点的degree低于网络中心的节点。torus也是边对称的(mesh不是),此属性有助于torus网络平衡各个通道的流量。 由于缺乏边缘对称性,mesh网络对中心通道的需求明显高于边缘通道;
接下来,我们根据第3.1节中给出的abstract metrics来检查torus和mesh的相关指标。torus network在每个维度上,需要有2个channel(2n);。因此,对于二维圆环,度数为4,对于三维圆环,度数为6。torus网络的平均跳数是通过平均所有可能的节点对之间的最小距离来找到的:
如果没有torus的wrap link,mesh的平均最小跳数会略高,如下所示:
除此以外,对于torus的bisection, 在均匀随机traffic, k为even的情况下,masx channle load 是k/8, 从而算出max injection throughput是 8/k flits/node/cycle;
对于mesh网络,max channel load 是k/4, 从而算出max injection throughput是 4/k flits/node/cycle;
与ring网络相比,mesh网络和torus网络都为路由消息提供了路径多样性。随着维数的增加,路径多样性也会增加。
Indirect Toplogies
Indirect networks connect terminal nodes via one or more intermediate stages of switch nodes;
间接网络通过一个或多个中间阶段的switch node,连接terminal node;只有terminal node才是流量的来源和目的地,中间节点只是在终端节点之间传输流量。
crossbars
最简单的间接拓扑结构称为crossbar。交叉开关通过nxm个简单crosspoint switch nodes, 将n个input和m个output连接起来。它被称为无阻塞,因为它始终可以将发送方连接到唯一的接收方;
butterflies
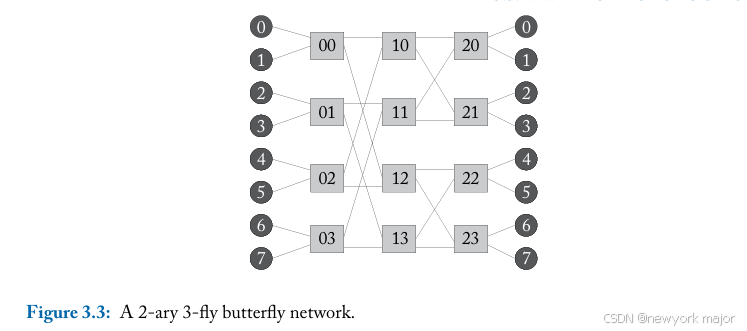
butterfly network是一种典型的indirect topologies; 可以被描述为k-ary n-flies, 其中,k表示switches的degree, n表示switches的级数; 上图中的例子就是一个2-ary 3-fly的bufferfly network。
这种网络由k^n个 terminal node(core or memory)组成, 同时包含n级k x k的switch节点;上图中,源节点和目标节点在此图中显示为逻辑上分开的,源节点在左侧,目标节点在右侧;
接下来,我们使用第 3.1 节中给出的指标来分析bufferfly。
- 蝴蝶网络中每个中间switch的degree为2k。
- 与hop count根据src-dst pair而变化的mesh或torus不同,蝴蝶网络中的每个src-dst pair都经历相同的hop count,即n-1 (假设源节点和目标节点也是交 换机)。
- 对于均匀分布的流量,蝴蝶的maximum channel load为1,导致峰值injection throughput为 1 flit/node/cycle。
- 其他需要将大量流量从网络的一半发送到另一半的流量模式将增加maximum channel load,从而降低injection throughput;
蝶形网络的主要缺点是缺乏路径多样性,并且这些网络无法利用局部性。在没有路径多样性的情况下,蝶形网络在 面对不平衡流量模式时表现不佳,例如当网络一半的每个节点都向另一半的节点发送消息时。
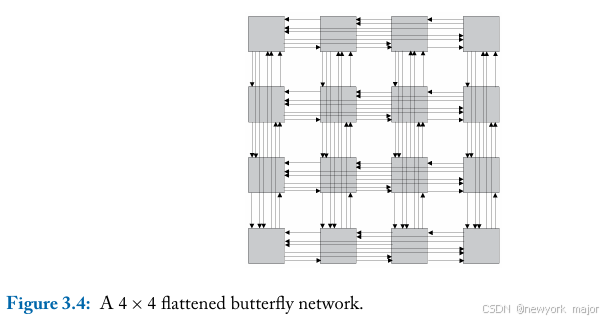
Flattended bufferfly network.
折叠版的蝴蝶,称为扁平蝴蝶,将中间的switch, 全部转换为一个switch的结构,将拓扑的间接版本转换为直接版本。现在,每个2x2 switch都变成了higher-radix switch。图3.4显示了4x4版本,其中每个router都由7个端口(包括图中未显示的core)。每个目的地最多可通过两跳到达。但是,最小路由在平衡流量负载方面效果不佳,因此必须选择非最小路径,从而增加跳数。
clos networks
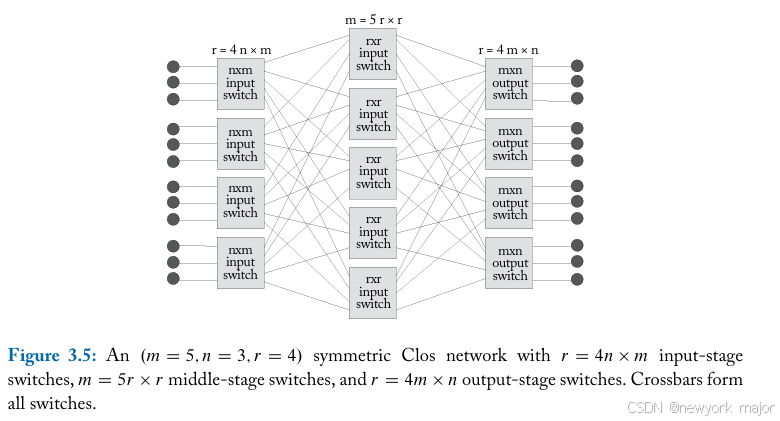
对称 Clos 网络是一个三级网络,其特征通过仨个维度,(m,n,r)来体现;
- m表示中间stage的switches的个数;
- n表示每个input/output switch的input/output port;
- r表示第一级,或者最后一级的switches个数;
当 m > 2n-1时,Clos network is strictly non-blocking,即任何输入端口都可以连接到 任何唯一的输出端口,就像crossbar一样;
- Clos network由r x n个nodes组成;
- 如上图所示,一个3级的Clos network, 所有的src-dst pair之间的hop count都是4;
- 每一级并不是使用特定的switch进行处理;
- 第一级/最后一级的switch的degree是n+m;
- 中间的switch的degree为2r;
- m个middle switch的path diversity为
- A disadvantage of a Clos network is its inability to exploit locality between source and destination pairs;
- Clos网络的一个缺点是无法利用源地址和目的地址之间的局部性。
Clos 网络可以沿着中间的一组switch折叠,这样输入和输出switch就可以共享;
fat trees
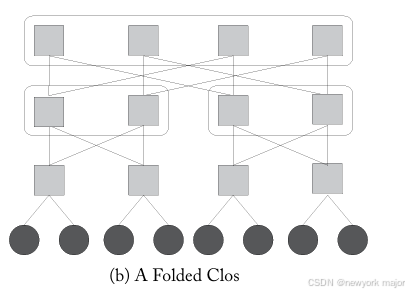
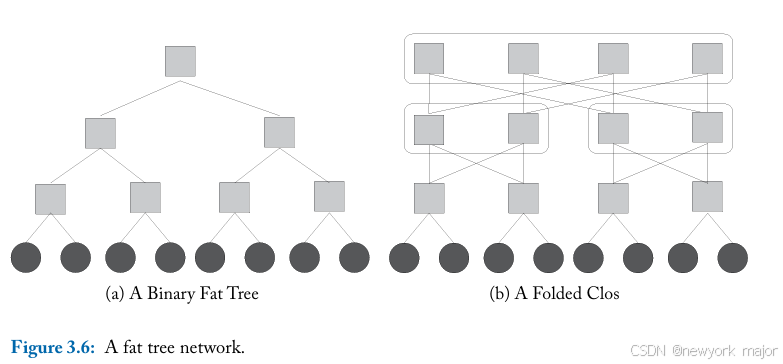
fat trees在逻辑上是一种二叉树网络,其中布线资源随着靠近根节点的阶段而增加(图 3.6a)。胖树可以由folded网络构建,如图3.6b所示,与图 3.6a 中的树网络相比,路径具有多样性。clos在根部折叠回自身,在逻辑上形成5级clos网络。在fat tree中,消息沿树向上路由,直到到 达共同祖先,然后向下路由到目的地;这使得fat tree能够利用通信节点之间的局部性(take advantage of locality between communicating nodes)。
尽管较高级别节点中的link比较低级别节点中的链接宽得多,但fat tree中每个switch的逻辑degree都是4。
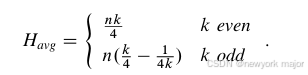
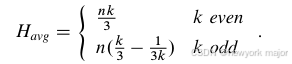

irregular topologies
MPSoC 设计可以利用各种异构IP blocks;由于异构性,上面描述的网格或环面等常规拓扑可能并不合适。 利用这些异构核心,定制拓扑通常比标准拓扑更节能,性能更好。
通常情况下,MPSoC的通信需求是已知的。基于结构化的通信模式,可以构建一个application characterization graph来捕获IP块之间的点对点通信需求。为了开始构建所需的拓扑结构,必须确定组件的数量、大小以及由通信模式决定的连接性。
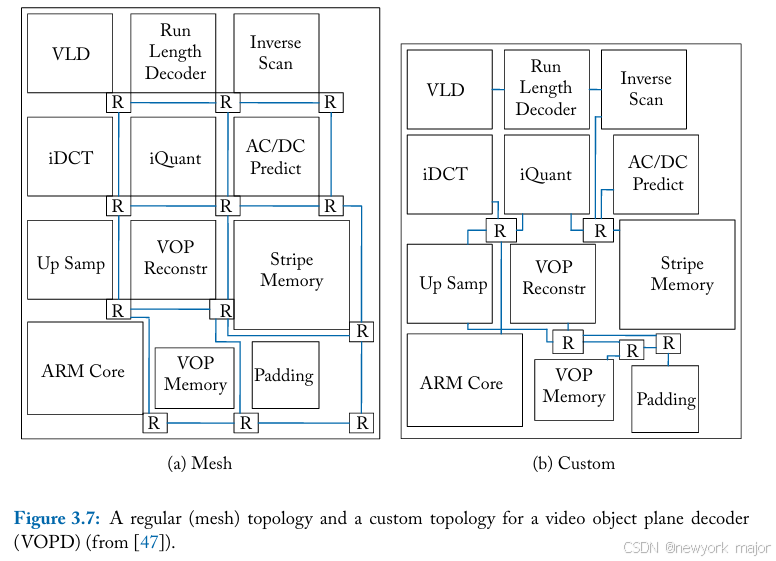
如上图所示,左侧是video object plane decoder的自定义拓扑结构示例。MPSoC由 12 个异构 IP 块组成。在图 3.7a 中,这些ip block需要 12 个router 的3x4 mesh拓扑。当考虑到特定的应用特性(例如,并非每IP都需要直接与其他每个块通信)时,将创建自定义拓扑(图3.7b)。这种不规则拓扑将switches从 12 个减少到 5 个;通过减少拓扑中的switches和links数量,可以显著节省功耗和面积。某些块可以直接连接而无需开关,例如 VLD 和运行长度解码器单元。
最后,switch的degree发生了变化;图3.7a中的 网格需要一个具有 5 个输入/输出端口的开关(尽管可以在边缘节点上减少端口)。5 个输入/输出 端口代表四个基本方向:北、南、东和西加上一个injection/enjection端口。所有这些端口都需要输入和输出连接,从而形成5x5 crossbar。使用定制拓扑,并非所有块都需要输入和输出端口;图3.7b中最大的switch是4x4 switch。在定制拓扑中,并非进出路由器的链路之间的每个连接都是必要的,从而导致switch较小;连接性受到限制,因为此特定应用程序不需要完全连接。
SPLITTING AND MERGING
人们已经探索了两种定制拓扑的技术:split和merge;
splitting,首先创建一个连接所有节点的大型crossbar,然后迭代地将其拆分为多个小switch,以适应一组设计约束。或者,具有大量switch的网络,如mesh或torus,可以用作起点。从这个起点开始,switch被合并在一起以减少面积和功率。
- splitting
实现定制网络拓扑的一种技术是从一个large fully connected switch(crossbar)开始。如此大的crossbar可能会违反设计约束,必须迭代地拆分成更小的switch,直到满足设计约束。两个switch之间提供的带宽必须满足现在必须在分区之间流动的通信量。
node可以在分区之间移动,以优化switch之间的通信量。
- merging
迭代地将较大的switch拆分为较小的switch的另一种方法是,从large switch开始,进行合并。通过合并拓扑中相邻的router,可以降低功耗和面积成本。在这种设计流程中,首先要对各个MPsoc component进行布图规划。可以根据应用特征图进行布局规划,例如,在布局规划时,通信频繁的节点应该放置在很近的地方。接下来,router被放置在每个channel交叉点,在那里三个或更多的通道合并或发散。最后一步是合并相邻的路由器,如果它们靠得很近,并且合并不会违反带宽或性能限制,并且考虑到合并会带来一些好处(例如降低功耗),则合并它们。
拓扑综合算法示例
Topology synthesis and mapping is an NP-hard problem.
因此,已经提出了几种启发式方法来有效地找到最佳拓扑。在本节中,我们提供 了一个针对 MPSoC 的特定应用拓扑合成算法的示例,该算法来自 Murali 等人。该算法是分割算法的一个示例; 它们从应用程序通信图开始,该图显示了各种应用程序任务之间所需的带宽,如图3.8a 所示。
该算法综合了许多不同的拓扑结构,从一个所有IP核通过一个large switch连接,到每个core都有自己的switch的极端topology。对于每个switch,通过算法调整工作频率和链路宽度。对于给定的switch i,输入图(图3 - 8a)被划分为i个最小切割分区。图3 - 8b展示了i==3的最小切割分区。对图进行最小割划分,使得跨划分的边的权值小于划分内的边。此外,分配给每个分区的结点数量几乎保持不变。这样的最小切割分区将确保具有高带宽的业务流使用相同的switch进行通信。
一旦确定了最小切割分区,就必须限制路由以避免死锁。我们会在第4章讨论避免死锁。接下来,switch之间必须建立物理link,并为所有流经switch的traffic找到路径。一旦确定了switch的大小和它们的连通性,就可以评估设计,以查看switch的功耗和跳数目标是否已经满足。最后,使用布局规划器确定综合设计的面积和wire长度。
Hierarchical Topologies
在上面的描述中,我们都是假设network node和terminal node之间,是一一对应的关系;我们还假设整个系统的拓扑结 构是统一的。然而,情况并非如此。在实际系统中,多个节点可能clustered together在一个拓扑中,这些cluster通过另一个拓扑连接在一起,构建一个分层设计;
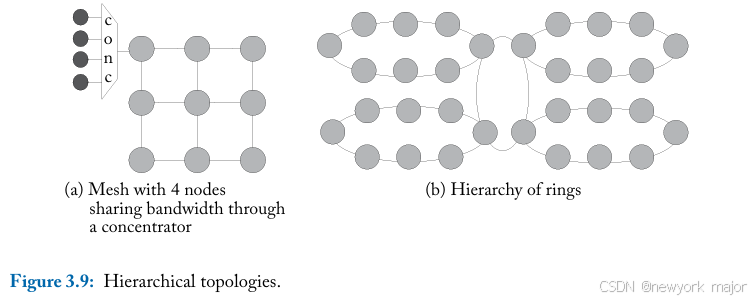
层次化拓扑的最简单形式是多个core使用connector共享同一个router。
- 图3.9a显示了这 样一个concentrated mesh,其中四个terminate node(core, cache等)共享一个network router。使用concentrated可减少mesh所需的router数量,从而减少hop cnt和网络大小(面积)。这也有助于将网络扩展到更大的规模。
- 在图3.9a中,concentration允许3x3网格仅使用 9 个router(而不是 36 个)来连接 36 个节点。但是,另一 方面,concentration会增加网络复杂性。concentrator必须实现sharing injection bandwidth的策略。此策略可以动态共享带宽或静态划分带宽,以便每个节点都能获得1/c 的injection bandwidth,其中c是concentration factor。
- 使用concentration的另一个缺点是,during periods of bursty communication,injection port bandwidth可能成为瓶颈。
图 3.9b 显示了另一种分层拓扑。32核芯片被划分为 8 个cluster。每个cluster由⼋个内核通过bi-directional ring连接而成。这4个ring, 通过另一个ring,互相连接。这种分层拓扑的挑战在于如何仲裁进入中心环的带宽。
Implemention
在本节中,我们将讨论芯片上拓扑的实现,同时考虑物理布局的实现和本章开头定义的抽象指标的作用。
PLACE-AND-ROUTE
拓扑中有两个组件需要在物理设计期间仔细考虑:links和routers;
- The links are routed on semi-global or global metal layers, depending on the channel widths and the distance they need to traverse。
- 导线电容往往比晶体管电容高一个数量级,如果优化不当,可能会dominate the energy of the network。
- target clock frequency决定了需要插入以满足时序的repeaters的大小和距离。
- 可以使用更粗的导线和更大的导线间距来降低导线电阻和耦合电容,从而提高速度和能效。然而,金属层密度规则和设计规则检查 (DRC) 可能会限制人们可以调 整这些参数的程度。
- 就面积而言,core to core links可以over active logic进行布线,从而减轻除repeaters以外的任何面积开销。
但需要小心,因为switching of transistors可能会在线路中引入串扰。同样,在低电压下工作的 SRAM 等 敏感电路上routing toggling links可能会引入故障和错误,导致缓存上方的区域通常被布线阻塞。因此,整个 芯片的布局规划需要仔细考虑links相对于处理器核心、缓存、内存控制器等的位置。
在router的实现过程中,需要考虑如下的几点:
- 在实现routers时,node degree(即router的in/out ports)决定了开销,因为每个端口都有相关的缓冲和state logic,并且需要link到下一个节点。
- 因此,虽然与高维网络相比,ring的网络性能(延迟、吞吐量、energy和可靠性)较差,但它们的实现开销较低,因为它们的degree为 2,而mesh或torus的degree为4。
- 同样,high-radix topologies(例如第3.3节中讨论的4x4 flattened butterfly)在相同channel width的情况下,比mesh具有更低的延迟和更高的吞吐量,但七端口router增加了更大的面积和energe footprint,特别是由于更大的crossbar switch,其面积以端口数的平方增长。
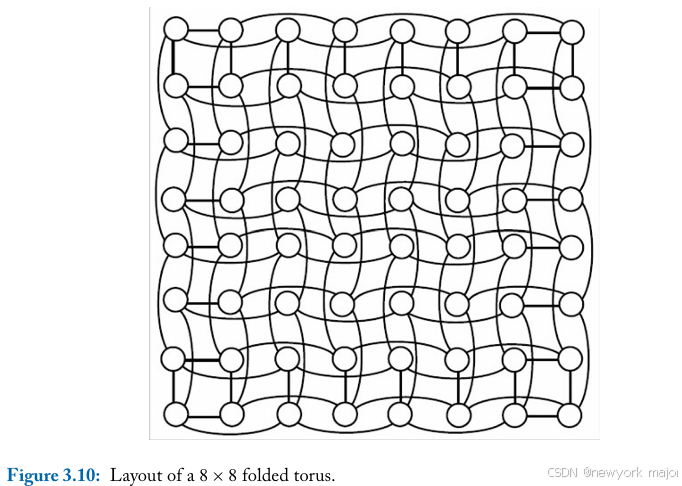
逻辑拓扑的2D floorplan也可能导致实施开销。例如,图3.1中的环形结构必须以折叠的形式在物理上进行安排,以使各节点间的导线长度相等(见图3.10),而不是在边缘节点之间使用长绕行链接。
因此,折叠环形结构中的导线长度是相同大小的mesh中的两倍,因此每跳时延和能量实际上更高。此外,环形结构需要两倍的链接,必须考虑在布线预算中。
如果沿着分割的导线轨道的可用数量是固定的,环形结构将受到比mesh更窄的link limits,从而降低每条link的带宽,增加传输延迟。另一方面,从建筑学角度比较,环形结构的跳数(导致更低的延迟和能量消耗)比网格更低。这些相反的特性说明了在选择不同拓扑结构时考虑实施细节的重要性。
同样,尝试创建针对应用程序通信图优化的不规则拓扑最终可能会产生许多交叉链接。这 些链接会在布局布线期间显示为线路拥塞,迫使自动化工具或设计人员绕过拥塞网络,从而增加 延迟和能源开销。
IMPLICATION OF ABSTRACT METRICS
我们在本章开头介绍了各种抽象指标,并用它们来比较和对比各种常见拓扑。在这里,我们将讨 论这些简单指标对片上网络实现的影响,解释为什么它们是片上网络延迟、面积和功耗的良好代理,同时强调使用这些指标的常见陷阱。
- Node degree
Node degree可用作router complexity的代理,因为higher degree意味着端口数量越多。在router中添加端口会导致额外的输入缓冲队列、allocators的额外请求以及crossbar switch的额外端口,所有这些都是router的critical path delay、area footprint, and power的主要因素。
虽然对于node degree较高的拓扑,router complexity肯定会增加,但link complexity与Node degree并不直接相关。这是因为link complexity取决于link width,因为link面积和功率开销与the number of ports的关系,比与the number of wires更密切。因此,如果在2端口 router和 3 端口router之间分配the same number of wires,则link complexity将大致相等。
- Hop count
hop count是广泛用来衡量整体网络延迟和功率的指标。 直观地看,这是有道理的,因为 flit 通常必须在每一跳处停止,going through the router pipeline followed by the link delay。然而,hop count在实践中并不总是与网络延迟相关,因为它在很大程度上取决于router pipeline length and the link propagation delay。
例如,一个只有两跳的网络,router pipeline depth of 5 cycles,router间距离较长,需要 4个周期进行link traversal,则实际网络延迟为18个周 期。相反,一个有三跳的网络,其中每个路由器都有一个单周期管道,链路延迟为一个周期,则总网络延迟只有六个 周期。如果两个网络具有相同的时钟频率,则后者具有更高跳数的网络反而会更快。不幸的是,router pipeline depth等参数通常直到设计周期的后期才为人所知。
通常情况下,拓扑以node degree和hop count为权衡,例如,一种拓扑可能具有low node degree但high average hop count(例如ring),而另一种拓扑可能具有high node degree但low average hop count(例如mesh),因此拓扑之间的比较变得更加棘手。在做出明智的选择之前, 必须考虑实施细节。
- Maximum channel load
最大信道负载是另一个可用作网络性能和吞吐量代理的指标。在这里,它是网络saturation throughput和最大功率的良好代理。拓扑上的最大信道负载越高,由拓扑和routing protocol引起的network congestion就越严重,因此,整体可实现吞吐量就越低。
显然,特定的流量模式会极大地影响最大信道负载,因此应使用代表性的流量模式来估计最大信道负载和吞吐量。由于它是饱和度的良好代理,因此它对于估计峰值功率也非常有用,as dynamic power is highest with peak switching activity and utilization in the network。
- Bisection bandwidth
二分带宽通常用作定义网络带宽的度量。二分链路上的channel load决定了网络在均匀随机流量下可实现的峰值吞吐量。例如,对于8x8网格,二分链路上的channel load(如第3.2 节所述)为8/4=2,将峰值注入吞吐量设置为 1/2 = 0.5 flits/node/cycle。 但是,由于负载平衡不完美,网络实现的实际吞吐量将低于此。
不理想的负载均衡是由于路由和流量控制协议在确定每个周期可以使用二分链路的实际数据量方面效率低下;这些问题将在后续章节中讨论。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » On-Chip-Network之Topology

发表评论 取消回复